Kafka入門實戰教學(7):Kafka Streams
1 關於流處理
流處理平臺(Streaming Systems)是處理無限資料集(Unbounded Dataset)的資料處理引擎,而流處理是與批次處理(Batch Processing)相對應的。所謂的無線資料,指的是資料永遠沒有盡頭。而流處理平臺就是專門處理這種資料集的系統或框架。下圖生動形象地展示了流處理和批次處理的區別:

總體來說,流處理給人的印象是低延時,但是結果可能不太精確。而批次處理則相反,它能提供精確的結果,但是往往存在高時延。
一個最簡單的Streaming的結構如下圖所示:
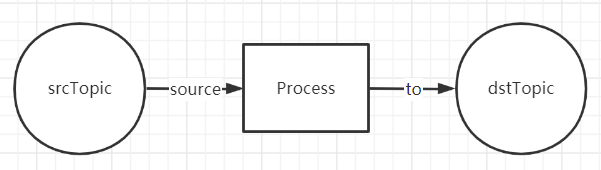
從一個Topic中讀取到資料,經過一些處理操作之後,寫入到另一個Topic中,嗯,這就是一個最簡單的Streaming流式計算。其中,Source Topic中的資料會源源不斷的產生新資料。
那麼,我們再在上面的結構之上擴充套件一下,假設定義了多個Source Topic及Destination Topic,那就構成如下圖所示的較為複雜的拓撲結構:

2 關於Kafka Streams
近些年來,開源流處理領域湧現出了很多優秀框架。光是在 Apache 基金會孵化的專案,關於流處理的巨量資料框架就有十幾個之多,比如早期的 Apache Samza、Apache Storm,以及這些年火爆的 Spark 以及 Flink 等。
Kafka Streams的特點
相比於其他流處理平臺,Kafka Streams 最大的特色就是它不是一個平臺,至少它不是一個具備完整功能(Full-Fledged)的平臺,比如其他框架中自帶的排程器和資源管理器,就是 Kafka Streams 不提供的。Kafka 官網明確定義 Kafka Streams 是一個使用者端庫(Client Library)。我們可以使用這個庫來構建高伸縮性、高彈性、高容錯性的分散式應用以及微服務。使用Kafka Streams API構建的應用程式就是一個普通的應用程式,我們可以選擇任何熟悉的技術或框架對其進行編譯、打包、部署和上線。很不幸,目前Kafka Streams還沒有在除了Java之外的其他主流開發語言的SDK上提供。Kafka Streams最大的特點就是,對於上下游資料來源的限定。目前Kafka Streams只支援與Kafka叢集進行互動,它並沒有提供開箱即用的外部資料來源聯結器。

Kafka Streams應用執行
Kafka Streams宣稱自己實現了精確一次處理語意(Exactly Once Semantics, EOS,以下使用EOS簡稱),所謂EOS,是指訊息或事件對應用狀態的影響有且只有一次。其實,對於Kafka Streams而言,它天然支援端到端的EOS,因為它本來就是和Kafka緊密相連的。下圖展示了一個典型的Kafka Streams應用的執行邏輯:
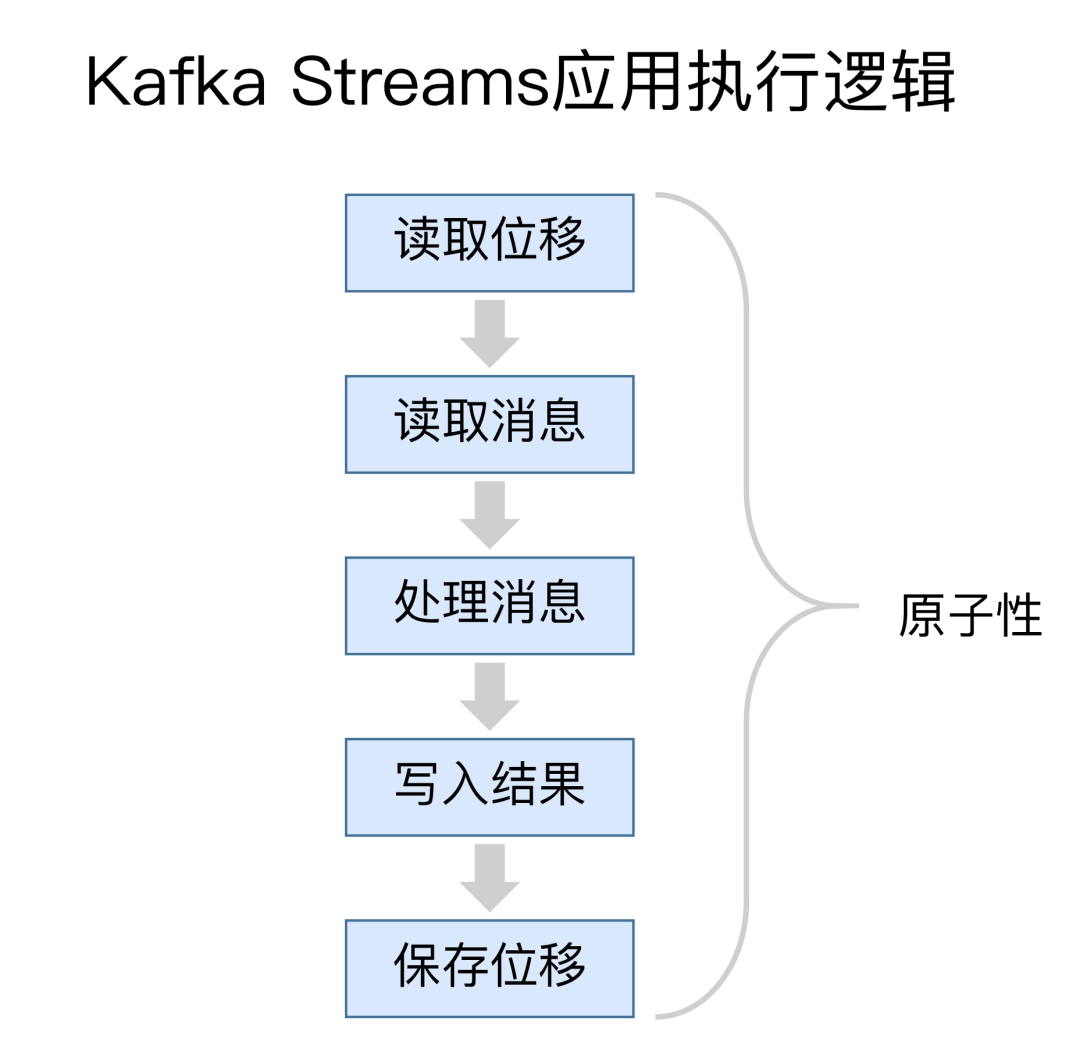
通常情況下,一個 Kafka Streams 需要執行 5 個步驟:
-
讀取最新處理的訊息位移;
-
讀取訊息資料;
-
執行處理邏輯;
-
將處理結果寫回到 Kafka;
-
儲存位置資訊。
這五步的執行必須是原子性的,否則無法實現精確一次處理語意。而在設計上,Kafka Streams在底層大量使用了Kafka事務機制和冪等性Producer來實現多分割區的寫入,又因為它只能讀寫Kafka,因此Kafka Streams很easy地就實現了端到端的EOS。
3 Kafka Streams使用者端
目前.NET圈主流的Kafka使用者端Confluent.Kafka並沒有提供Streams的功能,其實,目前Kafka Streams也只在Java使用者端提供了Streams功能,其他語言均沒有提供。

畫外音:畢竟Kafka是JVM系語言寫的(Scala+Java),Java就是嫡系,一等公民。
那麼,Confluent.Kafka團隊有沒有計劃提供這個功能呢?我在issue列表找到了一些comments,得到的結果是目前沒有這個計劃,它涉及到太多的工作量,WTF。那麼,.NET就真的沒有可以用的Kafka Streams使用者端了麼?實際上,有的,我在Confluent.Kafka的issue內容中找到了下面這個Kafka Streams使用者端:Streamiz.Kafka.Net。

Streamiz.Kafka.Net:https://github.com/LGouellec/kafka-streams-dotnet
目前Streamiz.Kafka.Net這個專案仍然屬於一個不斷開發完善的階段,Star數量278個,生產環境估計無法直接使用,但是拿來學習實踐還是可以的,目前最新版本:1.3.0。其實,Streamiz.Kafka.Net也是基於Confluent.Kafka開發的,相當於對Confluent.Kafka做了一些DSL擴充套件。它的介面名字與用法,和Java API幾乎一致。
4 第一個Streaming應用
如果你對Streaming的概念還不瞭解,建議先閱讀上一篇文章。
應用程式部分
首先,建立一個.NET Core或.NET 5/6的控制檯應用程式。
然後,通過Nuget安裝Streamiz.Kafka.Net包:
PM>Install-Package Streamiz.Kafka.Net
然後,開始編寫第一個Streaming應用程式:
using Streamiz.Kafka.Net; using Streamiz.Kafka.Net.SerDes; using Streamiz.Kafka.Net.Stream; using Streamiz.Kafka.Net.Table; using System; using System.Threading.Tasks; namespace EDT.Kafka.Streams.Demo { public class Program { public static async Task Main(string[] args) { // Stream configuration var config = new StreamConfig<StringSerDes, StringSerDes>(); config.ApplicationId = "test-streams-app"; config.BootstrapServers = "kafka1:9091,kafka2:9092,kafka3:9093"; StreamBuilder