(資料科學學習手札140)詳解geopandas中基於pyogrio的向量讀寫引擎
本文範例程式碼已上傳至我的
Github倉庫https://github.com/CNFeffery/DataScienceStudyNotes
1 簡介
大家好我是費老師,前不久我在一篇文章中給大家分享過geopandas在其0.11版本中為我們帶來的一些重要新特性,其中提到過新的向量讀寫後端,使得我們在read_file()以及to_file()中新增引數engine='pyogrio'即可獲得500%的效能提升。
而新引擎帶來的不僅是效能上的大幅提升,還帶來了諸多實用功能以方便我們讀寫常見向量檔案,今天我就來給大家詳細介紹這些新功能。

2 詳解geopandas中的pyogrio讀寫引擎
geopandas0.11版本之後新增的pyogrio引擎,基於geopandas團隊開發的同名Python庫,其基於OGR,而OGR則是著名的開源柵格空間資料轉換框架GDAL的重要分支庫,專注於向量資料的高效能轉換。

2.1 基於pyogrio的向量檔案讀取
對於0.11及以後版本的geopandas,向read_file()中傳入engine='pyogrio'後,即可切換至底層基於pyogrio.read_dataframe()的讀取引擎,獲取大幅度效能提升的同時也擁有了眾多的新功能引數,其中比較實用的有:
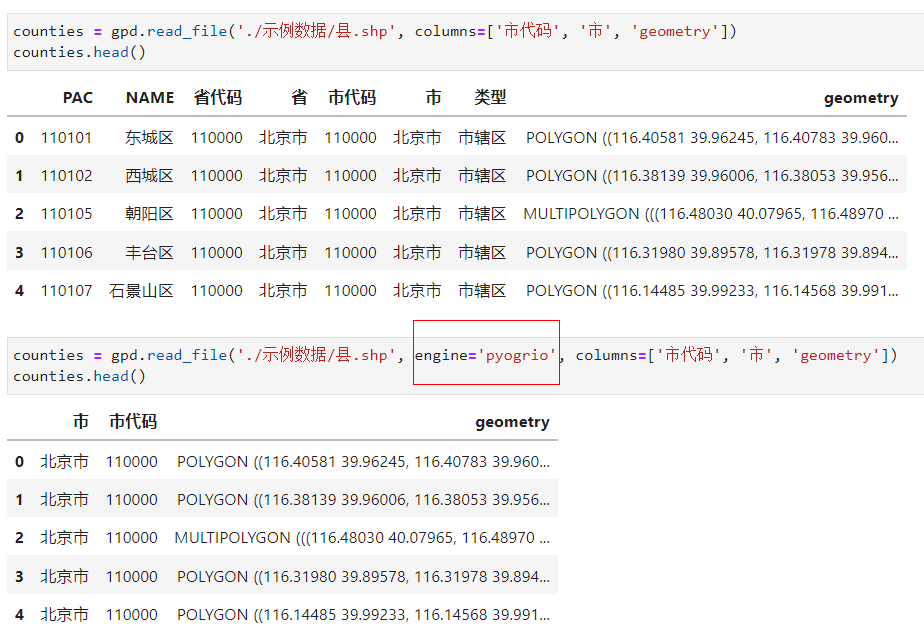
2.1.1 利用columns引數指定需要讀入的欄位
開啟pyogrio引擎後,我們可以通過設定引數columns來讀入指定的若干欄位,當你的向量檔案有很多無關緊要的欄位時,可以利用此特性來整潔資料以及減少讀入資料的記憶體消耗:
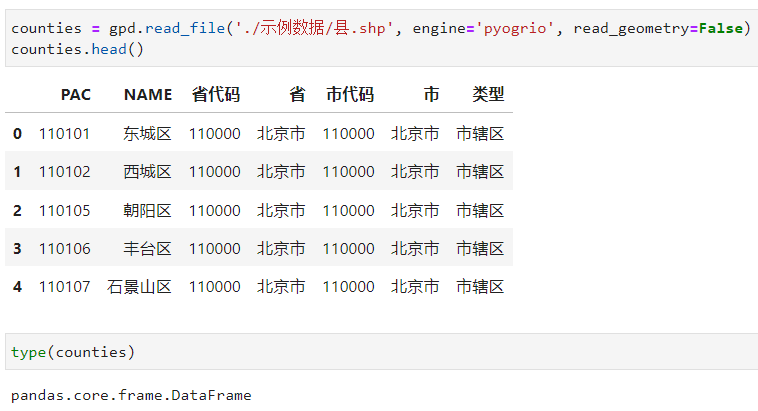
2.1.2 利用read_geometry引數設定是否忽略向量列
如果你不需要向量檔案中的向量資訊,只需要將其當作普通表格資料進行讀入,開啟pyogrio引擎後,設定read_geometry=False即可,所形成物件的型別也會變為普通的DataFrame:
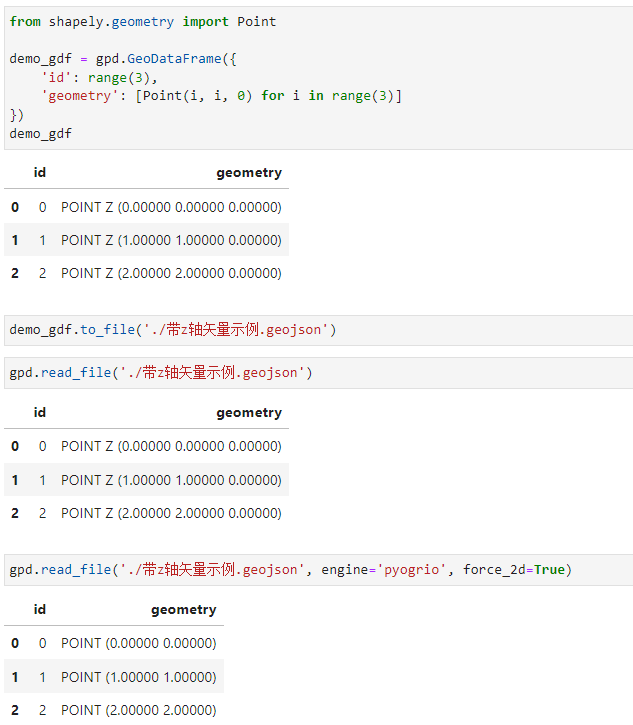
2.1.3 利用force_2d引數強制忽略z軸資訊
有些情況下,向量資料中的座標資訊帶有z軸高度資訊,如果分析過程中用不上該維度資訊,可以在開啟pyogrio引擎後設定force_2d=True強制轉換為2D向量,非常方便:
2.1.4 利用skip_features與max_features引數控制讀入資料規模
在開啟pyogrio引擎後,通過設定引數skip_features可以控制從資料第0行開始需要跳過的要素記錄數量:
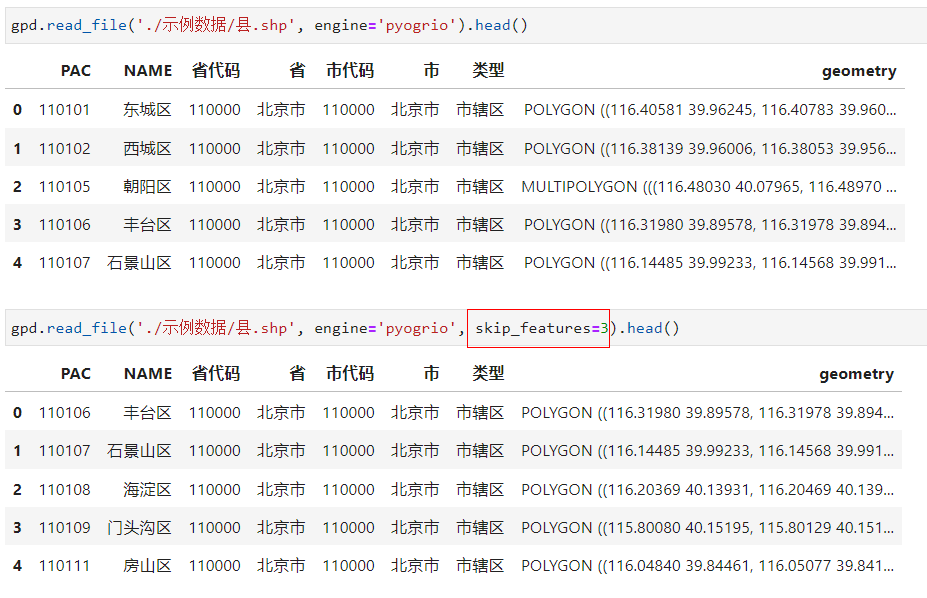
而通過設定引數max_features則可以控制最多讀取多少行要素記錄,當我們的向量檔案記錄行很多,而我們又只想簡單檢視幾行看看資料長什麼樣時,這個引數就很實用了:

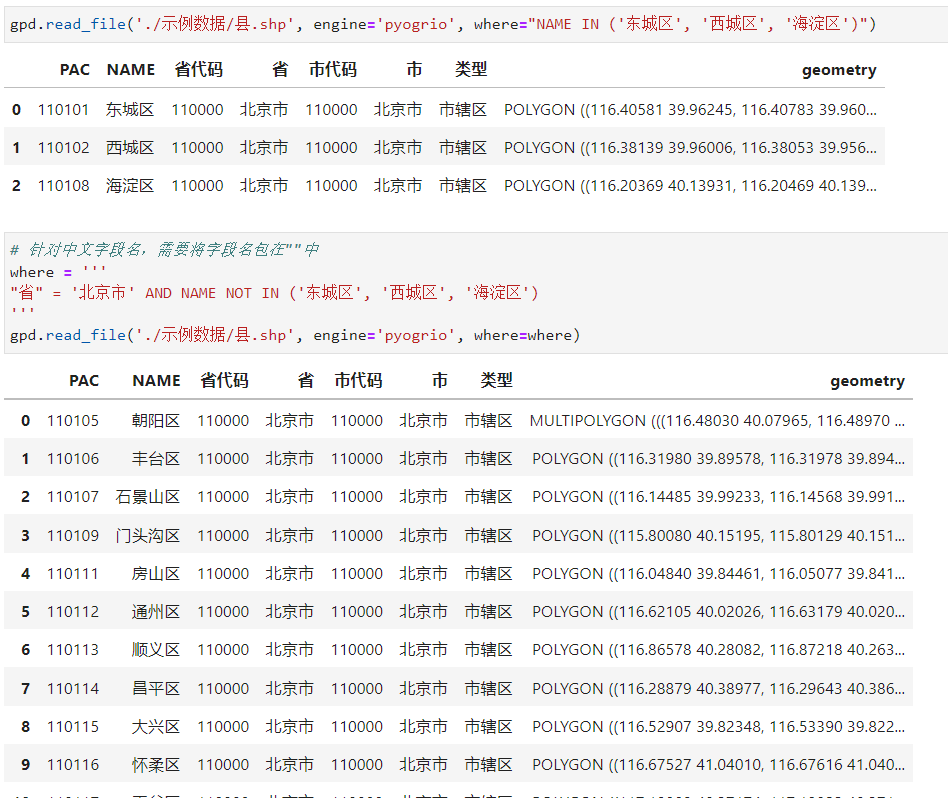
2.1.5 利用引數where對向量檔案進行條件過濾
這個新特性非常實用,我們可以像寫SQL查詢語句那樣傳入我們的過濾條件,從而幫助我們在讀取資料時就實現比較豐富自由的條件過濾效果,值得注意的是,針對中文等由unicode字元構成的欄位名,需要將其包裹在""中進行定義,參考下圖中我的做法:
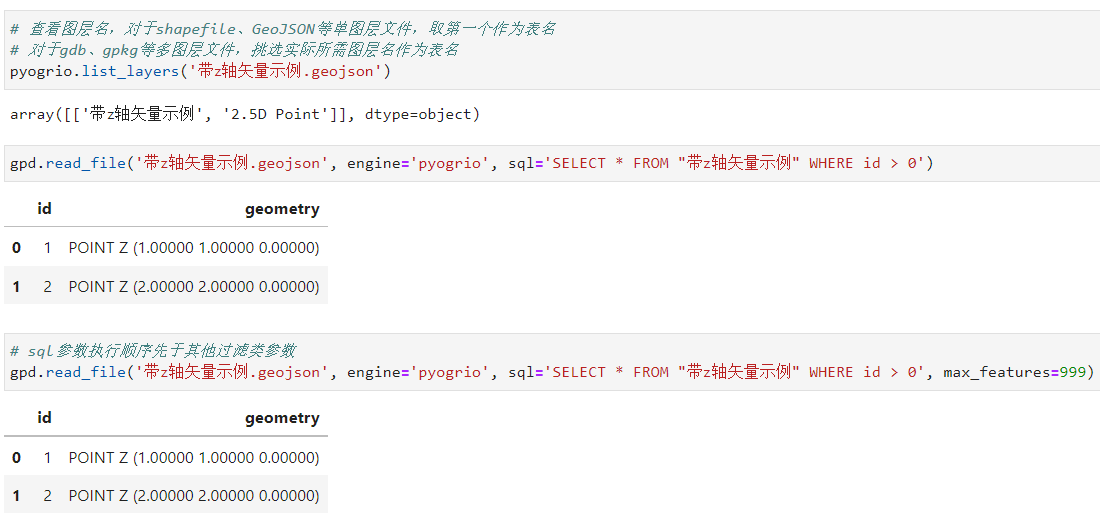
2.1.6 利用sql引數在原資料上直接進行sql查詢
前面我們介紹了多種用於過濾原資料的實用引數,而在在開啟pyogrio引擎後還有個非常實用的引數sql,可以幫助我們直接書寫SQL語句對原資料進行提取(注意,其執行順序先於上述其他過濾類引數):
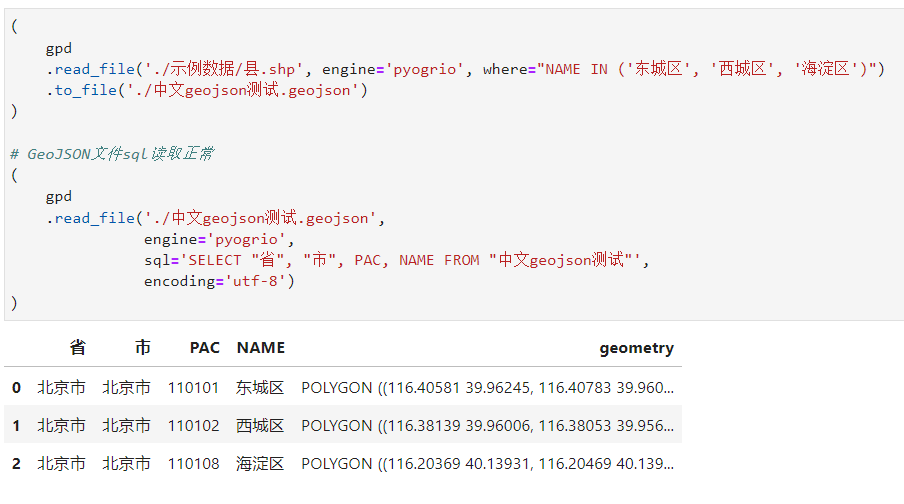
但要注意的是,目前pyogrio引擎的sql引數,在讀取諸如含有中文等unicode字元資訊的shapefile檔案時,不能正常的解析內容,而針對GeoJSON、gpkg等其他格式向量檔案時則一切正常:
GeoJSON檔案正常
gpkg檔案正常

shapefile檔案亂碼,親測即使指定encoding也無效
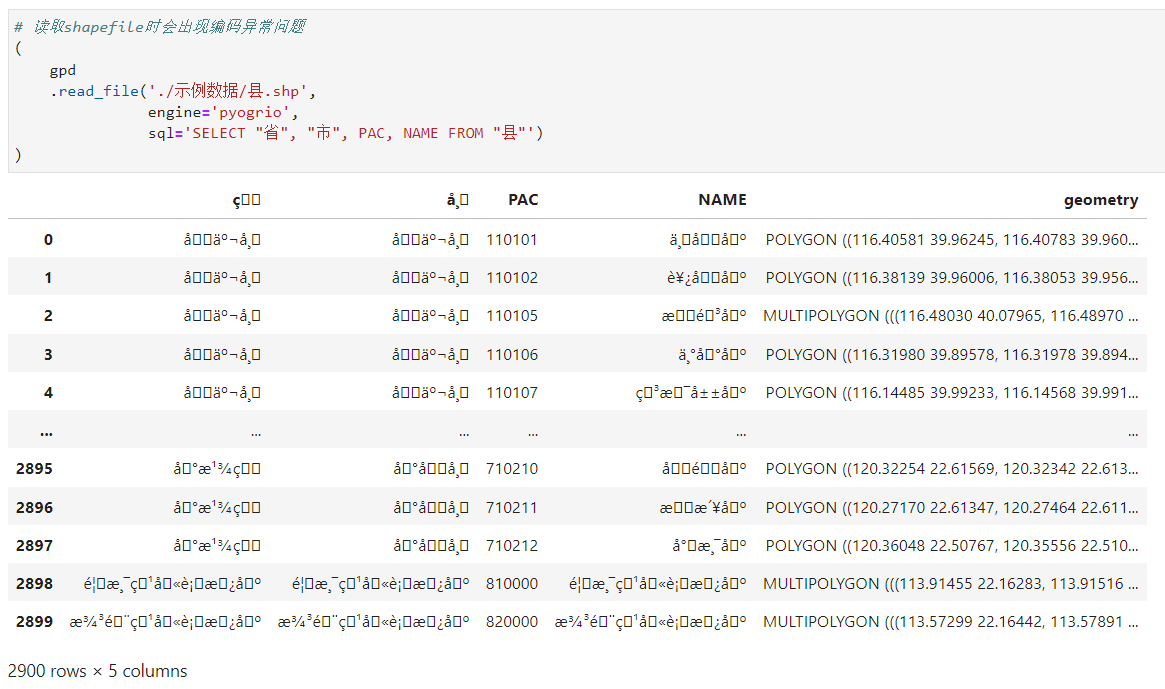
所以現階段建議讀取shapefile檔案時,可以使用columns+where的組合方式代替sql以實現同樣的效果。
2.2 基於pyogrio的向量檔案寫出
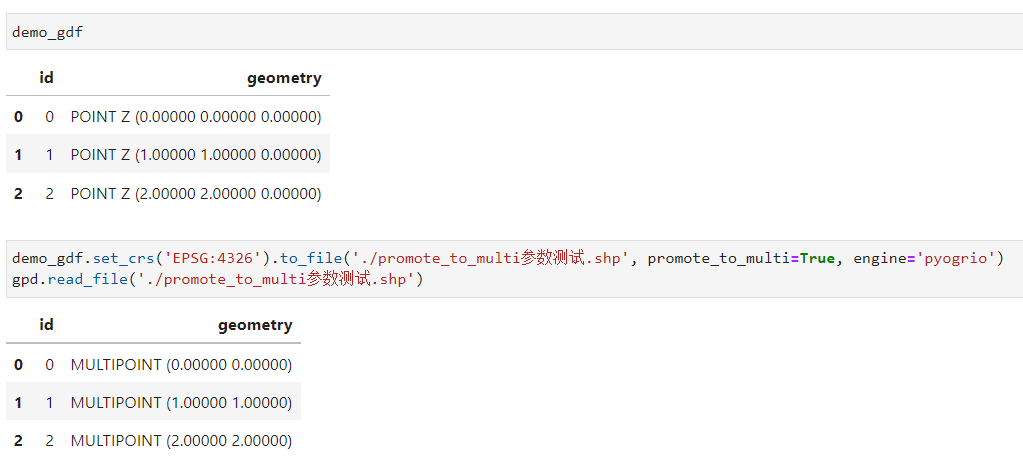
相較於檔案的讀取,新引擎中涉及檔案寫出的功能引數就寡淡很多,只發現一個比較特別的promote_to_multi引數,用於強制將單部件要素轉換為多部件要素:
2.3 pyogrio引擎支援的所有向量檔案型別
你可以通過pyogrio.list_drivers()檢視新引擎所支援的全部向量檔案格式,基本上只有你想不到沒有它覆蓋不到