開發實踐丨昇騰CANN的推理應用開發體驗
摘要:這是關於一次 Ascend 線上實驗的記錄,主要內容是通過網路模型載入、推理、結果輸出的部署全流程展示,從而快速熟悉並掌握 ACL(Ascend Computing Language)基本開發流程。
本文分享自華為雲社群《基於昇騰CANN的推理應用開發快速體驗(Python)》,作者: Tianyi_Li 。
前情提要
這是關於一次 Ascend 線上實驗的記錄,主要內容是通過網路模型載入、推理、結果輸出的部署全流程展示,從而快速熟悉並掌握 ACL(Ascend Computing Language)基本開發流程。
注意,為了保證學習和體驗效果,使用者應該具有以下知識儲備:
1.熟練的Python語言程式設計能力
2.深度學習基礎知識,理解神經網路模型輸入輸出資料結構
1. 目錄
2. 最終目標

1.瞭解ACL的基本概念,清楚ACL具備哪些能力,能為我們做什麼
2.瞭解ACL定義的程式設計模型,理解各類執行資源的概念及其相互關係
3.能夠區分Host和Device的概念,並學會管理這兩者各自的記憶體
4.載入一個離線模型進行推理,併為推理準備輸入輸出資料結構
3. 基礎知識
3.1 ATC介紹
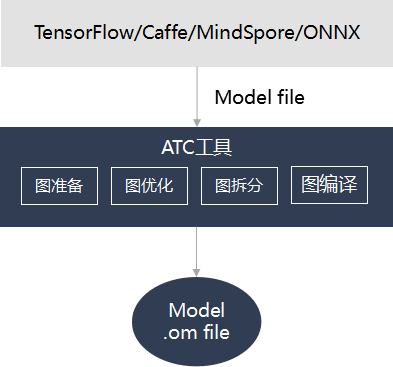
ATC(Ascend Tensor Compiler)是華為昇騰軟體棧提供的一個編譯工具,它的主要功能是將基於開源框架的網路模型(如 Caffe、TensorFlow 等)以及單運算元 Json 檔案,轉換成昇騰AI處理器支援的離線模型 Offline-Model 檔案(簡稱OM檔案)。在編譯過程中,可以實現運算元排程的優化、權值資料重排、記憶體使用優化等,並且可以脫離裝置完成模型的預處理。更詳細的ATC介紹,可參看官方檔案 。
需要說明的是,理論上對於華為自研 AI 計算框架 MindSpore 的支援會更加友好。
3.2 ACL介紹
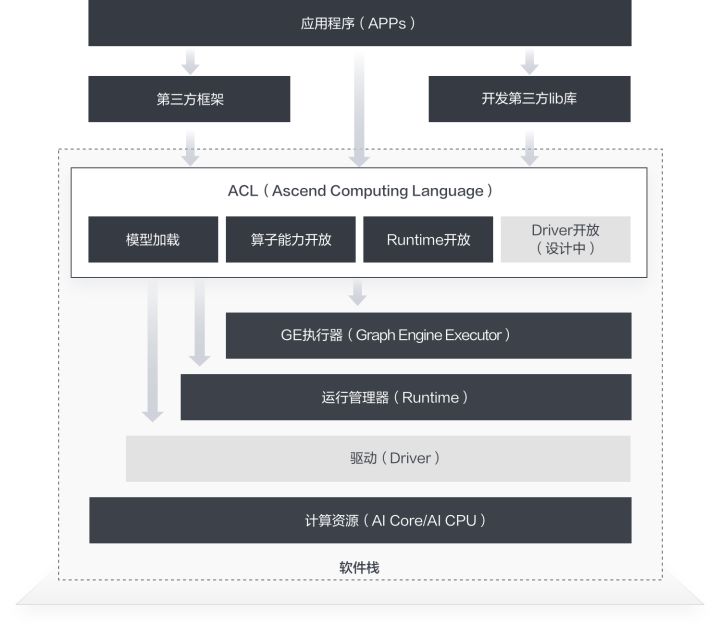
對已訓練好的權重檔案,比如 Caffe框架下的 caffemodel, TensorFlow框架下得到的 checkpoint 或者 pb 檔案,再經過 ATC 工具轉換後得到的離線模型檔案,ACL(Ascend Computing Language,昇騰計算語言)提供了一套用於在昇騰系列處理器上進行加速計算的API。基於這套API,您能夠管理和使用昇騰軟硬體計算資源,並進行機器學習相關計算。更詳細的ACL介紹,可參看官方檔案 。
最新版本支援 onnx 模型和 MindSpore 模型轉換為離線模型檔案,甚至可以直接通過MindSpore進行部署和推理。
當前 ACL 提供了 C/C++ 和 Python 程式設計介面,能夠很方便的幫助開發者達成包括但不限於如下這些目標:
1.載入深度學習模型進行推理
2.載入單運算元進行計算
3.影象、視訊資料的預處理
4. 準備工作
最終結果是使用 Resnet50 對 3 張圖片進行分類推理。為了達成這個結果,首先我們準備瞭如下兩個素材:
- 三張待推理分類的圖片資料,如:

