面試官:你確定 Redis 是單執行緒的程序嗎?
作者:小林coding
計算機八股文網站:https://xiaolincoding.com
大家好,我是小林。
這次主要分享 Redis 執行緒模型篇的面試題。
- Redis 是單執行緒嗎?
- Redis 單執行緒模式是怎樣的?
- Redis 採用單執行緒為什麼還這麼快?
- Redis 6.0 之前為什麼使用單執行緒?
- Redis 6.0 之後為什麼引入了多執行緒?
Redis 是單執行緒嗎?
Redis 單執行緒指的是「接收使用者端請求->解析請求 ->進行資料讀寫等操作->發生資料給使用者端」這個過程是由一個執行緒(主執行緒)來完成的,這也是我們常說 Redis 是單執行緒的原因。
但是,Redis 程式並不是單執行緒的,Redis 在啟動的時候,是會啟動後臺執行緒(BIO)的:
- Redis 在 2.6 版本,會啟動 2 個後臺執行緒,分別處理關閉檔案、AOF 刷盤這兩個任務;
- Redis 在 4.0 版本之後,新增了一個新的後臺執行緒,用來非同步釋放 Redis 記憶體,也就是 lazyfree 執行緒。例如執行 unlink key / flushdb async / flushall async 等命令,會把這些刪除操作交給後臺執行緒來執行,好處是不會導致 Redis 主執行緒卡頓。因此,當我們要刪除一個大 key 的時候,不要使用 del 命令刪除,因為 del 是在主執行緒處理的,這樣會導致 Redis 主執行緒卡頓,因此我們應該使用 unlink 命令來非同步刪除大key。
