Elasticsearch深度應用(上)
索引檔案寫入和近實時搜尋原理
基本概念
Segments in Lucene
眾所周知,Elasticsearch儲存的基本單元是shard,ES種一個index可能分為多個shard,事實上每個shard都是一個Lucence的Index,並且每個Lucence Index由多個Segment組成,每個Segment事實上是一些倒排索引的集合,每次建立一個新的Document,都會歸屬一個新的Segment,而不會去修改原來的Segment。且每次的檔案刪除操作,僅僅會標記Segment的一個刪除狀態,而不會真正立馬物理刪除。所以說ES的Index可以理解為一個抽象的概念。如下圖所示:

Commits in Lucene
Commit操作意味著將Segment合併,並寫入磁碟。保證記憶體資料不丟失。但刷盤是很重的IO操作,所以為了效能不會刷盤那麼及時。
Translog
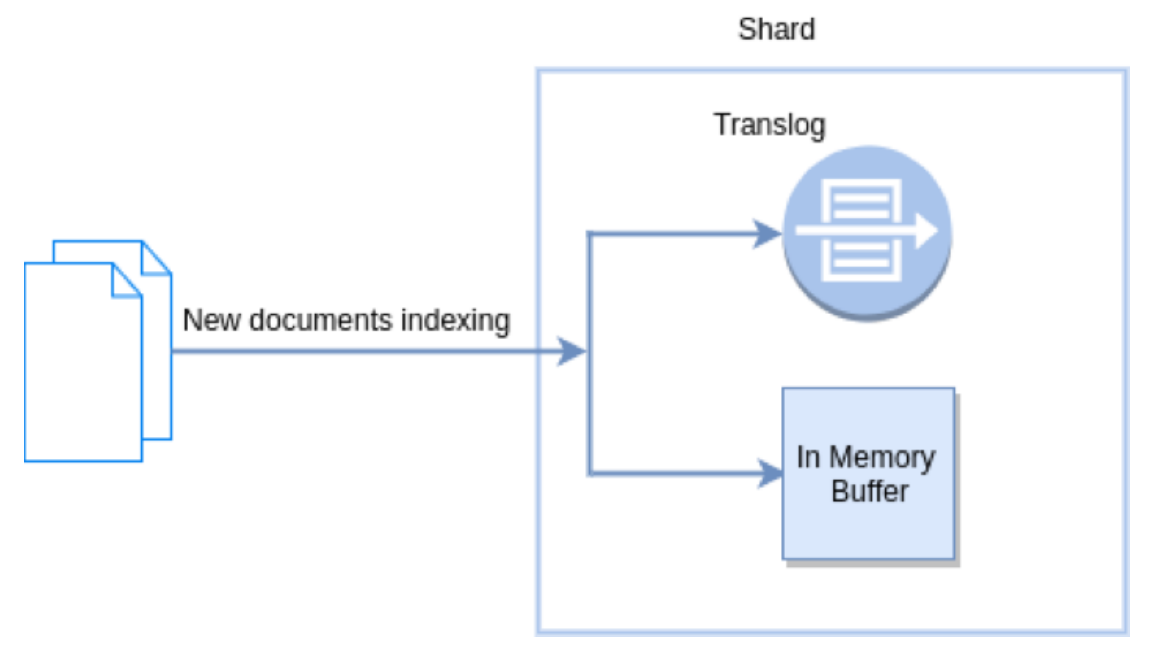
新檔案被索引意味著檔案首先寫入記憶體buffer和translog檔案。每個shard都對應一個translog檔案。
Refresh in Elasticsearch
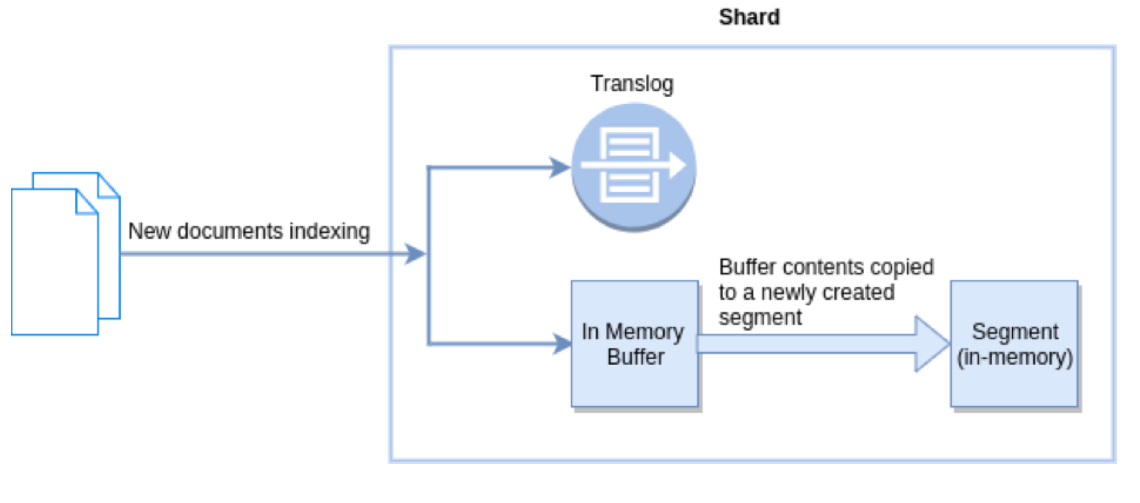
在Elasticsearch種,_refresh操作預設每秒執行一次,意味著將記憶體buffer的資料寫入到一個新的Segment中,這個時候索引變成了可被檢索的。寫入新Segment後會清空記憶體。
Flush in Elasticsearch
Flush操作意味著記憶體buffer的資料全都寫入新的Segment中,並將記憶體中所有的Segments全部刷盤,並且清空translog紀錄檔的過程。
近實時搜尋
提交一個新的段到磁碟需要一個fsync來確保段被物理性的寫入磁碟,這樣在斷電的時候就不會丟資料。但是fsync操作代價很大,如果每次索引一個檔案都去執行一次的話就會造成很大的效能問題。
像之前描述的一樣,在記憶體索引緩衝區中的檔案會被寫入到一個新的段中。但是這裡新段會被先寫入到檔案系統快取--這一步代價會比較低,稍後再被重新整理到磁碟(這一步代價比較高)。不過只要檔案已經在系統快取中,就可以像其它檔案一樣被開啟和讀取了。
原理:
當一個寫請求傳送到es後,es將資料寫入memory buffer中,並新增事務紀錄檔(translog)。如果每次一條資料寫入記憶體後立即寫到硬碟檔案上,由於寫入的資料肯定是離散的,因此寫入硬碟的操作也就是隨機寫入了。硬碟隨機寫入的效率相當低,會嚴重降低es的效能。
