論文閱讀 A Data-Driven Graph Generative Model for Temporal Interaction Networks
13 A Data-Driven Graph Generative Model for Temporal Interaction Networks
Abstract
本文提出了一個名為TagGen的端到端深度生成框架。通過一種新的取樣策略,用於結合從時間網路中提取的結構和時間上下文資訊。在此基礎上,TagGen引數化了一個雙級自注意力層以及一系列區域性操作,以生成臨時隨機遊走。最後,判別器選擇在輸入資料中可信的生成的時間隨機遊走,並將其輸入到組裝模組中生成時間網路。在7個真實資料集上的實驗結果表明
(1)TagGen在時間互動網路生成問題上優於所有基線
(2)TagGen顯著提高了預測模型在異常檢測和鏈路預測任務中的效能。
Conclusion
在本文中提出了TagGen,通過直接學習時間戳邊集合來生成時間網路的第一次嘗試。TagGen能夠通過一種新穎的上下文取樣策略和雙級自注意力機制生成捕捉輸入資料的重要結構和時間屬性的圖表。作者提出:(1)TagGen在包含6個指標的7個資料集上始終優於基線方法;(2) TagGen通過資料增強提高了異常檢測和鏈路預測方法的效能。
Figure and table
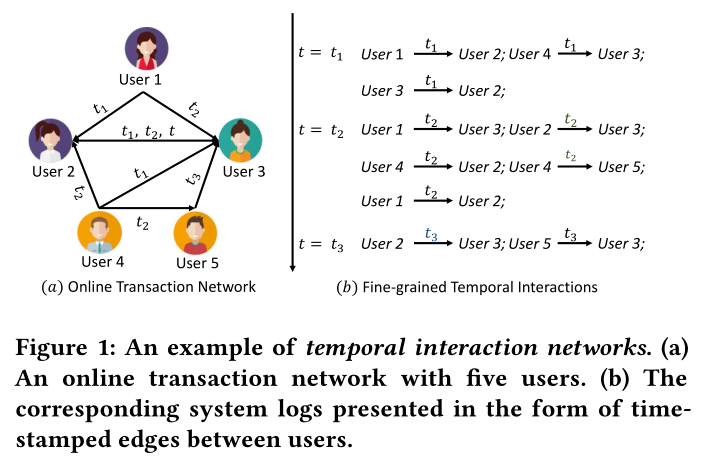
圖1 一個時間互動網路的例子。(a)有五個使用者的線上互動網路。(b)相應的系統紀錄檔以使用者之間帶時間戳的邊的形式表示。
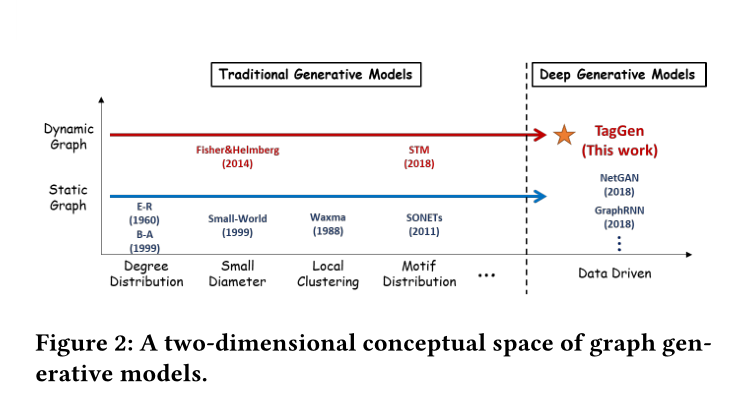
圖2 圖生成模型的二維概念空間(圖生成模型的歷史發展)
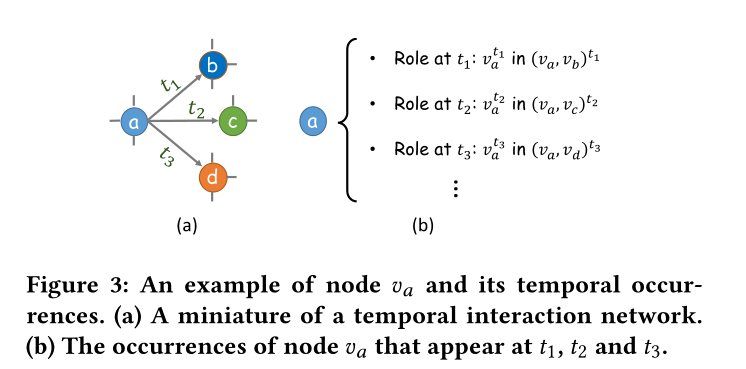
