分庫分表真的適合你的系統嗎?聊聊分庫分表和NewSQL如何選擇
曾幾何時,「並行高就分庫,資料大就分表」已經成了處理 MySQL 資料增長問題的聖經。
面試官喜歡問,博主喜歡寫,候選人也喜歡背,似乎已經形成了一個閉環。
但你有沒有思考過,分庫分表真的適合你的系統嗎?
分表
在業務剛剛發展起來的時候,流量全部打到了一個 MySQL 上,使用者資訊全落到了 user 表。

後來,user 表的資料量越來越大了。
於是,你做了一次垂直拆分,將原來的 user 表拆分成了新的 user 表和 user_details 表。
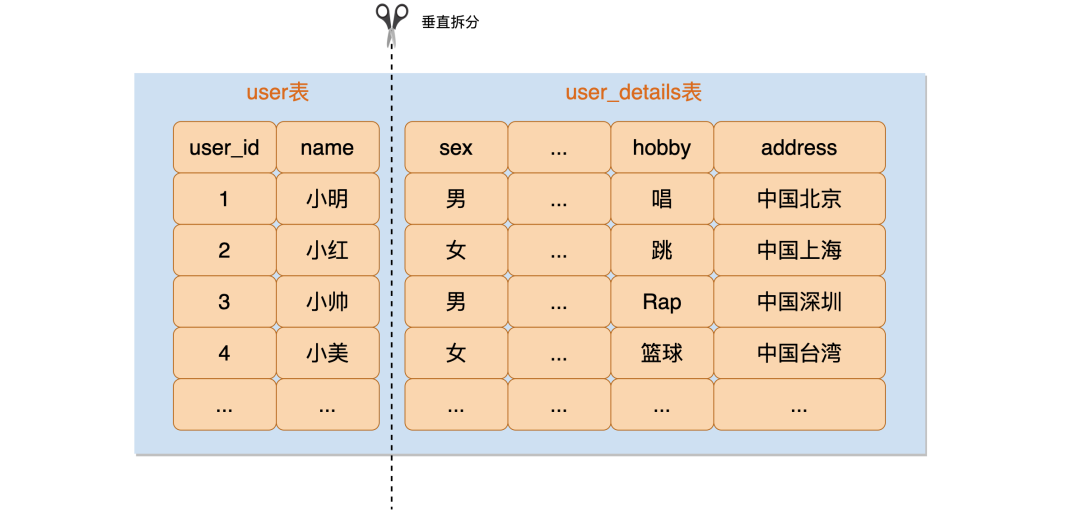
這樣一拆之後,使用者的資訊分散到兩個表,user 表的資料量一下就變小了,user 表資料量過大的問題暫時就解決了。
但隨著業務的發展,線上的流量越來越大,單個 MySQL 已經扛不住流量的壓力了。
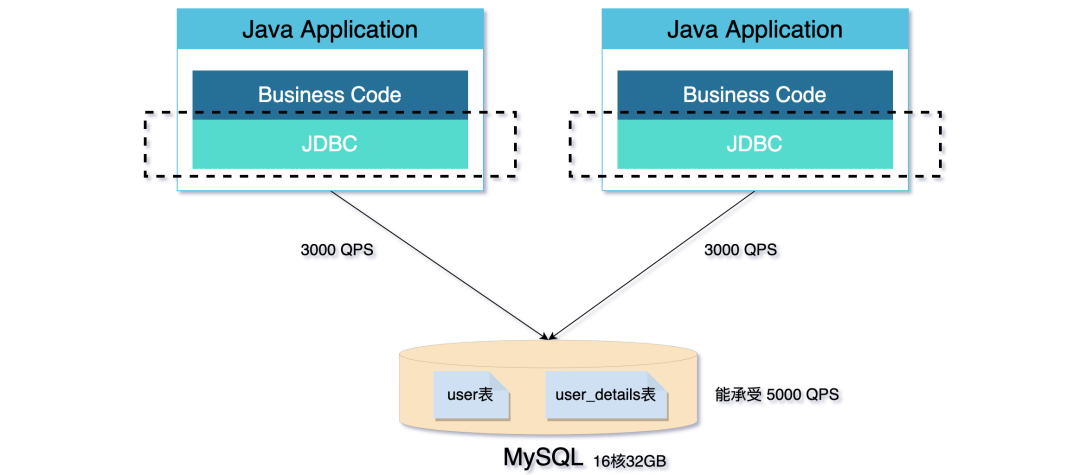
單個庫承受不住壓力的時候,就需要分庫了。
分庫
顧名思義,分庫就是將一個庫拆成多個庫,讓多個庫分擔流量的壓力。
拆成多個庫也意味著進行了分表,也就是說分庫一定分表,分表不一定分庫。
我們可以根據_偏應用_還是_偏 DB_,將分庫分表的實現方式分成三種型別:
-
JDBC 代理模式
-
DB 代理模式
-
Sharding On MySQL 的 DB 模式
JDBC 代理模式
JDBC 代理模式是一種無中心化的架構模式。ShardingSphere-JDBC 就是 JDBC 代理模式的典型實現。
通常以 jar 包形式提供服務,讓使用者端直連資料庫,這種模式無需額外部署和依賴,可理解為增強版的 JDBC 驅動。

JDBC 代理模式雖然簡單,但違背了 DB 透明的原則,侵入性比較高,需要針對不同的語言編寫不同的 Driver。
美團的 Zebra、MTDDL,阿里 TDDL 都是基於這種模式的實現。
DB 代理模式
DB 代理模式是中心化的架構模式。ShardingSphere-Proxy 就是 DB 代理模式的經典實現。
這種模式旨在實現透明化的資料庫代理端,並獨立於應用部署,因為獨立部署,所以對異構語言沒有限制,不會對應用造成侵入。
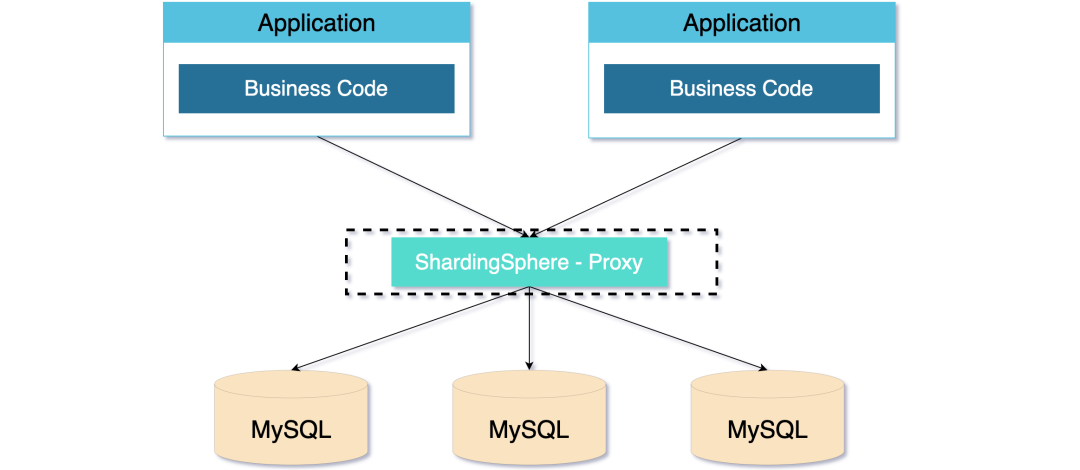
DB 代理模式比 JDBC 代理模式消耗的連線數會少,相對來說效能也會更好。
但中心化的設計也帶來了單點的問題,為了保持高可用和高效能,還需要引入 LVS/F5 等 VIP 來實現流量的負載均衡,如果跨 IDC,還依賴諸如 DNS 進行 IDC 分發,大大拉長了應用到資料庫的鏈路,進而提高了響應時間。
阿里的 MyCat、美團的 Meituan Atlas 和百度 Heisenberg 就是基於 DB 代理模式的實現。
Sharding On MySQL
Sharding On MySQL 相當於遮蔽了分庫分表的操作,是運維和中介軟體結合的沉澱,比較典型例子是阿里的 DRDS。
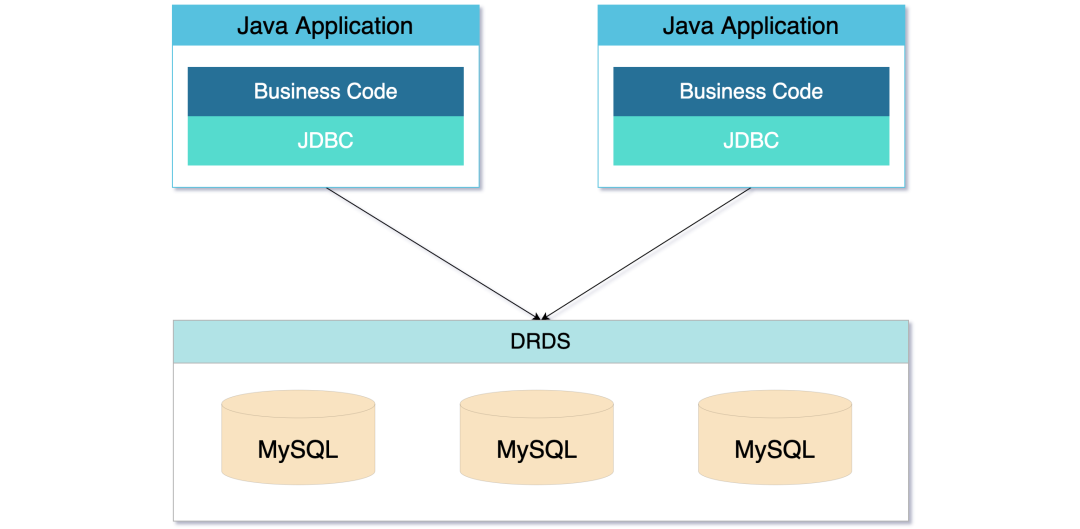
這種模式讓分庫分表變得模糊,對應用來說,更像是一個封裝了 MySQL 的新型資料庫。
雖然使用者使用變得更簡單了,但簡單的背後是運維的沉澱,分庫分表該存在的問題它依然存在。
分庫分表的成本
實現分庫分表的方式有很多,但不同模式的實現似乎都是在彌補 MySQL 不支援分散式的缺陷。
分庫分表這種強行讓 MySQL 達到一個偽「分散式」的狀態,也帶來了一些新的問題,比如:
-
功能限制問題:分庫分表後跨維度 join、聚合、子查詢不復存在,唯一鍵、外來鍵等全域性約束也只能靠業務保障,DB 慢慢弱化為儲存。
-
運維複雜度問題:分庫分表後的多個庫表的管理麻煩,運維成本非常高,資料查詢也很麻煩。
-
Sharding Key 問題:非 Sharding key 的查詢需要做額外的冗餘處理,需要引入 Elasticsearch、ClickHouse 等其他節點,進一步提高了系統的複雜度。
-
唯一 ID 問題:分庫分表後唯一 ID 得不到保障,需要對唯一 ID 進行改造。
-
分散式事務問題:MySQL 自帶的 XA 柔性事務效能太低,需要引入新的分散式事務解決方案。
NewSQL
從上文得知,分庫分表需要犧牲 MySQL 的一些功能,還帶來許多新的問題。
那有沒有一種方案,既能擁有 MySQL 的功能,又能支援資料的可延伸?
有。那就是 NewSQL。
NewSQL 是一類關聯式資料庫管理系統,旨在為線上事務處理(OLTP) 工作負載提供 NoSQL 系統的可延伸性,同時保持傳統資料庫系統的 ACID 保證。
國內比較知名的 NewSQL 有阿里的 OceanBase、騰訊的 TDSQL、PingCAP 的 TiDB。它們既有 MySQL 的功能,又有分散式可延伸的能力。
筆者對阿里的 OceanBase 只能說是略懂皮毛,就不過多描述。
我們重點看一下騰訊的 TDSQL 和 PingCAP 的 TiDB。

從兩者的架構圖(省略了部分模組)上可以看出,TDSQL 和 TiDB 的架構只有一些命名差別,可以說幾乎一模一樣。
兩者整體來說分為三個部分:
-
計算:負責接受使用者端的連線,執行 SQL 解析和優化,最終生成分散式執行計劃轉發給底層的儲存層執行。(TDSQL:SQL Engine 、TiDB:TiDB-Server)
-
儲存:分散式_KV 儲存_,類似 NoSQL 資料庫,支援彈性擴容和縮容。(TDSQL:TDStore 、TiDB:TiKV)
-
管控:整個叢集的元資訊管理模組,是整個叢集的大腦。(TDSQL:TDMetaCluster 、TiDB:Placement Driver )
兩者核心的儲存模組(TDStore/TiKV),都是基於 RocksDB 開發而來,都是_KV 儲存_的模式。
RocksDB 是由 Facebook 基於 LevelDB 開發的一款提供鍵值儲存與讀寫功能的 LSM-tree 架構引擎。
底層利用了_WAL(Write Ahead Log)技術_和_Sorted String Table_,比 B 樹類儲存引擎更高的寫吞吐。
NewSQL 平滑接入方案
因為筆者落地過 TiDB,所以會以 TiDB 為例描述如何接入 NewSQL,做到不影響線上使用的平滑遷移。
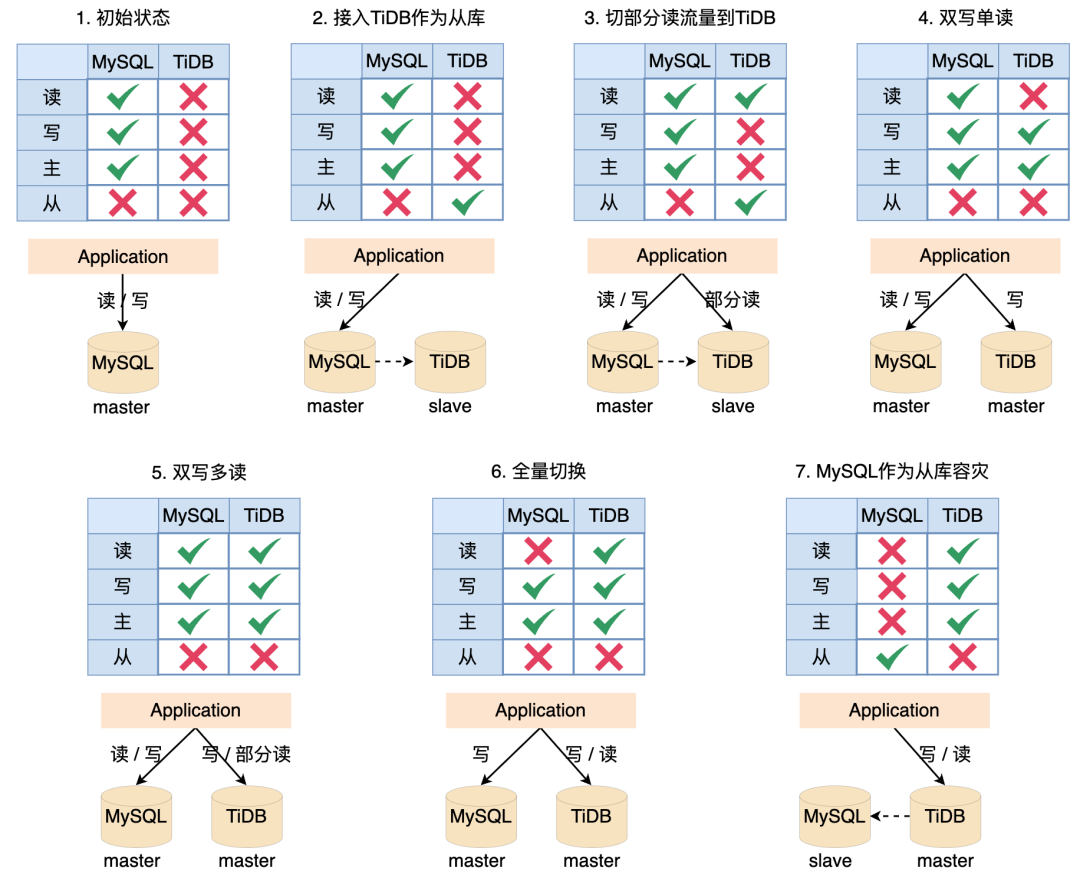
第一步:初始狀態,所有線上讀和寫都落到 MySQL。
第二步:將 TiDB 作為 MySQL 的從節點接入系統,所有線上讀寫還是都落到 MySQL,日末通過指令碼或者任務驗證 MySQL 的資料和 TiDB 的資料是否一致,這一步主要驗證 MySQL 資料同步到 TiDB 沒有問題。
第三步:將部分讀切換到 TiDB,這一步主要驗證 TiDB 同步的資料讀沒有問題,驗證系統 SQL 能正常在 TiDB 執行。
第四步:斷掉 MySQL 和 TiDB 之間的同步,雙寫 MySQL 和 TiDB,所有的線上讀流量都落到 MySQL。
第五步:將部分讀流量切到 TiDB,驗證 TiDB 寫入的資料能夠正常讀取。這一階段可以將部分冪等任務同時在兩個資料來源上執行,驗證兩者資料是否一致。
第六步:將所有的線上讀流量切到 TiDB,同時保持雙寫,如果出問題隨即切到 MySQL。
第七步:斷掉 MySQL 的寫流量,將 MySQL 作為 TiDB 的一個從庫,作為降級使用。
整個方案的基礎是:TiDB 相容 MySQL 協定和 MySQL 生態。
這個方案是建立在完全不信任 TiDB的基礎上設計的,驗證了 TiDB 和 MySQL 的契合點,所以整體會比較繁瑣,實際落地的時候可以根據情況省略一部分步驟。
NewSQL 真的有那麼好嗎?
NewSQL 並是不萬能的,也不必去過於神化 NewSQL,國內比較知名的幾種 NewSQL 或多或少都存在部分功能缺陷,以 TiDB 為例:
-
TiDB 的自增 ID 只能保證單個 TiKV 上的自增,並不能保證全域性自增。
-
由於 TiKV 儲存是根據 key 的二進位制順序排列的,使用自增 ID 可能會造成熱塊效應。
-
TiDB 預設 RC(讀已提交)的事務隔離級別,並且不支援 RR(可重複讀)隔離級別,雖然提供了基本等價於RR的SI(Snapshot Isolation),但還是存在_寫偏斜_問題
-
TiDB 的點查(select point)效能比 MySQL 要差不少,在幾個億級別的資料量才能勉強和 MySQL 打平。
-
因為底層基於 Raft 協定做資料同步,所以 TiDB 延遲會比 MySQL 要高。
-
...
所以說,NewSQL 也並不是屠龍刀,需要根據實際應用去評估這些缺陷帶來的影響。
NewSQL 的應用
NewSQL 在國內其實已經發展了很多年,OceanBase 誕生於 2010 年,TDSQL 可追溯到 2004 年,TiDB 誕生於 2015 年。
三者在國內外積累了不少的客戶案例。
OceanBase
-
OceanBase 已經覆蓋螞蟻集團100%核心鏈路,支撐全部五大業務板塊。目前執行數十億條不同的 SQL、資料量達數百 PB、伺服器核數過百萬。
-
中國工商銀行全行業務都使用 OceanBase,包含不限於存、貸、支付結算及創新業務等。
-
OceanBase 憑藉混合雲架構、高可用、Oracle 相容等特性,通過分散式中介軟體、金融套件、移動開發平臺整合解決方案,支撐網商銀行核心系統數位化轉型。
-
招商銀行的「海量行情繫統」和「歷史收益系統」就是採用 OceanBase 作為底層資料庫。
TDSQL
-
微眾銀行實現了 TDSQL 私有化部署,是一個典型的兩地多中心架構。
-
富途證券的港股交易系統、東吳證券新一代核心交易系統底層儲存都是 TDSQL。
-
數位廣東粵省事、深圳地鐵碼上乘車等業務都是在 TDSQL 上面跑的。
-
平安銀行、中國農業銀行、華夏銀行、中國銀行都有相關業務在 TDSQL 上。
TiDB
-
北京銀行的網聯支付業務,所有北京銀行的銀行卡繫結在比如支付寶、微信上的支付操作,後端的資料庫就是執行在 TiDB,而且是一個典型的兩地三中心同城雙活的架構,這個業務非常的關鍵,如果業務中斷超過一定時間,就是需要上報銀監會的。
-
日本排名第一的支付公司——Paypay,錢包和支付的業務都在 TiDB 上面。
-
中國人壽的壽財險業務,正在用 TiDB 陸續替換 Oracle 。
-
肯德基所有的會員登入系統,包括 KFC 的 APP 以及第三方登入,後臺資料庫都是用的 TiDB ,這套業務 2020 年 4 月份上線,已經經歷過多次肯德基的大促等活動,目前肯德基的後臺支付系統也已經切換到 TiDB 上。
-
麥當勞的賬戶以及訂單系統全部基於 TiDB,如果 TiDB 出問題了,那麼國內所有的麥當勞門店,包括線上和線下的點單系統都將沒法正常執行。
-
微眾銀行最核心和最賺錢的微粒貸業務,後臺的全量批次處理業務就執行在 TiDB 上面。
分庫分表和 NewSQL 到底怎麼選?
分庫分表是一個重量級的方案,它會帶來很多新的問題,對基建和運維的要求也很高。
NewSQL 功能強大但也有功能缺陷。
如何去抉擇需要根據系統現狀和公司情況去綜合判斷。
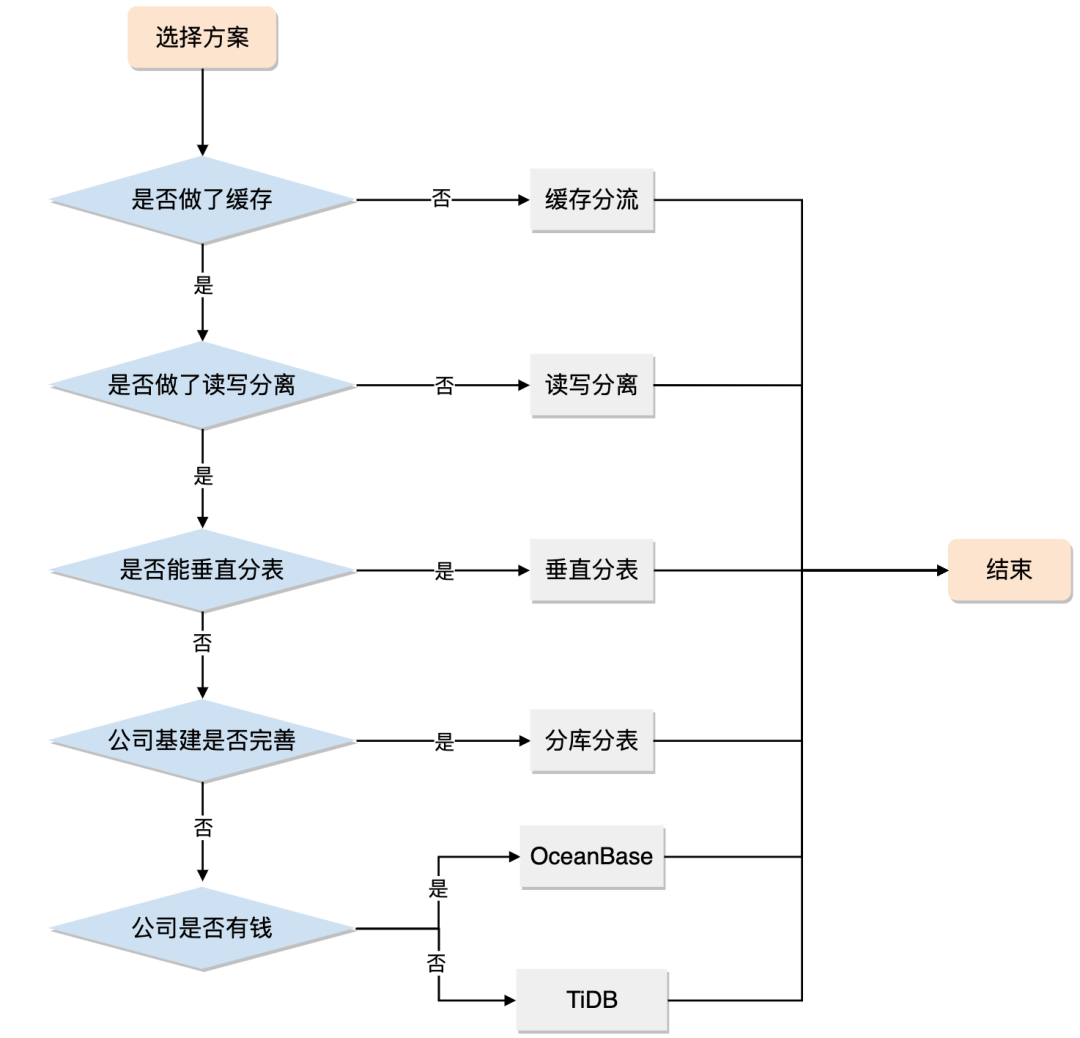
分庫分表是一個重量級的方案,如果_讀寫分離_、冷熱分離_等輕量級方案能解決的問題就沒必要上_分庫分表。
如果快取分流和讀寫分離都扛不住了,且你身處網際網路企業,基建尚可且運維也跟得上,_分庫分表_仍然是第一選擇;
但如果你身處一個傳統的企業,基建很差甚至沒有基建,那麼你可以考慮考慮_NewSQL_。
技術沒有高低之分,能解決問題的技術就是好技術,技術方案選擇上切莫炫技,也切勿過度設計!
參考資料
- https://shardingsphere.apache.org/document/current/cn/overview/
- https://docs.pingcap.com/zh/tidb/stable/tidb-architecture
- https://www.oceanbase.com/customer/home
- https://dbaplus.cn/news-11-1854-1.html
