CMU15445 (Fall 2019) 之 Project#2
前言
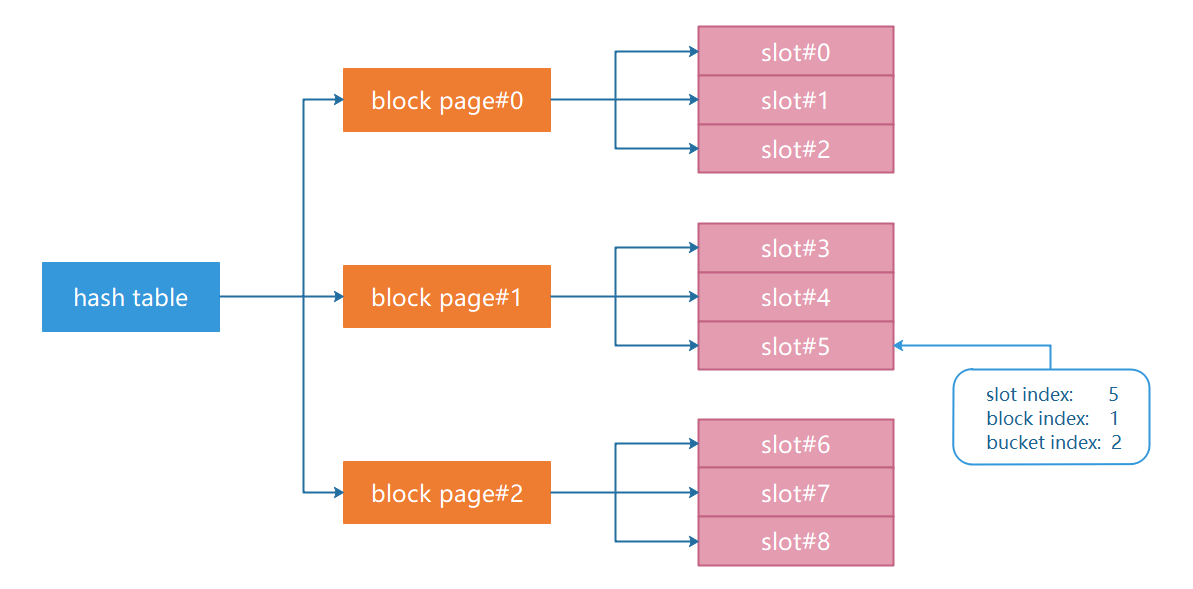
該實驗要求實現一個基於線性探測法的雜湊表,但是與直接放在記憶體中的雜湊表不同的是,該實驗假設雜湊表非常大,無法整個放入記憶體中,因此需要將雜湊表進行分割,將多個鍵值對放在一個 Page 中,然後搭配上一個實驗實現的 Buffer Pool Manager 一起食用。雜湊表的大致結構如下圖所示:
下面介紹如何實現一個執行緒安全的雜湊表。
程式碼實現
Page 佈局
從上圖可以看出,多個鍵值對被放在 Page 裡面,作為 Page 的資料存在磁碟中。為了更好地組織和管理這些鍵值對,實驗任務一要求我們實現兩個類:HashTableHeaderPage 和 HashTableBlockPage,HashTableHeaderPage 儲存著 block index 到 page id 的對映關係以及其他雜湊表後設資料,每個雜湊表只有一個 HashTableHeaderPage,而 HashTableBlockPage 可以有多個。
Hash Table Header Page
HashTableHeaderPage 有以下幾個欄位:
| 欄位 | 大小 | 描述 |
|---|---|---|
lsn_ |
4 bytes | Log sequence number (Used in Project 4) |
size_ |
4 bytes | Number of Key & Value pairs the hash table can hold |
page_id_ |
4 bytes | Self Page Id |
next_ind_ |
4 bytes | The next index to add a new entry to block_page_ids_ |
block_page_ids_ |
4080 bytes | Array of block page_id_t |
這些欄位總共 4096 位元組,正好是一個 Page 的大小,在 src/include/common/config.h 中可以修改 PAGE_SIZE 的大小。該類的實現程式碼如下:
namespace bustub {
page_id_t HashTableHeaderPage::GetBlockPageId(size_t index) {
assert(index < next_ind_);
return block_page_ids_[index];
}
page_id_t HashTableHeaderPage::GetPageId() const { return page_id_; }
void HashTableHeaderPage::SetPageId(bustub::page_id_t page_id) { page_id_ = page_id; }
lsn_t HashTableHeaderPage::GetLSN() const { return lsn_; }
void HashTableHeaderPage::SetLSN(lsn_t lsn) { lsn_ = lsn; }
void HashTableHeaderPage::AddBlockPageId(page_id_t page_id) { block_page_ids_[next_ind_++] = page_id; }
size_t HashTableHeaderPage::NumBlocks() { return next_ind_; }
void HashTableHeaderPage::SetSize(size_t size) { size_ = size; }
size_t HashTableHeaderPage::GetSize() const { return size_; }
} // namespace bustub
Hash Table Block Page
HashTableBlockPage 包含多個 slot,用於儲存鍵值對,所以該類定義了查詢、插入和刪除鍵值對的函數。為了跟蹤每個 slot 的使用情況,該類包含以下三個資料成員:
occupied_: 第 i 位置 1 表示 Page 的第 i 個 slot 上儲存了鍵值對或者之前存了鍵值對但之後被刪除了(起到墓碑的作用)readable_: 第 i 位置 1 表示 Page 的第 i 個 slot 上儲存了鍵值對array_: 用於儲存鍵值對的陣列
每個鍵值對的大小為 sizeof(std::pair<KeyType, ValueType>) 位元組(記為 PS),每個鍵值對對應兩個 bit(occupied 和 readable)即 1/4 個位元組,所以一個 Page 最多能儲存 BLOCK_ARRAY_SIZE = PAGE_SIZE / (PS + 1/4) 個鍵值對,即每個 Page 有 BLOCK_ARRAY_SIZE 個 slot。
由於 occupied_ 和 readable_ 被定義為 char 陣列,所以需要兩個輔助函數 GetBit 和 SetBit 來存取第 i 位的位元。
namespace bustub {
/**
* Store indexed key and and value together within block page. Supports
* non-unique keys.
*
* Block page format (keys are stored in order):
* ----------------------------------------------------------------
* | KEY(1) + VALUE(1) | KEY(2) + VALUE(2) | ... | KEY(n) + VALUE(n)
* ----------------------------------------------------------------
*
* Here '+' means concatenation.
*
*/
template <typename KeyType, typename ValueType, typename KeyComparator>
class HashTableBlockPage {
public:
// Delete all constructor / destructor to ensure memory safety
HashTableBlockPage() = delete;
KeyType KeyAt(slot_offset_t bucket_ind) const;
ValueType ValueAt(slot_offset_t bucket_ind) const;
bool Insert(slot_offset_t bucket_ind, const KeyType &key, const ValueType &value);
void Remove(slot_offset_t bucket_ind);
bool IsOccupied(slot_offset_t bucket_ind) const;
bool IsReadable(slot_offset_t bucket_ind) const;
private:
bool GetBit(const std::atomic_char *array, slot_offset_t bucket_ind) const;
void SetBit(std::atomic_char *array, slot_offset_t bucket_ind, bool value);
std::atomic_char occupied_[(BLOCK_ARRAY_SIZE - 1) / 8 + 1];
// 0 if tombstone/brand new (never occupied), 1 otherwise.
std::atomic_char readable_[(BLOCK_ARRAY_SIZE - 1) / 8 + 1];
MappingType array_[0];
};
} // namespace bustub
實現程式碼如下:
namespace bustub {
template <typename KeyType, typename ValueType, typename KeyComparator>
KeyType HASH_TABLE_BLOCK_TYPE::KeyAt(slot_offset_t bucket_ind) const {
return array_[bucket_ind].first;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
ValueType HASH_TABLE_BLOCK_TYPE::ValueAt(slot_offset_t bucket_ind) const {
return array_[bucket_ind].second;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BLOCK_TYPE::Insert(slot_offset_t bucket_ind, const KeyType &key, const ValueType &value) {
if (IsReadable(bucket_ind)) {
return false;
}
array_[bucket_ind] = {key, value};
SetBit(readable_, bucket_ind, true);
SetBit(occupied_, bucket_ind, true);
return true;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_BLOCK_TYPE::Remove(slot_offset_t bucket_ind) {
SetBit(readable_, bucket_ind, false);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BLOCK_TYPE::IsOccupied(slot_offset_t bucket_ind) const {
return GetBit(occupied_, bucket_ind);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BLOCK_TYPE::IsReadable(slot_offset_t bucket_ind) const {
return GetBit(readable_, bucket_ind);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BLOCK_TYPE::GetBit(const std::atomic_char *array, slot_offset_t bucket_ind) const {
return array[bucket_ind / 8] & (1 << bucket_ind % 8);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_BLOCK_TYPE::SetBit(std::atomic_char *array, slot_offset_t bucket_ind, bool value) {
if (value) {
array[bucket_ind / 8] |= (1 << bucket_ind % 8);
} else {
array[bucket_ind / 8] &= ~(1 << bucket_ind % 8);
}
}
// DO NOT REMOVE ANYTHING BELOW THIS LINE
template class HashTableBlockPage<int, int, IntComparator>;
template class HashTableBlockPage<GenericKey<4>, RID, GenericComparator<4>>;
template class HashTableBlockPage<GenericKey<8>, RID, GenericComparator<8>>;
template class HashTableBlockPage<GenericKey<16>, RID, GenericComparator<16>>;
template class HashTableBlockPage<GenericKey<32>, RID, GenericComparator<32>>;
template class HashTableBlockPage<GenericKey<64>, RID, GenericComparator<64>>;
} // namespace bustub
雜湊表
宣告
實驗要求我們實現雜湊表的插入、查詢、刪除和調整大小的的操作,對應的類宣告如下,為了完成這些操作,我們多定義了幾個私有的輔助函數和成員變數:
namespace bustub {
#define HASH_TABLE_TYPE LinearProbeHashTable<KeyType, ValueType, KeyComparator>
template <typename KeyType, typename ValueType, typename KeyComparator>
class LinearProbeHashTable : public HashTable<KeyType, ValueType, KeyComparator> {
public:
explicit LinearProbeHashTable(const std::string &name, BufferPoolManager *buffer_pool_manager,
const KeyComparator &comparator, size_t num_buckets, HashFunction<KeyType> hash_fn);
bool Insert(Transaction *transaction, const KeyType &key, const ValueType &value) override;
bool Remove(Transaction *transaction, const KeyType &key, const ValueType &value) override;
bool GetValue(Transaction *transaction, const KeyType &key, std::vector<ValueType> *result) override;
void Resize(size_t initial_size);
size_t GetSize();
private:
using slot_index_t = size_t;
using block_index_t = size_t;
enum class LockType { READ = 0, WRITE = 1 };
/**
* initialize header page and allocate block pages for it
* @param page the hash table header page
*/
void InitHeaderPage(HashTableHeaderPage *page);
/**
* get index according to key
* @param key the key to be hashed
* @return a tuple contains slot index, block page index and bucket index
*/
std::tuple<slot_index_t, block_index_t, slot_offset_t> GetIndex(const KeyType &key);
/**
* linear probe step forward
* @param bucket_index the bucket index
* @param block_index the hash table block page index
* @param header_page hash table header page
* @param raw_block_page raw hash table block page
* @param block_page hash table block page
* @param lock_type lock type of block page
*/
void StepForward(slot_offset_t &bucket_index, block_index_t &block_index, Page *&raw_block_page,
HASH_TABLE_BLOCK_TYPE *&block_page, LockType lockType);
bool InsertImpl(Transaction *transaction, const KeyType &key, const ValueType &value);
inline bool IsMatch(HASH_TABLE_BLOCK_TYPE *block_page, slot_offset_t bucket_index, const KeyType &key,
const ValueType &value) {
return !comparator_(key, block_page->KeyAt(bucket_index)) && value == block_page->ValueAt(bucket_index);
}
inline HashTableHeaderPage *HeaderPageCast(Page *page) {
return reinterpret_cast<HashTableHeaderPage *>(page->GetData());
}
inline HASH_TABLE_BLOCK_TYPE *BlockPageCast(Page *page) {
return reinterpret_cast<HASH_TABLE_BLOCK_TYPE *>(page->GetData());
}
/**
* get the slot number of hash table block page
* @param block_index the index of hash table block page
* @return the slot number of block page
*/
inline size_t GetBlockArraySize(block_index_t block_index){
return block_index < num_pages_ - 1 ? BLOCK_ARRAY_SIZE : last_block_array_size_;
}
// member variable
page_id_t header_page_id_;
BufferPoolManager *buffer_pool_manager_;
KeyComparator comparator_;
std::vector<page_id_t> page_ids_;
size_t num_buckets_;
size_t num_pages_;
size_t last_block_array_size_;
// Readers includes inserts and removes, writer is only resize
ReaderWriterLatch table_latch_;
// Hash function
HashFunction<KeyType> hash_fn_;
};
} // namespace bustub
建構函式
在建構函式中負責根據使用者指定的 num_buckets (也就是 slot 的數量)分配 Page,最後一個 Page 的 slot 數量可能少於前面的 Page。這裡還將每個 HashTableBlockPage 對應的 page_id 儲存到 page_ids_ 成員裡面了,這樣之後就不需要僅僅為了知道某個 HashTableBlockPage 的 page_id 而去找 BufferPoolManager 索要 HashTableHeaderPage。
template <typename KeyType, typename ValueType, typename KeyComparator>
HASH_TABLE_TYPE::LinearProbeHashTable(const std::string &name, BufferPoolManager *buffer_pool_manager,
const KeyComparator &comparator, size_t num_buckets,
HashFunction<KeyType> hash_fn)
: buffer_pool_manager_(buffer_pool_manager),
comparator_(comparator),
num_buckets_(num_buckets),
num_pages_((num_buckets - 1) / BLOCK_ARRAY_SIZE + 1),
last_block_array_size_(num_buckets - (num_pages_ - 1) * BLOCK_ARRAY_SIZE),
hash_fn_(std::move(hash_fn)) {
auto page = buffer_pool_manager->NewPage(&header_page_id_);
page->WLatch();
InitHeaderPage(HeaderPageCast(page));
page->WUnlatch();
buffer_pool_manager_->UnpinPage(header_page_id_, true);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::InitHeaderPage(HashTableHeaderPage *header_page) {
header_page->SetPageId(header_page_id_);
header_page->SetSize(num_buckets_);
page_ids_.clear();
for (size_t i = 0; i < num_pages_; ++i) {
page_id_t page_id;
buffer_pool_manager_->NewPage(&page_id);
buffer_pool_manager_->UnpinPage(page_id, false);
header_page->AddBlockPageId(page_id);
page_ids_.push_back(page_id);
}
}
查詢
雜湊表使用線性探測法進行鍵值對的查詢,由於實驗要求雜湊表支援插入同鍵不同值的鍵值對,所以線上性探測過程中需要將所有相同鍵的值插入 result 向量中:
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_TYPE::GetValue(Transaction *transaction, const KeyType &key, std::vector<ValueType> *result) {
table_latch_.RLock();
// get slot index, block page index and bucket index according to key
auto [slot_index, block_index, bucket_index] = GetIndex(key);
// get block page that contains the key
auto raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
raw_block_page->RLatch();
auto block_page = BlockPageCast(raw_block_page);
// linear probe
while (block_page->IsOccupied(bucket_index)) {
// find the correct position
if (block_page->IsReadable(bucket_index) && !comparator_(key, block_page->KeyAt(bucket_index))) {
result->push_back(block_page->ValueAt(bucket_index));
}
StepForward(bucket_index, block_index, raw_block_page, block_page, LockType::READ);
// break loop if we have returned to original position
if (block_index * BLOCK_ARRAY_SIZE + bucket_index == slot_index) {
break;
}
}
// unlock
raw_block_page->RUnlatch();
buffer_pool_manager_->UnpinPage(raw_block_page->GetPageId(), false);
table_latch_.RUnlock();
return result->size() > 0;
}
GetIndex 函數根據 key 計算出對應的 slot_index、block_index 和 bucket_index(就是 slot offset),結合上圖就能理解該函數的工作原理了:
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::GetIndex(const KeyType &key) -> std::tuple<slot_index_t, block_index_t, slot_offset_t> {
slot_index_t slot_index = hash_fn_.GetHash(key) % num_buckets_;
block_index_t block_index = slot_index / BLOCK_ARRAY_SIZE;
slot_offset_t bucket_index = slot_index % BLOCK_ARRAY_SIZE;
return {slot_index, block_index, bucket_index};
}
線上性探測過程中,我們可能從從一個 HashTableBlockPage 跳到下一個,這時候需要更新 bucket_index 和 block_index:
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::StepForward(slot_offset_t &bucket_index, block_index_t &block_index, Page *&raw_block_page,
HASH_TABLE_BLOCK_TYPE *&block_page, LockType lockType) {
if (++bucket_index != GetBlockArraySize(block_index)) {
return;
}
// move to next block page
if (lockType == LockType::READ) {
raw_block_page->RUnlatch();
} else {
raw_block_page->WUnlatch();
}
buffer_pool_manager_->UnpinPage(page_ids_[block_index], false);
// update index
bucket_index = 0;
block_index = (block_index + 1) % num_pages_;
// update page
raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
if (lockType == LockType::READ) {
raw_block_page->RLatch();
} else {
raw_block_page->WLatch();
}
block_page = BlockPageCast(raw_block_page);
}
插入
實驗要求雜湊表不允許插入已經存在的鍵值對,同時插入過程中如果回到了最初的位置,說明沒有可用的 slot 用於插入鍵值對,這時需要將雜湊表的大小翻倍。由於 Resize 的函數也要用到插入操作,如果直接呼叫 Insert 會出現死鎖,所以這裡使用 InsertImpl 來實現插入:
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_TYPE::Insert(Transaction *transaction, const KeyType &key, const ValueType &value) {
table_latch_.RLock();
auto success = InsertImpl(transaction, key, value);
table_latch_.RUnlock();
return success;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_TYPE::InsertImpl(Transaction *transaction, const KeyType &key, const ValueType &value) {
// get slot index, block page index and bucket index according to key
auto [slot_index, block_index, bucket_index] = GetIndex(key);
// get block page that contains the key
auto raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
raw_block_page->WLatch();
auto block_page = BlockPageCast(raw_block_page);
bool success = true;
while (!block_page->Insert(bucket_index, key, value)) {
// return false if (key, value) pair already exists
if (block_page->IsReadable(bucket_index) && IsMatch(block_page, bucket_index, key, value)) {
success = false;
break;
}
StepForward(bucket_index, block_index, raw_block_page, block_page, LockType::WRITE);
// resize hash table if we have returned to original position
if (block_index * BLOCK_ARRAY_SIZE + bucket_index == slot_index) {
raw_block_page->WUnlatch();
buffer_pool_manager_->UnpinPage(raw_block_page->GetPageId(), false);
Resize(num_pages_);
std::tie(slot_index, block_index, bucket_index) = GetIndex(key);
raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
raw_block_page->WLatch();
block_page = BlockPageCast(raw_block_page);
}
}
raw_block_page->WUnlatch();
buffer_pool_manager_->UnpinPage(raw_block_page->GetPageId(), success);
return success;
}
調整大小
由於實驗假設雜湊表很大,所以我們不能將原本的鍵值對全部儲存到記憶體中,然後調整 HashTableHeaderPage 的大小,複用 HashTableBlockPage 並建立新的 Page,再把鍵值對重新插入。而是應該直接建立新的 HashTableHeaderPage 和 HashTableBlockPage ,並刪除舊的雜湊表頁:
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::Resize(size_t initial_size) {
table_latch_.WLock();
num_buckets_ = 2 * initial_size;
num_pages_ = (num_buckets_ - 1) / BLOCK_ARRAY_SIZE + 1;
last_block_array_size_ = num_buckets_ - (num_pages_ - 1) * BLOCK_ARRAY_SIZE;
// save the old header page id
auto old_header_page_id = header_page_id_;
std::vector<page_id_t> old_page_ids(page_ids_);
// get the new header page
auto raw_header_page = buffer_pool_manager_->NewPage(&header_page_id_);
raw_header_page->WLatch();
InitHeaderPage(HeaderPageCast(raw_header_page));
// move (key, value) pairs to new space
for (size_t block_index = 0; block_index < num_pages_; ++block_index) {
auto old_page_id = old_page_ids[block_index];
auto raw_block_page = buffer_pool_manager_->FetchPage(old_page_id);
raw_block_page->RLatch();
auto block_page = BlockPageCast(raw_block_page);
// move (key, value) pair from each readable slot
for (slot_offset_t bucket_index = 0; bucket_index < GetBlockArraySize(block_index); ++bucket_index) {
if (block_page->IsReadable(bucket_index)) {
InsertImpl(nullptr, block_page->KeyAt(bucket_index), block_page->ValueAt(bucket_index));
}
}
// delete old page
raw_block_page->RUnlatch();
buffer_pool_manager_->UnpinPage(old_page_id, false);
buffer_pool_manager_->DeletePage(old_page_id);
}
raw_header_page->WUnlatch();
buffer_pool_manager_->UnpinPage(header_page_id_, false);
buffer_pool_manager_->DeletePage(old_header_page_id);
table_latch_.WUnlock();
}
刪除
刪除操作和查詢操作很像,不過是將找到的 slot 標上墓碑罷了:
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_TYPE::Remove(Transaction *transaction, const KeyType &key, const ValueType &value) {
table_latch_.RLock();
// get slot index, block page index and bucket index according to key
auto [slot_index, block_index, bucket_index] = GetIndex(key);
// get block page that contains the key
auto raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
raw_block_page->WLatch();
auto block_page = BlockPageCast(raw_block_page);
bool success = false;
while (block_page->IsOccupied(bucket_index)) {
// remove the (key, value) pair if find the matched readable one
if (IsMatch(block_page, bucket_index, key, value)) {
if (block_page->IsReadable(bucket_index)) {
block_page->Remove(bucket_index);
success = true;
} else {
success = false;
}
break;
}
// step forward
StepForward(bucket_index, block_index, raw_block_page, block_page, LockType::WRITE);
// break loop if we have returned to original position
if (block_index * BLOCK_ARRAY_SIZE + bucket_index == slot_index) {
break;
}
}
raw_block_page->WUnlatch();
buffer_pool_manager_->UnpinPage(raw_block_page->GetPageId(), success);
table_latch_.RUnlock();
return success;
}
獲取大小
最後是獲取雜湊表的大小操作,直接返回 num_buckets_ 就行了:
template <typename KeyType, typename ValueType, typename KeyComparator>
size_t HASH_TABLE_TYPE::GetSize() {
return num_buckets_;
}
測試
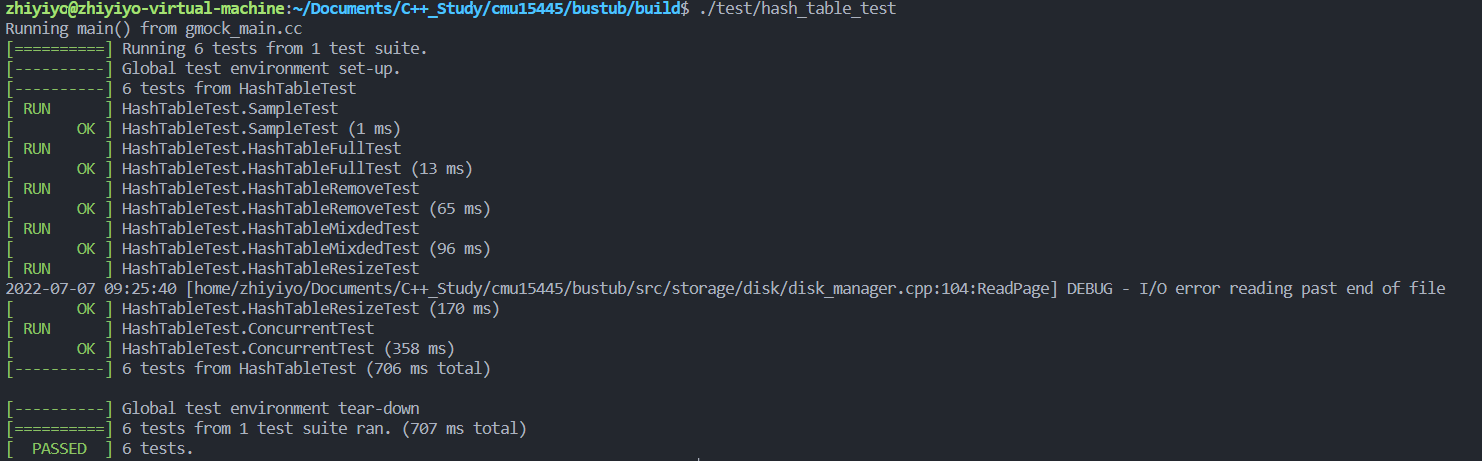
對雜湊表的測試結果如下,6 個測試全部通過了:
總結
該實驗主要考察對線性探測雜湊表、緩衝池管理器和讀寫鎖的理解,難度相比上一個實驗略有提升,但是理解了雜湊表的結構圖之後應該就不難完成該實驗了,以上~~