系統總出故障怎麼辦,或許你該學學穩定性建設!

大家好,我是樹哥。
說到系統穩定性,不知道大家會想起什麼?我想大多數人會覺得這個詞挺虛的,不知道系統穩定性指的是什麼。一年前的我看到這個詞,也是類似於這樣的感受,大概只知道要消除單點、做好監控報警,但卻並沒有一個體系化的方法論。經過一段時間的摸索,我對系統穩定性有了較為體系化的認識,於是迫不及待地希望和大家一起分享。所以今天,就讓我跟大家簡單聊聊系統穩定性建設這個話題吧!
何謂穩定性?
系統穩定性,從字面上來看,就是讓系統儘可能穩定,不要出問題。 但業務是變化的,系統肯定也是一直變化的,有可能新加了個功能就把系統搞掛了,也有可能突然業務流量暴增把系統搞掛了。所以,要保障系統穩定性可謂非常之難。但即使再難,也還是得去做,但到底怎麼做呢?
我們要保障系統穩定性,那就需要知道哪些因素可能會造成系統不穩定。我自己來了一個頭腦風暴,把所有可能造成系統不穩定的因素整理一下,下面是我梳理的會造成系統不穩定的部分因素:
- 未測試需求直接上線
- 上線的需求產品不知道
- 上線的新需求有 bug
- 頻繁釋出需求
- 釋出緊急需求
- 上線後沒有線上驗證
- 系統設計方案存在缺陷
- 系統程式碼實現存在缺陷
- 漏測了某個功能
- 上線時操作失誤
- 下游服務掛了
- 網路中斷導致呼叫失敗
- 上游呼叫流量突增,沖垮服務
- 應用伺服器記憶體溢位 OOM
- 應用伺服器 CPU 100%
- 資料庫主從延遲了
- 資料庫主庫掛了
- Kafka 訊息擠壓了
- Redis 響應緩慢
- 第三方服務商掛了
- 潛在的駭客攻擊
- 潛在的系統漏洞
是不是感覺特別多,看起來有點暈了?別怕,其實我們可以將所有的不穩定因素根據時間維度,將其分為三大類:上線前、上線時、上線後。
- 上線前的不穩定因素。 這塊指的是需求上線前的所有內容,包括需求評審、技術方案設計、程式碼編寫、功能測試等等。
- 上線時的不穩定因素。 這塊指的是上線時可能的不穩定因素,包括操作失誤、某個功能有問題導致線上出問題等等。
- 上線後的不穩定因素。 這塊指的是需求上線後,有可能出現的各種各樣的問題,例如中介軟體掛了、網路掛了等等。
我們現在已經知道哪個環節可能會出什麼問題,那麼接下來就是針對每個環境做一些特定的動作,從而提高系統穩定性了!
上線前
很多時候我們都以為系統穩定只是線上執行穩定就好了,但事實上需求研發流程是否規範,也會極大地影響到系統的穩定性。試想一下,如果誰都可以隨便提需求、做的功能沒有做方案設計、誰都可以直接操作線上伺服器,那麼這樣的系統服務能夠穩定得了嗎?所以說,需求上線前的過程也是影響系統穩定性的重大因素。
在我看來,在上線前這個階段,主要有三大塊非常重要的穩定性建設內容,分別是:
- 開發流程規範
- 釋出流程規範
- 高可用設計
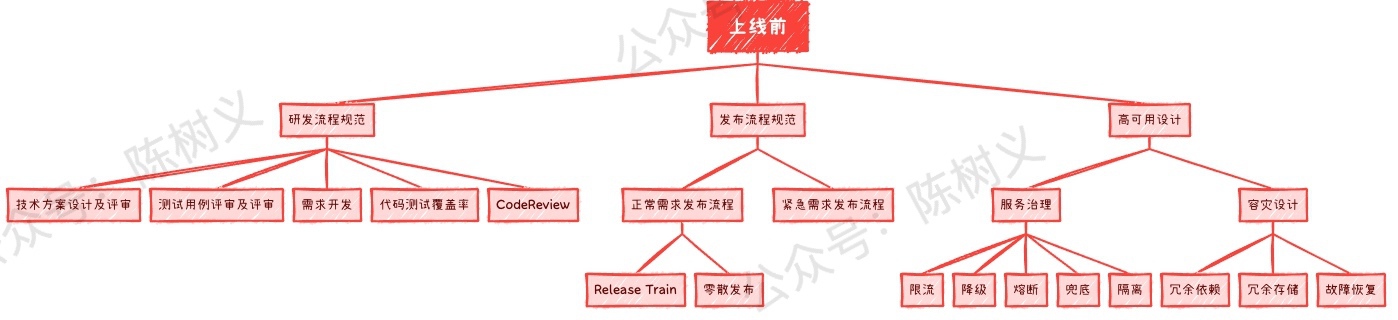
研發流程規範
研發流程規範,指的是一個需求從提出到完成的整個過程應該是怎樣流轉的。一般的需求研發流程包括:產品提出需求、技術預研、需求評審、技術方案設計、測試用例評審、技術方案評審、測試用例評審、需求開發、CodeReview、需求測試。不同公司根據情況會有所調整,但大差不差。
