MoCo V1:視覺領域也能自監督啦
何凱明從 CVPR 2020 上發表的 MoCo V1(Momentum Contrast for Unsupervised Visual Representation Learning),到前幾天掛在arxiv上面的 MoCo V3(An Empirical Study of Training Self-Supervised Visual Transformers),MoCo一共走過了三個版本。
今天介紹 MoCo 系列第一版 MoCo v1 就是在 SimCLR 發表前經典的影象自監督學習方法,MoCo v1 和 v2 是針對 CNN 設計的,而 MoCo v3 是針對 Transformer 結構設計的,反映了 MoCo 系列對視覺模型的普適性。
[TOC]
自監督學習 Self-Supervised Learning
一般機器學習分為有無監督學習,無監督學習和強化學習。而自監督學習(Self-Supervised Learning)是無監督學習裡面的一種,主要是希望能夠學習到一種通用的特徵表達用於下游任務 (Downstream Tasks)。而在視覺模型中,MoCo 之所以經典是創造出了一個固定的視覺自監督的模式:
Unsupervised Pre-train, Supervised Fine-tune.
預訓練模型使用自監督方法,下游任務使用監督方法微調
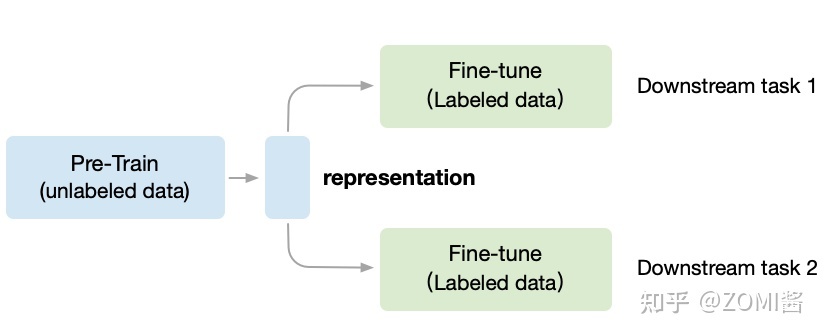
對應圖中,預訓練階段使用無標籤的資料集 (unlabeled data),因為帶標籤的(labeled data)資料收集非常昂貴,需要大量的新一代農民工去標註,成本是相當高。 相反,無標籤的資料集收集很方便,不需要大量的新一代農民工。

在無監督CV領域,第一階段叫做in a task-agnostic way,在訓練模型引數的時候,Self-Supervised Learning 就想不用帶標籤的資料,先把初始化網路模型的權重引數訓練到基本可用,得到一箇中間權重引數結果,我們把它叫做 Visual Representation。
