跨模態語意關聯對齊檢索-影象文字匹配(Image-Text Matching)CVPR2022
論文介紹:Negative-Aware Attention Framework for Image-Text Matching (基於負感知注意力的圖文匹配,CVPR2022)
程式碼主頁:https://github.com/CrossmodalGroup/NAAF
主要優勢:
1)不額外新增任何學習引數前提下,在基礎基線SCAN上取得顯著效能提升,達到SOTA;
2)模型設計簡單有效,只需要SCAN 的文字-影象(Text-to-Image)單方向計算,可以大幅減少基於注意力的匹配方法檢索耗時。
3)顯式的跨模態語意對齊相關性和不相關性學習。結合最優的相關性區分學習,構造一種聯合的優化框架。

一、前言
影象文字匹配任務定義:也稱為跨模態影象文字檢索,即通過某一種模態範例, 在另一模態中檢索語意相關的範例。例如,給定一張影象,查詢與之語意對應的文字,反之亦然。具體而言,對於任意輸入的文字-影象對(Image-Text Pair),圖文匹配的目的是衡量影象和文字之間的語意相似程度。
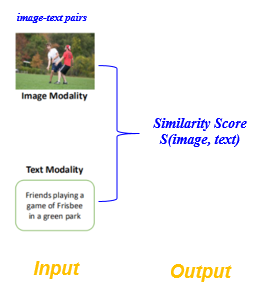
圖1 圖文匹配的輸入和輸出
核心挑戰:影象文字跨模態語意關聯致力於彌合視覺模態和語言模態之間的語意鴻溝,目的是實現異質模態(底層畫素組成的影象和高層語意向量表示的文字)間的準確語意對齊,即挖掘和建立影象和文字的跨模態語意一致性關聯對應關係。
現狀分析:現有的影象文字影象文字匹配工作可以大致分為兩類:1)全域性關聯:以整個文字和影象作為物件學習語意關聯;2)區域性關聯:以細粒度的影象顯著區域和文字單詞作為物件學習語意關聯。早期的工作屬於全域性關聯,即將整個影象和文字通過相應的深度學習網路對映至一個潛在的公共子空間,在該空間中影象和文字的跨模態語意關聯相似度可以被直接衡量,並且約束語意匹配的圖文對相似度大於其餘不匹配的圖文對。然而,這種全域性關聯正規化忽略了影象區域性顯著資訊以及文字區域性重要單詞的細粒度互動,阻礙了影象文字語意關聯精度的進一步提升。因此,基於細粒度影象區域和文字單詞的區域性關聯受到廣泛的關注和發展,並快速佔據主導優勢。對於現有的影象文字跨模態語意關聯正規化,核心思想是挖掘所有影象片段和文字片段之間的對齊關係。
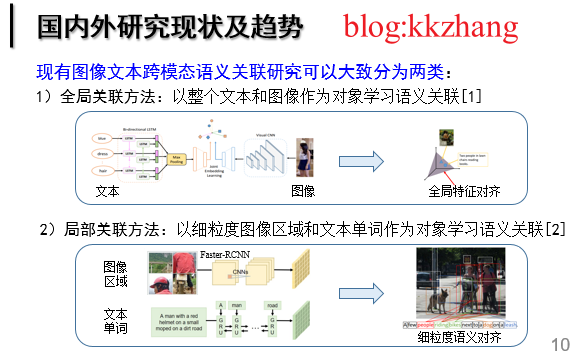
圖2 圖文匹配的發展現狀
交叉注意力網路SCAN通過區域和單詞之間的相互關注機制來捕捉所有潛在的區域性對齊,並激發出了一系列工作。跨模態交叉注意力旨在挖掘所有影象區域和文字單詞之間的對齊關係,通過區域性語意對齊來推理整體相關性。得益 於細粒度的模態資訊互動,基於交叉注意力的方法取得顯著的效能提升,併成為當前影象文字跨模態語意關聯的主流正規化。
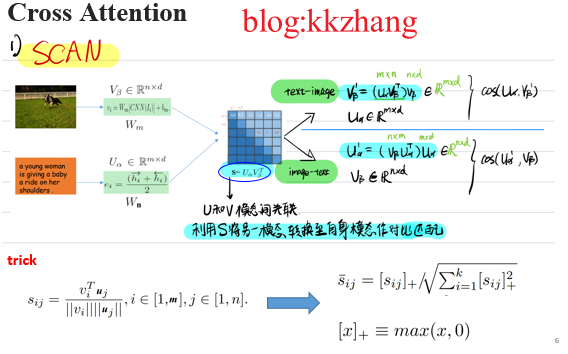
圖3 跨模態交叉注意力正規化SCAN
動機:現有方法往往根據關聯互動獲取模態間的對齊語意。該過程的目的是 最大化影象和文字中的對齊語意相似度,並以此作為線索依據來計算圖文匹配程度。具體的,在模態互動學習過程中,現有方法通常抑制非對齊線索的作用(通過一個 ReLU 函數抹除負關聯分數),導致模型主要學習對齊語意的正面作用。然而,他們都忽略了影象-文字對中豐富的非對齊線索對於衡量 是否匹配也十分重要。因為當文字描述中出現影象裡不存在的內容(非對齊的文字單詞片段),那麼這個 影象-文字對就是不匹配的。由此分析可知,非對齊的文字單詞片段對於衡量影象-文字對是否匹配同樣重要。最樸素的想法就是:我們可以充分的挖掘非對齊片段的負面作用,使原本檢索在Top位置的錯誤匹配降低相似分值,從而儘可能的檢索到正確的。如下圖所示:
