論文閱讀 TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS
14 TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS
Abstract
提出了時間圖網路(TGNs),一個通用的,有效的框架,在動態圖上的深度學習表示為時序事件序列。由於記憶模組和基於圖的操作的新穎組合,TGN在計算效率更高的同時,顯著優於以前的方法。
Conclusion
本文介紹了連續時間動態圖學習的通用框架TGN。我們在多個任務和資料集上獲得了最先進的結果,同時比以前的方法更快。
詳細的消融研究表明,記憶及其相關模組對儲存長期資訊的重要性,以及基於圖的嵌入模組對生成最新節點嵌入的重要性。
Figure and table
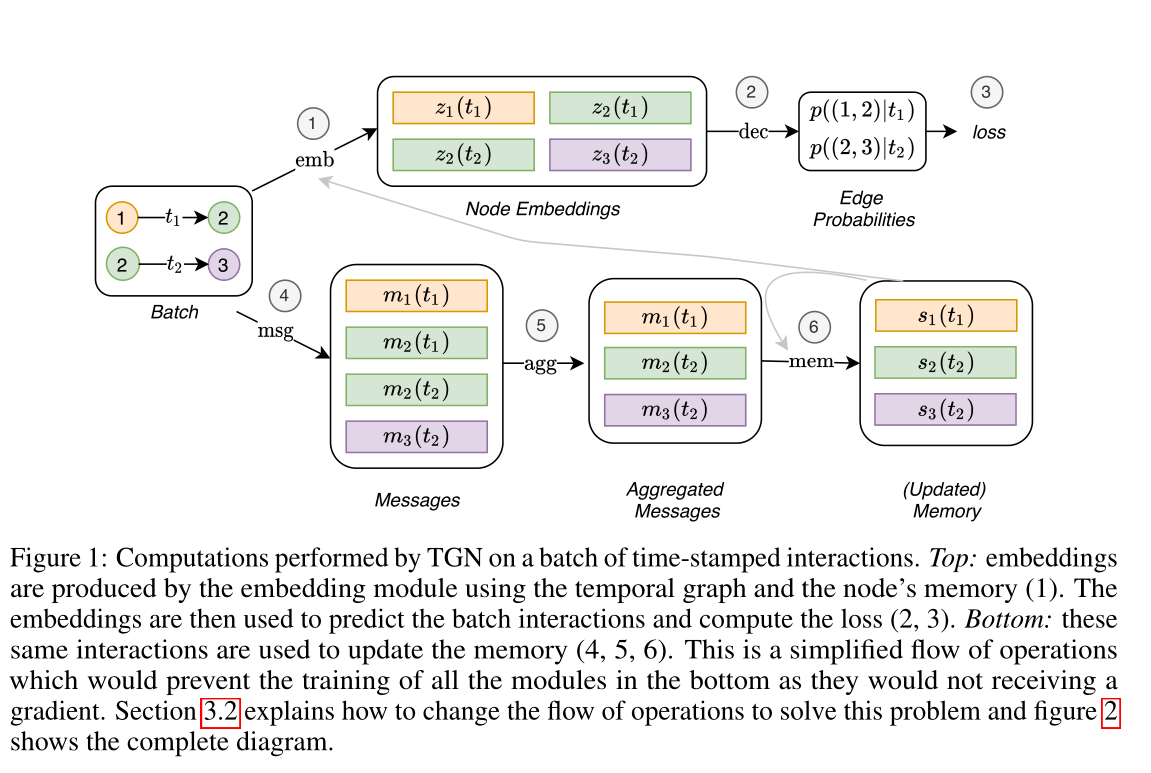
圖1 由TGN對一批帶時間戳的互動進行的計算。上方:嵌入由嵌入模組使用時間圖和節點的記憶(1)產生。然後,嵌入用於預測批次互動和計算損失(2,3)。下方:這些相同的互動用於更新記憶體(4,5,6)。這是一個簡化的操作流程,將防止下方所有模組的訓練,因為它們不會接收到梯度。第3.2節解釋瞭如何更改操作流程以解決此問題,圖2顯示了完整的關係圖。
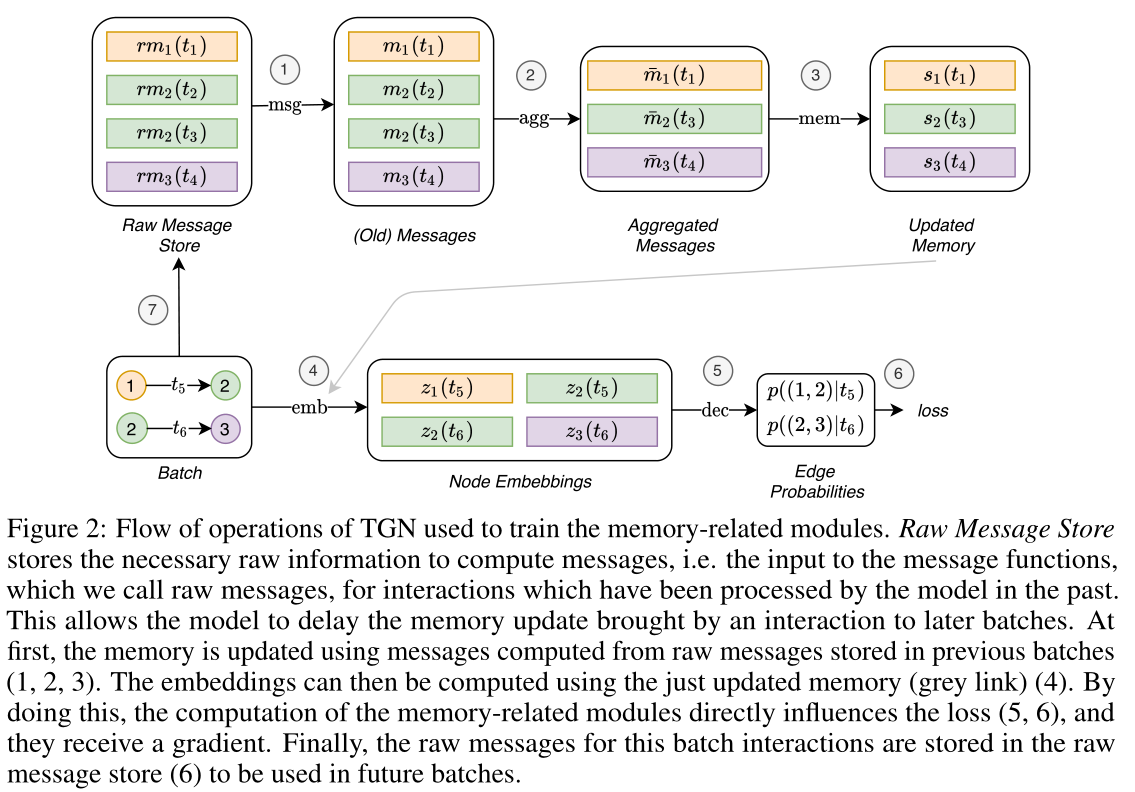
圖2:TGN用於訓練記憶相關模組的操作流程。原始訊息儲存(Raw Message Store)儲存計算訊息所需的原始資訊,即訊息函數的輸入,我們稱之為原始訊息,用於模型過去處理過的互動。
這允許模型將互動帶來的記憶更新延遲到以後的批次處理中。首先,使用從前幾批(1,2,3)中儲存的原始訊息計算出來的訊息更新記憶體。然後,可以使用剛剛更新的記憶(灰色箭頭)計算嵌入(4)。通過這樣做,記憶相關模組的計算直接影響損失(5,6)。最後,用於此批次處理互動的原始訊息儲存在原始訊息儲存(7)中,以便在未來的批次處理中使用。

表1 以往的連續時間動態圖深度學習模型都是TGN框架的具體案例。圖中顯示的是消融研究中使用的多種TGN變體。method(l,n)是指使用l層和n個鄰居的圖折積。\(†\)使用t-batch。\(∗\)使用鄰居的均勻抽樣,而預設是抽樣最近的鄰居。\(‡\)表示本文中沒有解釋訊息聚合。\(||\)表示使用目標節點鄰域的求和(通過圖注意力獲得)作為訊息函數的附加輸入。
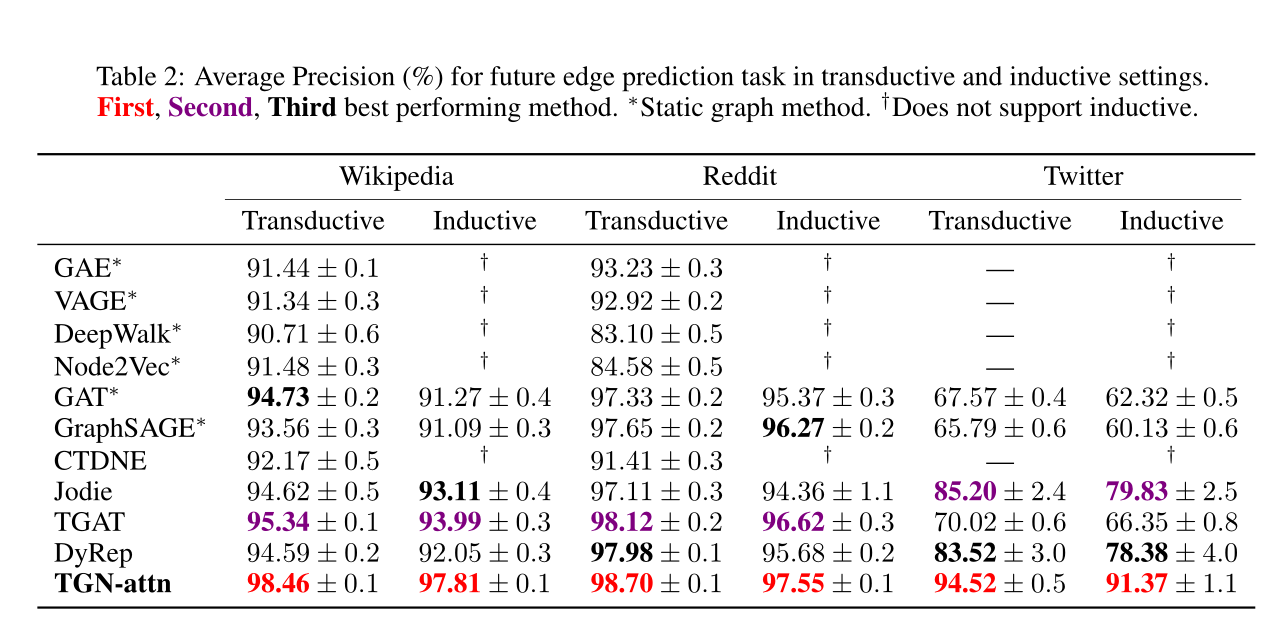
表2:在transductive和inductive設定下,未來邊緣預測任務的平均精度(%)。∗表示靜態圖的方法。†表示不支援歸納。
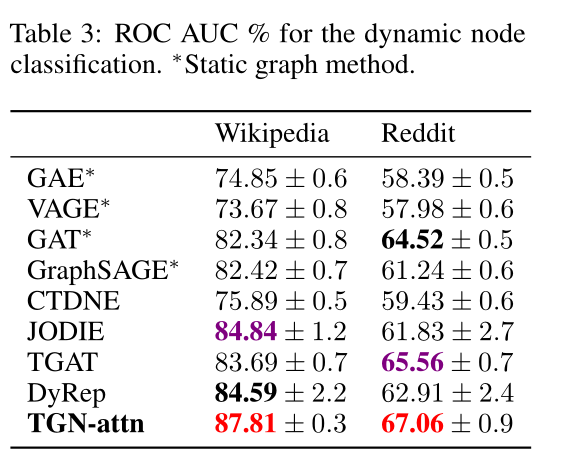
表3 動態節點分類的ROC AUC %。∗表示靜態圖的方法。

圖3 以transductive方式在維基百科資料集上的消融實驗,用於未來邊緣預測任務。計算平均值和標準差超過10次。
(a)不同模型的精度(以%為單位的測試平均精度)和速度(以秒為單位的epoch時間)之間的權衡。
(b)隨著鄰居數量的增加,不同層數、有無記憶的方法的效能。最後統一採用鄰居抽樣策略。
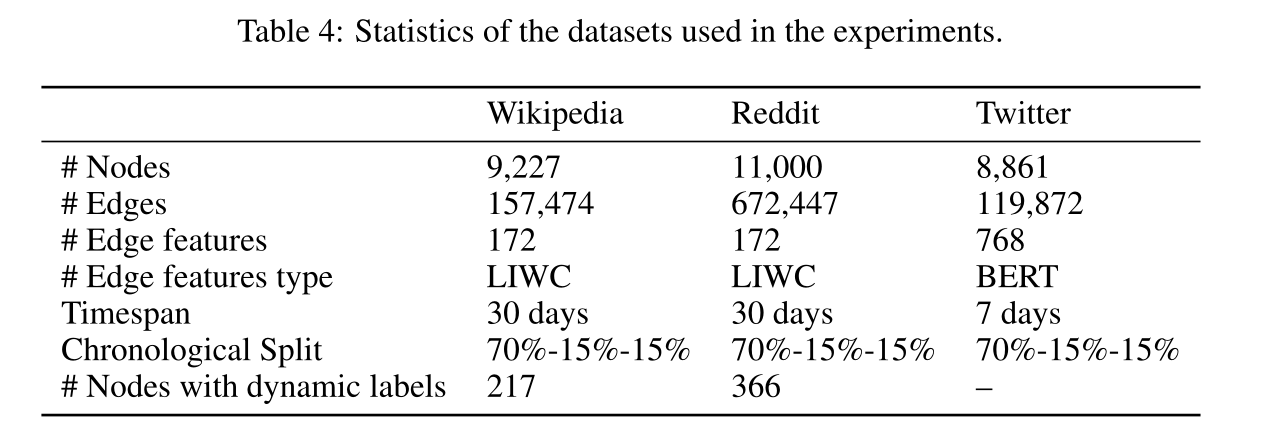
表4 實驗資料集的引數。
Introduction
在圖上進行深度學習的大多數方法都假設底層圖是靜態的。然而,現實生活中的大多數互動系統,如社會網路或生物互動體,都是動態的。
貢獻:在本文中提出了時間圖網路(tgn)的通用歸納框架,該框架作用於以事件序列表示的連續時間動態圖,並表明以前的許多方法都是tgn的具體範例。其次,提出了一種新的訓練策略,允許模型從資料的順序中學習,同時保持高效的並行處理。第三,我們對我們的框架的不同組成部分進行了詳細的消融實驗,並分析了速度和精度之間的權衡。
Method
2 BACKGROUND
靜態圖的深度學習:一個靜態圖\(\mathcal{G = (V, E)}\)由節點\(\mathcal{V} =\{ 1,…, n \}\)和邊\(\mathcal{E⊆V × V}\)構成,它們被賦予特徵,分別用\(\mathbf{V}_i\)和\(\mathbf{e}_{ij}\)表示,其中\(i,j=1,...,n\)。典型的圖神經網路(GNN)通過學習一種形式的區域性聚合規則來建立節點的嵌入\(\mathbf{z}_{i}\)
它被解釋為從鄰居\(j\)傳遞到節點\(i\)的訊息,此處\(n_i=\{ j:(i,j) \in \mathcal{E} \}\)表示節點\(i\)和MSG(訊息)的鄰居,\(h\)為可學習函數。
動態圖:動態圖主要有兩種模型。離散時間動態圖(DTDG)是在一定時間間隔內拍攝的靜態圖快照序列。連續時間動態圖(CTDG)更為通用,可以表示為事件的時間列表,包括邊的新增或刪除、節點的新增或刪除以及節點或邊緣特徵轉換。
本文的時間圖被建模為時間戳事件序列\(\mathcal{G} = \{ x(t_1), x(t_2),…\}\),表示一個節點的新增或更改,或一對節點在時間\(0≤t1≤t2≤...\)時的互動。事件\(x(t)\)可以有兩種型別:
1)節點事件由\(\mathbf{v}_i(t)\)表示,其中\(i\)表示節點的索引,\(\mathbf{v}\)是與事件相關的向量屬性。如果索引\(i\)以前沒有出現過,事件建立節點\(i\)(帶有給定的特徵),否則它更新特徵。
2)節點\(i\)和\(j\)之間的互動事件用一個(有向的)時間邊\(\mathbf{e}_{ij}(t)\)表示(在一對節點之間可能有不止一條邊,所以技術上這是一個多重圖)。
分別通過\(\mathcal{V}(T)=\left\{i: \exists \mathbf{v}_{i}(t) \in \mathcal{G}, t \in T\right\}\)和\(\mathcal{E}(T)=\left\{(i, j): \exists \mathbf{e}_{i j}(t) \in \mathscr{\mathcal { G }}, t \in T\right\}\)來表示頂點和邊的時間集合,通過\(n_{i}(T)=\{j:(i, j) \in \mathcal{E}(T)\}\)表示節點\(i\)在時間間隔\(T\)中的鄰居。\(n^k_i(T)\)表示k跳鄰居。時間圖\(\mathcal{G}\)在\(t\)時刻的快照是具有\(n(t)\)個節點的多重圖\(\mathcal{G}(t) = (\mathcal{V}[0, t], \mathcal{E}[0, t])\)。刪除事件在附錄A.1中進行了討論。
3 TEMPORAL GRAPH NETWORKS
根據(Representation learning for dynamic graphs: A survey)中的觀點,動態圖的神經模型可以被視為編碼器-解碼器對,其中編碼器是一個函數,從動態圖對映到節點嵌入,解碼器將一個或多個節點嵌入作為輸入,並進行特定於任務的預測,如節點分類或連結預測。本文的主要貢獻是一種新穎的時間圖網路(TGN)編碼器,它應用於一個連續時間動態圖,表示為一個時間戳事件序列,並在每個時間t時,得到圖節點嵌入\(\mathbf{Z}(t)=(\mathbf{z}_1(t),...,\mathbf{z}_{n(t)}(t))\)。
3.1 CORE MODULES
記憶模組:時間\(t\)時模型的記憶(狀態)由向量\(\mathbf{s}_i(t)\)組成,用於模型到目前為止觀察到的每個節點\(i\)。一個節點的記憶在事件發生後更新(例如與另一個節點互動或節點發生變化),它的目的是用壓縮格式表示該節點的歷史。由於這個特定的模組,tgn能夠記住圖中每個節點的長期依賴關係。當遇到一個新節點時,它的記憶體將被初始化為零向量,然後為涉及該節點的每個事件更新它,即使在模型完成訓練之後,記憶模組依舊保持更新。
還可以在模型中新增全域性(圖級別)記憶,以跟蹤整個網路的演化,本文將此作為未來的工作。
訊息函數:對於涉及節點\(i\)的每個事件,都會計算一條訊息來更新\(i\)的記憶。當源節點\(i\)和目標節點\(j\)在時間\(t\)發生互動事件\(\mathbf{e}_{ij}(t)\)時,可以計算兩條訊息:
類似地,對於節點級事件\(\mathbf{v}_i(t)\),可以為涉及事件的節點計算單個訊息:
其中\(\mathbf{s}_{i}(t^{-})\)是節點\(i\)在時間\(t\)之前的記憶(即從之前涉及\(i\)的互動開始的時間)
\(\operatorname{msg}_{\mathrm{s}},\operatorname{msg}_{\mathrm{d}},\operatorname{msg}_{\mathrm{n}}\)是可學的訊息函數,例如MLP。在所有的實驗中,為了簡單起見,我們選擇訊息函數作為標識(id),它只是輸入的連線。該框架還支援刪除事件,在附錄A.1中有介紹。
訊息聚合器:由於效率原因而採用批次處理可能會導致在同一批次處理中涉及同一節點\(i\)的多個事件。在本文的公式中,每個事件都會生成一條訊息,我們使用一種機制來聚合訊息:\(\mathbf{m}_{i}(t_1),...,\mathbf{m}_{i}(t_b)\),其中$ t_1,...,t_B≤t$
這裡,agg是一個聚合函數。雖然實現此模組可以考慮多種選擇(例如rnn或attention),但為了簡單起見,我們在實驗中考慮了兩種有效的不可學習(即無法BP)解決方案:最新訊息(只保留給定節點的最新訊息)和平均訊息(對給定節點的所有訊息進行平均)。我們將可學習聚合作為未來的研究方向。
記憶更新:如前所述,每個涉及節點自身的事件都會更新節點的記憶:
對於涉及兩個節點\(i\)和\(j\)的互動事件,在事件發生後更新兩個節點的記憶。對於節點級事件,只更新相關節點的記憶(不對鄰居做更新操作)。在這裡,mem是一個可學習的記憶更新函數,例如一個RNN,如LSTM 或GRU 。
嵌入:嵌入模組用於生成節點\(i\)在任意時刻\(t\)的時間嵌入\(\mathbf{z}_{i}\)。嵌入模組的主要目標是避免所謂的記憶陳舊問題(Kazemi et al., 2020)。由於節點\(i\)的記憶體只在該節點參與某個事件時才會更新,因此,在長時間沒有事件發生的情況下(例如,社群網路使用者在再次活躍之前停止使用該平臺一段時間),\(i\)的記憶體就會變得陳舊。雖然嵌入模組可以有多種實現,但本文使用的形式是:
其中\(h\)為可學習函數。嵌入函數包括許多不同的公式作為特殊情況,如下:
標誌Identity (id):\(emb(i, t) = \mathbf{s}_{i}(t)\),它直接使用記憶作為節點嵌入。
事件Time projection (time):\(\operatorname{emb}(i, t)=(1+\Delta t \mathbf{w}) \circ \mathbf{s}_{i}(t)\),其中\(\mathbf{w}\)是可學習的引數,\(∆t\)是自上次互動以來的時間,\(◦\)表示元素向量乘積。Jodie採用了這種嵌入方法。投影
時間圖注意Temporal Graph Attention (attn):一系列的\(L\)層圖注意層通過聚合\(L\)跳時間鄰居的資訊來計算\(i\)的嵌入。
在第L層,該方法的輸入為節點\(i\)的表示\(\mathbf{h}_i^{(l-1)}(t)\),當前事件戳\(t\),帶時間戳\(t_1,...,t_N\)的節點\(i\)鄰居表示\(\{ \mathbf{h}_1^{(l-1)}(t),...,\mathbf{h}_N^{(l-1)}(t) \}\)和特徵\(\mathbf{e}_{i1}(t_1),...,\mathbf{e}_{iN}(t_N)\),對於在\(i\)的時間鄰居中形成邊的每一個考慮的相互作用
其中
\(\phi(·)\)表示一種通用時間編碼
\(||\)是連線操作符
\(\mathbf{z}_{i}(t)=\operatorname{emb}(i, t)=\mathbf{h}_i^{(L)}(t)\)
每一層相當於執行多頭注意,其中query\((\mathbf{q}^{(l)}(t))\)是一個參考節點(即目標節點或其\(l−1\)跳鄰居之一),key\((\mathbf{k}^{(l)}(t))\)和value\((\mathbf{V}^{(l)}(t))\)是它的鄰居。最後,利用MLP將參考節點表示與聚合資訊結合起來。與該層的原始公式不同,其中沒有使用節點的時間特徵,在本文的情況下,每個節點的輸入表示\(\mathbf{h}^{(0) }_j(t) = \mathbf{s}_{i}(t) +\mathbf{v}_{i}(t)\),因此它允許模型同時利用當前記憶體\(\mathbf{s}_{i}(t)\)和時間節點特徵\(\mathbf{v}_{i}(t)\)。
時間圖求和Temporal Graph Sum (sum):圖上更簡單、更快的聚合:
其中,\(\phi(·)\)還是一種時間編碼
\(\mathbf{z}_{i}(t)=\operatorname{emb}(i, t)=\mathbf{h}_i^{(L)}(t)\)
在實驗中,本文對時間圖注意和時間圖和模組都使用了Time2Vec和TGAT中提出的時間編碼。
圖嵌入模組通過聚合來自節點鄰居記憶體的資訊來緩解陳舊的問題。當節點處於非活動狀態一段時間時,他的鄰居在最近可能是活躍的,通過聚集他們的記憶,TGN可以計算節點的最新嵌入。時間圖注意力還能夠根據特徵和時間資訊選擇哪個鄰居更重要。
3.2 TRAINING
TGN可以訓練用於各種任務,如邊緣預測(自我監督)或節點分類(半監督)。以連結預測為例:提供一個時間有序的相互作用列表,目標是根據過去觀察到的相互作用預測未來的相互作用。圖1顯示了TGN對一批訓練資料進行的計算。
訓練策略的複雜性與記憶相關模組(訊息函數、訊息聚合器和記憶更新器)有關,因為它們不會直接影響損失,因此不會接收到梯度。為了解決這個問題,必須在預測批次處理互動之前更新記憶體。然而,在使用模型預測相同的互動作用之前,用互動作用\(\mathbf{e}_{ij}(t)\)更新記憶體會導致資訊洩漏。為了避免這個問題,在處理批次處理時,使用來自前一批(儲存在原始訊息儲存中)的訊息更新記憶體,然後預測互動。圖2顯示了記憶體相關模組的訓練流程。訓練過程的虛擬碼如下。

在圖2中, 在任何時間t,原始訊息儲存包含(最多)一個原始訊息\(rm_i\),用於每個節點\(i\),這是從時間\(t\)之前涉及\(i\)的最後一次互動產生的。當模型處理涉及\(i\)的下一個互動時,它的記憶使用\(rm_i\)更新(圖2中的箭頭1、2、3),然後更新的記憶用於計算節點的嵌入和批次處理損失(箭頭4、5、6)。最後,新互動的原始訊息儲存在原始訊息儲存中(箭頭7)。其中,給定批次處理中的所有預測都可以存取相同的記憶狀態。雖然從批次處理中的第一個互動的角度來看,記憶是最新的(因為它包含了圖中所有之前互動的資訊),但從批次處理中的最後一個互動的角度來看,相同的記憶體是過時的,因為它缺乏關於同一批次處理中以前互動的資訊。這就不鼓勵使用大的批次處理大小(在批次處理大小與資料集一樣大的極端情況下,所有的預測都將使用初始的零記憶體)。作者發現批次大小為200可以很好地平衡速度和更新粒度。
Experiment
Datasets:Wikipedia、Reddit和Twitter資料集引數見表4
Baselines:
動態圖
CTDNE ,JODIE,DyRep ,TGAT
靜態圖
GAE ,VGAE ,DeepWalk,Node2Vec,GAT,GraphSAGE
5.1 PERFORMANCE
sota見表2
時間效率見圖3a,
5.2 CHOICE OF MODULES
本節介紹消融實驗,比較了TGN框架的不同範例,重點是速度與精度的權衡,由模組及其組合的選擇產生。表1包含實驗的變體。
此節從四個方面去對比模型變體:記憶,嵌入模組,訊息聚合器,模型層數
具體的效能和時間效率見圖3
Summary
整體方法還是挺簡單的,讀起來沒什麼壓力,以至於感覺讀了沒啥感覺,創新點像作者說的可能就是以前的許多方法都是tgn的具體範例吧。