DeiT:注意力也能蒸餾
DeiT:注意力也能蒸餾
《Training data-efficient image transformers & distillation through attention》
ViT 在巨量資料集 ImageNet-21k(14million)或者 JFT-300M(300million) 上進行訓練,Batch Size 128 下 NVIDIA A100 32G GPU 的計算資源加持下預訓練 ViT-Base/32 需要3天時間。
Facebook 與索邦大學 Matthieu Cord 教授合作發表 Training data-efficient image transformers(DeiT) & distillation through attention,DeiT 模型(8600萬引數)僅用一臺 GPU 伺服器在 53 hours train,20 hours finetune,僅使用 ImageNet 就達到了 84.2 top-1 準確性,而無需使用任何外部資料進行訓練。效能與最先進的折積神經網路(CNN)可以抗衡。所以呢,很有必要講講這個 DeiT 網路模型的相關內容。
下面來簡單總結 DeiT:
DeiT 是一個全 Transformer 的架構。其核心是提出了針對 ViT 的教師-學生蒸餾訓練策略,並提出了 token-based distillation 方法,使得 Transformer 在視覺領域訓練得又快又好。
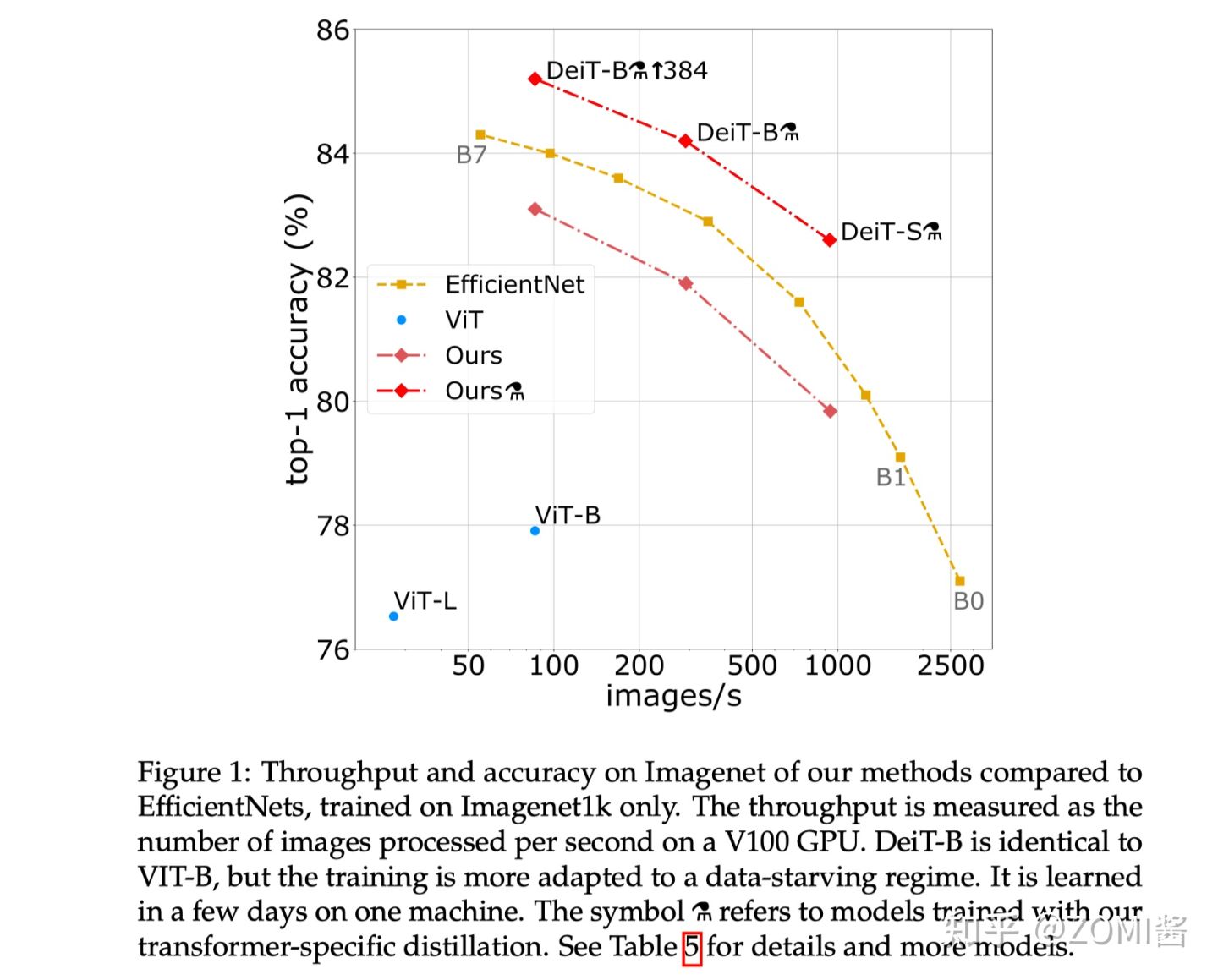
DeiT 相關背景
ViT 文中表示資料量不足會導致 ViT 效果變差。針對以上問題,DeiT 核心共用是使用了蒸餾策略,能夠僅使用 ImageNet-1K 資料集就就可以達到 83.1% 的 Top1。
那麼文章主要貢獻可以總結為三點:
- 僅使用 Transformer,不引入 Conv 的情況下也能達到 SOTA 效果。
- 提出了基於 token 蒸餾的策略,針對 Transformer 蒸餾方法超越傳統蒸餾方法。
- DeiT 發現使用 Convnet 作為教師網路能夠比使用 Transformer 架構效果更好。
正式瞭解 DeiT 演演算法之前呢,有幾個問題需要去了解的:ViT的缺點和侷限性,為什麼訓練ViT要準備這麼多資料,就不能簡單快速訓練一個模型出來嗎?另外 Transformer 視覺模型又怎麼玩蒸餾呢?
ViT 的缺點和侷限性
Transformer的輸入是一個序列(Sequence),ViT 所採用的思路是把影象分塊(patches),然後把每一塊視為一個向量(vector),所有的向量並在一起就成為了一個序列(Sequence),ViT 使用的資料集包括了一個巨大的包含了 300 million images的 JFT-300,這個資料集是私有的,即外部研究者無法復現實驗。而且在ViT的實驗中作者明確地提到:
"That transformers do not generalize well when trained on insufficient amounts of data."

意思是當不使用 JFT-300 巨量資料集時,效果不如CNN模型。也就反映出Transformer結構若想取得理想的效能和泛化能力就需要這樣大的資料集。DeiT 作者通過所提出的蒸餾的訓練方案,只在 Imagenet 上進行訓練,就產生了一個有競爭力的無折積 Transformer。
ViT 相關技術點
Multi-head Self Attention layers (MSA):
首先有一個 Query 矩陣 Q 和一個 Key 矩陣 K,把二者矩陣乘在一起並進行歸一化以後得到 attention 矩陣,它再與Value矩陣 V 相乘得到最終的輸出得到 Z。最後經過 linear transformation 得到 NxD 的輸出結果。
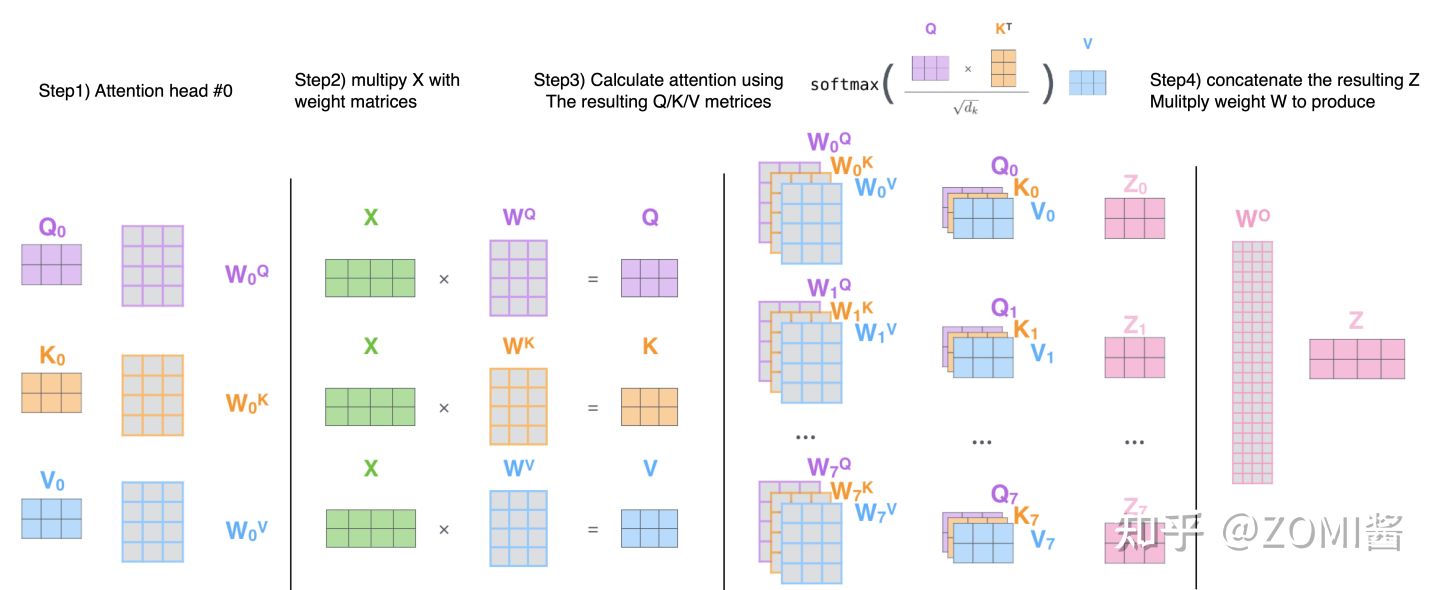
Feed-Forward Network (FFN):
Multi-head Self Attention layers 之後往往會跟上一個 Feed-Forward Network (FFN) ,它一般是由2個linear layer構成,第1個linear layer把維度從 D 維變換到 ND 維,第2個linear layer把維度從 ND 維再變換到 D 維。
此時 Transformer block 是不考慮位置資訊的,基於此 ViT 加入了位置編碼 (Positional Encoding),這些編碼在第一個 block 之前被新增到 input token 中代表位置資訊,作為額外可學習的embedding(Extra learnable class embedding)。
Class token:
Class token 與 input token 並在一起輸入 Transformer block 中,最後的輸出結果用來預測類別。這樣一來,Transformer 相當於一共處理了 N+1 個維度為 D 的token,並且只有第一個 token 的輸出用來預測類別。
知識蒸餾介紹
Knowledge Distillation(KD)最初被 Hinton 提出 「Distilling the Knowledge in a Neural Network」,與 Label smoothing 動機類似,但是 KD 生成 soft label 的方式是通過教師網路得到的。
KD 可以視為將教師網路學到的資訊壓縮到學生網路中。還有一些工作 「Circumventing outlier of autoaugment with knowledge distillation」 則將 KD 視為資料增強方法的一種。
提出背景
雖然在一般情況下,我們不會去區分訓練和部署使用的模型,但是訓練和部署之間存在著一定的不一致性。在訓練過程中,我們需要使用複雜的模型,大量的計算資源,以便從非常大、高度冗餘的資料集中提取出資訊。在實驗中,效果最好的模型往往規模很大,甚至由多個模型整合得到。而大模型不方便部署到服務中去,常見的瓶頸如下:
- 推理速度和效能慢
- 對部署資源要求高(記憶體,視訊記憶體等)
在部署時,對延遲以及計算資源都有著嚴格的限制。因此,模型壓縮(在保證效能的前提下減少模型的引數量)成為了一個重要的問題,而「模型蒸餾」屬於模型壓縮的一種方法。
理論原理
知識蒸餾使用的是 Teacher—Student 模型,其中 Teacher 是「知識」的輸出者,Student 是「知識」的接受者。知識蒸餾的過程分為2個階段:
- 原始模型訓練: 訓練 "Teacher模型", 簡稱為Net-T,它的特點是模型相對複雜,也可以由多個分別訓練的模型整合而成。我們對"Teacher模型"不作任何關於模型架構、引數量、是否整合方面的限制,唯一的要求就是,對於輸入X, 其都能輸出Y,其中Y經過softmax的對映,輸出值對應相應類別的概率值。
- 精簡模型訓練: 訓練"Student模型", 簡稱為Net-S,它是引數量較小、模型結構相對簡單的單模型。同樣的,對於輸入X,其都能輸出Y,Y經過softmax對映後同樣能輸出對應相應類別的概率值。
論文中,Hinton 將問題限定在分類問題下,或者其他本質上屬於分類問題的問題,該類問題的共同點是模型最後會有一個softmax層,其輸出值對應了相應類別的概率值。知識蒸餾時,由於已經有了一個泛化能力較強的Net-T,我們在利用Net-T來蒸餾訓練Net-S時,可以直接讓Net-S去學習Net-T的泛化能力。
其中KD的訓練過程和傳統的訓練過程的對比:
- 傳統training過程 Hard Targets: 對 ground truth 求極大似然 Softmax 值。
- KD的training過程 Soft Targets: 用 Teacher 模型的 class probabilities作為soft targets。

這就解釋了為什麼通過蒸餾的方法訓練出的 Net-S 相比使用完全相同的模型結構和訓練資料只使用Hard Targets的訓練方法得到的模型,擁有更好的泛化能力。
具體方法
第一步是訓練Net-T;第二步是在高溫 T 下,蒸餾 Net-T 的知識到 Net-S。

訓練 Net-T 的過程很簡單,而高溫蒸餾過程的目標函數由distill loss(對應soft target)和student loss(對應hard target)加權得到:
Deit 中使用 Conv-Based 架構作為教師網路,以 soft 的方式將歸納偏置傳遞給學生模型,將區域性性的假設通過蒸餾方式引入 Transformer 中,取得了不錯的效果。
DeiT 具體方法
為什麼DeiT能在大幅減少 1. 訓練所需的資料集 和 2. 訓練時長 的情況下依舊能夠取得很不錯的效能呢?我們可以把這個原因歸結為DeiT的訓練策略。ViT 在小資料集上的效能不如使用CNN網路 EfficientNet,但是跟ViT結構相同,僅僅是使用更好的訓練策略的DeiT比ViT的效能已經有了很大的提升,在此基礎上,再加上蒸餾 (distillation) 操作,效能超過了 EfficientNet。
假設有一個效能很好的分類器作為teacher model,通過引入了一個 Distillation Token,然後在 self-attention layers 中跟 class token,patch token 在 Transformer 結構中不斷學習。
Class token的目標是跟真實的label一致,而Distillation Token是要跟teacher model預測的label一致。
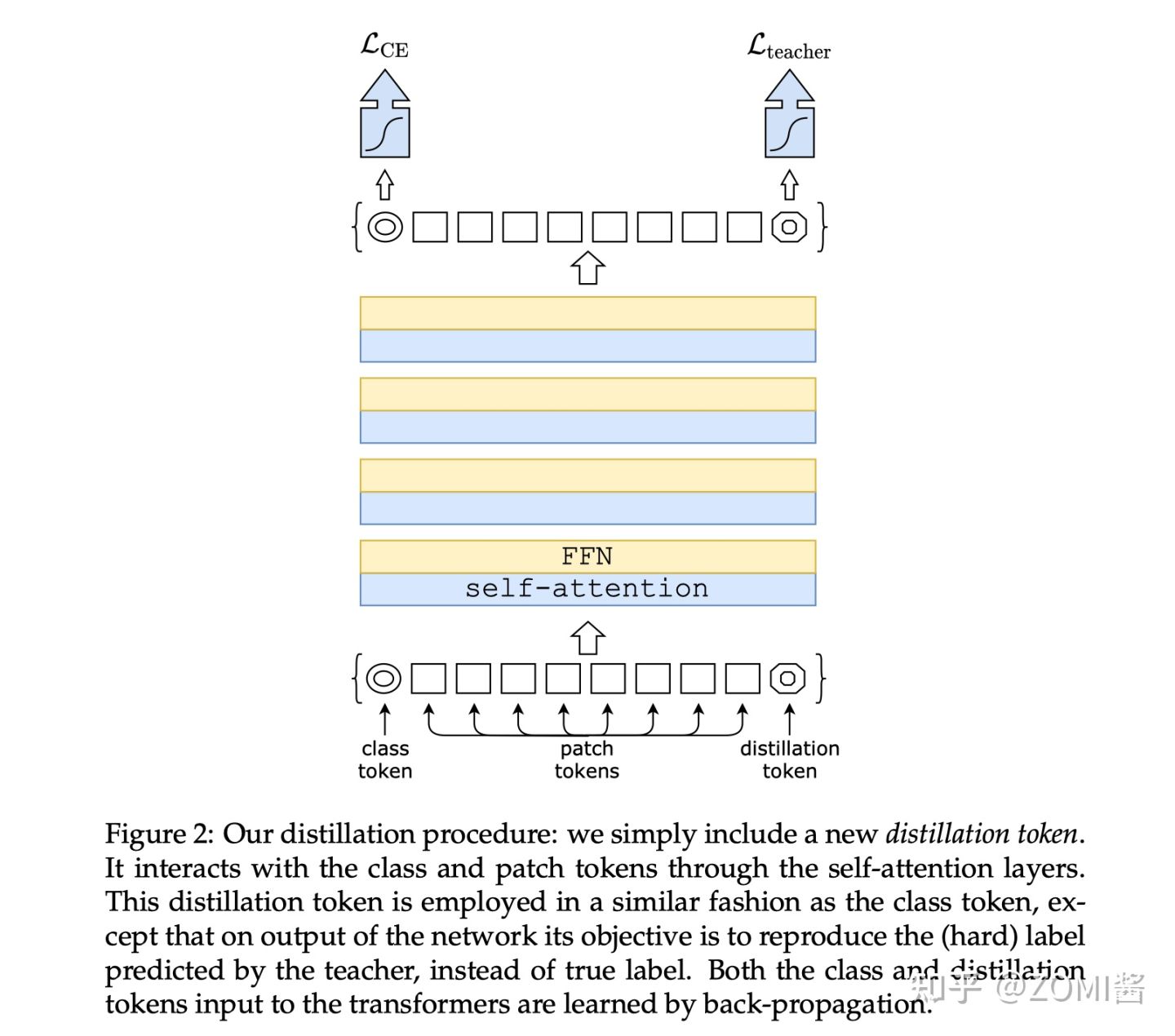
對比 ViT 的輸出是一個 softmax,它代表著預測結果屬於各個類別的概率的分佈。ViT的做法是直接將 softmax 與 GT label取 CE Loss。
而在 DeiT 中,除了 CE Loss 以外,還要 1)定義蒸餾損失;2)加上 Distillation Token。
- 定義蒸餾損失
蒸餾分兩種,一種是軟蒸餾(soft distillation),另一種是硬蒸餾(hard distillation)。軟蒸餾如下式所示,Z_s 和 Z_t 分別是 student model 和 teacher model 的輸出,KL 表示 KL 散度,psi 表示softmax函數,lambda 和 tau 是超引數:
硬蒸餾如下式所示,其中 CE 表示交叉熵:
學生網路的輸出 Z_s 與真實標籤之間計算 CE Loss 。如果是硬蒸餾,就再與教師網路的標籤取 CE Loss。如果是軟蒸餾,就再與教師網路的 softmax 輸出結果取 KL Loss 。
值得注意的是,Hard Label 也可以通過標籤平滑技術 (Label smoothing) 轉換成Soft Labe,其中真值對應的標籤被認為具有 1- esilon 的概率,剩餘的 esilon 由剩餘的類別共用。
- 加入 Distillation Token
Distillation Token 和 ViT 中的 class token 一起加入 Transformer 中,和class token 一樣通過 self-attention 與其它的 embedding 一起計算,並且在最後一層之後由網路輸出。
而 Distillation Token 對應的這個輸出的目標函數就是蒸餾損失。Distillation Token 允許模型從教師網路的輸出中學習,就像在常規的蒸餾中一樣,同時也作為一種對class token的補充。

DeiT 具體實驗
實驗引數的設定:圖中表示不同大小的 DeiT 結構的超引數設定,最大的結構是 DeiT-B,與 ViT-B 結構是相同,唯一不同的是 embedding 的 hidden dimension 和 head 數量。作者保持了每個head的隱變數維度為64,throughput是一個衡量DeiT模型處理圖片速度的變數,代表每秒能夠處理圖片的數目。

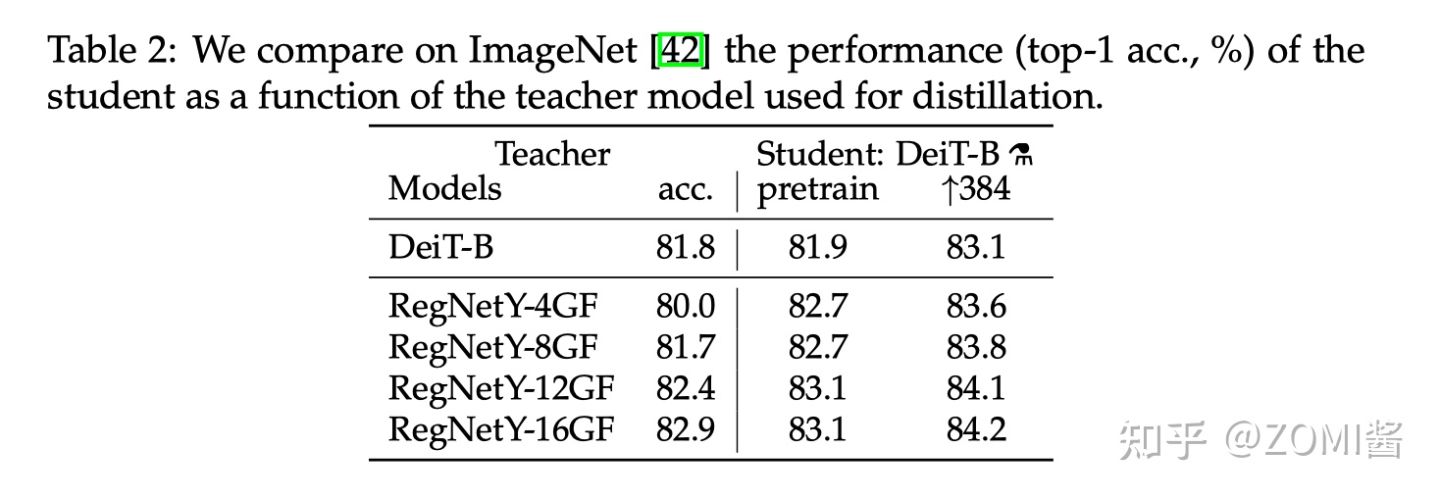
- Teacher model對比
作者首先觀察到使用 CNN 作為 teacher 比 transformer 作為 teacher 的效能更優。下圖中對比了 teacher 網路使用 DeiT-B 和幾個 CNN 模型 RegNetY 時,得到的 student 網路的預訓練效能以及 finetune 之後的效能。
其中,DeiT-B 384 代表使用解析度為 384×384 的影象 finetune 得到的模型,最後的那個小蒸餾符號 alembic sign 代表蒸餾以後得到的模型。
- 蒸餾方法對比
下圖是不同蒸餾策略的效能對比,label 代表有監督學習,前3行分別是不使用蒸餾,使用soft蒸餾和使用hard蒸餾的效能對比。前3行不使用 Distillation Token 進行訓練,只是相當於在原來 ViT 的基礎上給損失函數加上了蒸餾部分。
對於Transformer來講,硬蒸餾的效能明顯優於軟蒸餾,即使只使用 class token,不使用 distill token,硬蒸餾達到 83.0%,而軟蒸餾的精度為 81.8%。
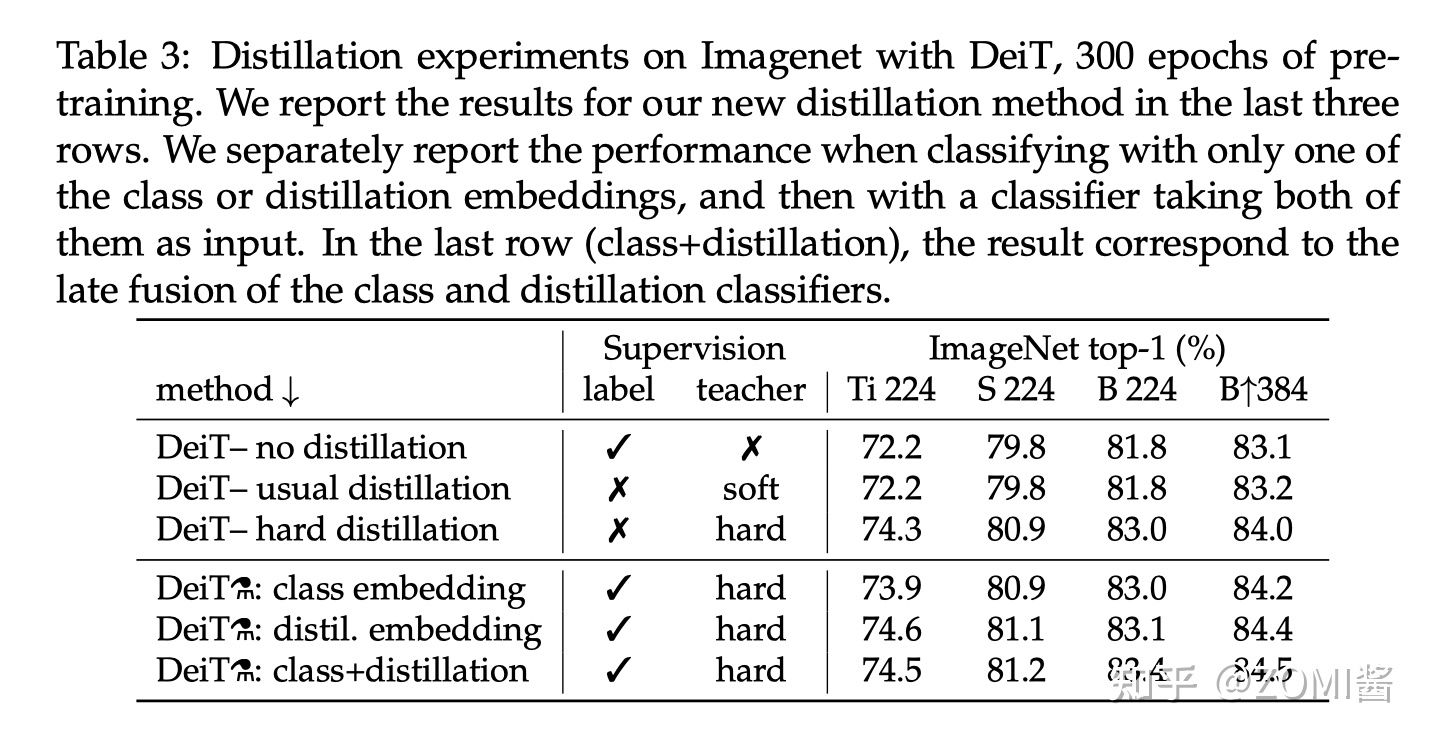
從最後兩列 B224 和 B384 看出,以更高的解析度進行微調有助於減少方法之間的差異。這可能是因為在微調時,作者不使用教師資訊。隨著微調,class token 和 Distillation Token 之間的相關性略有增加。
除此之外,蒸餾模型在 accuracy 和 throughput 之間的 trade-off 甚至優於 teacher 模型,這也反映了蒸餾的有趣之處。
- 效能對比
下面是不同模型效能的數值比較。可以發現在引數量相當的情況下,折積網路的速度更慢,這是因為大的矩陣乘法比小折積提供了更多的優化機會。EffcientNet-B4和DeiT-B alembic sign的速度相似,在3個資料集的效能也比較接近。

- 對比實驗
作者還做了一些關於資料增強方法和優化器的對比實驗。Transformer的訓練需要大量的資料,想要在不太大的資料集上取得好效能,就需要大量的資料增強,以實現data-efficient training。幾乎所有評測過的資料增強的方法都能提升效能。對於優化器來說,AdamW比SGD效能更好。
此外,發現Transformer對優化器的超引數很敏感,試了多組 lr 和 weight+decay。stochastic depth有利於收斂。Mixup 和 CutMix 都能提高效能。Exp.+Moving+Avg. 表示引數平滑後的模型,對效能提升只是略有幫助。最後就是 Repeated augmentation 的資料增強方式對於效能提升幫助很大。

小結
DeiT 模型(8600萬引數)僅用一臺 GPU 伺服器在 53 hours train,20 hours finetune,僅使用 ImageNet 就達到了 84.2 top-1 準確性,而無需使用任何外部資料進行訓練,效能與最先進的折積神經網路(CNN)可以抗衡。其核心是提出了針對 ViT 的教師-學生蒸餾訓練策略,並提出了 token-based distillation 方法,使得 Transformer 在視覺領域訓練得又快又好。
參照
[1] https://zhuanlan.zhihu.com/p/349315675
[2] DeiT:使用Attention蒸餾Transformer
[3] https://zhuanlan.zhihu.com/p/102038521
[4] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 2.7 (2015).
[5] Touvron, Hugo, et al. "Training data-efficient image transformers & distillation through attention." International Conference on Machine Learning. PMLR, 2021.
[6] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[7] Wei, Longhui, et al. "Circumventing outliers of autoaugment with knowledge distillation." European Conference on Computer Vision. Springer, Cham, 2020.