影象文字跨模態細粒度語意對齊-置信度校正機制 AAAI2022
論文介紹:Show Your Faith: Cross-Modal Confidence-Aware Network for Image-Text Matching (跨模態置信度感知的影象文字匹配網路)AAAI 2022
主要優勢:
1)首次提出跨模態置信度衡量機制,通過區域性對齊語意與全域性對齊語意的關係,進一步計算區域性對齊語意是否被真正描述的可信程度。從而更加準確的實現細粒度的跨模態區域性語意對齊。
2)提出一種新穎的置信度推理方法,以全域性文字作為橋樑,計算區域性影象區域是否被全域性文字描述的置信度。
3)在主流資料集上取得SOTA效能。
一、前言
影象文字匹配任務定義:也稱為跨模態影象文字檢索,即通過某一種模態範例, 在另一模態中檢索語意相關的範例。例如,給定一張影象,查詢與之語意對應的文字,反之亦然。具體而言,對於任意輸入的文字-影象對(Image-Text Pair),圖文匹配的目的是衡量影象和文字之間的語意相似程度。
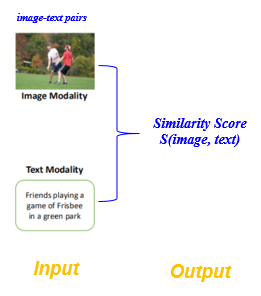
圖1 圖文匹配的輸入和輸出
核心挑戰:影象文字跨模態語意關聯致力於彌合視覺模態和語言模態之間的語意鴻溝,目的是實現異質模態(底層畫素組成的影象和高層語意向量表示的文字)間的準確語意對齊,即挖掘和建立影象和文字的跨模態語意一致性關聯對應關係。
現狀分析:現有的影象文字影象文字匹配工作可以大致分為兩類:1)全域性關聯:以整個文字和影象作為物件學習語意關聯;2)區域性關聯:以細粒度的影象顯著區域和文字單詞作為物件學習語意關聯。早期的工作屬於全域性關聯,即將整個影象和文字通過相應的深度學習網路對映至一個潛在的公共子空間,在該空間中影象和文字的跨模態語意關聯相似度可以被直接衡量,並且約束語意匹配的圖文對相似度大於其餘不匹配的圖文對。然而,這種全域性關聯正規化忽略了影象區域性顯著資訊以及文字區域性重要單詞的細粒度互動,阻礙了影象文字語意關聯精度的進一步提升。因此,基於細粒度影象區域和文字單詞的區域性關聯受到廣泛的關注和發展,並快速佔據主導優勢。對於現有的影象文字跨模態語意關聯正規化,核心思想是挖掘所有影象片段和文字片段之間的對齊關係。
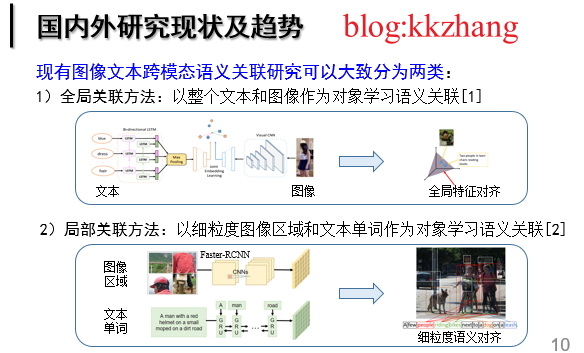
圖2 圖文匹配的發展現狀
交叉注意力網路SCAN通過區域和單詞之間的相互關注機制來捕捉所有潛在的區域性對齊,並激發出了一系列工作。跨模態交叉注意力旨在挖掘所有影象區域和文字單詞之間的對齊關係,通過區域性語意對齊來推理整體相關性。得益 於細粒度的模態資訊互動,基於交叉注意力的方法取得顯著的效能提升,併成為當前影象文字跨模態語意關聯的主流正規化。
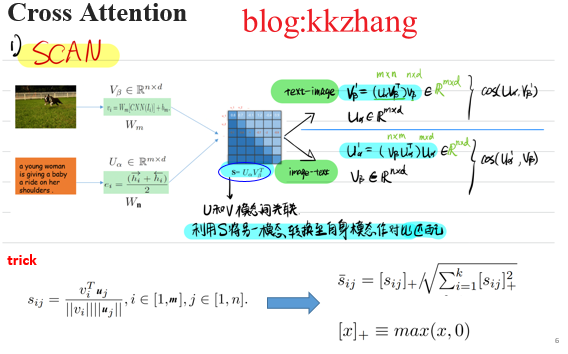
圖3 跨模態交叉注意力正規化SCAN
動機:現有的方法主要通過關聯區域性視覺-語意來匹配區域-單詞,再機械地聚合區域-單詞匹配對之間的區域性語意相似度來衡量影象-文字的整體相關性。然而在現有的方法中,區域性語意相似度,即區域-單詞匹配對的相關性,被以預設的匹設定信度1被聚合,這是不合理的。因為匹設定信度,即區域-單詞匹配對的可信程度,取決於全域性影象-文字語意,相互間存在差異。也就是說,某區域性區域-單詞對雖然是匹配的,但它與全域性的影象-文字語意並不一致,是不可信任的。因此,為了揭示區域性語意相似度對整體跨模態相關性的真實合理的貢獻水平,需要明確表示區域-單詞對在匹配中的置信度。在不考慮置信度的情況下,與整體語意不一致的區域-單詞匹配對將被不加區分地聚合,從而干擾整體相關性的度量。
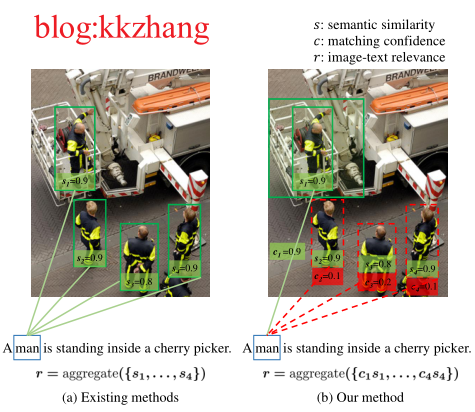
圖4 動機示意圖,通過進一步衡量每個區域性對齊語意的置信程度,實現更加準確的跨模態對齊
二、總體框架
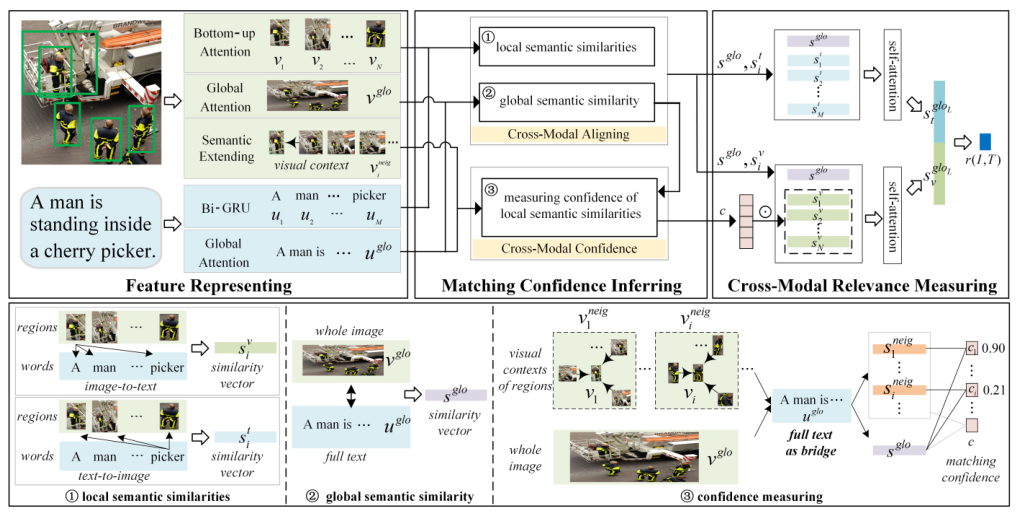
圖5 總體框架
整個方法分為三部分:1)影象與文字特徵表示;2)區域-單詞匹設定信度推理;3)區分匹設定信度的跨模態相關性度量。對於給定的影象和文字,首先進行影象與文字的特徵表示,以及各影象區域的視覺語意擴充套件,再以區域的視覺上下文和全文之間的語意相似度被包含在影象-文字的整體語意相似度中的程度,即該區域被文字所真正描述的相對程度,來推斷其匹設定信度,最後根據置信度在整體相關性聚合中過濾掉與全域性語意不一致的不可信區域性對齊資訊。
1:影象與文字特徵表示
文字採用雙向GRU編碼。影象採用在Visual Genomes資料集上訓練完備的以ResNet-101為骨幹網路的Faster R-CNN目標檢測器來抽取影象上36個顯著區域的特徵$\boldsymbol{x}_i$,然後將$\boldsymbol{x}_i$線性對映為共同嵌入空間中的視覺向量$\boldsymbol{v}_i$ 。影象的全域性表徵$\boldsymbol{v}^{glo}$通過以區域平均值$\boldsymbol{v}_{\text {ave}}=\frac{1}{N} \sum_{i=1}^{N} \boldsymbol{v}_{i}$為查詢鍵的注意力機制來編碼:
\begin{equation}
\boldsymbol{v}^{glo}=\frac{\sum_{i=1}^{N} w_{i} \boldsymbol{v}_{i}}{\left\|\sum_{i=1}^{N} w_{i} \boldsymbol{v}_{i}\right\|_{2}}
\label{eq:vis_glo}
\end{equation}
其中注意力權重$w_{i}$是$\boldsymbol{v}_{\text {ave}}$和區域特徵$\boldsymbol{v}_{i}$的相似度。
視覺語意擴充套件:為了使影象區域的語意更可區分,進一步提取各區域的視覺上下文進行語意擴充套件。考慮到一個區域的周邊場景通常包含與其相關的語意內容,設計以其周邊區域作為視覺上下文來擴充套件該區域。具體地,對於區域$\boldsymbol{v}_i$ ,將其周圍場景劃分為上、下、左、右四個視域,從每個視域中提取距其最近的3個區域並收集相關的索引號為集合${idx}_i$。將區域$\boldsymbol{v}_i$ 的語意擴充套件形式化表示為:
\begin{equation}
\boldsymbol{v}_{i}^{neig}=\frac{\sum_{i \in \text{idx}_i} w_{i} \boldsymbol{v}_{i}}{\left\|\sum_{i=1}^{N} w_{i} \boldsymbol{v}_{i}\right\|_{2}}
\label{eq:vis_context}
\end{equation}
其中$w_{i}$和全域性表徵$\boldsymbol{v}^{glo}$中區域$\boldsymbol{v}_i$相應的注意力權重相同。注意:這裡的聚合權重不需要學習,而是複用公式(1)中的權重$w_{i}$。
2:區域-單詞匹設定信度推理
匹設定信度由影象-文字的整體語意相似度中包含區域的視覺上下文與全文的語意相似度的多少來推斷。它表明了從整體影象的角度來看,文字對區域描述的相對程度。具體地,置信度是以整個文字為橋樑,由區域性區域-文字的語意相似度和整張影象-文字的語意相似度的內積來衡量的。
1)跨模態對齊
為了刻畫視覺和語言之間的詳細對齊關係,跨模態對齊視覺-語意,採用規範化距離向量來表示異質模態間的語意相似度。具體地,影象區域$\boldsymbol{s}^{v}_i$ 和其匹配到的語意相關文字$\boldsymbol{a}^t_i$ 的區域性語意相似度$\boldsymbol{s}^{v}_i$ 計算為:
\begin{equation}
\boldsymbol{s}^{v}_i=\frac{W_s^v|\boldsymbol{v}_i-\boldsymbol{a}^t_i|^{2}}{\left\|W_s^v|\boldsymbol{v}_i-\boldsymbol{a}^t_i|^{2}\right\|_{2}}
\end{equation}
其中$W_s^v \in \mathbb{R}^{P \times D}$ 是可學習引數矩陣。$\boldsymbol{s}^{v}_i$ 的文字模態上下文$\boldsymbol{a}^t_i$ 是 $\alpha_{i j} \boldsymbol{u}_{j}$的累加。其中
$\alpha_{i j}=\frac{e^{\left(\lambda \hat{c}_{i j}\right)}}{\sum_{i=1}^{K} e^{\left(\lambda \hat{c}_{i j}\right)}}$, $\hat{c}_{i j}=\left[c_{i j}\right]_{+} / \sqrt{\sum_{j=1}^{L}\left[c_{i j}\right]_{+}^{2}}$
,$c_{i j}$是影象區域 和單詞 的餘弦相似度。相似地,單詞$\boldsymbol{s}^{u}_j$ 和其視覺模態上下文$\boldsymbol{a}^v_j$ 之間的語意相似向量 被計算為
$\boldsymbol{s}^{u}_j=\frac{W_s^u|\boldsymbol{u}_j-\boldsymbol{a}^v_j|^{2}}{\left\|W_s^u|\boldsymbol{u}_j-\boldsymbol{a}^v_j|^{2}\right\|_{2}}$。
進一步度量整張影象$\boldsymbol{v}^{glo}$和全文字 $\boldsymbol{u}^{glo}$的全域性語意相似向量 :
\begin{equation}
