Elasticsearch深度應用(下)
Query檔案搜尋機制剖析
1. query then fetch(預設搜尋方式)
搜尋步驟如下:
- 傳送查詢到每個shard
- 找到所有匹配的檔案,並使用原生的Term/Document Frequery資訊進行打分
- 對結果構建一個優先佇列
- 返回關於結果的後設資料到請求節點。注意,實際檔案還沒有傳送,只是分數
- 來自所有shard的分數合併起來,並在請求節點上進行排序,檔案被按照查詢要去進行選擇
- 最終,實際檔案從它們各自所在的獨立的shard上檢索出來
- 結果被返回給使用者
優點:返回的資料量是準確的
缺點:效能一般,並且資料排名不準確
2. dfs query then fetch
比前面的方式多了一個DFS步驟。也就是查詢之前,先對所有分片傳送請求,把所有分片中的詞頻和檔案頻率等打分依據全部彙總到一塊,再執行後面的操作。
詳細步驟如下:
- 預查詢每個shard,詢問Term和Document frequency
- 傳送查詢到每個shard
- 找到所有匹配的檔案,並使用全域性的Term/Document Frequency資訊進行打分
- 對結果構建一個優先佇列
- 返回關於結果的後設資料到請求節點。注意,實際檔案還沒有傳送,只是分數。
- 來自所有shard的分數合併起來,並在請求節點進行排序,檔案被按照查詢要求進行選擇
- 最終,實際檔案從它們各自所在的獨立的shard上檢索出來
- 結果被返回給使用者
優點:返回的資料和資料排名都是準確的
缺點:效能較差
檔案增刪改和搜尋的請求過程
增刪改流程
- 使用者端首先會選擇一個節點傳送請求過去,這個節點可能是協調節點
- 協調節點會對document資料進行路由,將請求轉發給對應的node
- 實際上node的primary shard會處理請求,然後將資料同步到對應的含有replica shard的node上
- 協調節點如果發現含有primary shard的節點和含有replica shard的節點的符合要求的數量後,就會將響應結果返回給使用者端
搜尋流程
- 使用者端首先會選擇一個節點傳送請求獲取,這個節點可能是協調節點
- 協調節點將搜尋請求轉發到所有shard對應的primary shard或replica shard都可以
- query phase:每個shard將自己搜尋結果的後設資料發到請求節點(doc id和打分資訊),由請求節點進行資料的合併、排序、分頁等操作,產出最後結果
- fetch phase:請求節點根據doc id去各個節點上拉取實際的document資料,最終返回給使用者端。
排序詳解
說到排序,我們必須要說Doc Values這個東西。那麼Doc Values是什麼呢?又有什麼作用?
我們都知道ES之所以那麼快速,歸功於他的倒排索引的設計,然而他也不是萬能的,倒排索引的檢索效能是非常快的,但是在欄位值排序時卻不是理想的結構。

如上表可以看出,他只有詞對應的doc,但是並不知道每一個doc中的內容,那麼如果想要排序的話每一個doc都去獲取一次檔案內容豈不非常耗時?Doc Values的出現就是解決這個問題。
Doc Values是可以根據doc_values屬性進行設定的,預設為true。當設定為false時,無法基於該欄位排序、聚合、在指令碼中存取欄位值。
Doc Values是轉置倒排索引和正排索引的關係來解決這個問題。倒排索引將詞項對映到包含它們的檔案,Doc Values將檔案對映到它們包含的詞項:

當資料被轉置後,想要收集到每個檔案行,獲取所有的詞項就比較簡單了。所以搜尋使用倒排索引查詢檔案,聚合操作和排序就要使用Doc Values裡面的資料。
深入理解Doc Values
Doc Values是在索引時與倒排索引同時生成。也就是說Doc Values和倒排索引一樣,基於Segement生成並且是不可變的。同時Doc Values和倒排索引一樣序列化到磁碟,這樣對效能和擴充套件性有很大幫助。
Doc Values通過序列化把資料結構持久化到磁碟,我們可以充分利用作業系統的記憶體,而不是JVM的Heap。當workingset遠小於系統的可用記憶體,系統會自動將Doc Values儲存在記憶體中,使得其讀寫十分高速;不過,當其遠大於可用記憶體時,作業系統會自動把Doc Values寫入磁碟。很顯然,這樣效能會比在記憶體中差很多,但是它的大小就不再侷限於伺服器的記憶體了。如果是使用JVM的Heap來實現是因為容易OutOfMemory導致程式崩潰了。
禁用Doc Values
Doc Values預設對所有欄位啟用,除了analyzed strings。也就是說所有的數位、地理座標、紀錄檔、IP和不分析字元型別都會預設開啟。
analyzed strings暫時不能使用Doc Values,因為分析後會生成大量的Token,這樣非常影響效能。雖然Doc Values非常好用,但是如果你儲存的資料確實不需要這個特性,就不如禁用他,這樣不僅節省磁碟空間,也許會提升索引的速度。
要禁用Doc Values,在mapping設定即可。範例:
PUT my_index
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
Filter過濾機制剖析
- 在倒排索引中查詢搜尋串,獲取docment list
如下面這個例子,需要過濾date為2020-02-02的資料,去倒排索引中查詢,發現2020-02-02對應的document list是doc2、doc3.

- Filter為每個倒排索引中搜尋到的結果,構建一個bitset
如上面的例子,根據document list,構建的bitset是[0,1,1],1代表匹配,0代表不匹配
- 多個過濾條件時,遍歷每個過濾條件對應的bitset,優先從最稀疏的開始搜尋,查詢滿足所有條件的document。
另外多個過濾條件時,先過濾比較稀疏的條件,能先過濾掉儘可能多的資料。
-
caching bitset,跟蹤query,在最近256個query中超過一定次數的過濾條件,快取其bitset。對於小的segment(記錄數小於1000或小於總大小3%),不快取。
-
如果document有新增或修改,那麼cached bitset會被自動更新
-
filter大部分情況下,在query之前執行,先儘量過濾儘可能多的資料
控制搜尋精準度
基於boost的權重控制
考慮如下場景:
我們搜尋貼文,搜尋標題包含java或spark或Hadoop或elasticsearch。但是需要優先輸出包含java的,再輸出spark的的,再輸出Hadoop的,最後輸出elasticsearch。
我們先看如果不考慮優先順序時怎麼搜尋:
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "java"
}
}
},
{
"term": {
"title": {
"value": "elasticsearch"
}
}
},
.....省略
]
}
}
}
搜尋出來的結果跟我們想要的順序不一致,那麼我們下一步加權重。增加boost
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "java",
"boost": 5
}
}
},
{
"term": {
"title": {
"value": "spark",
"boost": 4
}
}
}
]
}
}
}
基於dis_max的策略控制
dix_max想要解決的是:
如果我們想要某一個filed中匹配到儘可能多的關鍵詞的被排在前面,而不是在多個filed中重複出現相同的詞語的排在前面。
舉例說明:
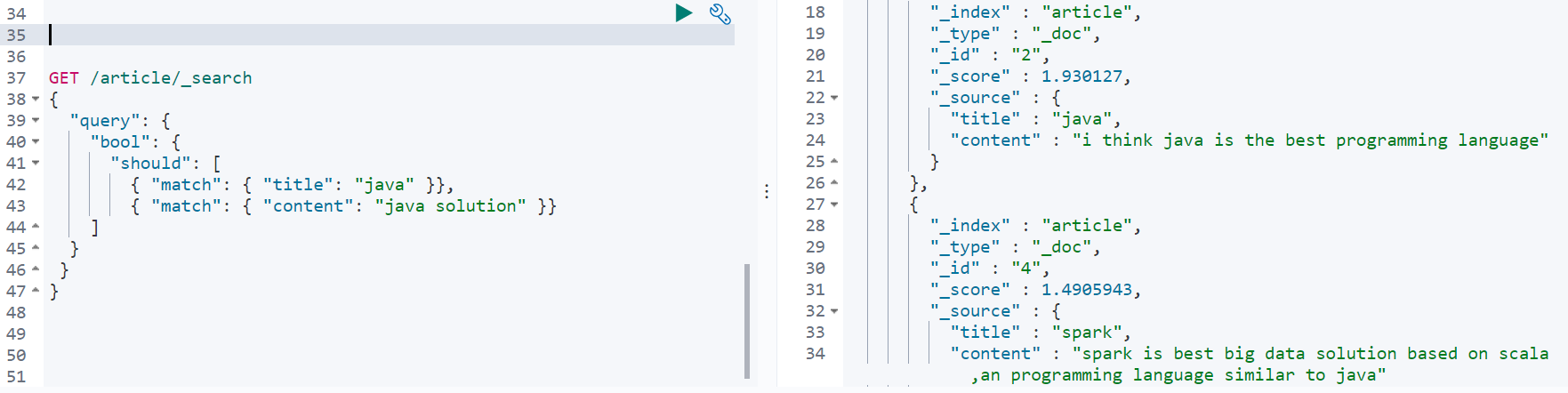
對於一個檔案會將title匹配到的分數和content匹配到的分數相加。所以doc id為2的檔案的分數比doc id為4的大。
dis_max查詢:
GET /article/_search
{
"query": {
"dis_max": {
"queries": [
{"match": {"title": "java"}},
{"match":{"content":"java solution"}}
]
}
}
}
查詢到的結果如下:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.4905943,
"hits" : [
{
"_index" : "article",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.4905943,
"_source" : {
"title" : "spark",
"content" : "spark is best big data solution based on scala,an programming language similar to java"
}
},
{
"_index" : "article",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.2039728,
"_source" : {
"title" : "java",
"content" : "i think java is the best programming language"
}
}
]
}
}
基於function_score自定義相關度分數
在用ES進行搜尋時,搜尋結果預設會以檔案的相關度進行排序,而這個"檔案的相關度",是可以通過function_score自定義的。
function_score提供了幾種型別的得分函數:
- script_score
- weight
- random_score
- field_value_factor
- decay functions:gauss、linear、exp
random_score
隨機打分,也就是每次查詢出來的排序都不一樣。
舉一個例子:
GET /article/_search
{
"query": {
"function_score": {
"query": {"match_all": {}},
"random_score": {}
}
}
}
field_value_factor
該函數可以根據檔案中的欄位來計算分數。
範例:
GET /item/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "price",
"factor": 1.2,
"modifier": "none"
}
}
}
}
| 屬性 | 說明 |
|---|---|
| field | 要從檔案中提取的欄位 |
| factor | 欄位值乘以的值,預設為1 |
| modifier | 應用於欄位值的修復符 |
modifier的取值有如下多種:
| Modifier | 說明 |
|---|---|
| none | 不要對欄位值應用任何乘數 |
| log | 取欄位值的常用對數。因為此函數將返回負值並在0到1之間的值上使用時導致錯誤,所以建議改用log1p |
| log1p | 將欄位值上加1並取對數 |
| log2p | 將欄位值上加2並取對數 |
| ln | 取欄位值的自然對數。因為此函數將返回負值並在0到1之間的值上使用時引起錯誤,所以建議改用 ln1p |
| ln1p | 將1加到欄位值上並取自然對數 |
| ln2p | 將2加到欄位值上並取自然對數 |
| square | 對欄位值求平方 |
| sqrt | 取欄位值的平方根 |
| reciprocal | 交換欄位值,與1 / x相同,其中x是欄位的值 |
field_value_score函數產生的分數必須為非負數,否則將引發錯誤。如果在0到1之間的值上使用log和ln修飾符將產生負值。請確保使用範圍過濾器限制該欄位的值以避免這種情況,或者使用log1p和ln1p
分頁效能問題
在ES中我們一般採用的分頁方式是from+size的形式,當資料量比較大時,Es會對分頁作出限制,因為此時效能消耗很大。
舉個例子:一個索引分10個shards,然後一個搜尋請求,from=990,size=10。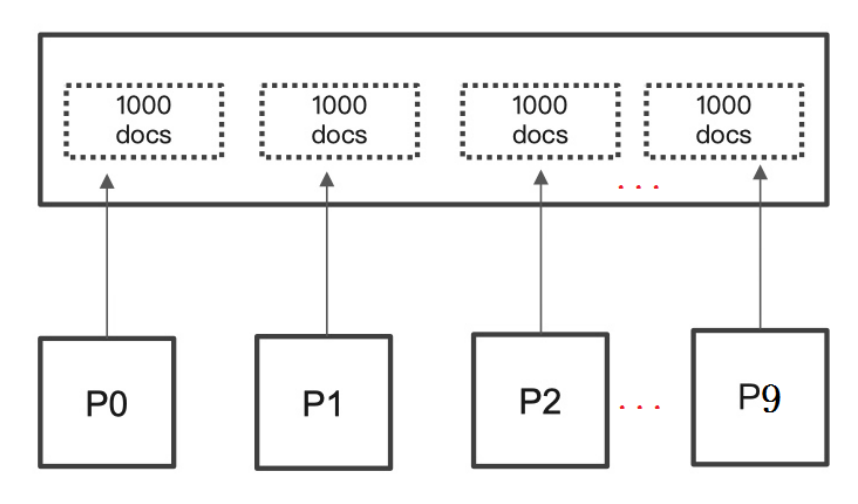
此時es會從每個shards上去查詢1000條資料,儘管每條資料只有_doc_id和_score,但是經不住它量大啊。如果from是10000呢?就更加耗費資源了。
解決方案
1. 利用scroll遍歷
scroll分為初始化和遍歷兩步。
步驟1:
POST /item/_search?scroll=1m&size=2
{
"query": { "match_all": {}}
}
步驟2:
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "步驟1中查詢出的值"
}
2. search after方式
在ES 5.x後提供的一種,根據上一頁的最後一條資料來確定下一頁的位置的方式。如果分頁請求的過程中,有資料的增刪改,也會實時的反映到遊標上。這種方式依賴上一頁的資料,所以不能跳頁。
步驟1:
GET /item/_search
{
"query": {
"match_all": {}
},
"size": 2
,"sort": [
{
"_id": {
"order": "desc"
}
}
]
}
查詢結果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "item",
"_type" : "_doc",
"_id" : "uL6choEB9TD2fYkcrziw",
"_score" : null,
"_source" : {
"title" : "小米8手機",
"images" : "http://image.lagou.com/12479122.jpg",
"price" : 2688,
"createTime" : "2022-02-02 12:02:02"
},
"sort" : [
"uL6choEB9TD2fYkcrziw"
]
},
{
"_index" : "item",
"_type" : "_doc",
"_id" : "tr6YgYEB9TD2fYkcFzjY",
"_score" : null,
"_source" : {
"title" : "小米手機",
"images" : "http://image.lagou.com/12479122.jpg",
"price" : 2688,
"createTime" : "2022-02-01 12:02:02"
},
"sort" : [
"tr6YgYEB9TD2fYkcFzjY"
]
}
]
}
}
步驟2:
GET /item/_search
{
"query": {
"match_all": {}
},
"size": 2,
"search_after":["tr6YgYEB9TD2fYkcFzjY"]
,"sort": [
{
"_id": {
"order": "desc"
}
}
]
}
總結對比:
| 分頁方式 | 效能 | 優點 | 缺點 | 場景 |
|---|---|---|---|---|
| from + size | 低 | 靈活性好,實現簡單 | 深度分頁問題 | 資料量比較小,能容忍深度分頁問題 |
| scroll | 中 | 解決了深度分頁問題 | 無法反映資料的實時性(快照版本)維護成本高,需要維護一個scroll_id | 海量資料的匯出需要查詢海量結果集的資料 |
| search_after | 高 | 效能最好 | 不存在深度分頁問題能夠反映資料的實時變更實現連續分頁的實現會比較複雜,因為每一次查詢都需要上次查詢的結果 | 海量資料的分頁 |