這樣優化Spring Boot,啟動速度快到飛起!
微服務用到一時爽,沒用好就呵呵啦,特別是對於服務拆分沒有把控好業務邊界、拆分粒度過大等問題,某些 Spring Boot 啟動速度太慢了,可能你也會有這種體驗,這裡將探索一下關於 Spring Boot 啟動速度優化的一些方方面面。
啟動時間分析
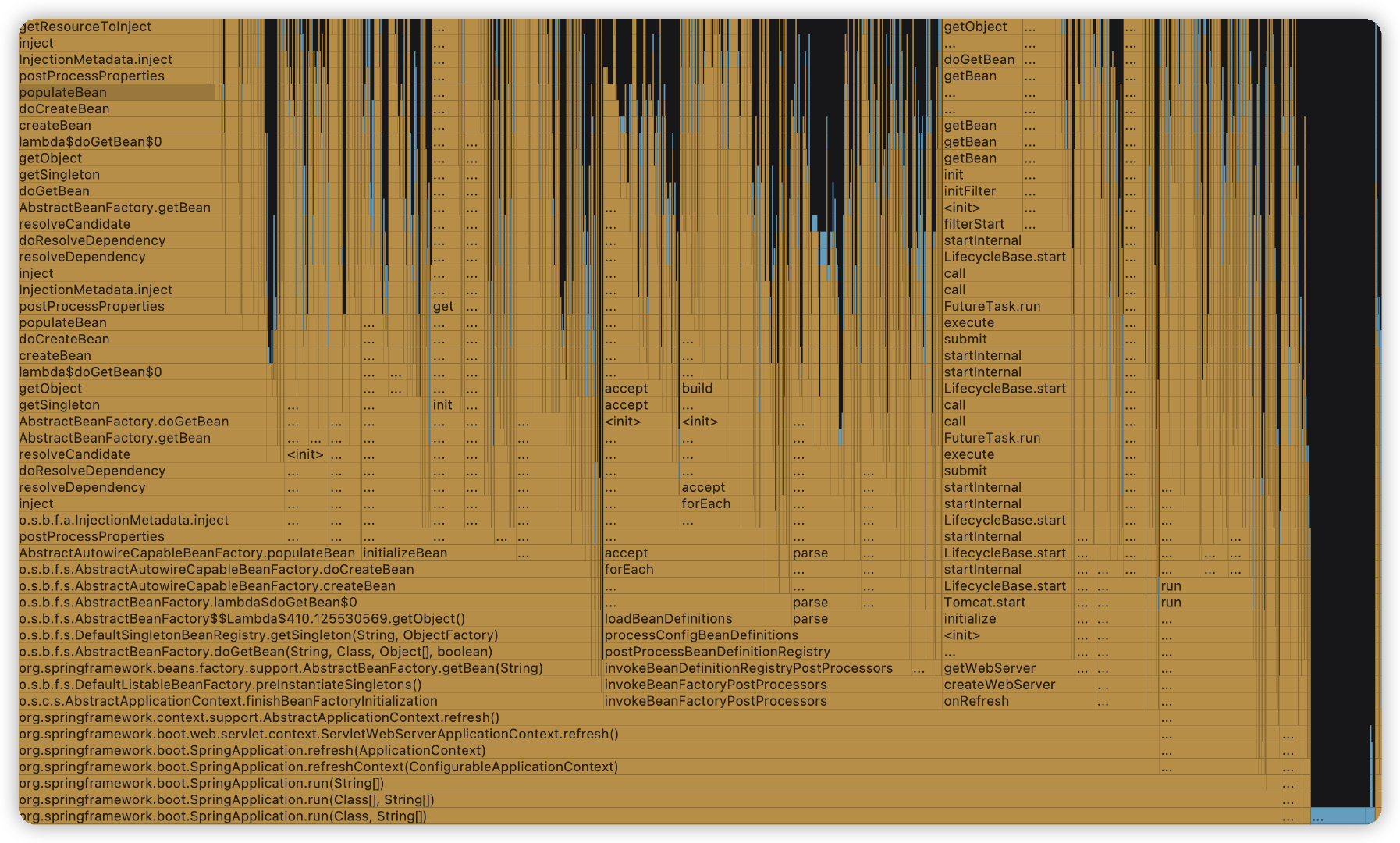
IDEA 自帶整合了 async-profile 工具,所以我們可以通過火焰圖來更直觀的看到一些啟動過程中的問題,比如下圖例子當中,通過火焰圖來看大量的耗時在 Bean 載入和初始化當中。
圖來自 IDEA 自帶整合的 async-profile 工具,可在 Preferences 中搜尋 Java Profiler 自定義設定,啟動使用 Run with xx Profiler。
y 軸表示呼叫棧,每一層都是一個函數,呼叫棧越深,火焰就越高,頂部就是正在執行的函數,下方都是它的父函數。
x 軸表示抽樣數,如果一個函數在 x 軸佔據的寬度越寬,就表示它被抽到的次數多,即執行的時間長。
啟動優化
減少業務初始化
大部分的耗時應該都在業務太大或者包含大量的初始化邏輯,比如建立資料庫連線、Redis連線、各種連線池等等,對於業務方的建議則是儘量減少不必要的依賴,能非同步則非同步。
延遲初始化
Spring Boot 2.2版本後引入 spring.main.lazy-initialization屬性,設定為 true 表示所有 Bean 都將延遲初始化。
可以一定程度上提高啟動速度,但是第一次存取可能較慢。
spring.main.lazy-initialization=true
Spring Context Indexer
Spring5 之後版本提供了spring-context-indexer功能,主要作用是解決在類掃描的時候避免類過多導致的掃描速度過慢的問題。
使用方法也很簡單,匯入依賴,然後在啟動類打上@Indexed註解,這樣在程式編譯打包之後會生成META-INT/spring.components檔案,當執行ComponentScan掃描類時,會讀取索引檔案,提高掃描速度。
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-indexer</artifactId>
<optional>true</optional>
</dependency>
關閉JMX
Spring Boot 2.2.X 版本以下預設會開啟 JMX,可以使用 jconsole 檢視,對於我們無需這些監控的話可以手動關閉它。
spring.jmx.enabled=false
關閉分層編譯
Java8 之後的版本,預設開啟多層編譯,使用命令java -XX:+PrintFlagsFinal -version | grep CompileThreshold檢視。
Tier3 就是 C1、Tier4 就是 C2,表示一個方法解釋編譯 2000 次進行 C1編譯,C1編譯後執行 15000 次會進行 C2編譯。

我們可以通過命令使用 C1 編譯器,這樣就不存在 C2 的優化階段,能夠提高啟動速度,同時配合 -Xverify:none/ -noverify 關閉位元組碼驗證,但是,儘量不要線上上環境使用。
-XX:TieredStopAtLevel=1 -noverify
另外的思路
上面介紹了一些從業務層面、啟動引數之類的優化,下面我們再看看基於 Java 應用本身有哪些途徑可以進行優化。
在此之前,我們回憶一下 Java 建立物件的過程,首先要進行類載入,然後去建立物件,物件建立之後就可以呼叫物件方法了,這樣就還會涉及到 JIT,JIT通過執行時將位元組碼編譯為本地機器碼來提高 Java 程式的效能。
因此,下面涉及到的技術將會概括以上涉及到的幾個步驟。
JAR Index
Jar包其實本質上就是一個 ZIP 檔案,當載入類的時候,我們通過類載入器去遍歷Jar包,找到對應的 class 檔案進行載入,然後驗證、準備、解析、初始化、範例化物件。
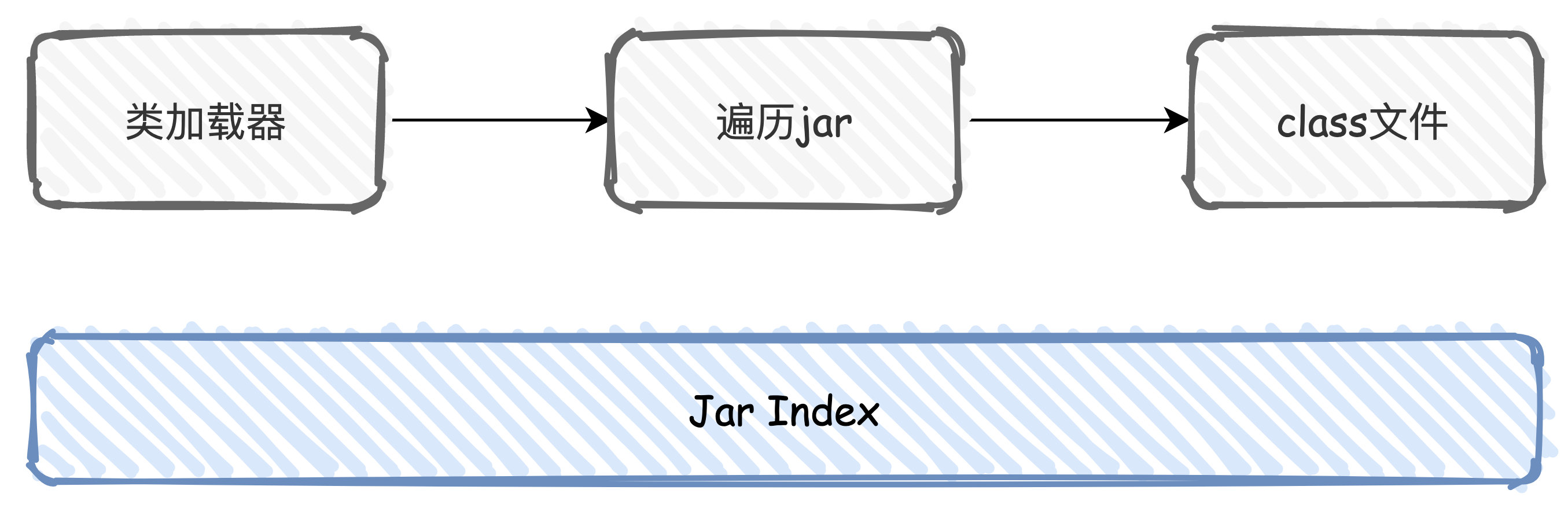
JarIndex 其實是一個很古老的技術,就是用來解決在載入類的時候遍歷 Jar 效能問題,早在 JDK1.3的版本中就已經引入。
假設我們要在A\B\C 3個Jar包中查詢一個class,如果能夠通過型別com.C,立刻推斷出具體在哪個jar包,就可以避免遍歷 jar 的過程。
A.jar
com/A
B.jar
com/B
C.jar
com/C
通過 Jar Index 技術,就可以生成對應的索引檔案 INDEX.LIST。
com/A --> A.jar
com/B --> B.jar
com/C --> C.jar
不過對於現在的專案來說,Jar Index 很難應用:
- 通過 jar -i 生成的索引檔案是基於 META-INF/MANIFEST.MF 中的 Class-Path 來的,我們目前大多專案都不會涉及到這個,所以索引檔案的生成需要我們自己去做額外處理
- 只支援 URLClassloader,需要我們自己自定義類載入邏輯
APPCDS
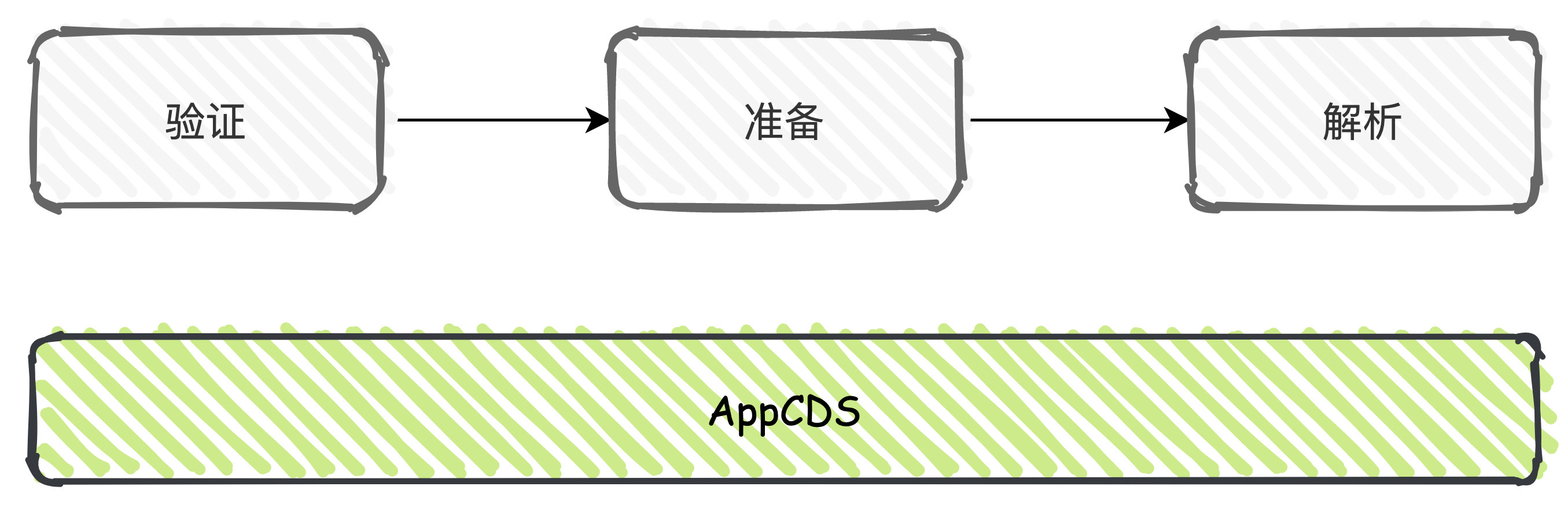
App CDS 全稱為 Application Class Data Sharing,主要是用於啟動加速和節省記憶體,其實早在在 JDK1.5 版本就已經引入,只是在後續的版本迭代過程中在不斷的優化升級,JDK13 版本中則是預設開啟,早期的 CDS 只支援BootClassLoader, 在 JDK8 中引入了 AppCDS,支援 AppClassLoader 和 自定義的 ClassLoader。
我們都知道類載入的過程中伴隨解析、校驗這個過程,CDS 就是將這個過程產生的資料結構儲存到歸檔檔案中,在下次執行的時候重複使用,這個歸檔檔案被稱作 Shared Archive,以jsa作為檔案字尾。
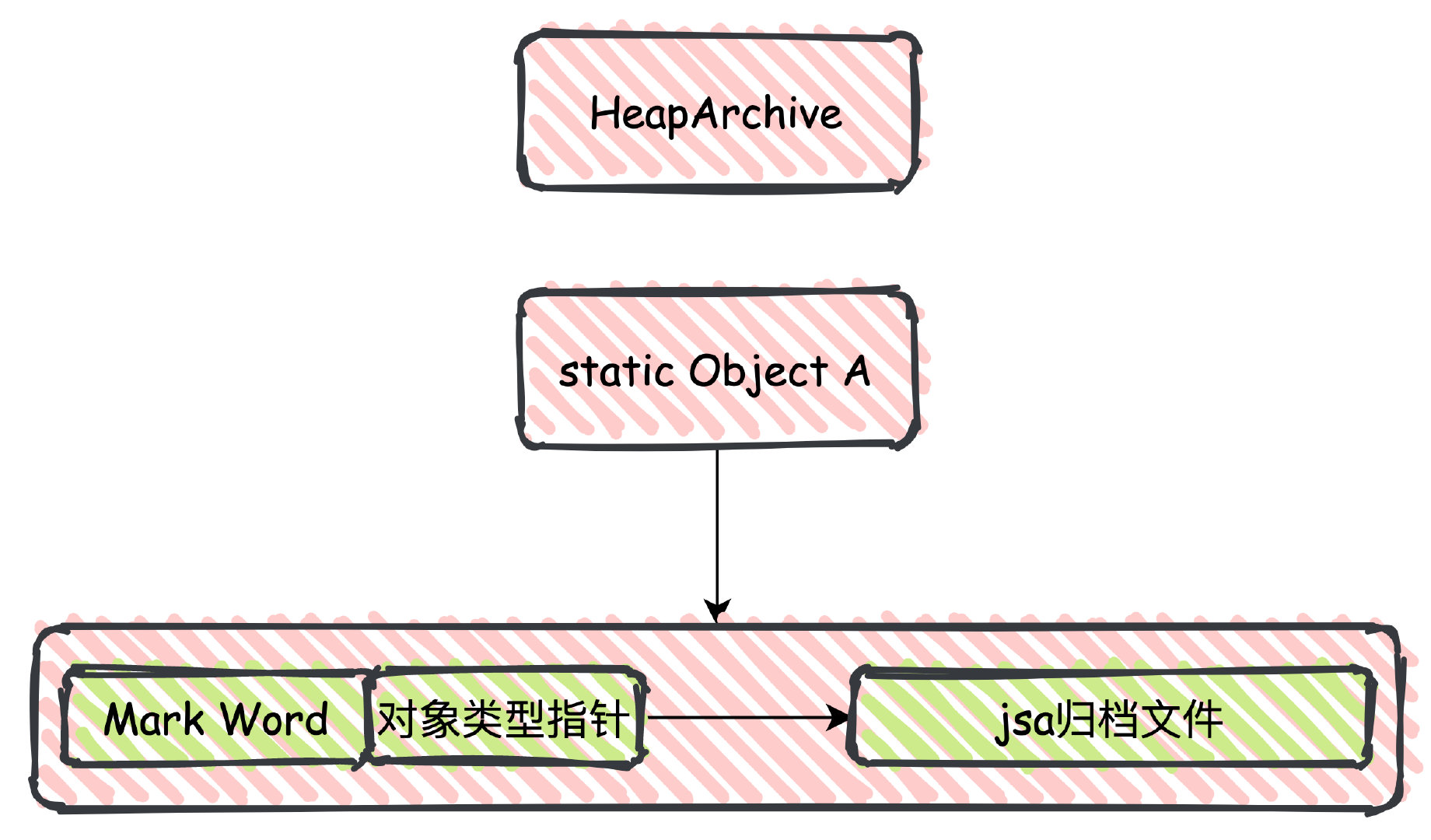
在使用時,則是將 jsa 檔案對映到記憶體當中,讓物件頭中的型別指標指向該記憶體地址。

讓我們一起看看怎麼使用。
首先,我們需要生成希望在應用程式之間共用的類列表,也即是 lst檔案。對於 Oracle JDK 需要加入 -XX:+UnlockCommercialFeature 命令來開啟商業化的能力,openJDK 無需此引數,JDK13的版本中將1、2兩步合併為一步,但是低版本還是需要這樣做。
java -XX:DumpLoadedClassList=test.lst
然後得到 lst 類列表之後,dump 到適合記憶體對映的 jsa 檔案當中進行歸檔。
java -Xshare:dump -XX:SharedClassListFile=test.lst -XX:SharedArchiveFile=test.jsa
最後,在啟動時加入執行引數指定歸檔檔案即可。
-Xshare:on -XX:SharedArchiveFile=test.jsa
