【系統設計】分散式鍵值資料庫
鍵值儲存 ( key-value store ),也稱為 K/V 儲存或鍵值資料庫,這是一種非關係型資料庫。每個值都有一個唯一的 key 關聯,也就是我們常說的 鍵值對。
常見的鍵值儲存有 Redis, Amazon DynamoDB,Microsoft Azure Cosmos DB,Memcached,etcd 等。
你可以在 DB-Engines 網站上看到鍵值儲存的排行。

設計要求

在這個面試的系統設計環節中,我們需要設計一個鍵值儲存, 要滿足下面的幾個要求
- 每個鍵值的資料小於 10kB。
- 有儲存巨量資料的能力。
- 高可用,高擴充套件性,低延遲。
單機版 - 鍵值儲存
對於單個伺服器來說,開發一個鍵值儲存相對來說會比較簡單,一種簡單的做法是,把鍵值都儲存在記憶體中的雜湊表中,這樣查詢速度非常快。但是,由於記憶體的限制,把所有的資料放到記憶體中明顯是行不通的。
所以,對於熱點資料(經常存取的資料)可以載入到記憶體中,而其他的資料可以儲存在磁碟。但是,當資料量比較大時,單個伺服器仍然會很快達到容量瓶頸。
分散式 - 鍵值儲存
分散式鍵值儲存也叫分散式雜湊表,把鍵值分佈在多臺伺服器上。在設計分散式系統時,理解 CAP(一致性,可用性,分割區容錯性) 定理很重要。
CAP 定理
CAP 定理指出,在分散式系統中,不可能同時滿足一致性、可用性和分割區容錯性。讓我們認識一下這三個定義:
- 一致性: 無論連線到哪一個節點,所有的使用者端在同一時間都會看到相同的資料。
- 可用性:可用性意味著任何請求資料的使用者端都會得到響應,即使某些節點因故障下線。
- 分割區容錯性:分割區表示兩個節點之間的網路通訊中斷。分割區容錯性意味著,當存在網路分割區時,系統仍然可以繼續執行。

通常可以用 CAP 的兩個特性對鍵值儲存進行分類:
CP(一致性和分割區容錯性)系統:犧牲可用性的同時支援一致性和分割區容錯。
AP(可用性和分割區容錯性)系統:犧牲一致性的同時支援可用性和分割區容錯。
CA(一致性和可用性)系統:犧牲分割區容錯性的同時支援一致性和可用性。
由於網路故障是不可避免的,所以在分散式系統中,必須容忍網路分割區。
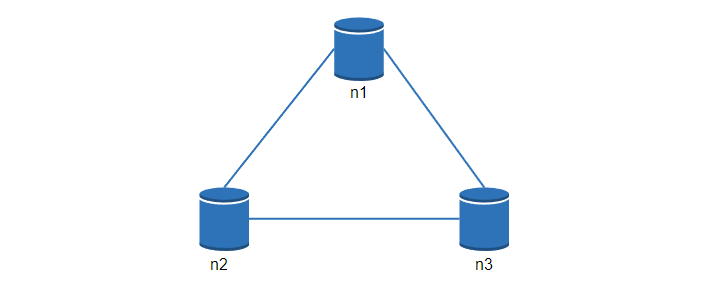
讓我們看一些具體的例子,在分散式系統中,為了保證高可用,資料通常會在多個系統中進行復制。假設資料在三個節點 n1, n2, n3 進行復制,如下:
理想情況
在理想的情況下,網路分割區永遠不會發生。寫入 n1 的資料會自動複製到 n2 和 n3,實現了一致性和可用性。
現實世界的分散式系統
在分散式系統中,網路分割區是無法避免的,當發生分割區時,我們必須在一致性和可用性之間做出選擇。
在下圖中,n3 出現了故障,無法和 n1 和 n2 通訊,如果使用者端把資料寫入 n1 或 n2,就沒辦法複製到 n3,就會出現資料不一致的情況。
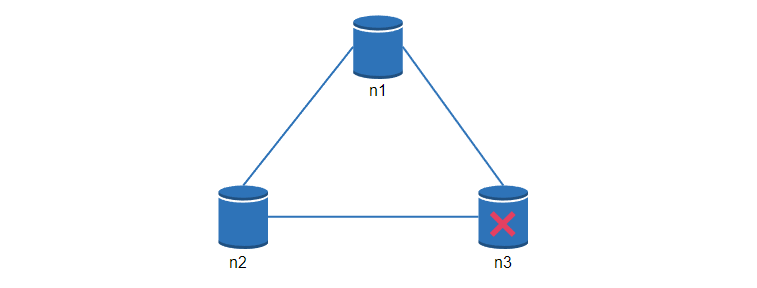
如果我們選擇一致性優先(CP系統),當 n3 故障時, 就必須阻止所有對 n1 和 n2 的寫操作,避免三個節點之間的資料不一致。涉及到錢的系統通常有極高的一致性要求。
如果我們選擇可用性優先(AP系統),當 n3 故障時,系統仍然可以正常的寫入讀取,但是可能會返回舊的資料,當網路分割區恢復後,資料再同步到 n3 節點。
選擇合適的 CAP 是構建分散式鍵值儲存的重要一環。
核心元件和技術
接下來,我們會討論構建鍵值儲存的核心元件和技術:
- 資料分割區
- 資料複製
- 一致性
- 不一致時的解決方案
- 故障處理
- 系統架構圖
- 資料寫入和讀取流程
資料分割區
在資料量比較大場景中,把資料都存放在單個伺服器明顯是不可行的,我們可以進行資料分割區,然後儲存到多個伺服器中。
需要考慮到的是,多個伺服器之間的資料應該是均勻分佈的,在新增或者刪除節點時,需要移動的資料應該儘量少。
一致性雜湊非常適合在這個場景中使用,下面的例子中,8臺伺服器被對映到雜湊環上,然後我們把鍵值的 key 也通過雜湊演演算法對映到環上,然後找到順時針方向遇到的第一個伺服器,並進行資料儲存。

使用一致性雜湊,在新增和刪除節點時,只需要移動很少的一部分資料。
資料複製
為了實現高可用性和可靠性,一條資料在某個節點寫入後,會複製到其他的節點,也就是我們常說的多副本。
那麼問題來了,如果我們有 8 個節點,一條資料需要在每個節點上都儲存嗎?
並不是,副本數和節點數沒有直接關係。副本數應該是一個可設定的引數,假如副本數為 3,同樣可以藉助一致性雜湊環,按照順時針找到 3 個節點,並進行儲存,如下

一致性
因為鍵值資料在多個節點上覆制,所以我們必須要考慮到資料一致性問題。
Quorum 共識演演算法可以保證讀寫操作的一致性,我們先看一下 Quorum 演演算法中 NWR 的定義。
N = 副本數, 也叫複製因子,在分散式系統中,表示同一條資料有多少個副本。
W = 寫一致性級別,表示一個寫入操作,需要等待幾個節點的寫入後才算成功。
R = 讀一致性級別,表示讀取一個資料時,需要同時讀取幾個副本數,然後取最新的資料。
如下圖,N = 3
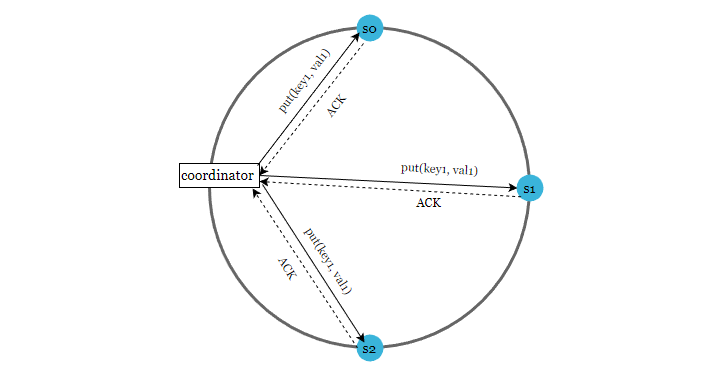
注意,W = 1 並不意味著資料只寫到一個節點,控制寫入幾個節點的是 N 副本數。
N = 3 表示,一條資料會寫入到 3 個節點,W = 1 表示,只要收到任何節點的第一個寫入成功確認訊息(ACK)後,就直接返回寫入成功。
這裡的重點是,對 N、W、R的值進行不同的組合時,會產生不同的一致性效果。
- 當 W + R > N 的時候,通常是 N = 3, W = R = 2,對於使用者端來講,整個系統能保證強一致性,一定能返回更新後的那份資料。
- 當 W + R <= N 的時候,對於使用者端來講,整個系統只能保證最終一致性,所以可能會返回舊資料。
通過 Quorum NWR,可以調節系統一致性的程度。
一致性模型
一致性模型是設計鍵值儲存要考慮的另外一個重要因素,一致性模型定義了資料一致性的程度。
- 強一致性: 任何一個讀取操作都會返回一個最新的資料。
- 弱一致性: 資料更新之後,讀操作可能會返回最新的值,也有可能會返回更新前的值。
- 最終一致性: 這是弱一致性的另外一種形式。可能當前節點的值是不一致的,但是等待一段時間的資料同步之後,所有節點的值最終會保持一致。
強一致性的通常做法是,當有副本節點因為故障下線時,其他的副本會強制中止寫入操作。一致性程度比較高,但是犧牲了系統的高可用。
而 Dynamo 和 Cassandra 都採用了最終一致性,這也是鍵值儲存推薦使用的一致性模型,當資料不一致時,使用者端讀取多個副本的資料,進行協調並返回資料。
不一致的解決方案:版本控制
多副本資料複製提供了高可用性,但是多副本可能會存在資料不一致的問題。
版本控制和向量時鐘(vector clock )是一個很好的解決方案。向量時鐘是一組 [server,version] 資料,它通過版本來檢查資料是否發生衝突。
假設向量時鐘由 D([S1, v1], [S2, v2], ..., [Sn, vn]) 表示,其中 D 是資料項,v1 是版本計數器,下面是一個例子
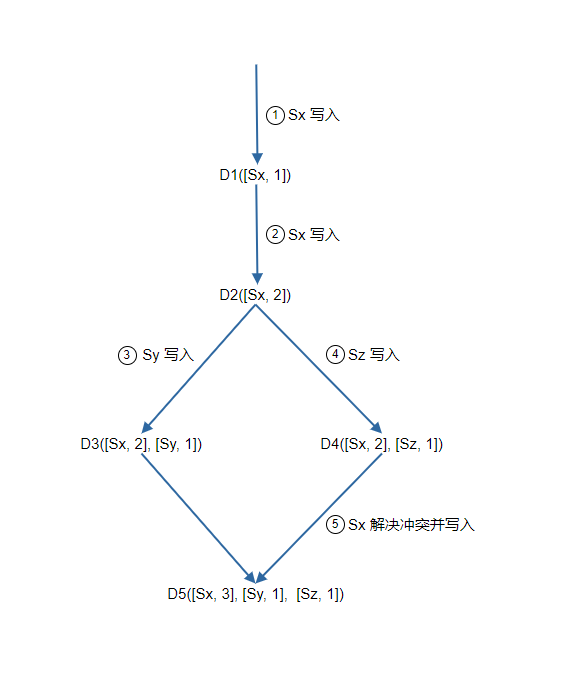
- 使用者端把資料 D1 寫入系統,寫入操作由 Sx 處理,伺服器 Sx 現在有向量時鐘 D1[(Sx, 1)]。
- 使用者端把 D2 寫入系統,假如這次還是由 Sx 處理,則版本號累加,現在的向量時鐘是 D2([Sx, 2])。
- 使用者端讀取 D2 並更新成 D3,假如這次的寫入由 Sy 處理, 現在的向量時鐘是D3([Sx, 2], [Sy, 1]))。
- 使用者端讀取 D2 並更新成 D4,假如這次的寫入由 Sz 處理,現在的向量時鐘是 D4([Sx, 2], [Sz, 1]))。
- 使用者端讀取到 D3 和 D4,檢查向量時鐘後發現衝突(因為不能判斷出兩個向量時鐘的順序關係),使用者端自己處理解決衝突,然後再次寫入。假如寫入是 Sx 處理,現在的向量時鐘是 D5([Sx, 3], [Sy, 1], [Sz, 1])。
注意,向量時鐘只能檢測到衝突,如何解決,那就需要使用者端讀取多個副本值自己處理了。
故障處理
在分散式大型系統中,發生故障是很常見的,接下來,我會介紹常見的故障處理方案。
故障檢測
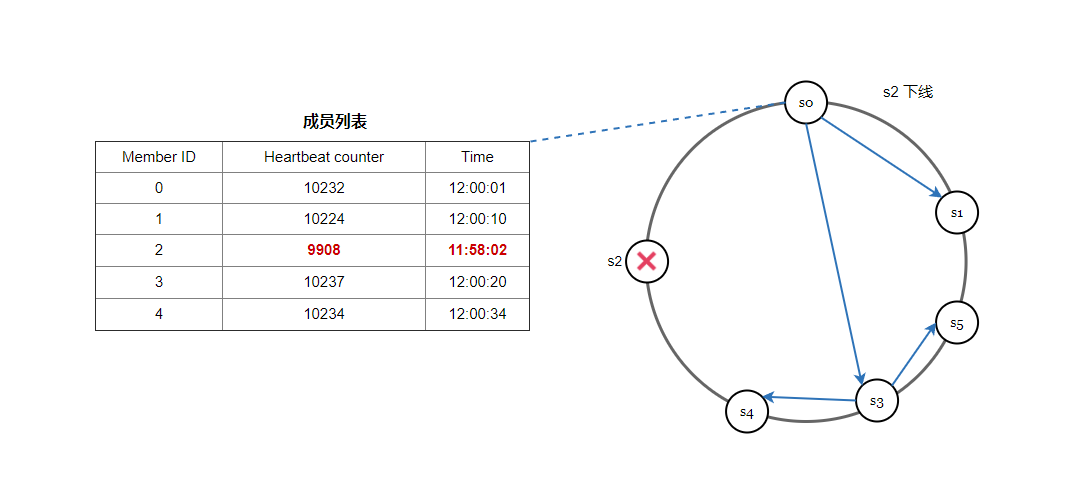
一種很常見的方案是使用 Gossip 協定,我們看一下它的工作原理:
- 每個節點維護一個節點成員列表,其中包含成員 ID 和心跳計數器。
- 每個節點週期性地增加它的心跳計數器。
- 每個節點週期性地向一組隨機節點傳送心跳,這些節點依次傳播到另一組節點。
- 一旦節點收到心跳,成員列表就會更新為最新資訊。
- 如果在定義的週期內,發現心跳計數器的值比較小,則認為該成員離線。
處理臨時故障
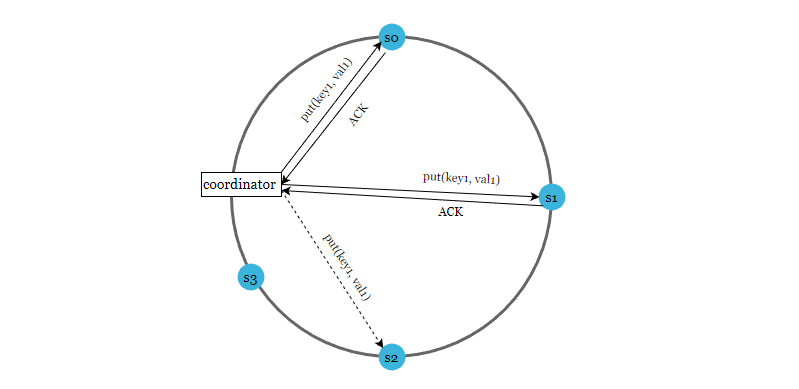
通過 gossip 協定檢測到故障後,為了保證資料一致性,嚴格的 Quorum 演演算法會阻止寫入操作。而 sloppy quorum 可以在臨時故障的情況下,保證系統的可用性。
當網路或者伺服器故障導致服務不可用時,會找一個臨時的節點進行資料寫入,當宕機的節點再次啟動後,寫入操作會更新到這個節點上,保持資料一致性。
如下圖所示,當 s2 不可用時,寫入操作暫時由 s3 處理, 在一致性雜湊環上順時針查詢到下一個節點就是s3,當 s2 重新上線時,s3 會把資料還給 s2。
處理長時間故障
資料會在多個節點進行資料複製,假如節點發生故障下線,並且在一段時間後恢復,那麼,節點之間的資料如何同步? 全量對比?明顯是低效的。我們需要一種高效的方法進行資料對比和驗證。
使用 Merkle 樹是一個很好的解決方案,Merkle 樹也叫做雜湊樹,這是一種樹結構,最下面的葉節點包含資料或雜湊值,每個中間節點是它的子節點內容的雜湊值,根節點也是由它的子節點內容的雜湊值組成。
下面的過程,展示了 Merkle 樹是如何構建的。
第 1 步,把鍵值的儲存空間劃分為多個桶,一個桶可以存放一定數量的鍵值。

第 2 步,建立桶之後,使用雜湊演演算法計算每個鍵的雜湊值。

第 3 步,根據桶裡面的鍵的雜湊值,計算桶的雜湊值。

第 4 步,計運算元節點的雜湊值,並向上構建樹,直到根節點結束。
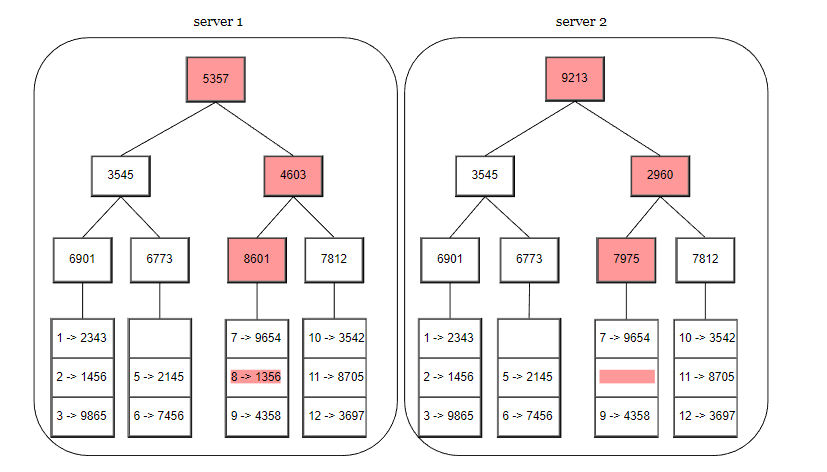
如果要比較兩個 Merkle 樹,首先要比較根雜湊,如果根雜湊一致,表示兩個節點有相同的資料。如果根雜湊不一致,就遍歷匹配子節點,這樣可以快速找到不一致的資料,並進行資料同步。
系統架構圖
我們已經討論了設計鍵值儲存要考慮到的技術問題,現在讓我們關注一下整體的架構圖,如下
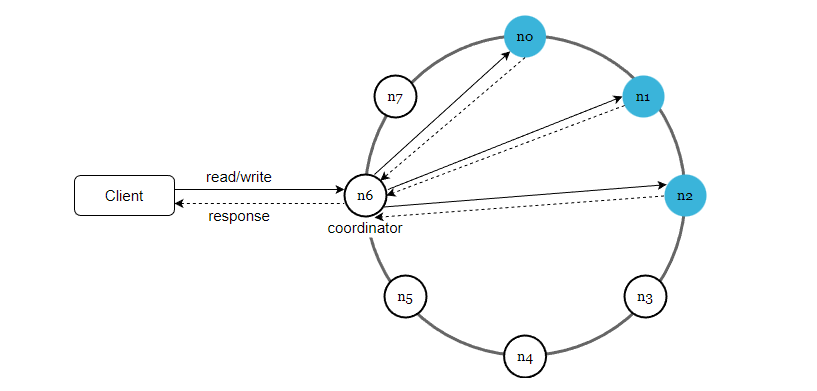
這個架構主要有下面幾個特點:
- 使用者端通過簡單的 API 和鍵值儲存進行通訊,get (key) 和 put (key, value)。
- coordinator 協調器充當了使用者端和鍵值儲存之間的代理節點。
- 所有節點對映到了一致性雜湊環上。
- 資料在多個節點上進行復制。
寫入流程
下圖展示了資料寫入到儲存節點的過程,主要基於 Cassandra 的架構設計。

- 寫入請求首先被持久化在提交紀錄檔檔案中。
- 然後資料儲存在記憶體快取中。
- 當記憶體已滿或者達到閾值時,資料移動到本地磁碟的 SSTable,這是一種高階資料結構,感興趣的讀者自行查閱資料瞭解。
讀取流程
在進行資料讀取時,它首先檢查資料是否在記憶體快取中,如果是,就把資料返回給使用者端,如下圖所示:

如果資料不在記憶體中,就會從磁碟中檢索。我們需要一種高效的方法,找到資料在哪個 SSSTable 中,通常可以使用布隆過濾器來解決這個問題。

- 系統首先檢查資料是否在記憶體快取中。
- 如果記憶體中沒有資料,系統會檢查布隆過濾器。
- 布隆過濾器可以快速找出哪些 SSTables 可能包含金鑰。
- SSTables 返回資料集的結果。
- 結果返回給使用者端。
Reference
[0] System Design Interview Volume 2:
https://www.amazon.com/System-Design-Interview-Insiders-Guide/dp/1736049119
[1] Amazon DynamoDB: https://aws.amazon.com/dynamodb/
[2] memcached: https://memcached.org/
[3] Redis: https://redis.io/
[4] Dynamo: Amazon’s Highly Available Key-value Store:
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[5] Cassandra: https://cassandra.apache.org/
[6] Bigtable: A Distributed Storage System for Structured Data:
https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
[7] Merkle tree: https://en.wikipedia.org/wiki/Merkle_tree
[8] Cassandra architecture: https://cassandra.apache.org/doc/latest/architecture/
[9] SStable: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
[10] Bloom filter https://en.wikipedia.org/wiki/Bloom_filter