在這個流程中,與研發相關的幾個比較重要的節點是:技術方案設計及評審、測試用例評審及評審、需求開發、程式碼測試覆蓋率、CodeReview。 我們上面提到的幾個影響穩定性的因素,就是因為沒有做好這幾個節點的工作導致的,包括:
- 未測試需求直接上線
- 上線的需求產品不知道
- 上線的新需求有 bug
- 上線後沒有線上驗證
- 系統設計方案存在缺陷
- 系統程式碼實現存在缺陷
如果能夠處理好上述幾個節點,那麼就能夠極大地降低研發流程導致的問題。這裡每個節點都有很深的學問,這裡就不展開講了,我們主要說個思路。
釋出流程規範
釋出流程規範主要是為了控制釋出許可權以及頻率的問題。
在專案初始,為了快速響應業務,一般許可權控制都很鬆,很多人都可以進行線上服務的釋出。但隨著業務越來越多、流量越來越大,相對應的故障也越來越多,到了某個時候就需要對許可權做管控,並且需要對需求的釋出頻率做控制。
對於需求釋出流程來說,一般有幾種釋出方式,分別是:Release Train 方式、零散發布方式。 Release Train 意思是固定時間視窗釋出,例如每週四釋出一次。如果無法趕上這次釋出時間,那麼就需要等到下次釋出視窗。零散發布方式,指的是有需要就釋出,不做釋出時間控制。但這種方式一般只在專案初期發揮作用,後期一般都會收緊。
除此之外,釋出流程中都會設有緊急釋出流程,即如果某個需求特別重要,或者有緊急漏洞需要修復,那麼可以通過該流程來緊急修復,從而避免因未到時間視窗而對業務產生影響。但一般來說,緊急釋出流程都比較麻煩,除非迫不得已不然不要審批通過,不然 Release Train 方式可能會退化成零散發布方式。
高可用設計
高可用設計指的是為了讓系統在各種異常情況下都能正常工作,從而使得系統更加穩定。 其實這塊應該是屬於研發流程規範中的技術方案設計的,但研發流程規範更加註重於規範,高可用設計更加註重高可用。另外,也由於高可用設計是非常重要,因此獨立拿出來作為一塊來說說。
對於高可用設計來說,一般可分為兩大塊,分別是:服務治理和容災設計。
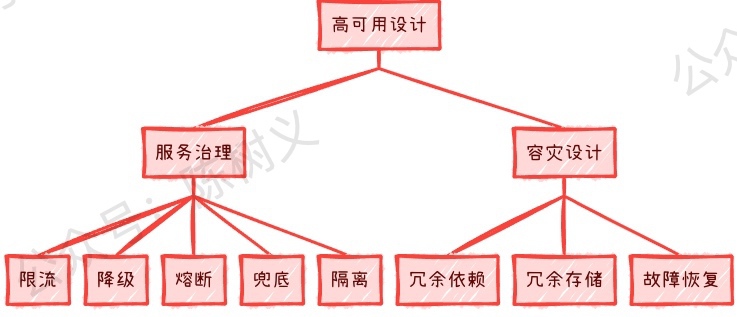
服務治理就包括了限流、降級、熔斷、兜底、隔離等,這一些考慮點都是為了讓系統在某些特殊情況下,都能穩定工作。 例如限流是為了在上游請求量太大的時候,系統不至於被巨大的流量擊垮,還可以正常提供服務。
容災設計應該說是更加高階點的設計了,指的是當下遊系、第三方、中介軟體掛了,如何保證系統還能正常執行? 可以說容災設計比起服務治理,其面臨的情況更加糟糕。例如支付系統最終是通過 A 服務商進行支付的,如果 A 服務商突然掛了,那我們的支付系統是不是就掛了?那有什麼辦法可以在這種情況(災難)發生的時候,讓我們的系統還能夠正常提供服務呢?這就是容災設計需要做的事情了。
上線時
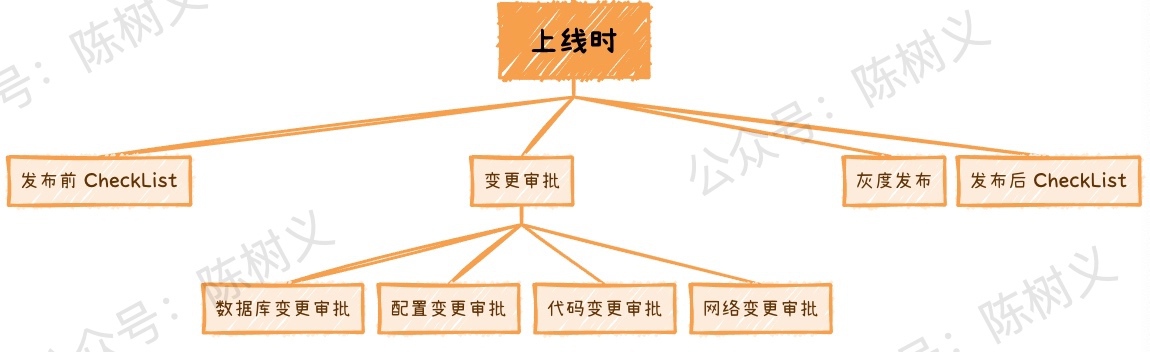
上線時這個階段,主要是確保功能按照原先設計的方案進行部署,這個階段主要是確保規範操作,避免失誤,因此可以制定相關的 CheckList 以及變更審批。其次,為了避免還可能存在未發現的功能缺陷,有時候還可以使用灰度釋出降低風險。在這個階段能做的一些穩定性建設如下圖所示。
上線後
當系統成功上線後,很多小夥伴以為工作就結束了,但實際上我們還有不少工作可以做。根據我的經驗,在上線後我們能做的穩定性建設包括:
- 監控報警
- 故障管理
- 緊急處理預案
- 容災演練
- 案例學習
- 全鏈路壓測

監控報警,指的是我們需要對應用做好執行資料的收集,監控好系統的執行狀態。當系統狀態異常時,我們需要及時地發現並報警,從而讓研發人員快速地解決問題。 一般來說,監控報警分為系統級別的監控報警和業務級別的監控報警。系統級別的監控報警包括 CPU、記憶體、磁碟等伺服器資源的監控,而業務級別的報警則需要根據業務情況自行定義。
故障管理,就是當發生故障時,我們需要遵循的整套處理規範。 團隊小的時候可能無所謂,但是當團隊大了的時候,我們就需要統一大家的故障處理流程,從而可以更快速地解決故障。此外,在故障解決完成之後還需要進行復盤,產出對應的故障報告。
Case Study 機制指的是定期學習其他團隊的高可用或者線上故障進行學習,從而提高團隊的系統設計能力,避免踩坑。
容災演練,其實就是模擬某些中介軟體或者服務故障,然後看看系統是否能按照之前設計的高可用方案實施。 容災演練是提升系統穩定性的一把利器,很多時候即使我們設計得很完美,但實際上卻沒發揮作用,究其根本就是沒有實踐過。是驢是馬,得拉出來溜溜才知道。
緊急處理預案,簡單就是要想到各種可能發現的情況,然後做好預案。 之後結合容災演練不斷進行優化,從而形成一套很好的處理預案。這樣當線上發生類似故障時,就可以輕鬆應對了。
全鏈路壓測,指的是對整個鏈路進行壓測。 不同公司可能會採用不同的方案,有些會直接線上上進行壓測,然後用流量標記的方式識別測試流量。有些則是進行流量錄製,之後重新搭建一套與線上非常類似的系統進行壓測。一般來說,第一種效果肯定會更好,成本也更低,但是對研發人員要求也更高,風險也更大。
總結
今天我們簡單地從上線前、上線時、上線後去探討了如何做穩定性建設,其中每一塊都可以展開來講很多內容。例如監控報警這塊,那我們應該監控系統的哪些指標?其實這些都是有一些成熟的方案了,例如要監控 TP90、響應延遲、呼叫延時、訊息處理延時等。
但出於篇幅原因,我們今天只是蜻蜓點水,點到為止,後續繼續再慢慢不斷完善,純當拋磚引玉吧。如果大家感興趣的話,可以關注下樹哥,後面我再慢慢一點點寫。最後,丟一個思維導圖,作為今天文章的結尾。

好了,這就是今天分享的全部內容了。
如果你喜歡今天的分享,記得一鍵三連支援我!你的鼓勵,是我寫文章最大的動力!
參考資料
- 專訪美團外賣曹振團:天下武功唯快不破 - 美團技術團隊
- 美團外賣使用者端高可用建設體系 - 美團技術團隊
- 專訪美團外賣曹振團:天下武功唯快不破 - 美團技術團隊
- 智慧支付穩定性測試實戰 - 美團技術團隊
- 大眾點評賬號業務高可用進階之路 - 美團技術團隊
- 大眾點評支付渠道閘道器系統的實踐之路 - 美團技術團隊
- 高可用性系統在大眾點評的實踐與經驗 - 美團技術團隊
- 美團外賣訂單中心的演進 - 美團技術團隊
- 服務容錯模式 - 美團技術團隊
- 美團資料庫高可用架構的演進與設想 - 美團技術團隊
- VIP!美團點評智慧支付核心交易系統的可用性實踐 - 美團技術團隊
- MECE分析法--周全邏輯的思考框架基礎 - 知乎
