Apache Hudi資料跳過技術加速查詢高達50倍
介紹
在 Hudi 0.10 中,我們引入了對高階資料佈局優化技術的支援,例如 Z-order和希爾伯特空間填充曲線(作為新的聚類演演算法),即使在經常使用過濾器查詢大表的複雜場景中,也可以在多個列而非單個列上進行資料跳過。
但實際上什麼是Data Skipping資料跳過?
隨著儲存在資料湖中的資料規模越來越大,資料跳過作為一種技術越來越受歡迎。 資料跳過本質上是各種型別索引的通用術語,使查詢引擎能夠有效地跳過資料,這與它當前執行的查詢無關,以減少掃描和處理的資料量,節省掃描的資料量以及( 潛在地)顯著提高執行時間。 讓我們以一個簡單的非分割區parquet表「sales」為例,它儲存具有如下模式的記錄:

此表的每個 parquet 檔案自然會在每個相應列中儲存一系列值,這些值與儲存在此特定檔案中的記錄集相對應,並且對於每個列 parquet 將遵循自然順序(例如,字串、日期、整數等) 或推導一個(例如,複合資料型別 parquet 按字典順序對它們進行排序,這也匹配其二進位制表示的排序)。
但是如果有一個排序和一個範圍......還有最小值和最大值!現在意味著每個 Parquet 檔案的每一列都有明確定義的最小值和最大值(也可以為 null)。最小值/最大值是所謂的列統計資訊的範例 - 表徵儲存在列檔案格式(如 Parquet)的單個列中的值範圍的指標,比如
- 值的總數
- 空值的數量(連同總數,可以產生列的非空值的數量)
- 列中所有值的總大小(以位元組為單位)(取決於使用的編碼、壓縮等)
配備了表徵儲存在每個檔案的每個單獨列中的一系列值的列統計資訊,現在讓我們整理下表:每一行將對應於一對檔名和列,並且對於每個這樣的對,我們將寫出相應的統計資料:最小值,最大值,計數,空計數:

這本質上是一個列統計索引!
為方便起見我們對上表進行轉置,使每一行對應一個檔案,而每個統計列將分叉為每個資料列的自己的副本:

這種轉置表示為資料跳過提供了一個非常明確的案例:
對於由列統計索引索引的列 C1、C2、... 上的謂詞 P1、P2、... 的查詢 Q,我們可以根據儲存在索引中的列統計資訊評估這些謂詞 P1、P2 等對於表的每個對應檔案,以瞭解特定檔案「file01」、「file02」等是否可能包含與謂詞匹配的值。這種方法正是 Spark/Hive 和其他引擎所做的,例如,當他們從 Parquet 檔案中讀取資料時——每個單獨的 Parquet 檔案都儲存自己的列統計資訊(對於每一列),並且謂詞過濾器被推播到 Parquet Reader 它能夠評估所討論的查詢是否符合儲存在列中(在檔案中)的資料條件,從而避免在檔案不包含任何與查詢謂詞匹配的資料的情況下對資料進行不必要的提取、解壓縮和解碼。
但是如果 Parquet 已經儲存了列統計資訊,那麼建立附加索引有什麼意義呢?
每個 Parquet 檔案僅單獨儲存我們上面組合的索引中的一行。這種方法的明顯缺點是,要了解哪些檔案可能包含查詢正在尋找的資料,查詢引擎必須讀取表中影響查詢效能的每個 Parquet 檔案的 Parquet 頁尾(甚至可能導致來自雲的限制)儲存)與以更緊湊格式表示的專用索引相比。
Hudi 0.11 中的列統計索引和資料跳過
在 Hudi 0.10 中,我們引入了非常簡單的列統計索引(儲存為簡單的 Parquet 表)的權宜之計實現,以支援 Hudi 中資料跳過實現的第一個版本,以展示 Z-order 和 Hilbert 的強大功能空間填充曲線作為高階佈局優化技術。
在 Hudi 0.11 中,我們在後設資料表中引入了多模索引,例如布隆過濾器索引和列統計索引,這兩者都實現為後設資料表中的專用分割區(分別為「column_stats」和「bloom_filters」)。雖然這些新索引仍處於試驗階段,但將列統計索引移動到後設資料表中意味著更多:
- 強大的支援:列統計索引 (CSI) 現在還享有後設資料表的一致性保證
- 高效實現:後設資料表使用 HFile 作為基礎檔案和紀錄檔檔案格式,促進基於鍵的快速查詢(排序鍵值儲存)。實際上意味著對於具有大量列的大型表,我們不需要讀取整個列統計索引,並且可以通過查詢查詢中參照的列來簡單地投影其部分。
設計
在這裡,我們將介紹新列統計索引設計的一些關鍵方面。如果您對更多詳細資訊感興趣,請檢視 RFC-27 瞭解更多詳細資訊。
列統計索引作為獨立分割區保留在後設資料表中(指定為「column_stats」)。為了能夠在保持靈活性的同時跟上最大表的規模,可以將索引設定為分片到多個檔案組中,並根據其鍵值將單個記錄雜湊到其中的任何一箇中。要組態檔組的數量,請使用以下設定(預設值為 2):
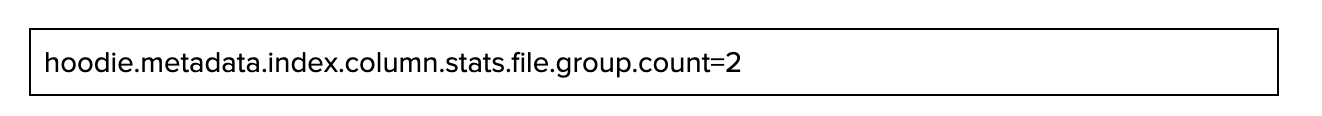
如前所述,後設資料表使用 HFile 作為其儲存檔案格式(這是一種非常有效的排序二進位制鍵值格式),以便能夠
- 有效地查詢基於它們的鍵的記錄以及
- 根據鍵的字首有效地掃描記錄範圍
為了解釋如何在列統計索引中使用它,讓我們看一下它的記錄鍵的組成:

用列字首索引記錄的鍵不是隨機的,而是由以下觀察引起的
- 通過 HFile 儲存所有排序的鍵值對,這樣的鍵組合提供了與特定列 C 相關的所有記錄的區域性性的良好屬性
- 對原始表的任何給定查詢通常只過濾少數列,這意味著我們可以通過避免讀取完整索引來尋求效率,而是簡單地將其連續切片投影到列 C1、C2 等查詢過濾上
為了更好地舉例說明,讓我們看一下 C2 列上的查詢 Q 過濾:

我們可以簡單地讀取一個連續的記錄塊,而無需 a) 讀取整個索引(可能很大),也不需要 b) 隨機尋找我們感興趣的記錄。這使我們能夠在非常大的表上獲得可觀的效能改進。
基準測試
為了全面演示列統計索引和資料跳過功能,我們將使用眾所周知的 Amazon 評論資料集(僅佔用 50Gb 儲存空間),以便任何人都可以輕鬆複製我們的結果,但是使用稍微不常見的攝取設定來展示列統計索引和資料跳過帶來的效率如何隨著資料集中的檔案數量而變化。
攝取
為了將 Amazon 評論資料集提取到 Hudi 表中,我們使用了這個gist。
請注意,您必須指定以下設定屬性以確保在攝取期間同步構建列統計索引:

但是,如果您想在當前沒有列統計索引的現有表上執行實驗,您可以利用非同步索引器功能回填現有表的索引。
查詢
請注意要檢視資料跳過操作,需要執行以下操作:
- 確保在讀取路徑上啟用了後設資料表
- 資料跳過功能已啟用
為此必須將以下 2 個屬性指定為 Spark 或 Hudi 選項:

預設情況下後設資料表僅在寫入端啟用,如果讀者願意在讀取路徑上利用後設資料表,他們仍然必須明確指定相應的設定
請檢視此gist以瞭解如何查詢先前攝取的資料集。
EMR 設定
所有測試都在具有以下設定的小型 EMR 叢集上執行,如果您選擇這樣做可以輕鬆地重現相同的結果。
節點:m5.xlarge(1 個 master / 3 個 executor)
Spark:OSS 3.2.1(Hadoop 3.2)
執行非分割區 COW 表
請注意我們故意壓縮檔案大小以生成大量有意義的檔案,因為資料集只有 50Gb。
- 資料集:亞馬遜評論(約 50Gb 未壓縮)
- 記錄:161M(~160 位元組)
- 表型別:COW(非分割區)
- 檔案大小:1Mb
- 檔案數:~39k(總大小~47Gb,壓縮,zstd)
- 列統計:21 列(~847k 記錄,~63 Mb)
- 預熱:否(冷快取,每次都重新啟動 shell 以重新整理任何快取)
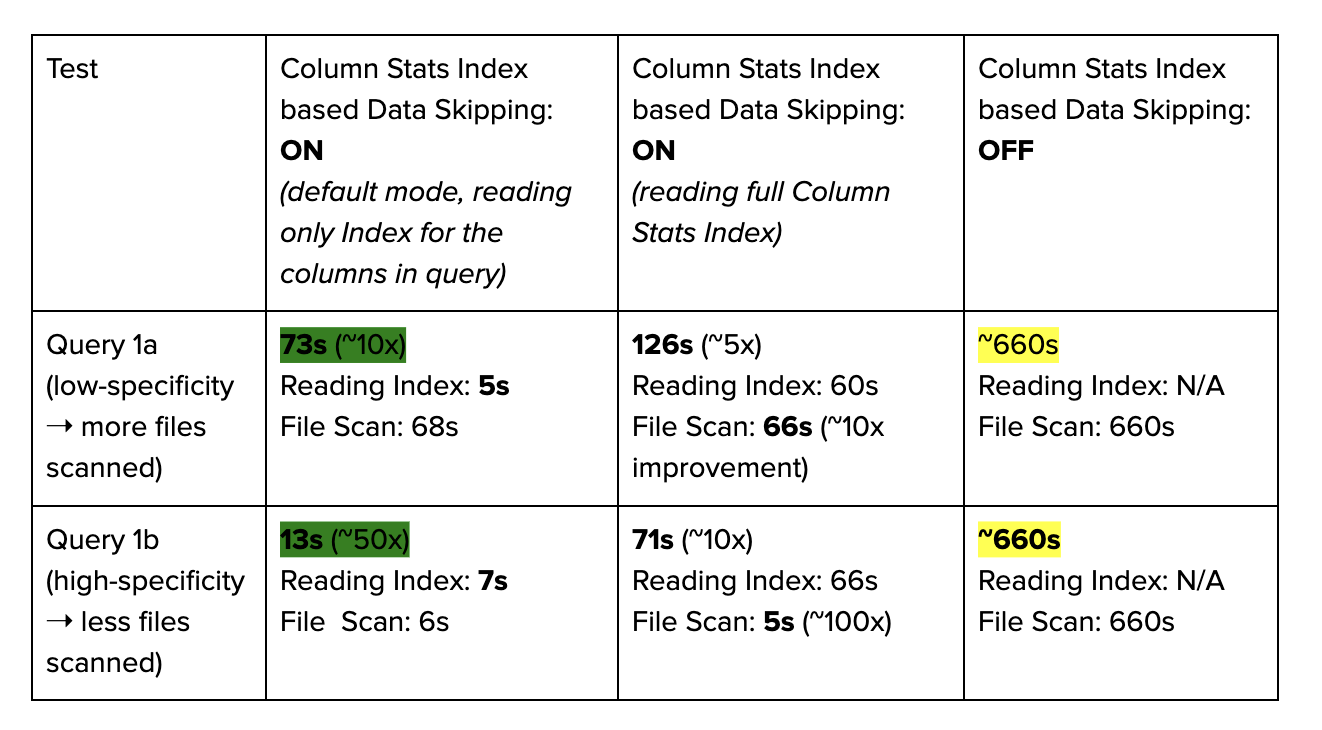
從上表中可以很容易地看出,由 Hudi 0.11 中的新列統計索引提供支援的資料跳過顯著提高了查詢的執行效能(與其修剪潛力成正比),減少了執行執行時間並節省了關鍵的計算資源 直接轉化為基於 Hudi 的基於雲的 Lakes 和 Lakehouses 的成本節約。
儘管現在 Hudi 使用者已經可以使用列統計索引和資料跳過的功能,但目前還有更多工作要做:
- 支援 Merge-On-Read 表中的資料跳過
- 為列統計索引查詢新增快取
- 進一步分析和優化列統計索引效能
如果您想關注當前正在進行的工作,請檢視 HUDI-1822 並留下您的評論。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

