關於 Flink 狀態與容錯機制
Flink 作為新一代基於事件流的、真正意義上的流批一體的巨量資料處理引擎,正在逐漸得到廣大開發者們的青睞。就從我自身的視角看,最近也是在資料團隊把一些原本由 Flume、SparkStreaming、Storm 編寫的流式作業往 Flink 遷移,它們之間的優劣對比本篇暫不討論。
近期會總結一些 Flink 的使用經驗和原理的理解,本篇先談談 Flink 中的狀態和容錯機制,這也是 Flink 核心能力之一,它支撐著 Flink Failover,甚至在較新的版本中,Flink 的 Queryable State 可以把內部狀態提供到外部系統進行查詢進而為一些 BI 大屏等資料場景提供直接的支援。
關於有狀態計算
先說說什麼是有狀態計算,「狀態」的概念比較寬泛,它既可以是 Flink 在執行過程中不斷產生的一些聚合指標,例如『每分鐘活躍使用者量』、『每小時系統成交額』等等之類被實時不斷聚合的變數。也可以是 Flink 視窗計算中未達到觸發條件前的資料集、也可以是 Kafka、Pulsar 等佇列的消費位移。
狀態分類
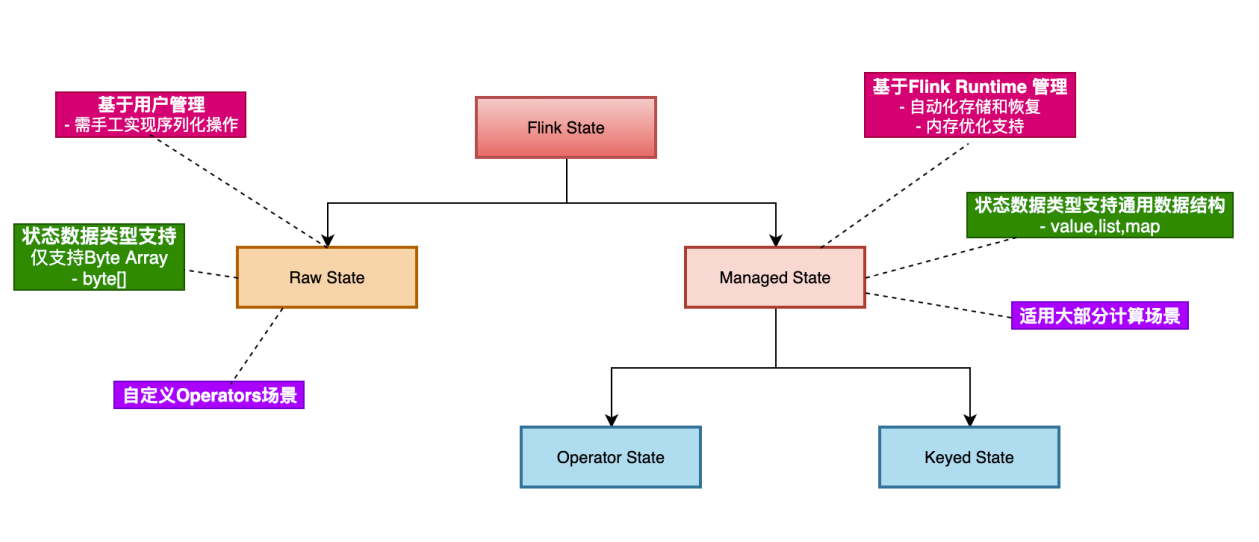
Flink 中的狀態從管理方式上來說,分為 Raw State 和 Managed State。其中,Raw State 是完全由使用者管理的,使用者需要實現狀態的序列化和反序列化且支援的資料型別有限制,一般很少會用到,除非在一些需要自定義運算元實現的場景下,Flink 自帶的一些狀態無法派上用場並且需要使用狀態的場景下才會使用。
Managed State 根據資料流是否經過 「keyBy」運算元,分為 Keyed State 和 Operate State。其實這倆的區別不是太大,Keyed State 只是一種特殊情況下的 Operate State,本質上他們還是使用 Flink 預定義好的一些狀態型別。

官網的解釋已經很清楚了,這裡直接複製過來,作一些補充解釋。其中
ValueState 就是可以儲存一個值,可以理解為一個普通變數; ListState 是由一個 List 實現的列表,可以儲存一個狀態集合; ReducingState 儲存一個單值,並且需要你提供 ReducingFunction,它會在裡往裡面新增元素的同時呼叫你的函數自動聚合結果,但要求型別統一,你不能兩次 add 元素型別是不同的; AggregatingState 允許你輸入和輸出的資料型別不一樣,也就是我 add(float) 得到 int 是被允許的,具體邏輯怎麼轉換取決於你的 AggregateFunction。
那麼,再來說說 Keyed State 和 Operate State 的區別,資料流 「keyBy」之後產生 KeyedStream,下游運算元收到的資料元素具有相同的 key,那麼對於這些運算元中使用的狀態就叫 Keyed State,它會自動繫結 key,一個 key 對應一個 State 儲存,也就是不同 key 的 State 是分開的。
而 Operate State 並不是基於 KeyedStream,所以在這些運算元裡使用狀態,其實繫結的是當前運算元範例上,需要注意的是,繫結的是運算元範例,也就是和你的並行度是有關係的。下文我會說狀態的儲存,其實狀態是儲存在 TaskManager 節點原生的。
狀態後端
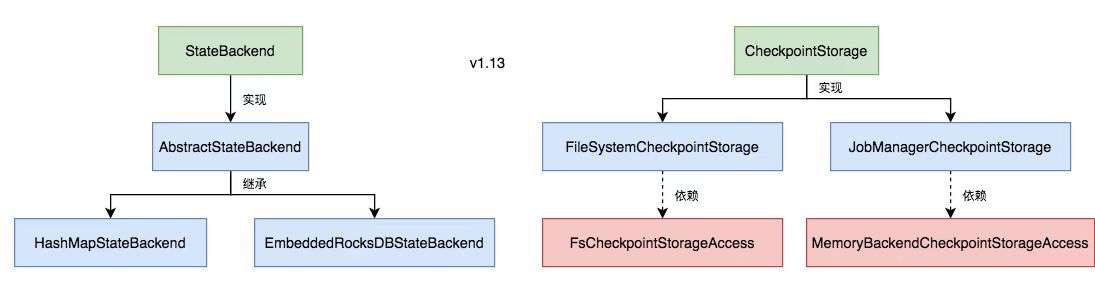
顧名思義,狀態後端其實指的就是狀態的儲存方式以及位置。Flink1.13 以前把普通狀態和 job checkpoint(快照檔案) 的後端儲存設定是在一起的。分為 MemoryStateBackend、FsStateBackend、RocksDBStateBackend,分別是基於記憶體、檔案系統以及 RocksDb(一種KV型別的本地儲存DB)。
而 Flink1.13 以後將普通資料狀態和 checkpoint 的狀態儲存後端分離了,HashMapStateBackend、EmbeddedRocksDBStateBackend 是普通狀態的兩個後端,分別是基於記憶體 HashMap 和 基於 RocksDb 兩種後端。checkpoint 的設定也分為記憶體和檔案系統(file、hdfs、rocksDb等)。也就是你可能有多種組合,資料狀態儲存在記憶體而 checkpoint 卻儲存在檔案系統等。
//設定記憶體狀態後端
