kube-scheduler的排程上下文
Scheduler結構
Scheduler 是整個 kube-scheduler 的一個 structure,提供了 kube-scheduler 執行所需的元件。
type Scheduler struct {
// Cache是一個抽象,會快取pod的資訊,作為scheduler進行查詢,操作是基於Pod進行增加
Cache internalcache.Cache
// Extenders 算是排程框架中提供的排程外掛,會影響kubernetes中的排程策略
Extenders []framework.Extender
// NextPod 作為一個函數提供,會阻塞獲取下一個ke'diao'du
NextPod func() *framework.QueuedPodInfo
// Error is called if there is an error. It is passed the pod in
// question, and the error
Error func(*framework.QueuedPodInfo, error)
// SchedulePod 嘗試將給出的pod排程到Node。
SchedulePod func(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (ScheduleResult, error)
// 關閉scheduler的訊號
StopEverything <-chan struct{}
// SchedulingQueue儲存要排程的Pod
SchedulingQueue internalqueue.SchedulingQueue
// Profiles中是多個排程框架
Profiles profile.Map
client clientset.Interface
nodeInfoSnapshot *internalcache.Snapshot
percentageOfNodesToScore int32
nextStartNodeIndex int
}
作為實際執行的兩個核心,SchedulingQueue ,與 scheduleOne 將會分析到這兩個
SchedulingQueue
在知道 kube-scheduler 初始化過程後,需要對 kube-scheduler 的整個 structure 和 workflow 進行分析
在 Run 中,執行的是 一個 SchedulingQueue 與 一個 scheduleOne ,從結構上看是屬於 Scheduler
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
sched.SchedulingQueue.Close()
}
SchedulingQueue 是一個佇列的抽象,用於儲存等待排程的Pod。該介面遵循類似於 cache.FIFO 和 cache.Heap 的模式。
type SchedulingQueue interface {
framework.PodNominator
Add(pod *v1.Pod) error
// Activate moves the given pods to activeQ iff they're in unschedulablePods or backoffQ.
// The passed-in pods are originally compiled from plugins that want to activate Pods,
// by injecting the pods through a reserved CycleState struct (PodsToActivate).
Activate(pods map[string]*v1.Pod)
// 將不可排程的Pod重入到佇列中
AddUnschedulableIfNotPresent(pod *framework.QueuedPodInfo, podSchedulingCycle int64) error
// SchedulingCycle returns the current number of scheduling cycle which is
// cached by scheduling queue. Normally, incrementing this number whenever
// a pod is popped (e.g. called Pop()) is enough.
SchedulingCycle() int64
// Pop會彈出一個pod,並從head優先順序佇列中刪除
Pop() (*framework.QueuedPodInfo, error)
Update(oldPod, newPod *v1.Pod) error
Delete(pod *v1.Pod) error
MoveAllToActiveOrBackoffQueue(event framework.ClusterEvent, preCheck PreEnqueueCheck)
AssignedPodAdded(pod *v1.Pod)
AssignedPodUpdated(pod *v1.Pod)
PendingPods() []*v1.Pod
// Close closes the SchedulingQueue so that the goroutine which is
// waiting to pop items can exit gracefully.
Close()
// Run starts the goroutines managing the queue.
Run()
}
而 PriorityQueue 是 SchedulingQueue 的實現,該部分的核心構成是兩個子佇列與一個資料結構,即 activeQ、backoffQ 和 unschedulablePods
activeQ:是一個 heap 型別的優先順序佇列,是 sheduler 從中獲得優先順序最高的Pod進行排程backoffQ:也是一個 heap 型別的優先順序佇列,存放的是不可排程的PodunschedulablePods:儲存確定不可被排程的Pod
type SchedulingQueue interface {
framework.PodNominator
Add(pod *v1.Pod) error
// Activate moves the given pods to activeQ iff they're in unschedulablePods or backoffQ.
// The passed-in pods are originally compiled from plugins that want to activate Pods,
// by injecting the pods through a reserved CycleState struct (PodsToActivate).
Activate(pods map[string]*v1.Pod)
// AddUnschedulableIfNotPresent adds an unschedulable pod back to scheduling queue.
// The podSchedulingCycle represents the current scheduling cycle number which can be
// returned by calling SchedulingCycle().
AddUnschedulableIfNotPresent(pod *framework.QueuedPodInfo, podSchedulingCycle int64) error
// SchedulingCycle returns the current number of scheduling cycle which is
// cached by scheduling queue. Normally, incrementing this number whenever
// a pod is popped (e.g. called Pop()) is enough.
SchedulingCycle() int64
// Pop removes the head of the queue and returns it. It blocks if the
// queue is empty and waits until a new item is added to the queue.
Pop() (*framework.QueuedPodInfo, error)
Update(oldPod, newPod *v1.Pod) error
Delete(pod *v1.Pod) error
MoveAllToActiveOrBackoffQueue(event framework.ClusterEvent, preCheck PreEnqueueCheck)
AssignedPodAdded(pod *v1.Pod)
AssignedPodUpdated(pod *v1.Pod)
PendingPods() []*v1.Pod
// Close closes the SchedulingQueue so that the goroutine which is
// waiting to pop items can exit gracefully.
Close()
// Run starts the goroutines managing the queue.
Run()
}
在New scheduler 時可以看到會初始化這個queue
podQueue := internalqueue.NewSchedulingQueue(
// 實現pod對比的一個函數即less
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
internalqueue.WithClusterEventMap(clusterEventMap),
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
)
而 NewSchedulingQueue 則是初始化這個 PriorityQueue
// NewSchedulingQueue initializes a priority queue as a new scheduling queue.
func NewSchedulingQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option) SchedulingQueue {
return NewPriorityQueue(lessFn, informerFactory, opts...)
}
// NewPriorityQueue creates a PriorityQueue object.
func NewPriorityQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option,
) *PriorityQueue {
options := defaultPriorityQueueOptions
for _, opt := range opts {
opt(&options)
}
// 這個就是 less函數,作為打分的一部分
comp := func(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
return lessFn(pInfo1, pInfo2)
}
if options.podNominator == nil {
options.podNominator = NewPodNominator(informerFactory.Core().V1().Pods().Lister())
}
pq := &PriorityQueue{
PodNominator: options.podNominator,
clock: options.clock,
stop: make(chan struct{}),
podInitialBackoffDuration: options.podInitialBackoffDuration,
podMaxBackoffDuration: options.podMaxBackoffDuration,
podMaxInUnschedulablePodsDuration: options.podMaxInUnschedulablePodsDuration,
activeQ: heap.NewWithRecorder(podInfoKeyFunc, comp, metrics.NewActivePodsRecorder()),
unschedulablePods: newUnschedulablePods(metrics.NewUnschedulablePodsRecorder()),
moveRequestCycle: -1,
clusterEventMap: options.clusterEventMap,
}
pq.cond.L = &pq.lock
pq.podBackoffQ = heap.NewWithRecorder(podInfoKeyFunc, pq.podsCompareBackoffCompleted, metrics.NewBackoffPodsRecorder())
pq.nsLister = informerFactory.Core().V1().Namespaces().Lister()
return pq
}
瞭解了Queue的結構,就需要知道 入佇列與出佇列是在哪裡操作的。在初始化時,需要註冊一個 addEventHandlerFuncs 這個時候,會注入三個動作函數,也就是controller中的概念;而在AddFunc中可以看到會入佇列。
注入是對 Pod 的informer注入的,注入的函數 addPodToSchedulingQueue 就是入棧
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToSchedulingQueue,
UpdateFunc: sched.updatePodInSchedulingQueue,
DeleteFunc: sched.deletePodFromSchedulingQueue,
},
func (sched *Scheduler) addPodToSchedulingQueue(obj interface{}) {
pod := obj.(*v1.Pod)
klog.V(3).InfoS("Add event for unscheduled pod", "pod", klog.KObj(pod))
if err := sched.SchedulingQueue.Add(pod); err != nil {
utilruntime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err))
}
}
而這個 SchedulingQueue 的實現就是 PriorityQueue ,而Add中則對 activeQ進行的操作
func (p *PriorityQueue) Add(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
// 格式化入棧資料,包含podinfo,裡會包含v1.Pod
// 初始化的時間,建立的時間,以及不能被排程時的記錄其plugin的名稱
pInfo := p.newQueuedPodInfo(pod)
// 入棧
if err := p.activeQ.Add(pInfo); err != nil {
klog.ErrorS(err, "Error adding pod to the active queue", "pod", klog.KObj(pod))
return err
}
if p.unschedulablePods.get(pod) != nil {
klog.ErrorS(nil, "Error: pod is already in the unschedulable queue", "pod", klog.KObj(pod))
p.unschedulablePods.delete(pod)
}
// Delete pod from backoffQ if it is backing off
if err := p.podBackoffQ.Delete(pInfo); err == nil {
klog.ErrorS(nil, "Error: pod is already in the podBackoff queue", "pod", klog.KObj(pod))
}
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", PodAdd).Inc()
p.PodNominator.AddNominatedPod(pInfo.PodInfo, nil)
p.cond.Broadcast()
return nil
}
在上面看 scheduler 結構時,可以看到有一個 nextPod的,nextPod就是從佇列中彈出一個pod,這個在scheduler 時會傳入 MakeNextPodFunc 就是這個 nextpod
func MakeNextPodFunc(queue SchedulingQueue) func() *framework.QueuedPodInfo {
return func() *framework.QueuedPodInfo {
podInfo, err := queue.Pop()
if err == nil {
klog.V(4).InfoS("About to try and schedule pod", "pod", klog.KObj(podInfo.Pod))
for plugin := range podInfo.UnschedulablePlugins {
metrics.UnschedulableReason(plugin, podInfo.Pod.Spec.SchedulerName).Dec()
}
return podInfo
}
klog.ErrorS(err, "Error while retrieving next pod from scheduling queue")
return nil
}
}
而這個 queue.Pop() 對應的就是 PriorityQueue 的 Pop() ,在這裡會將作為 activeQ 的消費端
func (p *PriorityQueue) Pop() (*framework.QueuedPodInfo, error) {
p.lock.Lock()
defer p.lock.Unlock()
for p.activeQ.Len() == 0 {
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the p.closed is set and the condition is broadcast,
// which causes this loop to continue and return from the Pop().
if p.closed {
return nil, fmt.Errorf(queueClosed)
}
p.cond.Wait()
}
obj, err := p.activeQ.Pop()
if err != nil {
return nil, err
}
pInfo := obj.(*framework.QueuedPodInfo)
pInfo.Attempts++
p.schedulingCycle++
return pInfo, nil
}
在上面入口部分也看到了,scheduleOne 和 scheduler,scheduleOne 就是去消費一個Pod,他會呼叫 NextPod,NextPod就是在初始化傳入的 MakeNextPodFunc ,至此回到對應的 Pop來做消費。
schedulerOne是為一個Pod做排程的流程。
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.ErrorS(err, "Error occurred")
return
}
if sched.skipPodSchedule(fwk, pod) {
return
}
...
排程上下文
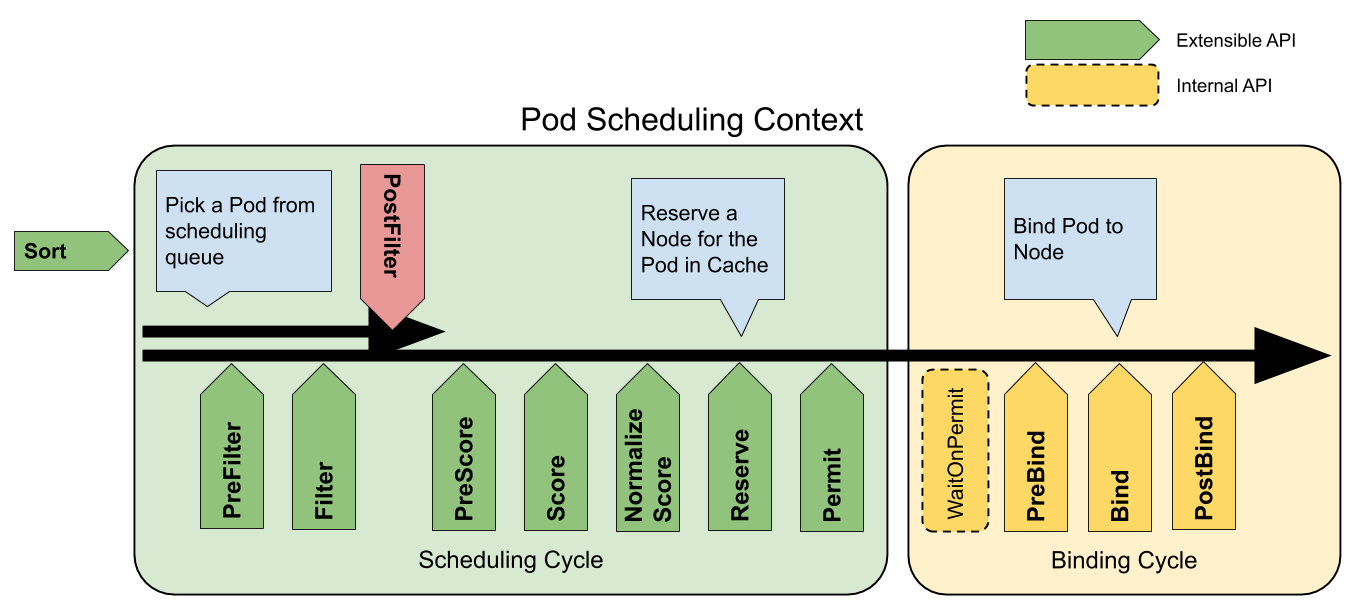
當了解了scheduler結構後,下面分析下排程上下文的過程。看看擴充套件點是怎麼工作的。這個時候又需要提到官網的排程上下文的圖。
排程框架 [2]
排程框架 (scheduling framework SF ) 是kubernetes為 scheduler設計的一個pluggable的架構。SF 將scheduler設計為 Plugin 式的 API,API將上一章中提到的一些列排程策略實現為 Plugin。
在 SF 中,定義了一些擴充套件點 (extension points EP ),而被實現為Plugin的排程程式將被註冊在一個或多個 EP 中,換句話來說,在這些 EP 的執行過程中如果註冊在多個 EP 中,將會在多個 EP 被呼叫。
每次排程都分為兩個階段,排程週期(Scheduling Cycel)與繫結週期(Binding Cycle)。
- SC 表示為,為Pod選擇一個節點;SC 是序列執行的。
- BC 表示為,將 SC 決策結果應用於叢集中;BC 可以同時執行。
排程週期與繫結週期結合一起,被稱為排程上下文 (Scheduling Context),下圖則是排程上下文的工作流
注:如果決策結果為Pod的排程結果無可用節點,或存在內部錯誤,則中止 SC 或 BC。Pod將重入佇列重試
擴充套件點 [3]
擴充套件點(Extension points)是指在排程上下文中的每個可延伸API,通過圖提現為[圖1]。其中 Filter 相當於 Predicate 而 Scoring 相當於 Priority。
對於排程階段會通過以下擴充套件點:
-
Sort:該外掛提供了排序功能,用於對在排程佇列中待處理 Pod 進行排序。一次只能啟用一個佇列排序。 -
preFilter:該外掛用於在過濾之前預處理或檢查 Pod 或叢集的相關資訊。這裡會終止排程 -
filter:該外掛相當於排程上下文中的Predicates,用於排除不能執行 Pod 的節點。Filter 會按設定的順序進行呼叫。如果有一個filter將節點標記位不可用,則將 Pod 標記為不可排程(即不會向下執行)。 -
postFilter:當沒有為 pod 找到FN時,該外掛會按照設定的順序進行呼叫。如果任何postFilter外掛將 Pod 標記為schedulable,則不會呼叫其餘外掛。即filter成功後不會進行這步驟 -
preScore:可用於進行預Score工作(通知性的擴充套件點)。 -
score:該外掛為每個通過filter階段的Node提供打分服務。然後Scheduler將選擇具有最高加權分數總和的Node。 -
reserve:因為繫結事件時非同步發生的,該外掛是為了避免Pod在繫結到節點前時,排程到新的Pod,使節點使用資源超過可用資源情況。如果後續階段發生錯誤或失敗,將觸發UnReserve回滾(通知性擴充套件點)。這也是作為排程週期中最後一個狀態,要麼成功到postBind,要麼失敗觸發UnReserve。 -
permit:該外掛可以阻止或延遲 Pod 的繫結,一般情況下這步驟會做三件事:appove:排程器繼續繫結過程Deny:如果任何一個Premit拒絕了Pod與節點的繫結,那麼將觸發UnReserve,並重入佇列Wait: 如果 Permit 外掛返回Wait,該 Pod 將保留在內部WaitPod 列表中,直到被Appove。如果發生超時,wait變為deny,將Pod放回至排程佇列中,並觸發Unreserve回滾 。
-
preBind:該外掛用於在 bind Pod 之前執行所需的前置工作。如,preBind可能會提供一個網路卷並將其掛載到目標節點上。如果在該步驟中的任意外掛返回錯誤,則Pod 將被deny並放置到排程佇列中。 -
bind:在所有的preBind完成後,該外掛將用於將Pod繫結到Node,並按順序呼叫繫結該步驟的外掛。如果有一個外掛處理了這個事件,那麼則忽略其餘所有外掛。 -
postBind:該外掛在繫結 Pod 後呼叫,可用於清理相關資源(通知性的擴充套件點)。 -
multiPoint:這是一個僅設定欄位,允許同時為所有適用的擴充套件點啟用或禁用外掛。
而 scheduler 對於排程上下文在程式碼中的實現就是 scheduleOne ,下面就是看這個排程上下文
Sort
Sort 外掛提供了排序功能,用於對在排程佇列中待處理 Pod 進行排序。一次只能啟用一個佇列排序。
在進入 scheduleOne 後,NextPod 從 activeQ 中佇列中得到一個Pod,然後的 frameworkForPod 會做打分的動作就是排程上下文的第一個擴充套件點 sort
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
fwk, err := sched.frameworkForPod(pod)
...
func (sched *Scheduler) frameworkForPod(pod *v1.Pod) (framework.Framework, error) {
// 獲取指定的profile
fwk, ok := sched.Profiles[pod.Spec.SchedulerName]
if !ok {
return nil, fmt.Errorf("profile not found for scheduler name %q", pod.Spec.SchedulerName)
}
return fwk, nil
}
回顧,因為在New scheduler時會初始化這個 sort 函數
podQueue := internalqueue.NewSchedulingQueue(
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
internalqueue.WithClusterEventMap(clusterEventMap),
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
)
preFilter
preFilter作為第一個擴充套件點,是用於在過濾之前預處理或檢查 Pod 或叢集的相關資訊。這裡會終止排程
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.ErrorS(err, "Error occurred")
return
}
if sched.skipPodSchedule(fwk, pod) {
return
}
klog.V(3).InfoS("Attempting to schedule pod", "pod", klog.KObj(pod))
// Synchronously attempt to find a fit for the pod.
start := time.Now()
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
// Initialize an empty podsToActivate struct, which will be filled up by plugins or stay empty.
podsToActivate := framework.NewPodsToActivate()
state.Write(framework.PodsToActivateKey, podsToActivate)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 這裡將進入prefilter
scheduleResult, err := sched.SchedulePod(schedulingCycleCtx, fwk, state, pod)
schedulePod 嘗試將給定的 pod 排程到節點列表中的節點之一。如果成功,它將返回節點的名稱。
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
// 用於將cache更新為當前內容
if err := sched.Cache.UpdateSnapshot(sched.nodeInfoSnapshot); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if sched.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
// 找到一個合適的pod時,會執行擴充套件點
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
...
findNodesThatFitPod 會執行對應的過濾外掛來找到最適合的Node,包括備註,以及方法名都可以看到,這裡執行的外掛