\boldsymbol{s}^{glo}=\frac{W_s^g|\boldsymbol{v}^{glo}-\boldsymbol{u}^{glo}|^{2}}{\left\|W_s^g|\boldsymbol{v}^{glo}-\boldsymbol{u}^{glo}|^{2}\right\|_{2}}
\end{equation}
其中, $W_s^g \in \mathbb{R}^{P \times D}$是可學習引數矩陣。
2) 匹設定信度推理
當影象的顯著區域被分開檢視時,它們的視覺語意是片段化的,以至於區域性對齊的區域-單詞可能與全域性的影象-文字語意不一致。置信度是指各區域的視覺語意和影象-文字全域性視野的一致性程度,可以過濾掉和全域性語意不一致的區域-單詞匹配對。具體地,首先將區域$\boldsymbol{v}_{i}$ 擴充套件為它的視覺上下文 $\boldsymbol{v}_{i}^{neig}$,以使各區域 的語意更加可分。擴充套件的視覺上下文可以用來驗證各區域在全文中被描述的程度
\begin{equation}
\boldsymbol{s}^{neig}_i=\frac{W_s^n|\boldsymbol{v}^{neig}_i-\boldsymbol{u}^{glo}|^{2}}{\left\|W_s^n|\boldsymbol{v}^{neig}_i-\boldsymbol{u}^{glo}|^{2}\right\|_{2}}
\end{equation}
,其中 $W_s^n \in \mathbb{R}^{P \times D}$是可學習引數矩陣。
參考給定的文字,全域性文字語意中對整個影象的語意描述的程度可由 $s^{glo}$度量。以文字為橋樑,由全域性語意對齊$\boldsymbol{s}^{glo}$ 和$\boldsymbol{s}^{neig}_i$ 來度量相應區域的匹設定信度$\epsilon_i$ :
\begin{eqnarray}
\epsilon_i = \boldsymbol{w}_{n}\left( \boldsymbol{s}^{glo} \odot \boldsymbol{s}^{neig}_i \right),\;i=1,2,\cdots,N \\
\boldsymbol{c} = \sigma\left(\operatorname{LayerNorm}\left([\epsilon_1,\epsilon_2,\cdots,\epsilon_N] \right)\right)
\end{eqnarray}
其中 , $\boldsymbol{w}_{n}\in \mathbb{R}^{1 \times P} $是可學習引數向量,$\odot$ 指示元素對應相乘操作, $\sigma$表示sigmoid函數, $\operatorname{LayerNorm}$表示層規範化操作。匹設定信度是由區域的視覺上下文和全文之間的語意相似度被包含在影象-文字的整體語意相似度中的程度推斷出來的,它表明了該區域是否真的從全域性的影象-文字的角度被描述的相對程度。
3:區分匹設定信度的跨模態相關性度量
為在圖文匹配中區分割區域-單詞匹配對的置信度,過濾雖然區域性匹配但在文字整體語意中沒有真正提及區域相關的區域-單詞對所貢獻的區域性語意相似度,即不可靠的區域-單詞匹配對,首先將每個區域查詢到的語意相似度 $\boldsymbol{s}^{v}_i$與其相應的 $c_i$相乘,並將全域性語意相似度和被置信度縮放後的區域性相似度集合為:
\begin{equation}
S_v=[\boldsymbol{s}^{glo}, c_1 \boldsymbol{s}^{v}_1, \cdots, c_N \boldsymbol{s}^{v}_N]
\end{equation}
同時,$\boldsymbol{s}^{glo}$和由單詞查詢到的語意相似度$\boldsymbol{s}^{t}_1, \boldsymbol{s}^{t}_2, \cdots, \boldsymbol{s}^{t}_M$被集合為$S_t=[\boldsymbol{s}^{glo}, \boldsymbol{s}^{t}_1, \cdots, \boldsymbol{s}^{t}_M]$。
分別在集合起來的$S_v$和$S_t$上應用多層自注意力推理,以便特定模態增強的全域性對齊資訊:
\begin{equation}
S^{l+1}=\operatorname{ReLU}\left(W_r^l\cdot\operatorname{softmax}\left(W_{q}^l S^{l} \cdot\left(W_{k}^l S^{l}\right)^{\top}\right) \cdot S^{l}\right)
\label{eq:atten_qk}
\end{equation}
進一步地,拼接最後第L層的視覺增強的全域性語意相似度$\boldsymbol{s}_v^{glo_L}$ 和語言增強的全域性語意相似度$\boldsymbol{s}_t^{glo_L}$ ,並將拼接向量輸入到由sigmoid函數啟用的全連線層來計算影象 $I$ 和文字 $T$ 之間的跨模態相關性 :
\begin{equation}
r(I,T) =\sigma \left(\boldsymbol{w}_s\left([\boldsymbol{s}^{{glo}_L}_v:\boldsymbol{s}^{{glo}_L}_t]\right)\right)
\label{eq:sim}
\end{equation}
其中$\boldsymbol{w}_s \in \mathbb{R}^{1 \times {2P}}$是將拼接全域性對齊資訊對映為標量相關性的可學習引數。
三、試驗效果
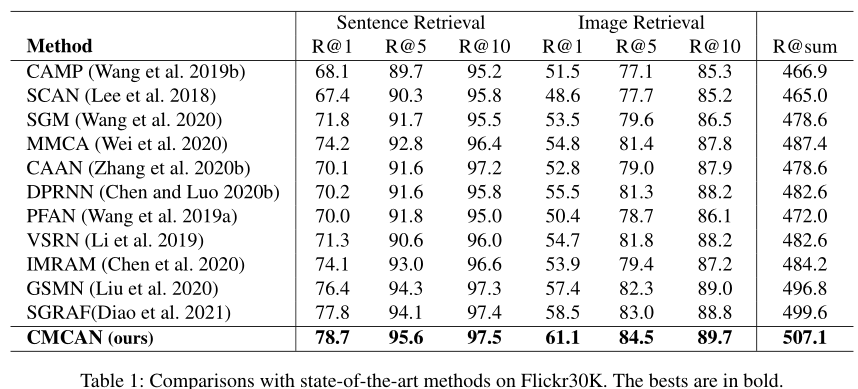
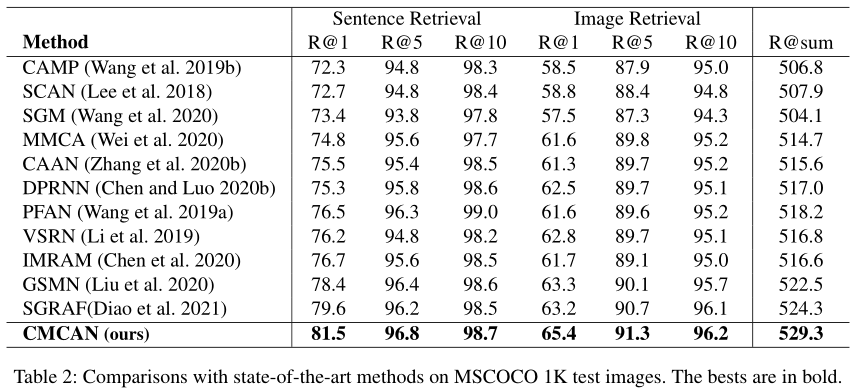
1、在主流資料集Flickr30K和MSCOCO上取得SOTA效能:
2、置信度視覺化

四、參考論文
Zhang H, Mao Z, Zhang K, et al. Show Your Faith: Cross-Modal Confidence-Aware Network for Image-Text Matching[C]// Proceedings of the AAAI conference on artificial intelligence. 2022.