需要注意的是,AppCDS只會在包含所有 class 檔案的 FatJar 生效,對於 SpringBoot 的巢狀 Jar 結構無法生效,需要利用 maven shade plugin 來建立 shade jar。
<build>
<finalName>helloworld</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<configuration>
<keepDependenciesWithProvidedScope>true</keepDependenciesWithProvidedScope>
<createDependencyReducedPom>false</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals><goal>shade</goal></goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
</transformer>
<transformer implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer">
<resource>META-INF/spring.factories</resource>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" />
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>${mainClass}</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
然後按照上述的步驟使用才可以,但是如果專案過大,檔案數大於65535啟動會報錯:
Caused by: java.lang.IllegalStateException: Zip64 archives are not supported
原始碼如下:
public int getNumberOfRecords() {
long numberOfRecords = Bytes.littleEndianValue(this.block, this.offset + 10, 2);
if (numberOfRecords == 0xFFFF) {
throw new IllegalStateException("Zip64 archives are not supported");
}
在 2.2 及以上版本修復了這個問題,所以使用的時候儘量使用高版本可以避免此類問題的出現。
Heap Archive
JDK9 中引入了HeapArchive,並且 JDK12 中被正式使用,我們可以認為 Heap Archive 是對 APPCDS 的一個延伸。
APPCDS 是持久化了類載入過程中驗證、解析產生的資料,Heap Archive 則是類初始化(執行 static 程式碼塊 cinit 進行初始化) 相關的堆記憶體的資料。

簡單來講,可以認為 HeapArchive 是在類初始化的時候通過記憶體對映持久化了一些 static 欄位,避免呼叫類初始化器,提前拿到初始化好的類,提高啟動速度。
AOT編譯
我們說過,JIT 是通過執行時將位元組碼編譯為本地機器碼,需要的時候直接執行,減少了解釋的時間,從而提高程式執行速度。
上面我們提到的 3 個提高應用啟動速度的方式都可以歸為類載入的過程,到真正建立物件範例、執行方法的時候,由於可能沒有被 JIT 編譯,在解釋模式下執行的速度非常慢,所以產生了 AOT 編譯的方式。
AOT(Ahead-Of-Time) 指的是程式執行之前發生的編譯行為,他的作用相當於是預熱,提前編譯為機器碼,減少解釋時間。
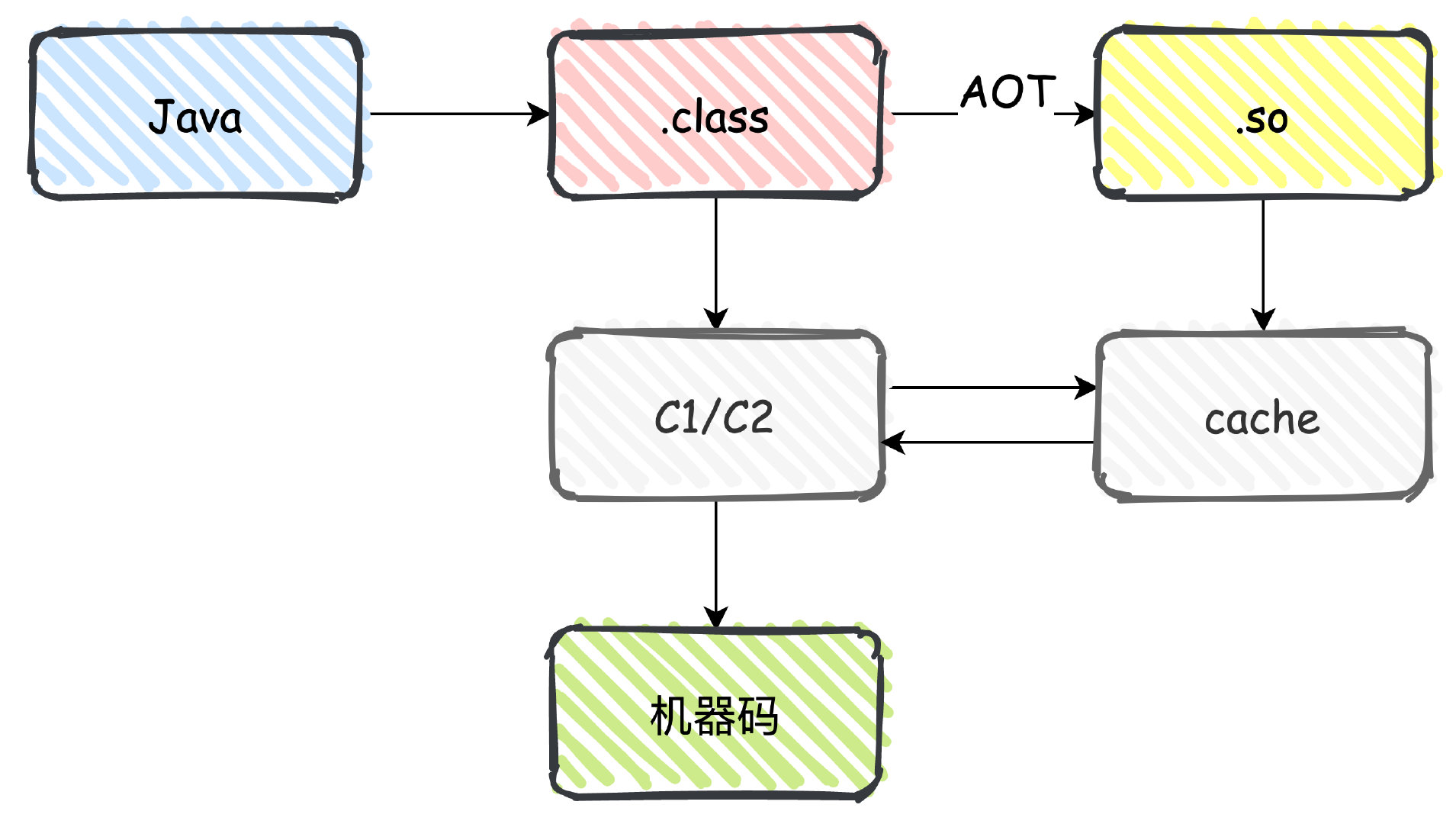
比如現在 Spring Cloud Native 就是這樣,在執行時直接靜態編譯成可執行檔案,不依賴 JVM,所以速度非常快。
但是 Java 中 AOT 技術不夠成熟,作為實驗性的技術在 JDK8 之後版本預設關閉,需要手動開啟。
java -XX:+UnlockExperimentalVMOptions -XX:AOTLibrary=
並且由於長期缺乏維護和調優這項技術,在 JDK 16 的版本中已經被移除,這裡就不再贅述了。
下線時間優化
優雅下線
Spring Boot 在 2.3 版本中增加了新特性優雅停機,支援Jetty、Reactor Netty、Tomcat 和 Undertow,使用方式:
server:
shutdown: graceful
# 最大等待時間
spring:
lifecycle:
timeout-per-shutdown-phase: 30s
如果低於 2.3 版本,官方也提供了低版本的實現方案,新版本中的實現基本也是這個邏輯,先暫停外部請求,關閉執行緒池處理剩餘的任務。
@SpringBootApplication
@RestController
public class Gh4657Application {
public static void main(String[] args) {
SpringApplication.run(Gh4657Application.class, args);
}
@RequestMapping("/pause")
public String pause() throws InterruptedException {
Thread.sleep(10000);
return "Pause complete";
}
@Bean
public GracefulShutdown gracefulShutdown() {
return new GracefulShutdown();
}
@Bean
public EmbeddedServletContainerCustomizer tomcatCustomizer() {
return new EmbeddedServletContainerCustomizer() {
@Override
public void customize(ConfigurableEmbeddedServletContainer container) {
if (container instanceof TomcatEmbeddedServletContainerFactory) {
((TomcatEmbeddedServletContainerFactory) container)
.addConnectorCustomizers(gracefulShutdown());
}
}
};
}
private static class GracefulShutdown implements TomcatConnectorCustomizer,
ApplicationListener<ContextClosedEvent> {
private static final Logger log = LoggerFactory.getLogger(GracefulShutdown.class);
private volatile Connector connector;
@Override
public void customize(Connector connector) {
this.connector = connector;
}
@Override
public void onApplicationEvent(ContextClosedEvent event) {
this.connector.pause();
Executor executor = this.connector.getProtocolHandler().getExecutor();
if (executor instanceof ThreadPoolExecutor) {
try {
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
threadPoolExecutor.shutdown();
if (!threadPoolExecutor.awaitTermination(30, TimeUnit.SECONDS)) {
log.warn("Tomcat thread pool did not shut down gracefully within "
+ "30 seconds. Proceeding with forceful shutdown");
}
}
catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
}
}
}
Eureka服務下線時間
另外,對於使用者端感知伺服器端下線時間方面的問題,我在之前的文章有提及到。
Eureka 使用了三級快取來儲存服務的範例資訊。
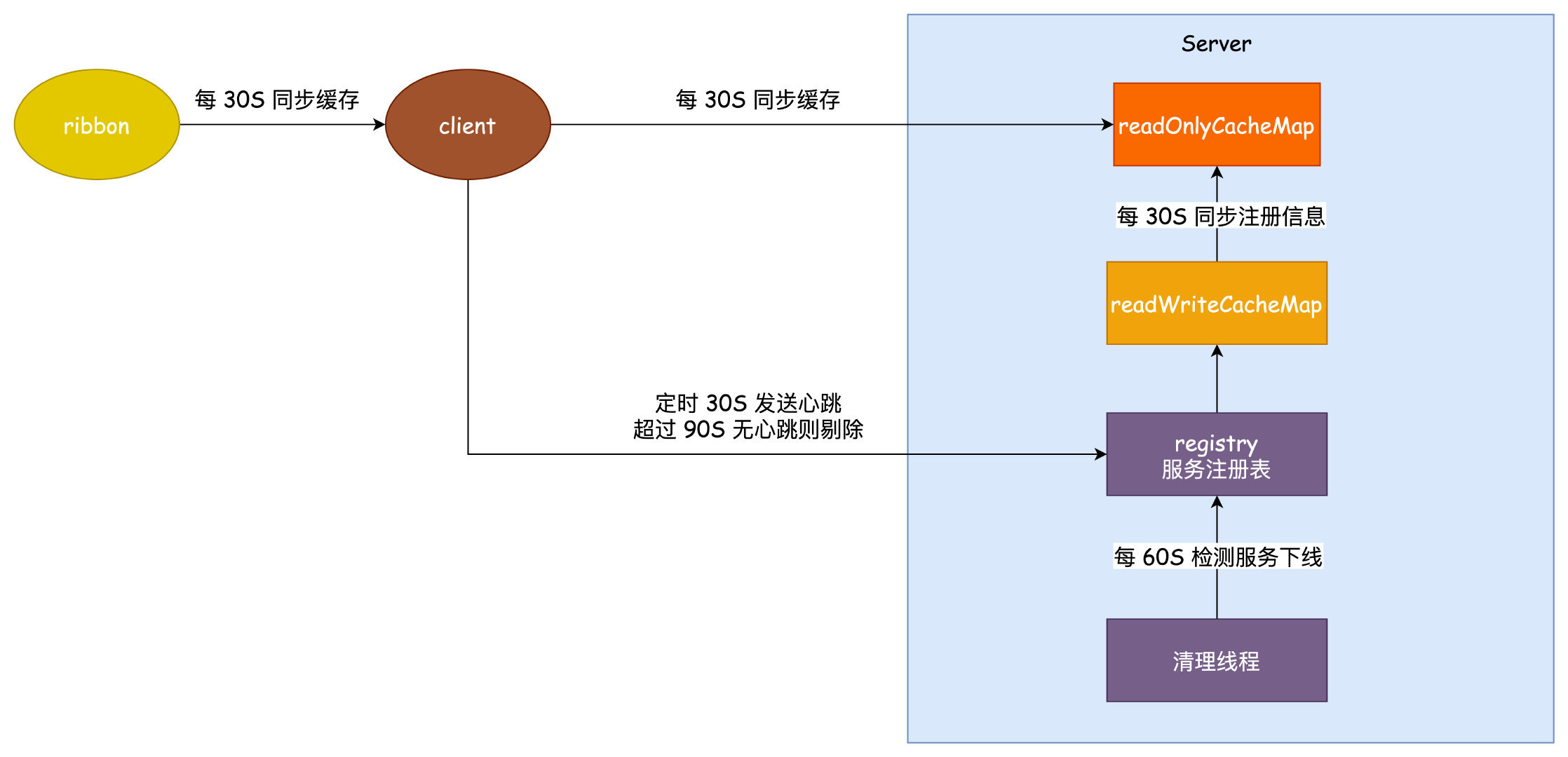
服務註冊的時候會和 server 保持一個心跳,這個心跳的時間是 30 秒,服務註冊之後,使用者端的範例資訊儲存到 Registry 服務登入檔當中,登入檔中的資訊會立刻同步到 readWriteCacheMap 之中。
而使用者端如果感知到這個服務,要從 readOnlyCacheMap 去讀取,這個唯讀快取需要 30 秒的時間去從 readWriteCacheMap 中同步。
使用者端和 Ribbon 負載均衡 都保持一個本地快取,都是 30 秒定時同步。
按照上面所說,我們來計算一下使用者端感知到一個服務下線極端的情況需要多久。
-
使用者端每隔 30 秒會傳送心跳到伺服器端
-
registry 儲存了所有服務註冊的範例資訊,他會和 readWriteCacheMap 保持一個實時的同步,而 readWriteCacheMap 和 readOnlyCacheMap 會每隔 30 秒同步一次。
-
使用者端每隔 30 秒去同步一次 readOnlyCacheMap 的註冊範例資訊
-
考慮到如果使用 ribbon 做負載均衡的話,他還有一層快取每隔 30 秒同步一次
如果說一個服務的正常下線,極端的情況這個時間應該就是 30+30+30+30 差不多 120 秒的時間了。
如果服務非正常下線,還需要靠每 60 秒執行一次的清理執行緒去剔除超過 90 秒沒有心跳的服務,那麼這裡的極端情況可能需要 3 次 60秒才能檢測出來,就是 180 秒的時間。
累計可能最長的感知時間就是:180 + 120 = 300 秒,5分鐘的時間。
解決方案當然就是改這些時間。
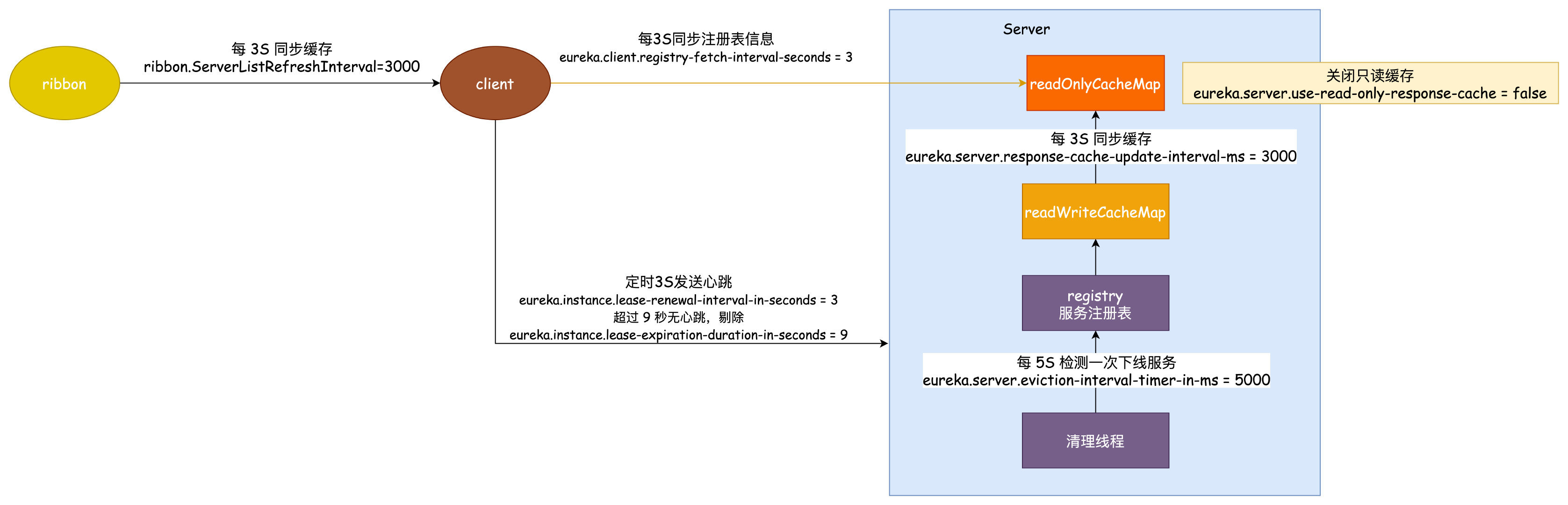
修改 ribbon 同步快取的時間為 3 秒:ribbon.ServerListRefreshInterval = 3000
修改使用者端同步快取時間為 3 秒 :eureka.client.registry-fetch-interval-seconds = 3
心跳間隔時間修改為 3 秒:eureka.instance.lease-renewal-interval-in-seconds = 3
超時剔除的時間改為 9 秒:eureka.instance.lease-expiration-duration-in-seconds = 9
清理執行緒定時時間改為 5 秒執行一次:eureka.server.eviction-interval-timer-in-ms = 5000
同步到唯讀快取的時間修改為 3 秒一次:eureka.server.response-cache-update-interval-ms = 3000
如果按照這個時間引數設定讓我們重新計算可能感知到服務下線的最大時間:
正常下線就是 3+3+3+3=12 秒,非正常下線再加 15 秒為 27 秒。
結束
OK,關於 Spring Boot 服務的啟動、下線時間的優化就聊到這裡,但是我認為服務拆分足夠好,程式碼寫的更好一點,這些問題可能都不是問題了。