之所以 Redis 為「關閉檔案、AOF 刷盤、釋放記憶體」這些任務建立單獨的執行緒來處理,是因為這些任務的操作都是很耗時的,如果把這些任務都放在主執行緒來處理,那麼 Redis 主執行緒就很容易發生阻塞,這樣就無法處理後續的請求了。
後臺執行緒相當於一個消費者,生產者把耗時任務丟到任務佇列中,消費者(BIO)不停輪詢這個佇列,拿出任務就去執行對應的方法即可。
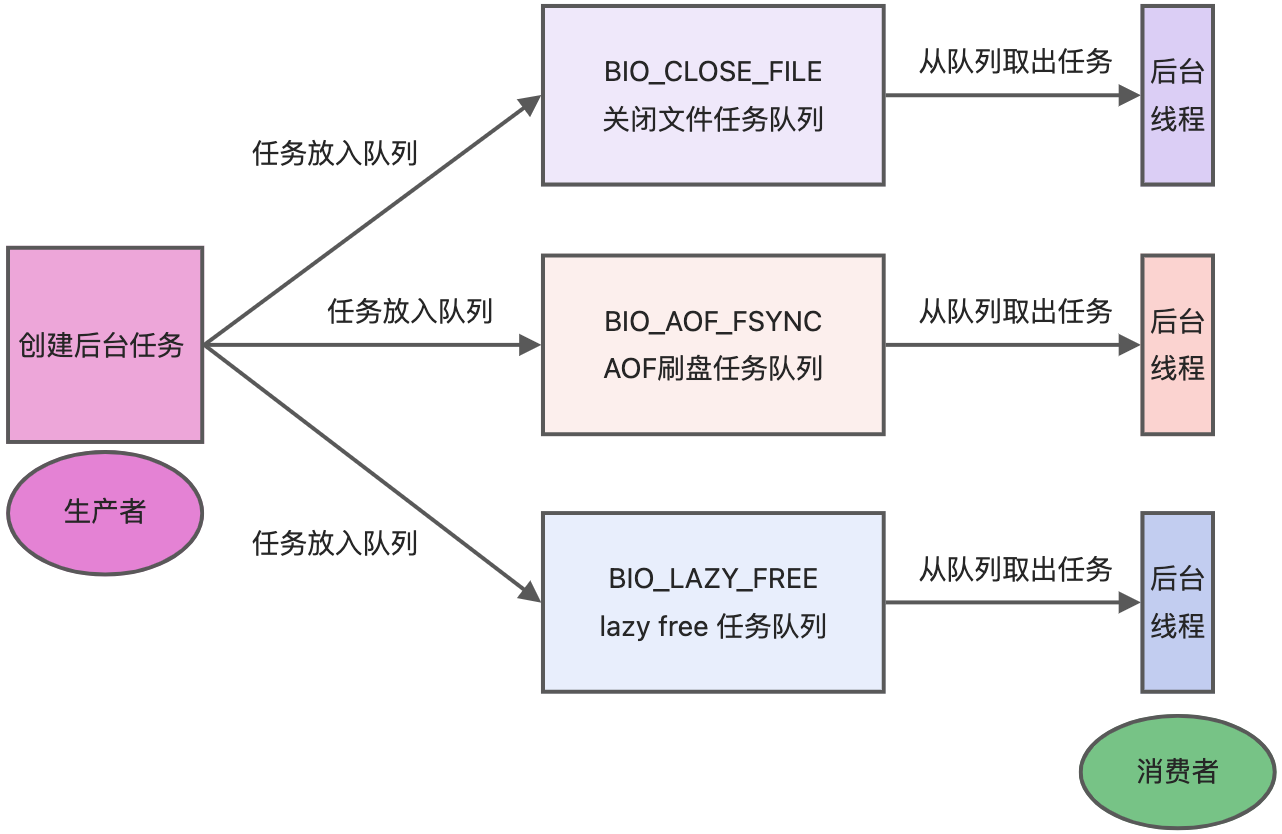
關閉檔案、AOF 刷盤、釋放記憶體這三個任務都有各自的任務佇列:
- BIO_CLOSE_FILE,關閉檔案任務佇列:當佇列有任務後,後臺執行緒會呼叫 close(fd) ,將檔案關閉;
- BIO_AOF_FSYNC,AOF刷盤任務佇列:當 AOF 紀錄檔設定成 everysec 選項後,主執行緒會把 AOF 寫紀錄檔操作封裝成一個任務,也放到佇列中。當發現佇列有任務後,後臺執行緒會呼叫 fsync(fd),將 AOF 檔案刷盤,
- BIO_LAZY_FREE,lazy free 任務佇列:當佇列有任務後,後臺執行緒會 free(obj) 釋放物件 / free(dict) 刪除資料庫所有物件 / free(skiplist) 釋放跳錶物件;
Redis 單執行緒模式是怎樣的?
Redis 6.0 版本之前的單線模式如下圖:
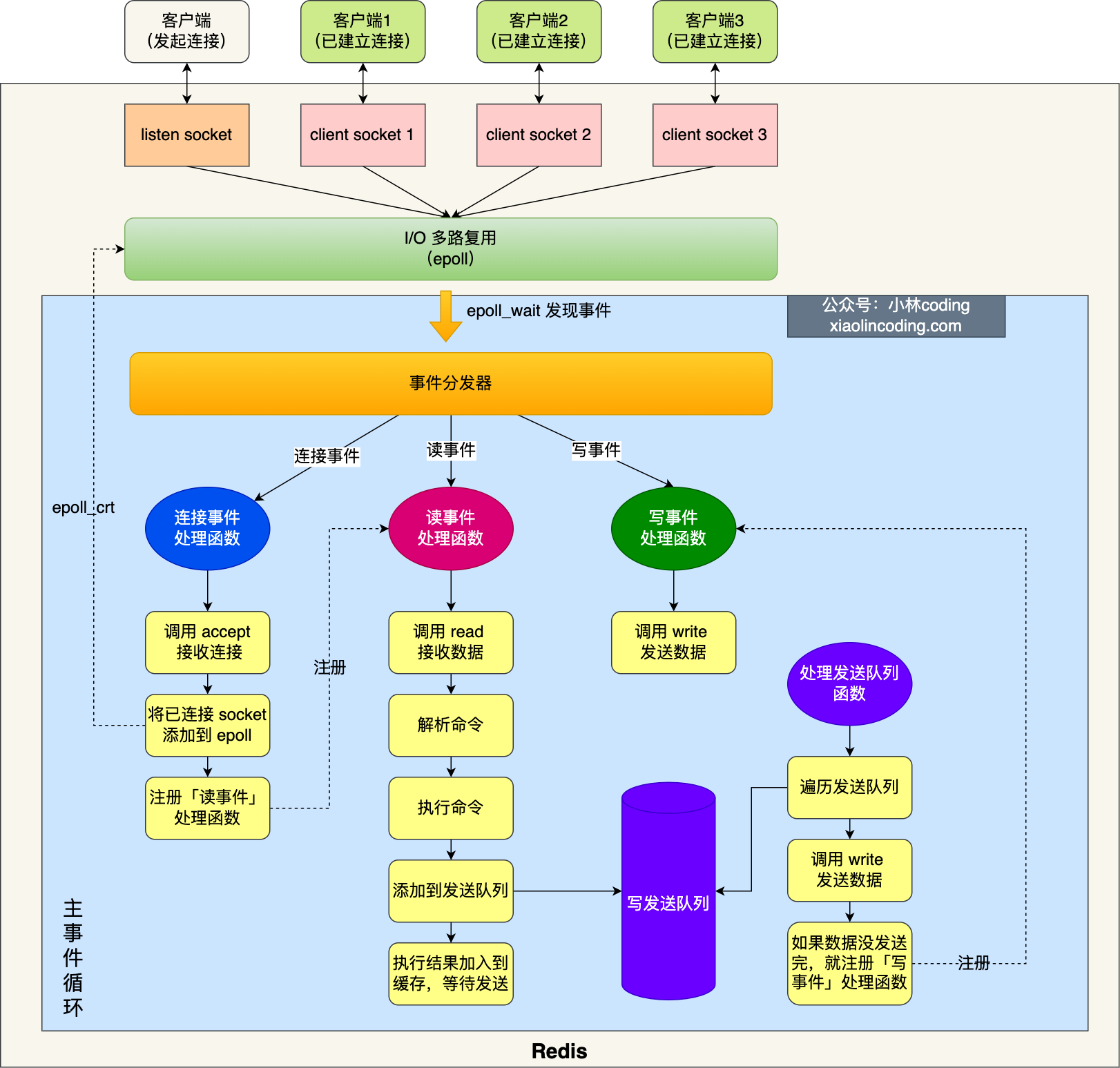
圖中的藍色部分是一個事件迴圈,是由主執行緒負責的,可以看到網路 I/O 和命令處理都是單執行緒。 Redis 初始化的時候,會做下面這幾年事情:
- 首先,呼叫 epoll_create() 建立一個 epoll 物件和呼叫 socket() 一個伺服器端 socket
