mongodb 資料塊遷移的原始碼分析
1. 簡介
上一篇我們聊到了mongodb資料塊的基本概念,和資料塊遷移的主要流程,這篇文章我們聊聊原始碼實現部分。
2. 遷移序列圖
資料塊遷移的請求是從設定伺服器(config server)發給(donor,捐獻方),再有捐獻方發起遷移請求給目標節點(recipient,接收方),後續遷移由捐獻方和接收方配合完成。
資料遷移結束時,捐獻方再提交遷移結果給設定伺服器,三方互動序列圖如下:
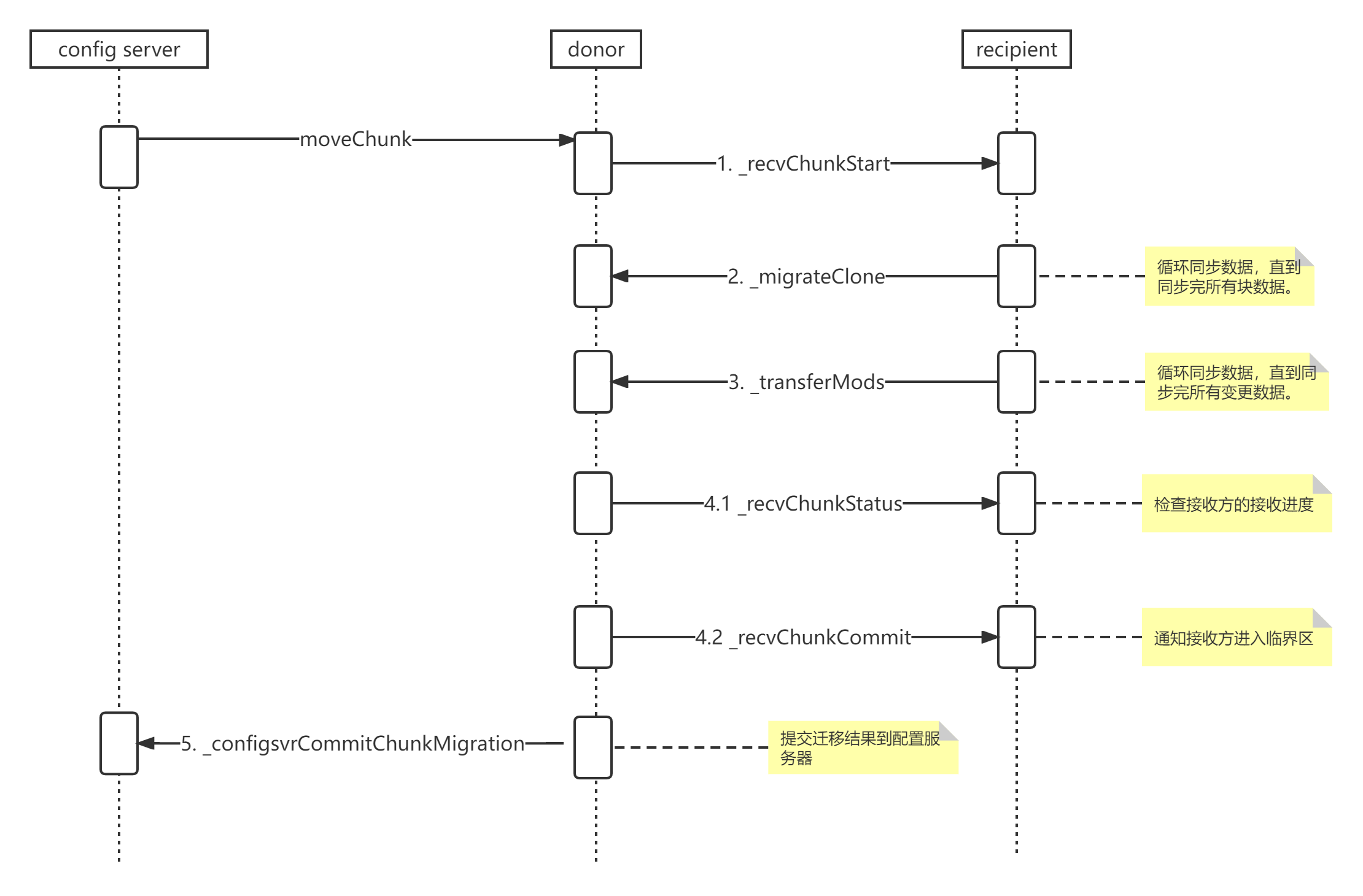
可以看到,序列圖中的5個步驟,是對應前面文章的遷移流程中的5個步驟,其中接收方的流程控制程式碼在migration_destination_manager.cpp中的_migrateDriver方法中,捐獻方的流程控制程式碼在donor的move_chunk_command.cpp中的_runImpl方法中完成,程式碼如下:
static void _runImpl(OperationContext* opCtx, const MoveChunkRequest& moveChunkRequest) { const auto writeConcernForRangeDeleter = uassertStatusOK(ChunkMoveWriteConcernOptions::getEffectiveWriteConcern( opCtx, moveChunkRequest.getSecondaryThrottle())); // Resolve the donor and recipient shards and their connection string auto const shardRegistry = Grid::get(opCtx)->shardRegistry(); // 準備donor和recipient的連線 const auto donorConnStr = uassertStatusOK(shardRegistry->getShard(opCtx, moveChunkRequest.getFromShardId())) ->getConnString(); const auto recipientHost = uassertStatusOK([&] { auto recipientShard = uassertStatusOK(shardRegistry->getShard(opCtx, moveChunkRequest.getToShardId())); return recipientShard->getTargeter()->findHost( opCtx, ReadPreferenceSetting{ReadPreference::PrimaryOnly}); }()); std::string unusedErrMsg; // 用於統計每一步的耗時情況 MoveTimingHelper moveTimingHelper(opCtx, "from", moveChunkRequest.getNss().ns(), moveChunkRequest.getMinKey(), moveChunkRequest.getMaxKey(), 6, // Total number of steps &unusedErrMsg, moveChunkRequest.getToShardId(), moveChunkRequest.getFromShardId()); moveTimingHelper.done(1); moveChunkHangAtStep1.pauseWhileSet(); if (moveChunkRequest.getFromShardId() == moveChunkRequest.getToShardId()) { // TODO: SERVER-46669 handle wait for delete. return; } // 構建遷移工作管理員 MigrationSourceManager migrationSourceManager( opCtx, moveChunkRequest, donorConnStr, recipientHost); moveTimingHelper.done(2); moveChunkHangAtStep2.pauseWhileSet(); // 向接收方傳送遷移命令 uassertStatusOKWithWarning(migrationSourceManager.startClone()); moveTimingHelper.done(3); moveChunkHangAtStep3.pauseWhileSet(); // 等待塊資料和變更資料都拷貝完成 uassertStatusOKWithWarning(migrationSourceManager.awaitToCatchUp()); moveTimingHelper.done(4); moveChunkHangAtStep4.pauseWhileSet(); // 進入臨界區 uassertStatusOKWithWarning(migrationSourceManager.enterCriticalSection()); // 通知接收方 uassertStatusOKWithWarning(migrationSourceManager.commitChunkOnRecipient()); moveTimingHelper.done(5); moveChunkHangAtStep5.pauseWhileSet(); // 在設定伺服器提交分塊後設資料資訊 uassertStatusOKWithWarning(migrationSourceManager.commitChunkMetadataOnConfig()); moveTimingHelper.done(6); moveChunkHangAtStep6.pauseWhileSet(); }
下面對每一個步驟的程式碼做分析。
3. 各步驟原始碼分析
3.1 啟動遷移( _recvChunkStart)
在啟動階段,捐獻方主要做了三件事:
1. 引數檢查,在MigrationSourceManager 建構函式中完成,不再贅述。
2. 註冊監聽器,用於記錄在遷移期間該資料塊內發生的變更資料,程式碼如下:
3. 向接收方傳送遷移命令_recvChunkStart。
步驟2和3的程式碼實現在一個方法中,如下:
Status MigrationSourceManager::startClone() { ...// 省略了部分程式碼 _cloneAndCommitTimer.reset(); auto replCoord = repl::ReplicationCoordinator::get(_opCtx); auto replEnabled = replCoord->isReplEnabled(); { const auto metadata = _getCurrentMetadataAndCheckEpoch(); // Having the metadata manager registered on the collection sharding state is what indicates // that a chunk on that collection is being migrated. With an active migration, write // operations require the cloner to be present in order to track changes to the chunk which // needs to be transmitted to the recipient. // 註冊監聽器,_cloneDriver除了遷移資料外,還會用於記錄在遷移過程中該資料塊增量變化的資料(比如新增的資料) _cloneDriver = std::make_unique<MigrationChunkClonerSourceLegacy>( _args, metadata.getKeyPattern(), _donorConnStr, _recipientHost); AutoGetCollection autoColl(_opCtx, getNss(), replEnabled ? MODE_IX : MODE_X, AutoGetCollectionViewMode::kViewsForbidden, _opCtx->getServiceContext()->getPreciseClockSource()->now() + Milliseconds(migrationLockAcquisitionMaxWaitMS.load())); auto csr = CollectionShardingRuntime::get(_opCtx, getNss()); auto lockedCsr = CollectionShardingRuntime::CSRLock::lockExclusive(_opCtx, csr); invariant(nullptr == std::exchange(msmForCsr(csr), this)); _coordinator = std::make_unique<migrationutil::MigrationCoordinator>( _cloneDriver->getSessionId(), _args.getFromShardId(), _args.getToShardId(), getNss(), *_collectionUUID, ChunkRange(_args.getMinKey(), _args.getMaxKey()), _chunkVersion, _args.getWaitForDelete()); _state = kCloning; } if (replEnabled) { auto const readConcernArgs = repl::ReadConcernArgs( replCoord->getMyLastAppliedOpTime(), repl::ReadConcernLevel::kLocalReadConcern); // 檢查當前節點狀態是否滿足repl::ReadConcernLevel::kLocalReadConcern auto waitForReadConcernStatus = waitForReadConcern(_opCtx, readConcernArgs, StringData(), false); if (!waitForReadConcernStatus.isOK()) { return waitForReadConcernStatus; } setPrepareConflictBehaviorForReadConcern( _opCtx, readConcernArgs, PrepareConflictBehavior::kEnforce); } _coordinator->startMigration(_opCtx); // 向接收方傳送開始拷貝資料的命令(_recvChunkStart) Status startCloneStatus = _cloneDriver->startClone(_opCtx, _coordinator->getMigrationId(), _coordinator->getLsid(), _coordinator->getTxnNumber()); if (!startCloneStatus.isOK()) { return startCloneStatus; } scopedGuard.dismiss(); return Status::OK(); }
接收方在收到遷移請求後,會先檢查本地是否有該表,如果沒有的話,會先建表會建立表的索引:
void MigrationDestinationManager::cloneCollectionIndexesAndOptions( OperationContext* opCtx, const NamespaceString& nss, const CollectionOptionsAndIndexes& collectionOptionsAndIndexes) { { // 1. Create the collection (if it doesn't already exist) and create any indexes we are // missing (auto-heal indexes). ...// 省略部分程式碼 { AutoGetCollection collection(opCtx, nss, MODE_IS); // 如果存在表,且不缺索引,則退出 if (collection) { checkUUIDsMatch(collection.getCollection()); auto indexSpecs = checkEmptyOrGetMissingIndexesFromDonor(collection.getCollection()); if (indexSpecs.empty()) { return; } } } // Take the exclusive database lock if the collection does not exist or indexes are missing // (needs auto-heal). // 建表時,需要對資料庫加鎖 AutoGetDb autoDb(opCtx, nss.db(), MODE_X); auto db = autoDb.ensureDbExists(); auto collection = CollectionCatalog::get(opCtx)->lookupCollectionByNamespace(opCtx, nss); if (collection) { checkUUIDsMatch(collection); } else { ...// 省略部分程式碼// We do not have a collection by this name. Create the collection with the donor's // options. // 建表 OperationShardingState::ScopedAllowImplicitCollectionCreate_UNSAFE unsafeCreateCollection(opCtx); WriteUnitOfWork wuow(opCtx); CollectionOptions collectionOptions = uassertStatusOK( CollectionOptions::parse(collectionOptionsAndIndexes.options, CollectionOptions::ParseKind::parseForStorage)); const bool createDefaultIndexes = true; uassertStatusOK(db->userCreateNS(opCtx, nss, collectionOptions, createDefaultIndexes, collectionOptionsAndIndexes.idIndexSpec)); wuow.commit(); collection = CollectionCatalog::get(opCtx)->lookupCollectionByNamespace(opCtx, nss); } // 建立對應的索引 auto indexSpecs = checkEmptyOrGetMissingIndexesFromDonor(collection); if (!indexSpecs.empty()) { WriteUnitOfWork wunit(opCtx); auto fromMigrate = true; CollectionWriter collWriter(opCtx, collection->uuid()); IndexBuildsCoordinator::get(opCtx)->createIndexesOnEmptyCollection( opCtx, collWriter, indexSpecs, fromMigrate); wunit.commit(); } } }
3.2 接收方拉取存量資料( _migrateClone)
接收方的拉取存量資料時,做了六件事情:
1. 定義了一個批次插入記錄的方法。
2. 定義了一個批次拉取資料的方法。
3. 定義生產者和消費佇列。
4. 啟動資料寫入執行緒,該執行緒會消費佇列中的資料,並呼叫批次插入記錄的方法把記錄儲存到本地。
5. 迴圈向捐獻方發起拉取資料請求(步驟2的方法),並寫入步驟3的佇列中。
6. 資料拉取結束後(寫入空記錄到佇列中,觸發步驟5結束),則同步等待步驟5的執行緒也結束。
詳細程式碼如下:
// 1. 定義批次寫入函數 auto insertBatchFn = [&](OperationContext* opCtx, BSONObj arr) { auto it = arr.begin(); while (it != arr.end()) { int batchNumCloned = 0; int batchClonedBytes = 0; const int batchMaxCloned = migrateCloneInsertionBatchSize.load(); assertNotAborted(opCtx); write_ops::InsertCommandRequest insertOp(_nss); insertOp.getWriteCommandRequestBase().setOrdered(true); insertOp.setDocuments([&] { std::vector<BSONObj> toInsert; while (it != arr.end() && (batchMaxCloned <= 0 || batchNumCloned < batchMaxCloned)) { const auto& doc = *it; BSONObj docToClone = doc.Obj(); toInsert.push_back(docToClone); batchNumCloned++; batchClonedBytes += docToClone.objsize(); ++it; } return toInsert; }()); const auto reply = write_ops_exec::performInserts(opCtx, insertOp, OperationSource::kFromMigrate); for (unsigned long i = 0; i < reply.results.size(); ++i) { uassertStatusOKWithContext( reply.results[i], str::stream() << "Insert of " << insertOp.getDocuments()[i] << " failed."); } { stdx::lock_guard<Latch> statsLock(_mutex); _numCloned += batchNumCloned; ShardingStatistics::get(opCtx).countDocsClonedOnRecipient.addAndFetch( batchNumCloned); _clonedBytes += batchClonedBytes; } if (_writeConcern.needToWaitForOtherNodes()) { runWithoutSession(outerOpCtx, [&] { repl::ReplicationCoordinator::StatusAndDuration replStatus = repl::ReplicationCoordinator::get(opCtx)->awaitReplication( opCtx, repl::ReplClientInfo::forClient(opCtx->getClient()).getLastOp(), _writeConcern); if (replStatus.status.code() == ErrorCodes::WriteConcernFailed) { LOGV2_WARNING( 22011, "secondaryThrottle on, but doc insert timed out; continuing", "migrationId"_attr = _migrationId->toBSON()); } else { uassertStatusOK(replStatus.status); } }); } sleepmillis(migrateCloneInsertionBatchDelayMS.load()); } }; // 2. 定義批次拉取函數 auto fetchBatchFn = [&](OperationContext* opCtx) { auto res = uassertStatusOKWithContext( fromShard->runCommand(opCtx, ReadPreferenceSetting(ReadPreference::PrimaryOnly), "admin", migrateCloneRequest, Shard::RetryPolicy::kNoRetry), "_migrateClone failed: "); uassertStatusOKWithContext(Shard::CommandResponse::getEffectiveStatus(res), "_migrateClone failed: "); return res.response; }; SingleProducerSingleConsumerQueue<BSONObj>::Options options; options.maxQueueDepth = 1; // 3. 使用生產者和消費者佇列來把同步的資料寫入到本地 SingleProducerSingleConsumerQueue<BSONObj> batches(options); repl::OpTime lastOpApplied; // 4. 定義寫傳輸執行緒,該執行緒會讀取佇列中的資料並寫入本地節點,直到無需要同步的資料時執行緒退出 stdx::thread inserterThread{[&] { Client::initThread("chunkInserter", opCtx->getServiceContext(), nullptr); auto client = Client::getCurrent(); { stdx::lock_guard lk(*client); client->setSystemOperationKillableByStepdown(lk); } auto executor = Grid::get(opCtx->getServiceContext())->getExecutorPool()->getFixedExecutor(); auto inserterOpCtx = CancelableOperationContext( cc().makeOperationContext(), opCtx->getCancellationToken(), executor); auto consumerGuard = makeGuard([&] { batches.closeConsumerEnd(); lastOpApplied = repl::ReplClientInfo::forClient(inserterOpCtx->getClient()).getLastOp(); }); try { while (true) { auto nextBatch = batches.pop(inserterOpCtx.get()); auto arr = nextBatch["objects"].Obj(); if (arr.isEmpty()) { return; } insertBatchFn(inserterOpCtx.get(), arr); } } catch (...) { stdx::lock_guard<Client> lk(*opCtx->getClient()); opCtx->getServiceContext()->killOperation(lk, opCtx, ErrorCodes::Error(51008)); LOGV2(21999, "Batch insertion failed: {error}", "Batch insertion failed", "error"_attr = redact(exceptionToStatus())); } }}; { //6. makeGuard的作用是延遲執行inserterThread.join() auto inserterThreadJoinGuard = makeGuard([&] { batches.closeProducerEnd(); inserterThread.join(); }); // 5. 向捐獻方發起拉取請求,並把資料寫入佇列中 while (true) { auto res = fetchBatchFn(opCtx); try { batches.push(res.getOwned(), opCtx); auto arr = res["objects"].Obj(); if (arr.isEmpty()) { break; } } catch (const ExceptionFor<ErrorCodes::ProducerConsumerQueueEndClosed>&) { break; } } } // This scope ensures that the guard is destroyed
3.3 接收方拉取變更資料( _recvChunkStart)
在本步驟,接收方會再拉取變更資料,即在前面遷移過程中,捐獻方上發生的針對該資料塊的寫入、更新和刪除的記錄,程式碼如下:
// 同步變更資料(_transferMods) const BSONObj xferModsRequest = createTransferModsRequest(_nss, *_sessionId); { // 5. Do bulk of mods // 5. 批次拉取變更資料,迴圈拉取,直至無變更資料 _setState(CATCHUP); while (true) { auto res = uassertStatusOKWithContext( fromShard->runCommand(opCtx, ReadPreferenceSetting(ReadPreference::PrimaryOnly), "admin", xferModsRequest, Shard::RetryPolicy::kNoRetry), "_transferMods failed: "); uassertStatusOKWithContext(Shard::CommandResponse::getEffectiveStatus(res), "_transferMods failed: "); const auto& mods = res.response; if (mods["size"].number() == 0) { // There are no more pending modifications to be applied. End the catchup phase // 無變更資料時,停止迴圈 break; } // 應用拉取到的變更資料 if (!_applyMigrateOp(opCtx, mods, &lastOpApplied)) { continue; } const int maxIterations = 3600 * 50; // 等待從節點完成資料同步 int i; for (i = 0; i < maxIterations; i++) { opCtx->checkForInterrupt(); outerOpCtx->checkForInterrupt(); if (getState() == ABORT) { LOGV2(22002, "Migration aborted while waiting for replication at catch up stage", "migrationId"_attr = _migrationId->toBSON()); return; } if (runWithoutSession(outerOpCtx, [&] { return opReplicatedEnough(opCtx, lastOpApplied, _writeConcern); })) { break; } if (i > 100) { LOGV2(22003, "secondaries having hard time keeping up with migrate", "migrationId"_attr = _migrationId->toBSON()); } sleepmillis(20); } if (i == maxIterations) { _setStateFail("secondary can't keep up with migrate"); return; } } timing.done(5); migrateThreadHangAtStep5.pauseWhileSet(); }
變更資料拉取結束,就進入等待捐獻方進入臨界區,在臨界區內,捐獻方會阻塞寫入請求,因此在未進入臨界區前,仍然需要拉取變更資料:
// 6. Wait for commit // 6. 等待donor進入臨界區 _setState(STEADY); bool transferAfterCommit = false; while (getState() == STEADY || getState() == COMMIT_START) { opCtx->checkForInterrupt(); outerOpCtx->checkForInterrupt(); // Make sure we do at least one transfer after recv'ing the commit message. If we // aren't sure that at least one transfer happens *after* our state changes to // COMMIT_START, there could be mods still on the FROM shard that got logged // *after* our _transferMods but *before* the critical section. if (getState() == COMMIT_START) { transferAfterCommit = true; } auto res = uassertStatusOKWithContext( fromShard->runCommand(opCtx, ReadPreferenceSetting(ReadPreference::PrimaryOnly), "admin", xferModsRequest, Shard::RetryPolicy::kNoRetry), "_transferMods failed in STEADY STATE: "); uassertStatusOKWithContext(Shard::CommandResponse::getEffectiveStatus(res), "_transferMods failed in STEADY STATE: "); auto mods = res.response; // 如果請求到變更資料,則應用到本地,並繼續請求變更資料,直到所有變更資料都遷移結束 if (mods["size"].number() > 0 && _applyMigrateOp(opCtx, mods, &lastOpApplied)) { continue; } if (getState() == ABORT) { LOGV2(22006, "Migration aborted while transferring mods", "migrationId"_attr = _migrationId->toBSON()); return; } // We know we're finished when: // 1) The from side has told us that it has locked writes (COMMIT_START) // 2) We've checked at least one more time for un-transmitted mods // 檢查transferAfterCommit的原因:進入COMMIT_START(臨界區)後,需要再拉取一次變更資料 if (getState() == COMMIT_START && transferAfterCommit == true) { // 檢查所有資料同步到從節點後,資料遷移流程結束 if (runWithoutSession(outerOpCtx, [&] { return _flushPendingWrites(opCtx, lastOpApplied); })) { break; } } // Only sleep if we aren't committing if (getState() == STEADY) sleepmillis(10); }
3.4 進入臨界區( _recvChunkStatus,_recvChunkCommit)
在該步驟,捐獻方主要做了三件事:
1. 等待接收方完成資料同步(_recvChunkStatus)。
2. 標記本節點進入臨界區,阻塞寫操作。
3. 通知接收方進入臨界區(_recvChunkCommit)。
相關程式碼如下:
Status MigrationSourceManager::awaitToCatchUp() { invariant(!_opCtx->lockState()->isLocked()); invariant(_state == kCloning); auto scopedGuard = makeGuard([&] { cleanupOnError(); }); _stats.totalDonorChunkCloneTimeMillis.addAndFetch(_cloneAndCommitTimer.millis()); _cloneAndCommitTimer.reset(); // Block until the cloner deems it appropriate to enter the critical section. // 等待資料拷貝完成,這裡會向接收方傳送_recvChunkStatus,檢查接收方的狀態是否是STEADY Status catchUpStatus = _cloneDriver->awaitUntilCriticalSectionIsAppropriate( _opCtx, kMaxWaitToEnterCriticalSectionTimeout); if (!catchUpStatus.isOK()) { return catchUpStatus; } _state = kCloneCaughtUp; scopedGuard.dismiss(); return Status::OK(); }
// 進入臨界區 Status MigrationSourceManager::enterCriticalSection() { ...// 省略部分程式碼
// 標記進入臨界區,後續更新類操作會被阻塞(通過ShardingMigrationCriticalSection::getSignal()檢查該標記) _critSec.emplace(_opCtx, _args.getNss(), _critSecReason); _state = kCriticalSection; // Persist a signal to secondaries that we've entered the critical section. This is will cause // secondaries to refresh their routing table when next accessed, which will block behind the // critical section. This ensures causal consistency by preventing a stale mongos with a cluster // time inclusive of the migration config commit update from accessing secondary data. // Note: this write must occur after the critSec flag is set, to ensure the secondary refresh // will stall behind the flag. // 通知從節點此時主節點已進入臨界區,如果有資料存取時要重新整理路由資訊(保證因果一致性) Status signalStatus = shardmetadatautil::updateShardCollectionsEntry( _opCtx, BSON(ShardCollectionType::kNssFieldName << getNss().ns()), BSON("$inc" << BSON(ShardCollectionType::kEnterCriticalSectionCounterFieldName << 1)), false /*upsert*/); if (!signalStatus.isOK()) { return { ErrorCodes::OperationFailed, str::stream() << "Failed to persist critical section signal for secondaries due to: " << signalStatus.toString()}; } LOGV2(22017, "Migration successfully entered critical section", "migrationId"_attr = _coordinator->getMigrationId()); scopedGuard.dismiss(); return Status::OK(); }
Status MigrationSourceManager::commitChunkOnRecipient() {
invariant(!_opCtx->lockState()->isLocked());
invariant(_state == kCriticalSection);
auto scopedGuard = makeGuard([&] { cleanupOnError(); });
// Tell the recipient shard to fetch the latest changes.
// 通知接收方進入臨界區,並再次拉取變更資料。
auto commitCloneStatus = _cloneDriver->commitClone(_opCtx);
if (MONGO_unlikely(failMigrationCommit.shouldFail()) && commitCloneStatus.isOK()) {
commitCloneStatus = {ErrorCodes::InternalError,
"Failing _recvChunkCommit due to failpoint."};
}
if (!commitCloneStatus.isOK()) {
return commitCloneStatus.getStatus().withContext("commit clone failed");
}
_recipientCloneCounts = commitCloneStatus.getValue()["counts"].Obj().getOwned();
_state = kCloneCompleted;
scopedGuard.dismiss();
return Status::OK();
}
3.5 提交遷移結果( _configsvrCommitChunkMigration)
此時,資料已經前部遷移結束,捐獻方將會向設定伺服器(config server)提交遷移結果,更新設定伺服器上面的分片資訊,程式碼如下:
BSONObjBuilder builder; { const auto metadata = _getCurrentMetadataAndCheckEpoch(); ChunkType migratedChunkType; migratedChunkType.setMin(_args.getMinKey()); migratedChunkType.setMax(_args.getMaxKey()); migratedChunkType.setVersion(_chunkVersion); // 準備提交更新元資訊的請求 const auto currentTime = VectorClock::get(_opCtx)->getTime(); CommitChunkMigrationRequest::appendAsCommand(&builder, getNss(), _args.getFromShardId(), _args.getToShardId(), migratedChunkType, metadata.getCollVersion(), currentTime.clusterTime().asTimestamp()); builder.append(kWriteConcernField, kMajorityWriteConcern.toBSON()); } // Read operations must begin to wait on the critical section just before we send the commit // operation to the config server // 進入提交階段時,會阻塞讀請求,其實現和阻塞寫請求類似 _critSec->enterCommitPhase(); _state = kCommittingOnConfig; Timer t; // 向設定伺服器提交更新後設資料的請求 auto commitChunkMigrationResponse = Grid::get(_opCtx)->shardRegistry()->getConfigShard()->runCommandWithFixedRetryAttempts( _opCtx, ReadPreferenceSetting{ReadPreference::PrimaryOnly}, "admin", builder.obj(), Shard::RetryPolicy::kIdempotent); if (MONGO_unlikely(migrationCommitNetworkError.shouldFail())) { commitChunkMigrationResponse = Status( ErrorCodes::InternalError, "Failpoint 'migrationCommitNetworkError' generated error"); }
4. 小結
至此,mongodb的資料塊遷移的原始碼基本分析完畢,這裡補充一下監聽變更資料的程式碼實現。
前面有提到監聽變更資料是由_cloneDriver完成的,下面看下_cloneDriver的介面定義:
class MigrationChunkClonerSourceLegacy final : public MigrationChunkClonerSource { ...// 省略部分程式碼 StatusWith<BSONObj> commitClone(OperationContext* opCtx) override; void cancelClone(OperationContext* opCtx) override; bool isDocumentInMigratingChunk(const BSONObj& doc) override;
// 該類定義了三個方法,當捐獻方有寫入、更新和刪除請求時,會分別呼叫這三個方法 void onInsertOp(OperationContext* opCtx, const BSONObj& insertedDoc, const repl::OpTime& opTime) override; void onUpdateOp(OperationContext* opCtx, boost::optional<BSONObj> preImageDoc, const BSONObj& postImageDoc, const repl::OpTime& opTime, const repl::OpTime& prePostImageOpTime) override; void onDeleteOp(OperationContext* opCtx, const BSONObj& deletedDocId, const repl::OpTime& opTime, const repl::OpTime& preImageOpTime) override;
下面以onInsertOp為例,看下其實現:
void MigrationChunkClonerSourceLegacy::onInsertOp(OperationContext* opCtx, const BSONObj& insertedDoc, const repl::OpTime& opTime) { dassert(opCtx->lockState()->isCollectionLockedForMode(_args.getNss(), MODE_IX)); BSONElement idElement = insertedDoc["_id"]; // 檢查該記錄是否在當前遷移資料塊的範圍內,如果不在,直接退出方法 if (!isInRange(insertedDoc, _args.getMinKey(), _args.getMaxKey(), _shardKeyPattern)) { return; } if (!_addedOperationToOutstandingOperationTrackRequests()) { return; }
// 將該記錄的_id記錄下面,方便後面拉取變更資料 if (opCtx->getTxnNumber()) { opCtx->recoveryUnit()->registerChange(std::make_unique<LogOpForShardingHandler>( this, idElement.wrap(), 'i', opTime, repl::OpTime())); } else { opCtx->recoveryUnit()->registerChange(std::make_unique<LogOpForShardingHandler>( this, idElement.wrap(), 'i', repl::OpTime(), repl::OpTime())); } }