Java 中的例外處理機制
本篇文章主要介紹了
- Java 中的異常
- 如何處理常式丟擲的異常
- 處理異常的原則
- 例外處理時,效能開銷大的地方
Java 語言在設計之初就提供了相對完善的例外處理機制。
我們首先介紹一下 Java 中的異常。
介紹 Java 中的異常
異常是程式在執行過程中出現的程式異常事件,異常會中斷正在執行的正常指令流 。
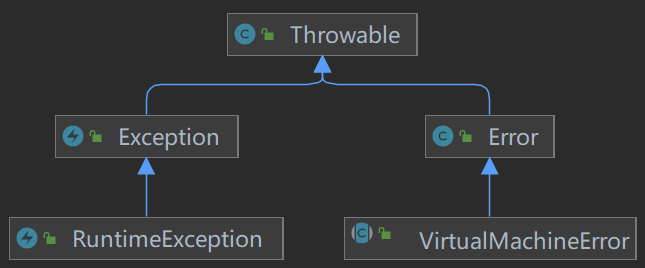
Java 中的異常分為兩大類:Exception 和 Error。
下面是 Exception 和 Error 的類定義
public class Exception extends Throwable {}
public class Error extends Throwable {}
Exception 和 Error 都繼承了 Throwable 類,在 Java 中只有 Throwable 型別的範例才可以被丟擲(throw)或者被捕獲(catch)。
Exception 和 Error 體現了 Java 平臺設計者對不同異常情況的分類。
下面我們逐一介紹 Error 和 Exception。
介紹 Error
Error 類物件一般是由虛擬機器器生成並丟擲,絕大部分的 Error 都會導致虛擬機器器自身處於不可恢復的狀態,是程式無法控制和處理的。當出現 Error 時,一般會選擇終止執行緒。
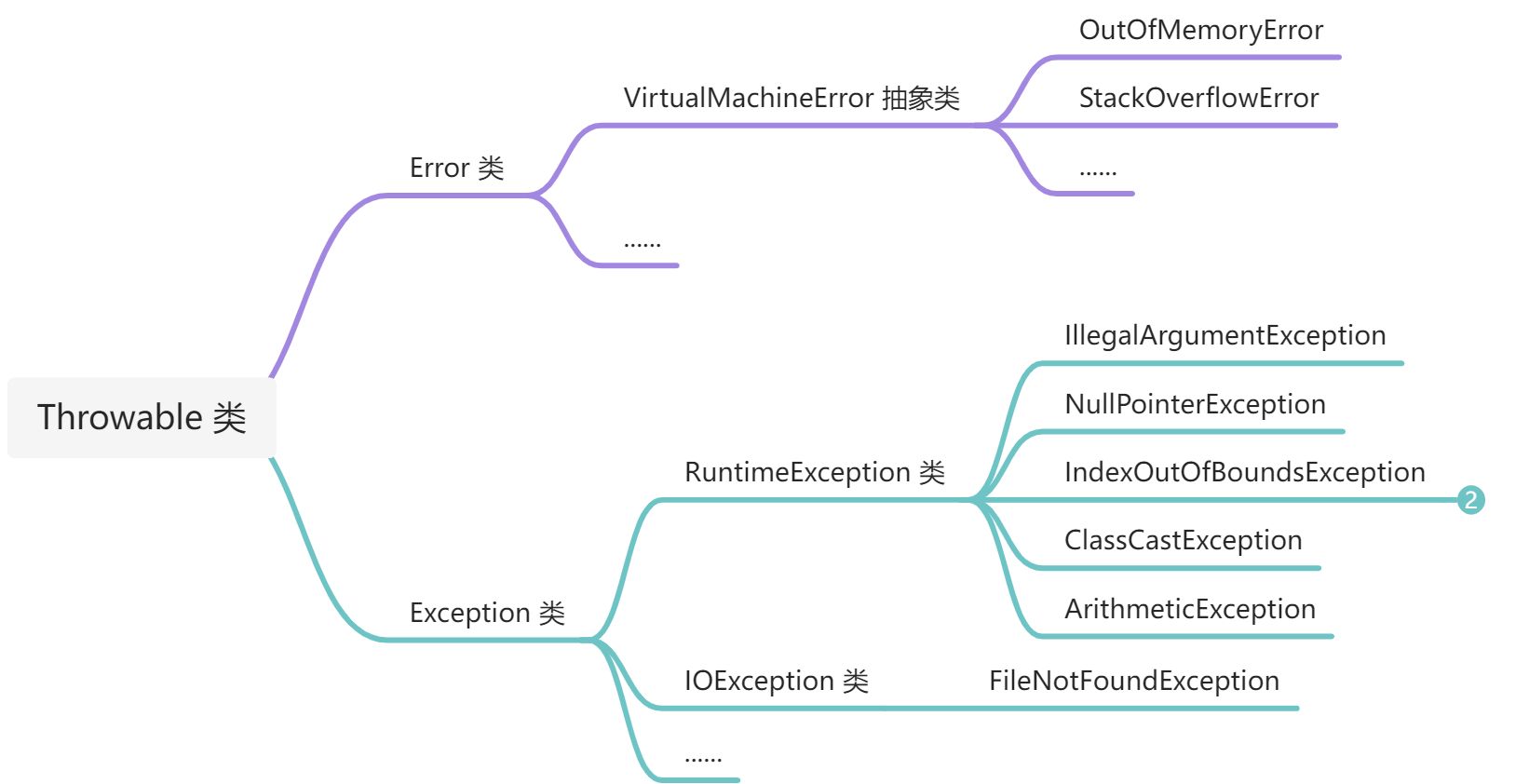
Error 中最常見的是虛擬機器器執行錯誤(VirtualMachineError 抽象類)。
虛擬機器器執行錯誤中最常見的有:
- 記憶體溢位(OutOfMemoryError):由於記憶體不足,虛擬機器器沒有可分配的記憶體了,垃圾回收器也不能釋放更多的記憶體,那麼虛擬機器器丟擲 OutOfMemoryError
- 棧溢位(StackOverflowError):如果一個執行緒已用的棧大小 超過 設定的允許最大的棧大小,那麼虛擬機器器丟擲 StackOverflowError
介紹 Exception
Exception 有兩種型別「編譯時異常」和「執行時異常」
- 「編譯時異常」對應 Java 的 Exception 類
- 「執行時異常」對應 Java 的 RuntimeException 類(RuntimeException 類繼承 Exception 類 )
下面是 Exception、RuntimeException 類的定義
public class Exception extends Throwable {}
public class RuntimeException extends Exception {}
對於「執行時異常」,我們在編寫程式碼的時候,可以不用主動去 try-catch 捕獲(不強制要求),編譯器在編譯程式碼的時候,並不會檢查程式碼是否有對執行時異常做了處理。
相反,對於「編譯時異常」,我們在編寫程式碼的時候,必須主動去 try-catch 獲取 或者 在函數定義中宣告向上丟擲異常(throws),否則編譯就會報錯。
所以:
- 「執行時異常」也叫作非受檢異常(Unchecked Exception)
- 「編譯時異常」也叫作受檢異常(Checked Exception)
在函數丟擲異常的時候,,我們該怎麼處理呢?是吞掉還是向上丟擲?
如果選擇向上丟擲,我們應該選擇丟擲哪種型別的異常呢?是受檢異常還是非受檢異常?
我們下文會對此介紹。
常見的編譯時異常有:
- FileNotFoundException:當嘗試開啟由指定路徑表示的檔案失敗時丟擲
- ClassNotFoundException:當應用程式嘗試通過其字串名稱載入類時丟擲,以下三種方法載入
- Class.forName(java.lang.String)
- ClassLoader.findSystemClass(java.lang.String)
- ClassLoader.loadClass(java.lang.String, boolean)
常見的執行時異常有:
- 非法引數異常(IllegalArgumentException):當傳入了非法或不正確的引數時丟擲
- 空指標異常(NullPointerException):當在需要物件的情況下使用了 null 時丟擲。
- 下標存取越界異常(IndexOutOfBoundsException):當某種索引(例如陣列,字串或向量)的索引超出範圍時丟擲。
- 型別轉換異常(ClassCastException):當嘗試將物件轉換為不是範例的子類時丟擲。
- 運算異常(ArithmeticException):運算條件出現異常時丟擲。例如,「除以零」的整數。
Java 異常類的結構
如何處理常式丟擲的異常
在函數丟擲異常的時候,我們該怎麼處理呢?是吞掉還是向上丟擲?
如果選擇向上丟擲,我們應該選擇丟擲哪種型別的異常呢?是受檢異常還是非受檢異常?
下面我們就對此介紹。
吞掉 or 丟擲
在函數丟擲異常的時候,我們該怎麼處理?是吞掉還是向上丟擲?
總結一下,在函數丟擲異常的時候,一般有下面三種處理方法。
- 直接吞掉
- 原封不動地 re-throw
- 包裝成新的異常 re-throw
直接吞掉。具體的程式碼範例如下所示:
public void func1() throws Exception1 {
// ...
}
public void func2() {
//...
try {
func1();
} catch (Exception1 e) {
//吐掉:try-catch列印紀錄檔
log.warn("...", e);
}
//...
}
原封不動地 re-throw。具體的程式碼範例如下所示:
public void func1() throws Exception1 {
// ...
}
//原封不動的re-throw Exception1
public void func2() throws Exception1 {
//...
func1();
//...
}
包裝成新的異常 re-throw。具體的程式碼範例如下所示:
public void func1() throws Exception1 {
// ...
}
public void func2() throws Exception2 {
//...
try {
func1();
} catch (Exception1 e) {
// wrap成新的Exception2然後re-throw
throw new Exception2("...", e);
}
//...