- 然後,呼叫 bind() 繫結埠和呼叫 listen() 監聽該 socket;
- 然後,將呼叫 epoll_crt() 將 listen socket 加入到 epoll,同時註冊「連線事件」處理常式。
初始化完後,主執行緒就進入到一個事件迴圈函數,主要會做以下事情:
- 首先,先呼叫處理傳送佇列函數,看是傳送佇列裡是否有任務,如果有傳送任務,則通過 write 函數將使用者端傳送快取區裡的資料傳送出去,如果這一輪資料沒有發生完,就會註冊寫事件處理常式,等待 epoll_wait 發現可寫後再處理 。
- 接著,呼叫 epoll_wait 函數等待事件的到來:
- 如果是連線事件到來,則會呼叫連線事件處理常式,該函數會做這些事情:呼叫 accpet 獲取已連線的 socket -> 呼叫 epoll_ctr 將已連線的 socket 加入到 epoll -> 註冊「讀事件」處理常式;
- 如果是讀事件到來,則會呼叫讀事件處理常式,該函數會做這些事情:呼叫 read 獲取使用者端傳送的資料 -> 解析命令 -> 處理命令 -> 將使用者端物件新增到傳送佇列 -> 將執行結果寫到傳送快取區等待傳送;
- 如果是寫事件到來,則會呼叫寫事件處理常式,該函數會做這些事情:通過 write 函數將使用者端傳送快取區裡的資料傳送出去,如果這一輪資料沒有發生完,就會繼續註冊寫事件處理常式,等待 epoll_wait 發現可寫後再處理 。
以上就是 Redis 單線模式的工作方式,如果你想看原始碼解析,可以參考這一篇:為什麼單執行緒的 Redis 如何做到每秒數萬 QPS ?
Redis 採用單執行緒為什麼還這麼快?
