Kafka Topic Partition Offset 這一長串都是啥?
摘要:Offset 偏移量,是針對於單個partition存在的概念。
本文分享自華為雲社群《Kafka Topic Partition Offset 這一長串都是啥?》,作者: gentle_zhou。
Kafka,作為一款分散式訊息釋出和訂閱系統,被廣泛應用於巨量資料傳輸場景;因為其高吞吐量、內建分割區、冗餘及容錯性的特點,可謂是一個很好的大規模訊息處理應用的解決方案(行為追蹤,紀錄檔收集)。
基本架構組成
Kafka裡幾有如下大基本要素:
- Producer:訊息生產者,向Kafka cluster內的Broker傳送訊息;位於使用者端內
- Kafka cluster:包含了1個或多個broker的叢集
- broker:訊息中介軟體處理節點,一個broker就是一個Kafka節點,一個broker裡會有1個或多個Topic
- Topic:主題,Kafka根據topic對訊息進行歸類;釋出到Kafka叢集的每條訊息都需要指定一個topic
- ZooKeeper cluster:一個分散式服務協調框架,管理和協調整個Kafka 叢集
- Consumer:訊息消費者,向Kafka cluster內的Broker那讀取訊息;位於使用者端內;每個Consumer屬於一個特定的Consumer Group
- Consumer Group:訊息消費者組,多個不同的Consumer Group可以消費同一個訊息,但是同一個Consumer Group中的不同Consumer不能消費同一個訊息
以上幾個元素它們之間是如何協調運作的呢? Producer會將訊息通過push 模式釋出到到Kafka Clustr內的broker,consumer則通過監聽把訊息通過pull 模式從 broker 那訂閱並消費。 而zookeeper則用來管理和協調整個Kafka 叢集。
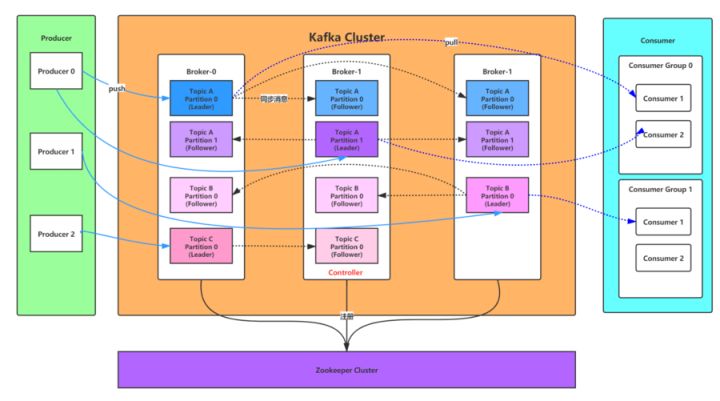
好,解釋了這些基本、表面的概念,我們回到標題這一長串,「Kafka Topic Partition Offset」。Topic作為一個訊息的邏輯概念,同類的訊息會被存到同一個topic下;每個 topic 可以有多個生產者向它傳送訊息,也可以有多個消費者去消費其中的訊息。那麼為何topic下會有1個或則多個partition呢?
Partition
Partition 分割區,在一個 topic 內,可以劃分為1個或多個分割區。
它其實是一個有序的訊息佇列,訊息會按照按順序被新增到一個叫做commit log的檔案中;一個commit log檔案就對應一個partition。同一個topic下不同分割區包含的訊息是不同的。
下圖中的p0,p1,p2就是3個分割區:

Offset
Offset 偏移量,是針對於單個partition存在的概念。partition中的訊息不止一個,根據進來的順序,都會分配到一個唯一的編號即offset,用來標示某個分割區中的唯一的message。
比如上圖中p0分割區裡的0,1就是兩條訊息,p1分割區裡的0,1,2就是三條訊息。offset的順序不跨分割區,這個順序只保證在同一個分割區內的訊息是有序的,不同的分割區內訊息的offset可能是相同的。
對於消費者來說,每次消費了分割區內一個訊息並且提交以後,就會儲存當前消費了的最近的一個 offset記錄,就不會再去消費已經消費過了的訊息了。
為何要搞分割區呢?
- 如果以訊息紀錄檔檔案的形式來儲存,那麼就會受到所在機器的檔案系統大小的限制;Topic 分割區之後,理論上一個topic可以處理任意數量的訊息資料
- 提高並行度,針對巨量資料場景,kafka應用了分散式儲存的思想,把Topic劃分為很多個Partition,不同的分割區還可以存在不同的叢集機器節點上
參考連結
- https://kafka.apache.org/intro
- https://www.huaweicloud.com/product/dms.html
- https://blog.51cto.com/u_15281317/3007837