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new HashMapStateBackend());
//設定RocksDb狀態後端
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new EmbeddedRocksDBStateBackend());
//設定checkpoint記憶體儲存
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
//設定checkpoint檔案儲存
env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir");
env.getCheckpointConfig().setCheckpointStorage("hdfs://namenode:40010/flink/checkpoints");
關於 Checkpoint & Savepoint
上文也多次提到了 Checkpoint,其實它是 Flink Failover 的基礎,在 Flink 中叫做檢查點,簡單來說就是它把 job 執行過程中各個運算元中的狀態快照儲存到狀態後端,當 job 發生異常即可從最近的 Checkpoint 檔案恢復故障前各個運算元中資料處理現場。
Savepoint 和 Checkpoint 本質上是一個東西,只不過 Checkpoint 由 Flink 管理觸發和儲存,而 Savepoint 一般是使用者主動通過命令去觸發並指定檔案輸出路徑。Checkpoint 是用於故障恢復,Savepoint 一般用於程式升級。
實現原理
Aligned Checkpoints(對齊)
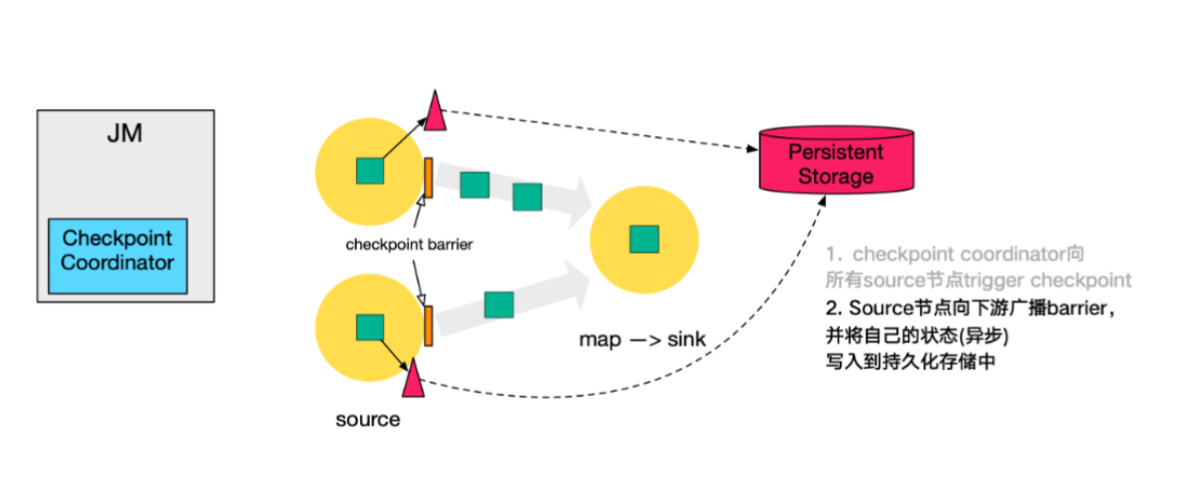
每個 Jobmanager 都有一個元件 checkpointCoordinator 負責整個 job 的 Checkpoint 觸發,它會根據使用者設定的生成 Checkpoint 間隔時間,定時往 source 資料流中插入特殊資料(barrier),然後 barrier 資料就像普通資料一樣流向下游運算元,下游運算元在收到 barrier 資料之後會停止處理資料等待「對齊」。