builder = new StreamBuilder(); // Stream "test-stream-input" topic with filterNot condition and persist in "test-stream-output" topic. builder.Stream<string, string>("test-stream-input") .FilterNot((k, v) => v.Contains("test")) .To("test-stream-output"); // Create a table with "test-ktable" topic, and materialize this with in memory store named "test-store" builder.Table("test-stream-ktable", InMemory<string, string>.As("test-stream-store")); // Build topology Topology t = builder.Build(); // Create a stream instance with toology and configuration KafkaStream stream = new KafkaStream(t, config); // Subscribe CTRL + C to quit stream application Console.CancelKeyPress += (o, e) => { stream.Dispose(); }; // Start stream instance with cancellable token await stream.StartAsync(); } } }
這個範例Streaming應用程式很簡單,它實現的就是一個如下圖所示的最簡單的處理流程:
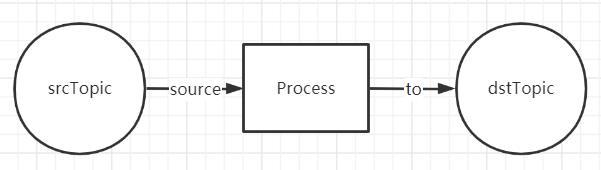
Source Topic是test-stream-input,Destination Topic是test-stream-output,分別對應輸入源 和 輸出地。在處理過程中會建立一個Table,名為test-stream-ktable,它會作為輸入流和輸出流的中間狀態。在Kafka Streams中,流在時間維度上聚合成表,而表在時間維度上不斷更新成流。換句話說,表會轉換成流,流又再轉換成表,如此反覆,完成所謂的Streaming流式計算。
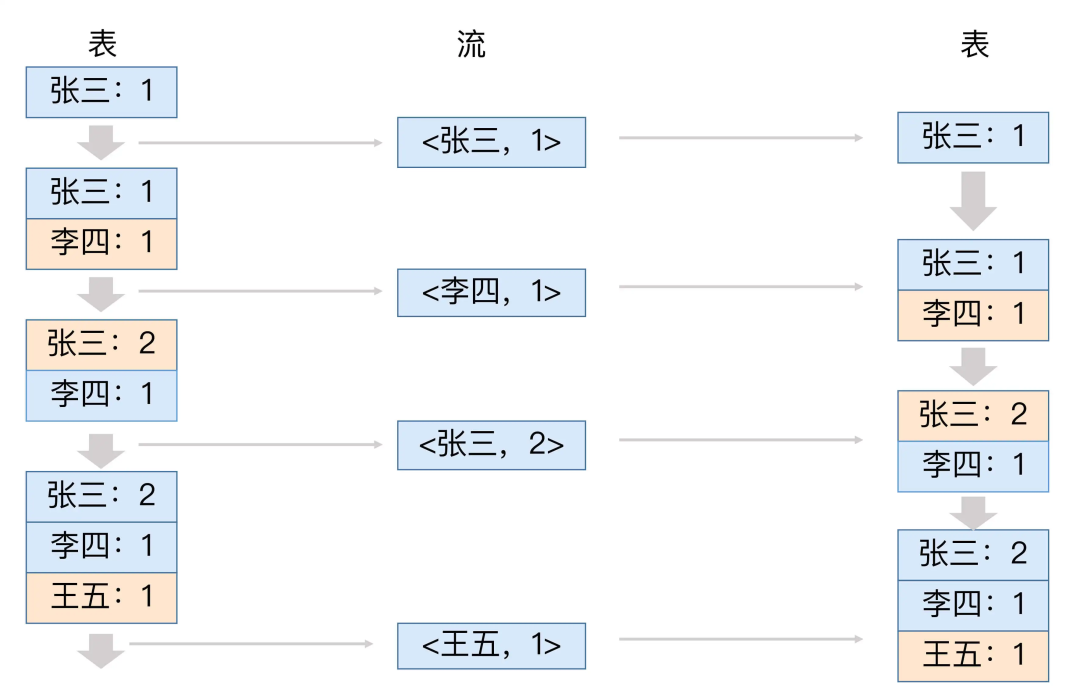
這個test-stream-ktable會儲存在記憶體中一個名為test-stream-kstore的區域,我們理解到這裡就夠了。最後,回到最關鍵的一句程式碼,如下所示。在對輸入源進行處理時,使用了一個DSL進行快速的過濾,即判斷輸入的訊息是否包含test這個字串,包含就不做過濾處理,不包含則進行處理,即傳遞給test-stream-output。
最後,回到最關鍵的一句程式碼,如下所示。在對輸入源進行處理時,使用了一個DSL進行快速的過濾,即判斷輸入的訊息是否包含test這個字串,包含就不做過濾處理,不包含則進行處理,即傳遞給test-stream-output。
builder.Stream<string, string>("test-stream-input") .FilterNot((k, v) => v.Contains("test")) .To("test-stream-output");
Broker部分
為了完成這個demo,我們提前在Kafka Broker端建立幾個如下圖紅線框中的topic。
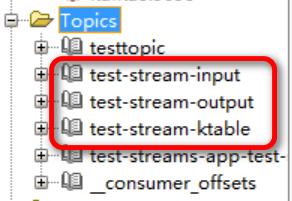
為了方便演示驗證,我們暫且都給他們設定為單個分割區,無額外副本。
測試效果
首先,我們將.NET控制檯程式啟動起來。
然後,我們在Broker端開啟一個Producer命令列,陸續手動輸入一些資料來源:
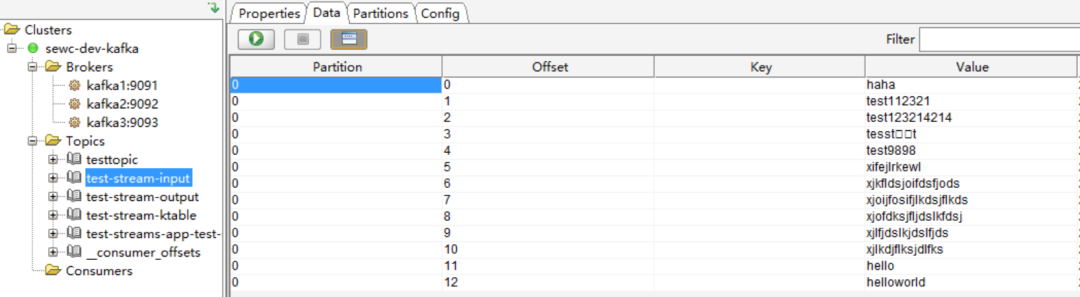
# kafka-console-producer.sh --topic=test-stream-input --broker-list kafka1:9091,kafka2:9092,kafka3:9093 >haha >test112321 >test123214214 >tesst^H^Ht >test9898 >xifejlrkewl >xjkfldsjoifdsfjods >xjoijfosifjlkdsjflkds >xjofdksjfljdslkfdsj >xjlfjdslkjdslfjds >xjlkdjflksjdlfks >hello >helloworld
可以看到,輸入的資料來源中包含了3個含有test關鍵詞的字串訊息。期望的結果是,在Streams應用程式處理邏輯中,過濾掉這3個,將其餘的訊息都進行處理傳遞到output中。
然後,我們就可以通過Kafka Tool去看看input和output這兩個topic的資料驗證一下了:
(1)test-stream-input
(2)test-stream-output
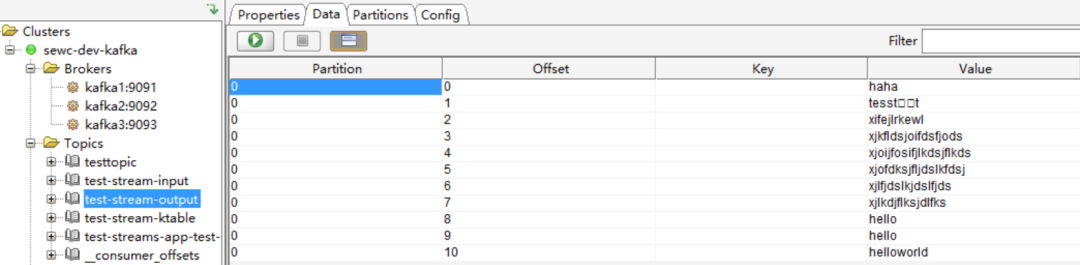
可以看到,test-stream-output中未包含含有test關鍵詞的訊息,第一個Streaming應用程式執行成功。
5 經典WordCount應用
所謂wordcount就是一個經典的單詞計數的應用程式,它可以統計在指定資料來源中每個單詞出現的次數。在Streaming流式計算和MapReduce分散式計算中,它經常出現在範例程式碼中。

應用程式部分
改寫一下上面的demo範例程式碼:
var config = new StreamConfig<StringSerDes, StringSerDes>(); config.ApplicationId = "test-wordcount-app"; config.BootstrapServers = "kafka1:9091,kafka2:9092,kafka3:9093"; StreamBuilder builder = new StreamBuilder(); builder.Stream<string, string>("test-word-in") .FlatMapValues(value => value.Split(" ", StringSplitOptions.RemoveEmptyEntries).ToList()) // 根據空格分隔多個單詞 .Map((key, value) => KeyValuePair.Create(value, "1")) // 轉換為(單詞, 1)的鍵值對形式 .GroupByKey() // 根據單詞分組 .Count() // 計算各個分組value的數量 .ToStream() .Map((key, value) => KeyValuePair.Create(key, $"{key} : {value.ToString()}")) .To("test-word-out"); // Create a table with "test-ktable" topic, and materialize this with in memory store named "test-store" builder.Table("test-word-ktable", InMemory<string, string>.As("test-word-store")); // Build topology Topology t = builder.Build(); // Create a stream instance with toology and configuration KafkaStream stream = new KafkaStream(t, config); // Subscribe CTRL + C to quit stream application Console.CancelKeyPress += (o, e) => { stream.Dispose(); }; // Start stream instance with cancellable token await stream.StartAsync();
Broker端部分
新增幾個範例程式碼需要用到的topic:test-word-in, test-word-out 以及 test-word-ktable。
測試效果
首先,我們將.NET控制檯程式啟動起來。
然後,我們在Broker端開啟一個Producer命令列,陸續手動輸入一些資料來源:
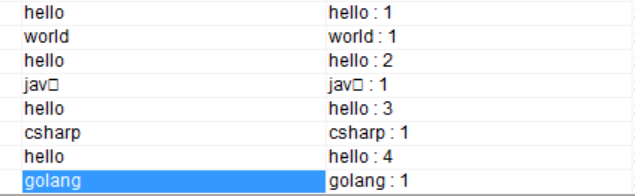
# kafka-console-producer.sh --topic=test-word-in --broker-list kafka1:9091,kafka2:9092,kafka3:9093 >hello world >hello jav^H >hello csharp >hello golang
可以看到,這裡我們的hello出現了4次,其他單詞均只出現了1次。
那麼,我們可以直接去test-word-out這個topic中驗證一下:
6 總結
本文總結了Kafka Streams的基本概念與執行流程,並結合.NET使用者端給出了一個Kafka Streams應用程式的範例。
參考資料
kafka-streams-dotnet:https://lgouellec.github.io/kafka-streams-dotnet
極客時間,胡夕《Kafka核心技術與實戰》
B站,尚矽谷《Kafka 3.x入門到精通教學》