因此es在設計時在memory buffer和硬碟間加入了Linux的快取記憶體(Filesy stemcache)來提高es的寫效率。當寫請求傳送到es後,es將資料暫時寫入memory buffer中,此時寫入的資料還不能被查詢到。預設設定下,es每1秒鐘將memory buffer中的資料refresh到Linux的Filesy stemcache,並清空memory buffer,此時寫入的資料就可以被查詢到了。
Refresh API
在Elasticsearch中,寫入和開啟一個新段的輕量的過程叫做refresh。預設情況下每個分片會每秒自動重新整理一次。這就是為什麼我們說Elasticsearch是近實時搜尋:檔案的變化並不是立即對搜尋可見,但會在一秒之內變為可見。
這些行為可能會對新使用者造成困惑:他們索引了一個檔案然後嘗試搜尋它,但卻沒有搜到。這個問題的解決辦法是用refresh API執行一次手動重新整理:
- 重新整理所有索引
POST /_refresh
- 只重新整理某一個索引
POST /索引名/_refresh
- 只重新整理某一個檔案
PUT /索引名/_doc/{id}?refresh
{"test":"test"}
並不是所有的情況都需要每秒重新整理。可能你正在使用Elasticsearch索引大量的紀錄檔檔案,你可能想優化索引速度而不是近實時搜尋,可以通過設定refresh_interval,降低每個索引的重新整理頻率。
PUT /my_logs
{
"settings": { "refresh_interval": "30s" }
}
refresh_interval可以在既存索引上進行動態更新。在生產環境中,當你正在建立一個大的新索引時,可以先關閉自動重新整理,待開始使用該索引時,再把它們調回來。
PUT /my_logs/_settings
{ "refresh_interval": -1 }
持久化變更
如果沒有用fsync把資料從檔案系統快取刷(flush)到硬碟,我們不能保證資料在斷電甚至是程式正常退出之後依然存在。為了保證Elasticsearch的可靠性,需要確保資料變化被持久化到磁碟。
在動態更新索引時,我們說一次完整的提交會將段刷到磁碟,並寫入一個包含所有段列表的提交點。Elasticsearch在啟動或重新開啟一個索引的過程中使用這個提交點來判斷哪些段隸屬於當前分片。
即使通過每秒重新整理(refresh)實現了近實時搜尋,我們仍然需要經常進行完整提交來確保能從失敗中恢復。但在兩次提交之間發生變化的檔案怎麼辦?我們也不希望丟失掉這些資料。Elasticsearch增加了一個translog,或者叫事務紀錄檔,在每一次對Elasticsearch進行操作時均進行了紀錄檔記錄。
