00 預訓練語言模型的前世今生(全文 24854 個詞)
預訓練語言模型的前世今生 - 從Word Embedding到BERT
本篇文章共 25027 個詞,一個字一個字手碼的不容易,轉載請標明出處:
預訓練語言模型的前世今生 - 從Word Embedding到BERT - 二十三歲的有德
Bert 最近很火,應該是最近最火爆的 AI 進展,網上的評價很高,從模型創新角度看一般,創新不算大。但是架不住效果太好了,基本重新整理了很多 NLP 的任務的最好效能,有些任務還被刷爆了,這個才是關鍵。另外一點是 Bert 具備廣泛的通用性,就是說絕大部分 NLP 任務都可以採用類似的兩階段模式直接去提升效果,這個第二關鍵。客觀的說,把 Bert 當做最近兩年 NLP 重大進展的集大成者更符合事實。
本文的主題是預訓練語言模型的前世今生,會大致說下 NLP 中的預訓練技術是一步一步如何發展到 Bert 模型的,從中可以很自然地看到 Bert 的思路是如何逐漸形成的,Bert 的歷史沿革是什麼,繼承了什麼,創新了什麼,為什麼效果那麼好,主要原因是什麼,以及為何說模型創新不算太大,為何說 Bert 是近年來 NLP 重大進展的集大成者。
預訓練語言模型的發展並不是一蹴而就的,而是伴隨著諸如詞嵌入、序列到序列模型及 Attention 的發展而產生的。
DeepMind 的電腦科學家 Sebastian Ruder 給出了 21 世紀以來,從神經網路技術的角度分析,自然語言處理的里程碑式進展,如下表所示:
| 年份 | 2013 年 | 2014 年 | 2015 年 | 2016 年 | 2017 年 |
|---|---|---|---|---|---|
| 技術 | word2vec | GloVe | LSTM/Attention | Self-Attention | Transformer |
| 年份 | 2018 年 | 2019 年 | 2020 年 |
|---|---|---|---|
| 技術 | GPT/ELMo/BERT/GNN | XLNet/BoBERTa/GPT-2/ERNIE/T5 | GPT-3/ELECTRA/ALBERT |
本篇文章將會通過上表顯示的 NLP 中技術的發展史一一敘述,由於 19 年後的技術大都是 BERT 的變體,在這裡不會多加敘述,讀者可以自行加以瞭解。
一、預訓練
1.1 影象領域的預訓練
在介紹影象領域的預訓練之前,我們首先介紹下折積神經網路(CNN),CNN 一般用於圖片分類任務,並且CNN 由多個層級結構組成,不同層學到的影象特徵也不同,越淺的層學到的特徵越通用(橫豎撇捺),越深的層學到的特徵和具體任務的關聯性越強(人臉-人臉輪廓、汽車-汽車輪廓),如下圖所示:

由此,當領導給我們一個任務:阿貓、阿狗、阿虎的圖片各十張,然後讓我們設計一個深度神經網路,通過該網路把它們三者的圖片進行分類。
對於上述任務,如果我們親手設計一個深度神經網路基本是不可能的,因為深度學習一個弱項就是在訓練階段對於資料量的需求特別大,而領導只給我們合計三十張圖片,顯然這是不夠的。
雖然領導給我們的資料量很少,但是我們是否可以利用網上現有的大量已做好分類標註的圖片。比如 ImageNet 中有 1400 萬張圖片,並且這些圖片都已經做好了分類標註。

上述利用網路上現有圖片的思想就是預訓練的思想,具體做法就是:
- 通過 ImageNet 資料集我們訓練出一個模型 A
- 由於上面提到 CNN 的淺層學到的特徵通用性特別強,我們可以對模型 A 做出一部分改進得到模型 B(兩種方法):
- 凍結:淺層引數使用模型 A 的引數,高層引數隨機初始化,淺層引數一直不變,然後利用領導給出的 30 張圖片訓練引數
- 微調:淺層引數使用模型 A 的引數,高層引數隨機初始化,然後利用領導給出的 30 張圖片訓練引數,但是在這裡淺層引數會隨著任務的訓練不斷髮生變化

通過上述的講解,對影象預訓練做個總結(可參照上圖):對於一個具有少量資料的任務 A,首先通過一個現有的大量資料搭建一個 CNN 模型 A,由於 CNN的淺層學到的特徵通用性特別強,因此在搭建一個 CNN 模型 B,其中模型 B 的淺層引數使用模型 A 的淺層引數,模型 B 的高層引數隨機初始化,然後通過凍結或微調的方式利用任務 A 的資料訓練模型 B,模型 B 就是對應任務 A 的模型。
1.2 預訓練的思想
有了影象領域預訓練的引入,我們在此給出預訓練的思想:任務 A 對應的模型 A 的引數不再是隨機初始化的,而是通過任務 B 進行預先訓練得到模型 B,然後利用模型 B 的引數對模型 A 進行初始化,再通過任務 A 的資料對模型 A 進行訓練。注:模型 B 的引數是隨機初始化的。
二、語言模型
想了解預訓練語言模型,首先得了解什麼是語言模型。
語言模型通俗點講就是計算一個句子的概率。也就是說,對於語言序列 \(w_1,w_2,\cdots,w_n\),語言模型就是計算該序列的概率,即 \(P(w_1,w_2,\cdots,w_n)\)。
下面通過兩個範例具體瞭解上述所描述的意思:
- 假設給定兩句話 「判斷這個詞的磁性」 和 「判斷這個詞的詞性」,語言模型會認為後者更自然。轉化成數學語言也就是:\(P(判斷,這個,詞,的,詞性) \gt P(判斷,這個,詞,的,磁性)\)
- 假設給定一句話做填空 「判斷這個詞的____」,則問題就變成了給定前面的詞,找出後面的一個詞是什麼,轉化成數學語言就是:\(P(詞性|判斷,這個,詞,的) \gt P(磁性|判斷,這個,詞,的)\)
通過上述兩個範例,可以給出語言模型更加具體的描述:給定一句由 \(n\) 個片語成的句子 \(W=w_1,w_2,\cdots,w_n\),計算這個句子的概率 \(P(w_1,w_2,\cdots,w_n)\),或者計算根據上文計算下一個詞的概率 \(P(w_n|w_1,w_2,\cdots,w_{n-1})\)。
下面將介紹語言模型的兩個分支,統計語言模型和神經網路語言模型。
2.1 統計語言模型
統計語言模型的基本思想就是計算條件概率。
給定一句由 \(n\) 個片語成的句子 \(W=w_1,w_2,\cdots,w_n\),計算這個句子的概率 \(P(w_1,w_2,\cdots,w_n)\) 的公式如下(條件概率乘法公式的推廣,鏈式法則):
對於上一節提到的 「判斷這個詞的詞性」 這句話,利用上述的公式,可以得到:
對於上一節提到的另外一個問題,當給定前面詞的序列 「判斷,這個,詞,的」 時,想要知道下一個詞是什麼,可以直接計算如下概率:
其中,\(w_{next} \in V\) 表示詞序列的下一個詞,\(V\) 是一個具有 \(|V|\) 個詞的詞典(詞集合)。
對於公式(1),可以展開成如下形式:
對於公式(2),可以把字典 \(V\) 中的多有單詞,逐一作為 \(w_{next}\),帶入計算,最後取最大概率的詞作為 \(w_{next}\) 的候選詞。
如果 \(|V|\) 特別大,公式(2)的計算將會非常困難,但是我們可以引入馬爾科夫鏈的概念(當然,在這裡只是簡單講講如何做,關於馬爾科夫鏈的數學理論知識可以自行檢視其他參考資料)。
假設字典 \(V\) 中有 「火星」 一詞,可以明顯發現 「火星」 不可能出現在 「判斷這個詞的」 後面,因此(火星,判斷,這個,詞,的)這個組合是不存在的,並且詞典中會存在很多類似於 「火星」 這樣的詞。
進一步,可以發現我們把(火星,判斷,這個,詞,的)這個組合判斷為不存在,是因為 「火星」 不可能出現在 「詞的」 後面,也就是說我們可以考慮是否把公式(1)轉化為
公式(3)就是馬爾科夫鏈的思想:假設 \(w_{next}\) 只和它之前的 \(k\) 個詞有相關性,\(k=1\) 時稱作一個單元語言模型,\(k=2\) 時稱為二元語言模型。
可以發現通過馬爾科夫鏈後改寫的公式計算起來將會簡單很多,下面我們舉個簡單的例子介紹下如何計算一個二元語言模型的概率。
其中二元語言模型的公式為:
假設有一個文字集合:
「詞性是動詞」
「判斷單詞的詞性」
「磁性很強的磁鐵」
「北京的詞性是名詞」
對於上述文字,如果要計算 \(P(詞性|的)\) 的概率,通過公式(4),需要統計 「的,詞性」 同時按序出現的次數,再除以 「的」 出現的次數:
上述文字集合是我們自客製化的,然而對於絕大多數具有現實意義的文字,會出現資料稀疏的情況,例如訓練時未出現,測試時出現了的未登入單詞。
由於資料稀疏問題,則會出現概率值為 0 的情況(填空題將無法從詞典中選擇一個詞填入),為了避免 0 值的出現,會使用一種平滑的策略——分子和分母都加入一個非 0 正數,例如可以把公式(4)改為:
2.2 神經網路語言模型
上一節簡單的介紹了統計語言模型,並且在結尾處講到統計語言模型存在資料稀疏問題,針對該問題,我們也提出了平滑方法來應對這個問題。
神經網路語言模型則引入神經網路架構來估計單詞的分佈,並且通過詞向量的距離衡量單詞之間的相似度,因此,對於未登入單詞,也可以通過相似詞進行估計,進而避免出現資料稀疏問題。

上圖為神經網路語言模型結構圖,它的學習任務是輸入某個句中單詞 \(w_t = bert\) 前的 \(t-1\) 個單詞,要求網路正確預測單詞 「bert」,即最大化:
上圖所示的神經網路語言模型分為三層,接下來我們詳細講解這三層的作用:
- 神經網路語言模型的第一層,為輸入層。首先將前 \(n-1\) 個單詞用 Onehot 編碼(例如:0001000)作為原始單詞輸入,之後乘以一個隨機初始化的矩陣 Q 後獲得詞向量 \(C(w_i)\),對這 \(n-1\) 個詞向量處理後得到輸入 \(x\),記作 \(x=(C(w_1),C(w_2),\cdots,C(w_{t-1}))\)
- 神經網路語言模型的第二層,為隱層,包含 \(h\) 個隱變數,\(H\) 代表權重矩陣,因此隱層的輸出為 \(Hx+d\),其中 \(d\) 為偏置項。並且在此之後使用 \(tanh\) 作為啟用函數。
- 神經網路語言模型的第三層,為輸出層,一共有 \(|V|\) 個輸出節點(字典大小),直觀上講,每個輸出節點 \(y_i\) 是詞典中每一個單詞概率值。最終得到的計算公式為:\(y = softmax(b+Wx+U\tanh(d+Hx))\),其中 \(W\) 是直接從輸入層到輸出層的權重矩陣,\(U\) 是隱層到輸出層的引數矩陣。
三、詞向量
在描述神經網路語言模型的時候,提到 Onehot 編碼和詞向量 \(C(w_i)\),但是並沒有具體提及他們到底是什麼玩意。
由於他們對於未來 BERT 的講解非常重要,所以在這裡重開一章來描述詞向量到底是什麼,如何表示。
3.1 獨熱(Onehot)編碼
把單詞用向量表示,是把深度神經網路語言模型引入自然語言處理領域的一個核心技術。
在自然語言處理任務中,訓練集大多為一個字或者一個詞,把他們轉化為計算機適合處理的數值類資料非常重要。
早期,人們想到的方法是使用獨熱(Onehot)編碼,如下圖所示:

對於上圖的解釋,假設有一個包含 8 個次的字典 \(V\),「time」 位於字典的第 1 個位置,「banana」 位於字典的第 8 個位置,因此,採用獨熱表示方法,對於 「time」 的向量來說,除了第 1 個位置為 1,其餘位置為 0;對於 「banana」 的向量來說,除了第 8 個位置為 1,其餘位置為 0。
但是,對於獨熱表示的向量,如果採用餘弦相似度計算向量間的相似度,可以明顯的發現任意兩者向量的相似度結果都為 0,即任意二者都不相關,也就是說獨熱表示無法解決詞之間的相似性問題。
3.2 Word Embedding
由於獨熱表示無法解決詞之間相似性問題,這種表示很快就被詞向量表示給替代了,這個時候聰明的你可能想到了在神經網路語言模型中出現的一個詞向量 \(C(w_i)\),對的,這個 \(C(w_i)\) 其實就是單詞對應的 Word Embedding 值,也就是我們這節的核心——詞向量。
在神經網路語言模型中,我們並沒有詳細解釋詞向量是如何計算的,現在讓我們重看神經網路語言模型的架構圖:
上圖所示有一個 \(V×m\) 的矩陣 \(Q\),這個矩陣 \(Q\) 包含 \(V\) 行,\(V\) 代表詞典大小,每一行的內容代表對應單詞的 Word Embedding 值。
只不過 \(Q\) 的內容也是網路引數,需要學習獲得,訓練剛開始用隨機值初始化矩陣 \(Q\),當這個網路訓練好之後,矩陣 \(Q\) 的內容被正確賦值,每一行代表一個單詞對應的 Word embedding 值。
但是這個詞向量有沒有解決詞之間的相似度問題呢?為了回答這個問題,我們可以看看詞向量的計算過程:
通過上述詞向量的計算,可以發現第 4 個詞的詞向量表示為 \([10\,12\,19]\)。
如果再次採用餘弦相似度計算兩個詞之間的相似度,結果不再是 0 ,既可以一定程度上描述兩個詞之間的相似度。
下圖給了網上找的幾個例子,可以看出有些例子效果還是很不錯的,一個單詞表達成 Word Embedding 後,很容易找出語意相近的其它詞彙。

