Node.js精進(9)——效能監控(上)
市面上成熟的 Node.js 效能監控系統,監控的指標有很多。
以開源的 Easy-Monitor 為例,在系統監控一欄中,指標包括記憶體、CPU、GC、程序、磁碟等。
這些系統能全方位的監控著應用的一舉一動,並且可以提供安全提醒、線上分析、匯出真實狀態等服務。
本專題分為上下兩個篇章,會簡單分析下在 Node.js 環境中的幾個資源瓶頸,包括CPU 、記憶體和程序奔潰,並且會給出相應的監控方法。
本系列所有的範例原始碼都已上傳至Github,點選此處獲取。
一、CPU
在 Linux 系統中,可以通過 top 命令看到當前的 CPU 資源利用率、記憶體使用等資訊,並且可按特定指標排序,類似於 Windows 的工作管理員。
在 Node.js 中,提供了兩個方法可以讀取和計算出 CPU 負載和 CPU 使用率兩個指標。
這兩個指標在一定程度上都可以反映一臺計算機的繁忙程度。
1)CPU 負載
CPU 負載是指在一段時間內等待或佔用 CPU 的程序數,程序是作業系統中資源分配的最小單位。
平均負載(Load Average)就是那些程序數除以時間得到的平均數。
假設一臺計算機只有一個 CPU 並且是一核,將 CPU 比作一座只有一條單向車道的橋,車比作程序。
- 當平均負載為 0 時,橋上沒有車。
- 當平均負載為 0.5 時,橋上一半路段有車。
- 當平均負載為 1 時,橋上所有路段都有車,雖然大橋已滿,但不會堵車。
- 當平均負載為 2 時,大橋已滿,並且還多了一樣多的車在橋外排隊等待。
如果 CPU 每分鐘可以處理 100 個程序,那麼當平均負載是 2 時,還有 100 個程序在排隊等待中。
現在的晶片廠商往往會讓 1 個 CPU 包含多個核,並且還能將 1 個核虛擬成 2 個邏輯 CPU,CPU 負載建議的計算方式是:
(CPU個數 * 核數 * 2 * 0.8)或者(CPU個數 * 核數 * 2 * 0.7)
不建議 CPU 長期滿負荷工作。對於平均負載的量化,會採用三個時間標準:1 分鐘,5 分鐘和 15 分鐘。
1 分鐘的時間比較短,有時候峰值突然升高,有可能是暫時現象。
5 分鐘和 15 分鐘是較為合適的評判指標,當這兩個時間段內的平均負載都大於 1,那就表明問題持續存在。
這是一個危險的訊號,CPU 上等待的程序在增多,若不及時清理,就會越堵越長,影響程式的正常執行。
在 os 模組中,提供了 loadavg() 方法,可以得到一個包含 1、5 和 15 分鐘的平均負載的陣列。
const os = require("os");
os.loadavg(); // [ 1.9951171875, 1.951171875, 1.93359375 ]
注意,平均負載是 Unix 特有的概念,在 Windows 上,返回值始終為 [0, 0, 0]。
2)CPU 使用率
CPU 使用率是指程式在執行期間佔用 CPU 的百分比,也就是說量化 CPU 的佔用情況,計算方式如下:
CPU使用率 = (1 - CPU空閒時間 / CPU總時間) * 100
CPU 使用率高,並不意味著 CPU 負載也高,例如當前任務很少,其中有一個需要大量的計算(CPU 密集型場景),那麼使用率會很高,但負載很低。
CPU 負載高,並不意味著 CPU 使用率也高,例如當前任務很多,在任務執行過程中因為等待 I/O 使得 CPU 非常空閒(I/O 密集型場景),那麼使用率就會變低,但負載很高。
在 os 模組中,提供了 cpus() 方法,可得到以每個邏輯 CPU 核心資訊組成的物件陣列,如下所示。
[ { model: 'Intel(R) Core(TM) i9-9880H CPU @ 2.30GHz', speed: 2300, times: { user: 27207990, nice: 0, sys: 17891890, idle: 179286370, irq: 0 } }, { model: 'Intel(R) Core(TM) i9-9880H CPU @ 2.30GHz', speed: 2300, times: { user: 294240, nice: 0, sys: 352550, idle: 223732290, irq: 0 } }, ]
其中 times 屬性是一些時間資訊,其中 nice 值僅適用於 POSIX 平臺。在 Windows 中,所有處理器的 nice 值始終為 0。
- user:CPU 在使用者模式下花費的毫秒數。
- nice:CPU 在良好模式下花費的毫秒數。
- sys:CPU 在系統模式下花費的毫秒數。
- idle:CPU 在空閒模式下花費的毫秒數。
- irq:CPU 在中斷請求模式下花費的毫秒數。
下面用一個範例計算 CPU 使用率,遍歷 CPU 資訊陣列後,將各個時間依次累加,然後返回總時間和空閒時間,最後套用公式計算。
function getCPUInfo() { const cpus = os.cpus(); let user = 0, nice = 0, sys = 0, idle = 0, irq = 0, total = 0; // 遍歷 CPU for (const cpu in cpus) { const times = cpus[cpu].times; user += times.user; nice += times.nice; sys += times.sys; idle += times.idle; irq += times.irq; } total += user + nice + sys + idle + irq; return { idle, total, }; } const cpu = getCPUInfo(); // CPU 使用率 const usage = (1 - cpu.idle / cpu.total) * 100;
3)v8-profiler
Node.js 是基於 V8 引擎執行的,而 V8 引擎內部實現了一個 CPU Profiler,並且開放了相關 API,v8-profiler 就是一個基於這些 API 收集一些執行時資料(例如 CPU 和記憶體)的庫。
不過在安裝時,會報錯,因此需要換一個包:v8-profiler-next,基於 v8-profiler,相容 Node.js V4 以上的所有版本。
../src/cpu_profiler.cc:6:9: error: no member named 'Handle' in namespace 'v8'; did you mean 'v8::CodeEventHandler::Handle'?
在下面的範例中,是一段需要消耗 CPU 計算的加密程式碼。
const crypto = require('crypto');
const password = 'test'
const salt = crypto.randomBytes(128).toString('base64')
crypto.pbkdf2Sync(password, salt, 10000, 64, 'sha512').toString('hex')
在下面的範例中,會在 1 分鐘後匯出一份 CPU 分析檔案,執行後會在當前目錄生成 cpuprofile 字尾的檔案。
const fs = require('fs');
const v8Profiler = require('v8-profiler-next');
const title = 'test';
// 相容 vscode 中的 cpuprofile 解析
v8Profiler.setGenerateType(1);
v8Profiler.startProfiling(title, true);
// 1分鐘後執行
setTimeout(() => {
const profile = v8Profiler.stopProfiling(title);
// 匯出CPU分析檔案
profile.export(function (error, result) {
fs.writeFileSync(`${title}.cpuprofile`, result);
profile.delete();
});
}, 60 * 1000);
點選 Chrome DevTools 工具列右側的更多按鈕,選擇 More tools -> JavaScript Profiler 進入到 CPU 的分析頁面。
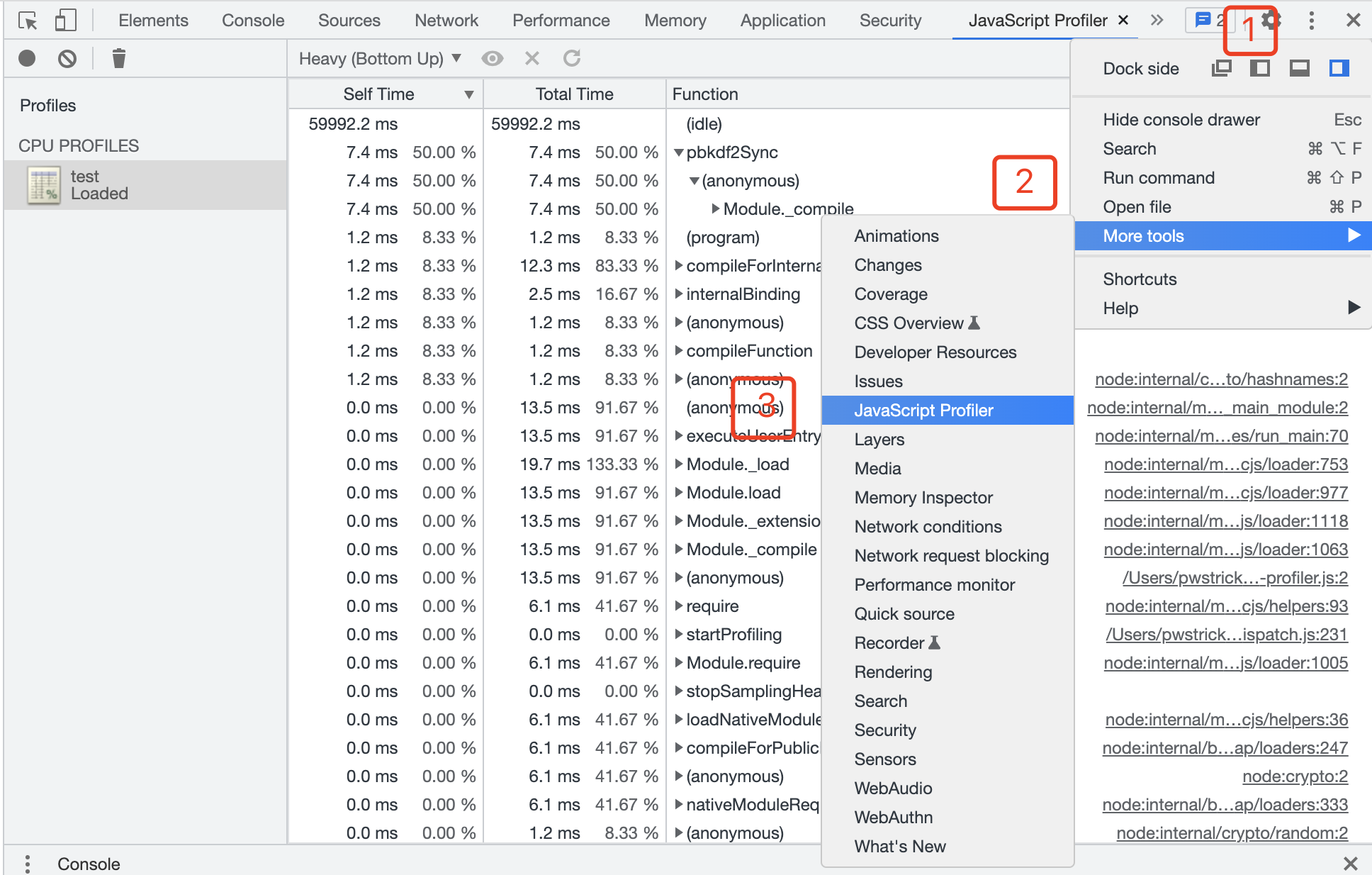
將分析檔案 Load 進來,首先看到的是 Heavy 檢視的分析結果,在圖中選中的下拉框中還可以選擇 Chart 和 tree。
前者能顯示火焰圖,按時間順序排列;後者能顯示呼叫結構的總體狀況,從呼叫堆疊的頂端開始,即從最初呼叫的位置開始。

在 Heavy 檢視中,會按照對應用的效能影響程度從高到低排列,這其中有 3 個指標:
- Self Time:完成當前函數呼叫所用的時間,僅包括函數本身的語句,不包括它呼叫的任何子函數。
- Total Time:完成此函數的當前呼叫以及它呼叫的任何子函數所花費的總時間。
- Function:函數名及其全路徑,可展開檢視子函數。
切換到 Tree 檢視,逐層開啟,就可以看到 pbkdf2Sync() 函數佔據了 CPU 的大部分時間。
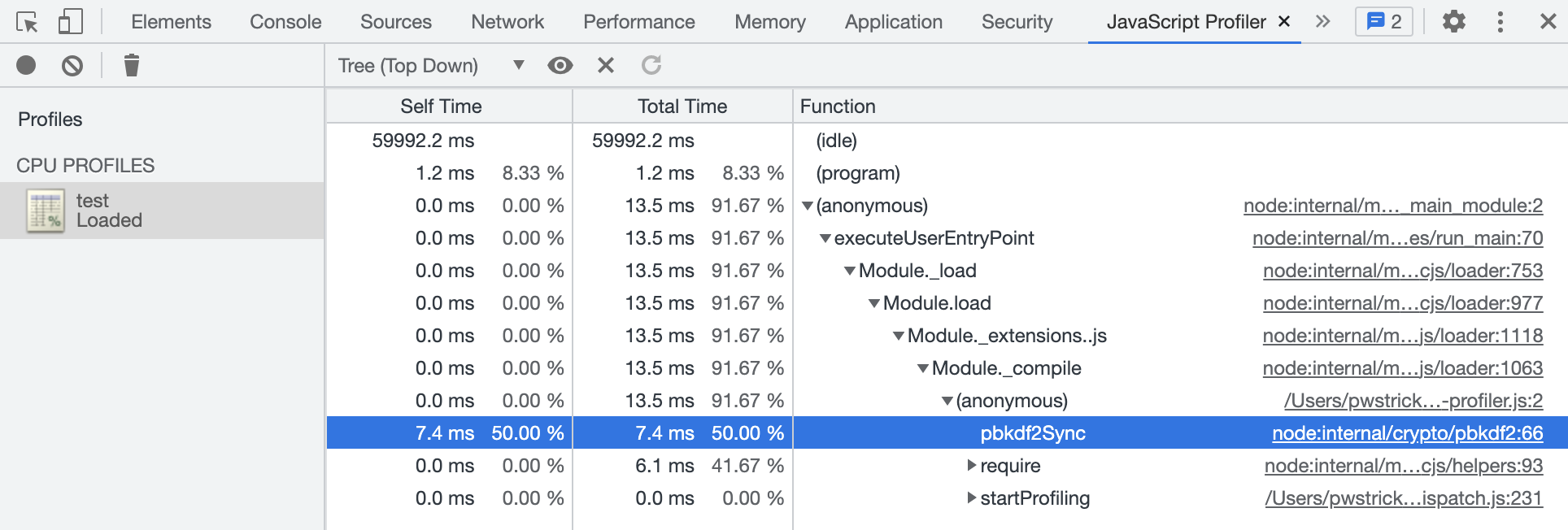
上圖中的 (program) 只計算了 native code 的時間,不包含執行指令碼程式碼的時間(即沒有在 JavaScript 的堆疊上),idle 也是 native 在執行 (program) 的一種。
二、垃圾回收器
Node.js 是一個基於 V8 引擎的 JavaScript 執行時環境,而 Node.js 中的垃圾回收器(GC)其實就是 V8 的垃圾回收器。
這麼多年來,V8 的垃圾回收器(Garbage Collector,簡寫GC)從一個全停頓(Stop-The-World),慢慢演變成了一個更加並行,並行和增量的垃圾回收器。
本節內容參考了 V8 團隊分享的文章:Trash talk: the Orinoco garbage collector。
1)代際假說
在垃圾回收中有一個重要術語:代際假說(The Generational Hypothesis),這個假說不僅僅適用於 JavaScript,同樣適用於大多數的動態語言,Java、Python 等。
代際假說表明很多物件在記憶體中存在的時間很短,即從垃圾回收的角度來看,很多物件在分配記憶體空間後,很快就變得不可存取。
2)兩種垃圾回收器
在 V8 中,會將堆分為兩塊不同的區域:新生代(Young Generation)和老生代(Old Generation)。
新生代中存放的是生存時間短的物件,大小在 1~ 8M之間;老生代中存放的生存時間久的物件。
對於這兩塊區域,V8 會使用兩個不同的垃圾回收器:
- 副垃圾回收器(Scavenger)主要負責新生代的垃圾回收。如果經過垃圾回收後,物件還存活的話,就會從新生代移動到老生代。
- 主垃圾回收器(Full Mark-Compact)主要負責老生代的垃圾回收。
無論哪種垃圾回收器,都會有一套共同的工作流程,定期去做些任務:
- 標記活動物件和非活動物件,前者是還在使用的物件,後者是可以進行垃圾回收的物件。
- 回收或者重用被非活動物件佔據的記憶體,就是在標記完成後,統一清理那些被標記為可回收的物件。
- 整理記憶體碎片(不連續的記憶體空間),這一步是可選的,因為有的垃圾回收器不會產生記憶體碎片。
3)副垃圾回收器
V8 為新生代採用 Scavenge 演演算法,會將記憶體空間劃分成兩個區域:物件區域(From-Space)和空閒區域(To-Space)。
副垃圾回收器在清理新生代時,會先將所有的活動物件移動(evacuate)到連續的一塊空閒記憶體中(這樣能避免記憶體碎片)。
然後將兩塊記憶體空間互換,即把 To-Space 變成 From-Space。

接著為了新生代的記憶體空間不被耗盡,對於兩次垃圾回收後還活動的物件,會把它們移動到老生代,而不是 To-Space。

最後是更新參照已移動的原始物件的指標。上述幾步都是交錯進行,而不是在不同階段執行。
4)主垃圾回收器
主垃圾回收器負責老生代的清理,而在老生代中,除了新生代中晉升的物件之外,還有一些大的物件也會被分配到此處。
主垃圾回收器採用了 Mark-Sweep(標記清除)和 Mark-Compact(標記整理)兩種演演算法,其中涉及三個階段:標記(marking),清除(sweeping)和整理(compacting)。
(1)在標記階段,會從一組根元素開始,遞迴遍歷這組根元素。其中根元素包括執行堆疊和全域性物件,瀏覽器環境下的全域性物件是 window,Node.js 環境下是 global。
在這個遍歷過程中,會追溯每一個指向 JavaScript 物件的指標,將其標記為可存取,同時追溯物件中每一個屬性的指標。
這個過程會一直持續至找到並標記執行時可到達的所有物件,而那些追溯不到的就是垃圾資料。
(2)在清除階段,會將非活動物件佔用的記憶體空間新增到一個叫空閒列表的資料結構中。
空閒列表中的記憶體塊由大小來區分,這是為了方便以後需要分配記憶體時,可以快速的找到大小合適的記憶體空間並分配給新的物件。
下圖描繪了在將垃圾資料回收前後,記憶體佔用的情況。

可以看出,在執行清除演演算法後,會產生大量不連續的記憶體碎片。
(3)在整理階段,會讓所有活動的物件都向一端移動,然後直接清理掉端邊界以外的記憶體,如下圖所示。

5)垃圾回收機制
在本節開頭提到了並行(parallel)、增量(incremental)和並行(concurrent)三種垃圾回收機制。
(1)並行是指主執行緒和協助執行緒同時執行同樣的工作,這仍然是一種全停頓。
但垃圾回收所耗費的時間等於總時間除以參與的執行緒數量(加上一些同步開銷)。
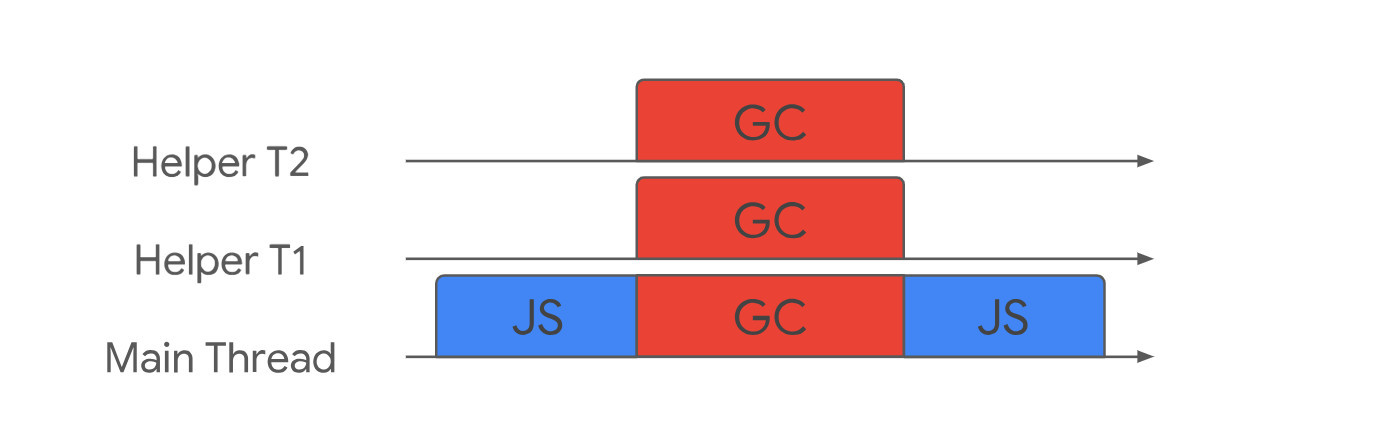
(2)增量是指主執行緒間歇性的去做少量的垃圾回收,而不是花一整段時間去執行。
雖然沒有減少主執行緒暫停的時間,但 JavaScript 的執行都能得到及時的響應。
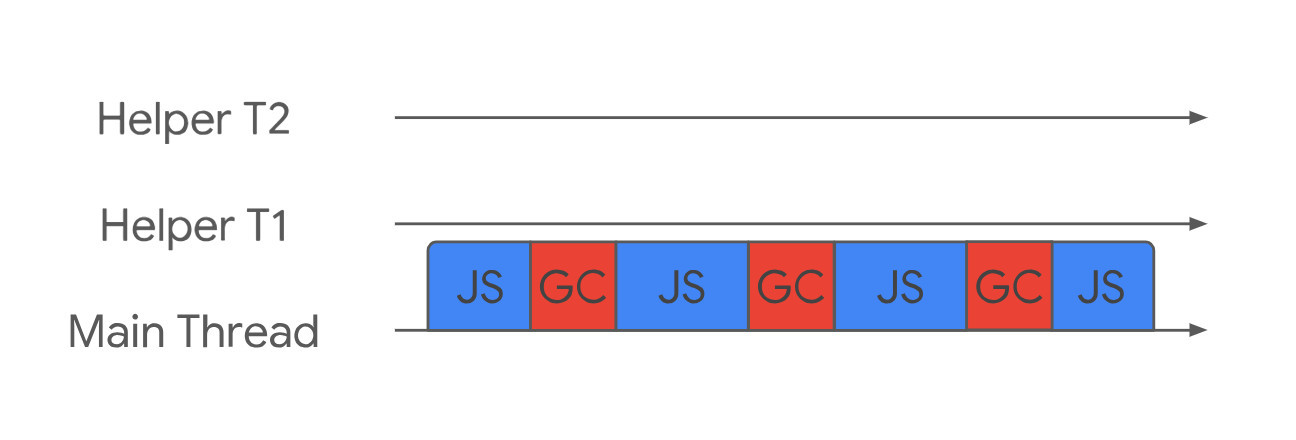
(3)並行是指主執行緒一直執行 JavaScript,而輔助執行緒在後臺執行垃圾回收,這種實現起來最難,需要處理很多複雜的場景。
例如 JavaScript 堆上的任何東西都可以隨時更改,使之前所做的工作無效。 況且現在有讀/寫競爭,輔助執行緒和主執行緒有可能同時在更改同一個物件。
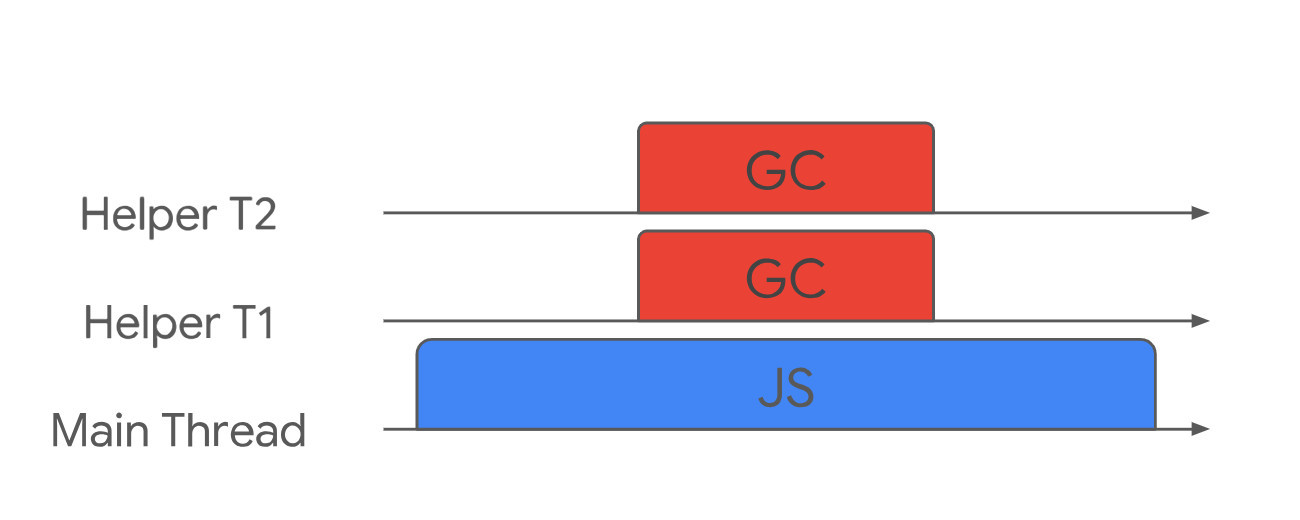
V8 在新生代垃圾回收中會使用並行清理,每個協助執行緒會將所有的活動物件都移動到 To-Space。
主垃圾回收器主要使用並行標記,當堆的動態分配接近最高閾值時,會啟動並行標記任務。
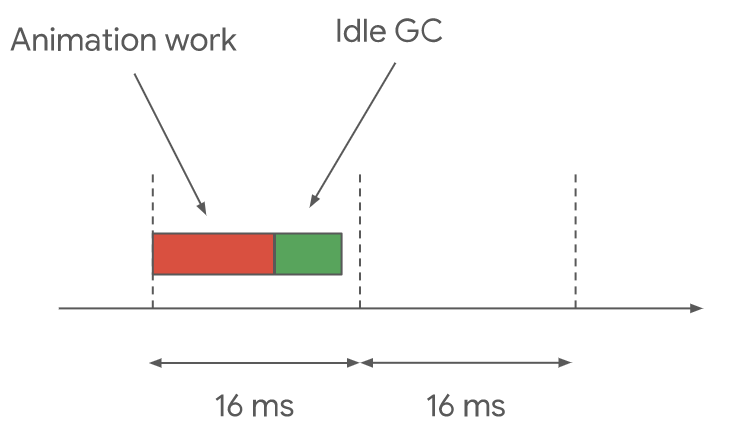
V8 會利用主執行緒上的空閒時間主動的去執行垃圾回收,在 Chrome 中,大約有 16.6 毫秒的時間去渲染動畫的每一幀。
如果動畫提前完成,那麼就能在下一幀之前的空閒時間去觸發垃圾回收。
在《綜合性 GC 問題和優化》一文中提到,絕大部分的 GC 引發的問題會表現在 CPU 上,而本質上這類問題卻是 GC 引起的記憶體問題。
一般產生的流程是:先在堆記憶體不斷達到觸發 GC 的預設條件,然後不斷觸發 GC,最後 CPU 飆高。
參考資料:
深入 Nodejs 原始碼探究 CPU 資訊的獲取與實時計算
Difference between 'self' and 'total' in Chrome CPU Profile of JS
Deep understanding of chrome V8 garbage collection mechanism