- 使用ATC工具,將 tensorflow 的 googlenet.pb 模型轉換成昇騰支援的om(offine-model) 檔案。
推理後我們將列印每張圖片置信度排前5位的標籤及其置信度。
5. 開始
5.1 初始化
在開始呼叫ACL的任何介面之前,首先要做ACL的初始化。初始化的程式碼很簡單,只有一行:
acl.init(config_path)
這個介面呼叫會幫您準備好ACL的執行時環境。其中呼叫時傳入的引數是一個組態檔在磁碟上的路徑,這裡暫時不必關注。
有初始化就有去初始化,在確定完成了ACL的所有呼叫之後,或者程序退出之前,要做去初始化操作,介面呼叫也十分簡單:
acl.finalize()
匯入Python包:
import argparse import numpy as np import struct import acl import os from PIL import Image
介面介紹:

函數範例:
def init(): ret = acl.init() check_ret("acl.init", ret)
5.2 申請計算資源
想要使用昇騰處理器提供的加速計算能力,需要對執行管理資源申請,包括Device、Context、Stream。且需要按順序申請,主要涉及以下三個介面:
acl.rt.set_device(device_id)
這個介面指定計算裝置,告訴執行時環境我們想要用哪個裝置,或者更具體一點,哪個晶片。但是要注意,晶片和我們在這裡傳入的編號之間並沒有物理上的一一對應關係。
acl.rt.create_context(device_id)
Context作為一個容器,管理了所有物件(包括Stream、Event、裝置記憶體等)的生命週期。不同Context的Stream、不同Context的Event是完全隔離的,無法建立同步等待關係。個人理解為,如果計算資源足夠的話,可以建立多個Context,分別執行不同的應用,來提高硬體利用率,而不用擔心應用之間的互相干擾,類似於Docker。
acl.rt.create_stream()
Stream用於維護一些非同步操作的執行順序,確保按照應用程式中的程式碼呼叫順序在Device上執行。基於Stream的kernel執行和資料傳輸能夠實現Host運算操作、Host與Device間的資料傳輸、Device內的運算並行。
介面介紹:



