【機器學習】支援向量機分類
2022-07-13 09:01:17
前言
支援向量機是一類按監督學習方式對資料進行二元分類的廣義線性分類器,其決策邊界是對學習樣本求解的最大邊距超平面。SVM嘗試尋找一個最優決策邊界,使距離兩個類別最近的樣本最遠。
SVM使用鉸鏈損失函數計算經驗風險並在求解系統中加入了正則化項以優化結構風險,是一個具有稀疏性和穩健性的分類器 。SVM可以通過核方法(kernel method)進行非線性分類,是常見的核學習(kernel learning)方法之一
SVM原理
-
引入

-
直觀理解
- 對資料進行分類,當超平面資料點‘間隔’越大,分類的確信度也越大。
- 我們上面用的棍子就是分類平面。
-
支援向量
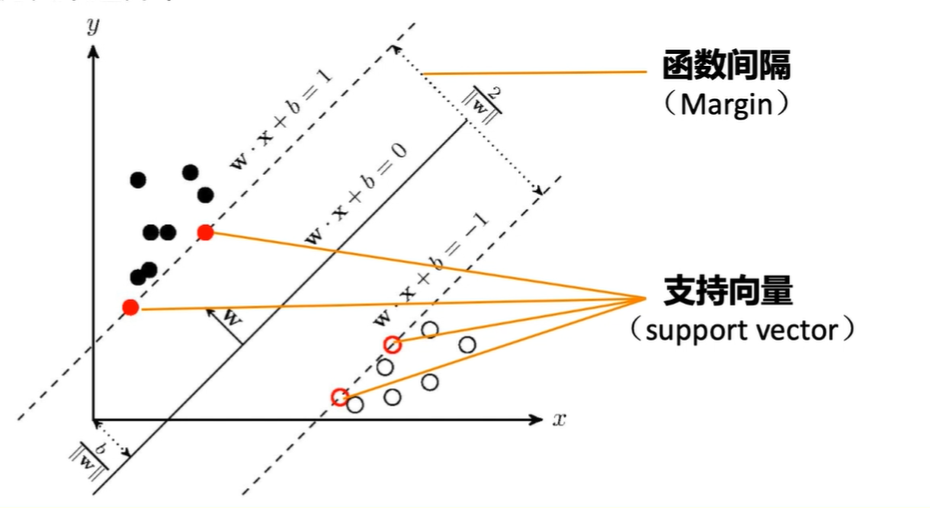
- 我們可以看到決定分割面其實只有上面4個紅色的點決定的,這四個點就叫做支援向量。
非線性SVM與核函數
如何變幻空間
對於非線性的資料我們是通過核函數把資料分為不同的平面在進行處理。
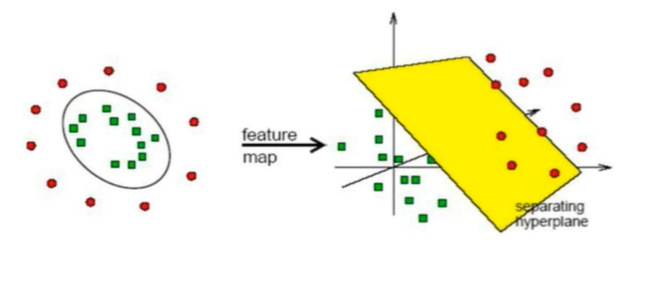
- 核函數
- 線性核函數:K(x,z) = x*z
- 多項式核函數:K(x,z) = (x*z+1)^p
- 高斯核函數:K(x,z) = exp(\(\frac{-|x-z|^2}{z*a^2}\))
- 混合核:K(x,z) = aK1(x,z)+(1-a)K2(x,z), 0<=a<1\
多分類處理應用
-
一對多法(OVR SVMs)
- 訓練時依次把某個類別樣本歸為一類,其他剩餘樣本歸為一類
- k個SVM:分類時將未知樣本分類為具有最大分類函數值的那類
-
一對一法(OVO SVMs或者pairwise)
- 在任意兩類樣本之間設計一個SVM
- k(k-1)/2個SVM
- 當對一個未知樣本進行分類時,最後得票最多的類別即為該未知樣本的類。
-
層次SVM
- 層次分類法首先將所有類別分成兩個子類,再將子類進一步劃分成兩個次級子類,如此迴圈,直到得到一個單獨的類別為止。類似與二元樹分類。
優點
- 相對於其他分類演演算法不需要過多樣本,並且由於SVM引入核函數,所以SVM可以處理高維樣本。
- 結構風險最小,這種風險是指分類器對問題真實模型的逼近與問題真實解之間的累計誤差。
- 非線性,是指SVM擅長應對樣本傳輸線性不可分的情況,主要通過鬆弛變數(懲罰變數)和核函數技術來實現,這也是SVM的精髓所在。
開源包
LibSVM:https://www.csie.ntu.edu.tw/~cjlin/libsvm/
Liblinear:https://www.csie.ntu.edu.tw/~cjlin/liblinear/
資料集
資料集是使用sklearn包中的資料集。也可以下載下來方便使用。
百度網路硬碟:
連結:https://pan.baidu.com/s/16H2xRXQItIY0hU0_wIAvZw
提取碼:vq2i
SVM實現鳶尾花分類
- 程式碼
## 資料集 sklearn中
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib import colors
from sklearn import svm
from sklearn import model_selection
## 載入資料集
def iris_type(s):
it = {b'Iris-setosa':0, b'Iris-versicolor':1, b'Iris-virginica':2}
return it[s]
data = np.loadtxt('Iris-data/iris.data',dtype=float,delimiter=',',converters={4:iris_type})
x,y = np.split(data, (4, ), axis=1)
x = x[:,:2]
x_train,x_test, y_train, y_test = model_selection.train_test_split(x,y,random_state=1,test_size=0.2)
## 構建SVM分類器,訓練函數
def classifier():
clf = svm.SVC(C=0.8, kernel='linear', decision_function_shape='ovr')
return clf
def train(clf, x_train, y_train):
clf.fit(x_train, y_train.ravel())
clf = classifier()
train(clf,x_train,y_train)
## 初始化分類器,訓練模型
def show_accuracy(a, b, tip):
acc = a.ravel()==b.ravel()
print('%s accracy:%.3f'%(tip, np.mean(acc)))
## 展示訓練結果,及驗證結果
def print_accracy(clf, x_train, y_train, x_test, y_test):
print('training prediction:%.3f'%(clf.score(x_train, y_train)))
print('test prediction:%.3f'%(clf.score(x_test, y_test)))
show_accuracy(clf.predict(x_train),y_train, 'training data')
show_accuracy(clf.predict(x_test), y_test, 'testing data')
print('decision_function:\n',clf.decision_function(x_train)[:2])
print_accracy(clf, x_train, y_train, x_test, y_test)
def draw(clf, x):
iris_feature = 'sepal length', 'sepal width', 'petal length', 'petal width'
x1_min,x1_max = x[:,0].min(), x[:,0].max()
x2_min,x2_max = x[:,1].min(), x[:,1].max()
x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j]
grid_test = np.stack((x1.flat, x2.flat), axis=1)
print('grid_test:\n',grid_test[:2])
z = clf.decision_function(grid_test)
print('the distance:',z[:2])
grid_hat = clf.predict(grid_test)
print(grid_hat[:2])
grid_hat = grid_hat.reshape(x1.shape)
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'b', 'r'])
plt.pcolormesh(x1, x2, grid_hat, cmap=cm_light)
plt.scatter(x[:,0], x[:, 1],c=np.squeeze(y), edgecolors='k', s=50, cmap=cm_dark)
plt.scatter(x_test[:,0],x_test[:,1], s=120, facecolor='none', zorder=10)
plt.xlabel(iris_feature[0])
plt.ylabel(iris_feature[1])
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title('Iris data classification via SVM')
plt.grid()
plt.show()
draw(clf, x)
結果展示
可以看到分類效果和之前的k-means聚類效果圖是差不多的。
有興趣的可以看看k-means聚類進行分類:
使用k-means聚類對鳶尾花進行分類:https://www.cnblogs.com/hjk-airl/p/16410359.html
-
分類效果圖
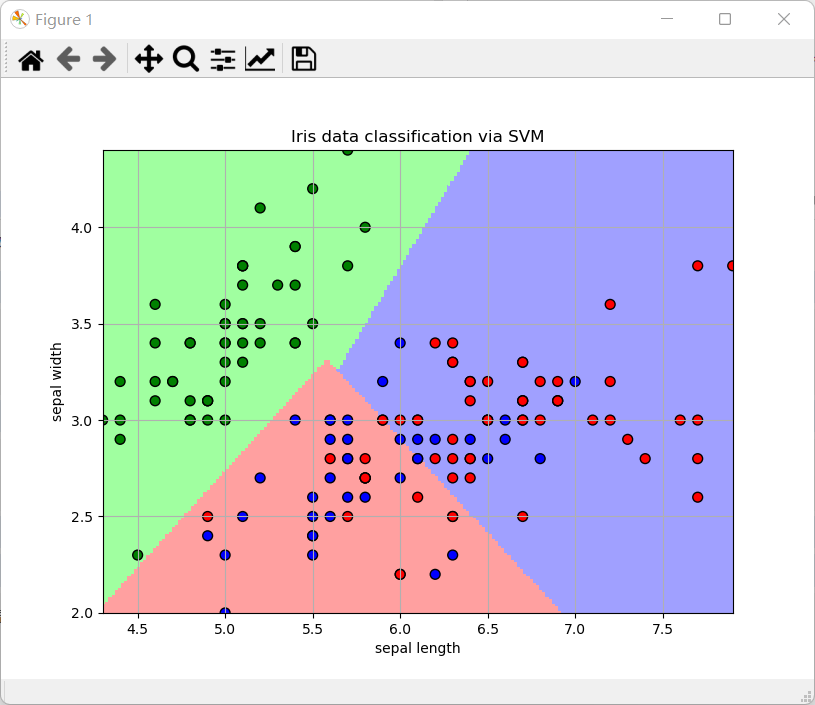
-
分類結果引數
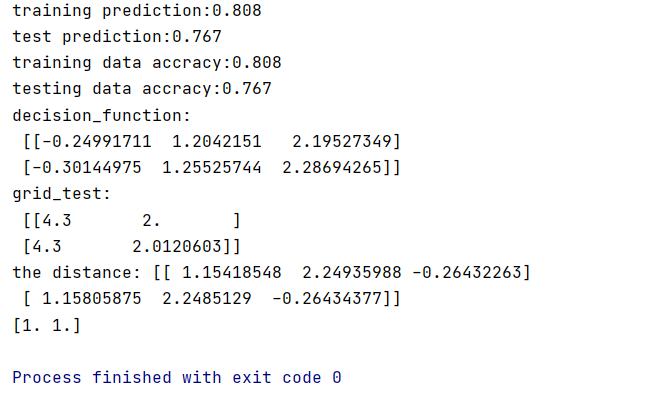
總結
可以看到SVM鳶尾花分類和K-means聚類是不同的,但是都可以達到分類的效果。