整個流程如下:
- 一個檔案被索引之後,就會被新增到記憶體緩衝區,並且追加到了translog。如下圖:
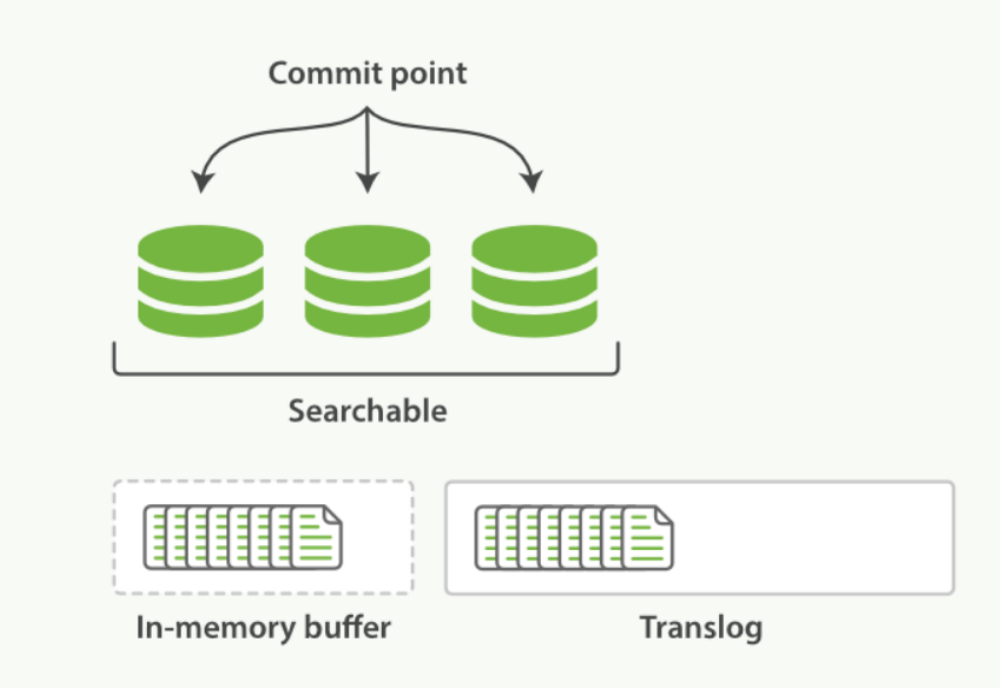
-
分片每秒refres一次,refresh完成後,快取被清空
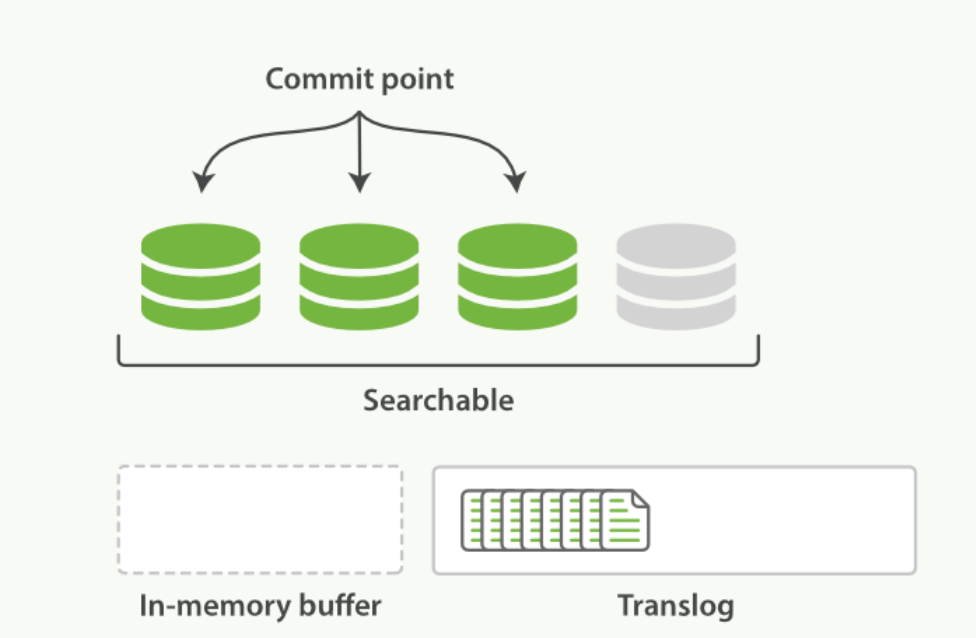
-
這個程序繼續工作,更多的檔案被新增到記憶體緩衝區和追加到事務紀錄檔
-
每隔一段時間--例如translog變得越來越大--索引被重新整理(flush);一個新的translog被建立,並且一個全量提交被執行。
- 所有在記憶體緩衝區的檔案被寫入一個新的段
- 緩衝區被清空
- 一個提交點被寫入磁碟
- 檔案系統快取通過fsync被重新整理(flush)
- 老的translog被刪除
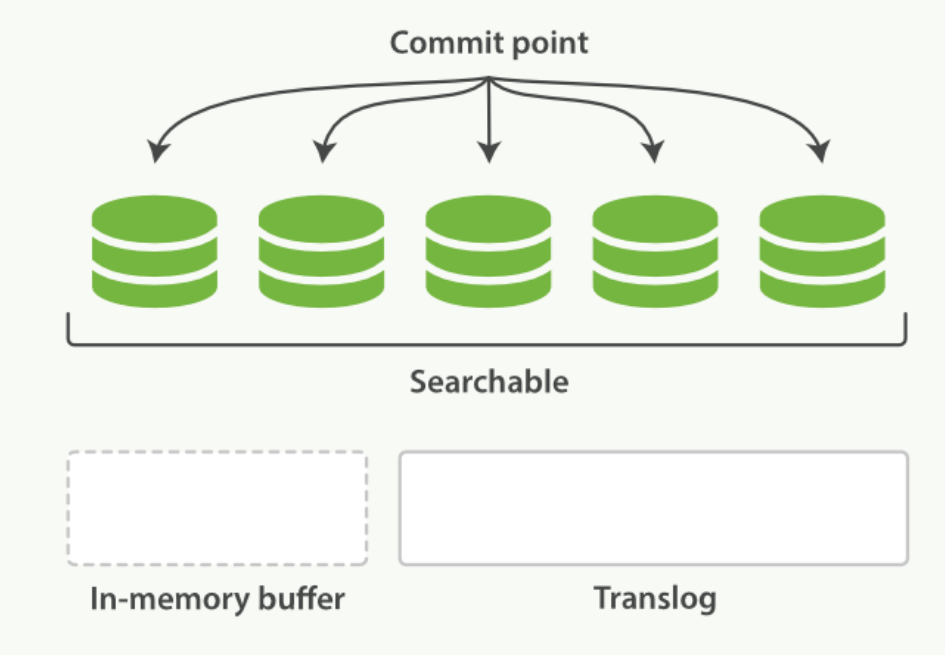
translog提供所有還沒有被刷到磁碟的操作的一個持久化紀錄。當Elasticsearch啟動的時候,它會從磁碟中使用最後一個提交點去恢復已知的段,並且會重放translog中所有在最後一次提交後發生的變更操作。
Flush API
這個執行一個提交併且截斷translog的行為在Es中被稱為一次flush。分片每30分鐘被自動重新整理(flush),或者在translog太大的時候也會重新整理。
flush API 可以被用來執行手工的重新整理
POST /索引名稱/_flush
#重新整理(flush)所有的索引並且等待所有重新整理在返回前完成
POST /_flush?wait_for_ongoin
我們知道用fsync把資料從檔案系統快取flush到硬碟是安全的,那麼如果我們覺得偶爾丟失幾秒資料也沒關係,可以啟用async。
PUT /索引名/_settings {
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
索引檔案儲存段合併機制
由於自動重新整理流程每秒會建立一個新的段,這樣會導致短時間內的段數量暴增。而段數目太多會帶來較大的麻煩。每一個段都會消耗檔案控制程式碼、記憶體和CPU執行週期。更重要的是,每個搜尋請求都必須輪流檢查每個段;所以段越多,搜尋也就越慢。
Elasticsearch通過在後臺進行段合併來解決這個問題。小的段被合併到大的段,然後這些大的段再被合併到更大的段。段合併的時候會將那些舊的已刪除檔案從檔案系統中清除。被刪除的檔案(或被更新檔案的舊版本)不會被拷貝到新的大段中。
合併大的段需要消耗大量的I/O和CPU資源,如果任其發展會影響搜尋效能。Elasticsearch在預設情況下會對合並流程進行資源限制,所以搜尋仍然有足夠的資源很好地執行。預設情況下,歸併執行緒的限速設定indices.store.throttle.max_bytes_per_sec是20MB。對於寫入量較大,磁碟轉速較高,甚至使用SSD槽的伺服器來說,這個限速是明顯過低的。對於ELKStack應用,建議可以適當調大到100MB或者更高。
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}
歸併策略
歸併執行緒是按照一定的執行策略來挑選 segment 進行歸併的。主要有以下幾條:
index.merge.policy.floor_segment預設2MB,小於這個大小的segment,優先被歸併。
index.merge.policy.max_merge_at_once預設一次最多歸併10個segment
index.merge.policy.max_merge_at_once_explicit預設optimize時一次最多歸併30個segment。
index.merge.policy.max_merged_segment預設5GB,大於這個大小的segment,不用參與歸併。optimize除外
optimize API
optimizeAPI大可看做是強制合併API。它會將一個分片強制合併到max_num_segments引數指定大小的段數目。這樣做的意圖是減少段的數量(通常減少到一個),來提升搜尋效能。
在特定情況下,使用optimizeAPI頗有益處。例如在紀錄檔這種用例下,每天、每週、每月的紀錄檔被儲存在一個索引中。老的索引實質上是唯讀的;它們也並不太可能會發生變化。在這種情況下,使用optimize優化老的索引,將每一個分片合併為一個單獨的段就很有用了;這樣既可以節省資源,也可以使搜尋更加快速。
api:
POST /logstash-2014-10/_optimize?max_num_segments=1
java api:
forceMergeRequest.maxNumSegments(1)
Es樂觀鎖
Es的後臺是多執行緒非同步的,多個請求之間沒有順序,可能後發起修改請求的先被執行。Es的並行是基於自己的_version版本號進行並行控制的。
1. 基於seq_no
樂觀鎖範例:
先新增一條資料
PUT /item/_doc/4
{
"date":"2022-07-01 01:00:00",
"images":"aaa",
"price":22,
"title":"先"
}
查詢:
GET /item/_doc/4
可以查出我們的seq_no和primary_term
{
"_index" : "item",
"_type" : "_doc",
"_id" : "4",
"_version" : 5,
"_seq_no" : 12,
"_primary_term" : 5,
"found" : true,
"_source" : {
"date" : "2022-07-01 01:00:00",
"images" : "aaa",
"price" : 33,
"title" : "先"
}
}
然後兩個使用者端都根據這個seq_no和primary_term去修改資料,會有一個提示異常的。
PUT /item/_doc/4?if_seq_no=12&if_primary_term=5
{
"date":"2022-07-01 01:00:00",
"images":"aaa",
"price":33,
"title":"先"
}
2. 基於external version
es提供了一個功能,不用它內部的_version來進行並行控制,你可以根據你自己維護的版本號進行並行控制。
?version=1&version_type=external
區別在於,version方式,只有當你提供的version與es中的version一模一樣的時候,才可以進行修改,只要不一樣,就報錯。當version_type=external的時候,只有當你提供的version比es中的_version大的時候,才能完成修改
範例:
我先查出目前的version為7
{
"_index" : "item",
"_type" : "_doc",
"_id" : "4",
"_version" : 7,
"_seq_no" : 14,
"_primary_term" : 5,
"found" : true,
"_source" : {
"date" : "2022-07-01 01:00:00",
"images" : "aaa",
"price" : 33,
"title" : "先"
}
}
只有設定為8才能成功修改了
PUT /item/_doc/4?version=8&version_type=external
{
"title":"先"
}
分散式資料一致性如何保證
es5.0版本後
PUT /test_index/_doc/1?wait_for_active_shards=2&timeout=10s
{
"name":"xiao mi"
}
這代表著所有的shard中必須要有2個處於active狀態才能執行成功,否則10s後超時報錯。