}
當我們面對函數丟擲異常的時候,應該選擇上面的哪種處理方式呢?我總結了下面三個參考原則:
- 如果 func1() 丟擲的異常是可以恢復,且 func2() 的呼叫方並不關心此異常,我們完全可以在 func2() 內將 func1() 丟擲的異常吞掉;
- 如果 func1() 丟擲的異常對 func2() 的呼叫方來說,也是可以理解的、關心的 ,並且在業務概念上有一定的相關性,我們可以選擇直接將 func1 丟擲的異常 re-throw;
- 如果 func1() 丟擲的異常太底層,對 func2() 的呼叫方來說,缺乏背景去理解、且業務概念上無關,我們可以將它重新包裝成呼叫方可以理解的新異常,然後 re-throw。
應該選擇上面的哪種處理方式,總結來說就是從以下兩個方面進行判斷:
- 函數1 丟擲的異常是否可以恢復
- 函數1 丟擲的異常對於 函數2 的呼叫方來說是否可以理解、關心、業務概念相關
總之,是否往上繼續丟擲,要看上層程式碼是否關心這個異常。關心就將它丟擲,否則就直接吞掉。
是否需要包裝成新的異常丟擲,看上層程式碼是否能理解這個異常、是否業務相關。如果能理解、業務相關就可以直接丟擲,否則就封裝成新的異常丟擲。
對於處理常式丟擲的異常,我們需要注意:
- 如果選擇吞掉函數丟擲的異常的話,我們必須把異常輸出到紀錄檔系統,方便後續診斷。
- 如果把異常輸出到紀錄檔系統時,我們在保證診斷資訊足夠的同時,也要考慮避免包含敏感資訊,因為那樣可能導致潛在的安全問題。
如果我們看 Java 的標準類庫,你可能注意到類似 java.net.ConnectException,出錯資訊是類似「 Connection refused (Connection refused)」,而不包含具體的機器名、IP、埠等,一個重要考量就是資訊保安。
類似的情況在紀錄檔中也有,比如,使用者資料一般是不可以輸出到紀錄檔裡面的。
受檢異常 or 非受檢異常
在函數丟擲異常的時候,如果選擇向上丟擲,我們應該選擇丟擲哪種型別的異常呢?是受檢異常還是非受檢異常?
對於程式碼 bug(比如下標存取越界、空指標)以及不可恢復的異常(比如資料庫連線失敗),即便我們捕獲了,也做不了太多事情,我們希望程式能 fail-fast,所以,我們傾向於使用非受檢異常,將程式終止掉。
對於可恢復異常、業務異常,比如提現金額大於餘額的異常,我們更傾向於使用受檢異常,明確告知呼叫者需要捕獲處理。
處理異常的原則
儘量不要捕獲通用異常
儘量不要捕獲類似 Exception 這樣的通用異常,而應該捕獲特定異常(儘量縮小捕獲的異常範圍)。
下面舉例說明,範例程式碼如下:
try {
// 業務程式碼
// …
Thread.sleep(1000L);
} catch (Exception e) {
// Ignore it
}
對於 Thread.sleep() 函數丟擲的 InterruptedException,我們不應該捕獲 Exception 通用異常,而應該捕獲 InterruptedException 這樣的特定異常。
這是因為我們要保證程式不會捕獲到我們不希望捕獲的異常。比如,我們更希望 RuntimeException 導致執行緒終止,而不是被捕獲。
不要生吞異常
不要生吞(swallow)異常,儘量把異常資訊記錄到紀錄檔系統中。
這是例外處理中要特別注意的事情,因為生吞異常很可能會導致難以診斷的詭異情況。
如果我們沒有把異常丟擲,也沒有把異常記錄到紀錄檔系統,程式可能會在後續出現難以排查的 bug。沒人能夠輕易判斷究竟是哪裡丟擲了異常,以及是什麼原因產生了異常。
再來看一段程式碼
try {
// 業務程式碼
// …
} catch (IOException e) {
e.printStackTrace();
}
這段程式碼作為一段實驗程式碼,是沒有任何問題的,但是在產品程式碼中,通常都不允許這樣處理。
你先思考一下這是為什麼呢?
我們先來看看 printStackTrace() 的檔案,開頭就是「Prints this throwable and its backtrace to the standard error stream」。問題就在這裡,在稍微複雜一點的生產系統中,標準出錯(STERR)不是個合適的輸出選項,因為你很難判到底輸出到哪裡去了。尤其是對於分散式系統,如果發生異常,但是無法找到堆疊軌跡(stacktrace),這純屬是為診斷設定障礙。
所以,最好使用產品紀錄檔,詳細地將異常記錄到紀錄檔系統裡。
例外處理時,效能開銷大的地方
我們從效能角度來審視一下 Java 的例外處理機制,這裡有兩個效能開銷相對大的地方:
- try-catch 程式碼段會產生額外的效能開銷,或者換個角度說,它往往會影響 JVM 對程式碼進行優化,所以建議僅捕獲有必要的程式碼段,儘量不要一個大的 try 包住整段的程式碼;
- Java 每範例化一個 Exception,都會對當時的棧進行快照,這是一個相對比較重的操作。如果範例化 Exception 發生的非常頻繁,這個開銷可就不能被忽略了。
當我們的服務出現反應變慢、吞吐量下降的時候,檢查發生最頻繁的 Exception 也是一種思路。
參考文章
本文來自部落格園,作者:真正的飛魚,轉載請註明原文連結:https://www.cnblogs.com/feiyu2/p/exception.html