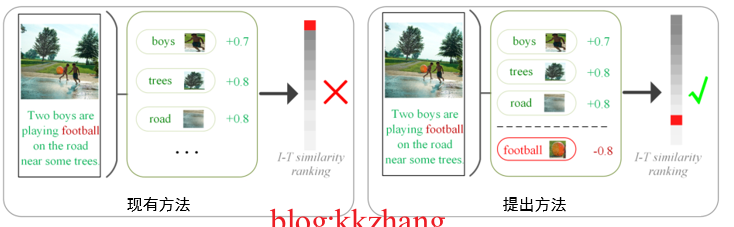
圖4 負感知注意力動機分析
二、總體框架
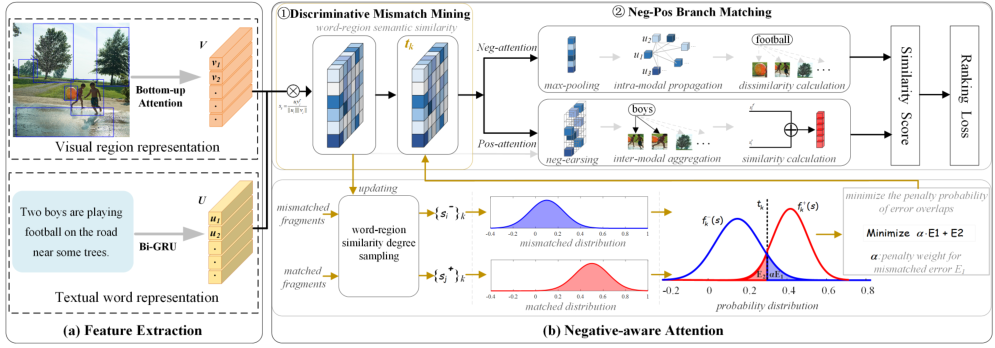
圖5 負感知注意力的總體框架圖
Overview:負感知注意力網路包含兩個主要模組:1)不匹配挖掘模組:通過建模匹配片段和不匹配片段的相似度分佈,然後通過優化兩個分佈的最小錯分概率求解最優的相似度區分閾值,從而儘可能的區分不匹配片段。2)正負雙分支匹配模組:通過兩種不同的掩碼注意力機制,一方面關注匹配片段的相似度,另一方面精確計算不匹配片段的不相似度,聯合利用前者的正面作用和後者的負面作用進行影象和文字之間的跨模態語意關聯衡量。
亮點:①第一個聯合利用匹配和不匹配片段的正面和負面作用,並顯式挖掘不匹配片段的工作。②在訓練過程中組成聯合優化框架:前向優化:自適應地學習最優相關性閾值,獲取更優的語意對齊;後向優化:由於最優閾值在參與注意力計算過程,因此在梯度反向傳播優化時,會促使相關和不相關的相似度逐漸分離,從而學習更有區分性的影象文字特徵嵌入。
下面,分別介紹兩個模組的具體實現:
1)不匹配片段挖掘模組
在一個影象-文字對中包含大量的匹配和不匹配的片段,我們需要充分利用這兩種型別的資訊來實現更精確的檢索效能。在實際匹配的過程中,計算出區域-單詞對的相似度分數後,需要一個邊界來決定它是匹配片段還是不匹配片段,現有的方法通常隱式地以固定值0作為區分邊界。為了更準確地區分匹配片段和不匹配片段,我們對兩者的相似度進行取樣,然後顯式地、自適應地建模兩者的相似度分佈,繼而找到一個最優的區分邊界,實現有效的不匹配片段挖掘。考慮到缺乏關於片段級的區域-單詞是否匹配的先驗資訊,並且影象中含有大量背景區域,我們從文字的角度出發,設計了一種取樣策略:對於一個匹配的文字,其中任意的單詞一定可以在其匹配影象中找到至少一個匹配區域,我們視一個文字單詞$u_{i}, i \in[1, m]$和其匹配影象的所有區域$\{v^{+}_{j}\}_{j=1}^{n}$中相似度分數最高的為匹配片段,進而做出取樣:
\begin{eqnarray}
s^{+}_{i}=\underset{j}{\text{max}}(\{{v^{+}_{j} u_{i}^{\mathrm{T}}}/({\|v^{+}_{j}\|\|u_i\|})\}_{j=1}^{n}),\label{E13}
\end{eqnarray}
另一方面,對於一個不匹配的圖文對,文字中的不匹配單詞與影象中的所有區域都不匹配,此時單詞$u_{i}, i \in[1, m]$和不匹配影象的所有區域$\{v^{-}_{j}\}_{j=1}^{n}$中相似度分數最高的可以代表不匹配片段的相似度的上界,由此做出取樣:
\begin{eqnarray}
s^{-}_{i}=\underset{j}{\text{max}}(\{{v^{-}_{j} u_{i}^{\mathrm{T}}}/({\|v^{-}_{j}\|\|u_i\|})\}_{j=1}^{n}),\label{E14}
\end{eqnarray}
並構造如下集合:
\begin{eqnarray}
{S}^{-}_{k} =[s^{-}_{1}, s^{-}_{2}, s^{-}_{3}, \ldots, s^{-}_{i}, \ldots],\label{E3}\\
{S}^{+}_{k} =[s^{+}_{1}, s^{+}_{2}, s^{+}_{3}, \ldots, s^{+}_{i}, \ldots],\label{E4}
\end{eqnarray}
其中${S}^{-}_{k}$和${S}^{+}_{k}$分別表示不匹配區域-單詞的相似度分數$s^{-}_{i}$和匹配區域-單詞的相似度分數$s^{+}_{i}$的集合,它們會在訓練過程中動態更新,$k$即為更新的輪數。基於構造出的兩個集合,我們可以分別建立匹配片段和不匹配片段的相似度分$s$數的概率分佈模型:
$f^{-}_{k}(s)=\frac{1}{\sigma^{-}_{k}\sqrt{2\pi}}e^{[-\frac{(s-\mu^{-}_{k})^{2}}{2(\sigma^{-}_{k})^2}]}$, $f^{+}_{k}(s)=\frac{1}{\sigma^{+}_{k}\sqrt{2\pi}}e^{[-\frac{(s-\mu^{+}_{k})^{2}}{2(\sigma^{+}_{k})^2}]}$,
其中, $(\mu^{-}_{k}, \sigma^{-}_{k})$ 和 $(\mu^{+}_{k}, \sigma^{+}_{k})$分別是兩種概率分佈的均值和標準差。
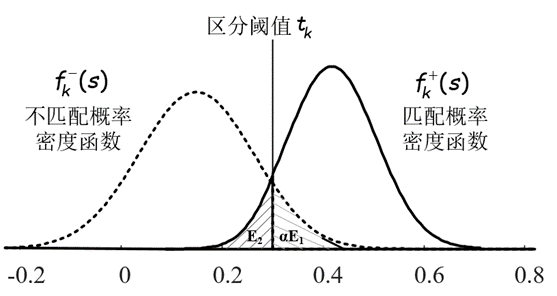
圖6 匹配和不匹配片段相似度分佈建模
分別得到兩個相似度分佈建模後,可以用一個顯式的邊界$t$在匹配片段和不匹配片段之間進行區分,如圖6所示,相似度分數大於$t$的區域-單詞對被視為匹配片段,反之則為不匹配片段。其中,有兩種區分錯誤的情況:將實際上不匹配的片段區分為匹配的(如圖6中的$E_1$),或者將實際上匹配的片段誤認為是不匹配的(如圖6中的$E_2$)。我們的目的是最大限度的挖掘出不匹配片段,需要找出一個最優的邊界$t$,使得區分錯誤的概率最低,保證識別的準確性,即解決如下優化問題:
\begin{equation}\label{E5}
\begin{array}{ll}{\underset{{t}}{\text{min}}} & \alpha \int_{t}^{+\infty}f_{k}^{-}(s)d{s} + \int_{-\infty}^{t}f_{k}^{+}(s)d{s},
\\ {\text {s.t. }}& t\geq 0,\end{array}
\end{equation}
其中$t$是該問題的決策變數,$\alpha$是懲罰引數。
對於該問題的最優解求解,我們首先搜尋它的一階導數的零點,並根據可行域的約束條件在$t \geq 0$處截斷(使用$[\cdot]_{+} \equiv max(\cdot,0)$),得到最優解為:
\begin{equation}\label{E6}
t_{k} = [(({\beta_{2}^{k}}^2-4\beta_{1}^{k} \beta_{3}^{k})^{\frac{1}{2}}-\beta_{2}^{k})/(2\beta_{1}^{k})]_{+}
\end{equation}
其中$\beta_{1}^{k} = (\sigma^{+}_{k})^2-(\sigma^{-}_{k})^2$, $\beta_{2}^{k} = 2(\mu^{+}_{k}{\sigma^{-}_{k}}^2-\mu^{-}_{k}{\sigma^{+}_{k}}^2)$, 和 $\beta_{3}^{k} = (\sigma^{+}_{k}\mu^{-}_{k})^2 - (\sigma^{-}_{k}\mu^{+}_{k})^2 + 2(\sigma^{+}_{k}\sigma^{-}_{k})^2\ln\frac{\sigma^{-}_{k}}{\alpha\sigma^{+}_{k}}$。
有兩點值得強調。 (1) 在訓練過程中,關於顯式的相關性邊界,其首先從不匹配和匹配片段的相似度分佈中學習,然後將被整合到注意力匹配過程中,以調整更具備區分性的相似度分佈,從而建立一個迭代優化過程。這樣,不配片段的分佈將最大限度地與匹配片段的分佈分開,其中不配片段可以產生更魯棒的負面影響。因此,不匹配的片段也可以作為有意義的線索來準確測量影象-文字的相似性。(2) 在訓練結束時,我們期望自適應學習邊界能夠同時保證最大挖掘不匹配片段,避免誤判匹配片段導致效能下降。為了使學習邊界收斂到具有更好挖掘精度的狀態,我們給出調整初始懲罰引數滿足的理論條件,或者更簡單的實現為:$t_k = \mu^{+}_{k}-3\sigma^{+}_{k}$。
2)正負雙分支匹配模組
在該模組中,我們同時考慮影象-文字對之間的匹配片段和不匹配片段,通過使用正面和負面兩種不同的注意力掩碼,分別從兩個分支精確衡量它們的積極和消極作用。我們首先計算所有區域和單詞對之間的語意相關度:
\begin{equation}\label{E7}
{s}_{ij}=\frac{u_{i} v_{j}^{\mathrm{T}}}{\|u_i\|\|v_j\|}, i\in[1,m], j\in[1,n]
\end{equation}
依然從文字的角度出發,計算一個文字單詞$u_i, i\in[1, m]$和一個影象所有區域$\{v_j\}_{j=1}^{n}$的相似度與區分邊界$t_k$的差值,其中的最大值體現了這個片段是匹配還是不匹配的程度:
\begin{equation}\label{E8}
{s}_{i}=\underset{{j}}{\text{max}}(\{s_{ij}-t_k\}_{j=1}^{n}),
\end{equation}
由此,可以衡量出一個影象文字對中第個單詞所帶來的負面作用為:
\begin{equation}\label{E9}
s_{i}^{neg} = {s}_{i}\odot\text{Mask}_{neg}({s}_{i})
\end{equation}
其中$\text{Mask}_{neg}(\cdot)$為掩碼函數,當輸入為負數時輸出為1,否則為0,$\odot$表示點積運算。
同時,我們可以考慮到單詞在文字內的語意內關係,使語意相似的單詞獲得相同的匹配關係,在推理過程中(Inference/Testing stage),對每個單詞的匹配程度進行一次模態內傳播:
\begin{equation}\label{E10}
\hat{s}_{i}\!=\! \sum_{l=1}^{m} w_{il}^{intra}{s}_{l}, \ \text{s.t.} \ w_{il}^{intra}\!=\text{softmax}_{\lambda}(\{{\frac{u_i u_l^{\mathrm{T}}}{\|u_i\|\|{u}_{l}\|}}\}_{l=1}^{m}),
\end{equation}
其中$ w_{il}^{intra}$表示第$i$個和第$l$個單詞之間的語意關係,$\lambda$是比例因子。
另一方面,衡量圖文對的相似程度時,我們首先關注跨模態的共用語意,第$i$個單詞在影象中相關的共用語意可以被聚合為:
\begin{equation}\label{E11}
\hat{v}_{i}=\sum_{j=1}^{n} w_{ij}^{inter} v_j, \quad s.t. \ \ w_{ij}^{inter} = \text{softmax}_{\lambda}(\{\text{Mask}_{pos}(s_{ij}-t_k)\}_{j=1}^{n}),
\end{equation}
其中$w_{ij}^{inter}$是單詞和區域的語意關聯,$\text{Mask}_{pos}(\cdot)$為掩碼函數,當輸入為正數時輸出與輸入相等,否則輸出$-\infty$,這樣使得不相關的影象區域($s_{ij}-t_k<0$)的注意力權重被削減至0。由此,片段的相似度分數為$s_{i}^{f} = {u_{i}{\hat{v}_{i}}^{\mathrm{T}}}/(\|u_i\|\|\hat{v}_{i}\|)$。
另外,區域與單詞間的相關度分數也反應了圖文間的相似程度,得到由相關度權重加權的相似度分數$s_{i}^{r}$ = $\sum_{j=1}^{n}w_{ij}^{relev}s_{ij}$,其中$w_{ij}^{relev}=\text{softmax}_{\lambda}(\{\bar{s}_{ij}\}_{j=1}^{n})$,$\bar{s}_{ij}= [{s}_{ij}]_{+}/\sqrt{\sum_{i=1}^{m}[{s}_{ij}]_{+}^{2}}$。因此,一個影象文字對中第個單詞所帶來的正面作用為:
\begin{equation}\label{E12}
s_{i}^{pos} = s_{i}^{f} + s_{i}^{r}
\end{equation}
最終,影象文字對 $(U, V)$的相似度由正面作用和負面作用共同決定:
\begin{equation}\label{E12-2}
S(U, V) = \frac{1}{m}\sum_{i=1}^{m} (s_{i}^{neg} + s_{i}^{pos})
\end{equation}
三、試驗效果
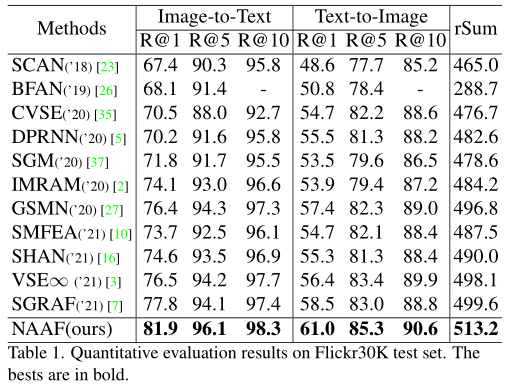
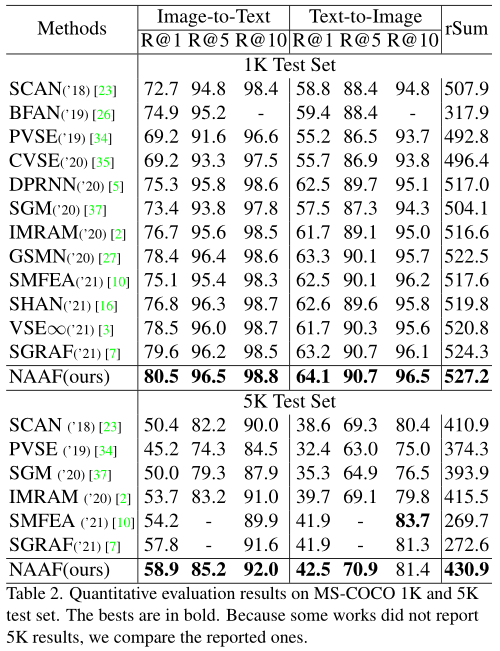
1)達到SOTA
2)視覺化
最優閾值學習過程:
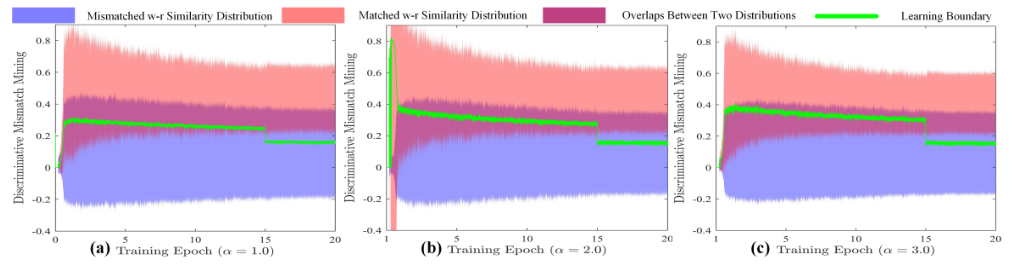
不匹配線索挖掘對比(藍色為不匹配)

四、論文
Zhang K, Mao Z, Wang Q, et al. Negative-Aware Attention Framework for Image-Text Matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 15661-15670.