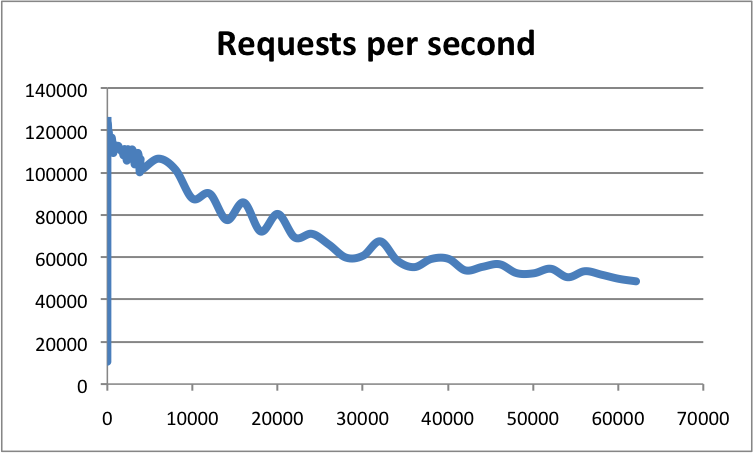
官方使用基準測試的結果是,單執行緒的 Redis 吞吐量可以達到 10W/每秒,如下圖所示:
之所以 Redis 採用單執行緒(網路 I/O 和執行命令)那麼快,有如下幾個原因:
- Redis 的大部分操作都在記憶體中完成,並且採用了高效的資料結構,因此 Redis 瓶頸可能是機器的記憶體或者網路頻寬,而並非 CPU,既然 CPU 不是瓶頸,那麼自然就採用單執行緒的解決方案了;
- Redis 採用單執行緒模型可以避免了多執行緒之間的競爭,省去了多執行緒切換帶來的時間和效能上的開銷,而且也不會導致死鎖問題。
- Redis 採用了 I/O 多路複用機制處理大量的使用者端 Socket 請求,IO 多路複用機制是指一個執行緒處理多個 IO 流,就是我們經常聽到的 select/epoll 機制。簡單來說,在 Redis 只執行單執行緒的情況下,該機制允許核心中,同時存在多個監聽 Socket 和已連線 Socket。核心會一直監聽這些 Socket 上的連線請求或資料請求。一旦有請求到達,就會交給 Redis 執行緒處理,這就實現了一個 Redis 執行緒處理多個 IO 流的效果。
Redis 6.0 之前為什麼使用單執行緒?
我們都知道單執行緒的程式是無法利用伺服器的多核 CPU 的,那麼早期 Redis 版本的主要工作(網路 I/O 和執行命令)為什麼還要使用單執行緒呢?我們不妨先看一下Redis官方給出的FAQ。

核心意思是:CPU 並不是制約 Redis 效能表現的瓶頸所在,更多情況下是受到記憶體大小和網路I/O的限制,所以 Redis 核心網路模型使用單執行緒並沒有什麼問題,如果你想要使用服務的多核CPU,可以在一臺伺服器上啟動多個節點或者採用分片叢集的方式。
除了上面的官方回答,選擇單執行緒的原因也有下面的考慮。
使用了單執行緒後,可維護性高,多執行緒模型雖然在某些方面表現優異,但是它卻引入了程式執行順序的不確定性,帶來了並行讀寫的一系列問題,增加了系統複雜度、同時可能存線上程切換、甚至加鎖解鎖、死鎖造成的效能損耗。
Redis 6.0 之後為什麼引入了多執行緒?
雖然 Redis 的主要工作(網路 I/O 和執行命令)一直是單執行緒模型,但是在 Redis 6.0 版本之後,也採用了多個 I/O 執行緒來處理網路請求,這是因為隨著網路硬體的效能提升,Redis 的效能瓶頸有時會出現在網路 I/O 的處理上。
所以為了提高網路請求處理的並行度,Redis 6.0 對於網路請求採用多執行緒來處理。但是對於讀寫命令,Redis 仍然使用單執行緒來處理,所以大家不要誤解 Redis 有多執行緒同時執行命令。
Redis 官方表示,Redis 6.0 版本引入的多執行緒 I/O 特性對效能提升至少是一倍以上。
Redis 6.0 版本支援的 I/O 多執行緒特性,預設是 I/O 多執行緒只處理寫操作(write client socket),並不會以多執行緒的方式處理讀操作(read client socket)。要想開啟多執行緒處理使用者端讀請求,就需要把 Redis.conf 組態檔中的 io-threads-do-reads 設定項設為 yes。
//讀請求也使用io多執行緒
io-threads-do-reads yes
同時, Redis.conf 組態檔中提供了 IO 多執行緒個數的設定項。
// io-threads N,表示啟用 N-1 個 I/O 多執行緒(主執行緒也算一個 I/O 執行緒)
io-threads 4
關於執行緒數的設定,官方的建議是如果為 4 核的 CPU,建議執行緒數設定為 2 或 3,如果為 8 核 CPU 建議執行緒數設定為 6,執行緒數一定要小於機器核數,執行緒數並不是越大越好。 因此, Redis 6.0 版本之後,Redis 在啟動的時候,預設情況下會有 6 個執行緒:
- Redis-server : Redis的主執行緒,主要負責執行命令;
- bio_close_file、bio_aof_fsync、bio_lazy_free:三個後臺執行緒,分別非同步處理關閉檔案任務、AOF刷盤任務、釋放記憶體任務;
- io_thd_1、io_thd_2、io_thd_3:三個 I/O 執行緒,io-threads 預設是 4 ,所以會啟動 3(4-1)個 I/O 多執行緒,用來分擔 Redis 網路 I/O 的壓力。
系列《圖解Redis》文章:
面試篇:
資料型別篇:
持久化篇:
功能篇:
高可用篇:
快取篇: