深入理解Apache Hudi非同步索引機制
在我們之前的文章中,我們討論了多模式索引的設計,這是一種用於Lakehouse架構的無伺服器和高效能索引子系統,以提高查詢和寫入效能。在這篇部落格中,我們討論了構建如此強大的索引所需的機制,非同步索引機制的設計,類似於 PostgreSQL 和 MySQL 等流行的資料庫系統,它支援索引構建而不會阻塞寫入。
背景
Apache Hudi 將事務和更新/刪除/更改流新增到彈性雲端儲存和開放檔案格式之上的表中。 Hudi 內部的一個關鍵元件是事務資料庫核心,它協調對 Hudi 表的讀取和寫入。索引是該核心的最新子系統。所有索引都儲存在內部 Hudi Merge-On-Read (MOR) 表中,即後設資料表在事務上與資料表保持同步,即使在出現故障時也是如此。後設資料表也被構建為由 Hudi 的表服務自行管理,就像資料表一樣。
動機
而Hudi目前支援三種索引;檔案、column_stats 和bloom_filter,巨量資料的數量和種類使得新增更多索引以進一步降低I/O 成本和查詢延遲勢在必行。建立新索引的一種方法是停止所有寫入程式,然後在後設資料表內建立一個新的索引分割區,然後恢復寫入程式。隨著我們新增更多索引,這可能並不理想,因為,a)它需要停機,b)它不會隨著更多索引而擴充套件。因此,需要在與寫入並行的表上動態新增和刪除索引。非同步索引有兩個好處,改進寫入延遲和解耦故障。對於那些熟悉資料庫系統中的「CREATE INDEX」的人來說會了解建立索引是多麼容易,而不用擔心持續的寫入。將非同步索引新增到 Hudi 豐富的表服務集是嘗試為 Lakehouse 帶來類似資料庫的易用性、可靠性和效能。
設計
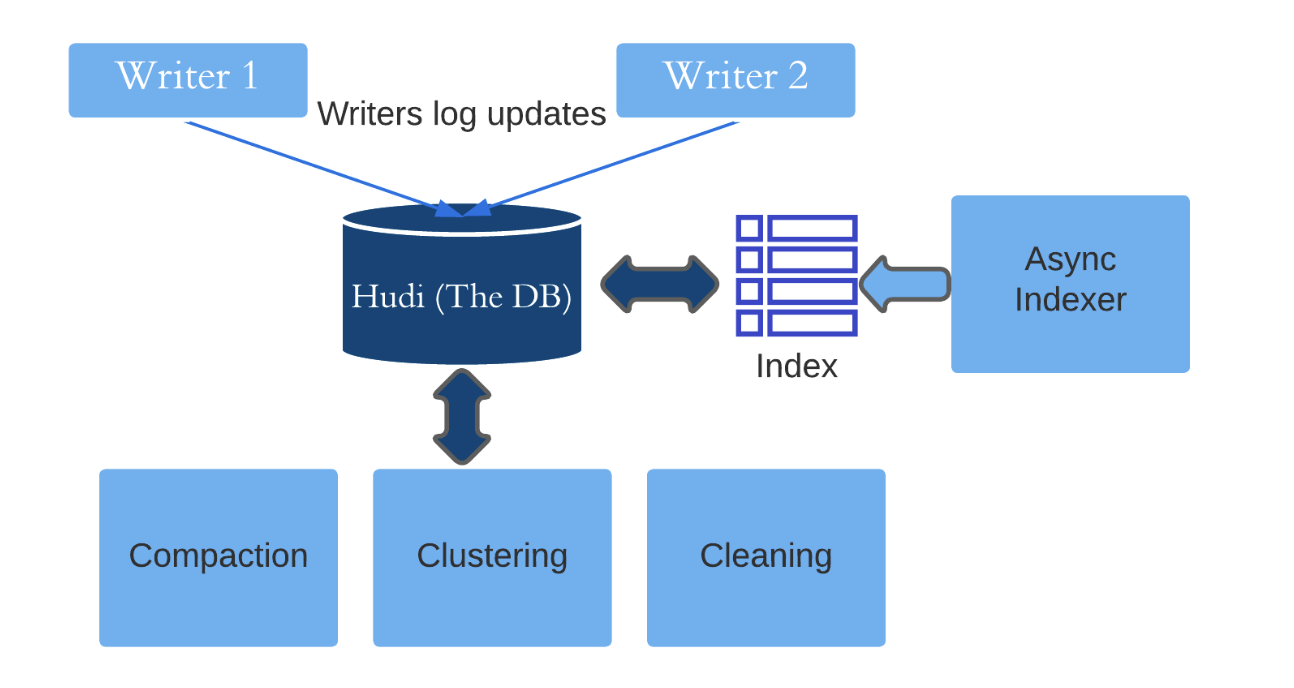
與正在進行的寫入進行非同步索引的核心是確保這些寫入可以對索引執行一致的更新,即使歷史資料正在後臺被索引。處理這個問題的一種方法是完全鎖定索引分割區,直到歷史資料被索引然後趕上。然而,衝突的可能性只會隨著長時間執行的事務的鎖定而增加。這個問題的解決依賴於 Hudi 事務核心設計的三個支柱:
Hudi 檔案佈局
Hudi 表中的資料檔案被組織成檔案組,其中每個檔案組包含多個檔案切片。每個切片都包含一個在特定提交時生成的基本檔案,以及一組包含對基本檔案的更新的紀錄檔檔案。這使得我們將在下一節中看到細粒度的並行控制成為可能。初始化檔案組並寫入基本檔案後,另一個寫入器可以記錄對同一檔案組的更新,並且將建立一個新切片。
混合並行控制
非同步索引混合使用樂觀並行控制和基於紀錄檔的並行控制模型。索引分為兩個階段:排程和執行。
在排程過程中,索引器(負責建立新索引的外部程序)獲取一個短鎖,併為資料檔案生成一個索引計劃,直到最後一個提交時刻 t。它初始化與請求的索引對應的後設資料分割區,並在此階段完成後釋放鎖。這應該需要幾秒鐘,並且在此階段不會寫入任何索引檔案。
在執行期間,索引器執行計劃,將索引基礎檔案(對應於直到瞬間 t 的資料檔案)寫入後設資料分割區。同時,常規的正在進行的寫入繼續將更新記錄到與後設資料分割區中的基本檔案相同的檔案組中的紀錄檔檔案。編寫基本檔案後,索引器會檢查 t 之後的所有已完成提交instant,以確保它們中的每一個都根據其索引計劃新增條目,否則只是優雅地中止。這是當樂觀並行控制啟動時,使用後設資料表鎖來檢查寫入者是否影響了重疊檔案,如果存在衝突,則中止,優雅中止確保可以以冪等方式重試索引。
Hudi時間線
Hudi 維護了在不同時刻在表上執行的所有操作的時間表。將其視為事件紀錄檔,作為程序間協調的核心部分。 Hudi 在時間軸上實現了細粒度的基於紀錄檔的並行協定。為了將索引與其他寫入操作區分開來,我們在此時間線上引入了一個名為「索引」的新操作。此操作的狀態轉換由索引器處理。排程索引會在時間線中新增一個「indexing.requested」 instant。執行階段在執行計劃時將其轉換為「inflight」狀態,然後在索引完成後最終轉換為「completed」狀態。索引器僅在向時間線新增事件時鎖定,而不是在寫入索引檔案時鎖定。
這種設計的優點如下:
- 資料寫入和索引是分離的,但它們彼此瞭解。
- 它可以擴充套件到其他型別的索引。
- 它適用於批次處理和流式工作負載。
使用時間線作為事件紀錄檔,兩種並行模型的混合提供了出色的可延伸性和非同步性,以便索引過程與寫入器與其他表服務(如compaction和clustering)同時執行。
檔案
有關索引器的設計和實現的更多詳細資訊,請檢視 RFC-45。要設定並檢視執行中的索引器,請遵循非同步索引指南。
未來的工作
非同步索引功能是 Lakehouse 架構中的首創,仍在不斷髮展。雖然可以與寫入器同時建立索引,但刪除索引需要表級鎖定,因為表通常會被其他讀取器/寫入器執行緒使用。因此,一項工作是通過延遲刪除索引並增加非同步量來克服當前的限制,以便可以同時建立或刪除多個索引。另一項工作是增強索引器的可用性;與 SQL 和其他型別的索引整合,例如二級鍵的Bloom索引,基於Lucene的二級索引(RFC-52)等。我們歡迎社群更多的想法和貢獻。
結論
Hudi 的多模式索引和非同步索引功能表明,事務資料湖不僅僅是表格格式和後設資料。分散式儲存系統的基本原理也適用於 Lakehouse 架構,並且挑戰出現在不同的規模上。這種規模的非同步索引很快就會成為必需品。我們討論了一種可延伸到其他索引型別、可延伸和非阻塞的設計,並將繼續在此框架的基礎上為索引子系統新增更多功能。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

