【Kaggle】如何有效避免OOM(out of memory)和漫長的煉丹過程
本文介紹一些避免transformers的OOM以及訓練等流程太漫長的方法,主要參考了kaggle notebook Optimization approaches for Transformers | Kaggle,其中梯度累積Gradient Accumulation,凍結Freezing已經在之前的部落格中介紹過,本文會依次介紹混合精度訓練Automatic Mixed Precision, 8-bit Optimizers, and 梯度檢查點Gradient Checkpointing, 然後介紹一些NLP專用的方法,比如Dynamic Padding, Uniform Dynamic Padding, and Fast Tokenizers.
Automatic Mixed Precision
作用:不損失最終質量的情況下減少記憶體消耗和訓練時間
關鍵思想:是使用較低的精度將模型的梯度和引數保持在memory中,即不是使用全精度 (例如float32),而是使用半精度 (例如float16) 將張量保持在memory中。但是,當以較低的精度計算梯度時,某些值可能很小,以至於它們被視為零,這種現象稱為 「overflow」。為了防止 「overflow溢位」,原始論文的作者提出了一種梯度縮放方法。
PyTorch提供了一個具有必要功能 (從降低精度到梯度縮放) 的軟體包,用於使用自動混合精度,稱為torch.cuda.amp。自動混合精度可以輕鬆地將其插入訓練和推理程式碼中。
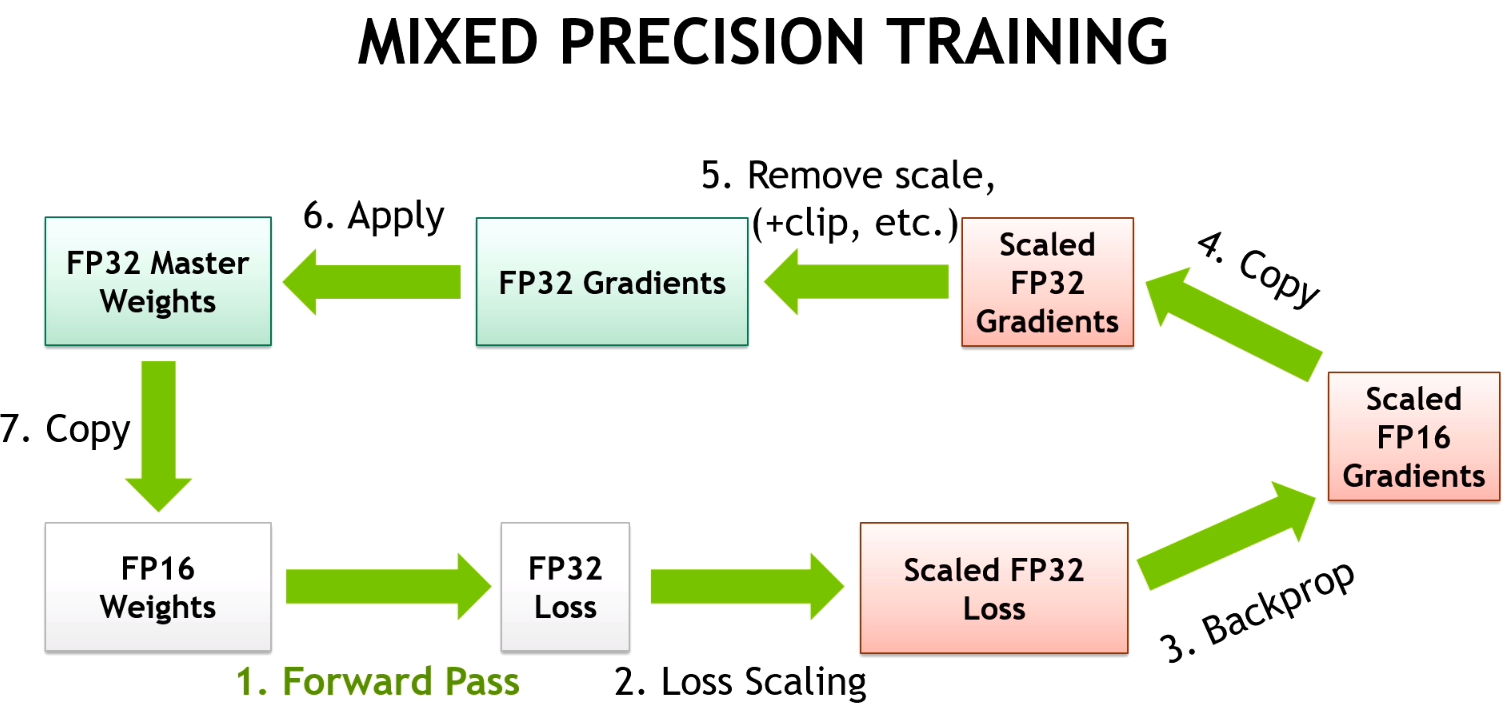
Vanilla training loop
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# backward pass
loss.backward()
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
optimizer.step()
model.zero_grad()
Training loop with Automatic Mixed Precision
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass with `autocast` context manager!!