函數範例:
import sys import os from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all" home_path = !echo ${HOME} sys.path.append(os.path.join(home_path[0] , "jupyter-notebook/")) print('System init success.') # atlas_utils是本團隊基於pyACL封裝好的一套工具庫,如果您也想參照的話,請首先將 # https://gitee.com/ascend/samples/tree/master/python/common/atlas_utils # 這個路徑下的程式碼引入您的工程中 from atlas_utils.acl_resource import AclResource from constants import * # 建立一個AclResource類的範例 acl_resource = AclResource() #AscendCL資源初始化(封裝版本) acl_resource.init() # 上方「init」方法具體實現(僅供參考) # 請閱讀「init(self)」方法,觀察初始化和執行時資源申請的詳細操作步驟 def init(self): """ Init resource """ print("init resource stage:") ret = acl.init() utils.check_ret("acl.init", ret) #指定用於運算的Device ret = acl.rt.set_device(self.device_id) utils.check_ret("acl.rt.set_device", ret) print("Set device n success.") #顯式建立一個Context self.context, ret = acl.rt.create_context(self.device_id) utils.check_ret("acl.rt.create_context", ret) #建立一個Stream self.stream, ret = acl.rt.create_stream() utils.check_ret("acl.rt.create_stream", ret) #獲取當前昇騰AI軟體棧的執行模式 #0:ACL_DEVICE,表示執行在Device的Control CPU上或開發者版上 #1:ACL_HOST,表示執行在Host CPU上 self.run_mode, ret = acl.rt.get_run_mode() utils.check_ret("acl.rt.get_run_mode", ret) print("Init resource success")
需要說明的是這裡使用了 atlas_utils ,這是昇騰團隊基於 pyACL 封裝好的一套工具庫,可以更加便捷的使用,但可能存在更新不及時的問題,也不易於優化提升,以及個人學習理解,建議能不用,則不用。
5.3 載入模型
既然要呼叫模型進行推理,首先當然是要把模型載入進來。ACL 提供了多種模型載入和記憶體管理方式,這裡我們只選取其中相對簡單的一種,即從磁碟上載入離線模型,並且載入後的模型記憶體由ACL自動管理:
model_path = "./model/resnet50.om"; # 模型檔案在磁碟上的路徑 model_id, ret = acl.mdl.load_from_file(model_path) # 載入模型
其中,model_id 是系統完成模型載入後生成的模型ID對應的指標物件,載入後生成的model_id,全域性唯一。
記得這個「model_id」,後邊我們使用模型進行推理,以及解除安裝模型的時候還要用到。
有載入自然就有解除安裝,模型解除安裝的介面比較簡單:
acl.mdl.unload(model_id)
至此,您腦海中應該有這樣一個概念,即使用了任何的資源,載入了任何的素材,都要記得用完後銷燬和解除安裝。這點對於使用 C/C++程式設計的同學應該很好理解。
介面介紹:

函數範例:
def load_model(model_path): model_path = "./model/googlenet_yuv.om" model_id, ret = acl.mdl.load_from_file(model_path) check_ret("acl.mdl.load_from_file", ret) return model_id
5.4 獲取模型資訊
模型描述需要特殊的資料型別,使用以下函數來建立並獲取該資料型別。
acl.mdl.create_desc()
acl.mdl.get_desc(model_desc, model_id)
獲取到模型型別後,還需要根據該型別來獲取模型的輸入輸出個數,呼叫函數如下:
acl.mdl.get_num_inputs(model_desc)
acl.mdl.get_num_outputs(model_desc)
介面介紹:

函數範例:
def get_model_data(model_id): global model_desc model_desc = acl.mdl.create_desc() ret = acl.mdl.get_desc(model_desc, model_id) check_ret("acl.mdl.get_desc", ret) input_size = acl.mdl.get_num_inputs(model_desc) output_size = acl.mdl.get_num_outputs(model_desc) return input_size, output_size
5.5 申請device記憶體
要使用 NPU 進行加速計算,首先要申請能夠被 NPU 直接存取到的專用記憶體。在講解記憶體申請之前,首先我們要區分如下兩個概念:
Host:Host指與Device相連線的X86伺服器、ARM伺服器,會利用Device提供的NN(Neural-Network )計算能力,完成業務。
Device:Device指安裝了晶片的硬體裝置,利用PCIe介面與Host側連線,為Host提供NN計算能力。
簡而言之,我們的資料需要先從Host側進行載入,即讀進Host側記憶體,隨後將其拷貝到Device側記憶體,才能進行計算。計算後的結果還要傳回Host側才能進行使用。
申請Device側記憶體:
dev_ptr, ret = acl.rt.malloc(size, policy) # 申請device側記憶體
其中,dev_ptr是device側記憶體指標,size是device側記憶體大小。
這裡我們分配了跟Host側同樣大小的記憶體,準備用於在Device側存放推理資料。本介面最後一個引數policy是記憶體分配規則。
ACL_MEM_MALLOC_HUGE_FIRST ----- 優先申請大頁記憶體,如果大頁記憶體不夠,則使用普通頁的記憶體。 ACL_MEM_MALLOC_HUGE_ONLY ----- 僅申請大頁,如果大頁記憶體不夠,則返回錯誤。 ACL_MEM_MALLOC_NORMAL_ONLY ----- 僅申請普通頁。
使用完別忘了釋放申請過的記憶體:acl.rt.malloc-> acl.rt.free,切記!!!
介面介紹:

函數範例:
def gen_data_buffer(size, des): global model_desc func = buffer_method[des] for i in range(size): temp_buffer_size = acl.mdl.get_output_size_by_index(model_desc, i) temp_buffer, ret = acl.rt.malloc(temp_buffer_size, const.ACL_MEM_MALLOC_NORMAL_ONLY) check_ret("acl.rt.malloc", ret) if des == "in": input_data.append({"buffer": temp_buffer, "size": temp_buffer_size}) elif des == "out": output_data.append({"buffer": temp_buffer, "size": temp_buffer_size}) def malloc_device(input_num, output_num): gen_data_buffer(input_num, des="in") gen_data_buffer(output_num, des="out")
5.6 圖片處理(DVPP)
數位視覺預處理模組(DVPP)作為昇騰AI軟體棧中的編解碼和影象轉換模組,為神經網路發揮著預處理輔助功能。當來自系統記憶體和網路的視訊或影象資料進入昇騰AI處理器的計算資源中運算之前,由於Davinci架構對輸入資料有固定的格式要求,如果資料未滿足架構規定的輸入格式、解析度等要求,就需要呼叫數位視覺處理模組進行格式的轉換,才可以進行後續的神經網路計算步驟。
DVPP相關介面介紹:
讀取、初始化圖片:
AclImage(image_file)
圖片預處理:
yuv_image=jpegd(image)
將輸入圖片縮放為輸出尺寸:
resized_image = _dvpp.resize(yuv_image, MODEL_WIDTH, MODEL_HEIGHT)
函數範例:
def image_process_dvpp(): global run_mode global images_list stream, ret = acl.rt.create_stream() check_ret("acl.rt.create_stream", ret) run_mode, ret = acl.rt.get_run_mode() check_ret("acl.rt.get_run_mode", ret) _dvpp = Dvpp(stream, run_mode) _dvpp.init_resource() IMG_EXT = ['.jpg', '.JPG', '.png', '.PNG', '.bmp', '.BMP', '.jpeg', '.JPEG'] images_list = [os.path.join("./data", img) for img in os.listdir("./data") if os.path.splitext(img)[1] in IMG_EXT] img_list = [] for image_file in images_list: image = AclImage(image_file) image_input = image.copy_to_dvpp() yuv_image = _dvpp.jpegd(image_input) resized_image = dvpp.resize(yuv_image, MODEL_WIDTH, MODEL_HEIGHT) img_list.append(resized_image) print("dvpp_process image: {} success".format(image_file)) return img_list
5.7 資料傳輸
5.7.1 host傳輸資料至device
把資料從Host側拷貝至Device側:
acl.rt.memcpy(dst, dest_max, src, count, direction)
引數的順序是:目的記憶體地址,目的記憶體最大大小,源記憶體地址,拷貝長度,拷貝方向。
direction拷貝方向當前支援四種:
ACL_MEMCPY_HOST_TO_HOST ----- host->host ACL_MEMCPY_HOST_TO_DEVICE ----- host->device ACL_MEMCPY_DEVICE_TO_HOST ----- device->host ACL_MEMCPY_DEVICE_TO_DEVICE ----- device->device
該步驟已在DVPP介面內自動完成。
介面介紹:


函數範例:
def _data_interaction_in(dataset): global input_data temp_data_buffer = input_data for i in range(len(temp_data_buffer)): item = temp_data_buffer[i] ptr = acl.util.numpy_to_ptr(dataset) ret = acl.rt.memcpy(item["buffer"], item["size"], ptr, item["size"], ACL_MEMCPY_HOST_TO_DEVICE) check_ret("acl.rt.memcpy", ret)
5.7.2 準備推理所需資料結構
模型推理所需的輸入輸出資料,是通過一種特定的資料結構來組織的,這種資料結構叫「dataSet」,即所有的輸入,組成了1個dateset,所有的輸出組成了一個dataset。而對於很多模型來講,輸入其實不止一個,那麼所有的輸入集合叫「dataSet」,其中的每一個輸入叫什麼呢?
答案是「dataBuffer」。即一個模型的多個輸入,每個輸入是一個「dataBuffer」,所有的dataBuffer構成了一個「dataSet」。
下面我們從構建dataBuffer開始。
dataBuffer的建立很簡單,還記得前邊我們申請了Device側的記憶體,並且把資料傳過去了嗎?現在要用到了。我們當時的device側記憶體地址:data,這段記憶體的長度:size。使用上邊兩個物件來建立一個dataBuffer:
acl.create_data_buffer(data, size)
現在,這個「buffer」就是我們的第一個輸入了。
介面介紹:

函數範例:
def create_buffer(dataset, type="in"): global input_data, output_data if type == "in": temp_dataset = input_data else: temp_dataset = output_data for i in range(len(temp_dataset)): item = temp_dataset[i] data = acl.create_data_buffer(item["buffer"], item["size"]) if data is None: ret = acl.destroy_data_buffer(dataset) check_ret("acl.destroy_data_buffer", ret) _, ret = acl.mdl.add_dataset_buffer(dataset, data) if ret != ACL_ERROR_NONE: ret = acl.destroy_data_buffer(dataset) check_ret("acl.destroy_data_buffer", ret)
針對本實驗所用到的 resnet50 模型,我們只需要一個輸入即可,那現在有了dataBuffer,要如何構建dataSet呢?
很簡單:
acl.mdl.create_dataset()
dataset有了,下面就是向這個dataset中放置DataBuffer了:
acl.mdl.add_dataset_buffer(dataset, data)
這樣,我們在dataset中新增了一個databuffer,輸入準備好了。
建立輸出資料結構同理,當您拿到一個模型,您應該是清楚這個模型的輸出資料結構的,根據其輸出個數、每個輸出佔用記憶體的大小來申請相應的device記憶體、dataBuffer以及dataSet即可。
現在假設我們已經建立好了輸出的dataset,其變數名稱叫做:
outputDataSet
至此,我們準備好了推理所需的所有素材。
當然,將來用完之後別忘了銷燬:
acl.create_data_buffer-> acl.destory_data_buffer; acl.mdl.create_dataset-> acl.mdl.destroy_dataset
介面介紹:



函數範例:
def _gen_dataset(type="in"): global load_input_dataset, load_output_dataset dataset = acl.mdl.create_dataset() if type == "in": load_input_dataset = dataset else: load_output_dataset = dataset create_buffer(dataset, type)
5.8 推理
所有素材準備好之後,模型推理已經是順理成章的事情了,還記得我們的幾個關鍵素材嗎?
model_id
load_input_dataset
load_output_dataset
最終的推理,其實只需要一行程式碼:
ret = acl.mdl.execute(model_id, input, output)
這是個同步介面,執行緒會阻塞在這裡直到推理結束。推理結束後就可以提取load_output_dataset中的資料進行使用了。
介面介紹:

函數範例:
def inference(model_id, _input, _output): global load_input_dataset, load_output_dataset ret = acl.mdl.execute(model_id, load_input_dataset, load_output_dataset) check_ret("acl.mdl.execute", ret)
5.9 後處理
5.9.1釋放資源
資源有申請就要有釋放,呼叫以下介面釋放之前申請的dataset和databuffer:
ret = acl.mdl.destroy_dataset(dataset)
ret = acl.destory_data_buffer(data_buffer)
介面介紹:

函數範例:
def _destroy_data_set_buffer(): global load_input_dataset, load_output_dataset for dataset in [load_input_dataset, load_output_dataset]: if not dataset: continue num = acl.mdl.get_dataset_num_buffers(dataset) for i in range(num): data_buf = acl.mdl.get_dataset_buffer(dataset, i) if data_buf: ret = acl.destroy_data_buffer(data_buf) check_ret("acl.destroy_data_buffer", ret) ret = acl.mdl.destroy_dataset(dataset) check_ret("acl.mdl.destroy_dataset", ret)
5.9.2 申請host記憶體
建立outputDataset的時候,您應該使用了device側的記憶體,將這部分記憶體拷貝回host側,即可直接使用了。
申請Host側記憶體:
host_ptr是host側記憶體指標,隨後即可使用host_ptr指向的記憶體來暫存推理輸入資料。把資料從device側拷貝至host側:
ret = acl.rt.memcpy(dst, dest_max, src, count, direction)
引數的順序是:目的記憶體地址,目的記憶體最大大小,源記憶體地址,拷貝長度,拷貝方向。(支援host->host, host->device, device->host, device->device四種,與申請device記憶體相同)
使用完別忘了釋放申請過的記憶體:
acl.rt.malloc_host-> acl.rt.free_host
介面介紹:

函數範例:
def _data_interaction_out(dataset): global output_data temp_data_buffer = output_data if len(dataset) == 0: for item in output_data: temp, ret = acl.rt.malloc_host(item["size"]) if ret != 0: raise Exception("can't malloc_host ret={}".format(ret)) dataset.append({"size": item["size"], "buffer": temp}) for i in range(len(temp_data_buffer)): item = temp_data_buffer[i] ptr = dataset[i]["buffer"] ret = acl.rt.memcpy(ptr, item["size"], item["buffer"], item["size"], ACL_MEMCPY_DEVICE_TO_HOST) check_ret("acl.rt.memcpy", ret)
5.9.3 獲取推理結果並列印
將推理後的結果資料轉換為numpy型別,然後按照圖片分類置信度前五的順序列印出來。
結果範例如下:

介面介紹:

函數範例:
def print_result(result): global images_list, INDEX dataset = [] for i in range(len(result)): temp = result[i] size = temp["size"] ptr = temp["buffer"] data = acl.util.ptr_to_numpy(ptr, (size,), 1) dataset.append(data) st = struct.unpack("1000f", bytearray(dataset[0])) vals = np.array(st).flatten() top_k = vals.argsort()[-1:-6:-1] print() print("======== image: {} =============".format(images_list[INDEX])) print("======== top5 inference results: =============") INDEX+=1 for n in top_k: object_class = get_image_net_class(n) print("label:%d confidence: %f, class: %s" % (n, vals[n], object_class))
6. 完整樣例演示
ACL完整程式範例:
import argparse import numpy as np import struct import acl import os from PIL import Image import sys home_path = get_ipython().getoutput('echo ${HOME}') sys.path.append(os.path.join(home_path[0] , "jupyter-notebook/")) print('System init success.') from src.acl_dvpp import Dvpp import src.constants as const from src.acl_image import AclImage from src.image_net_classes import get_image_net_class WORK_DIR = os.getcwd() ACL_MEM_MALLOC_HUGE_FIRST = 0 ACL_MEMCPY_HOST_TO_DEVICE = 1 ACL_MEMCPY_DEVICE_TO_HOST = 2 ACL_ERROR_NONE = 0 MODEL_WIDTH = 224 MODEL_HEIGHT = 224 IMG_EXT = ['.jpg', '.JPG', '.png', '.PNG', '.bmp', '.BMP', '.jpeg', '.JPEG'] ret = acl.init() # GLOBAL load_input_dataset = None load_output_dataset = None input_data = [] output_data = [] _output_info = [] images_list = [] model_desc = 0 run_mode = 0 INDEX = 0 if WORK_DIR.find("src") == -1: MODEL_PATH = WORK_DIR + "/src/model/googlenet_yuv.om" DATA_PATH = WORK_DIR + "/src/data" else: MODEL_PATH = WORK_DIR + "/model/googlenet_yuv.om" DATA_PATH = WORK_DIR + "/data" buffer_method = { "in": acl.mdl.get_input_size_by_index, "out": acl.mdl.get_output_size_by_index } def check_ret(message, ret): if ret != ACL_ERROR_NONE: raise Exception("{} failed ret={}" .format(message, ret)) def init(): ret = acl.init() check_ret("acl.init", ret) print("init success") def allocate_res(device_id): ret = acl.rt.set_device(device_id) check_ret("acl.rt.set_device", ret) context, ret = acl.rt.create_context(device_id) check_ret("acl.rt.create_context", ret) print("allocate_res success") return context def load_model(model_path): model_id, ret = acl.mdl.load_from_file(model_path) check_ret("acl.mdl.load_from_file", ret) print("load_model success") return model_id def get_model_data(model_id): global model_desc model_desc = acl.mdl.create_desc() ret = acl.mdl.get_desc(model_desc, model_id) check_ret("acl.mdl.get_desc", ret) input_size = acl.mdl.get_num_inputs(model_desc) output_size = acl.mdl.get_num_outputs(model_desc) print("get_model_data success") return input_size, output_size def gen_data_buffer(num, des): global model_desc func = buffer_method[des] for i in range(num): #temp_buffer_size = (model_desc, i) temp_buffer_size = acl.mdl.get_output_size_by_index(model_desc, i) temp_buffer, ret = acl.rt.malloc(temp_buffer_size, const.ACL_MEM_MALLOC_NORMAL_ONLY) check_ret("acl.rt.malloc", ret) if des == "in": input_data.append({"buffer": temp_buffer, "size": temp_buffer_size}) elif des == "out": output_data.append({"buffer": temp_buffer, "size": temp_buffer_size}) def malloc_device(input_num, output_num): gen_data_buffer(input_num, des="in") gen_data_buffer(output_num, des="out") def image_process_dvpp(dvpp): global run_mode global images_list # _dvpp.init_resource() IMG_EXT = ['.jpg', '.JPG', '.png', '.PNG', '.bmp', '.BMP', '.jpeg', '.JPEG'] images_list = [os.path.join(DATA_PATH, img) for img in os.listdir(DATA_PATH) if os.path.splitext(img)[1] in IMG_EXT] img_list = [] for image_file in images_list: #讀入圖片 image = AclImage(image_file) image_input = image.copy_to_dvpp() #對圖片預處理 yuv_image = dvpp.jpegd(image_input) resized_image = dvpp.resize(yuv_image, MODEL_WIDTH, MODEL_HEIGHT) img_list.append(resized_image) print("dvpp_process image: {} success".format(image_file)) return img_list def _data_interaction_in(dataset): global input_data temp_data_buffer = input_data for i in range(len(temp_data_buffer)): item = temp_data_buffer[i] ptr = acl.util.numpy_to_ptr(dataset) ret = acl.rt.memcpy(item["buffer"], item["size"], ptr, item["size"], ACL_MEMCPY_HOST_TO_DEVICE) check_ret("acl.rt.memcpy", ret) print("data_interaction_in success") def create_buffer(dataset, type="in"): global input_data, output_data if type == "in": temp_dataset = input_data else: temp_dataset = output_data for i in range(len(temp_dataset)): item = temp_dataset[i] data = acl.create_data_buffer(item["buffer"], item["size"]) if data is None: ret = acl.destroy_data_buffer(dataset) check_ret("acl.destroy_data_buffer", ret) _, ret = acl.mdl.add_dataset_buffer(dataset, data) if ret != ACL_ERROR_NONE: ret = acl.destroy_data_buffer(dataset) check_ret("acl.destroy_data_buffer", ret) #print("create data_buffer {} success".format(type)) def _gen_dataset(type="in"): global load_input_dataset, load_output_dataset dataset = acl.mdl.create_dataset() #print("create data_set {} success".format(type)) if type == "in": load_input_dataset = dataset else: load_output_dataset = dataset create_buffer(dataset, type) def inference(model_id, _input, _output): global load_input_dataset, load_output_dataset ret = acl.mdl.execute(model_id, load_input_dataset, load_output_dataset) check_ret("acl.mdl.execute", ret) def _destroy_data_set_buffer(): global load_input_dataset, load_output_dataset for dataset in [load_input_dataset, load_output_dataset]: if not dataset: continue num = acl.mdl.get_dataset_num_buffers(dataset) for i in range(num): data_buf = acl.mdl.get_dataset_buffer(dataset, i) if data_buf: ret = acl.destroy_data_buffer(data_buf) check_ret("acl.destroy_data_buffer", ret) ret = acl.mdl.destroy_dataset(dataset) check_ret("acl.mdl.destroy_dataset", ret) def _data_interaction_out(dataset): global output_data temp_data_buffer = output_data if len(dataset) == 0: for item in output_data: temp, ret = acl.rt.malloc_host(item["size"]) if ret != 0: raise Exception("can't malloc_host ret={}".format(ret)) dataset.append({"size": item["size"], "buffer": temp}) for i in range(len(temp_data_buffer)): item = temp_data_buffer[i] ptr = dataset[i]["buffer"] ret = acl.rt.memcpy(ptr, item["size"], item["buffer"], item["size"], ACL_MEMCPY_DEVICE_TO_HOST) check_ret("acl.rt.memcpy", ret) def print_result(result): global images_list, INDEX dataset = [] for i in range(len(result)): temp = result[i] size = temp["size"] ptr = temp["buffer"] data = acl.util.ptr_to_numpy(ptr, (size,), 1) dataset.append(data) st = struct.unpack("1000f", bytearray(dataset[0])) vals = np.array(st).flatten() top_k = vals.argsort()[-1:-6:-1] print() print("======== image: {} =============".format(images_list[INDEX])) print("======== top5 inference results: =============") INDEX+=1 for n in top_k: object_class = get_image_net_class(n) print("label:%d confidence: %f, class: %s" % (n, vals[n], object_class)) def release(model_id, context): global input_data, output_data ret = acl.mdl.unload(model_id) check_ret("acl.mdl.unload", ret) while input_data: item = input_data.pop() ret = acl.rt.free(item["buffer"]) check_ret("acl.rt.free", ret) while output_data: item = output_data.pop() ret = acl.rt.free(item["buffer"]) check_ret("acl.rt.free", ret) if context: ret = acl.rt.destroy_context(context) check_ret("acl.rt.destroy_context", ret) context = None ret = acl.rt.reset_device(0) check_ret("acl.rt.reset_device", ret) print('release source success') def main(): global input_data #init() context = allocate_res(0) model_id = load_model(MODEL_PATH) input_num, output_num = get_model_data(model_id) malloc_device(input_num, output_num) dvpp = Dvpp() img_list = image_process_dvpp(dvpp) for image in img_list: image_data = {"buffer":image.data(), "size":image.size} input_data[0] = image_data _gen_dataset("in") _gen_dataset("out") inference(model_id, load_input_dataset, load_output_dataset) _destroy_data_set_buffer() res = [] _data_interaction_out(res) print_result(res) release(model_id,context) if __name__ == '__main__': main()
更多有關ACL的介紹,請詳見官方參考檔案 。