圖3 節點\(v_a\)和它的時序事件的一個樣例。(a)一個小型的時序互動網路。(b)節點\(v_a\)在時間\(t_1,t_2,t_3\)發生的事件
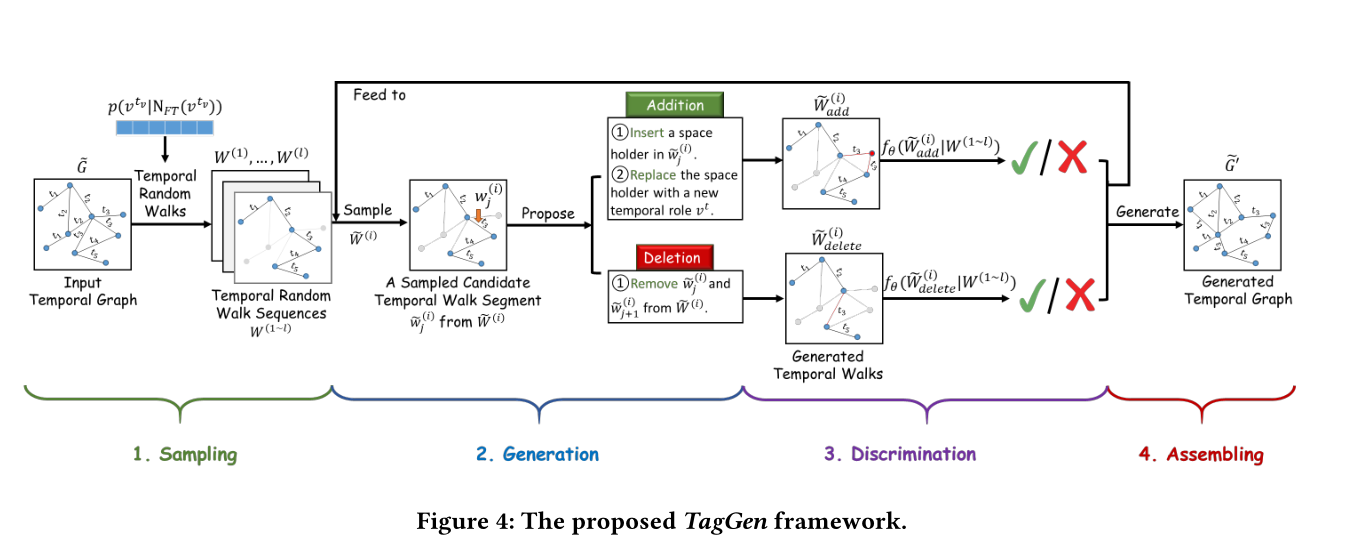
圖4 TagGen框架結構
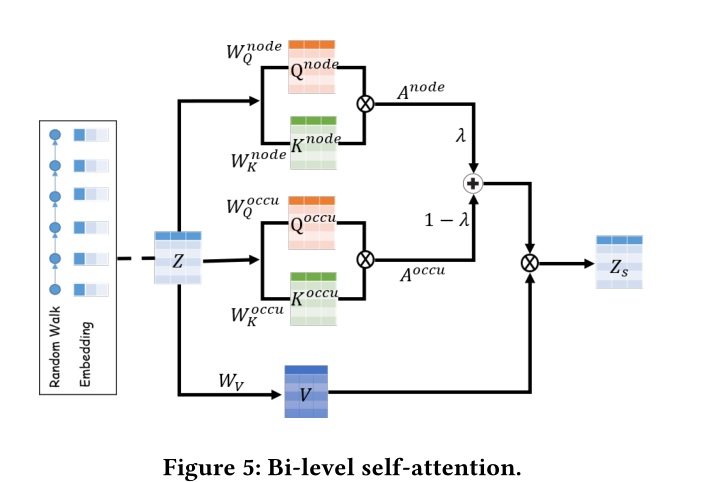
圖5 雙級自注意力架構(有點意思)
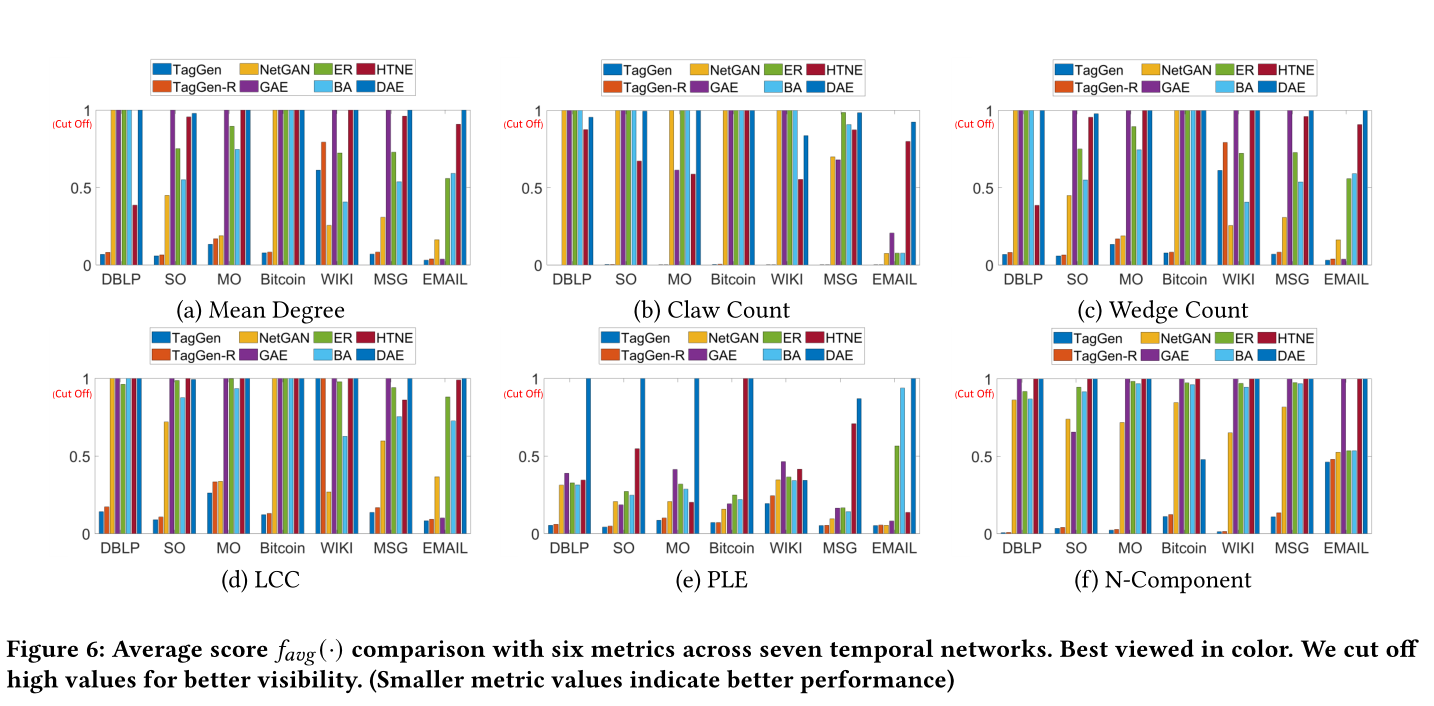
圖6 7個時間網路中6個指標的平均得分\(f_{avg}(·)\)比較。為了更好的能展示,去掉了高值。(度量值越小表示效能越好)
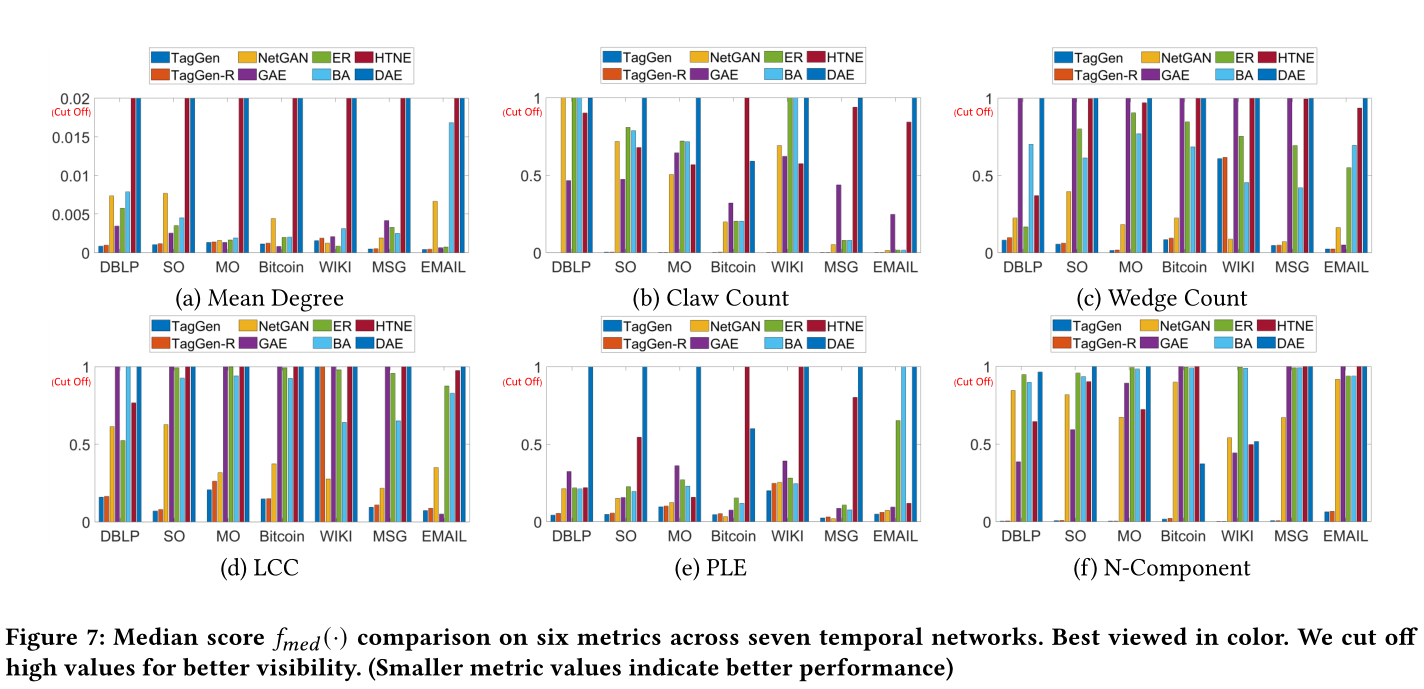
圖7 7個時間網路的6個指標的中位數\(f_{med}(·)\)得分。為了更好的展示,去掉了高值。(度量值越小表示效能越好)
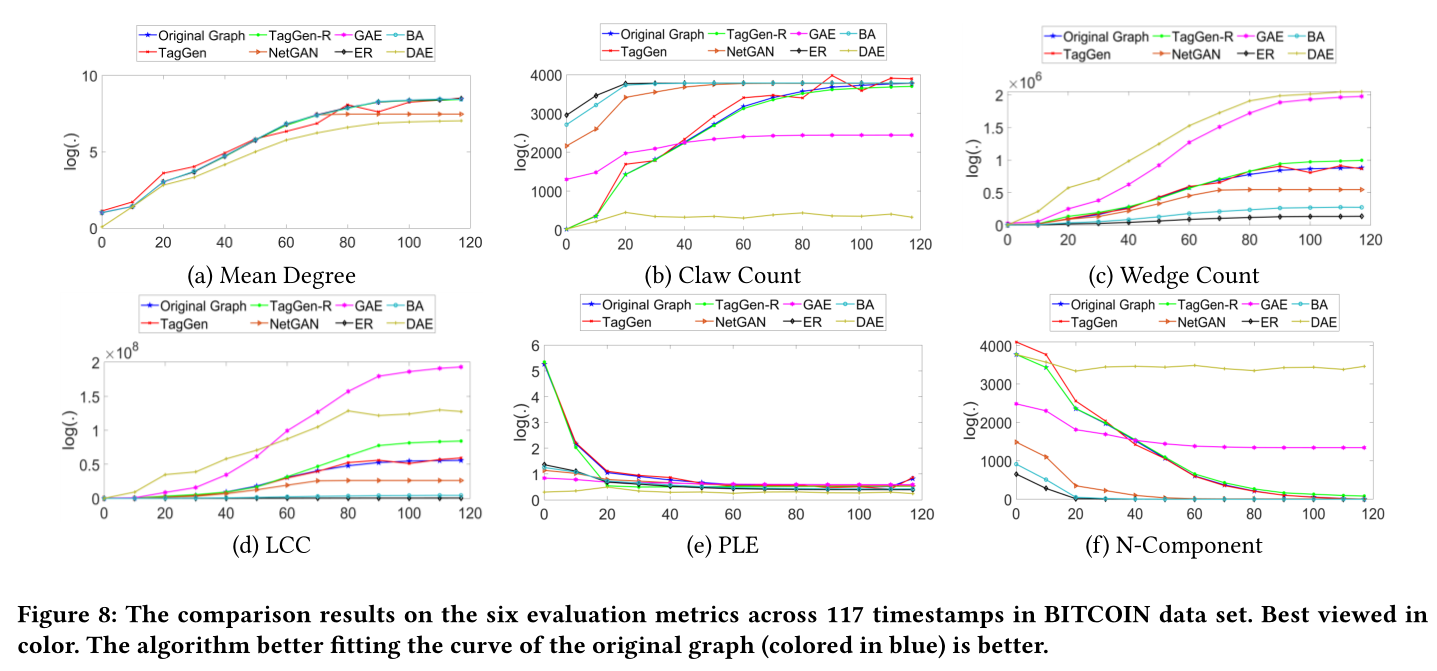