第二階段叫做in a task-specific way,根據下游任務 (Downstream Tasks) 使用帶標籤的資料集把引數訓練到精度達標,這時使用的資料集量就不用太多了,因為引數經過了階段一的預訓練啦。
MoCo 遵循這個思想,預訓練的 MoCo 模型也會得到 Visual Representation,然後通過 Fine-tune 以適應各種各樣的下游任務(比如目標檢測、語意分割等)。下面圖中的實驗結果表明,MoCo在 7 個檢測/語意分割任務(PASCAL VOC, COCO, 其他的資料集)上可以超過了監督學習訓練版本。

自監督學習的關鍵可以概括為兩點:Pretext Task,Loss Function,在下面分別介紹。
Contrastive loss
Contrastive loss 來自於 2006年 Yann LeCun 組的工作(Dimension- ality reduction by learning an invariant mapping)。
Contrastive loss 的思想是想讓:1)相近的樣本之間的距離越小越好。2)不似樣本之間的距離如果小於m,則通過互斥使其距離接近m。文章對第二個點有個形象的解釋,就像長度為m的彈簧,如果它被壓縮,則會因為斥力恢復到長度m。

其中 W 是網路權重;Y 是成對標籤,如果 X1,X2 這對樣本屬於同一個類,Y=0,屬於不同類則 Y=1。Dw 是 X1 與 X2 在潛變數空間的歐幾里德距離。當 Y=0,調整引數最小化X1與X2 之間的距離。當 Y=1,如果 X1與X2 之間距離大於 m,則不做優化;如果 X1 與 X2 之間的距離小於 m, 則增大兩者距離到 m。
最後的實際效果就像論文給出的實驗結果,訓練完後在Mnist手寫字型資料集上4和9明確的分開出來了。

Pretext Task
Pretext Task(譯作:藉口、託辭)是無監督學習領域的一個常見的術語,專指通過完成暫時的任務A,能夠對後續的任務B、C、D有幫助。下面針對NLP和CV有兩種主要的Pretext模式。
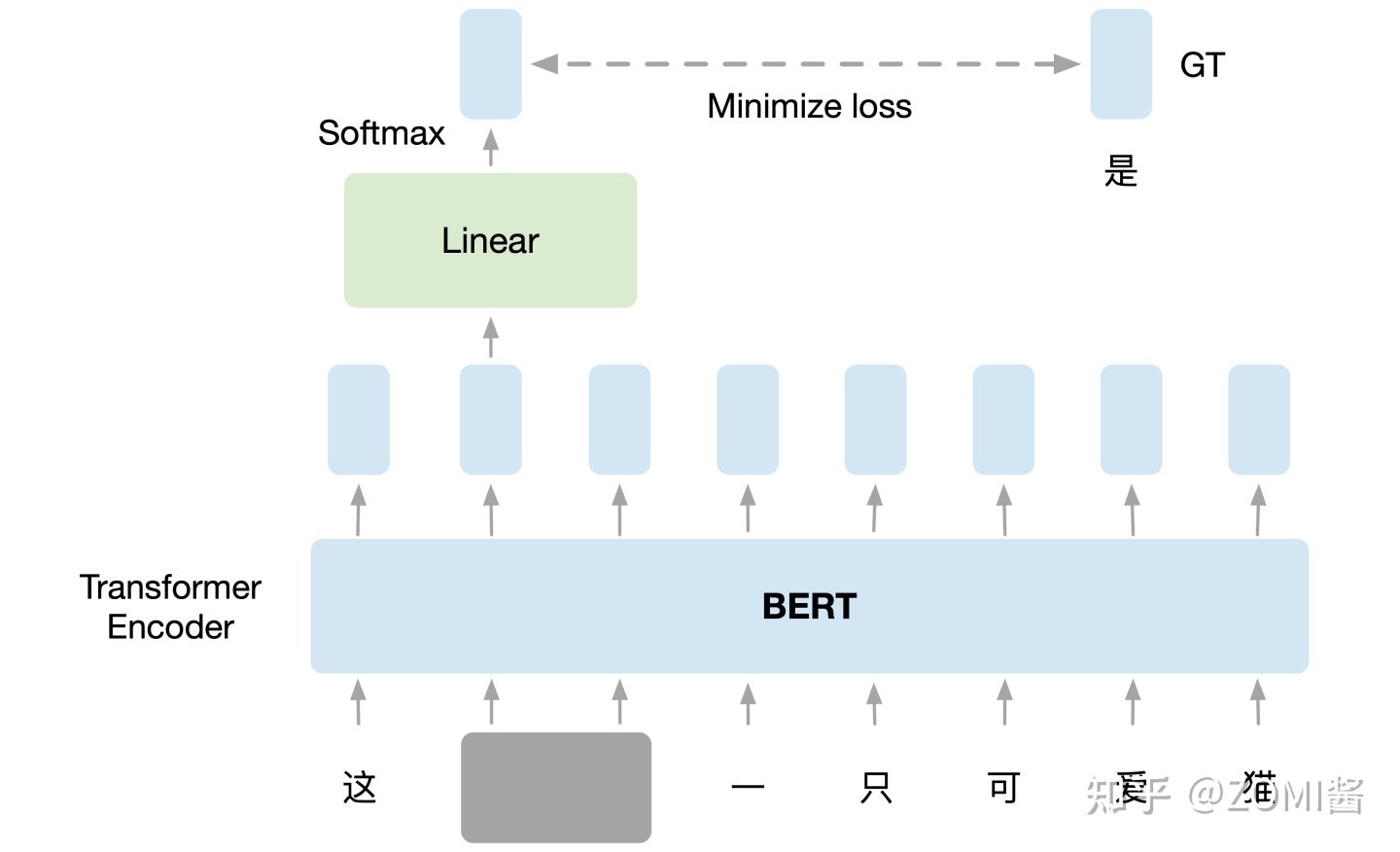
- NLP領域的 Pretext Task:在訓練 BERT 的時候,預訓練過程進行作填空的任務。
如下圖所示,把輸入文字裡面的一部分隨機蓋住,就是直接用一個掩碼 Mask 把要蓋住的token(字元或者一個字)給遮蓋住,換成一個特殊的字元。接下來把這個蓋住的 token 對應位置輸出的向量執行線性變換 Linear Transformation,對輸出執行softmax計算輸出關於每一個字的概率分佈。因為這時候 BERT 並不知道被掩蓋住的字是 "灣" ,但是輸入的原始資料是知道這個資訊的,所以損失就是讓這個輸出和被蓋住的 "灣" 越接近越好。這個任務和下游任務毫不相干,但是 BERT 就是通過 Pretext Task 學習到了很好的 Language Representation 作為預訓練模型,很好地適應了下游任務。
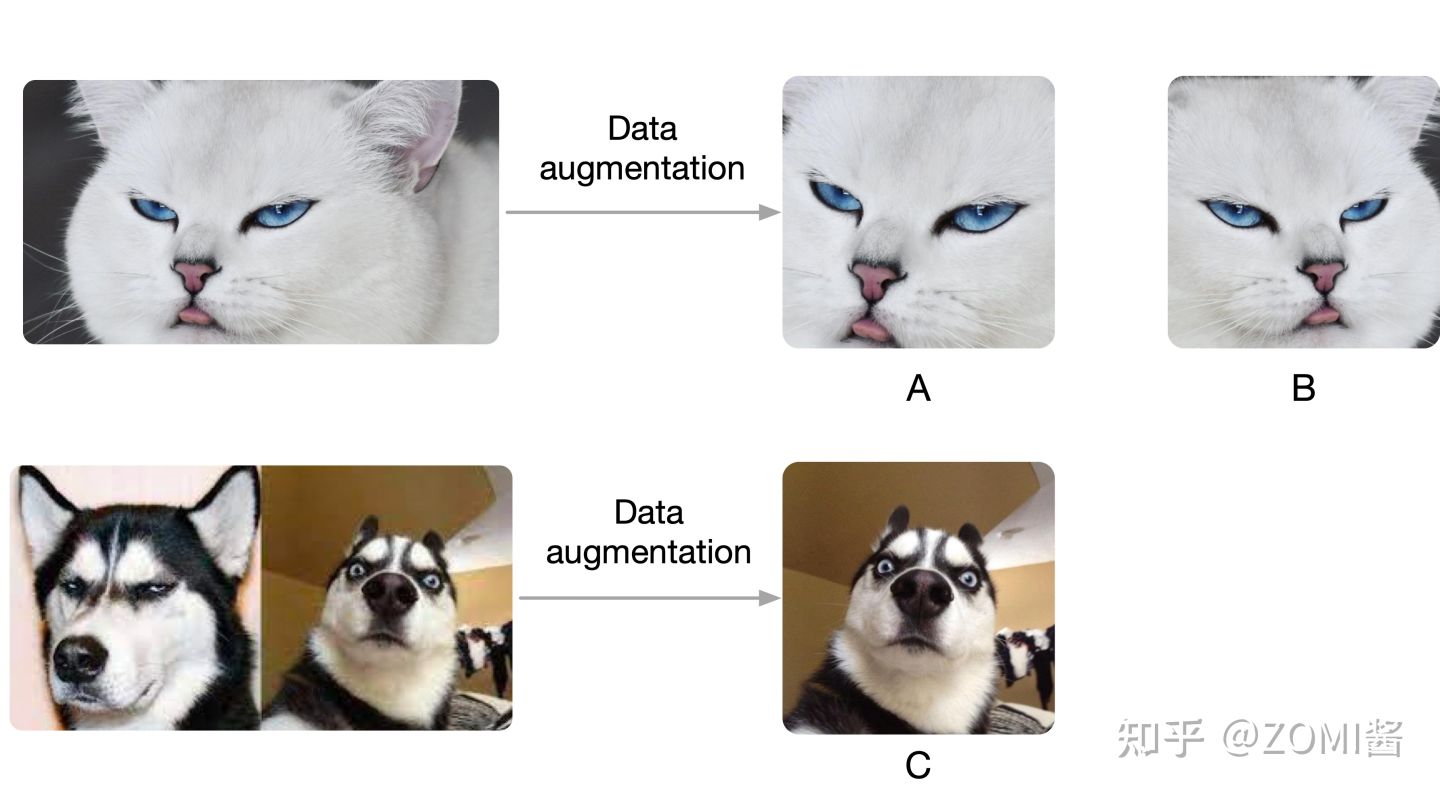
(2) CV領域的 Pretext Task:在訓練 SimCLR 的時候,預訓練過程讓模型區分相似和不相似的影象。
如下圖所示,假設現在有1張圖片 x ,先對 x 進行資料增強,得到2張增強以後的圖片 x_i, x_j 。接下來把增強後的圖片 x_i, x_j 輸入到Encoder裡面,注意這2個Encoder是共用引數的,得到representation h_i 和 h_j ,再把 h_i 和 h_j 通過 Projection head 得到 representation z_i 和 z_j。下面的目標就是最大化同一張圖片得到的 z_i 和 z_j ,最小化不同張圖片得到的 z_i 和 z_j。其具體的結構表示式是:

通過上圖方式訓練視覺模型,學習到了很好的視覺預訓練模型的表達 Image Representation,在下游任務只要稍微進行 Fine-tune,效果就會比有很大的提升。
MoCo V1 原理
整篇文章其實主要是在介紹如何用對比學習去無監督地學習視覺的表徵。
基本原理
先考慮一個任務,現在有兩個圖片,圖片1和圖片2。先在圖片1中通過資料增益產生兩張圖片,記作A,B,在圖片2中截出一個patch記作C,現在把B和C放到樣本庫裡面,樣本庫圖片的位置隨機打亂,然後以A作為查詢的物件,讓你從樣本庫中找到與A對應的圖片。
假設隨機裁剪了A,B, C三個圖,然後將A設為被預測的物件,然後A通過encoder1編碼為向量q,接著B、C經過encoder2編碼為k1和k2。q和k1算相似度得到S1,q和k2算相似度得到S2。我們的目的是想要讓機器學出來A和B是一類(關聯性強),而A和C其它不是(關聯性弱)。
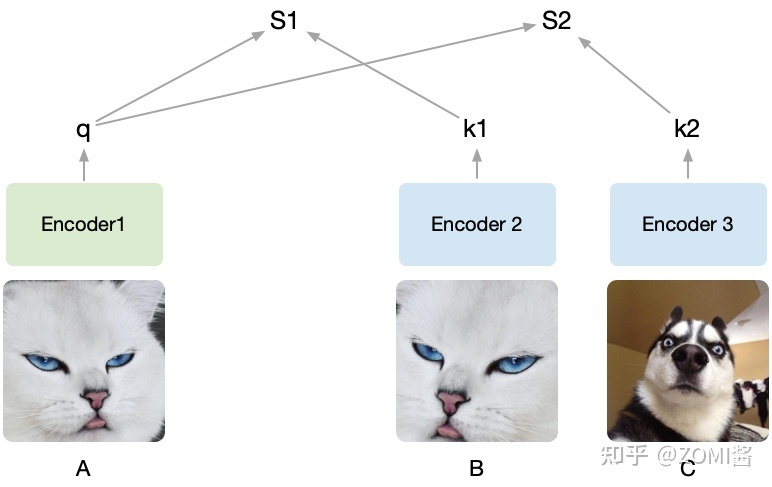
由於提前知道A和B是同一張圖截出來的,而C不是,因此希望S1(A和B的相似度)儘可能高而S2(A和C的相似度)儘可能低。把B打上是正類的標籤,把C打上是負類的標籤,即同一張圖片截出來的patch彼此為正類,不同的圖片截出來的記為負類,由於這種方式只需要設定一個規則,然後讓機器自動去打上標籤,基於這些自動打上的標籤去學習,所以也叫做自監督學習,MoCo就是通過不需要藉助手工標註去學習視覺表徵。
MoCo通過構建一個動態的負類佇列來進行對比學習,依舊通過上面的例子來說,一般要學到好的表徵需要比較多的負類樣本,但是由於計算資源限制又不能加入太多的負類樣本,並且我們也不希望負類樣本是一成不變的,因此提出了就有了 dynamic dictionary with a queue。

x^query可以類比上面的圖A,x^key類比是圖B和圖C,圖中的encoder可以是CNN,queue就是樣本佇列,剩下momentum encoder和contrastive loss。
contrastive loss
對比學習關注的是能不能區別出同類和非同類的樣本,Contrastive loss有很多不同的形式,MoCo使用的是InfoNCE,表示式如下:
這裡通過點積來計算 q 和 k 的相似度,k+ 是指正樣本經過momentum encoder編碼成的向量,注意的是裡面對照樣本里面只有一個正樣本,其餘都是負樣本,至於分母 τ 就是softmax的溫度引數,用來控制概率分佈的尖銳和平滑。
momentum encoder
原始的自監督學習方法裡面的這一批負樣本就相當於是有個字典 (Dictionary),字典的key就是負樣本,字典的value就是負樣本通過 Encoder 之後得到的特徵向量。
那麼現在問題來了:這一批負樣本,即字典的大小是多大呢?
負樣本的規模就是 batch size,即字典的大小就是 batch size。
舉個例子,假設 batch size = 256,那麼對於給定的一個樣本 ,選擇一個正樣本 (經過data augmentation的影象)。然後選擇256個負樣本,然後使用 loss function 來將與正樣本之間的距離拉近,負樣本之間的距離推開到係數m。
毫無疑問是 batch size 越大效果越好的,這一點在 SimCLR 中也得到了證明。但是,由於硬體的影響 batch size 不能設定過大,因此很難應用大量的負樣本。因此效率較低,如圖(a)。
於是圖(b)採用一個較大的memory bank儲存較大的字典:對於給定的一個樣本 ,選擇一個正樣本 (經過data augmentation的影象)。採用一個較大的 memory bank 儲存較大的字典,這個 memory bank 具體儲存的是所有樣本的表徵 representation(涵蓋所有的樣本,比如樣本一共有60000個,那麼memory bank大小就是60000,字典大小也是60000)。取樣其中的一部分負樣本 ,然後使用Contrastive loss將 q 與正樣本之間的距離拉近,負樣本之間的距離推開。這次只更新 Encoder 的引數,和取樣的key值 。因為這時候沒有了 Encoder 的反向傳播,所以支援memory bank容量很大。
但是,這一個step更新的是 Encoder 的引數,和幾個取樣的key值 ,下個step更新的是 Encoder 的引數,和幾個取樣的key值 ,Encoder 的引數每個step都更新,但是某一個 key 可能很多個step才被取樣到更新一次,而且一個epoch只會更新一次。這就出現了一個問題:每個step編碼器都會進行更新,這樣最新的 query 取樣得到的 key 可能是好多個step之前的編碼器編碼得到的 key,因此喪失了一致性。
從這一點來看,(a)端到端自監督學習方法的一致性最好,但是受限於batchsize的影響。而(b)採用一個memory bank儲存較大的字典,一致性卻較差。

實現對比學習可以有以上三種形式。在(a)中,encoder q和encoder k都是端對端一起訓練,encoder q和encoder k可以是兩個不同的網路。(b)的話是把對比的樣本全部存到一個memory bank中,訓練的時候之間從memory bank中取樣。
(c)就是MoCo的做法,與(a)不同的是,右邊的 Encoder 是不直接通過反向傳播來訓練的,而是優化器產生的動量更新,更新的表示式如下。
θ_k 是右邊 Encoder 的引數,m預設設為0.999,θ_q 是左邊編碼 query 的 Encoder,θ_q 通過反向傳播來更新,θ_k 則是通過 θ_q 動量更新。為什麼採用這樣的方式來更新?論文給出的解釋是 θ_k 直接通過反向傳播來更新的效果並不好,因為 θ_k 快速的變化會導致 key 的表徵不穩定,但是動量更新很好地解決了這個問題。
現在的 Momentum Encoder 的更新是通過4式,以動量的方法更新的,不涉及反向傳播,所以 輸入的負樣本 (negative samples) 的數量可以很多,具體就是 Queue 的大小可以比較大,那當然是負樣本的數量越多越好了。這就是 Dictionary as a queue 的含義,即通過動量更新的形式,使得可以包含更多的負樣本。而且 Momentum Encoder 的更新極其緩慢,所以Momentum Encoder 的更新相當於是看了很多的 Batch,也就是很多負樣本。
MoCo的每個step都會更新Momentum Encoder,雖然更新緩慢,但是每個step都會通過式(4)更新 Momentum Encoder,這樣 Encoder 和 Momentum Encoder 每個step 都有更新,就解決了一致性的問題。
MoCo V1演演算法理解
如果還沒有了解清楚的話,可以來看下演演算法訓練的虛擬碼,也許會更清晰一點。

- 資料增強:
現在我們有一堆無標籤的資料,拿出一個 Batch,程式碼錶示為 x,也就是 張圖片,分別進行兩種不同的資料增強,得到 x_q 和 x_k,則 x_q 是 張圖片,x_k 也是 張圖片。
for x in loader: # 輸入一個影象序列x,包含N張圖,沒有標籤
x_q = aug(x) # 查詢queue的圖 (資料增強得到)
x_k = aug(x) # 模板圖 (資料增強得到)- 分別通過 Encoder 和 Momentum Encoder:
x_q 通過 Encoder 得到特徵 q,維度是 NxC,這裡特徵空間由一個長度為 C=128 的向量表示。
x_k 通過 Momentum Encoder 得到特徵 k,維度是 NxC。
q = f_q.forward(x_q) # 提取查詢特徵,輸出NxC
k = f_k.forward(x_k) # 提取模板特徵,輸出NxC- Momentum Encoder的引數不更新:
# 不使用梯度更新f_k的引數,假設用於提取模板的表示應該是穩定的,不應立即更新
k = k.detach()- 計算 N 張圖片的自己與自己的增強圖的特徵的匹配度:
# 這裡bmm是分批矩陣乘法,輸出Nx1,也就是自己與自己的增強圖的特徵的匹配度
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))這裡得到的 l_pos 的維度是 (N, 1, 1),N 代表 N 張圖片的自己與自己的增強圖的特徵的匹配度。
- 計算 N 張圖片與佇列中的 K 張圖的特徵的匹配度:
# 輸出Nxk,自己與上一批次所有圖的匹配度(全不匹配)
l_neg = mm(q.view(N,C), queue.view(C,K))這裡得到的 l_neg 的維度是 (N, K),代表 N 張圖片與佇列 Queue 中的 K 張圖的特徵的匹配度。
- 把 4, 5 兩步得到的結果concat起來:
logits = cat([l_pos, l_neg], dim=1) # 輸出 Nx(1+k)這裡得到的 logits 的維度是 (N, K+1),把它看成是一個矩陣的話呢,有 N 行,代表一個 Batch Size 裡面的 N 張圖片。每一行的第1個元素是某張圖片自己與自己的匹配度。
- NCE損失函數,就是為了保證自己與自己衍生的匹配度輸出越大越好,否則越小越好:
labels = zeros(N)
# NCE損失函數,就是為了保證自己與自己衍生的匹配度輸出越大越好,否則越小越好
loss = CrossEntropyLoss(logits/t, labels)
loss.backward()- 更新 Encoder 的引數:
update(f_q.params) # f_q 使用梯度立即更新- Momentum Encoder 的引數使用動量更新:
# 這裡使用動量法更新
f_k.params = m * f_k.params + (1 - m) * f_q.params- 更新佇列,刪除最老的一個 Batch,加入一個新的 Batch:
enqueue(queue, k) # 為了生成反例,所以引入了佇列
dequeue(queue)MoCo V1 實驗部分
- 實驗一:Linear Classification Protocol
評價一個自監督模型的效能,最關鍵和最重要的實驗莫過於 Linear Classification Protocol 了,它也叫做 Linear Evaluation,具體做法就是先使用自監督的方法預訓練 Encoder,這一過程不使用任何 label。預訓練完以後 Encoder 部分的權重也就確定了,這時候把它的權重凍結住,同時在 Encoder 的末尾新增 Global Average Pooling 和一個線性分類器 (FC+softmax),並在固定資料集上做 Fine-tune,這一過程使用全部的 label。
上述方法在(a)原始的端到端自監督學習方法,(b)採用一個較大的memory bank儲存較大的字典,(c)MoCo方法的結果對比如下圖。
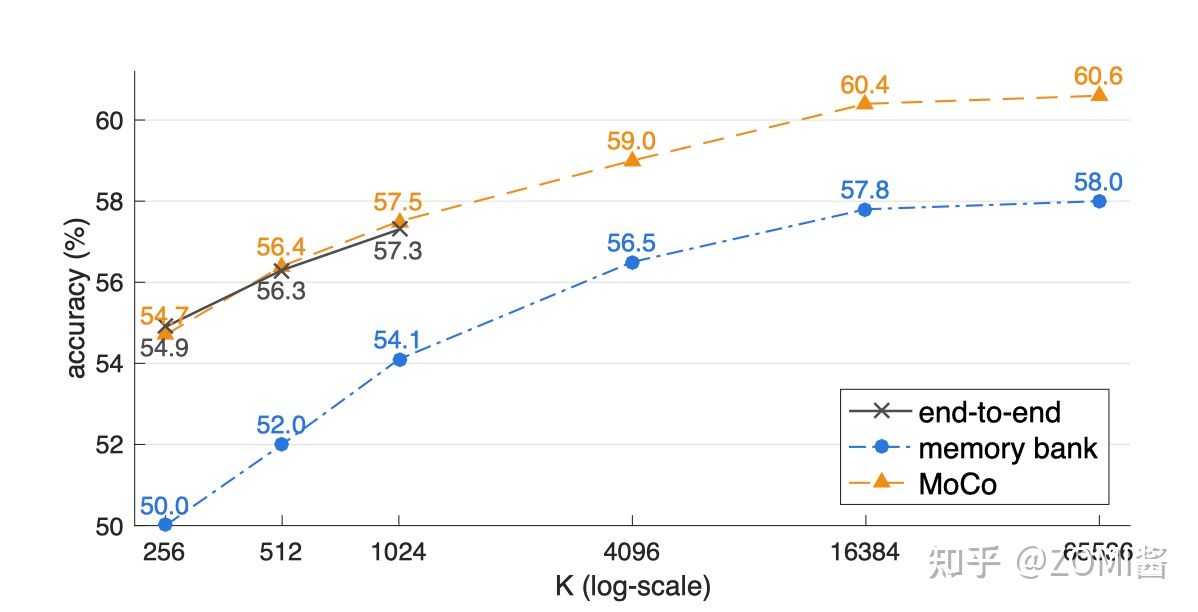
看到圖中的3條曲線都是隨著 K 的增加而上升的,證明對於每一個樣本來講,正樣本的數量都是一個,隨著負樣本數量的上升,自監督訓練的效能會相應提升。我們看圖中的黑色線(a)最大取到了1024,因為這種方法同時使用反向傳播更新 Encoder 和 Encoder 的引數,所以 Batch size 的大小受到了視訊記憶體容量的限制。同時橙色曲線是最優的,證明了MoCo方法的有效性。
- 實驗四:下游任務 Fine-tune 結果
有了預訓練好的模型,就相當於是已經把引數訓練到了初步成型,這時候再根據下游任務 (Downstream Tasks) 的不同去用帶標籤的資料集把引數訓練到完全成型,那這時用的資料集量就不用太多了,因為引數經過了第1階段就已經訓練得差不多了。
本文的下游任務是:PASCAL VOC Object Detection 以及 COCO Object Detection and Segmentation,主要對比的物件是 ImageNet 預訓練模型 (ImageNet supervised pre-training),注意這個模型是使用100%的 ImageNet 標籤訓練的。
如下圖是在 trainval07+12 (約16.5k images) 資料集上 Fine-tune 之後的結果,當Backbone 使用 R50-dilated-C5 時,在 ImageNet-1M 上預訓練的 MoCo 模型的效能與有監督學習的效能是相似的。在 Instagram-1B 上預訓練的 MoCo 模型的效能超過了有監督學習的效能。當Backbone 使用 R50-dilated-C5 時,在 ImageNet-1M 或者 Instagram-1B 上預訓練的 MoCo 模型的效能都超過了有監督學習的效能。
參照
[1] Hadsell, Raia, Sumit Chopra, and Yann LeCun. "Dimensionality reduction by learning an invariant mapping." 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). Vol. 2. IEEE, 2006.
[2] Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020.
[3] He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[4] https://zhuanlan.zhihu.com/p/364446773
[5] https://zhuanlan.zhihu.com/p/46