資料採集與預處理課設——人在迴路的氣溫資料動態處理與視覺化
資料採集與預處理課設——人在迴路的氣溫資料動態處理與視覺化
摘要
本次研究旨在通過python網路爬蟲技術,獲得中國各城市近90天的氣象資料,運用HTML、Xpath、jieba、counter等技術對資料進行處理,繪製動態視覺化圖、詞雲圖等,結合@chenjiandongx等人提供的pyecharts技術將其具現在地圖上的同時,採用LSTM時間序列分析技術實現基於歷史資料的天氣預測。我們希望通過實現全國城市氣象資料的視覺化,把握異常氣候影響範圍與程度。相較於傳統的圖片視覺化,本研究採用網頁動態展示,通過實現地圖中城市連結到對應網頁,網頁控制元件關聯資料表資料檢視、圖表型別以及視窗範圍,大大增加了互動性,方便了研究與使用。
引言
巨量資料時代的到來為氣象研究提供了大量的資料支撐,如何高效地獲取與使用現有的大量資料已成為重要的研究課題。但由於資料過於分散,沒有公開的大型氣象資訊視覺化平臺,日常研究受到資料數量以及工具的限制。
本研究試通過對全國資料整合分析,實現資料全覽的視覺化分析網頁平臺搭建,基於當前易獲取資料做出對於巨量資料的情況的合理規劃與嘗試,設計了滑動視窗與資料縮放,並提供了基於LSTM時間序列分析的氣象預測資料,為氣象學者研究氣候學做出切實可行的嘗試,有利於對水電等重要資源進行合理規劃與排程。
資料模型
如表1-1,在天氣網導航頁中記錄了各個城市歷史天氣資訊的網址索引連結。通過存取導航頁面,採用xpath存取./@href的值,獲得各個城市歷史資訊的網址。
表1-1 擬爬取網頁資訊表
|
全國所有城市資訊 |
https://www.tianqishi.com/lishi/ |
|
單個城市近90天天氣資料 |
https://www.tianqishi.com + city.xpath('./@href') |
如表1-2,存取頁面獲取各個城市的資料,得到圖1中的歷史天氣資訊表格,通過加註資料標籤設定省市名稱,備註網站URL,新增資料標籤轉存到csv檔案中,並以省市名稱命名檔案。 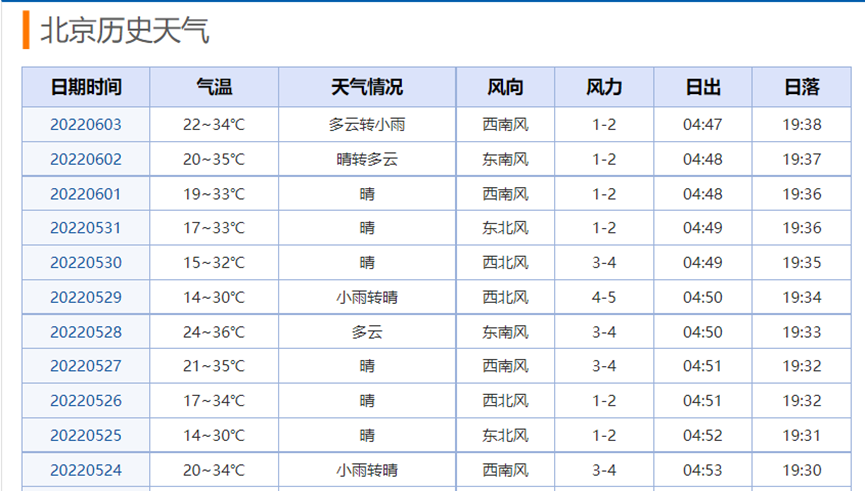
圖1 網頁中歷史天氣資料資訊
程式中用到的城市天氣資訊資料如表1-2。
表1-2 城市天氣資訊資料採集表
|
欄位名稱 |
資料型別 |
資料說明 |
|
provinceName |
Str |
省級名稱 |
|
city_name |
Str |
城市名稱 |
|
city_url |
Str |
城市對應網頁地址 |
|
data |
List[Str,Str,Str,Str,Str,Str] |
城市單日天氣資料 |
軟體架構
如圖2,首先採用python網路爬蟲技術獲取網頁資料資訊,通過文字預處理,採用正規表示式提取城市資訊、對日期資訊進行資料型別轉換、此外將其他資料進行收集與文字編碼後儲存至csv檔案中。通過存取csv檔案,將「天氣情況」資料使用逗號拼接為文字,而後呼叫jieba庫進行中文分詞、採用counter進行詞頻統計。
呼叫pyecharts實現中國城市地圖具象在網頁中,而後在每個城市對應控制元件後的value中儲存其url的值。對每個城市儲存在csv的資訊進行動態視覺化與詞雲圖繪製,實現line表和bar表的切換,同時設定對最高溫和最低溫的堆疊、平鋪功能切換,設定區域縮放以及視窗自調整功能。通過Page.SimplePageLayout佈局形式將其居中顯示在網頁中間,更好地適應使用者使用以及螢幕大小的改變。
最後在map圖中新增滑鼠響應,對value值進行呼叫,改變map中屬性的值實現每個城市控制元件的高亮顯示,以及通過window.open實現新視窗的開啟。
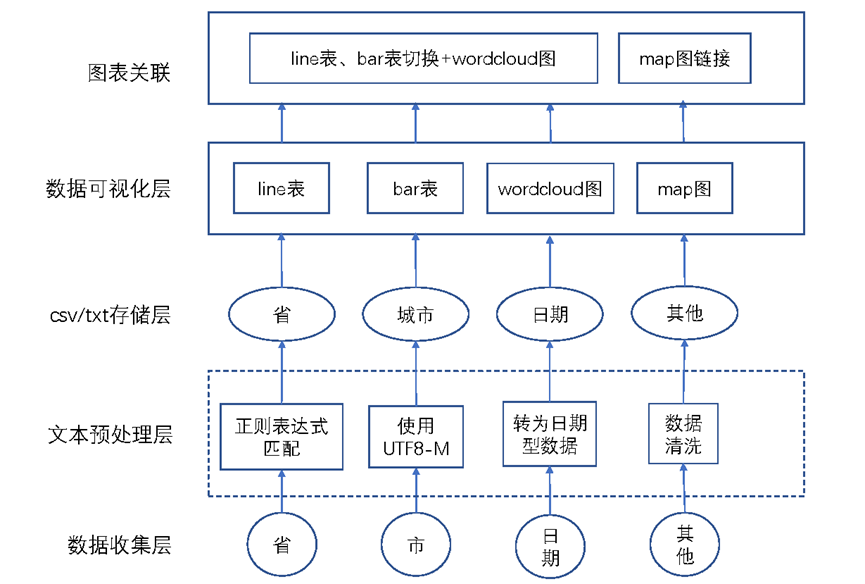
圖2 軟體架構圖
採集策略與預處理模型
資料採集流程圖
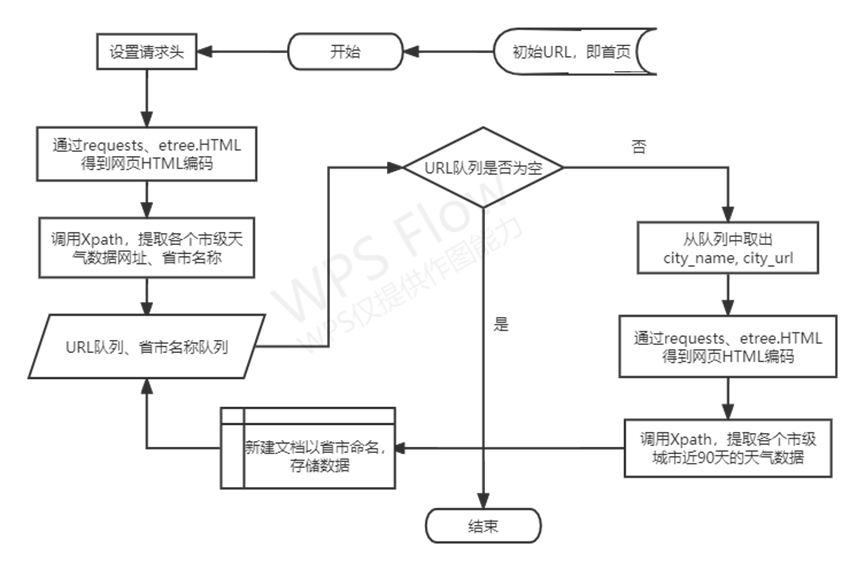
圖3 資料採集流程圖
關鍵資料採集與預處理策略
(1)通過xpath存取ul結點,儲存每個結點下的HTML內容,然後同樣採用xpath爬蟲技術,通過url_head + city.xpath('./@href') 的方式,獲得城市頁面的網址,然後記錄省市作為標籤,呼叫get_WeatherMessage方法獲取資料,此外呼叫time包,採用time.sleep的方式控制爬蟲速度,防止被網站伺服器發現並停止爬蟲程序。
url_head = 'https://www.tianqishi.com' for i in tree.xpath("//div[@class='box p']/ul"): provinceName = i.xpath('./li[1]//text()')[0] for city in i.xpath('./li/a'): city_url = url_head + city.xpath('./@href')[0] city_name = city.xpath('.//text()')[0] get_WeatherMessage(provinceName, city_name, city_url) time.sleep(30)
(2)由分析的URL來分別爬取近90天全國各省市的天氣資料,包括日期時間、氣溫、天氣情況、風向、風力、日出、日落等六項資料,獲取到的資料會以指定格式存放。由於採用. CSV 檔案能夠使資料交換更加容易,故採用 CSV的形式進行儲存[1]。使用open(fr'D:/dataSave/{provinceName}{city_name}.csv', 'a', encoding='utf-8')建立檔案並以省市命名csv檔案以及sheet,將已讀取的資料列表以續寫的開啟方式,採用編碼為utf-8寫入方便後續呼叫研究使用該資料。
for box in range(1, 90): data = city_tree.xpath(f"//tr[{box}]/td//text()") with open(fr'D:/dataSave/{provinceName}{city_name}.csv', 'a', encoding='utf-8', newline="") as writer: csv_write = csv.writer(writer, dialect='excel') csv_write.writerow(data) writer.close() print('已完成對', city_name, '的爬取', '\n')
(3)採用os.listdir存取資料夾,獲得資料夾中全部的檔名,記入dirs。然後通過字元拼接獲得所有檔案存取的路徑。此外,通過正規表示式"歷史天氣(.*?).csv"獲取檔案目錄中的城市名,便於後續在地圖中對應分析。此外,對於日期時間資訊進行格式轉化,將其通過pd.to_datetime()轉為日期型資料,再通過dt.date刪去多餘的精度,有利於後續對於單個城市的視覺化建圖。然後在通過遍歷表格得到關於天氣情況的txt文字,使用jieba和counter進行詞頻統計。
dirs = os.listdir('D:/dataSave') for filename in dirs: path = 'D:/dataSave/' + filename city = re.findall(r"歷史天氣(.*?).csv", path)[0] data = pd.read_csv(path, encoding='utf-8') data['日期時間'] = data['日期時間'].apply(lambda x: pd.to_datetime(x, format="%Y%m%d")) data['日期時間'] = data['日期時間'].dt.date text = "" for i in data['天氣情況']: text = text + ',' + i words = [x for x in jieba.lcut(text) if x != ','] words_count = Counter(words).most_common(40)
資料分析與視覺化
資料視覺化
為了使得課題研究資料結果更加清晰明顯,決定將對資料圖進行視覺化製作,由於本次課題主要是為了研究各地的天氣波動,於是嘗試將該資料在地圖上採用html的形式展示。
(1)採用來自麻省理工大學的@chenjiandongx等人制作的pyecharts.map中國地圖視覺化json檔案,並針對視覺化需要進行修改。在初始模板中,沒有提供視覺化實現方式,僅提供市級區分,以及對應的資料填寫位置,但其對於資料只提供了數位以及字串型別的解析支援,想要完成外連需要自己另外尋找解決方案。通過偵錯,在每個城市對應的按鍵中以字串形式儲存了URL地址,實現了僅支援實現單個區域選中並塗色處理。而後嘗試了通過在map中新增方法實現URL的觸發,但由於其不支援HTML文字解析,即使外部匯入HTML庫也無法完成該功能;而後嘗試通過在外部新增pyautogui庫實現滑鼠事件的獲取,但由於目標數量過多且處於動態變化,無法對應地新增控制元件時間監視器,故pyautogui庫也無法實現該功能。
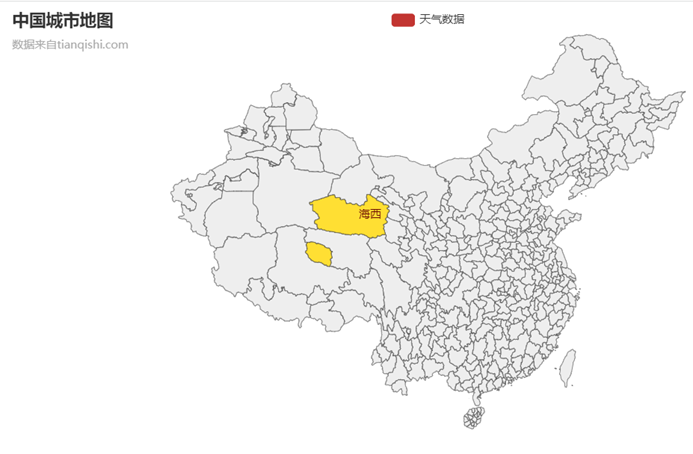
圖4 經過初步偵錯的中國城市地圖
(2)同樣採用@chenjiandongx等人提供的網頁line表繪製,通過查閱資料自己定義屬性值,更改資料顯示方式,頁面框架,動畫渲染,實現了動態切換折線圖與柱狀圖、儲存圖片為.png格式檢視與更改表格資料、下方設定拉伸條,調整時間條的同時解決了資料密度較大的情況下可能出現的問題,通過標註表示最高溫、最低溫,以及每日最高溫的平均值、最低溫的平均值,可以通過滑鼠移動檢視每個日期所帶資料,可以選擇隱藏最高氣溫/最低氣溫,僅觀察一項,此外設定區間縮放功能以及撤回功能。由此實現直觀、流暢、介面簡潔、展示效果好的可互動式視覺化,供研究使用。
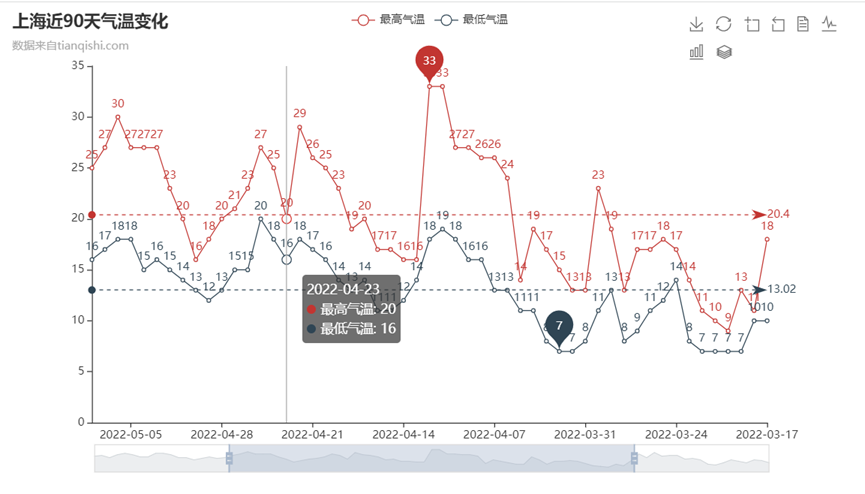
(3)通過調取資料表中「天氣情況」列資料進行文字分析,通過呼叫jieba庫實現中文分詞,而後採用counter庫進行詞頻統計,最後呼叫wordcloud生成詞雲圖,該圖表可以實現對近日天氣情況頻率的分析。此外利用網頁的優勢,新增了滑鼠事件動態響應標籤,更好地補全了網頁展示的資訊。

圖11 天氣情況詞雲圖
(4)通過直接檢視與修改網頁前端程式碼,學習相關JavaScript知識。先是嘗試了使用JQ選擇器,獲取網頁事件並通過標籤呼叫實現URL獲取,但由於網頁標籤不夠詳細,無法實現URL的精確定位,故無法解決(1)中的遺留問題;最後選擇在網頁中自行新增滑鼠事件獲取響應資訊,解析pramas獲得URL地址,而後通過window.open實現新網頁頁面的開啟。
chart_46c9f11bad4044d2aa5bde8fd9fda973.on("click", function (params) {
url ='file:///'+params.data.value;
window.open(url);
// window.location.href=url; //更新視窗
});
(5)採用LSTM時間序列分析,基於已有資料訓練得到新的資料。長短期記憶(Long short-term memory, LSTM)相比普通的RNN,LSTM能夠在更長的序列中有更好的表現,故而在面對日益增長的天氣資料時,LSTM能發揮更好的作用。以安徽安慶資料為例,將前十天的日最低氣溫作為訓練集,而後對新一天的最低溫進行預測,得到新的一天的真實資料後加入訓練集進行增強訓練,最終預測結果如圖10所示:可以看到預測結果趨勢與真實值一致,預測效果較為理想。
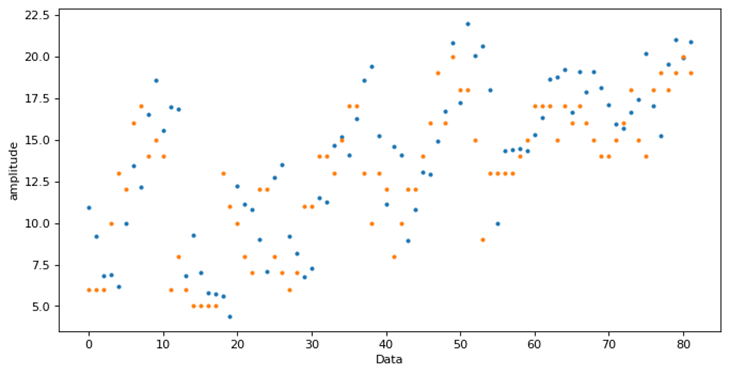
圖12 時間序列分析預測結果對比圖(橙:實際值,藍:預測值)
結論
本文通過使用python網路爬蟲獲取天氣網的天氣狀況,實現豐富多樣的資料視覺化,幫助使用者在運用相關的專業知識實現對以往資料的橫向和縱向、大尺度和小尺度的比較[1];再者,通過分析氣溫的變化規律,可以得到區域性對流空氣對我國天氣的影響情況;通過某地區天氣情況詞頻統計可以判斷城市的宜居程度以及提供旅遊時間參考。
視覺化中提供了滑動視窗、檢視縮放,在資料預測分析中採用了LSTM神經網路,能夠很好地適應資料量增大的情況。總體上,本研究對於構建全國城市巨量資料氣象資訊平臺做出了切實可行的嘗試,不論是對氣象學研究還是全國各城市的能源的合理排程分配工作都具有重要意義。
參考文獻
[1] 霍瑛,李海峰,王衝. 基於天氣指數的資料分析_霍瑛[J]. 哈爾濱商業大學學報(自然科學版), 2018, 34(4): 440-446.
[2] 於學鬥,柏曉鈺. 基於Python的城市天氣資料爬蟲程式分析_於學鬥[J]. 辦公自動化, 2022, 27(7): 10-13, 9.
相較最終版有省略
製作:BDT20040