圖8 位元幣資料集中117個時間步下的6個評估指標的比較結果。更好地擬合原始圖(藍色)曲線的演演算法是更好的。
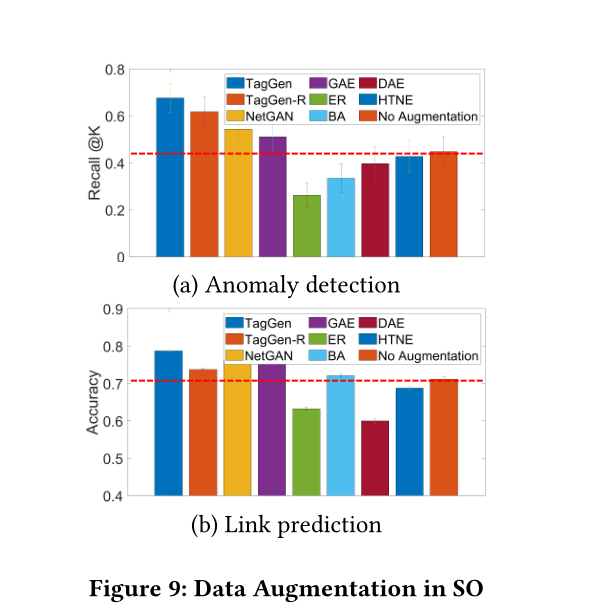
圖9 SO中的資料增強
附錄:

表1 相關符號
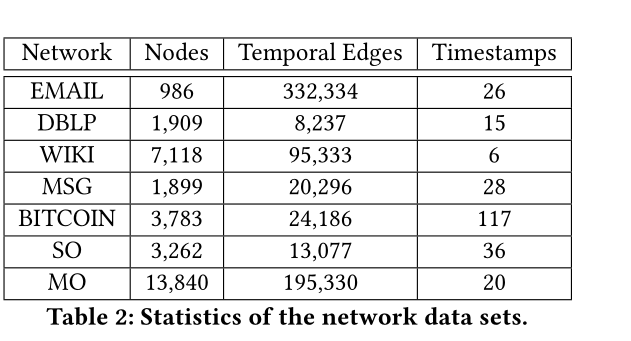
表2 資料集引數
Introduction
動態系統建模的傳統方法是通過將時間戳聚合到一系列快照中來構建時間演化圖。一個缺點是定義時間演進圖的正確粒度的不確定性。在訓練深度生成模型時,如果粒度過細,大量的快照會帶來難以處理的計算成本;如果粒度太粗,細粒度的時間上下文資訊(例如,節點和邊的新增/刪除)可能會在時間聚合期間丟失。
圖2比較了各種圖生成器,以說明現有技術與我們的技術相比的侷限性。本文的目標是首次解決以下三個挑戰(問題二算兩個挑戰吧):
(問題1)是否可以直接從原始時間網路(即時間互動網路)中學習,而不是構建時間演變圖?
