【百度飛槳】手寫數位識別模型部署Paddle Inference
從完成一個簡單的『手寫數位識別任務』開始,快速瞭解飛槳框架 API 的使用方法。
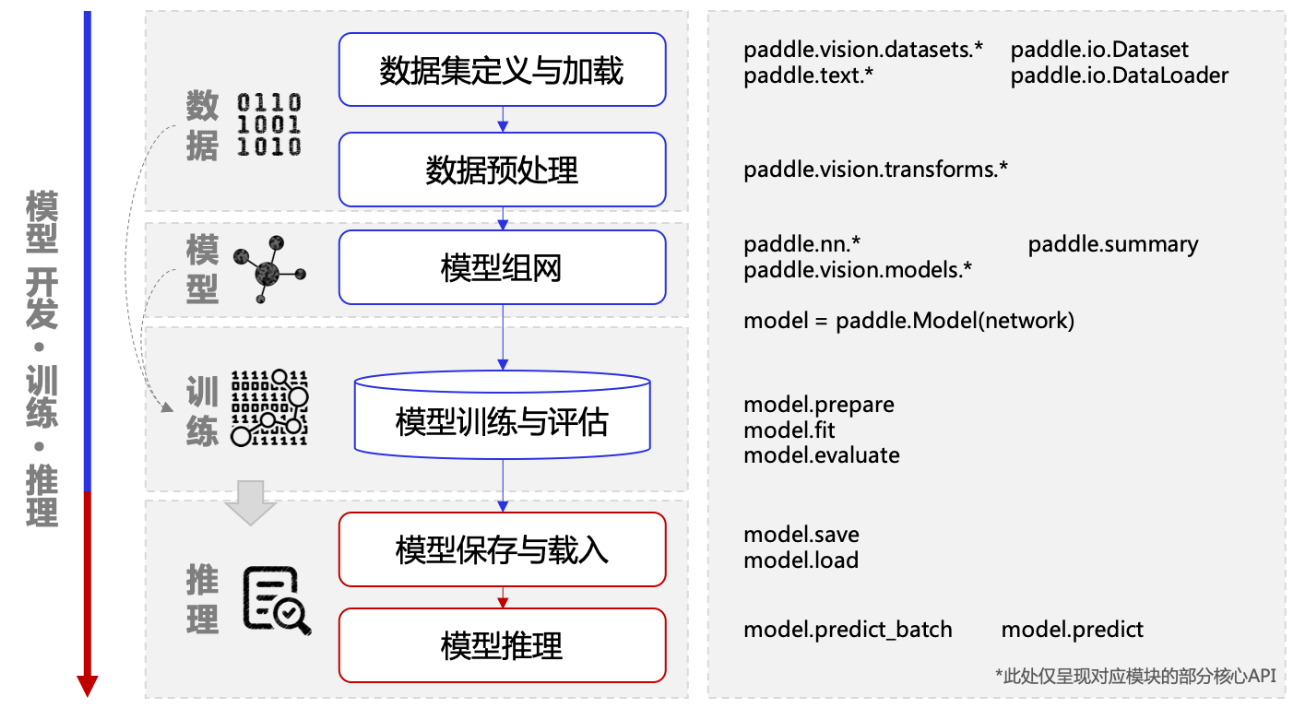
模型開發
『手寫數位識別』是深度學習裡的 Hello World 任務,用於對 0 ~ 9 的十類數位進行分類,即輸入手寫數位的圖片,可識別出這個圖片中的數位。
本任務用到的資料集為 MNIST 手寫數位資料集,用於訓練和測試模型。該資料集包含 60000 張訓練圖片、 10000 張測試圖片、以及對應的分類標籤檔案,每張圖片上是一個 0 ~ 9 的手寫數位,解析度為 28 * 28。
環境設定
直接去飛槳AI Studio首頁建立專案——新增資料集
匯入要用到的包
import paddle import numpy as np import matplotlib.pyplot as plt import cv2 import paddle.vision.transforms as T
載入資料集
飛槳在 paddle.vision.datasets 下內建了計算機視覺(Computer Vision,CV)領域常見的資料集,如 MNIST、Cifar10、Cifar100、FashionMNIST 和 VOC2012 等。在本任務中,先後載入了 MNIST 訓練集(mode='train')和測試集(mode='test'),訓練集用於訓練模型,測試集用於評估模型效果。
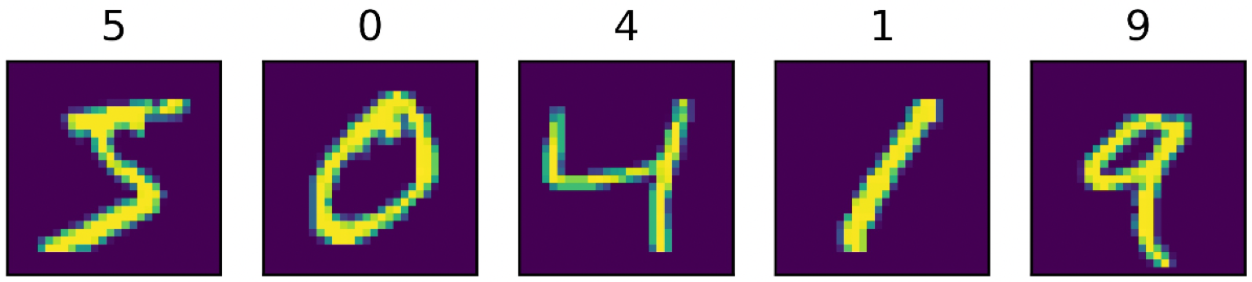
transform = T.Normalize(mean=[127.5], std=[127.5]) train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform) eval_dataset = paddle.vision.datasets.MNIST(mode='test',transform=transform) # 列印資料集裡圖片數量 print('訓練集樣本量:{}, 驗證集樣本量{}'.format(len(train_dataset),len(eval_dataset))) #顯示樣本 cv2.imwrite("C:/1.PNG", train_dataset[0][0]) plt.figure() plt.imshow(train_dataset[0][0].reshape([28,28]),cmap=plt.cm.binary) plt.show()
模型組網
飛槳的模型組網有多種方式,既可以直接使用飛槳內建的模型,也可以自定義組網。『手寫數位識別任務』比較簡單,普通的神經網路就能達到很高的精度。
可以使用飛槳內建的 LeNet 作為模型。飛槳在 paddle.vision.models 下內建了 CV 領域的一些經典模型,LeNet 就是其中之一,呼叫很方便,只需一行程式碼即可完成 LeNet 的網路構建和初始化。num_classes 欄位中定義分類的類別數,因為需要對 0 ~ 9 的十類數位進行分類,所以設定為 10。
# 模型組網並初始化網路 lenet = paddle.vision.models.LeNet(num_classes=10) # 視覺化模型組網結構和引數 paddle.summary(lenet,(1, 1, 28, 28))
--------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # =========================================================================== Conv2D-1 [[1, 1, 