這個「對齊」操作一直是效能瓶頸,它指的是某個運算元只有等到所有上游範例的 barrier 事件之後才會開始做 Checkpoint,一個簡單 union 例子:A、B 兩股資料流合併到 C,那麼 C 只有收到 A 和 B 兩條流的 barrier 事件之後才會做 Checkpoint。
其實也比較容易理解,假如 A 做完 Checkpoint 並將自己處理到的資料偏移量記錄到快照中,向 C 傳播 barrier 事件,B 負載比較高還沒開始做,那麼如果當 C 只收到 A 的 barrier 事件後就開始做 Checkpoint 並剛好在它做完之後發生 job 故障並開始恢復,那麼 B 其實是沒有做完 Checkpoint 的,只能恢復到上一次的,這就直接導致上次以來所有的資料處理需要重複處理。這是比較大的問題,所以有個「對齊」操作。
以上只是基於沒有「對齊」操作的前提下做的假設,回到正常的處理流程上來。每個運算元在自己做完 Checkpoint 後就會通知 checkpointCoordinator 並告知快照檔案儲存位置,當最後一個運算元完成了 Checkpoint,那麼整個 Checkpoint 流程 Completed。
UnAligned Checkpoints(非對齊)
上文其實也提到了,對齊的 Checkpoint 存在比較大的效能瓶頸,一方面會阻塞資料流正常處理,另一方面可能會導致 Flink 反壓進而導致 Checkpoint 超時 job 失敗並積壓更多的資料待處理,反壓的問題待會兒說,先看下非對齊特性。
Flink1.11 以後加入了 UnAligned Checkpoints,但仍不是預設設定,需要顯式設定,原因是非對齊的方式會產生比較大的 State 用於快取一些資料,仍然只適用於一些容易高反壓且複雜難以優化的 job。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enables the unaligned checkpoints
env.getCheckpointConfig().enableUnalignedCheckpoints();
Chandy-Lamport 演演算法的狀態變化如下:
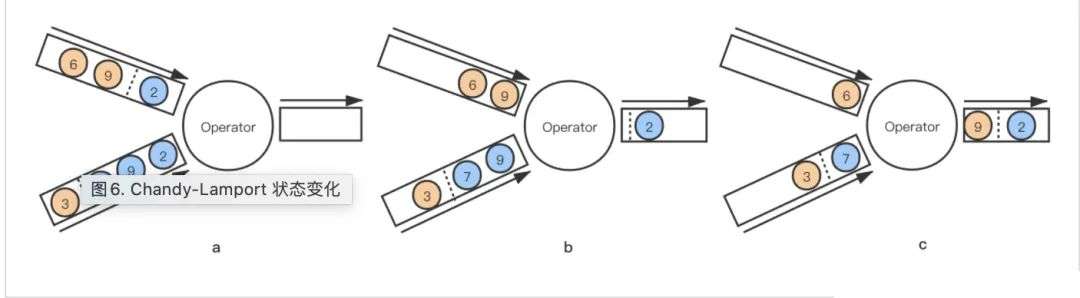
對於非對齊的 Checkpoint 來說,任意一條流的 barrier 事件到來都將直接觸發當前運算元的 Checkpoint。以上圖來說,上面的流稱為 A 流,下面的流稱為 B 流,虛線是 barrier 事件,我們假設這是一個 equals-join 操作。
當 A 流中的資料「2」流過 Operator 並且和 B 流中的資料「2」join 成功,Operator 運算元向下遊輸出資料「2」 然後收到 A 流的 barrier 事件,Operator 運算元當即開啟本運算元的 Checkpoint 並向下遊輸出 barrier,此時這個 Checkpoint 已經是一個 Running 的狀態 這時 B 流過來的每一條資料都會被快取在狀態中,直到收到 B 流的 barrier 事件,這期間 A 流和 B 流是正常 join 處理的,完全無阻塞的 當收到來自 B 流的 barrier,停止對 B 流資料的快取,完成當前運算元的非同步快照(快照中會包含所有快取的B流資料)
這樣,其實不論哪個時間點出現 job 的故障恢復,從 Checkpoint 恢復出來運算元對齊的狀態+快取(會被恢復到輸出channel)的資料即可保證資料處理現場都是正確的。但是缺點比較明顯,就是需要儲存大容量的狀態,Checkpoint 檔案也是很大,job 恢復的速度也會比較慢。
關於 Flink 反壓
反壓就是指 Flink 中上下游運算元資料處理能力不匹配,下游運算元處理太慢,上游運算元傳送區資料溢位。反壓造成的最常見的影響就是造成 Checkpoint 超時,進而的 job 故障恢復。
Credit-Based 反壓機制
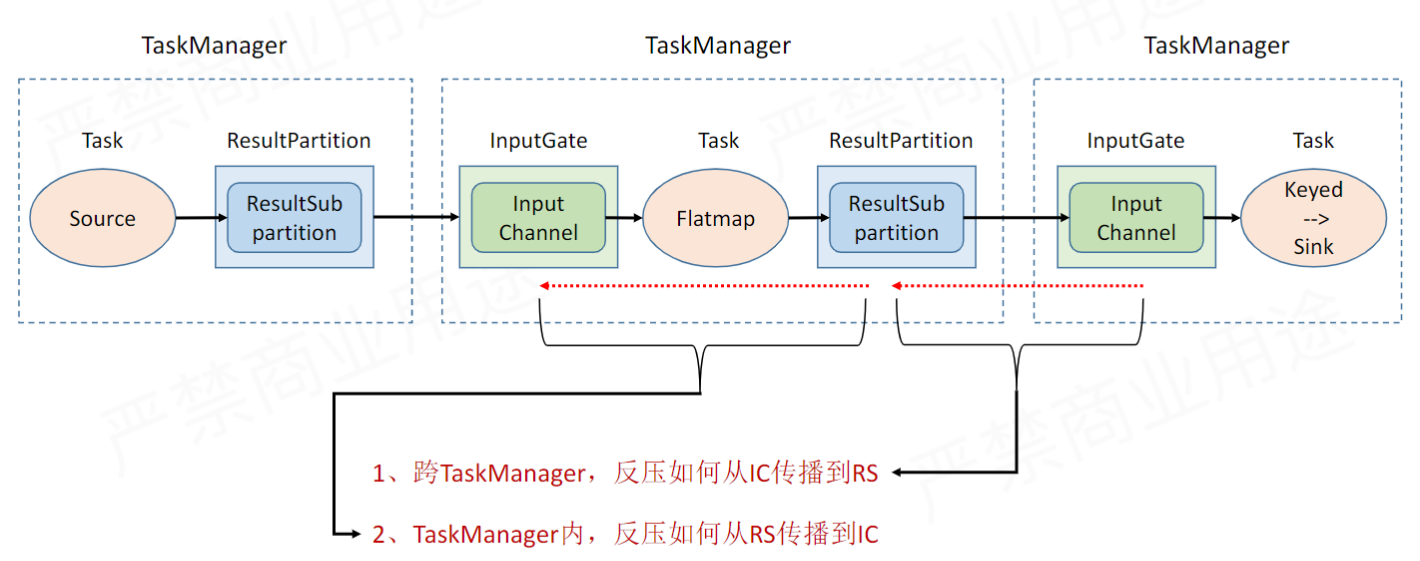
反壓其實主要就分為兩個部分,一個是運算元與運算元之間,下游運算元要通過反壓限制上游運算元的傳送速率,另一個是每個運算元內部,寫操作要反壓限制讀操作的讀取速率。
TaskManager 間反壓機制
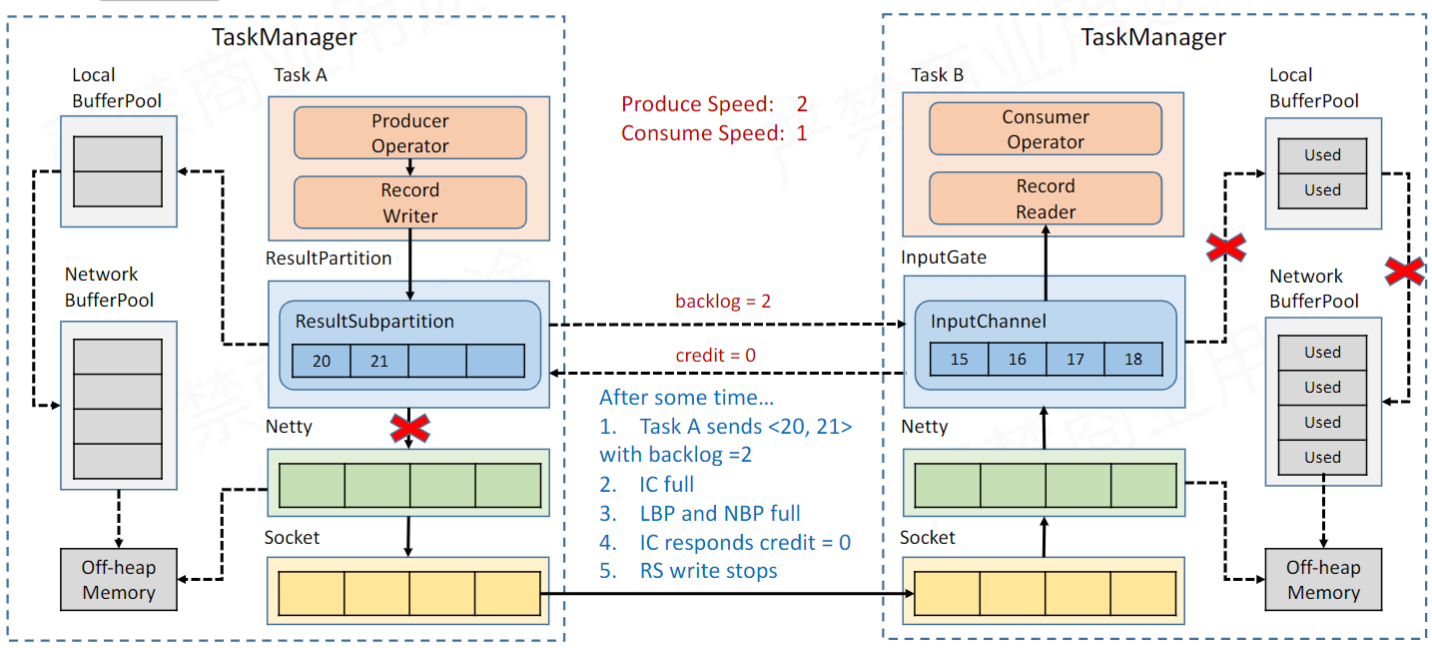
這張圖展示了 Flink 運算元跨節點通訊的基本流程,NetWorkBufferPool 在每個 TaskManager 管理著網路通訊相關的緩衝區記憶體申請釋放; LocalBufferPool 是每個運算元內部的緩衝池,從 NetWorkBufferPool 申請而來;ResultSubpartition 是寫出緩衝區,從 LocalBufferPool 申請而來;InputChannel 是讀緩衝區,從 LocalBufferPool 申請而來。
整體的流程就是,Writer 寫資料到 ResultSubpartition,再往下傳到 Netty,最終通過 Socket 發到其他節點,其他節點通過 Reader 讀取資料寫入 InputChannel。
Credit 也叫授信機制,每次從寫緩衝區往下游節點寫資料的時候會通過「backlog」告訴下游的 Reader 自己還積壓多少資料未傳送。而下游 Reader 接收資料的同時會去檢查自己是否還有足夠的空間放下未來即將到來的資料,通過「credit」反應出來,如果沒有足夠的空間且向 LocalBufferPool 申請無果就會返回「credit=0」。
Writer 得到「credit=0」後會阻塞往 Netty 寫資料的操作,進而緩解了下游運算元的壓力(有探活機制,一旦檢測到下游可寫會恢復寫操作的)
TaskManager 內部反壓機制
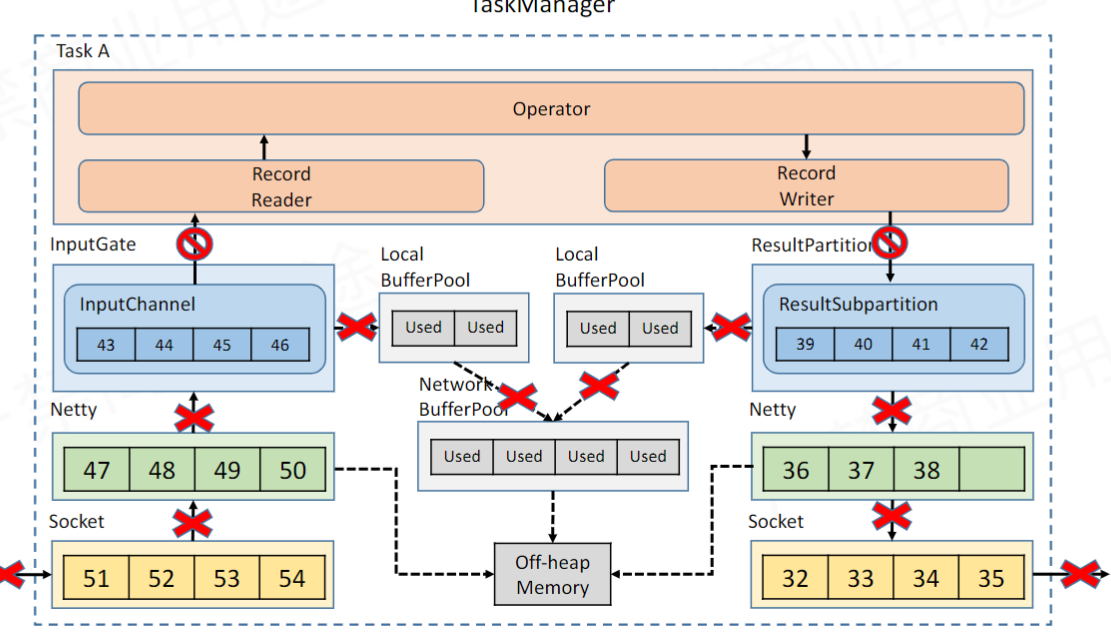
上面談到下游反饋回來的「credit=0」會阻塞自己對外的輸出操作,那麼它也應該傳播反壓到當前節點的讀操作。其實 Flink 裡面是把 Reader 和 Writer 放在一個執行緒裡的,那麼如果寫被阻塞了,讀就自然被阻塞住。
這樣上游運算元就會迅速填滿 InputChannel,自動觸發反壓,向上一級級傳播,完成整個反壓的全域性調整。
到這裡其實反壓就介紹完了,上文說道反壓會影響到 Checkpoint,就是說一級級反壓的結果就是整個 job 中資料流動緩慢,以至於 Checkpoint barrier 在一定時間內沒有完成對齊進而會導致 Checkpoint 超時失敗,任務重啟,然後由於重啟回退又有更嚴重的資料積壓,形成惡性迴圈。(也就是非對齊 Checkpoint 要解決的問題)
歡迎交流~