(問題2)能否開發一個端到端的深度生成模型,以確保生成的圖能夠保留原始資料的結構和時間特徵(例如,度分佈的重尾,以及隨著時間的推移不斷縮小的網路直徑)?
為此,提出了時間互動網路的深層圖生成模型TagGen,以解決上述所有挑戰。首先提出了一種隨機遊走抽樣策略,從輸入圖中結合提取關鍵的結構和時間上下文資訊。在此基礎上開發了一種雙級的自我注意機制,該機制可以從提取的時間隨機遊動中直接訓練,同時保留了時間互動網路的性質。此外,本文設計了一種新的網路上下文生成方案,該方案定義了一系列區域性操作來執行節點和邊的新增(在時間t隨機選擇一個節點與另一個節點連線)和刪除(隨機終止時間t的兩個節點之間的互動),從而模擬了真實動態系統的演化過程。特別地,TagGen維護圖的狀態,並通過訓練從提取的時間隨機遊走生成新的時間邊緣。
TagGen中的判別器模組根據所構造圖的當前狀態接受或拒絕所有圖事件的操作。最後,將所選擇的真實概率最大的時間隨機遊走輸入組裝模組,生成時間網路。
本文的主要貢獻總結如下:
問題:正式定義了時間互動網路生成的問題,並確定了其在實際應用中產生的獨特挑戰。
演演算法:我們提出了一個端到端的時間互動網路生成學習框架,該框架可以(1)直接從一系列帶時間戳的節點和邊中學習,(2)保持輸入資料的結構和時間特徵。
評估:TagGen模型sota
Method
2 PROBLEM DEFINITION
附錄表1展示了使用的符號解釋
與傳統的動態圖定義為離散快照序列不同,時間互動網路表示為時間邊的集合。每個節點在不同的時間戳上與多個時間戳邊相關聯,這導致節點\(v=\{v^{t_1},...,v^{T} \}\)出現的次數不同。例如,在圖3中,節點\(v_a\)與三次事件的\(\{v_a^{t_1},v_a^{t_2},v_a^{t_3} \}\)相關聯。這三次事件分別在\(t_1,t_2,t_3\)發生。在下面將給出時序互動網路和時序事件的形式定義
定義1(時序事件):在一個時間互動網路中,節點\(v\)與一個時序事件包\(\{v^{t_1},v^{t_2},... \}\)相關聯,它範例化了節點\(v\)在網路中時間戳\(\{t_1,t_2,... \}\)的事件。
定義2(時間互動網路):時間互動網路\(\widetilde{G}=(\widetilde{V}, \widetilde{E})\)是由節點的集合\(\widetilde{V}=\{v_1,v_2,...v_n \}\)和邊的集合\(\widetilde{E} = \{e_1^{t_{e_1}},e_2^{t_{e_2}},...,e_m^{t_{e_m}} \}\)組成的,其中\(e_i^{t_{e_i}} = (u_{e_i},v_{e_i})^{t_{e_i}}\)
定義3 (時間網路鄰居):給定一個在時間戳\(t_v\)發生的時序事件\(v^{t_v}\),事件\(v^{t_v}\)的鄰居被定義為\(\mathcal{N}_{F T}\left(v^{t_{v}}\right)=\left\{v_{i}^{t_{v_{i}}}\left|f_{s p}\left(v_{i}^{t_{v_{i}}}, v^{t_{v}}\right) \leq d_{\mathcal{N}_{F T}},\right| t_{v}-t_{v_{i}} \mid \leq t_{\mathcal{N}_{F T}}\right\}\),其中\(f_{sp}(·|·)\)兩個節點之間的最短路徑,\(d_{\mathcal{N}_{F T}}\)是自定義的鄰居範圍,\(t_{\mathcal{N}_{F T}}\)為自定義鄰居時間視窗。
在CTDNE中作者定義了時序隨機遊走,它是一個遵循時間順序約束的頂點序列。在本文中,將放寬這一約束:鄰居時間視窗\([t_v-t_{\mathcal{N}_{F T}},t_v+t_{\mathcal{N}_{F T}}]\)內的所有節點都是\(v^{t_v}\)的時間鄰居,可以從\(v\)通過隨機漫步存取。下在面定義了k長度時間遊走
定義4 (k長度時間遊走):給定一個時序互動網路\(\widetilde{G}\),一個k長度的時間遊走\(W=\left\{w_{1}, \ldots, w_{k}\right\}\)被定義為一個接一個遍歷的事件時間遍歷序列,即\(w_i=(u_{w_i},v_{w_i})^{t_{w_i}}\),其中\(u_{w_i}\)和\(v_{w_i}\)分別為\(W\)中第\(i\)次時間的源節點和目標節點。
有了上述所有的概念,我們準備將時間互動網路生成問題形式化如下。
問題1(時間互動網路生成):
輸入:一個時間互動網路\(\widetilde{G}\),表示為時間戳邊的集合\(\left\{\left(u_{e_{1}}, v_{e_{1}}\right)^{t_{e_{1}}}, \ldots,\left(u_{e_{m}}, v_{e_{m}}\right)^{t_{e_{m}}}\right\}\)
輸出:一個合成的時間互動網路\(\widetilde{G}^{\prime}=\left(\widetilde{V}^{\prime}, \widetilde{E}^{\prime}\right)\),該網路能準確地捕捉到觀測到的時間網路\(\widetilde{G}\)的結構和時間特性。
3 MODEL
3.1 A Generic Learning Framework
圖4概述了我們提出的框架,它包括四個主要階段。給定一個由時間邊集合(即帶時間戳的互動)定義的時間互動網路,我們首先通過一種新的取樣策略對的一組時間隨機遊動進行取樣,提取時間互動網路的網路上下文資訊。其次,我們開發了一種深層生成機制,它定義了一組簡單而有效的操作(即在時間邊上的新增和刪除)來生成合成隨機遊走。第三,在取樣的時間隨機漫步上訓練鑑別器,以確定生成的時間漫步是否與真實的時間漫步遵循相同的分佈。最後,通過鑑別器收集符合條件的合成時間漫步,生成時間互動網路。在下面的小節中,我們將詳細描述TagGen的每個階段。
Context sampling:受網路嵌入方法deepwalk的啟發,作者把時間網路上下文取樣問題看作是通過時間隨機遊走在網路鄰域\(\mathcal{N}_{F T}\)上進行區域性探索的一種形式。具體來說,給定一個時間事件\(v^{t_v}\),我們的目標是提取一組序列,能夠生成其鄰居\(\mathcal{N}_{F T}\left(v^{t_{v}}\right)\)。為了公平有效地對鄰域上下文進行取樣,我們應該從整個資料中選擇最具代表性的時間事件作為初始節點。這裡我們提出通過計算每個事件\(v^{t_v}\)給定的其時間網路鄰居\(\mathcal{N}_{F T}\left(v^{t_{v}}\right)\)的條件概率來估計的上下文重要性\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\),如下所示。
其中\(\mathcal{N}_{T}\left(v^{t_{v}}\right)\)和\(\mathcal{N}_{S}\left(v^{t_{v}}\right)\)分別表示\(v^{t_v}\)的時間鄰居和結構鄰居
直觀上看,當\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\)高時,\(v^{t_v}\)是其鄰居的一個代表性節點,這可能是一個很好的隨機遊走初始點;當\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\)值較低時,\(p(v^{t_v})\)極有可能是一個異常點,其行為與其相鄰點發生偏離。這裡主要的關鍵問題是如何評估\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\),如果\(\mathcal{N}_{T}\left(v^{t_{v}}\right)\)和\(\mathcal{N}_{S}\left(v^{t_{v}}\right)\)相互獨立,那可以得到
然而,在真實的網路中,拓撲上下文和時間上下文在一定程度上是相關的,這在Temporal Information Transformed into a Spatial Code by a Neural Network with Realistic Properties.中已經觀察到。例如,度較高的節點(即\(\mathcal{N}_{S}\left(v^{t_{v}}\right)\)較高)在未來的時間戳中具有較高的活躍概率(即\(\mathcal{N}_{T}\left(v^{t_{v}}\right)\)較高),反之亦然。這些觀察結果使我們能夠指出拓撲鄰居分佈和時間鄰居分佈之間存在弱依賴。
定義5(弱依賴):對於任意\(v^{t_{v}} \in \widetilde{V}\),對應的時間鄰居分佈\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\)與拓撲鄰居分佈\(p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)之間存在弱依賴關係,使得對於\(\delta > 0\)
基於定義5,這裡嘗試建立\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right),p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)和\(p\left(v^{t_{v}} \mid \mathcal{N}_{F T}\left(v^{t_{v}}\right)\right)\)的關係
引理1:對於任意的\(v^{t_{v}} \in \widetilde{V}\),如果時間鄰居分佈\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\)與拓撲鄰居分佈\(p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)之間存在弱依賴關係,則有下列不等式成立
這個引理的證明可以在附錄B中找到。在[30]之後,我們假設\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\)和\(p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)遵循均勻分佈,在一個區域性區域的所有時間實體都是同等重要的。接著通過計算,\(p\left(v^{t_{v}} \mid \mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\),\(p\left(v^{t_{v}} \mid \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)\)和\(p\left( \mathcal{N}_{S}\left(v^{t_{v}}\right),\mathcal{N}_{T}\left(v^{t_{v}}\right)\right)\)(例如,通過核密度估計接近Variable Kernel Density Estimation),對於初始節點的選擇,我們可以根據式3推斷上下文重要性\(p(v^{t_v}|\mathcal{N}_{F T}\left(v^{t_{v}}\right))\)。
在選擇了初始時間事件後,我們使用有偏差的時間隨機遊走來提取一個時間遊走集合,用於訓練TagGen。採用基於隨機遊走的取樣方法的關鍵原因在於其控制序列長度的靈活性以及聯合捕獲結構鄰域和時間鄰域上下文資訊的能力。
Sequence generation:要生成合成的時間隨機遊走,一個簡單的解決方案是通過從提取的隨機遊走[5]學習來訓練序列模型。然而,在時間網路環境下,如何模擬網路演化併產生時間互動網路尚不清楚。因此,本文設計了一組區域性操作,\(action = \{ add,delete \}\),用於對時間實體進行新增和刪除操作,模擬真實動態網路的演化過程。給定一個k長度的時間隨機遊走\(\widetilde{W}^{(i)}=\left\{\widetilde{w}_{1}^{(i)}, \ldots, \widetilde{w}_{k}^{(i)}\right\}\),我們首先根據自定義的先驗分佈\(p(\widetilde{W}^{(i)})\)抽樣一個候選時間遊走段\(\widetilde{w}_{j}^{(i)} \in \widetilde{W}^{(i)}\)。在本文中,我們假設\(p(\widetilde{W}^{(i)})\)服從均勻分佈。然後,我們以\(p_{action}= \{ p_{add},p_{delete}\}\)的概率隨機執行下列操作之一。
add: 新增操作以兩步方式完成。首先,我們在候選時間遊走段\(\widetilde{w}_{j}^{(i)}=\left(u_{\widetilde{w}_{j}^{(i)}}, v_{\widetilde{w}_{j}^{(i)}}\right)^{{ }^{w_{j}^{(i)}}}\)中插入一個預留位置標誌,接著用一個時序實體\(v*^{t_{v*}}\)去代替預留位置,然後將遊走段分做兩段,寫作\(\left\{\left(u_{\widetilde{w}_{j}^{(i)}}, v *\right)^{t_{v *}},\left(v *, v_{\widetilde{w}_{j}^{(i)}} \right)^{t_{\widetilde{w}_{j}^{(i)}}}\right\}\)(吐槽一下這個式子,連公式識別都會識別錯,有點濫用上下標了)。經過這次的新增以後時間隨機遊走序列\(\widetilde{W}^{(i)}_{add}\)將會變成k+1。
delete:刪除操作從\(\widetilde{W}^{(i)}=\left\{\widetilde{w}_{1}^{(i)}, \ldots, \widetilde{w}_{j}^{(i)}, \ldots, \widetilde{w}_{k}^{(i)}\right\}\)中刪除候選的時間遊走段\(\widetilde{w}_{j}^{(i)}\),使修改後的時間隨機遊走\(\widetilde{W}^{(i)}_{delete}\)的長度為k-1
Sample discrimination:為了確保生成的圖上下文遵循與輸入相似的全域性結構分佈,TagGen配備了一個判別器模型\(f_\theta(·)\),該模型的作用是區分生成的時間網路是否遵循與原始圖相同的分佈。對於每個生成的時間隨機遊走,\(W^{(1 \sim l)}=\{ W^{(1)},...,W^{(l)}\}\)經過一系列的操作\(action = \{add,delete\}\),給定提取的真實時間隨機遊走\(W^{(1 \sim l)}=\{ W^{(1)},...,W^{(l)}\}\),TagGen計算條件概率\(p\left(\widetilde{W}_{\text {action }}^{(i)} \mid W^{(1 \sim l)}\right)\)如下
其中,\(f_\theta(·)\)計算在給定訓練資料\(W^{(1 \sim l)}=\{ W^{(1)},...,W^{(l)}\}\)的情況下,\(\widetilde{W}^{(i)}_{action}\)的可信度,\(p_{\text {action }}(\text { action })\)是\(\widetilde{W}^{(i)}_{action}\)的權重係數。
為了計算並行提高效率,作者使用了Transformer的架構(LSTM或者RNN的架構很難並行,導致效率較低)
但是,使用標準Transformer引數化的直接實現可能無法捕獲這種雙級依賴項(即節點級依賴項和事件級依賴項)。本文提出了一個雙級的自我注意機制,如圖5所示。
給定一個長度為k的時間遊走\(\widetilde{W}^{(i)}\),首先通過時間網路嵌入方法(CTDNE)為每個節點\(v^t\)(在\(t\)時刻的節點\(v\))得到一個\(d\)維的表示\(\mathbf{Z} \in {\mathbb{R}}^{n \times d}\)。因此,每個節點\(v\)被表示為一個時間事件\(v=\{v^{t1},v^{t2},...,v^T\}\)的包
雙層自我注意機制旨在共同學習:
(1)\(\widetilde{G}\)中節點之間的依賴關係
(2)不同時間事件之間的依賴關係。
按照transformer中的符號,我們如下所示定義事件級注意\(\mathbf{A^{occu}} \in {\mathbb{R}}^{n_r \times n_r}\)和節點級注意\(\mathbf{A^{node}} \in {\mathbb{R}}^{n_r \times n_r}\)。
其中\(z^{t1}_i(z^{t1}_j) \in {\mathbb{R}}^{1 \times d}\)是節點\(z^{t1}_i(z^{t1}_j)\)的d維嵌入
\(\mathbf{W_{Q}^{o c c u}} \in {\mathbb{R}}^{d \times d_k}\)和\(\mathbf{W_{K}^{occu}} \in {\mathbb{R}}^{d \times d_k}\)分別是事件級別的query矩陣和key矩陣,
\(\mathbf{W_{Q}^{node}} \in {\mathbb{R}}^{d \times d_k}\)和\(\mathbf{W_{K}^{node}} \in {\mathbb{R}}^{d \times d_k}\)分別是節點級別的query矩陣和key矩陣,
\(d_k\)是一個可調整的維度引數
\(f_{agg}(·)\)是一個聚合函數,它彙總每個節點的所有事件級資訊。在實現上,寫作\(\operatorname{f_{agg}}\left(v_{i}^{t}\right)=\sum_{v_{i}^{t} \in v_{i}}\mathbf{z_{i}^{t}}\),因此無論時間如何,同一個節點的該函數值總是相同的,例如當\(t_1 \ne t_2\)時,\(\operatorname{f_{agg}}\left(v_{i}^{t_1}\right)=\operatorname{f_{agg}}\left(v_{i}^{t_2}\right)\),這樣,\(\mathbf{A^{occu}}\)和\(\mathbf{A^{node}}\)中的元素就完全對齊了。此外,我們引入一個係數\(\lambda \in [0,1]\)來平衡事件級注意和節點級注意,得到最終的雙層自我注意\(\mathbf{Z_s}\)
其中 \(\mathbf{W_vZ}\),\(\mathbf{W_V}\)表示權重矩陣
對於圖5中描述的單頭部注意,我們在鑑別器\(f_{\theta}(·)\)中使用\(ℎ= 4\)個並行注意層(即頭部)來選擇合格的合成隨機遊走\(\widetilde{W}^{(i)}_{action}\)。\(f_{\theta}(·)\)中隱藏表示的更新規則與中定義的標準Transformer模型相同。在階段3結束時,所有經過\(f_{\theta}(·)\)選擇的合成時間隨機遊走將被輸入到階段2的開始(見圖4),逐步修改這些序列,直到滿足自定義的停止標準,序列準備合成(階段4)。
Graph assembling:在此階段,我們將所有生成的時間隨機遊走集合起來,生成時間互動網路。首先計算生成的時間隨機遊走中每個時間邊\(e^{t_e}=(u,v)^{t_e}\)的頻率計數\(s(e^{t_e})\)。為了確保頻率計數是可靠的,所以從原始圖中提取了大量的時間隨機遊走,以避免一些未被表示的時間事件(即度較小的節點)沒有抽樣。為了將這些頻率計數轉換為離散的時間邊,我們使用以下策略:
(1)首先,我們以\(p\left(v^{t_{v}}, v^{*} \in \mathcal{N}_{S}\left(v^{t_{v}}\right)\right)=\frac{s\left(e^{t_{e}}=\left(v, v^{*}\right)^{t_{v}}\right)}{\sum_{v^{*} \in \mathcal{N}_{S}\left(v^{t_{v}}\right)} s\left(e^{t_{e}}=\left(v, v^{*}\right)^{t_{v}}\right)}\)為概率從每個時間事件\(v^{t_v}\)開始生成至少一條時間邊,以確保\(\widetilde{G}\)中所有觀察到的時間事件都包含在內;
(2)然後在每個時間戳以概率\(p(e^{t_e})=\frac{s(e^{t_e})}{\sum_{e_i^{t_{e_i}}} s({e_i^{t_{e_i}}})}\)生成至少一個時間邊
(3)生成數量最大的時間邊,直到生成的圖具有與原始圖相同的邊緣密度。
3.2 Optimization Algorithm

用的SGD,優化演演算法見演演算法1。給定的輸入包括時間互動網路\(\widetilde{G}\)、鄰居範圍\(d_{\mathcal{N}_{FT}}\)、鄰居時間窗\(t_{\mathcal{N}_{FT}}\)、初始節點數\(l\)、每個初始節點的步行數\(\gamma\)、步行長度K、每個序列的運算元\(c_1\)和常數引數\(\xi \in (0.5,1)\)。對於\(\xi > 0.5\),我們強制新增運算元大於刪除運算元。這樣,我們就可以避免生成零入口的時間隨機遊走序列的情況。從步驟1到步驟3,我們從輸入資料中抽取一組時間隨機遊走\(\mathcal{S}\),訓練鑑別器\(f_\theta(·)\)。步驟4到步驟14是TagGen的主體,它生成時間隨機遊走\(\mathcal{S}\)的準確樣本數量。
首先以\(W^{(i)}\)的第一個條目初始化每個合成漫步\(\widetilde{W}^{(i)}\),即\(\widetilde{W}^{(i)}={w_1^{(i)}}\)。從步驟7到步驟12,我們執行\(c_1\)次操作(即新增和刪除)為每個合成遊走\(\widetilde{W}^{(i)}\)生成上下文,並使用鑑別器\(f_\theta(·)\)選擇符合條件的時間隨機遊走儲存在\(\mathcal{S’}\)中。最後,步驟15通過確保所有時間事件和時間戳都包含在\(\widetilde{G’}\)中,從而在\(\mathcal{S’}\)的基礎上構造\(\widetilde{G’}\)。
Experiment
4 EXPERIMENTAL RESULTS
4.1 Experiment Setup
資料集:DBLP,SO,MO,WIKI,EMAIL,MSG,BITCOIN
baseline: Erdös-Rényi (ER),Barabási-Albert (BA) ,GAE [18],NetGAN [5],HTNE [45], DAE [13]
評價指標:Mean Degree, Claw Count, Wedge Count, PLE, LCC, N-Component但是推廣到了動態圖。給定一個真實網路\(\widetilde{G}\),合成網路\(\widetilde{G’}\)和使用者特定指標\(f_m(·)\),首先通過從初始時間戳到當前時間戳\(t\)的聚合來構造\(\widetilde{G}(\widetilde{G^{\prime}})\)的快照\(\widetilde{S}^{t}(\widetilde{S^{\prime}}^{t}),t=1,...,T\)序列:
4.2 Quantitative Results for Graph Generation
sota見圖7,圖8
4.3 Case Studies in Data Augmentation
資料增強效果見圖9
Summary
時序圖+GAN+transformer,綜合性很強的論文,其中比較有意思的就是提出那個雙級自注意力。