28, 28]] [1, 6, 28, 28] 60 ReLU-1 [[1, 6, 28, 28]] [1, 6, 28, 28] 0 MaxPool2D-1 [[1, 6, 28, 28]] [1, 6, 14, 14] 0 Conv2D-2 [[1, 6, 14, 14]] [1, 16, 10, 10] 2,416 ReLU-2 [[1, 16, 10, 10]] [1, 16, 10, 10] 0 MaxPool2D-2 [[1, 16, 10, 10]] [1, 16, 5, 5] 0 Linear-1 [[1, 400]] [1, 120] 48,120 Linear-2 [[1, 120]] [1, 84] 10,164 Linear-3 [[1, 84]] [1, 10] 850 =========================================================================== Total params: 61,610 Trainable params: 61,610 Non-trainable params: 0 --------------------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.11 Params size (MB): 0.24 Estimated Total Size (MB): 0.35 --------------------------------------------------------------------------- {'total_params': 61610, 'trainable_params': 61610}
也可以自己隨便搭建一個:
network = paddle.nn.Sequential(
paddle.nn.Conv2D(1,10,5),
paddle.nn.MaxPool2D(3,2),
paddle.nn.Conv2D(10,20,5),
paddle.nn.MaxPool2D(3,2),
paddle.nn.Flatten(),
paddle.nn.Linear(180,64),
paddle.nn.ReLU(),
paddle.nn.Linear(64,10)
)
model = paddle.Model(network)
model.summary((1,1,28,28)) # 可以搭建一層就看看網路結構
模型訓練
模型訓練需完成如下步驟:
-
使用 paddle.Model 封裝模型。 將網路結構組合成可快速使用 飛槳高層 API 進行訓練、評估、推理的範例,方便後續操作。
-
使用 paddle.Model.prepare 完成訓練的設定準備工作。 包括損失函數、優化器和評價指標等。飛槳在 paddle.optimizer 下提供了優化器演演算法相關 API,在 paddle.nn Loss層 提供了損失函數相關 API,在 paddle.metric 下提供了評價指標相關 API。
-
使用 paddle.Model.fit 設定迴圈引數並啟動訓練。 設定引數包括指定訓練的資料來源
train_dataset、訓練的批大小batch_size、訓練輪數epochs等,執行後將自動完成模型的訓練迴圈。
因為是分類任務,這裡損失函數使用常見的 CrossEntropyLoss (交叉熵損失函數),優化器使用 Adam,評價指標使用 Accuracy 來計算模型在訓練集上的精度。
# 封裝模型,便於進行後續的訓練、評估和推理 model = paddle.Model(lenet) # 模型訓練的設定準備,準備損失函數,優化器和評價指標 model.prepare(paddle.optimizer.Adam(parameters=model.parameters()), paddle.nn.CrossEntropyLoss(), paddle.metric.Accuracy()) # 開始訓練 model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
模型評估、驗證
模型訓練完成之後,呼叫 paddle.Model.evaluate ,使用預先定義的測試資料集,來評估訓練好的模型效果,評估完成後將輸出模型在測試集上的損失函數值 loss 和精度 acc。
result = model.evaluate(eval_dataset,verbose=1) print(result) res = model.predict(eval_dataset,verbose=1) def show_img(img,predict): plt.figure() plt.title("predict:{}".format(predict)) plt.imshow(img.reshape([28,28]),cmap=plt.cm.binary) plt.show() indexs = [1,26,56,111] for idx in indexs: show_img(eval_dataset[idx][0], res[0][idx].argmax())
模型儲存
模型訓練完成後,通常需要將訓練好的模型引數和優化器等資訊,持久化儲存到引數檔案中,便於後續執行推理驗證。
在飛槳中可通過呼叫 paddle.Model.save 儲存模型。程式碼範例如下,其中 output 為模型儲存的資料夾名稱,minst 為儲存的模型檔名稱。
# 儲存模型,資料夾會自動建立 model.save('./output/mnist')
以上程式碼執行後會在output目錄下儲存兩個檔案,mnist.pdopt為優化器的引數,mnist.pdparams為模型的引數。
output ├── mnist.pdopt # 優化器的引數 └── mnist.pdparams # 模型的引數
如果是
model.save('snap/mnist',training=False)
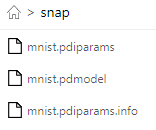
選擇前兩個進行部署
模型部署
環境設定
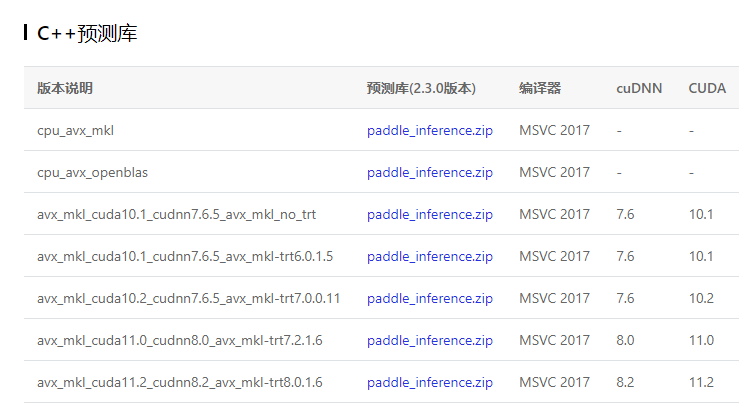
- 下載安裝C++預測庫,
- 下載opencv
- 下載tensorrt的對應版本
- 下載安裝cuda以及cudnn(如果和上面給的版本不一樣,還要自己編譯太麻煩,不如就選10.2)
- 屬性頁設定
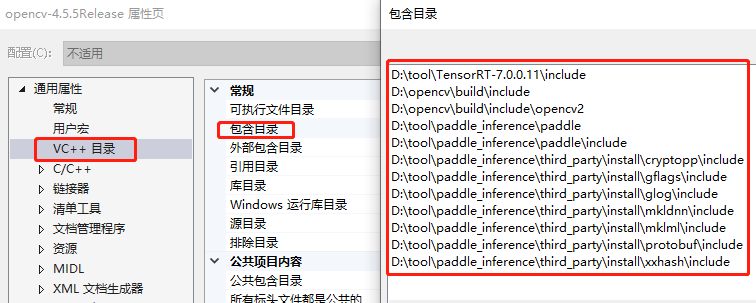
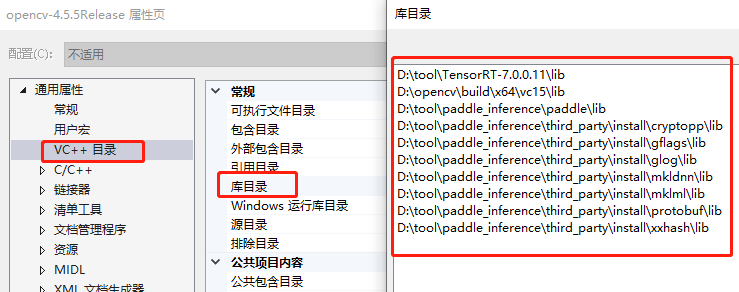
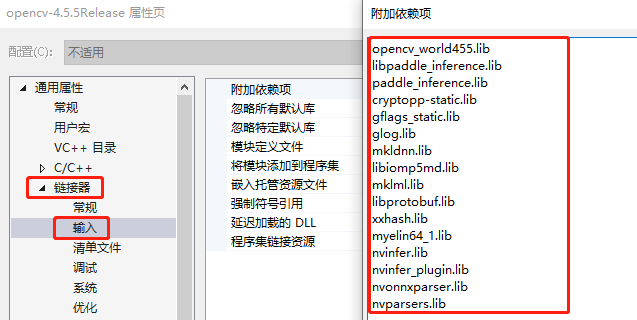
程式碼
"Paddle.h"
#pragma once #include <opencv2/opencv.hpp> #include <paddle_inference_api.h> #include <numeric> using namespace cv; using namespace std; class Paddle { private: paddle_infer::Config config; public: bool loadModel(string& model_dir, string& model_file, string& params_file, int threads); void softmax(const vector<float>& input, vector<float>& result); void preprocess(Mat& src, Mat& dst, float meanValue, float stdValue); void gpuInference(Mat& srcImage, int srcWidth, int srcHeight, int matType, float meanValue, float stdValue, int& labelIndex, double& probability); };
"Paddle.cpp"
#include "Paddle.h" //載入模型 bool Paddle::loadModel(string& model_dir, string& model_file, string& params_file, int threads) { // Config預設是使用CPU預測,可以設定開啟MKLDNN加速、設定CPU的執行緒數、開啟IR優化、開啟記憶體優化。 if (model_dir == "") { config.SetModel(model_file, params_file); // Load combined model } else { config.SetModel(model_dir); // Load no-combined model } config.EnableMKLDNN(); config.EnableUseGpu(1000, 0); //config.SetCpuMathLibraryNumThreads(threads); config.SwitchIrOptim(); config.EnableMemoryOptim(); return true; } void Paddle::softmax(const vector<float>& input, vector<float>& result) { result.clear(); float max = *std::max_element(input.begin(), input.end()); subtract(input, max, result); exp(result, result); float total = sum(result)[0]; divide(result, total, result); } //預處理 void Paddle::preprocess(Mat& src, Mat& dst, float meanValue, float stdValue) { Scalar mean(meanValue); Scalar std(stdValue); src.convertTo(src, CV_32F, 1.0 / 255.0); subtract(src, mean, src); divide(src, std, src); dst = src.clone(); } //單張影象前向傳播 void Paddle::gpuInference(Mat& srcImage, int srcWidth, int srcHeight, int matType, float meanValue, float stdValue, int& labelIndex, double& probability) { clock_t start, end; Mat dstImage(srcWidth, srcHeight,CV_32FC1); //預處理 int buffer_size = srcWidth * srcHeight; preprocess(srcImage, dstImage, meanValue, stdValue); std::vector<float> input_buffer; input_buffer.assign((float*)dstImage.datastart, (float*)dstImage.dataend); input_buffer.resize(buffer_size); // 建立Predictor std::shared_ptr<paddle_infer::Predictor> predictor = paddle_infer::CreatePredictor(config); // 設定輸入 auto input_names = predictor->GetInputNames(); auto input_t = predictor->GetInputHandle(input_names[0]); std::vector<int> input_shape = { 1, 1, srcWidth, srcHeight }; input_t->Reshape(input_shape); input_t->CopyFromCpu(input_buffer.data()); start = clock(); predictor->Run(); end = clock(); // 後處理 auto output_names = predictor->GetOutputNames(); auto output_t = predictor->GetOutputHandle(output_names[0]); std::vector<int> output_shape = output_t->shape(); int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1, std::multiplies<int>()); std::vector<float> out_data; out_data.resize(out_num); output_t->CopyToCpu(out_data.data());
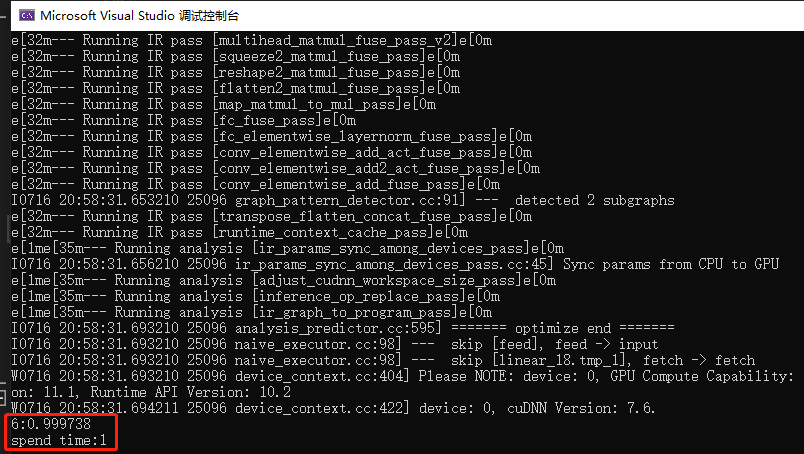
Point maxLoc; double maxValue = 0; vector<float> output; softmax(out_data, output); minMaxLoc(output, 0, &maxValue, 0, &maxLoc); labelIndex = maxLoc.x; probability = maxValue; cout << labelIndex << ":" << probability; double time = end - start; cout << "spend time:" << time << endl; }
呼叫
#include "Paddle.h" int main() { Paddle p; string model_dir = ""; string model_file = "F:/C++Projects/paddle/mnist.pdmodel"; string params_file = "F:/C++Projects/paddle/mnist.pdiparams"; p.loadModel(model_dir, model_file, params_file, 1); Mat src = imread("D:/Backup/桌面/6.png", 0); resize(src, src, Size(28, 28)); bitwise_not(src, src);//變成黑底白字 int labelIndex = 0; double probability = 0.0; p.gpuInference(src, 28, 28, CV_8UC1, 0.5, 0.5, labelIndex, probability); }
結果: