Tapdata 的 2.0 版 ,開源的 Live Data Platform 現已釋出
https://www.bilibili.com/video/BV1tT411g7PA/?aid=470724972&cid=766317673&page=1
點選上方連結,一分鐘快速瞭解 Tapdata
6月29日,Tapdata 產品釋出暨開源說明會線上開幕,圍繞「Your Last ETL」這一主題,緊扣「實時資料」這一詞眼,正式官宣自帶 ETL 的實時資料平臺 Tapdata Live Data Platform 上線,以及 Tapdata 核心功能的開源計劃等重磅訊息。
釋出會現場,Tapdata 核心團隊成員與多位資料行業專家、資料生態先行者、開源資料產品代表、企業客戶代表及投資機構代表齊聚,著眼於「流動的」、「新鮮的」資料,結合歷史解決方案與實踐案例,站在生產、消費與資本等不同視角,共同探討實時資料應用場景及技術變遷,深度剖析新一代實時資料平臺的技術架構,深入洞察資料行業的發展現狀與前沿優勢,帶來持續的乾貨內容和密集的精彩觀點分享,高能不斷,下面帶您回顧本次活動亮點。△ 點選觀看完整視訊回放
一、時代為何需要一個全新的實時資料架構?
離線分析場景的資料訴求是已經發生了的過去,而實時業務場景的資料需求是明確的未來。而場景差異已然足夠孕育一個新的技術架構。
不斷增長的資料孤島和歷史方案的侷限性
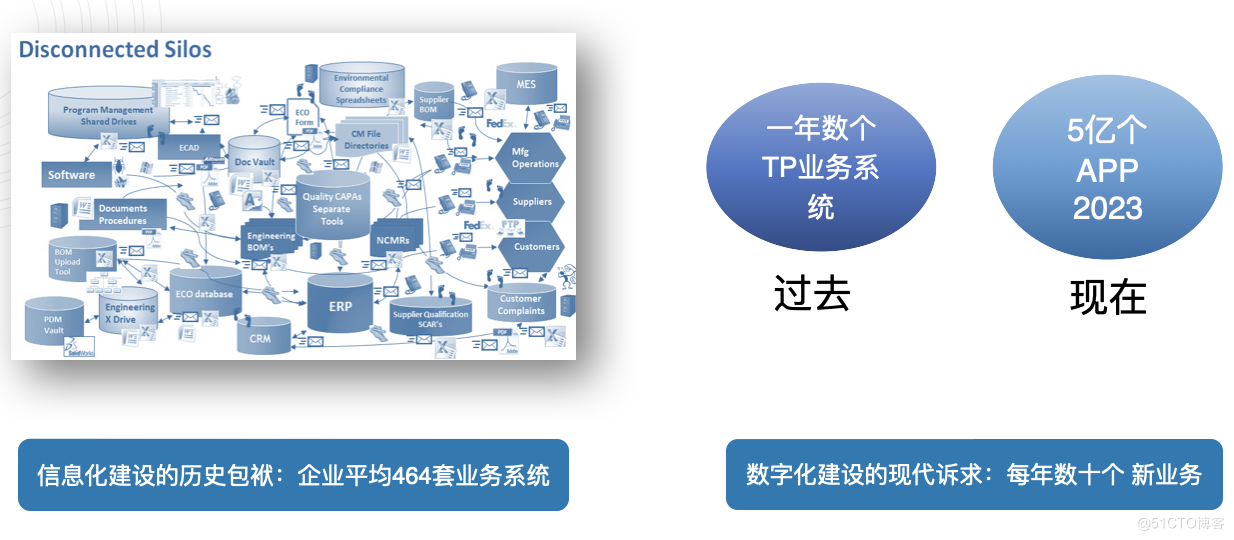
資料孤島的形成背景
在過去數十年間,企業搭建了非常多的業務系統,且數量仍在不斷擴張。而隨著資料架構日益低程式碼化和平臺化,企業又可以以更低的成本建立更多新的業務系統。企業的資料和系統由此也越來越多,這就直接導致資料孤島問題的產生。由於系統間彼此並不連通,取用資料的過程就變得複雜,在真正用上資料之前,還需要做很多「額外」的工作,包括資料的打通、整合、融合等等。
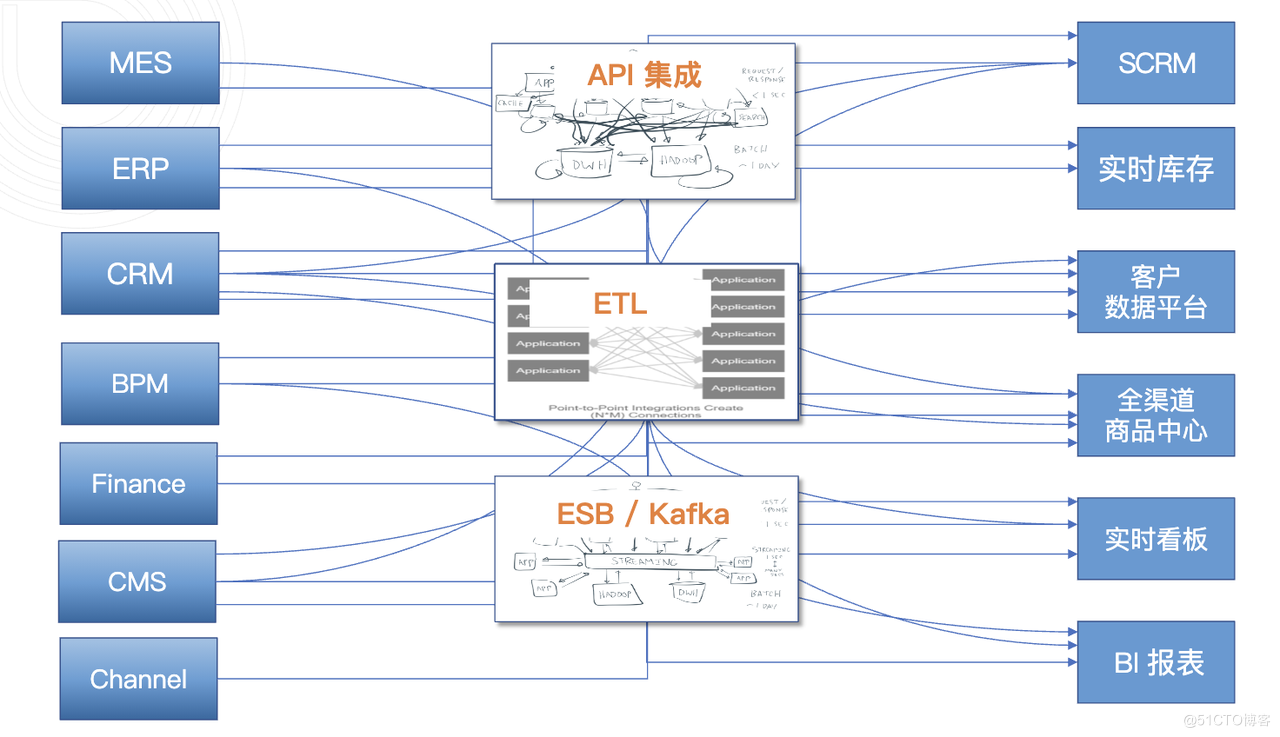
從歷史資訊系統到新的業務系統,企業資料整合的常見模式
企業資料整合的常見模式包括傳統的 API、ETL,早期的 ESB,以及今天的主流 Kafka,在多種既有方案的影響下,企業內部產生了大量各種各樣的資料整合鏈路。這些方案在滿足了一部分技術需求的同時,也不可避免地在資料時代的演進中暴露出侷限性。

歷史資料整合解決方案及其侷限性
其中,API 整合成本相對較低,只要具備一定的程式碼能力,無需第三方工具,即可由研發團隊按照資料共用需求對系統進行 API 封裝,為下游新業務供數。但直接在源庫上構建 API 對效能的影響也比較大,且 API 通常會有 Rate Limit,難以支撐海量資料讀寫。此外,API 基本上只能對單庫釋出資料,難以跨庫操作。
ETL 也是過去很長一段時間裡的主推方案,這種方式的優勢在於,不需要寫太多 Java 程式碼或服務程式碼,而是通過工具或指令碼的方式,來實現資料向下遊系統的抽取複製。ETL 的侷限性主要體現在不易管理上,因為太過簡單且無法複用,導致每個新起業務都需要不少數量的 ETL 鏈路,最終散落在企業各處。
缺乏統一管理的的下場,就是痛苦的義大利麵式結構狀態。面對這一痛點,二十年前就出現了不錯的架構解決方案——用** ESB/MQ** 將資料都推到中央化的企業訊息佇列、服務匯流排上,然後將企業各個需要共用資料的系統,通過 API 和 Service 的方式連線起來,省去了多個系統之間兩兩互動的重複工作,降低了系統之間的對接成本。但整體成本仍較高,所以多用於商業化方案。而且開發複雜、系統耦合較高,效能又較低,很快就退熱成了「明日黃花」,被類似於 Kafka 這樣的分散式開源產品所取代。
大約十年前,Kafka 迅速流行起來,大量企業開始基於 Kafka 實現資料整合。但由於 Kafka 並非為此而生,最初只是一個分散式的紀錄檔儲存,所以其架構設計特性更傾向於高並行、高效能、分散式。相較於資料整合要求的鏈路短、耗時短、延遲短,基於 Kafka 的 ETL 架構因節點較多,反而顯露出長鏈路、資料容易中斷、排查難等特性。如果想要實現,還需要做很多 Java 程式碼開發,使用複雜度很高。
最近十年,各種中央化資料平臺打得火熱,特別是以 Hadoop 為主的巨量資料平臺,以及傳統數倉、新一代數倉等代表,這一類方案的表現是將企業內散落在各個資料孤島的資料集中化到一個平臺裡,從而實現通過中央平臺統一獲取需要的資料。但由於其技術架構多基於 Hadoop,本質上還是一個以離線分析為核心場景的技術棧,多用於對歷史資料進行洞察、分析,資料不夠實時,無法支撐對實時資料要求較高的一些 TP 型業務場景。
在綜合考察了既有諸多解決方案背後的技術架構和侷限性之後,Tapdata 開始思考用一種更好的方式來解決資料孤島問題的可能性——做最後一次 ETL,也是實時的 ETL,通過資料映象實現資料虛擬化,並對映象資料進行中央化儲存,經過一定的加工處理,形成一個可複用的資料 Copy 模型。然後在這個中央化平臺上,以各種服務化方式為下游業務提供最新鮮的需求資料,本質上即 DaaS 概念的實現。基於此,Tapdata 自研了一套完整的產品化方案:Tapdata Live Data Platform。
Tapdata 選擇了完全自研
優秀的開源元件如此多的今天,Tapdata 為什麼不在這些優秀組建的基礎上搭建解決方案,而是設計一套新架構呢?
誠然,沿用開源元件這樣的模式的確可以在一定程度上解決一些問題,但並非最佳選擇。Tapdata 之所以選擇自研一套新的技術架構,除了想要讓產品變得小而輕、更好維護之外,還包含了自身的技術認知和追求。

離線分析場景 vs 實時業務場景
在真實的案例場景中,Tapdata 發現,實時業務場景(OLTP) 對資料的訴求與 傳統的離線分析(OLAP) 具有本質不同。實時業務場景下,資料訴求一般是秒級;資料本身參與核心業務流轉,每一條資料都與真實業務掛鉤,單位價值高,對資料準確性的要求是 100%;業務資料量較之離線分析場景小很多。
如何更好地適應實時業務場景特性,並同時滿足傳統離線分析場景需求?Tapdata 基於 DaaS 架構的Live Data Platform 或將會是當前時代的最優解。Tapdata Live Data Platform 的重點在於 Live,在於資料的流動和鮮活,而這個一體化實時資料服務平臺的技術架構,也是為了契合這個主題而設計的。
二、Tapdata Live Data Platform:首個基於 DaaS 架構的實時資料平臺
事實證明,DaaS 體現了當下一種非常自然且合理的服務化趨勢,即將資料抽象為服務,為下游的所有業務提供極易用的資料能力。Tapdata 的願景就是構建一個以實時資料為 DNA 的 DaaS 平臺,讓使用者無需關注底層技術,只需要關注業務邏輯和資料——像自來水一樣,開啟水龍頭就能使用新鮮資料,就應該這樣簡單!
Tapdata 誕生於一個大家對 DaaS(Data as a Service)有了解但少有觸及其本質的時期。彼時,將 DaaS 作為基礎架構的資料產品可謂少之又少,但 Tapdata 認定了這個方向,並沿著這個方向不斷努力。歷時三年,精心打磨出首個基於 DaaS 架構的實時資料平臺——Live Data Platform(LDP)。
三年鋒芒初顯:從 DaaS 先行者到自帶 ETL 的實時資料平臺
從錨定實時資料賽道邁出 DaaS 第一步開始,歷時三年,Tapdata 目標中的資料服務化產品已初具規模。那麼我們到底可以在哪些場景下用 Tapdata LDP 來完成怎樣的工作?

一圖速覽我們可以用 Tapdata LDP 來做什麼?
場景1:實時資料整合平臺
可將 Tapdata LDP 用作一個實時資料整合平臺(Real Time Data Integration),用以替換升級老一代 ETL 工具,像是 Kettle、OGG、Kafka ETL 等相對複雜的方案,或是 ETL 指令碼等。
場景2:實時資料服務平臺
升級後的實時資料服務平臺(Incremental DaaS),可以用來搭建企業級的資料共用中心,將企業核心資料放到中央化平臺裡,取代 ESB/MQ,在某些場景下還可以替代 Hadoop 巨量資料平臺、數倉等,可以更好地為企業 BI 資料分析等下游業務提供資料服務支撐。
場景3:實時主資料服務
未來,Tapdata 還將推出實時主資料服務(Active Master Data Service),可以升級傳統的以周或月為單位進行主資料更新的解決方案,Tapdata 的目標是通過實時的方式來更新主資料,並且藉助 API 服務直接接入遊業務中,讓下游業務可以直接用上企業核心資料。
Tapdata LDP 是如何工作的?
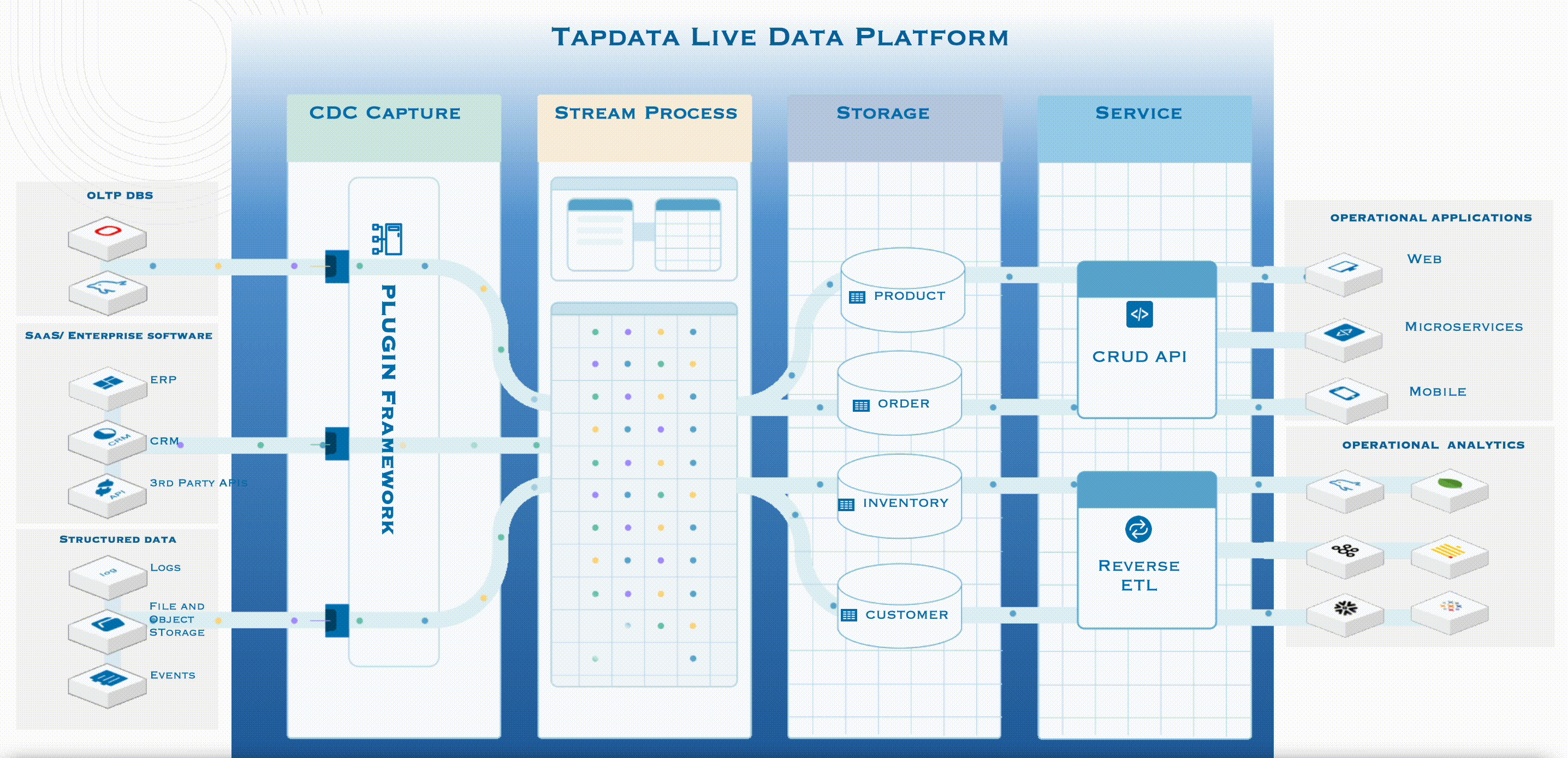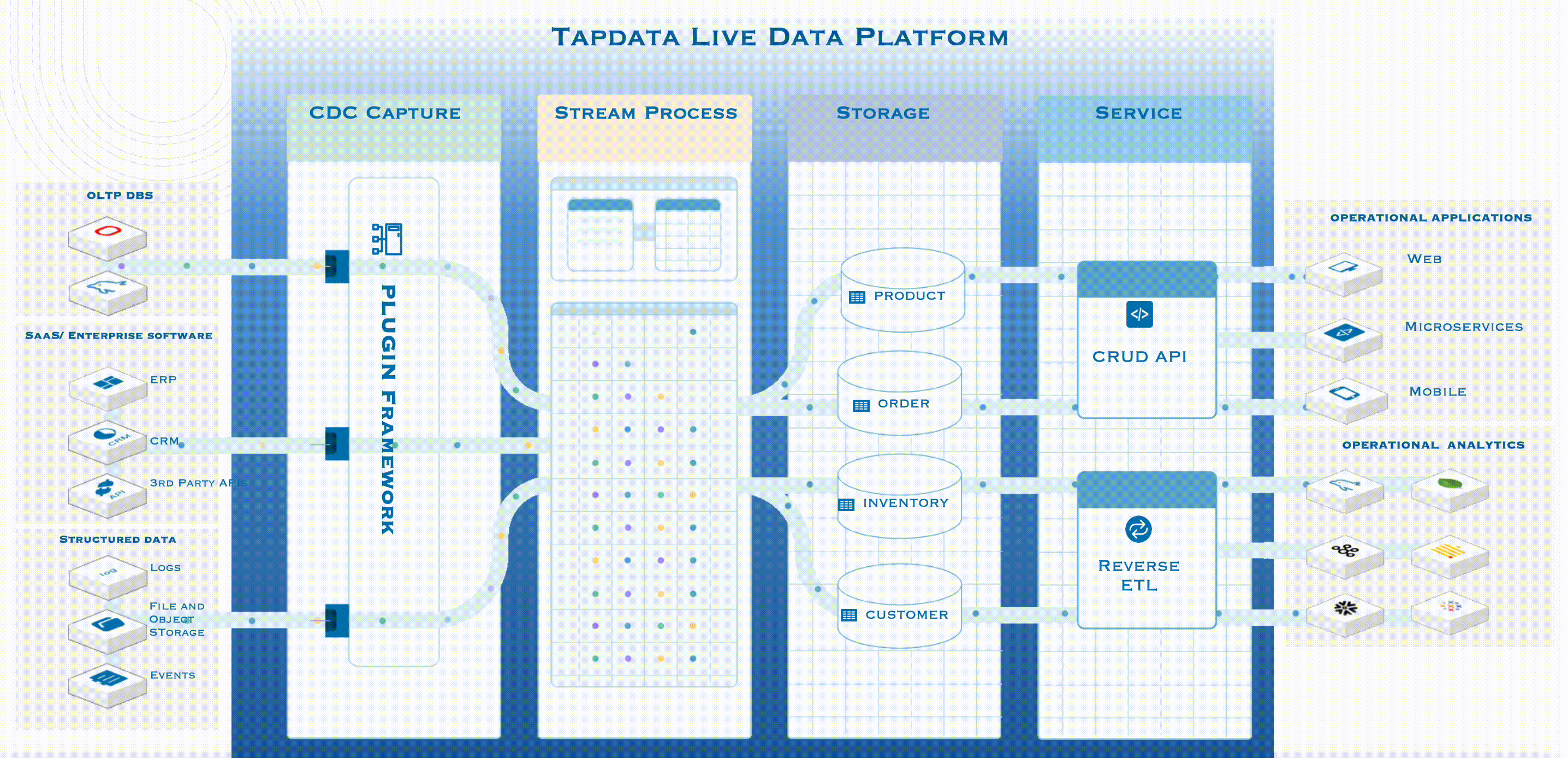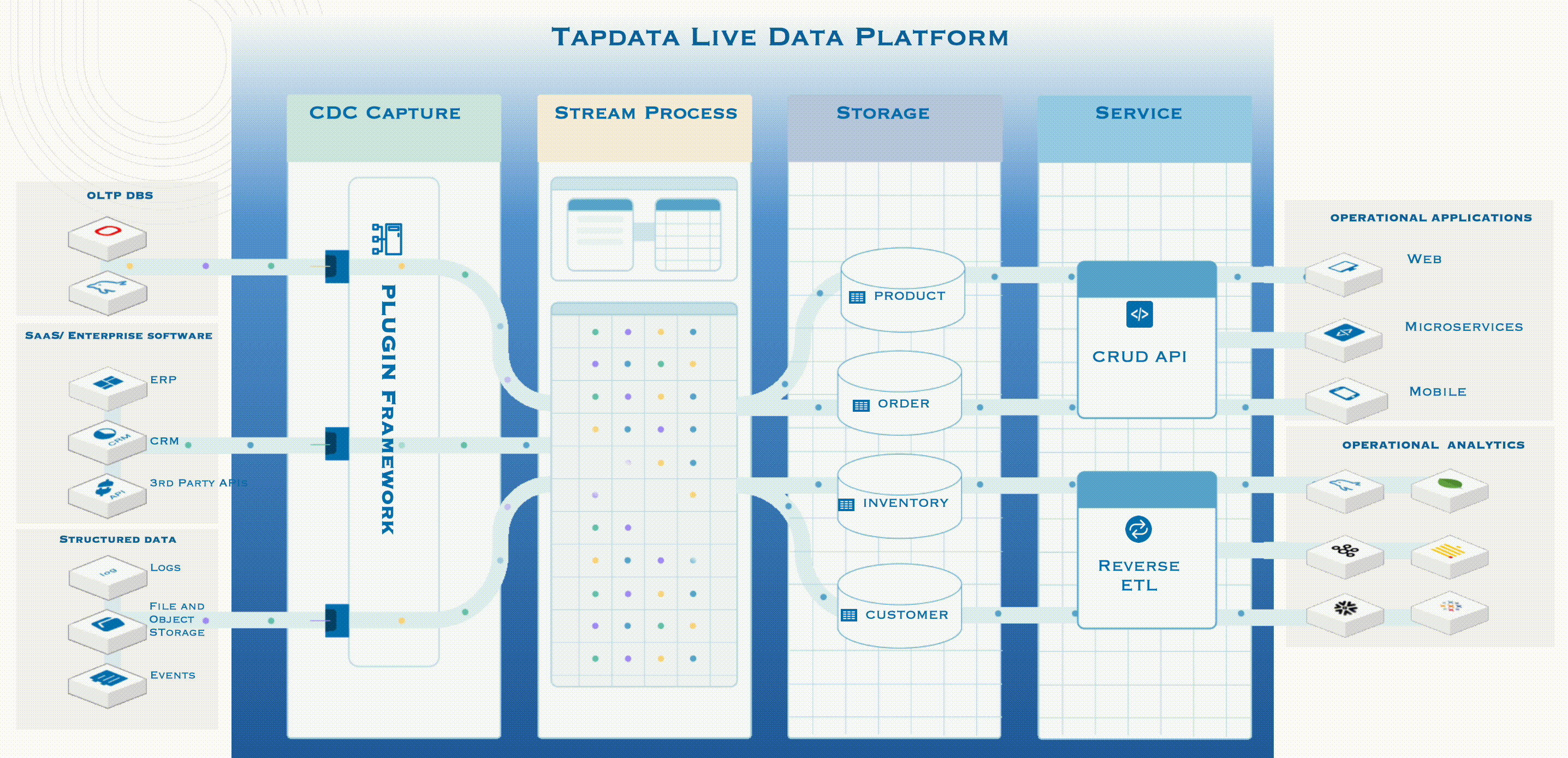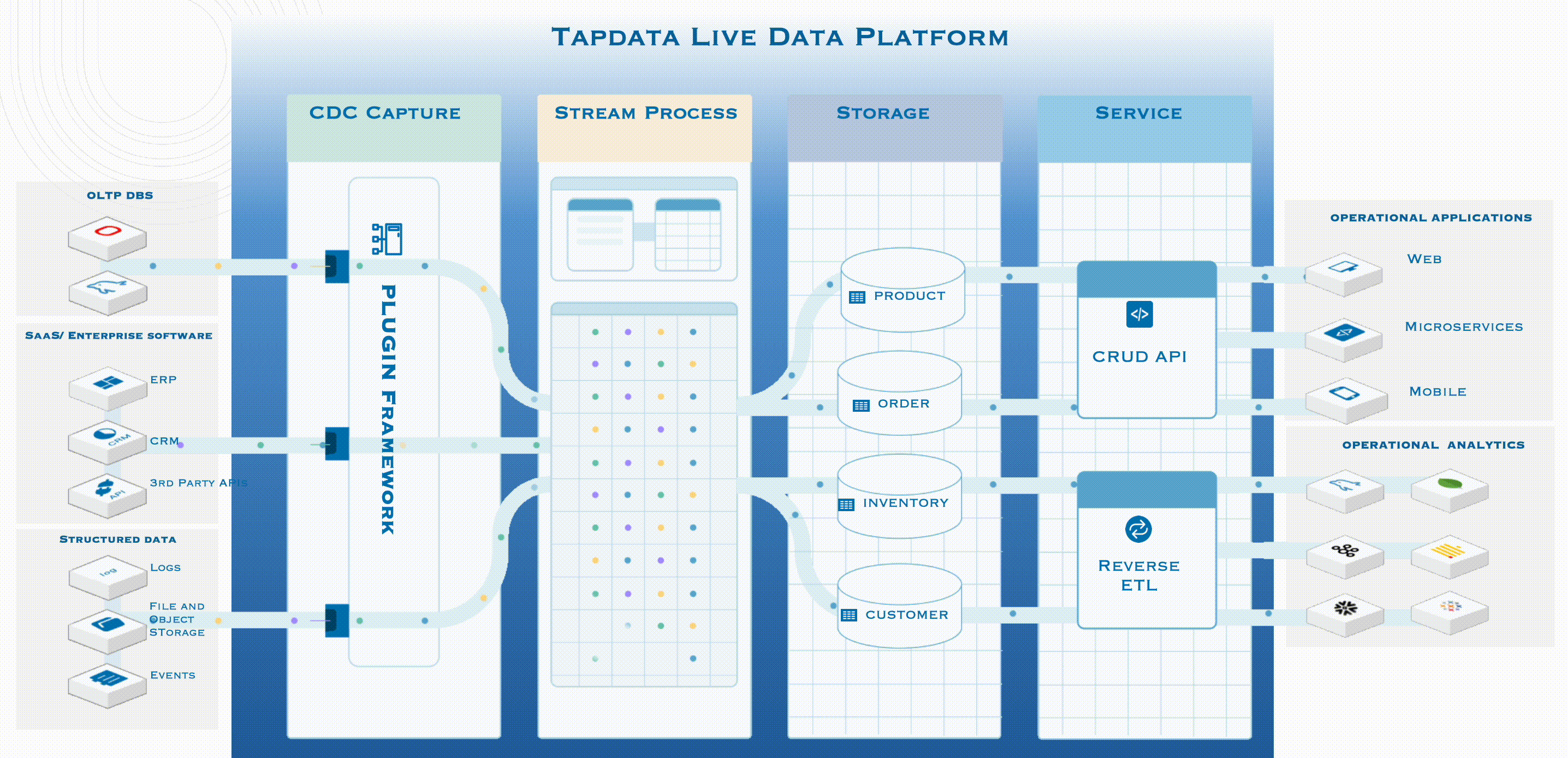
Tapdata LIve Data Platform 的工作機制
如上圖所示,左側是企業的所有資料來源,包括主流的 OLTP 資料庫,以及業務系統、檔案、資訊流事件等等。 Tapdata LDP 的工作機制是:
第一步,先基於紀錄檔解析的能力,通過開放式框架 Plugin Framework,以實時等方式,第一時間對這些資料來源頭中修改/更新/變動的資料進行採集並標準化,形成標準時間後進入流處理框架;
第二步,通過 Tapdata 自研方案,無需離開程序,在程序內即可完成資料計算、建模和轉型,快速得出結果,進入 DaaS Storage 層;
第三步,在將資料放入 Storage 層時,實際上已經形成了一套邏輯模型,在這裡,使用者無需關心資料儲存在哪裡,只需要關注真正需要的是哪些資料資訊;
第四步,也是 DaaS 的關鍵價值所在,在服務層,有兩種主流的資料服務模式,分別是 Pull 和 Push。前者指的是 Tapdata 會自動釋出一些 API,這些 API 支援低程式碼釋出,可以按照具體需求釋出資料。而當所需資料在業務系統中已有儲存時,就可以通過 REVERSE ETL,反向把這些經過整理、治理的資料推播給使用者,這也就是 Push 模式。
通過上圖大家不難發現,所有資料驅動業務都在最右側,並不包含在 Tapdata 四步工作流程之內。因為無論最終要用資料做什麼樣的業務,都是使用者自身需要關注的事情,Tapdata 只專注於提供準確、一致的最新資料。這就是 DaaS 的精髓:我們不做業務,我們只為實時資料做準備。
Tapdata 技術架構
如下圖所示,Tapdata 技術架構由一個大的外掛體系、資料管理、系統和互動三部分構成。
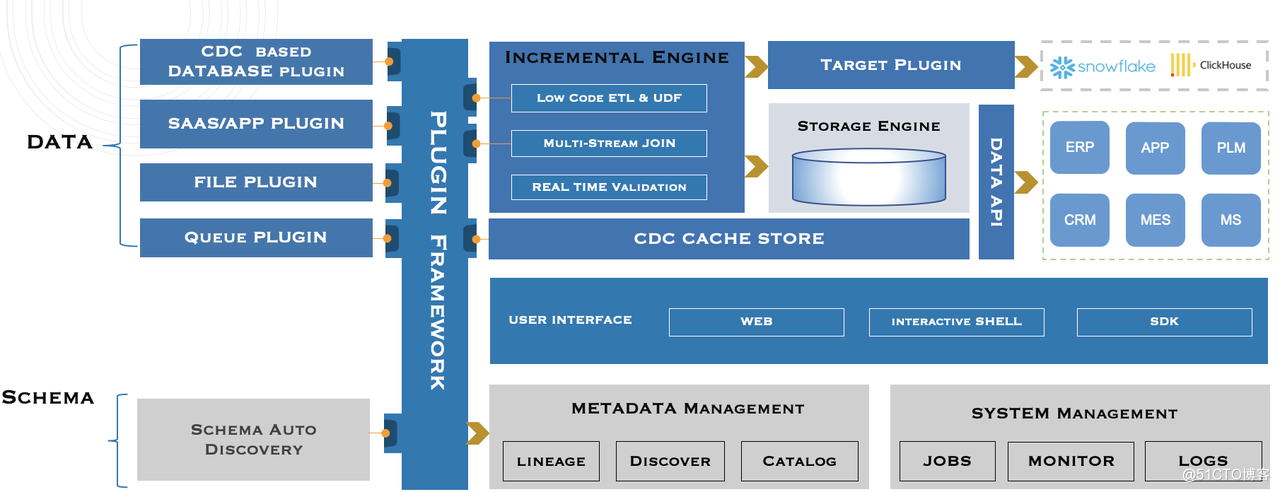
Tapdata 技術架構概覽:一圖瞭解 Tapdata LDP 平臺架構方案
其中,外掛體系又包含資料和結構的整合、計算和運算元整合、快取整合等多個組成部分:
-
資料整合:用以對接各種資料來源,包括平臺主打的基於紀錄檔實時解析的資料庫實時整合、以 API 和 Webhook 為特點的服務或應用的實時整合、來自 Excel/TXT 等檔案的整合,以及來自 Kafka 等各種訊息佇列的整合等。目前,Tapdata 平臺內已實現了對 40+ 不同資料來源的支援,包括 Oracle、MySQL、PostgreSQL、SQLServer 等主流資料庫、API、佇列、物聯網等,並且還在持續擴充更多的資料來源和型別。
-
結構整合:與資料整合密不可分,提供資料結構的觀察檢視,可以幫助使用者更理解自己的資料,瞭解資料結構自身的流動和變化。
-
計算和運算元整合:對應引擎元件,承擔了 LDP 的計算功能。是 Tapdata 專為實時資料服務場景打造的計算元件。在引擎中,使用者可以完成拖拉拽、低程式碼構建 ETL 的任務,也可以基於 JS Python 等開發語言,視覺化封裝各種各樣的操作元件,還能實現多流寬表流式聚合這樣繁重的高階能力,使用更方便。
相較於基於 Kafka 的 ETL,在使用上無需進行冗長的鏈路開發,鏈路更短、延遲更低、更易排查 -
快取整合:對應快取儲存,是 Tapdata 基於流計算場景對於儲存的獨特訴求而特別設計的元件,是順序和隨機的矛盾結合體,代表了效能和準確性之間的高度平衡。
-
資料來源外掛:在完成資料計算之後,資料可以通過資料來源外掛寫入使用者需要的目標庫,完成流轉閉環。
-
Data API:利用 Tapdata 內建的資料儲存服務,還能直接將計算後的資料釋出為 API 介面,做到了真正的資料即服務。
在資料管理部分,針對使用者對資料探索和感知能力的訴求,LDP 提供了資料溯源、搜尋和資料目錄的功能。
在系統和互動的部分,系統模組主打企業特性,包括監控告警、全員審計等模組;互動部分則提供了基於瀏覽器的介面操作、互動式的命令列操作,以及可遷入 SDK 的整合操作,用來滿足不同使用者的需求。
初步瞭解 LDP 架構大框架之後,下文將基於幾個重點模組來解析其設計原則的細節、搭建中遇到的問題和對應的解決思路。
Tapdata 架構核心自研組建
- Plugin Framework:外掛化平臺擴充套件體系設計
Tapdata 外掛體系中的各個元件分別對應不同的擴充套件能力,「可延伸」這一原則體現在 Tapdata 架構設計的方方面面,為適應不同場景帶來了便利。可以說 Tapdata 就是在外掛體系上生長的平臺。
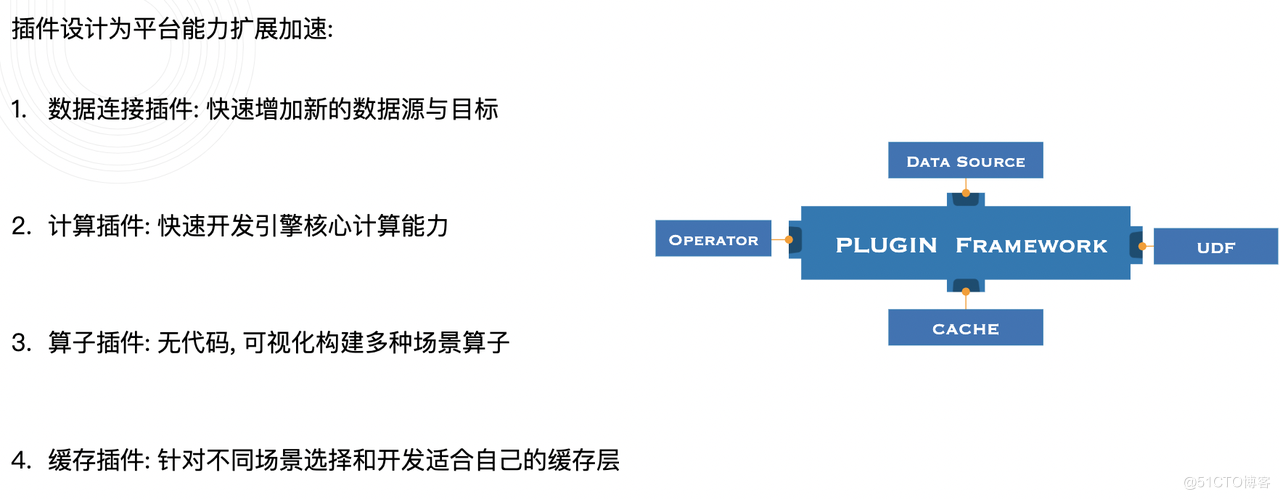
外掛設計 Tapdata LDP 的能力擴充套件加速
選取幾個具有代表性的資料連線外掛(DataSource Plugin)為例:
① DATA:準確高效而穩健的資料接入
實時場景不僅對資料接入的效能和準確性要求高,對各種異常情況下的可排查性、可恢復能力的要求也很高。為此,Tapdata 在批流一體等常見介面之外,還提供了很多雖然不常見但非常有用的介面方法,共同支撐起一個能夠提供企業級資料準確性和穩定性保障的實時資料平臺。例如:
- 全量增量的斷點續傳:偶爾犯錯, 快速恢復
- 資料回放:錯已鑄成, 快速回滾
- 獲取源庫最新事件時間:精準延遲判斷
- 無條件心跳廣播:避免稀疏事件的斷點影響
- 冪等設計: 保證資料的最終準確性
② META:優雅的模型自動推斷體系
在資料準確性這個問題上,資料本身外,資料結構的準確性也不容忽視。隨著資料來源數量和型別的不斷擴充套件,異構複製等場景對 Tapdata LDP 造成的維護壓力只會越來越大,編譯成本也會越來越高。對於這個問題,常見的解法有兩種。一是基於 JSON 型別或語言原生型別進行結構描述,其弊端是往往會導致異構同步表結構不準確,需要使用者手動調整。二是基於一些開源框架,使用時需要先在目標端手動建立表,才可以開始做計算。顯然都不是很好的方案。
Tapdata LDP 針對資料結構的準確性做出優化
為此,Tapdata 給出了創造性的新思路——引入一個抽象的中間層,只需要描述資料來源到中間層的對映,就會自動匹配出最適合的目標型別,給出對映關係,並自動構建目標表模型。該系統上線之後,使用者側遇到的建表不准問題大幅減少,同時也從根本上解決了資料來源數量擴充套件的一大難題。
https://www.bilibili.com/video/BV1uZ4y1Y7KK/?aid=385693533&cid=766330100&page=1
戳上方連結,檢視資料連線外掛的成品效果演示,展示一個 MySQL 資料來源從註冊到使用的全過程
- Incremental Engine:分散式輕量實時計算引擎
Tapdata LDP 的計算引擎全稱是 Incremental Engine,顧名思義,專為增量實時計算設計,也是我們目前發現的最適合實時資料服務的引擎架構。引擎是一體化設計,相較於傳統架構的多程序資料互通模式,Tapdata LDP 將鏈路變得極其簡單。
Tapdata LDP 單程序完成資料互通,鏈路極簡
源→引擎→目標,所有工作都在一個程序內完成,極大地降低了使用者的使用負擔。而極簡併不意味著功能上的代償,LDP 引擎的功能齊全。從基本的同步、轉換,到高階的多流合併、多種聚合計算,LDP 引擎都有能力支援;資料來源、計算、運算元、儲存也都可以實現外掛化擴充套件。此外,多個計算引擎之間,還實現了任務的自動故障轉移,具備分散式高可用的優勢。而且在多流無窗合併場景下,Tapdata 在滿足資料準確性的前提下數十倍降低了資源消耗,這也是 LDP 的一項特色能力。引擎為 Tapdata LDP 提供了核心動力,完美適配實資料服務平臺計算框架的需求。
- CDC CACHE STORE:專為流計算場景優化的快取引擎
CDC Cache Store 元件的設計初衷是用來快取 CDC 增量事件。如下表所示,市面上常見的幾種資料庫,在增量訂閱方面的表現,或多或少都存在一些缺陷,並不能很好地滿足實時資料服務場景的需求。**
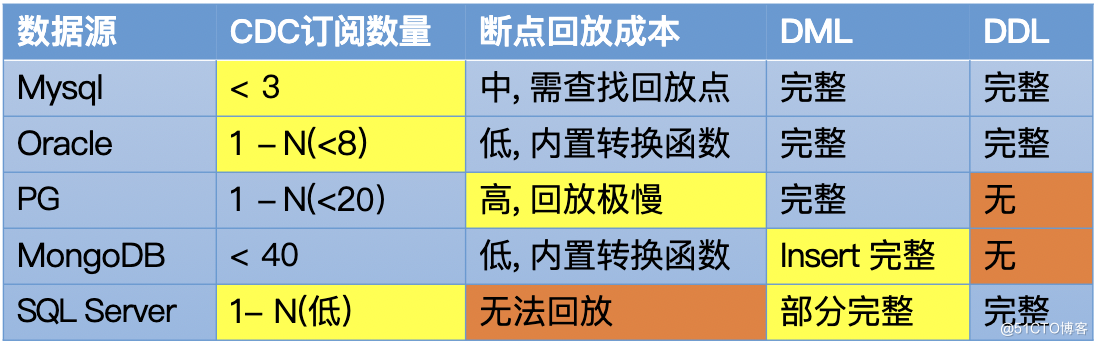
面對流計算對儲存引擎提出的順序訂閱和隨機讀寫的矛盾訴求,Tapdata 選擇對快取儲存進行抽象,自主開發了一個快取引擎,在具備一定高可用效能的隨機讀寫基礎上,對事件定義的並行效能做了很大的提升,在支撐平臺處理更多預算任務的同時,也讓整個平臺的技術架構變得更加乾淨。
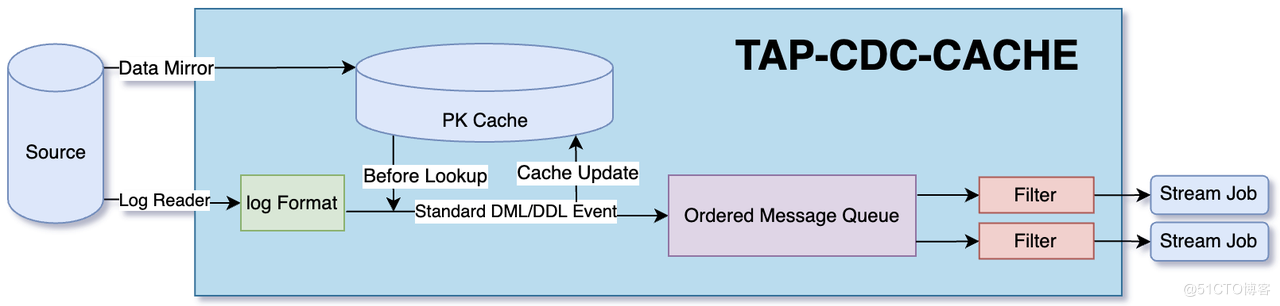
Tapdata CDC CACHE STORE 架構設計
- API Service:打造端到端完整閉環產品方案
面對如黃金般珍貴的實時資料,Tapdata 力求將資料獲取的便利性最大化。作為一體化解決方案,LDP 已實現如下能力:寬表直接釋出為介面,幫助業務快速上線;資料庫型別上層抽象,遮蔽介面差異;支援線上介面偵錯、執行;支援企業級管理,審計與監控功能一應俱全……由此,Tapdata LDP 讓資料價值的發揮實現了完美閉環,這也是 Tapdata 的一個設計目標。
Tapdata 優勢特性
作為新一代資料平臺,Tapdata LDP 具有以下三大特徵:
① 面向服務的清晰架構:用最高效的方式來使用資料

服務化架構意味著,我們能夠把資料同步到中臺中央化平臺裡進行復用,從而大幅減少從源頭髮出的資料鏈路,把鏈路的數量從數百降到數十甚至更少,降低對源頭源庫的影響。從實時資料整合角度來看,Tapdata LDP 需要更少的節點,可以從十幾個程序降到兩三個程序。而且邊界清晰,專注於資料的第一公里或者前幾公里,拒絕全家桶,專注基礎能力。
② 全鏈路實時的能力:支援 TP+AP 場景,發揮更大的資料價值

這也是 Tapdata 主打的 DNA 品質,從 LDP 的命名就能看出 Tapdata 對 Live 的高度重視。Live 即鮮活、新鮮,Tapdata 全程面向具有最高價值的 TP 和實時分析的 AP 場景,旨在發揮更大的實時資料價值,主要體現在這幾個方面:
- 採集實時:Tapdata 支援超 40+個資料來源,支援源到目標 Any to Any 的資料實時同步對接,接下來還將通過開源的方式,在 Tapdata 主力之餘,讓開發者們參與共創,一起努力讓資料來源版圖快速拓展到 100+。
- 傳輸實時:從源端到目標端,精準控制,實現了低至亞秒級的傳輸延遲。
- 計算實時:過程中需要計算時,Tapdata LDP 具有每秒數萬條的實時流計算處理能力,單節點的情況下,通過並行分散式該能力還可以進一步提升。
③ 最易用的資料開發體驗:面向開發者、面向資料工程師
站在審視一個資料產品的角度,Tapdata 非常關注 LDP 的易用性和靈活性,無需部署十幾個節點,開發者、資料工程師直接下載就可以非常方便地使用起來,打造卓越的使用體驗。Tapdata 提供了兩種使用互動的方式:
- 全程視覺化:面向資料工程師,支援對企業的所有資料進行托拉拽式的加工、建模、處理、合併,所見即所得,快速獲取一個永久實時更新的資料模型。
- 首創 Fluent ETL API:面向開發者,特別針對開源社群,無需 SQL,只需要寫一段程式就可以擁有資料整合能力,完成資料開發工作。
Tapdata 相信,IT 服務化是一個非常明確的趨勢,從 20 年前亞馬遜把基礎架構作為服務開始(IaaS, Infrastructure as a Service),到十多年前把資料庫中介軟體作為服務(PaaS, Platform as a Service),再到近幾年特別火熱的 SaaS(Software as a Service),「服務化」的發展非常快,服務化價值也得到了歷史的證明。而如今的趨勢,就是將資料抽象為一種服務,為下游的一切業務提供支撐。讓資料使用像開啟水龍頭使用自來水一樣簡單,這是 Tapdata 的願景,也是 Tapdata 命名的初衷——Make Your Data on Tap。
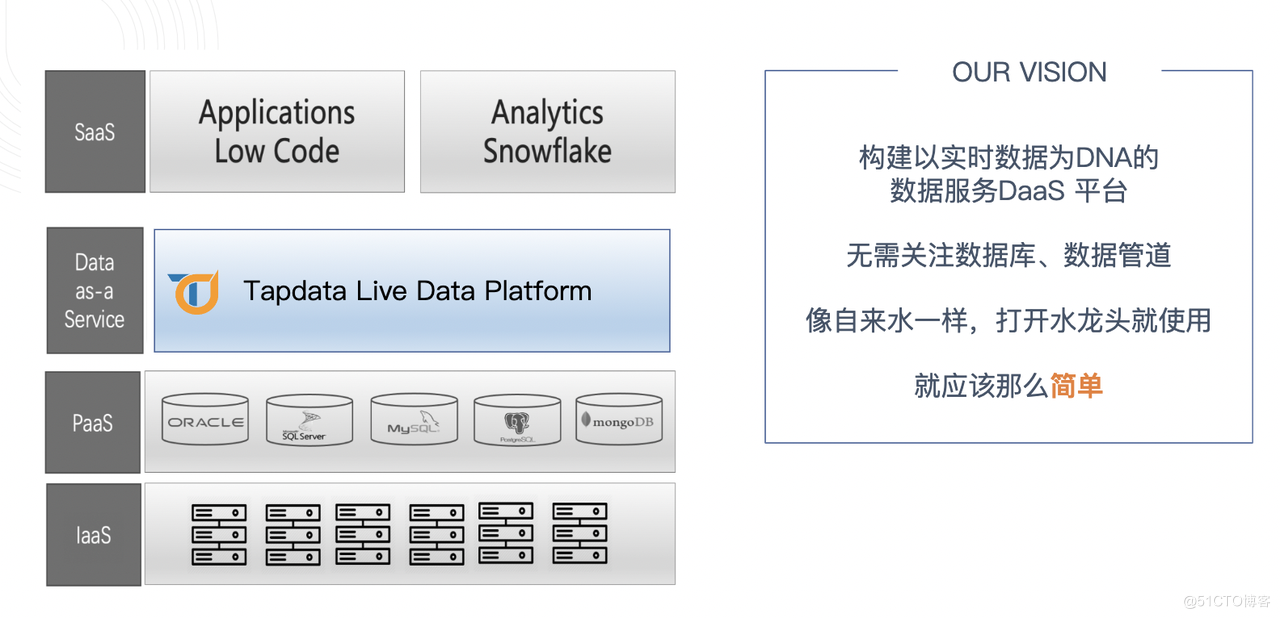
IT 服務化趨勢下,DaaS 的發展已成必然
與此同時,我們也欣慰地發現,行業中已經有越來越多的視線開始投向這一賽道,期待集結更多力量推動資料技術的發展更進一步。
Tapdata LDP 現已開放自助體驗通道
讀到這裡,相信大家對 Tapdata LDP 已經有了一定的認知。想要進一步瞭解更多相關資訊?想要真正上手體驗 LDP 產品功能?歡迎註冊成為 Tapdata LDP 首批體驗官,獲取體驗官專屬服務:
自助流程:
第1步:點選這裡 註冊成為「Tapdata 體驗官」
第2步:註冊成功後進入「體驗官個人中心」
第3步:在專屬服務中點選「下載安裝包並獲取企業版 License」,按照試用指引完成安裝和 License 啟用。或點選「企業版線上 DEMO 體驗」獲得登入賬號和密碼
三、「魚」與「熊掌」兼得:Tapdata 並駕齊驅的開源與商業化
Tapdta 創始人 TJ 從寫下 Tapdata 的第一行程式碼開始,就決定一定要將原始碼開放出去。
6月的最後一天,Tapdata 開源版本正式上線。
無論是從公司的角度還是從行業生態的角度,開源與商業化從來都不是「魚」與「熊掌」的關係,而是互為引擎的相輔相成。開源帶來技術創新,為 Tapdata 輸送生生不息的迭代動力;商業化收益反哺開源社群,又將為開源模式持續運轉提供穩定的基礎支撐。「開放」與「開源」正是 Tapdata 刻進 DNA 裡的戰略堅持。
- GitHub 專案連結:https://www.github.com/tapdata/tapdata
- 開源站點:https://tapdata.github.io
Tapdata 為什麼要做開源?
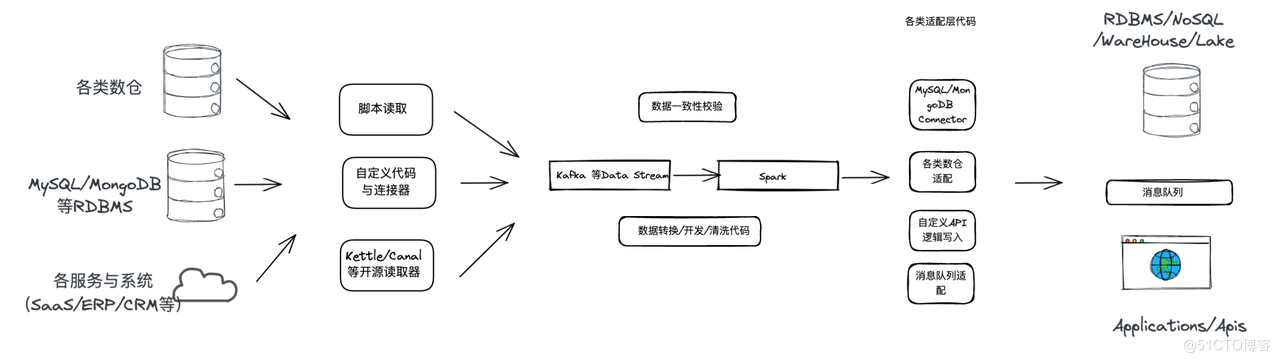
基於開源組建的資料整合解決方案
今天,已經有越來越多的企業和使用者意識到了資料的價值。但複雜且繁瑣的既有開源解決方案往往讓很多使用者望而卻步。面對現存資料平臺開源解決方案存在的鏈路長、非實時、成本高、難維護等缺陷,Tapdata 正在全力打造與之相對的一種快速、實時、簡單、易用的新平臺。Tapdata 希望以全自動化的實時資料整合能力為基礎,連線並統一企業的資料孤島,成為企業的主資料底座。
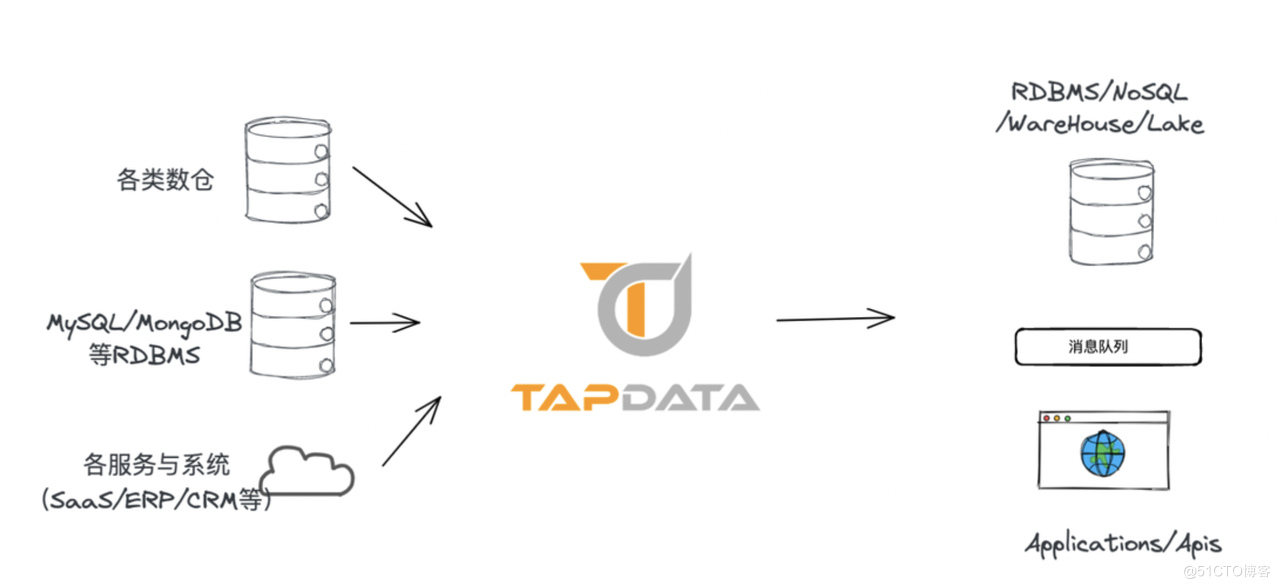
Tapdata 致力於打造快速、實時、簡單、易用的新方案
同時我們也深知:一個人、一個公司的力量是有限的,而 Tapdata 的願景是遠大的,在通往目標的路上,有大量挑戰在等待著我們。我們需要社群的聲音、使用者的鞭策、積極的參與以及多方的幫助,一同將產品打造得更強。我們希望通過開源,讓越來越多的開發者參與到 Tapdata 的使用與開發中來,幫助 Tapdata 開源專案實現更快的成長,更快地滿足更多使用者的訴求,讓更多使用者能夠獲得新鮮資料的價值,並帶來更多的需求與場景。
Tapdata 創始人TJ 從寫下第一行程式碼開始,就決定一定要將我們的原始碼開放出去。我們已經準備好了——讓 Tapdata 開源版本,為更多開發者輸送實時資料的新鮮血液。
Tapdata 開源 RoadMap

如上面的開源路線圖所示,6 月 30 日釋出的首個開源版本核心覆蓋的場景是:實時資料同步、開發和 Fluent ETL。3 個月之後,我們將釋出 Tapdata 1.5 版本,預計新增實時資料校驗、增量資料校驗、自定義函數與聚合運算元場景支援,同時將資料來源補充到 50 個以上。
預計將於 2022 年 https://www.cnblogs.com/tapdata/p/11 月 30 日正式釋出的 2.0 版本補充的核心能力包括:Any DB-To-API,資料目錄、資料發現、資料溯源,並將支援的資料來源數量提升至 80+。除此之外,我們還有非常多想要和所有社群開發者在演進過程中一同探索實現的能力,和共同交流解決的問題。在未來,Tapdata 開源版本還將推出 Open API、流式儲存引擎、Open Metadata、Master Data 等多重重磅能力,敬請期待!

Tapdata 開源能力清單
Tapdata 首批開源體驗官限量招募中!
為了更好地傾聽開發者們的聲音,共創優雅易用、功能完備的實時資料平臺,Tapdata 現公開徵集開源專案體驗官,搶鮮體驗優質開源專案 Tapdata ,成為社群首批成員,結識更多開發者同路人,與 Tapdata 攜手挖掘資料潛能,第一時間獲取專案最新資訊。
作為 Tapdata 社群首批使用者,你將可以:
- 讓你的資料快人一步,感受 Data on Tap
- 獲得 Tapdata 開源 Issue、需求的特殊優先順序
- 第一時間收穫社群最新資訊(包括但不限於開發計劃、核心技術、業務場景等)
- 參與活動、領取開源體驗官新手任務、獲得上午雙肩包、潮牌 T 恤等更多好禮
- 有機會受邀加入 Tapdata Committer Program,成為正式的 Tapdata Committer
- 有機會直接參與並影響 Tapdata 的未來走向

原文連結:Tapdata 的 2.0 版 ,開源的 Live Data Platform 現已釋出 - Tapdata