kubernetes 靜態儲存與動態儲存
靜態儲存
Kubernetes 同樣將作業系統和 Docker 的 Volume 概念延續了下來,並且對其進一步細化。Kubernetes 將 Volume 分為持久化的 PersistentVolume 和非持久化的普通 Volume 兩類。為了不與前面定義的 Volume 這個概念產生混淆,後面特指 Kubernetes 中非持久化的 Volume 時,都會帶著「普通」字首。
普通 Volume 的設計目標不是為了持久地儲存資料,而是為同一個 Pod 中多個容器提供可共用的儲存資源,因此 Volume 具有十分明確的生命週期——與掛載它的 Pod 相同的生命週期,這意味著儘管普通 Volume 不具備持久化的儲存能力,但至少比 Pod 中執行的任何容器的存活期都更長,Pod 中不同的容器能共用相同的普通 Volume,當容器重新啟動時,普通 Volume 中的資料也會能夠得到保留。當然,一旦整個 Pod 被銷燬,普通 Volume 也將不復存在,資料在邏輯上也會被銷燬掉,至於實質上會否會真正刪除資料,就取決於儲存驅動具體是如何實現 Unmount、Detach、Delete 介面的。
從作業系統裡傳承下來的 Volume 概念,在 Docker 和 Kubernetes 中繼續按照一致的邏輯延伸拓展,只不過 Kubernetes 為將其與普通 Volume 區別開來,專門取了 PersistentVolume 這個名字,你可以從下圖直觀地看出普通 Volume、PersistentVolume 和 Pod 之間的關係差異。
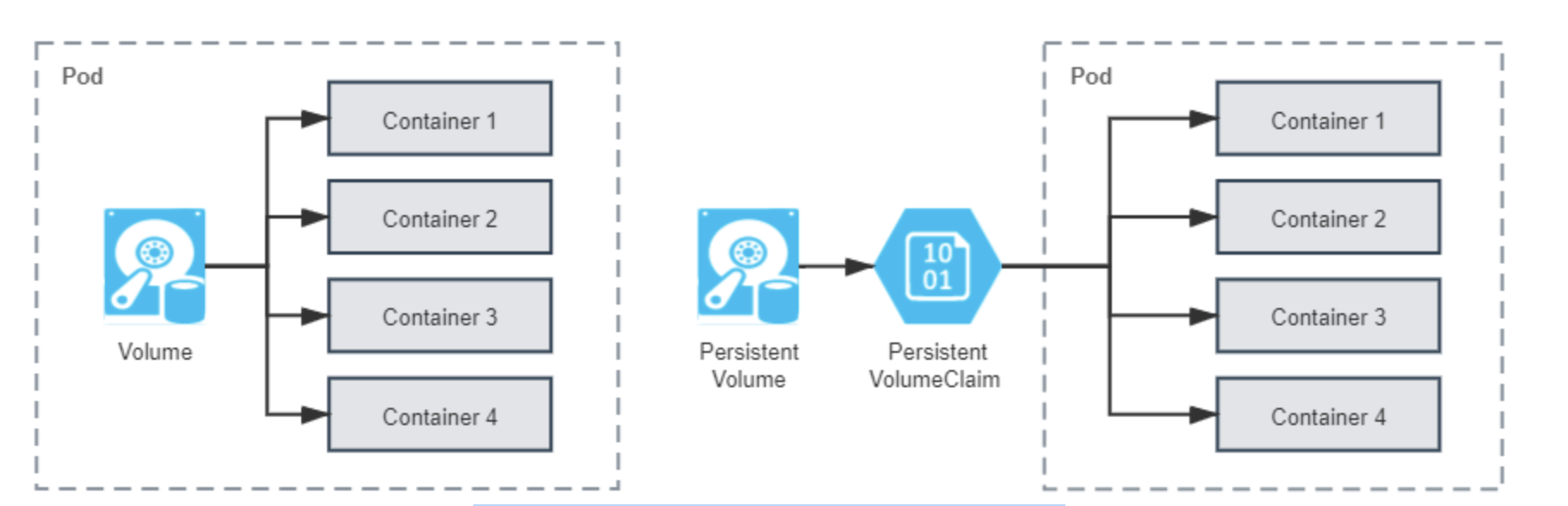
從「Persistent」這個單詞就能顧名思義,PersistentVolume 是指能夠將資料進行持久化儲存的一種資源物件,它可以獨立於 Pod 存在,生命週期與 Pod 無關,因此也決定了 PersistentVolume 不應該依附於任何一個宿主機節點,否則必然會對 Pod 排程產生干擾限制。
將 PersistentVolume 與 Pod 分離後,便需要專門考慮 PersistentVolume 該如何被 Pod 所參照的問題。原本在 Pod 中參照其他資源是常有的事,要麼直接通過資源名稱直接參照,要麼通過標籤選擇器(Selectors)間接參照。但是這種方法在這裡卻不太妥當。那應該是系統管理員(運維人員)說的算,還是由使用者(開發人員)說的算?最合理的答案是他們一起說的才算,因為只有開發能準確評估 Pod 執行需要消耗多大的儲存空間,只有運維能清楚知道當前系統可以使用的儲存裝置狀況,為了讓他們得以各自提供自己擅長的資訊,Kubernetes 又額外設計出了 PersistentVolumeClaim 資源。Kubernetes 官方給出的概念定義也特別強調了 PersistentVolume 是由管理員(運維人員)負責維護的,使用者(開發人員)通過 PersistentVolumeClaim 來匹配到合乎需求的 PersistentVolume。
PersistentVolume & PersistentVolumeClaim
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator.
A PersistentVolumeClaim (PVC) is a request for storage by a user.
PersistentVolume 是由管理員負責提供的叢集儲存。
PersistentVolumeClaim 是由使用者負責提供的儲存請求。
PersistentVolume 是 Volume 這個抽象概念的具象化表現,通俗地說就它是已經被管理員分配好的具體的儲存,這裡的「具體」是指有明確的儲存系統地址,有明確的容量、存取模式、儲存位置等資訊;而 PersistentVolumeClaim 則是 Pod 對其所需儲存能力的宣告,通俗地說就是滿足這個 Pod 正常執行要滿足怎樣的條件,譬如要消耗多大的儲存空間、要支援怎樣的存取方式。因此兩者並不是誰參照誰的固定關係,而是根據實際情況動態匹配的,兩者配合工作的具體過程如下。
- 管理員準備好要使用的儲存系統,它應是某種網路檔案系統(NFS)或者雲儲存系統,一般來說應該具備跨主機共用的能力。
- 管理員根據儲存系統的實際情況,手工預先分配好若干個 PersistentVolume,並定義好每個 PersistentVolume 可以提供的具體能力。譬如以下例子所示:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nginx-html
spec:
capacity:
storage: 5Gi # 最大容量為5GB
accessModes:
- ReadWriteOnce # 存取模式為RWO
persistentVolumeReclaimPolicy: Retain # 回收策略是Retain
nfs: # 儲存驅動是NFS
path: /html
server: 172.16.10.10
以上 YAML 中定義的儲存能力具體為:
- 儲存的最大容量是 5GB。
- 儲存的存取模式是「只能被一個節點讀寫掛載」(ReadWriteOnce,RWO),另外兩種可選的存取模式是「可以被多個節點以唯讀方式掛載」(ReadOnlyMany,ROX)和「可以被多個節點讀寫掛載」(ReadWriteMany,RWX)。
- 儲存的回收策略是 Retain,即在 Pod 被銷燬時並不會刪除資料。另外兩種可選的回收策略分別是 Recycle ,即在 Pod 被銷燬時,由 Kubernetes 自動執行rm -rf /volume/*這樣的命令來自動刪除資料;以及 Delete,它讓 Kubernetes 自動呼叫 AWS EBS、GCE PersistentDisk、OpenStack Cinder 這些雲端儲存的刪除指令。
- 儲存驅動是 NFS,其他常見的儲存驅動還有 AWS EBS、GCE PD、iSCSI、RBD(Ceph Block Device)、GlusterFS、HostPath,等等。
- 使用者根據業務系統的實際情況,建立 PersistentVolumeClaim,宣告 Pod 執行所需的儲存能力。譬如以下例子所示:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-html-claim
spec:
accessModes:
- ReadWriteOnce # 支援RWO存取模式
resources:
requests:
storage: 5Gi # 最小容量5GB
# 以上 YAML 中宣告了要求容量不得小於 5GB,必須支援 RWO 的存取模式。
-
Kubernetes 建立 Pod 的過程中,會根據系統中 PersistentVolume 與 PersistentVolumeClaim 的供需關係對兩者進行撮合,如果系統中存在滿足 PersistentVolumeClaim 宣告中要求能力的 PersistentVolume 則撮合成功,將它們繫結。如果撮合不成功,Pod 就不會被繼續建立,直至系統中出現新的或讓出空閒的 PersistentVolume 資源。
-
以上幾步都順利完成的話,意味著 Pod 的儲存需求得到滿足,繼續 Pod 的建立過程,整個過程如下圖:
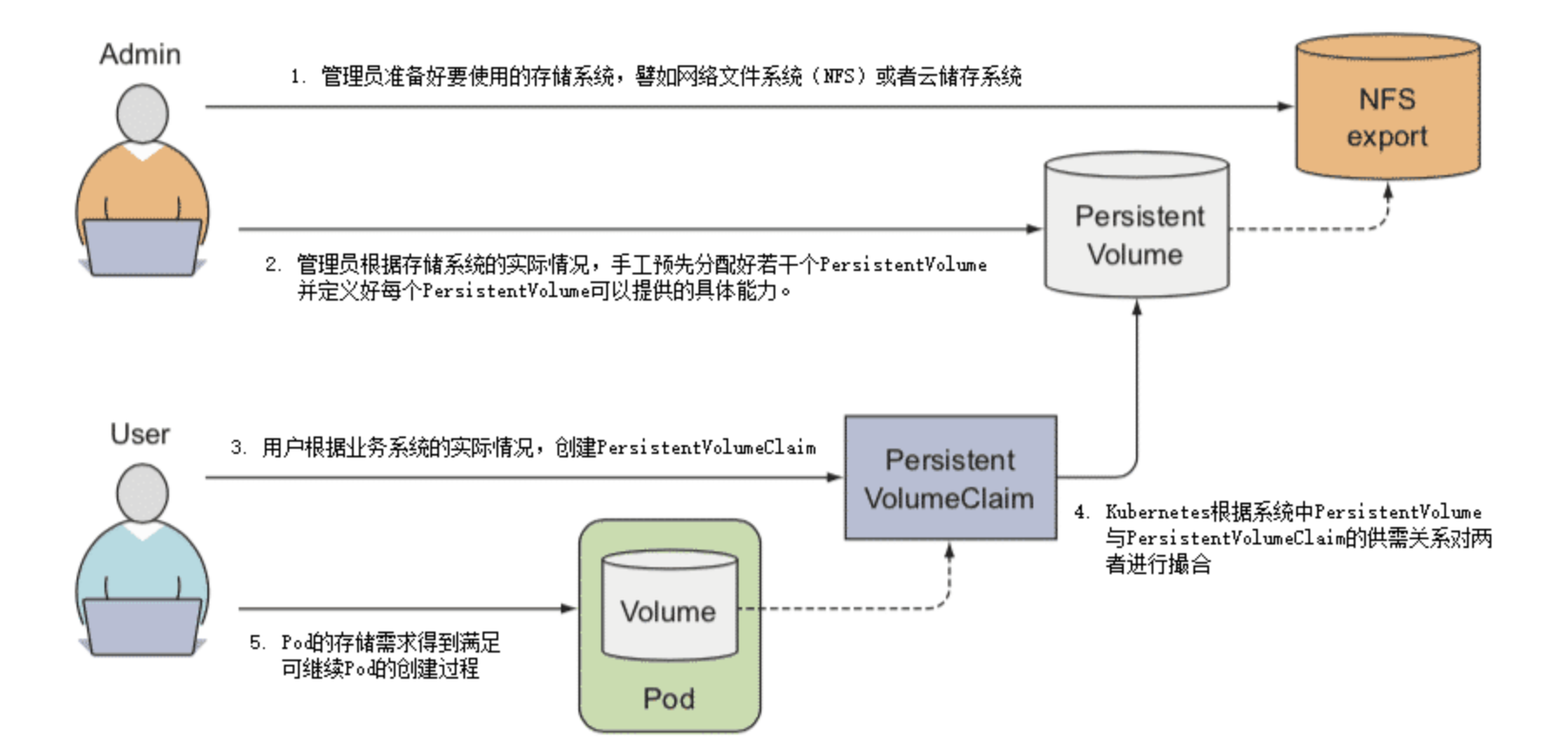
Kubernetes 對 PersistentVolumeClaim 與 PersistentVolume 撮合的結果是產生一對一的繫結關係,「一對一」的意思是 PersistentVolume 一旦繫結在某個 PersistentVolumeClaim 上,直到釋放以前都會被這個 PersistentVolumeClaim 所獨佔,不能再與其他 PersistentVolumeClaim 進行繫結。這意味著即使 PersistentVolumeClaim 申請的儲存空間比 PersistentVolume 能夠提供的要少,依然要求整個儲存空間都為該 PersistentVolumeClaim 所用,這有可能會造成資源的浪費。譬如,某個 PersistentVolumeClaim 要求 3GB 的儲存容量,當前 Kubernetes 手上只剩下一個 5GB 的 PersistentVolume 了,此時 Kubernetes 只好將這個 PersistentVolume 與申請資源的 PersistentVolumeClaim 進行繫結,平白浪費了 2GB 空間。假設後續有另一個 PersistentVolumeClaim 申請 2GB 的儲存空間,那它也只能等待管理員分配新的 PersistentVolume,或者有其他 PersistentVolume 被回收之後才被能成功分配。
動態儲存
對於中小規模的 Kubernetes 叢集,PersistentVolume 已經能夠滿足有狀態應用的儲存需求,PersistentVolume 依靠人工介入來分配空間的設計算是簡單直觀,卻算不上是先進,一旦應用規模增大,PersistentVolume 很難被自動化的問題就會突顯出來。這是由於 Pod 建立過程中去掛載某個 Volume,要求該 Volume 必須是真實存在的,否則 Pod 啟動可能依賴的資料(如一些設定、資料、外部資源等)都將無從讀取。Kubernetes 有能力隨著流量壓力和硬體資源狀況,自動擴縮 Pod 的數量,但是當 Kubernetes 自動擴充套件出一個新的 Pod 後,並沒有辦法讓 Pod 去自動掛載一個還未被分配資源的 PersistentVolume。想解決這個問題,要麼允許多個不同的 Pod 都共用相同的 PersistentVolumeClaim,這種方案確實只靠PersistentVolume 就能解決,卻損失了隔離性,難以通用;要麼就要求每個 Pod 用到的 PersistentVolume 都是已經被預先建立並分配好的,這種方案靠管理員提前手工分配好大量的儲存也可以實現,卻損失了自動化能力。
無論哪種情況,都難以符合 Kubernetes 工業級編排系統的產品定位,對於大型叢集,面對成百上千,乃至成千上萬的 Pod,靠管理員手工分配儲存肯定是捉襟見肘疲於應付的。在 2017 年 Kubernetes 釋出 1.6 版本後,終於提供了今天被稱為動態儲存分配(Dynamic Provisioning)的解決方案,讓系統管理員擺脫了人工分配的 PersistentVolume 的窘境,與之相對,人們把此前的分配方式稱為靜態儲存分配(Static Provisioning)。
所謂的動態儲存分配方案,是指在使用者宣告儲存能力的需求時,不是通過 Kubernetes 管理員人工預置或者是建立的 PersistentVolume,而是由特定的資源分配器(Provisioner)自動地在儲存資源池或者雲端儲存系統中分配符合使用者儲存需要的 PersistentVolume,然後掛載到 Pod 中使用,完成這項工作的資源被命名為 StorageClass,它的具體工作過程如下:
- 管理員根據儲存系統的實際情況,先準備好對應的 Provisioner。Kubernetes 官方已經提供了一系列預置的 In-Tree Provisioner,放置在kubernetes.io的 API 組之下。其中部分 Provisioner 已經有了官方的 CSI 驅動,比如 vSphere 的 Kubernetes 自帶驅動為kubernetes.io/vsphere-volume,VMware 的官方驅動為csi.vsphere.vmware.com。
- 管理員不再是手工去分配 PersistentVolume,而是根據儲存去設定 StorageClass。Pod 是可以動態擴縮的,而儲存則是相對固定的,哪怕使用的是具有擴充套件能力的雲端儲存,也會將它們視為儲存容量、IOPS 等引數可變的固定儲存來看待,譬如你可以將來自不同雲端儲存提供商、不同效能、支援不同存取模式的儲存設定為各種型別的 StorageClass,這也是它名字中「Class」(型別)的由來,譬如以下例子所示:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs #AWS EBS的Provisioner
parameters:
type: gp2
reclaimPolicy: Retain
- 使用者依然通過 PersistentVolumeClaim 來宣告所需的儲存,但是應在宣告中明確指出該由哪個 StorageClass 來代替 Kubernetes 處理該 PersistentVolumeClaim 的請求,譬如以下例子所示:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: standard-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: standard #明確指出該由哪個StorageClass來處理該PersistentVolumeClaim的請求
resource:
requests:
storage: 5Gi
- 如果 PersistentVolumeClaim 中要求的 StorageClass 及它用到的 Provisioner 均是可用的話,那這個 StorageClass 就會接管掉原本由 Kubernetes 撮合 PersistentVolume 與 PersistentVolumeClaim 的操作,按照 PersistentVolumeClaim 中宣告的儲存需求,自動產生出滿足該需求的 PersistentVolume 描述資訊,並行送給 Provisioner 處理。
- Provisioner 接收到 StorageClass 發來的建立 PersistentVolume 請求後,會操作其背後儲存系統去分配空間,如果分配成功,就生成並返回符合要求的 PersistentVolume 給 Pod 使用。
- 以上幾步都順利完成的話,意味著 Pod 的儲存需求得到滿足,繼續 Pod 的建立過程,整個過程如下圖所示。

使用 Dynamic Provisioning 來分配儲存無疑是更合理的設計,不僅省去了管理員的人工操作的中間層,也不再需要將 PersistentVolume 這樣的概念暴露給終端使用者,因為 Dynamic Provisioning 裡的 PersistentVolume 只是處理過程的中間產物,使用者不再需要接觸和理解它,只需要知道由 PersistentVolumeClaim 去描述儲存需求,由 StorageClass 去滿足儲存需求即可。只描述意圖而不關心中間具體的處理過程是宣告式程式設計的精髓,也是流程自動化的必要基礎。
由 Dynamic Provisioning 來分配儲存還能獲得更高的可管理性,譬如前面提到的回收策略,當希望 PersistentVolume 跟隨 Pod 一同被銷燬時,以前經常會設定回收策略為 Recycle 來回收空間,即讓系統自動執行rm -rf /volume/*命令,這種方式往往過於粗暴,遇到更精細的管理需求,譬如「刪除到回收站」或者「敏感資訊粉碎式徹底刪除」這樣的功能實現起來就很麻煩。而 Dynamic Provisioning 中由於有 Provisioner 的存在,如何建立、如何回收都是由 Provisioner 的程式碼所管理的,這就帶來了更高的靈活性。現在 Kubernetes 官方已經明確建議廢棄掉 Recycle 策略,如有這類需求就應改由 Dynamic Provisioning 去實現了。
Static Provisioning 的主要使用場景已侷限於管理員能夠手工管理儲存的小型叢集,它符合很多小型系統,尤其是私有化部署系統的現狀,但並不符合當今運維自動化所提倡的思路。Static Provisioning 的存在,某種意義上也可以視為是對歷史的一種相容,在可見的將來,Kubernetes 肯定仍會把 Static Provisioning 作為使用者分配儲存的一種主要方案供使用者選用。