with autocast(enabled=True):
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# scale gradint and perform backward pass!!
scaler.scale(loss).backward()
# before gradient clipping the optimizer parameters must be unscaled.!!
scaler.unscale_(optimizer)
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()
8-bit Optimizers
8位元優化器的思想類似於自動混合精度,其中模型的引數和梯度保持在較低的精度,但8位元優化器還將優化器的狀態保持在較低的精度。https://arxiv.org/abs/2110.02861作者表明8位元優化器顯著降低了記憶體利用率,略微加快了訓練速度。此外,作者研究了不同超引數設定的影響,並表明8位元優化器對不同的學習速率、beta和權重衰減引數的選擇是穩定的,不會損失效能或損害收斂性。因此,作者為8位元優化器提供了一個高階庫,稱為bitsandbytes。
Initializing optimizer via PyTorch API
import torch
from transformers import AutoConfig, AutoModel
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# selecting parameters, which requires gradients
model_parameters = filter(lambda parameter: parameter.requires_grad, model.parameters())
# initializing optimizer
optimizer = torch.optim.AdamW(params=model_parameters, lr=2e-5, weight_decay=0.0)
print(f"32-bit Optimizer:\n\n{optimizer}")
32-bit Optimizer:
AdamW (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 2e-05
maximize: False
weight_decay: 0.0
)
Initializing optimizer via bitsandbytes API
!pip install -q bitsandbytes-cuda110
def set_embedding_parameters_bits(embeddings_path, optim_bits=32):
"""
https://github.com/huggingface/transformers/issues/14819#issuecomment-1003427930
"""
embedding_types = ("word", "position", "token_type")
for embedding_type in embedding_types:
attr_name = f"{embedding_type}_embeddings"
if hasattr(embeddings_path, attr_name):
bnb.optim.GlobalOptimManager.get_instance().register_module_override(
getattr(embeddings_path, attr_name), 'weight', {'optim_bits': optim_bits}
)
import bitsandbytes as bnb
# selecting parameters, which requires gradients
model_parameters = filter(lambda parameter: parameter.requires_grad, model.parameters())
# initializing optimizer
bnb_optimizer = bnb.optim.AdamW(params=model_parameters, lr=2e-5, weight_decay=0.0, optim_bits=8)
# bnb_optimizer = bnb.optim.AdamW8bit(params=model_parameters, lr=2e-5, weight_decay=0.0) # equivalent to the above line
# setting embeddings parameters
set_embedding_parameters_bits(embeddings_path=model.embeddings)
print(f"8-bit Optimizer:\n\n{bnb_optimizer}")
8-bit Optimizer:
AdamW (
Parameter Group 0
betas: (0.9, 0.999)
eps: 1e-08
lr: 2e-05
weight_decay: 0.0
)
Gradient Checkpointing
有時,即使使用小批次和其他優化技術,例如梯度累積、凍結或自動精度訓練,我們仍然可能耗盡記憶體,尤其是在模型足夠大的情況下。作者證明了梯度檢查點可以顯著地將記憶體利用率從\(O(n)\)降低到\(O(\sqrt{n})\),其中n是模型中的層數。這種方法實現了在單個GPU上訓練大型模型,或提供更多記憶體以增加批次處理大小,從而更好更快地收斂。
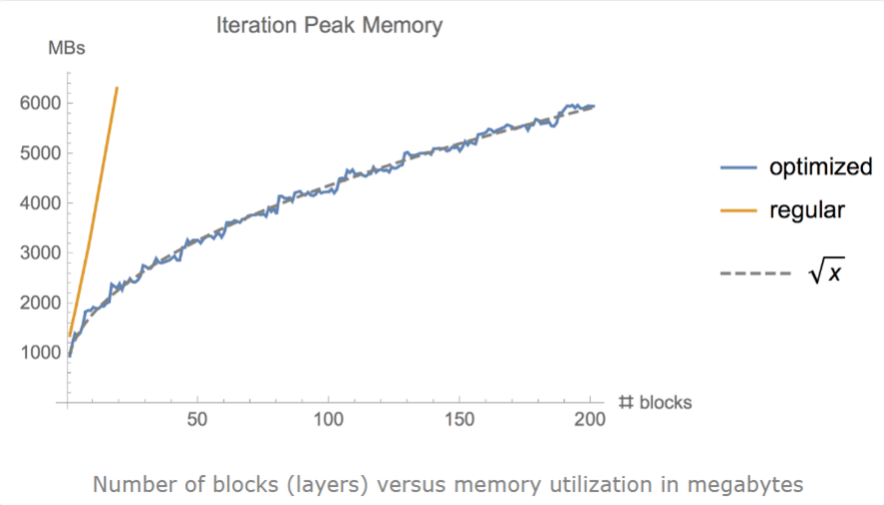
梯度檢查點背後的思想是計算小塊中的梯度,同時在正向和反向傳播過程中從記憶體中刪除不必要的梯度,從而降低記憶體利用率,儘管這種方法需要更多的計算步驟來再現整個反向傳播計算圖。
pytorch提供了torch.utils.checkpoint.checkpoint 和 torch.utils.checkpoint.checkpoint_sequential 函數來實現梯度檢查點。
"Specifically, in the forward pass, function will run in torch.no_grad() manner, i.e., not storing the intermediate activations. Instead, the forward pass saves the inputs tuple and the function parameter. In the backwards pass, the saved inputs and function is retrieved, and the forward pass is computed on function again, now tracking the intermediate activations, and then the gradients are calculated using these activation values."
另外,huggingface同樣支援梯度檢查點,可以對PreTrainedModel instance使用gradient_checkpointing_enable 方法。
程式碼實現
from transformers import AutoConfig, AutoModel
# https://github.com/huggingface/transformers/issues/9919
from torch.utils.checkpoint import checkpoint
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# gradient checkpointing
model.gradient_checkpointing_enable()
print(f"Gradient Checkpointing: {model.is_gradient_checkpointing}")
Gradient Checkpointing: True
Fast Tokenizers
base和fast tokenizer的區別:fast是在rust編寫的,因為python在迴圈中非常慢,fast可以讓我們在tokenize時獲得額外的加速。下圖是tokenize工作的原理示意,Tokenizer型別可以通過更改 transformers.AutoTokenizer from_pretrained 將 use_fast 屬性設為True。

程式碼實現
from transformers import AutoTokenizer
# initializing Base version of Tokenizer
model_path = "microsoft/deberta-v3-base"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
print(f"Base version Tokenizer:\n\n{tokenizer}", end="\n"*3)
# initializing Fast version of Tokenizer
fast_tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
print(f"Fast version Tokenizer:\n\n{fast_tokenizer}")
Base version Tokenizer:
PreTrainedTokenizer(name_or_path='microsoft/deberta-v3-base', vocab_size=128000, model_max_len=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'bos_token': '[CLS]', 'eos_token': '[SEP]', 'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
Fast version Tokenizer:
PreTrainedTokenizerFast(name_or_path='microsoft/deberta-v3-base', vocab_size=128000, model_max_len=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': '[CLS]', 'eos_token': '[SEP]', 'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
Dynamic Padding
即對輸入的mini batch動態進行padding,將batch的輸入填充到該batch的最大輸入長度,可以將訓練速度提高35%甚至50%,注意,pad token不應包括在某些任務(比如MLM和NER)的損失計算過程中。
Uniform Dynamic Padding
這是基於動態填充的方法,其思想是預先按文字的相應長度對文字進行排序,在訓練或推理期間比動態填充需要更少的計算。但不建議在訓練期間使用統一的動態填充,因為訓練意味著輸入的shuffle。