四、Word2Vec 模型
2013 年最火的用語言模型做 Word Embedding 的工具是 Word2Vec ,後來又出了Glove(由於 Glove 和 Word2Vec 的作用類似,並對 BERT 的講解沒有什麼幫助,之後不再多加敘述),Word2Vec是怎麼工作的呢?看下圖:
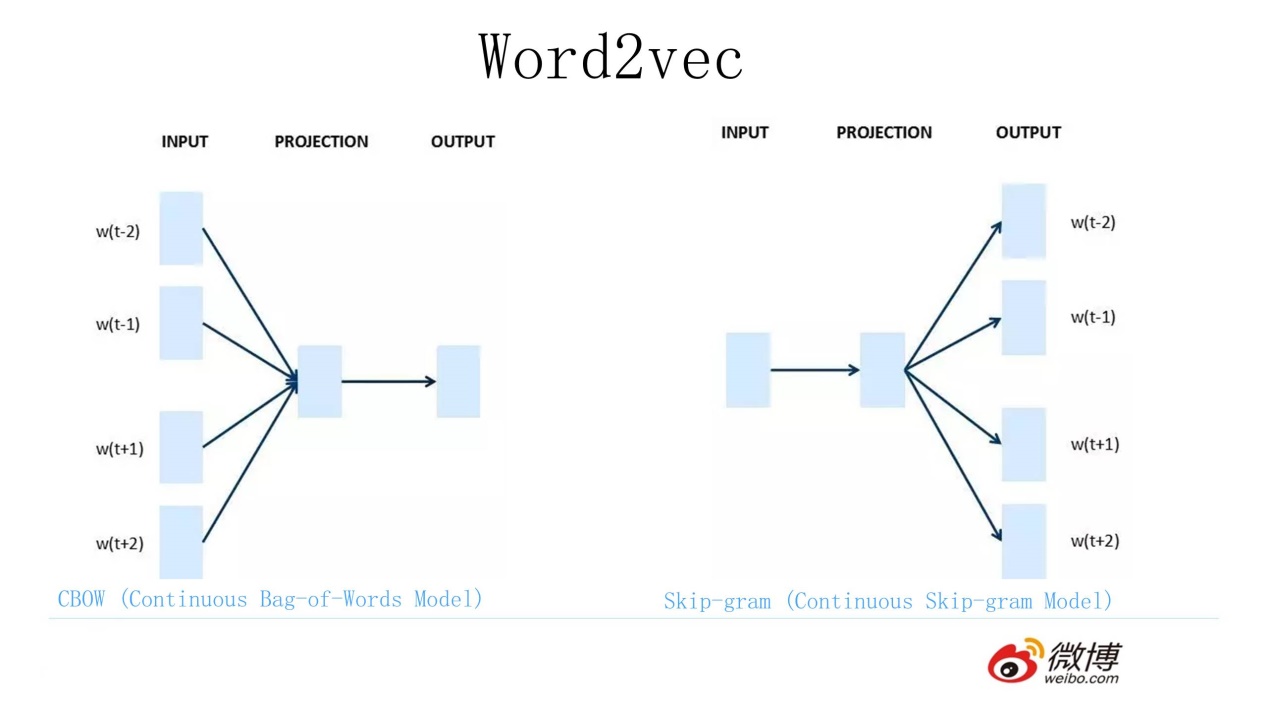
Word2Vec 的網路結構其實和神經網路語言模型(NNLM)是基本類似的,只是這個圖長得清晰度差了點,看上去不像,其實它們是親兄弟。不過這裡需要指出:儘管網路結構相近,而且都是做語言模型任務,但是他們訓練方法不太一樣。
Word2Vec 有兩種訓練方法:
- 第一種叫 CBOW,核心思想是從一個句子裡面把一個詞摳掉,用這個詞的上文和下文去預測被摳掉的這個詞;
- 第二種叫做 Skip-gram,和 CBOW 正好反過來,輸入某個單詞,要求網路預測它的上下文單詞。
而你回頭看看,NNLM 是怎麼訓練的?是輸入一個單詞的上文,去預測這個單詞。這是有顯著差異的。
為什麼 Word2Vec 這麼處理?原因很簡單,因為 Word2Vec 和 NNLM 不一樣,NNLM 的主要任務是要學習一個解決語言模型任務的網路結構,語言模型就是要看到上文預測下文,而 Word Embedding只是 NNLM 無心插柳的一個副產品;但是 Word2Vec 目標不一樣,它單純就是要 Word Embedding 的,這是主產品,所以它完全可以隨性地這麼去訓練網路。
為什麼要講 Word2Vec 呢?這裡主要是要引出 CBOW 的訓練方法,BERT 其實跟它有關係,後面會講解它們之間的關係,當然它們的關係 BERT 作者沒說,是我猜的,至於我猜的對不對,你看完這篇文章之後可以自行判斷。
五、自然語言處理的預訓練模型
突然在文章中插入這一段,其實就是給出一個問題:Word Embedding 這種做法能算是預訓練嗎?這其實就是標準的預訓練過程。要理解這一點要看看學會 Word Embedding 後下遊任務是怎麼使用它的。

假設如上圖所示,我們有個NLP的下游任務,比如 QA,就是問答問題,所謂問答問題,指的是給定一個問題 X,給定另外一個句子 Y,要判斷句子 Y 是否是問題 X 的正確答案。
問答問題假設設計的網路結構如上圖所示,這裡不展開講了,懂得自然懂,不懂的也沒關係,因為這點對於本文主旨來說不關鍵,關鍵是網路如何使用訓練好的 Word Embedding 的。
它的使用方法其實和前面講的 NNLM 是一樣的,句子中每個單詞以 Onehot 形式作為輸入,然後乘上學好的 Word Embedding 矩陣 Q,就直接取出單詞對應的 Word Embedding 了。
這乍看上去好像是個查表操作,不像是預訓練的做法是吧?其實不然,那個Word Embedding矩陣Q其實就是網路 Onehot 層到 embedding 層對映的網路引數矩陣。
所以你看到了,使用 Word Embedding 等價於什麼?等價於把 Onehot 層到 embedding 層的網路用預訓練好的引數矩陣 Q 初始化了。這跟前面講的影象領域的低層預訓練過程其實是一樣的,區別無非 Word Embedding 只能初始化第一層網路引數,再高層的引數就無能為力了。
下游NLP任務在使用 Word Embedding 的時候也類似影象有兩種做法,一種是 Frozen,就是 Word Embedding 那層網路引數固定不動;另外一種是 Fine-Tuning,就是 Word Embedding 這層引數使用新的訓練集合訓練也需要跟著訓練過程更新掉。
上面這種做法就是18年之前NLP領域裡面採用預訓練的典型做法,並且 Word Embedding 其實對於很多下游 NLP 任務是有幫助的,只是幫助沒有大到閃瞎忘記戴墨鏡的圍觀群眾的雙眼而已。
六、RNN 和 LSTM
為什麼要在這裡穿插一個 RNN(Recurrent Neural Network) 和 LSTM(Long Short-Term Memory) 呢?
因為接下來要介紹的 ELMo(Embeddings from Language Models) 模型在訓練過程中使用了雙向長短期記憶網路(Bi-LSTM)。
當然,這裡只是簡單地介紹,想要詳細瞭解的可以去檢視網上鋪天蓋地的參考資料。
6.1 RNN
傳統的神經網路無法獲取時序資訊,然而時序資訊在自然語言處理任務中非常重要。
例如對於這一句話 「我吃了一個蘋果」,「蘋果」 的詞性和意思,在這裡取決於前面詞的資訊,如果沒有 「我吃了一個」 這些詞,「蘋果」 也可以翻譯為喬布斯搞出來的那個被咬了一口的蘋果。
也就是說,RNN 的出現,讓處理時序資訊變為可能。
RNN 的基本單元結構如下圖所示:
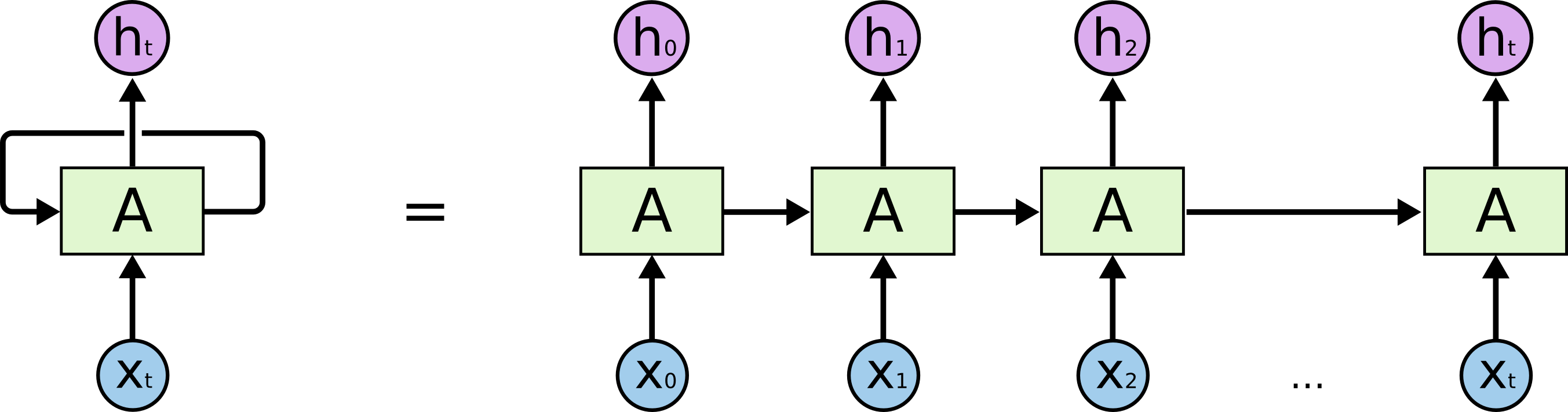
上圖左邊部分稱作 RNN 的一個 timestep,在這個 timestep 中可以看到,在 \(t\) 時刻,輸入變數 \(x_t\),通過 RNN 的一個基礎模組 A,輸出變數 \(h_t\),而 \(t\) 時刻的資訊,將會傳遞到下一個時刻 \(t+1\)。
如果把模組按照時序展開,則會如上圖右邊部分所示,由此可以看到 RNN 為多個基礎模組 A 的互連,每一個模組都會把當前資訊傳遞給下一個模組。
RNN 解決了時序依賴問題,但這裡的時序一般指的是短距離的,首先我們先介紹下短距離依賴和長距離依賴的區別:
- 短距離依賴:對於這個填空題 「我想看一場籃球____」,我們很容易就判斷出 「籃球」 後面跟的是 「比賽」,這種短距離依賴問題非常適合 RNN。
- 長距離依賴:對於這個填空題 「我出生在中國的瓷都景德鎮,小學和中學離家都很近,……,我的母語是____」,對於短距離依賴,「我的母語是」 後面可以緊跟著 「漢語」、「英語」、「法語」,但是如果我們想精確答案,則必須回到上文中很長距離之前的表述 「我出生在中國的瓷都景德鎮」,進而判斷答案為 「漢語」,而 RNN 是很難學習到這些資訊的。
6.2 RNN 的梯度消失問題
在這裡我簡單講解下 RNN 為什麼不適合長距離依賴問題。

