關於cpu體系架構的一些有趣的故事分享
從排查一次匪夷所思的coredump,引出各種體系架構的差異。
本文中的所有內容來自學習DCC888的學習筆記或者自己理解的整理,如需轉載請註明出處。周榮華@燧原科技
1 背景
從全世界有記載的第一臺計算機Z1 (computer) - Wikipedia在1936年發明,到1946年馮諾依曼體系架構的清晰提出,計算機體系架構的演進雖然沒有什麼革命性的變化,但各種體系架構的微調還是很明顯的。
發展到現在雖然存在X86/ARM/MIPS/ALPHA/PPC/RISC-V等多種門派,但實際的設計思想上,主要有兩種,一種是基於X86的系統架構,另外一種就是其他系統架構。
為什麼這麼分?
因為X86的很多特性,基本上只有X86有,而其他體系架構基本上都是共用的另外一種。
例如CISC和RISC,位元組對齊,變長指令和固定長度指令,指令定址模式,等等。
現在用的各種體系架構,只有x86是複雜指令集,變長,記憶體存取可以不是位元組對齊的(當然,對齊之後效能更好),沒有固定的載入和儲存指令,而是採用很多計算指令直接存取記憶體。
相對於x86,其他體系架構,包括ARM/MIPS/ALPHA/PPC/RISC-V,都是精簡指令集,指令長度也是固定的,記憶體存取必須對齊,否則coredump,記憶體的存取只能通過有限的幾個載入和儲存指令進行,其他計算指令僅限於在暫存器上操作。
2 體系架構
計算機的體系架構,英文稱為Computer architecture - Wikipedia,涉及的工作主要分三部分:
指令集、微架構和系統設計。
其中指令集相當於使用者介面,是軟體和硬體的介面。
微架構是指令集的具體實現。
系統設計主要是支撐微架構的記憶體、匯流排、功耗等設計。
下面的問題單就X86來闡述。
32位元的處理器太古老,我們單說64位元之後的故事。
x86-64 - Wikipedia講述了x86-64的體系架構的微架構演進過程:
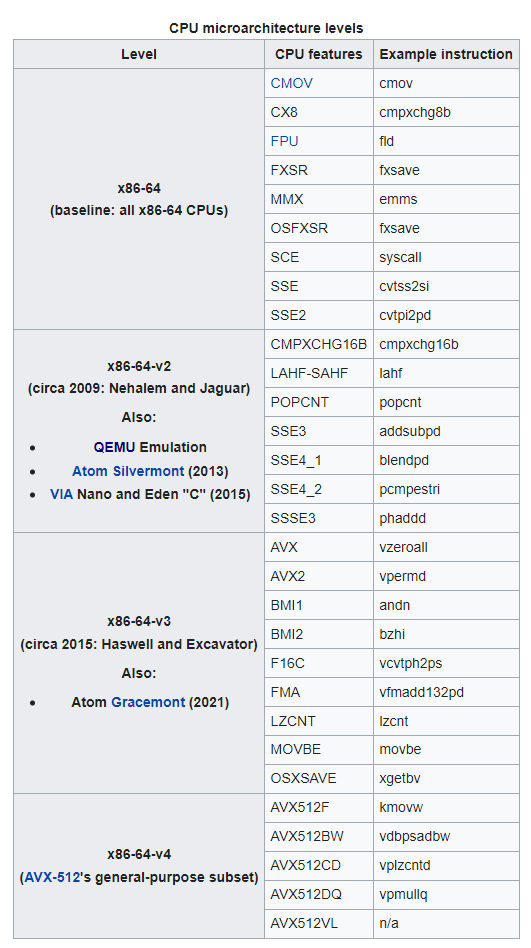
最早出來的是x86-64,相當於64位元x86的基線版本,基本上所有64位元x86處理器都支援,包括常見的MMX、SSE、FPU,都不是問題。基於這個基線版本往上發展出了v2/v3和v4版本。
現在虛擬機器器(QEMU)基本上支援到v2就終結了,所以後面v3/v4變成了少數使用者的選擇。隨著這些微架構的演進,不僅指令集,暫存器也會有較大變化。那怎麼保證編譯出來的程式在各種x86的硬體上都能正常執行是個大問題。解決這個問題的主角就是編譯器。
考慮到泛化和效能的不同要求,即使在同樣的體系架構下,也可以指定具體的硬體版本,這就是gcc/clang等編譯器的arch引數的由來。
x86 Options (Using the GNU Compiler Collection (GCC))中提到的arch的取值從各種具體的處理器型號,到泛化的v2/v3/v4,都是為了方便程式設計師可以儘可能保證相容性的前提下,也能提升效能。
如果不考慮泛化,使用者還可以簡單用一個-march-native在x86平臺上實現基於當前硬體的極致優化。
3 問題
這裡碰到的一個問題就是極致優化帶來的相容性問題。
某伺服器上編譯出來的版本,在部分x86的機器上能正常執行,但部分x86機器上不能正常執行。通過gdb斷點排查,報非法指令,而且程式碼段指向vxorps這條指令,後面緊跟著的3個暫存器非常扎眼zmm。
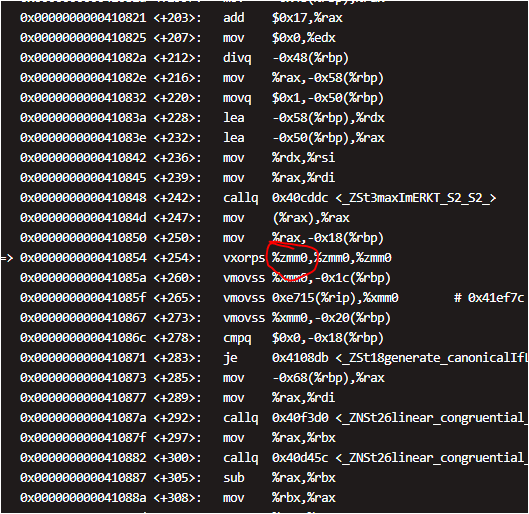
zmm暫存器是v4版本引入的功能。
能執行含zmm暫存器指令的cpu是「Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz」,網上查了一下,是intel 2017年的產品。
到目前位置,MMX指令使用的暫存器經過了三代演進,xmm/ymm/zmm:
xmm0 ~ xmm15, are 128 bits, almost every modern machine has it, they are released in 1999.
ymm0 ~ ymm15, are 256 bits, new machine usually have it, they are released in 2011.
zmm0 ~ zmm31, are 512 bits, normal pc probably don't have it (as the year 2016),
由於後一代的暫存器長度是上一代的兩倍,決定了前一代處理器是無法使用後一代處理器的暫存器的,相反,本地如果是更高一級的暫存器,可以執行低階的暫存器相關指令。
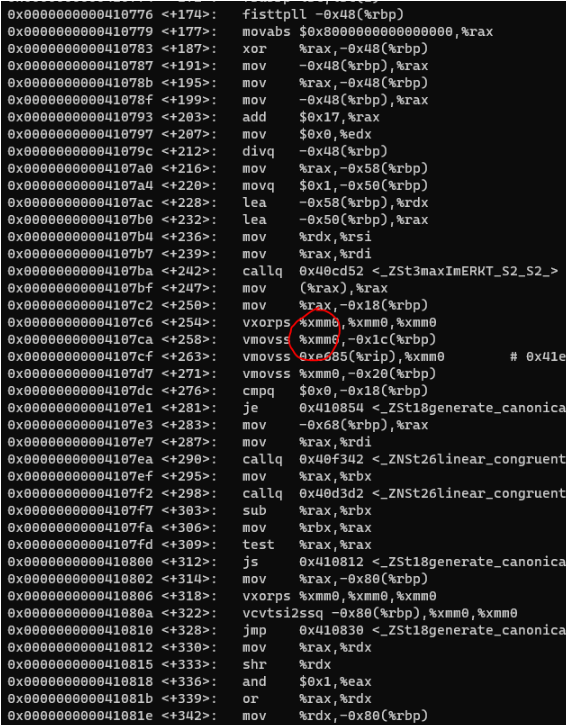
同樣的程式碼,都指定-march=native的情況下,在「AMD Ryzen Threadripper 3960X 24-Core Processor」上編譯的結果是這樣的,指令本身沒有變,暫存器從zmm變成了xmm。
4 問題的解決
既然知道是gcc的arch指定有問題導致的,就要從修改arch入手。
做了一些實驗,例如下面左邊是-march=native編譯,右邊是-march=x86-64的結果。可以看出native編譯出來使用incl,相對於addl,使指令更短,效能更好。

最終各種實驗對比結果看結論如下:
-m64 -march=x86-64 -mtune=generic 編譯出來的結果使用xmm暫存器
-march=native 編譯出來的結果,在amd伺服器上是xmm暫存器,在intel伺服器上是zmm暫存器
為了保證相容性,先統一用-m64 -march=x86-64 -mtune=generic 進行編譯。
5 怎麼做的更好
由於大多數編譯器還不支援-march=x86-64-v2等直接選擇x86-64具體版本的選項,有一種折中方案是native-avx512的做法,一般引數是這樣的:
add_compile_options (-march=native)
add_compile_options (-mno-avx512f)
這樣寫的意思是其他方面可以儘量用本地能支援的最新的,但不要使用avx512f的功能,約等於x86-64-v3這個arch引數的功能。