Pytorch分散式訓練
用單機單卡訓練模型的時代已經過去,單機多卡已經成為主流設定。如何最大化發揮多卡的作用呢?本文介紹Pytorch中的DistributedDataParallel方法。
1. DataParallel
其實Pytorch早就有資料並行的工具DataParallel,它是通過單程序多執行緒的方式實現資料並行的。
簡單來說,DataParallel有一個引數伺服器的概念,引數伺服器所線上程會接受其他執行緒傳回來的梯度與引數,整合後進行引數更新,再將更新後的引數發回給其他執行緒,這裡有一個單對多的雙向傳輸。因為Python語言有GIL限制,所以這種方式並不高效,比方說實際上4卡可能只有2~3倍的提速。
2. DistributedDataParallel
Pytorch目前提供了更加高效的實現,也就是DistributedDataParallel。從命名上比DataParallel多了一個分散式的概念。首先 DistributedDataParallel是能夠實現多機多卡訓練的,但考慮到大部分的使用者並沒有多機多卡的環境,本篇博文主要介紹單機多卡的用法。
從原理上來說,DistributedDataParallel採用了多程序,避免了python多執行緒的效率低問題。一般來說,每個GPU都執行在一個單獨的程序內,每個程序會獨立計算梯度。
同時DistributedDataParallel拋棄了引數伺服器中一對多的傳輸與同步問題,而是採用了環形的梯度傳遞,這裡參照知乎上的圖例。這種環形同步使得每個GPU只需要和自己上下游的GPU進行程序間的梯度傳遞,避免了引數伺服器一對多時可能出現的資訊阻塞。
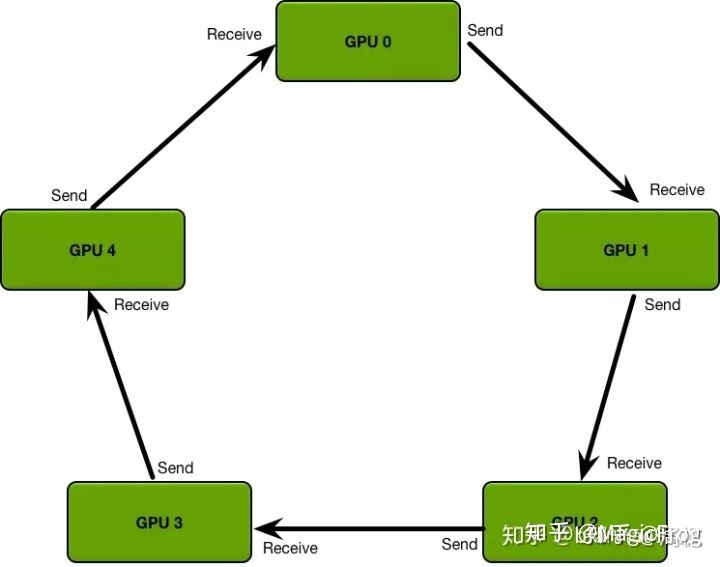
3. DistributedDataParallel範例
下面給出一個非常精簡的單機多卡範例,分為六步實現單機多卡訓練。
第一步,首先匯入相關的包。
import argparse
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
第二步,加一個引數,local_rank。這比較好理解,相當於就是告知當前的程式跑在那一塊GPU上,也就是下面的第三行程式碼。local_rank是通過pytorch的一個啟動指令碼傳過來的,後面將說明這個指令碼是啥。最後一句是指定通訊方式,這個選nccl就行。
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1, type=int)
args = parser.parse_args()
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend='nccl')
第三步,包裝Dataloader。這裡需要的是將sampler改為DistributedSampler,然後賦給DataLoader裡面的sampler。
為什麼需要這樣做呢?因為每個GPU,或者說每個程序都會從DataLoader裡面取資料,指定DistributedSampler能夠讓每個GPU取到不重疊的資料。
讀者可能會比較好奇,在下面指定了batch_size為24,這是說每個GPU都會被分到24個資料,還是所有GPU平分這24條資料呢?答案是,每個GPU在每個iter時都會得到24條資料,如果你是4卡,一個iter中總共會處理24*4=96條資料。
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)
trainloader = torch.utils.data.DataLoader(my_trainset,batch_size=24,num_workers=4,sampler=train_sampler)
第四步,使用DDP包裝模型。device_id仍然是args.local_rank。
model = DDP(model, device_ids=[args.local_rank])
第五步,將輸入資料放到指定GPU。後面的前後向傳播和以前相同。
for imgs,labels in trainloader:
imgs=imgs.to(args.local_rank)
labels=labels.to(args.local_rank)
optimizer.zero_grad()
output=net(imgs)
loss_data=loss(output,labels)
loss_data.backward()
optimizer.step()
第六步,啟動訓練。torch.distributed.launch就是啟動指令碼,nproc_per_node是GPU數。
python -m torch.distributed.launch --nproc_per_node 2 main.py
通過以上六步,我們就讓模型跑在了單機多卡上。是不是也沒有那麼麻煩,但確實要比DataParallel複雜一些,考慮到加速效果,不妨試一試。
4. DistributedDataParallel注意點
DistributedDataParallel是多程序方式執行的,那麼有些操作就需要小心了。如果你在程式碼中寫了一行print,並使用4卡訓練,那麼你將會在控制檯看到四行print。我們只希望看到一行,那該怎麼做呢?
像下面一樣加一個判斷即可,這裡的get_rank()得到的是程序的標識,所以輸出操作只會在程序0中執行。
if dist.get_rank() == 0:
print("hah")
你會經常需要dist.get_rank()的。因為有很多操作都只需要在一個程序裡執行,比如儲存模型,如果不加以上判斷,四個程序都會寫模型,可能出現寫入錯誤;另外load預訓練模型權重時,也應該加入判斷,只load一次;還有像輸出loss等一些場景。
【參考】https://zhuanlan.zhihu.com/p/178402798