如上圖所示,為RNN模型結構,前向傳播過程包括:
- 隱藏狀態:\(h^{(t)} = \sigma (z^{(t)}) = \sigma(Ux^{(t)} + Wh^{(t-1)} + b)\) ,此處啟用函數一般為 \(tanh\) 。
- 模型輸出:\(o^{(t)} = Vh^{(t)} + c\)
- 預測輸出:\(\hat{y}^{(t)} = \sigma(o^{(t)})\) ,此處啟用函數一般為softmax。
- 模型損失:\(L = \sum_{t = 1}^{T} L^{(t)}\)
RNN 所有的 timestep 共用一套引數 \(U,V,W\),在 RNN 反向傳播過程中,需要計算 \(U,V,W\) 等引數的梯度,以 \(W\) 的梯度表示式為例(假設 RNN 模型的損失函數為 \(L\)):
對於公式(9)中的 \(\left( \prod_{k=t + 1}^{T} \frac{\partial h^{(k)}}{\partial h^{(k - 1)}} \right) = \left( \prod_{k=t+1}^{T} tanh^{'}(z^{(k)}) W \right)\),\(\tanh\) 的導數總是小於 1 的,由於是 \(T-(t+1)\) 個 timestep 引數的連乘,如果 \(W\) 的主特徵值小於 1,梯度便會消失;如果 \(W\) 的特徵值大於 1,梯度便會爆炸。
需要注意的是,RNN和DNN梯度消失和梯度爆炸含義並不相同。
RNN中權重在各時間步內共用,最終的梯度是各個時間步的梯度和,梯度和會越來越大。因此,RNN中總的梯度是不會消失的,即使梯度越傳越弱,也只是遠距離的梯度消失。 從公式(9)中的 \(\left( \prod_{k=t+1}^{T} tanh^{'}(z^{(k)}) W \right)\) 可以看到,RNN所謂梯度消失的真正含義是,梯度被近距離(\(t+1 趨向於 T\))梯度主導,遠距離(\(t+1 遠離 T\))梯度很小,導致模型難以學到遠距離的資訊。
6.3 LSTM
為了解決 RNN 缺乏的序列長距離依賴問題,LSTM 被提了出來,首先我們來看看 LSTM 相對於 RNN 做了哪些改進:

如上圖所示,為 LSTM 的 RNN 門控結構(LSTM 的 timestep),LSTM 前向傳播過程包括:
- 遺忘門:決定了丟棄哪些資訊,遺忘門接收 \(t-1\) 時刻的狀態 \(h_{t-1}\),以及當前的輸入 \(x_t\),經過 Sigmoid 函數後輸出一個 0 到 1 之間的值 \(f_t\)
- 輸出: \(f_{t} = \sigma(W_fh_{t-1} + U_fx_{t} + b_f)\)
- 輸入門:決定了哪些新資訊被保留,並更新細胞狀態,輸入們的取值由 \(h_{t-1}\) 和 \(x_t\) 決定,通過 Sigmoid 函數得到一個 0 到 1 之間的值 \(i_t\),而 \(\tanh\) 函數則創造了一個當前細胞狀態的候選 \(a_t\)
- 輸出:\(i_{t} = \sigma(W_ih_{t-1} + U_ix_{t} + b_i)\) , \(\tilde{C_{t} }= tanhW_ah_{t-1} + U_ax_{t} + b_a\)
- 細胞狀態:舊細胞狀態 \(C_{t-1}\) 被更新到新的細胞狀態 \(C_t\) 上,
- 輸出:\(C_{t} = C_{t-1}\odot f_{t} + i_{t}\odot \tilde{C_{t} }\)
- 輸出門:決定了最後輸出的資訊,輸出門取值由 \(h_{t-1}\) 和 \(x_t\) 決定,通過 Sigmoid 函數得到一個 0 到 1 之間的值 \(o_t\),最後通過 \(\tanh\) 函數決定最後輸出的資訊
- 輸出:\(o_{t} = \sigma(W_oh_{t-1} + U_ox_{t} + b_o)\) , \(h_{t} = o_{t}\odot tanhC_{t}\)
- 預測輸出:\(\hat{y}_{t} = \sigma(Vh_{t}+c)\)
6.4 LSTM 解決 RNN 的梯度消失問題
明白了 RNN 梯度消失的原因之後,我們看 LSTM 如何解決問題的呢?
RNN 梯度消失的原因是,隨著梯度的傳導,梯度被近距離梯度主導,模型難以學習到遠距離的資訊。具體原因也就是 \(\prod_{k=t+1}^{T}\frac{\partial h_{k}}{\partial h_{k - 1}}\) 部分,在迭代過程中,每一步 \(\frac{\partial h_{k}}{\partial h_{k - 1}}\) 始終在 [0,1) 之間或者始終大於 1。
而對於 LSTM 模型而言,針對 \(\prod _{k=t+1}^{T} \frac{\partial C_{k}}{\partial C_{k-1}}\) 求得:
在 LSTM 迭代過程中,針對 \(\prod_{k=t+1}^{T} \frac{\partial C_{k}}{\partial C_{k-1}}\) 而言,每一步\(\frac{\partial C_{k}}{\partial C_{k-1}}\) 可以自主的選擇在 [0,1] 之間,或者大於1,因為 \(f_{k}\) 是可訓練學習的。那麼整體 \(\prod _{k=t+1}^{T} \frac{\partial C_{k}}{\partial C_{k-1}}\) 也就不會一直減小,遠距離梯度不至於完全消失,也就能夠解決 RNN 中存在的梯度消失問題。
LSTM 遺忘門值 \(f_t\) 可以選擇在 [0,1] 之間,讓 LSTM 來改善梯度消失的情況。也可以選擇接近 1,讓遺忘門飽和,此時遠距離資訊梯度不消失;也可以選擇接近 0,此時模型是故意阻斷梯度流,遺忘之前資訊。
另外需要強調的是LSTM搞的這麼複雜,除了在結構上天然地克服了梯度消失的問題,更重要的是具有更多的引數來控制模型;通過四倍於RNN的引數量,可以更加精細地預測時間序列變數。
此外,我記得有一篇文章講到,LSTM 在 200左右長度的文字上,就已經捉襟見肘了。
七、ELMo 模型
7.1 ELMo 的預訓練
在講解 Word Embedding 時,細心地讀者一定已經發現,這些詞表示方法本質上是靜態的,每一個詞都有一個唯一確定的詞向量,不能根據句子的不同而改變,無法處理自然語言處理任務中的多義詞問題。

如上圖所示,例如多義詞 Bank,有兩個常用含義,但是 Word Embedding 在對 bank 這個單詞進行編碼的時候,是區分不開這兩個含義的。
因為儘管這兩句含有 bank 的句子中 bank 上下文環境中出現的單詞不同,但是在用語言模型訓練的時候,不論什麼上下文的句子經過 Word2Vec,都是預測相同的單詞 bank,而同一個單詞佔用的是同一行的引數空間,這會導致兩種不同的上下文資訊都會編碼到相同的 Word Embedding 空間裡,進而導致Word Embedding 無法區分多義詞的不同語意。
所以對於比如 Bank 這個詞,它事先學好的 Word Embedding 中混合了幾種語意 ,在應用中來了個新句子,即使從上下文中(比如句子包含 money 等詞)明顯可以看出它代表的是 「銀行」 的含義,但是對應的 Word Embedding 內容也不會變,它還是混合了多種語意。
針對 Word Embedding 中出現的多義詞問題,ELMo 提供了一個簡潔優雅的解決方案。
ELMo 的本質思想是:我事先用語言模型學好一個單詞的 Word Embedding,此時多義詞無法區分,不過這沒關係。在我實際使用 Word Embedding 的時候,單詞已經具備了特定的上下文了,這個時候我可以根據上下文單詞的語意再去調整單詞的 Word Embedding 表示,這樣經過調整後的 Word Embedding 更能表達在這個上下文中的具體含義,自然也就解決了多義詞的問題了。所以 ELMo 本身是個根據當前上下文對 Word Embedding 動態調整的思路。
ELMo 採用了典型的兩階段過程:
- 第一個階段是利用語言模型進行預訓練;
- 第二個階段是在做下游任務時,從預訓練網路中提取對應單詞的網路各層的 Word Embedding 作為新特徵補充到下游任務中。

上圖展示的是其第一階段預訓練過程,它的網路結構採用了雙層雙向 LSTM,目前語言模型訓練的任務目標是根據單詞 \(w_i\) 的上下文去正確預測單詞 \(w_i\),\(w_i\) 之前的單詞序列 Context-before 稱為上文,之後的單詞序列 Context-after 稱為下文。
圖中左端的前向雙層 LSTM 代表正方向編碼器,輸入的是從左到右順序的除了預測單詞外 \(W_i\) 的上文 Context-before;右端的逆向雙層 LSTM 代表反方向編碼器,輸入的是從右到左的逆序的句子下文Context-after;每個編碼器的深度都是兩層 LSTM 疊加。
這個網路結構其實在 NLP 中是很常用的。使用這個網路結構利用大量語料做語言模型任務就能預先訓練好這個網路,如果訓練好這個網路後,輸入一個新句子 \(s_{new}\) ,句子中每個單詞都能得到對應的三個 Embedding:
- 最底層是單詞的 Word Embedding;
- 往上走是第一層雙向 LSTM 中對應單詞位置的 Embedding,這層編碼單詞的句法資訊更多一些;
- 再往上走是第二層 LSTM 中對應單詞位置的 Embedding,這層編碼單詞的語意資訊更多一些。
也就是說,ELMo 的預訓練過程不僅僅學會單詞的 Word Embedding,還學會了一個雙層雙向的 LSTM 網路結構,而這兩者後面都有用。
7.2 ELMo 的 Feature-based Pre-Training
上面介紹的是 ELMo 的第一階段:預訓練階段。那麼預訓練好網路結構後,如何給下游任務使用呢?

上圖展示了下游任務的使用過程,比如我們的下游任務仍然是 QA 問題,此時對於問句 X:
- 我們可以先將句子 X 作為預訓練好的 ELMo 網路的輸入,這樣句子 X 中每個單詞在 ELMO 網路中都能獲得對應的三個 Embedding;
- 之後給予這三個 Embedding 中的每一個 Embedding 一個權重 a,這個權重可以學習得來,根據各自權重累加求和,將三個 Embedding 整合成一個;
- 然後將整合後的這個 Embedding 作為 X 句在自己任務的那個網路結構中對應單詞的輸入,以此作為補充的新特徵給下游任務使用。
- 對於上圖所示下游任務 QA 中的回答句子 Y 來說也是如此處理。
因為 ELMo 給下游提供的是每個單詞的特徵形式,所以這一類預訓練的方法被稱為 「Feature-based Pre-Training」。
至於為何這麼做能夠達到區分多義詞的效果,原因在於在訓練好 ELMo 後,在特徵提取的時候,每個單詞在兩層 LSTM 上都會有對應的節點,這兩個節點會編碼單詞的一些句法特徵和語意特徵,並且它們的 Embedding 編碼是動態改變的,會受到上下文單詞的影響,周圍單詞的上下文不同應該會強化某種語意,弱化其它語意,進而就解決了多義詞的問題。
八、Attention
上面巴拉巴拉了一堆,都在為 BERT 的講解做鋪墊,而接下來要敘述的 Attention 和 Transformer 同樣如此,它們都只是 BERT 構成的一部分。
8.1 人類的視覺注意力
Attention 是注意力的意思,從它的命名方式看,很明顯借鑑了人類的注意力機制,因此,我們首先介紹人類的視覺注意力。

視覺注意力機制是人類視覺所特有的大腦訊號處理機制。人類視覺通過快速掃描全域性影象,獲得需要重點關注的目標區域,也就是一般所說的注意力焦點,而後對這一區域投入更多注意力資源,以獲取更多所需要關注目標的細節資訊,而抑制其他無用資訊。
這是人類利用有限的注意力資源從大量資訊中快速篩選出高價值資訊的手段,是人類在長期進化中形成的一種生存機制,人類視覺注意力機制極大地提高了視覺資訊處理的效率與準確性。
上圖形象化展示了人類在看到一副影象時是如何高效分配有限的注意力資源的,其中紅色區域表明視覺系統更關注的目標,很明顯對於上圖所示的場景,人們會把注意力更多投入到人的臉部,文字的標題以及文章首句等位置。
深度學習中的注意力機制從本質上講和人類的選擇性視覺注意力機制類似,核心目標也是從眾多資訊中選擇出對當前任務目標更關鍵的資訊。
8.2 Attention 的本質思想
從人類的視覺注意力可以看出,注意力模型 Attention 的本質思想為:從大量資訊中有選擇地篩選出少量重要資訊並聚焦到這些重要資訊上,忽略不重要的資訊。
在詳細講解 Attention之前,我們在講講 Attention的其他作用。之前我們講解 LSTM 的時候說到,雖然 LSTM 解決了序列長距離依賴問題,但是單詞超過 200 的時候就會失效。而 Attention 機制可以更加好的解決序列長距離依賴問題,並且具有平行計算能力。現在不明白這點不重要,隨著我們對 Attention 的慢慢深入,相信你會明白。
首先我們得明確一個點,注意力模型從大量資訊 Values 中篩選出少量重要資訊,這些重要資訊一定是相對於另外一個資訊 Query 而言是重要的,例如對於上面那張嬰兒圖,Query 就是觀察者。也就是說,我們要搭建一個注意力模型,我們必須得要有一個 Query 和一個 Values,然後通過 Query 這個資訊從 Values 中篩選出重要資訊。
通過 Query 這個資訊從 Values 中篩選出重要資訊,簡單點說,就是計算 Query 和 Values 中每個資訊的相關程度。

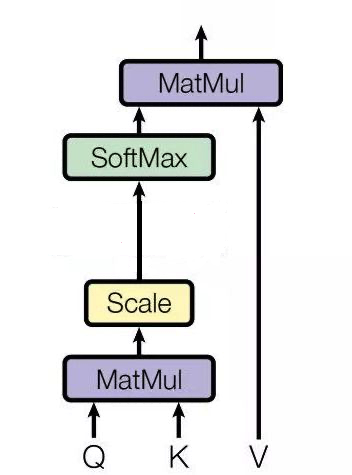
再具體點,通過上圖,Attention 通常可以進行如下描述,表示為將 Query(Q) 和 key-value pairs(把 Values 拆分成了鍵值對的形式) 對映到輸出上,其中 query、每個 key、每個 value 都是向量,輸出是 V 中所有 values 的加權,其中權重是由 Query 和每個 key 計算出來的,計算方法分為三步:
- 第一步:計算比較 Q 和 K 的相似度,用 f 來表示:\(f(Q,K_i)\quad i=1,2,\cdots,m\),一般第一步計算方法包括四種
- 點乘(Transformer 使用):\(f(Q,K_i) = Q^T K_i\)
- 權重:\(f(Q,K_i) = Q^TWK_i\)
- 拼接權重:\(f(Q,K_i) = W[Q^T;K_i]\)
- 感知器:\(f(Q,K_i)=V^T \tanh(WQ+UK_i)\)
- 第二步:將得到的相似度進行 softmax 操作,進行歸一化:\(\alpha_i = softmax(\frac{f(Q,K_i)}{\sqrt d_k})\)
- 這裡簡單講解除以 \(\sqrt d_k\) 的作用:假設 \(Q\) , \(K\) 裡的元素的均值為0,方差為 1,那麼 \(A^T=Q^TK\) 中元素的均值為 0,方差為 d。當 d 變得很大時, \(A\) 中的元素的方差也會變得很大,如果 \(A\) 中的元素方差很大(分佈的方差大,分佈集中在絕對值大的區域),在數量級較大時, softmax 將幾乎全部的概率分佈都分配給了最大值對應的標籤,由於某一維度的數量級較大,進而會導致 softmax 未來求梯度時會消失。總結一下就是 \(\operatorname{softmax}\left(A\right)\) 的分佈會和d有關。因此 \(A\) 中每一個元素乘上 \(\frac{1}{\sqrt{d_k}}\) 後,方差又變為 1,並且 \(A\) 的數量級也將會變小。
- 第三步:針對計算出來的權重 \(\alpha_i\),對 \(V\) 中的所有 values 進行加權求和計算,得到 Attention 向量:\(Attention = \sum_{i=1}^m \alpha_i V_i\)
8.3 Self Attention 模型
上面已經講了 Attention 就是從一堆資訊中篩選出重要的資訊,現在我們來通過 Self Attention 模型來詳細講解如何找到這些重要的資訊。
Self Attention 模型的架構如下圖所示,接下來我們將按照這個模型架構的順序來逐一解釋。
首先可以看到 Self Attention 有三個輸入 Q、K、V:對於 Self Attention,Q、K、V 來自句子 X 的 詞向量 x 的線性轉化,即對於詞向量 x,給定三個可學習的矩陣引數 \(W_Q,W_k,W_v\),x 分別右乘上述矩陣得到 Q、K、V。
接下來為了表示的方便,我們先通過向量的計算敘述 Self Attention 計算的流程,然後再描述 Self Attention 的矩陣計算過程
-
第一步,Q、K、V 的獲取

上圖操作:兩個單詞 Thinking 和 Machines。通過線性變換,即 \(x_i\) 和 \(x_2\) 兩個向量分別與\(W_q,W_k,W_v\) 三個矩陣點乘得到 ${q_1,q_2},{k_1,k_2},{v_1,v_2} $ 共 6 個向量。矩陣 Q 則是向量 \(q_1,q_2\) 的拼接,K、V 同理。
-
第二步,MatMul
-

上圖操作:向量 \({q_1,k_1}\) 做點乘得到得分 112, \({q_1,k_2}\) 做點乘得到得分96。注意:這裡是通過 \(q_1\) 這個資訊找到 \(x_1,x_2\) 中的重要資訊。
-
-
第三步和第四步,Scale + Softmax
上圖操作:對該得分進行規範,除以 \(\sqrt {d_k} = 8\)
-
-
第五步,MatMul
-
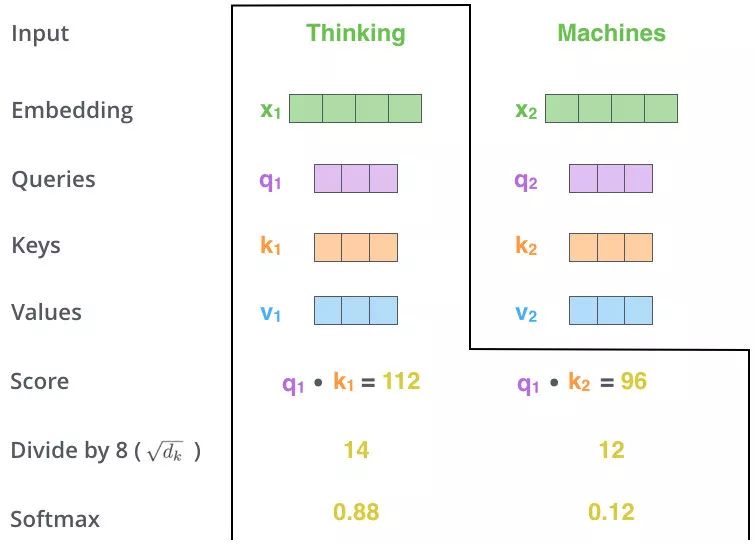
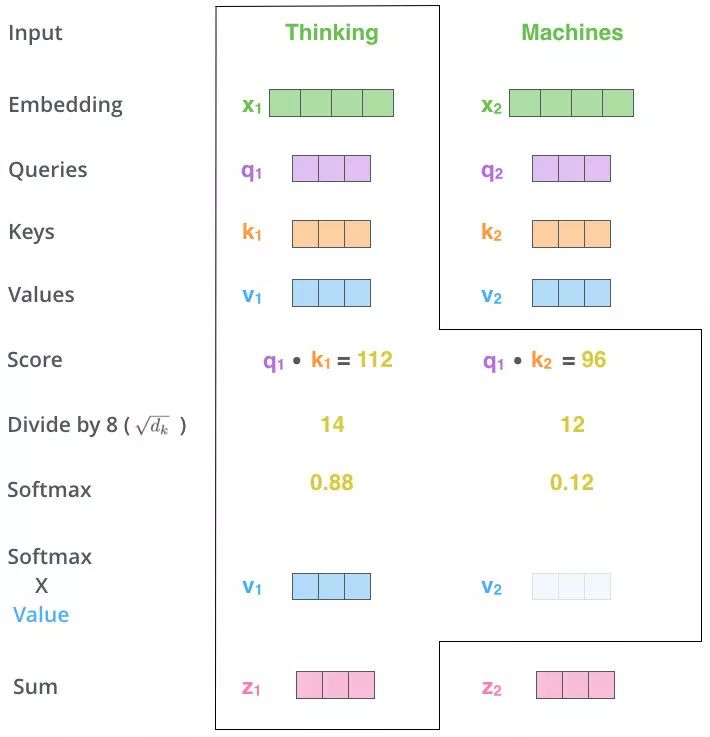
用得分比例 [0.88,0.12] 乘以 \([v_1,v_2]\) 值得到一個加權後的值,將這些值加起來得到 \(z_1\)。
上述所說就是 Self Attention 模型所做的事,仔細感受一下,用 \(q_1\)、\(K=[k_1,k_2]\) 去計算一個 Thinking 相對於 Thinking 和 Machine 的權重,再用權重乘以 Thinking 和 Machine 的 \(V=[v_1,v_2]\) 得到加權後的 Thinking 和 Machine 的 \(V=[v_1,v_2]\),最後求和得到針對各單詞的輸出 \(z_1\)。
同理可以計算出 Machine 相對於 Thinking 和 Machine 的加權輸出 \(z_2\),拼接 \(z_1\) 和 \(z_2\) 即可得到 Attention 值 \(Z=[z_1,z_2]\),這就是 Self Attention 的矩陣計算,如下所示。
之前的例子是單個向量的運算例子。這張圖展示的是矩陣運算的例子,輸入是一個 [2x4] 的矩陣(句子中每個單詞的詞向量的拼接),每個運算是 [4x3] 的矩陣,求得 Q、K、V。

Q 對 K 轉製做點乘,除以 \(\sqrt d_k\),做一個 softmax 得到合為 1 的比例,對 V 做點乘得到輸出 Z。那麼這個 Z 就是一個考慮過 Thinking 周圍單詞 Machine 的輸出。

注意看這個公式,\(QK^T\) 其實就會組成一個 word2word 的 attention map!(加了 softmax 之後就是一個合為 1 的權重了)。比如說你的輸入是一句話 "i have a dream" 總共 4 個單詞,這裡就會形成一張 4x4 的注意力機制的圖:

這樣一來,每一個單詞對應每一個單詞都會有一個權重,這也是 Self Attention 名字的來源,即 Attention 的計算來源於 Source(源句) 和 Source 本身,通俗點講就是 Q、K、V 都來源於輸入 X 本身。
8.4 Self Attention 和 RNN、LSTM 的區別
引入 Self Attention 有什麼好處呢?或者說通過 Self Attention 到底學到了哪些規律或者抽取出了哪些特徵呢?我們可以通過下述兩幅圖來講解:


從上述兩張圖可以看出,Self Attention 可以捕獲同一個句子中單詞之間的一些句法特徵(例如第一張圖展示的有一定距離的短語結構)或者語意特徵(例如第二張圖展示的 its 的指代物件為 Law)。
有了上述的講解,我們現在可以來看看 Self Attention 和 RNN、LSTM 的區別:
- RNN、LSTM:如果是 RNN 或者 LSTM,需要依次序列計算,對於遠距離的相互依賴的特徵,要經過若干時間步步驟的資訊累積才能將兩者聯絡起來,而距離越遠,有效捕獲的可能性越小。
- Self Attention:
- 通過上述兩幅圖,很明顯的可以看出,引入 Self Attention 後會更容易捕獲句子中長距離的相互依賴的特徵,因為 Self Attention 在計算過程中會直接將句子中任意兩個單詞的聯絡通過一個計算步驟直接聯絡起來,所以遠距離依賴特徵之間的距離被極大縮短,有利於有效地利用這些特徵;
- 除此之外,Self
Attention 對於一句話中的每個單詞都可以單獨的進行 Attention 值的計算,也就是說 Self Attention 對計算的並行性也有直接幫助作用,而對於必須得依次序列計算的 RNN 而言,是無法做到平行計算的。
從上面的計算步驟和圖片可以看出,無論句子序列多長,都可以充分捕獲近距離上往下問中的任何依賴關係,進而可以很好的提取句法特徵還可以提取語意特徵;而且對於一個句子而言,每個單詞的計算是可以並行處理的。
理論上 Self-Attention (Transformer 50 個左右的單詞效果最好)解決了 RNN 模型的長序列依賴問題,但是由於文字長度增加時,訓練時間也將會呈指數增長,因此在處理長文字任務時可能不一定比 LSTM(200 個左右的單詞效果最好) 等傳統的 RNN 模型的效果好。
上述所說的,則是為何 Self Attention 逐漸替代 RNN、LSTM 被廣泛使用的原因所在。
8.5 Masked Self Attention 模型
趁熱打鐵,我們講講 Transformer 未來會用到的 Masked Self Attention 模型,這裡的 Masked 就是要在做語言模型(或者像翻譯)的時候,不給模型看到未來的資訊,它的結構如下圖所示:
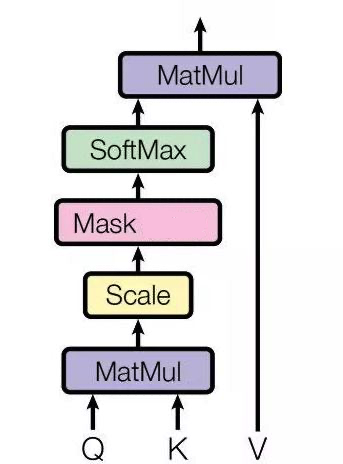
上圖中和 Self Attention 重複的部分此處就不講了,主要講講 Mask 這一塊。
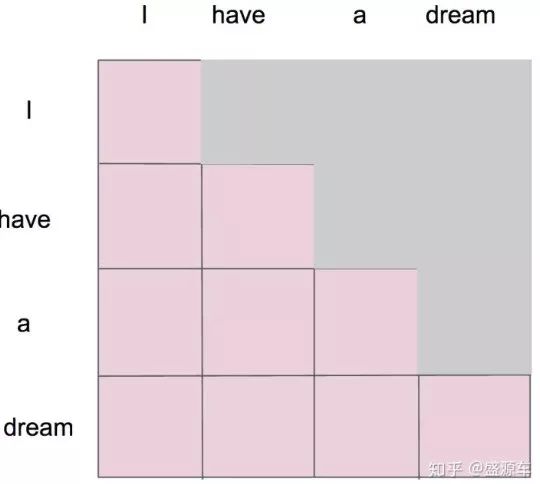
假設在此之前我們已經通過 scale 之前的步驟得到了一個 attention map,而 mask 就是沿著對角線把灰色的區域用0覆蓋掉,不給模型看到未來的資訊,如下圖所示:
詳細來說:
- "i" 作為第一個單詞,只能有和 "i" 自己的 attention;
- "have" 作為第二個單詞,有和 "i、have" 前面兩個單詞的 attention;
- "a" 作為第三個單詞,有和 "i、have、a" 前面三個單詞的 attention;
- "dream" 作為最後一個單詞,才有對整個句子 4 個單詞的 attention。
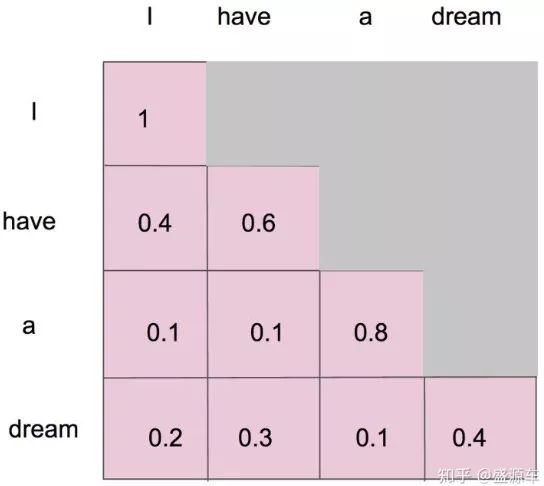
並且在做完 softmax 之後,橫軸結果合為 1。如下圖所示:
具體為什麼要 mask,未來再講解 Transformer 的時候我們會詳細解釋。
8.6 Multi-head Self Attention 模型
由於 Transformer 使用的都是 Self Attention 的進階版 Multi-head Self Attention,我們簡單講講 Multi-head Self Attention 的架構,並且在該小節結尾處講講它的優點。
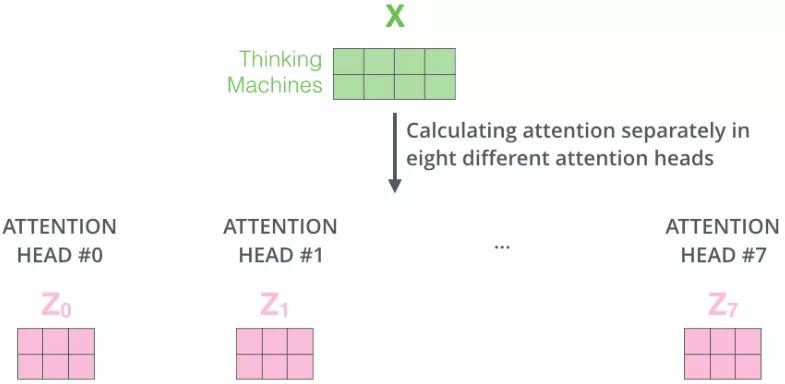
Multi-Head Attention 就是把 Self Attention 得到的注意力值 \(Z\) 切分成 n 個 \(Z_1,Z_2,\cdots,Z_n\),然後通過全連線層獲得新的 \(Z'\).
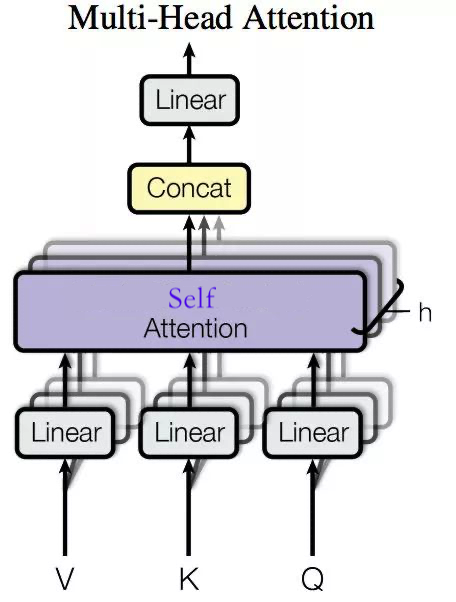
我們還是以上面的形式來解釋,我們對 \(Z\) 進行 8 等份的切分得到 8 個 \(Z_i\) 矩陣:
為了使得輸出與輸入結構相同,拼接矩陣 \(Z_i\) 後乘以一個線性 \(W_0\) 得到最終的Z:

可以通過下圖看看 multi-head attention 的整個流程:

上述操作有什麼好處呢?多頭相當於把原始資訊 Source 放入了多個子空間中,也就是捕捉了多個資訊,對於使用 multi-head(多頭) attention 的簡單回答就是,多頭保證了 attention 可以注意到不同子空間的資訊,捕捉到更加豐富的特徵資訊。其實本質上是論文原作者發現這樣效果確實好。
九、Position Embedding
在 Attention 和 RNN、LSTM 的對比中,我們說到 Attention 解決了長距離依賴問題,並且可以支援並行化,但是它就真的百利而無一害了嗎?
其實不然,我們往前回顧,Self Attention 的 Q、K、V 三個矩陣是由同一個輸入 \(X_1=(x_1,x_2,\cdots,x_n)\) 線性轉換而來,也就是說對於這樣的一個被打亂序列順序的 \(X_2=(x_2,x_1,\cdots,x_n)\) 而言,由於 Attention 值的計算最終會被加權求和,也就是說兩者最終計算的 Attention 值都是一樣的,進而也就表明了 Attention 丟掉了 \(X_1\) 的序列順序資訊。

如上圖所示,為了解決 Attention 丟失的序列順序資訊,Transformer 的提出者提出了 Position Embedding,也就是對於輸入 \(X\) 進行 Attention 計算之前,在 \(X\) 的詞向量中加上位置資訊,也就是說 \(X\) 的詞向量為 \(X_{final\_embedding} = Embedding + Positional\, Embedding\)
但是如何得到 \(X\) 的位置向量呢?
其中位置編碼公式如下圖所示:

其中 pos 表示位置、i 表示維度、\(d_{model}\)表示位置向量的向量維度 、\(2i、2i+1\) 表示的是奇偶數(奇偶維度),上圖所示就是偶數位置使用 \(\sin\) 函數,奇數位置使用 \(\cos\) 函數。
有了位置編碼,我們再來看看位置編碼是如何嵌入單詞編碼的(其中 512 表示編碼維度),通過把單詞的詞向量和位置向量進行疊加,這種方式就稱作位置嵌入,如下圖所示:

Position Embedding 本身是一個絕對位置的資訊,但在語言模型中,相對位置也很重要。那麼為什麼位置嵌入機制有用呢?
我們不要去關心三角函數公式,可以看看下圖公式(3)中的第一行,我們做如下的解釋,對於 「我愛吃蘋果」 這一句話,有 5 個單詞,假設序號分別為 1、2、3、4、5。

假設 \(pos=1=我、k=2=愛、pos+k=3=吃\),也就是說 \(pos+k=3\) 位置的位置向量的某一維可以通過 \(pos=1\) 位置的位置向量的某一維線性組合加以線性表示,通過該線性表示可以得出 「吃」 的位置編碼資訊蘊含了相對於前兩個字 「我」 的位置編碼資訊。
總而言之就是,某個單詞的位置資訊是其他單詞位置資訊的線性組合,這種線性組合就意味著位置向量中蘊含了相對位置資訊。
十、Transformer
10.1 Transformer 的結構
萬事俱備,只欠東風,下面我們來講講我們的重點之一,Transformer,你可以先記住這一句話:Transformer 簡單點看其實就是 self-attention 模型的疊加,首先我們來看看 Transformer 的整體框架。
Transformer 的整體框架如下圖所示:

上圖所示的整體框架乍一眼一看非常複雜,由於 Transformer 起初是作為翻譯模型,因此我們以翻譯舉例,簡化一下上述的整體框架:

從上圖可以看出 Transformer 相當於一個黑箱,左邊輸入 「Je suis etudiant」,右邊會得到一個翻譯結果 「I am a student」。
再往細裡講,Transformer 也是一個 Seq2Seq 模型(Encoder-Decoder 框架的模型),左邊一個 Encoders 把輸入讀進去,右邊一個 Decoders 得到輸出,如下所示:

在這裡,我們穿插描述下 Encoder-Decoder 框架的模型是如何進行文字翻譯的:
- 將序列 \((x_1,x_2,\cdots,x_n)\) 作為 Encoders 的輸入,得到輸出序列 \((z_1,z_2,\cdots,z_n)\)
- 把 Encoders 的輸出序列 \((z_1,z_2,\cdots,z_n)\) 作為 Decoders 的輸入,生成一個輸出序列 \((y_1,y_2,\cdots,y_m)\)。注:Decoders 每個時刻輸出一個結果
第一眼看到上述的 Encodes-Decoders 框架圖,隨之產生問題就是 Transformer 中 左邊 Encoders 的輸出是怎麼和右邊 Decoders 結合的。因為decoders 裡面是有N層的,再畫張圖直觀的看就是這樣:

也就是說,Encoders 的輸出,會和每一層的 Decoder 進行結合。
現在我們取其中一層進行詳細的展示:

通過上述分析,發現我們想要詳細瞭解 Transformer,只要瞭解 Transformer 中的 Encoder 和 Decoder 單元即可,接下來我們將詳細闡述這兩個單元。
10.2 Encoder
有了上述那麼多知識的鋪墊,我們知道 Eecoders 是 N=6 層,通過上圖我們可以看到每層 Encoder 包括兩個 sub-layers:
- 第一個 sub-layer 是 multi-head self-attention,用來計算輸入的 self-attention;
- 第二個 sub-layer 是簡單的前饋神經網路層 Feed Forward;
注意:在每個 sub-layer 我們都模擬了殘差網路(在下面的資料流示意圖中會細講),每個sub-layer的輸出都是 \(LayerNorm(x+Sub\_layer(x))\),其中 \(sub\_layer\) 表示的是該層的上一層的輸出
現在我們給出 Encoder 的資料流示意圖,一步一步去剖析

- 深綠色的 \(x_1\) 表示 Embedding 層的輸出,加上代表 Positional Embedding 的向量之後,得到最後輸入 Encoder 中的特徵向量,也就是淺綠色向量 \(x_1\);
- 淺綠色向量 \(x_1\) 表示單詞 「Thinking」 的特徵向量,其中 \(x_1\) 經過 Self-Attention 層,變成淺粉色向量 \(z_1\);
- \(x_1\) 作為殘差結構的直連向量,直接和 \(z_1\) 相加,之後進行 Layer Norm 操作,得到粉色向量 \(z_1\);
- 殘差結構的作用:避免出現梯度消失的情況
- Layer Norm 的作用:為了保證資料特徵分佈的穩定性,並且可以加速模型的收斂
- \(z_1\) 經過前饋神經網路(Feed Forward)層,經過殘差結構與自身相加,之後經過 LN 層,得到一個輸出向量 \(r_1\);
- 該前饋神經網路包括兩個線性變換和一個ReLU啟用函數:\(FFN(x) = max(0,xW_1+b_1)W_2+b2\)
- 由於 Transformer 的 Encoders 具有 6 個 Encoder,\(r_1\) 也將會作為下一層 Encoder 的輸入,代替 \(x_1\) 的角色,如此迴圈,直至最後一層 Encoder。
需要注意的是,上述的 \(x、z、r\) 都具有相同的維數,論文中為 512 維。
10.3 Decoder
Decoders 也是 N=6 層,通過上圖我們可以看到每層 Decoder 包括 3 個 sub-layers:
- 第一個 sub-layer 是 Masked multi-head self-attention,也是計算輸入的 self-attention;
- 在這裡,先不解釋為什麼要做 Masked,後面在 「Transformer 動態流程展示」 這一小節會解釋
- 第二個 sub-layer 是 Encoder-Decoder Attention 計算,對 Encoder 的輸入和 Decoder 的Masked multi-head self-attention 的輸出進行 attention 計算;
- 在這裡,同樣不解釋為什麼要對 Encoder 和 Decoder 的輸出一同做 attention 計算,後面在 「Transformer 動態流程展示」 這一小節會解釋
- 第三個 sub-layer 是前饋神經網路層,與 Encoder 相同。
10.4 Transformer 輸出結果
以上,就講完了 Transformer 編碼和解碼兩大模組,那麼我們迴歸最初的問題,將 「機器學習」 翻譯成 「machine learing」,解碼器的輸出是一個浮點型的向量,怎麼轉化成 「machine learing」 這兩個詞呢?讓我們來看看 Encoders 和 Decoders 互動的過程尋找答案:

從上圖可以看出,Transformer 最後的工作是讓解碼器的輸出通過線性層 Linear 後接上一個 softmax
- 其中線性層是一個簡單的全連線神經網路,它將解碼器產生的向量 A 投影到一個更高維度的向量 B 上,假設我們模型的詞彙表是10000個詞,那麼向量 B 就有10000個維度,每個維度對應一個惟一的詞的得分。
- 之後的softmax層將這些分數轉換為概率。選擇概率最大的維度,並對應地生成與之關聯的單詞作為此時間步的輸出就是最終的輸出啦!

假設詞彙表維度是 6,那麼輸出最大概率詞彙的過程如下:

十一、Transformer 動態流程展示
首先我們來看看拿 Transformer 作翻譯時,如何生成翻譯結果的:

繼續進行:

假設上圖是訓練模型的某一個階段,我們來結合 Transformer 的完整框架描述下這個動態的流程圖:
- 輸入 「je suis etudiant」 到 Encoders,然後得到一個 \(K_e\)、\(V_e\) 矩陣;
- 輸入 「I am a student」 到 Decoders ,首先通過 Masked Multi-head Attention 層得到 「I am a student」 的 attention 值 \(Q_d\),然後用 attention 值 \(Q_d\) 和 Encoders 的輸出 \(K_e\)、\(V_e\) 矩陣進行 attention 計算,得到第 1 個輸出 「I」;
- 輸入 「I am a student」 到 Decoders ,首先通過 Masked Multi-head Attention 層得到 「I am a student」 的 attention 值 \(Q_d\),然後用 attention 值 \(Q_d\) 和 Encoders 的輸出 \(K_e\)、\(V_e\) 矩陣進行 attention 計算,得到第 2 個輸出 「am」;
- ……
現在我們來解釋我們之前遺留的兩個問題。
11.1 為什麼 Decoder 需要做 Mask
-
訓練階段:我們知道 「je suis etudiant」 的翻譯結果為 「I am a student」,我們把 「I am a student」 的 Embedding 輸入到 Decoders 裡面,翻譯第一個詞 「I」 時
- 如果對 「I am a student」 attention 計算不做 mask,「am,a,student」 對 「I」 的翻譯將會有一定的貢獻
- 如果對 「I am a student」 attention 計算做 mask,「am,a,student」 對 「I」 的翻譯將沒有貢獻
-
測試階段:我們不知道 「我愛中國」 的翻譯結果為 「I love China」,我們只能隨機初始化一個 Embedding 輸入到 Decoders 裡面,翻譯第一個詞 「I」 時:
- 無論是否做 mask,「love,China」 對 「I」 的翻譯都不會產生貢獻
- 但是翻譯了第一個詞 「I」 後,隨機初始化的 Embedding 有了 「I」 的 Embedding,也就是說在翻譯第二詞 「love」 的時候,「I」 的 Embedding 將有一定的貢獻,但是 「China」 對 「love」 的翻譯毫無貢獻,隨之翻譯的進行,已經翻譯的結果將會對下一個要翻譯的詞都會有一定的貢獻,這就和做了 mask 的訓練階段做到了一種匹配
總結下就是:Decoder 做 Mask,是為了讓訓練階段和測試階段行為一致,不會出現間隙,避免過擬合
11.2 為什麼 Encoder 給予 Decoders 的是 K、V 矩陣
我們在講解 Attention 機制中曾提到,Query 的目的是藉助它從一堆資訊中找到重要的資訊。
現在 Encoder 提供了 \(K_e、V_e\) 矩陣,Decoder 提供了 \(Q_d\) 矩陣,通過 「我愛中國」 翻譯為 「I love China」 這句話詳細解釋下。
當我們翻譯 「I」 的時候,由於 Decoder 提供了 \(Q_d\) 矩陣,通過與 \(K_e、V_e\) 矩陣的計算,它可以在 「我愛中國」 這四個字中找到對 「I」 翻譯最有用的單詞是哪幾個,並以此為依據翻譯出 「I」 這個單詞,這就很好的體現了注意力機制想要達到的目的,把焦點放在對自己而言更為重要的資訊上。
- 其實上述說的就是 Attention 裡的 soft attention機制,解決了曾經的 Encoder-Decoder 框架的一個問題,在這裡不多做敘述,有興趣的可以參考網上的一些資料。
- 早期的 Encoder-Decoder 框架中的 Encoder 通過 LSTM 提取出源句(Source) 「我愛中國」 的特徵資訊 C,然後 Decoder 做翻譯的時候,目標句(Target)「I love China」 中的任何一個單詞的翻譯都來源於相同特徵資訊 C,這種做法是極其不合理的,例如翻譯 「I」 時應該著眼於 「我」,翻譯 「China」 應該著眼於 「中國」,而早期的這種做法並沒有體現出,然而 Transformer 卻通過 Attention 的做法解決了這個問題。
十二、GPT 模型
12.1 GPT 模型的預訓練
在講解 ELMo 的時候,我們說到 ELMo 這一類預訓練的方法被稱為 「Feature-based Pre-Training」。並且如果把 ELMo 這種預訓練方法和影象領域的預訓練方法對比,發現兩者模式看上去還是有很大差異的。
除了以 ELMo 為代表的這種基於特徵融合的預訓練方法外,NLP 裡還有一種典型做法,這種做法和影象領域的方式就是看上去一致的了,一般將這種方法稱為 「基於Fine-tuning的模式」,而 GPT 就是這一模式的典型開創者,下面先讓我們看看 GPT 的網路結構。

GPT 是 「Generative Pre-Training」 的簡稱,從名字看其含義是指的生成式的預訓練。
GPT也採用兩階段過程:
- 第一個階段:利用語言模型進行預訓練;
- 第二個階段:通過 Fine-tuning 的模式解決下游任務。
上圖展示了 GPT 的預訓練過程,其實和 ELMo 是類似的,主要不同在於兩點:
- 首先,特徵抽取器用的不是 RNN,而是用的 Transformer,它的特徵抽取能力要強於RNN,這個選擇很明顯是很明智的;
- 其次,
- GPT 的預訓練雖然仍然是以語言模型作為目標任務,但是採用的是單向的語言模型,所謂 「單向」 的含義是指:語言模型訓練的任務目標是根據 \(w_i\) 單詞的上下文去正確預測單詞 \(w_i\) , \(w_i\) 之前的單詞序列Context-before稱為上文,之後的單詞序列Context-after稱為下文。
- ELMo 在做語言模型預訓練的時候,預測單詞 \(w_i\) 同時使用了上文和下文,而 GPT 則只採用 Context-before 這個單詞的上文來進行預測,而拋開了下文。
- GPT 這個選擇現在看不是個太好的選擇,原因很簡單,它沒有把單詞的下文融合進來,這限制了其在更多應用場景的效果,比如閱讀理解這種任務,在做任務的時候是可以允許同時看到上文和下文一起做決策的。如果預訓練時候不把單詞的下文嵌入到 Word Embedding 中,是很吃虧的,白白丟掉了很多資訊。
12.2 GPT 模型的 Fine-tuning
上面講的是 GPT 如何進行第一階段的預訓練,那麼假設預訓練好了網路模型,後面下游任務怎麼用?它有自己的個性,和 ELMO 的方式大有不同。
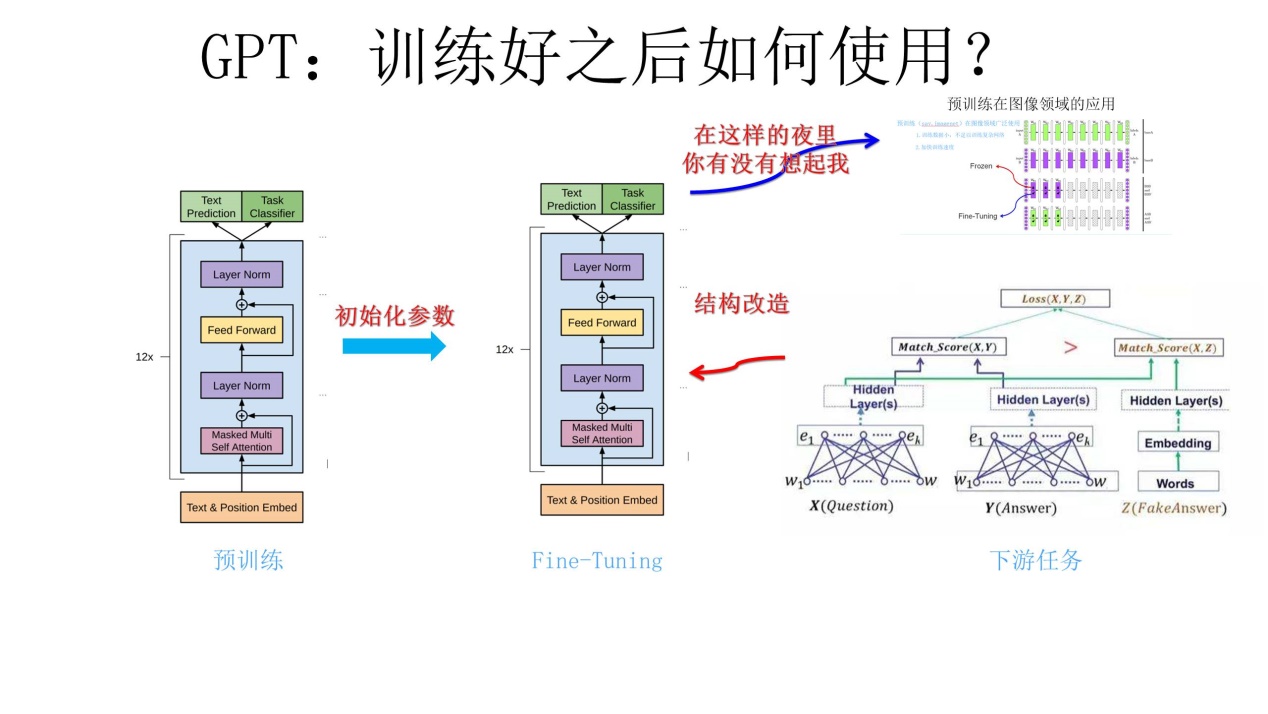
上圖展示了 GPT 在第二階段如何使用:
-
首先,對於不同的下游任務來說,本來你可以任意設計自己的網路結構,現在不行了,你要向 GPT 的網路結構看齊,把任務的網路結構改造成和 GPT 一樣的網路結構。
-
然後,在做下游任務的時候,利用第一步預訓練好的引數初始化 GPT 的網路結構,這樣通過預訓練學到的語言學知識就被引入到你手頭的任務裡來了。
-
再次,你可以用手頭的任務去訓練這個網路,對網路引數進行 Fine-tuning,使得這個網路更適合解決手頭的問題。就是這樣。
這有沒有讓你想起最開始提到的影象領域如何做預訓練的過程,對,這跟那個預訓練的模式是一模一樣的。
對於 NLP 各種花樣的不同任務,怎麼改造才能靠近 GPT 的網路結構呢?由於 GPT 對下游任務的改造過程和 BERT 對下游任務的改造極其類似,並且我們主要目的是為了講解 BERT,所以這個問題將會在 BERT 那裡得到回答。
十三、BERT 模型
13.1 BERT:公認的里程碑
BERT 模型可以作為公認的里程碑式的模型,但是它最大的優點不是創新,而是集大成者,並且這個集大成者有了各項突破,下面讓我們看看 BERT 是怎麼集大成者的。
- BERT 的意義在於:從大量無標記資料集中訓練得到的深度模型,可以顯著提高各項自然語言處理任務的準確率。
- 近年來優秀預訓練語言模型的集大成者:參考了 ELMO 模型的雙向編碼思想、借鑑了 GPT 用 Transformer 作為特徵提取器的思路、採用了 word2vec 所使用的 CBOW 方法
- BERT 和 GPT 之間的區別:
- GPT:GPT 使用 Transformer Decoder 作為特徵提取器、具有良好的文字生成能力,然而當前詞的語意只能由其前序詞決定,並且在語意理解上不足
- BERT:使用了 Transformer Encoder 作為特徵提取器,並使用了與其配套的掩碼訓練方法。雖然使用雙向編碼讓 BERT 不再具有文字生成能力,但是 BERT 的語意資訊提取能力更強
- 單向編碼和雙向編碼的差異,以該句話舉例 「今天天氣很{},我們不得不取消戶外運動」,分別從單向編碼和雙向編碼的角度去考慮 {} 中應該填什麼詞:
- 單向編碼:單向編碼只會考慮 「今天天氣很」,以人類的經驗,大概率會從 「好」、「不錯」、「差」、「糟糕」 這幾個詞中選擇,這些詞可以被劃為截然不同的兩類
- 雙向編碼:雙向編碼會同時考慮上下文的資訊,即除了會考慮 「今天天氣很」 這五個字,還會考慮 「我們不得不取消戶外運動」 來幫助模型判斷,則大概率會從 「差」、「糟糕」 這一類詞中選擇
13.2 BERT 的結構:強大的特徵提取能力
-
如下圖所示,我們來看看 ELMo、GPT 和 BERT 三者的區別
-

- ELMo 使用自左向右編碼和自右向左編碼的兩個 LSTM 網路,分別以 \(P(w_i|w_1,\cdots,w_{i-1})\) 和 \(P(w_i|w_{i+1},\cdots,w_n)\) 為目標函數獨立訓練,將訓練得到的特徵向量以拼接的形式實現雙向編碼,本質上還是單向編碼,只不過是兩個方向上的單向編碼的拼接而成的雙向編碼。
- GPT 使用 Transformer Decoder 作為 Transformer Block,以 \(P(w_i|w_1,\cdots,w_{i-1})\) 為目標函數進行訓練,用 Transformer Block 取代 LSTM 作為特徵提取器,實現了單向編碼,是一個標準的預訓練語言模型,即使用 Fine-Tuning 模式解決下游任務。
- BERT 也是一個標準的預訓練語言模型,它以 \(P(w_i|w_1,\cdots,w_{i-1},w_{i+1},\cdots,w_n)\) 為目標函數進行訓練,BERT 使用的編碼器屬於雙向編碼器。
- BERT 和 ELMo 的區別在於使用 Transformer Block 作為特徵提取器,加強了語意特徵提取的能力;
- BERT 和 GPT 的區別在於使用 Transformer Encoder 作為 Transformer Block,並且將 GPT 的單向編碼改成雙向編碼,也就是說 BERT 捨棄了文字生成能力,換來了更強的語意理解能力。
-
BERT 的模型結構如下圖所示:

從上圖可以發現,BERT 的模型結構其實就是 Transformer Encoder 模組的堆疊。在模型引數選擇上,論文給出了兩套大小不一致的模型。
\(BERT_{BASE}\) :L = 12,H = 768,A = 12,總引數量為 1.1 億
\(BERT_{LARGE}\):L = 24,H = 1024,A = 16,總引數量為 3.4 億
其中 L 代表 Transformer Block 的層數;H 代表特徵向量的維數(此處預設 Feed Forward 層中的中間隱層的維數為 4H);A 表示 Self-Attention 的頭數,使用這三個引數基本可以定義 BERT的量級。
BERT 引數量級的計算公式:
訓練過程也是很花費計算資源和時間的,總之表示膜拜,普通人即便有 idea 沒有算力也只能跪著。
13.3 BERT 之無監督訓練
和 GPT 一樣,BERT 也採用二段式訓練方法:
- 第一階段:使用易獲取的大規模無標籤餘料,來訓練基礎語言模型;
- 第二階段:根據指定任務的少量帶標籤訓練資料進行微調訓練。
不同於 GPT 等標準語言模型使用 \(P(w_i|w_1,\cdots,w_{i-1})\) 為目標函數進行訓練,能看到全域性資訊的 BERT 使用 \(P(w_i|w_1,\cdots,w_{i-1},w_{i+1},\cdots,w_n)\) 為目標函數進行訓練。
並且 BERT 用語言掩碼模型(MLM)方法訓練詞的語意理解能力;用下句預測(NSP)方法訓練句子之間的理解能力,從而更好地支援下游任務。
13.4 BERT之語言掩碼模型(MLM)
BERT 作者認為,使用自左向右編碼和自右向左編碼的單向編碼器拼接而成的雙向編碼器,在效能、引數規模和效率等方面,都不如直接使用深度雙向編碼器強大,這也是為什麼 BERT 使用 Transformer Encoder 作為特徵提取器,而不使用自左向右編碼和自右向左編碼的兩個 Transformer Decoder作為特徵提取器的原因。
由於無法使用標準語言模型的訓練模式,BERT 借鑑完形填空任務和 CBOW 的思想,使用語言掩碼模型(MLM )方法訓練模型。
MLM 方法也就是隨機去掉句子中的部分 token(單詞),然後模型來預測被去掉的 token 是什麼。這樣實際上已經不是傳統的神經網路語言模型(類似於生成模型)了,而是單純作為分類問題,根據這個時刻的 hidden state 來預測這個時刻的 token 應該是什麼,而不是預測下一個時刻的詞的概率分佈了。
隨機去掉的 token 被稱作掩碼詞,在訓練中,掩碼詞將以 15% 的概率被替換成 [MASK],也就是說隨機 mask 語料中 15% 的 token,這個操作則稱為掩碼操作。注意:在CBOW 模型中,每個詞都會被預測一遍。
但是這樣設計 MLM 的訓練方法會引入弊端:在模型微調訓練階段或模型推理(測試)階段,輸入的文字中將沒有 [MASK],進而導致產生由訓練和預測資料偏差導致的效能損失。
考慮到上述的弊端,BERT 並沒有總用 [MASK] 替換掩碼詞,而是按照一定比例選取替換詞。在選擇 15% 的詞作為掩碼詞後這些掩碼詞有三類替換選項:
- 80% 練樣本中:將選中的詞用 [MASK] 來代替,例如:
「地球是[MASK]八大行星之一」
- 10% 的訓練樣本中:選中的詞不發生變化,該做法是為了緩解訓練文字和預測文字的偏差帶來的效能損失,例如:
「地球是太陽系八大行星之一」
- 10% 的訓練樣本中:將選中的詞用任意的詞來進行代替,該做法是為了讓 BERT 學會根據上下文資訊自動糾錯,例如:
「地球是蘋果八大行星之一」
作者在論文中提到這樣做的好處是,編碼器不知道哪些詞需要預測的,哪些詞是錯誤的,因此被迫需要學習每一個 token 的表示向量,另外作者也表示雙向編碼器比單項編碼器訓練要慢,進而導致BERT 的訓練效率低了很多,但是實驗也證明 MLM 訓練方法可以讓 BERT 獲得超出同期所有預訓練語言模型的語意理解能力,犧牲訓練效率是值得的。
13.5 BERT 之下句預測(NSP)
在很多自然語言處理的下游任務中,如問答和自然語言推斷,都基於兩個句子做邏輯推理,而語言模型並不具備直接捕獲句子之間的語意聯絡的能力,或者可以說成單詞預測粒度的訓練到不了句子關係這個層級,為了學會捕捉句子之間的語意聯絡,BERT 採用了下句預測(NSP )作為無監督預訓練的一部分。
NSP 的具體做法是,BERT 輸入的語句將由兩個句子構成,其中,50% 的概率將語意連貫的兩個連續句子作為訓練文字(連續句對一般選自篇章級別的語料,以此確保前後語句的語意強相關),另外 50% 的概率將完全隨機抽取兩個句子作為訓練文字。
連續句對:[CLS]今天天氣很糟糕[SEP]下午的體育課取消了[SEP]
隨機句對:[CLS]今天天氣很糟糕[SEP]魚快被烤焦啦[SEP]
其中 [SEP] 標籤表示分隔符。 [CLS] 表示標籤用於類別預測,結果為 1,表示輸入為連續句對;結果為 0,表示輸入為隨機句對。
通過訓練 [CLS] 編碼後的輸出標籤,BERT 可以學會捕捉兩個輸入句對的文字語意,在連續句對的預測任務中,BERT 的正確率可以達到 97%-98%。
13.6 BERT 之輸入表示
BERT 在預訓練階段使用了前文所述的兩種訓練方法,在真實訓練中一般是兩種方法混合使用。
由於 BERT 通過 Transformer 模型堆疊而成,所以 BERT 的輸入需要兩套 Embedding 操作:
- 一套為 One-hot 詞表對映編碼(對應下圖的 Token Embeddings);
- 另一套為位置編碼(對應下圖的 Position Embeddings),不同於 Transformer 的位置編碼用三角函數表示,BERT 的位置編碼將在預訓練過程中訓練得到(訓練思想類似於Word Embedding 的 Q 矩陣)
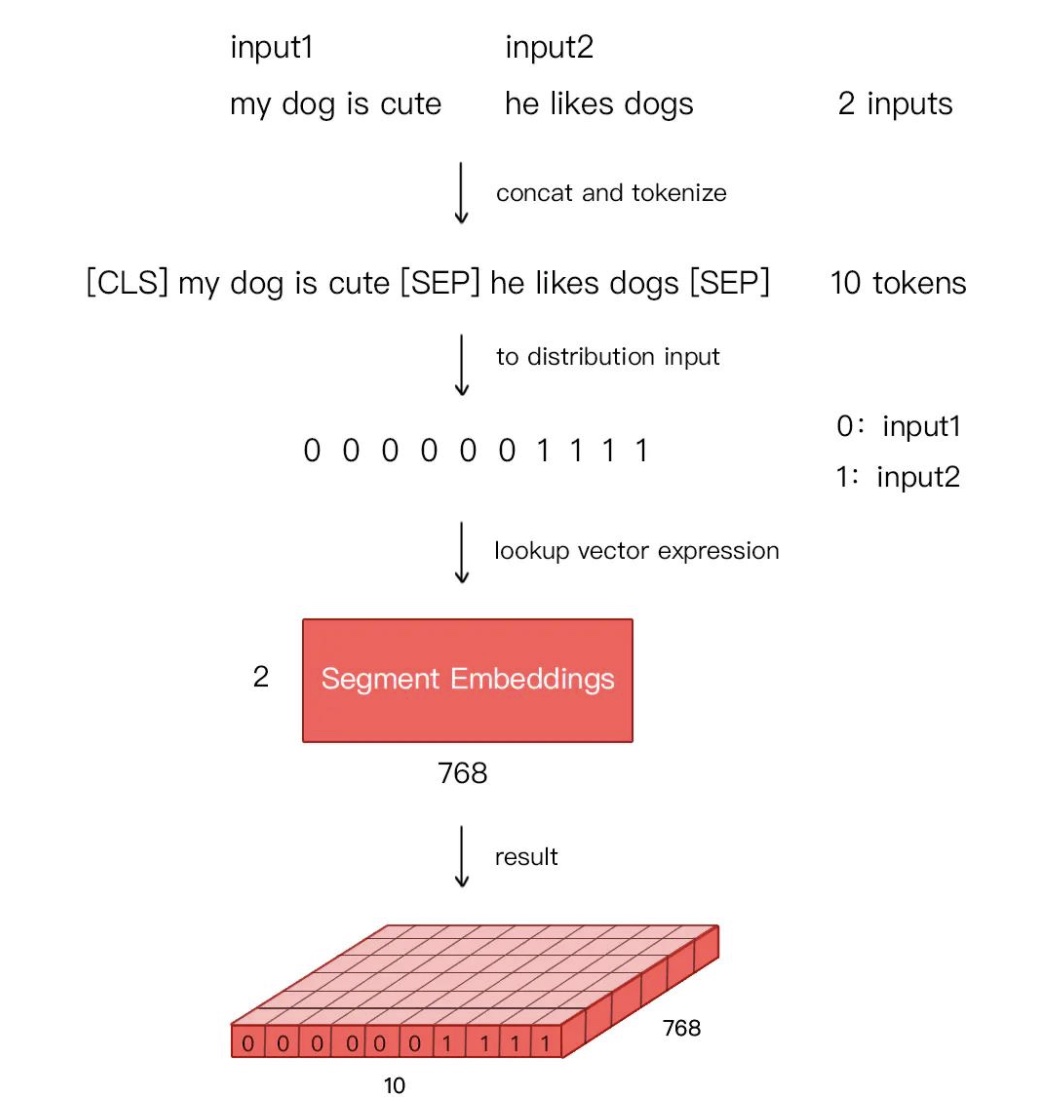
- 由於在 MLM 的訓練過程中,存在單句輸入和雙句輸入的情況,因此 BERT 還需要一套區分輸入語句的分割編碼(對應下圖的 Segment Embeddings),BERT 的分割編碼也將在預訓練過程中訓練得到

對於分割編碼,Segment Embeddings 層只有兩種向量表示。前一個向量是把 0 賦給第一個句子中的各個 token,後一個向量是把 1 賦給第二個句子中的各個 token ;如果輸入僅僅只有一個句子,那麼它的 segment embedding 就是全 0,下面我們簡單舉個例子描述下:
[CLS]I like dogs[SEP]I like cats[SEP] 對應編碼 0 0 0 0 0 1 1 1 1
[SEP]I Iike dogs and cats[SEP] 對應編碼 0 0 0 0 0 0 0
十四、BERT 下游任務改造
BERT 根據自然語言處理下游任務的輸入和輸出的形式,將微調訓練支援的任務分為四類,分別是句對分類、單句分類、文字問答和單句標註,接下來我們將簡要的介紹下 BERT 如何通過微調訓練適應這四類任務的要求。
14.1 句對分類
給定兩個句子,判斷它們的關係,稱為句對分類,例如判斷句對是否相似、判斷後者是否為前者的答案。
針對句對分類任務,BERT 在預訓練過程中就使用了 NSP 訓練方法獲得了直接捕獲句對語意關係的能力。
如下圖所示,句對用 [SEP] 分隔符拼接成文字序列,在句首加入標籤 [CLS],將句首標籤所對應的輸出值作為分類標籤,計算預測分類標籤與真實分類標籤的交叉熵,將其作為優化目標,在任務資料上進行微調訓練。

針對二分類任務,BERT 不需要對輸入資料和輸出資料的結構做任何改動,直接使用與 NSP 訓練方法一樣的輸入和輸出結構就行。
針對多分類任務,需要在句首標籤 [CLS] 的輸出特徵向量後接一個全連線層和 Softmax 層,保證輸出維數與類別數目一致,最後通過 arg max 操作(取最大值時對應的索引序號)得到相對應的類別結果。
下面給出句對分相似性任務的範例:
任務:判斷句子 「我很喜歡你」 和句子 「我很中意你」 是否相似
輸入改寫:「[CLS]我很喜歡你[SEP]我很中意你」
取 「[CLS]」 標籤對應輸出:[0.02, 0.98]
通過 arg max 操作得到相似類別為 1(類別索引從 0 開始),即兩個句子相似
14.2 單句分類
給定一個句子,判斷該句子的類別,統稱為單句分類,例如判斷情感類別、判斷是否為語意連貫的句子。
針對單句二分類任務,也無須對 BERT 的輸入資料和輸出資料的結構做任何改動。
如下圖所示,單句分類在句首加入標籤 [CLS],將句首標籤所對應的輸出值作為分類標籤,計算預測分類標籤與真實分類標籤的交叉熵,將其作為優化目標,在任務資料上進行微調訓練。

同樣,針對多分類任務,需要在句首標籤 [CLS] 的輸出特徵向量後接一個全連線層和 Softmax 層,保證輸出維數與類別數目一致,最後通過 argmax 操作得到相對應的類別結果。
下面給出語意連貫性判斷任務的範例:
任務:判斷句子「海大球星飯茶吃」 是否為一句話
輸入改寫:「[CLS]海大球星飯茶吃」
取 「[CLS]」 標籤對應輸出:[0.99, 0.01]
通過 arg max 操作得到相似類別為 0,即這個句子不是一個語意連貫的句子
14.3 文字問答
給定一個問句和一個蘊含答案的句子,找出答案在後這種的位置,稱為文字問答,例如給定一個問題(句子 A),在給定的段落(句子 B)中標註答案的其實位置和終止位置。
文字問答任何和前面講的其他任務有較大的差別,無論是在優化目標上,還是在輸入資料和輸出資料的形式上,都需要做一些特殊的處理。
為了標註答案的起始位置和終止位置,BERT 引入兩個輔助向量 s(start,判斷答案的起始位置) 和 e(end,判斷答案的終止位置)。
如下圖所示,BERT 判斷句子 B 中答案位置的做法是,將句子 B 中的每一個次得到的最終特徵向量 \(T_i'\) 經過全連線層(利用全連線層將詞的抽象語意特徵轉化為任務指向的特徵)後,分別與向量 s 和 e 求內積,對所有內積分別進行 softmax 操作,即可得到詞 Tok m(\(m\in [1,M]\))作為答案其實位置和終止位置的概率。最後,去概率最大的片段作為最終的答案。

文字回答任務的微調訓練使用了兩個技巧:
- 用全連線層把 BERT 提取後的深層特徵向量轉化為用於判斷答案位置的特徵向量
- 引入輔助向量 s 和 e 作為答案其實位置和終止位置的基準向量,明確優化目標的方向和度量方法
下面給出文字問答任務的範例:
任務:給定問句 「今天的最高溫度是多少」,在文字 「天氣預報顯示今天最高溫度 37 攝氏度」 中標註答案的起始位置和終止位置
輸入改寫:「[CLS]今天的最高溫度是多少[SEP]天氣預報顯示今天最高溫度 37 攝氏度」
BERT Softmax 結果:
篇章文字 天氣 預報 顯示 今天 最高溫 37 攝氏度 起始位置概率 0.01 0.01 0.01 0.04 0.10 0.80 0.03 終止位置概率 0.01 0.01 0.01 0.03 0.04 0.10 0.80 對 Softmax 的結果取 arg max,得到答案的起始位置為 6,終止位置為 7,即答案為 「37 攝氏度」
14.4 單句標註
給定一個句子,標註每個次的標籤,稱為單句標註。例如給定一個句子,標註句子中的人名、地名和機構名。
單句標註任務和 BERT 預訓練任務具有較大差異,但與文字問答任務較為相似。
如下圖所示,在進行單句標註任務時,需要在每個詞的最終語意特徵向量之後新增全連線層,將語意特徵轉化為序列標註任務所需的特徵,單句標註任務需要對每個詞都做標註,因此不需要引入輔助向量,直接對經過全連線層後的結果做 Softmax 操作,即可得到各類標籤的概率分佈。

由於 BERT 需要對輸入文字進行分詞操作,獨立詞將會被分成若干子詞,因此 BERT 預測的結果將會是 5 類(細分為 13 小類):
- O(非人名地名機構名,O 表示 Other)
- B-PER/LOC/ORG(人名/地名/機構名初始單詞,B 表示 Begin)
- I-PER/LOC/ORG(人名/地名/機構名中間單詞,I 表示 Intermediate)
- E-PER/LOC/ORG(人名/地名/機構名終止單詞,E 表示 End)
- S-PER/LOC/ORG(人名/地名/機構名獨立單詞,S 表示 Single)
將 5 大類的首字母結合,可得 IOBES,這是序列標註最常用的標註方法。
下面給出命名實體識別(NER)任務的範例:
任務:給定句子 「愛因斯坦在柏林發表演講」,根據 IOBES 標註 NER 結果
輸入改寫:「[CLS]愛 因 斯坦 在 柏林 發表 演講」
BERT Softmax 結果:
BOBES 愛 因 斯坦 在 柏林 發表 演講 O 0.01 0.01 0.01 0.90 0.01 0.90 0.90 B-PER 0.90 0.01 0.01 0.01 0.01 0.01 0.01 I-PER 0.01 0.90 0.01 0.01 0.01 0.01 0.01 E-PER 0.01 0.01 0.90 0.01 0.01 0.01 0.01 S-LOC 0.01 0.01 0.01 0.01 0.01 0.01 0.01 對 Softmax 的結果取 arg max,得到最終地 NER 標註結果為:「愛因斯坦」 是人名;「柏林」 是地名
14.5 BERT效果展示
無論如何,從上述講解可以看出,NLP 四大類任務都可以比較方便地改造成 Bert 能夠接受的方式,總之不同型別的任務需要對模型做不同的修改,但是修改都是非常簡單的,最多加一層神經網路即可。這其實是 Bert 的非常大的優點,這意味著它幾乎可以做任何NLP的下游任務,具備普適性,這是很強的。
但是講了這麼多,一個新模型好不好,效果才是王道。那麼Bert 採用這種兩階段方式解決各種 NLP 任務效果如何?
在 11 個各種型別的 NLP 任務中達到目前最好的效果,某些任務效能有極大的提升。

十五、預訓練語言模型總結

到這裡我們可以再梳理下幾個模型之間的演進關係。
從上圖可見,Bert 其實和 ELMO 及 GPT 存在千絲萬縷的關係,比如如果我們把 GPT 預訓練階段換成雙向語言模型,那麼就得到了 Bert;而如果我們把 ELMO 的特徵抽取器換成 Transformer,那麼我們也會得到Bert。
所以你可以看出:Bert最關鍵兩點,一點是特徵抽取器採用 Transformer;第二點是預訓練的時候採用雙向語言模型。
那麼新問題來了:對於 Transformer 來說,怎麼才能在這個結構上做雙向語言模型任務呢?乍一看上去好像不太好搞。我覺得吧,其實有一種很直觀的思路,怎麼辦?看看 ELMO 的網路結構圖,只需要把兩個 LSTM 替換成兩個 Transformer,一個負責正向,一個負責反向特徵提取,其實應該就可以。
當然這是我自己的改造,Bert 沒這麼做。那麼 Bert 是怎麼做的呢?我們前面不是提過 Word2Vec 嗎?我前面肯定不是漫無目的地提到它,提它是為了在這裡引出那個 CBOW 訓練方法,所謂寫作時候埋伏筆的 「草蛇灰線,伏脈千里」,大概就是這個意思吧?
前面提到了 CBOW 方法,它的核心思想是:在做語言模型任務的時候,我把要預測的單詞摳掉,然後根據它的上文 Context-Before 和下文 Context-afte r去預測單詞。
其實 Bert 怎麼做的?Bert 就是這麼做的。從這裡可以看到方法間的繼承關係。當然 Bert 作者沒提 Word2Vec 及 CBOW 方法,這是我的判斷,Bert 作者說是受到完形填空任務的啟發,這也很可能,但是我覺得他們要是沒想到過 CBOW 估計是不太可能的。
從這裡可以看出,在文章開始我說過 Bert 在模型方面其實沒有太大創新,更像一個最近幾年 NLP 重要技術的集大成者,原因在於此,當然我不確定你怎麼看,是否認同這種看法,而且我也不關心你怎麼看。其實 Bert 本身的效果好和普適性強才是最大的亮點。
最後,我講講我對Bert的評價和看法,我覺得 Bert 是 NLP 裡裡程碑式的工作,對於後面 NLP 的研究和工業應用會產生長久的影響,這點毫無疑問。但是從上文介紹也可以看出,從模型或者方法角度看,Bert 借鑑了 ELMO,GPT 及 CBOW,主要提出了 Masked 語言模型及 Next Sentence Prediction,但是這裡 Next Sentence Prediction 基本不影響大局,而 Masked LM 明顯借鑑了 CBOW 的思想。所以說 Bert 的模型沒什麼大的創新,更像最近幾年 NLP 重要進展的集大成者,這點如果你看懂了上文估計也沒有太大異議,如果你有大的異議,槓精這個大帽子我隨時準備戴給你。
如果歸納一下這些進展就是:首先是兩階段模型,第一階段雙向語言模型預訓練,這裡注意要用雙向而不是單向,第二階段採用具體任務 Fine-tuning 或者做特徵整合;第二是特徵抽取要用Transformer 作為特徵提取器而不是 RNN 或者 CNN;第三,雙向語言模型可以採取 CBOW 的方法去做(當然我覺得這個是個細節問題,不算太關鍵,前兩個因素比較關鍵)。Bert 最大的亮點在於效果好及普適性強,幾乎所有 NLP 任務都可以套用 Bert 這種兩階段解決思路,而且效果應該會有明顯提升。可以預見的是,未來一段時間在 NLP 應用領域,Transformer 將佔據主導地位,而且這種兩階段預訓練方法也會主導各種應用。
另外,我們應該弄清楚預訓練這個過程本質上是在做什麼事情,本質上預訓練是通過設計好一個網路結構來做語言模型任務,然後把大量甚至是無窮盡的無標註的自然語言文字利用起來,預訓練任務把大量語言學知識抽取出來編碼到網路結構中,當手頭任務帶有標註資訊的資料有限時,這些先驗的語言學特徵當然會對手頭任務有極大的特徵補充作用,因為當資料有限的時候,很多語言學現象是覆蓋不到的,泛化能力就弱,整合儘量通用的語言學知識自然會加強模型的泛化能力。如何引入先驗的語言學知識其實一直是 NLP 尤其是深度學習場景下的 NLP 的主要目標之一,不過一直沒有太好的解決辦法,而 ELMO/GPT/Bert 的這種兩階段模式看起來無疑是解決這個問題自然又簡潔的方法,這也是這些方法的主要價值所在。
對於當前 NLP 的發展方向,我個人覺得有兩點非常重要:
- 一個是需要更強的特徵抽取器,目前看 Transformer 會逐漸擔當大任,但是肯定還是不夠強的,需要發展更強的特徵抽取器;
- 第二個就是如何優雅地引入大量無監督資料中包含的語言學知識,注意我這裡強調地是優雅,而不是引入,此前相當多的工作試圖做各種語言學知識的嫁接或者引入,但是很多方法看著讓人牙疼,就是我說的不優雅。
目前看預訓練這種兩階段方法還是很有效的,也非常簡潔,當然後面肯定還會有更好的模型出現。
完了,這就是預訓練語言模型的前世今生。
由於個人剛入門 NLP 方向,就不妄自總結,上述總結全部來自知乎文章:從Word Embedding到Bert模型—自然語言處理中的預訓練技術發展史-張俊林
十六、參考資料
我只是知識的搬運工,想詳細瞭解各個知識點的讀者可以自行選擇參考下列資料。
參考書籍:
《預訓練語言模型》- 卲浩、劉一烽
《基於 BERT 模型的自然語言處理實戰》- 李金洪
參考論文:
參考部落格: