pyflink的安裝和測試
pyflink安裝
安裝前提:python3.6-3.8
參考:Installation | Apache Flink
Python version (3.6, 3.7 or 3.8) is required for PyFlink. Please run the following command to make sure that it meets the requirements:
$ python --version
# the version printed here must be 3.6, 3.7 or 3.8
這裡你可以安裝python3或者Anaconda3,最後通過python -V命令檢視版本資訊
兩種安裝方式:
本次安裝基於flink1.13.2版本
- 如果你有網路:可以直接通過命令安裝
python -m pip install apache-flink==1.13.2
- 原始碼編譯方式
In addition you need Maven 3 and a JDK (Java Development Kit). Flink requires at least Java 8 to build.
maven選擇3.2.5版本,java選擇高一點的java8版本
參考:Building Flink from Source | Apache Flink
下載原始碼:(這裡我從其他網址下載的1.13.2的原始碼)
git clone https://github.com/apache/flink.git
編譯:編譯的過程中可能會報錯,具體解決就好
mvn clean install -DskipTests
#To speed up the build you can skip tests, QA plugins, and JavaDocs:
或者:mvn clean install -DskipTests -Dfast
編譯完成後開始處理pyflink的事情
安裝gcc【可選】
yum install -y gcc gcc-c++
安裝依賴(flink-python目錄在flink編譯目錄下面)
python -m pip install -r flink-python/dev/dev-requirements.txt
然後轉到 flink 原始碼的根目錄並執行此命令來構建 和 的 sdist 包和 wheel 包:apache-flink,apache-flink-libraries的 sdist 包可以在 下找到。它可以按如下方式安裝:apache-flink-libraries``./flink-python/apache-flink-libraries/dist/
cd flink-python; python setup.py sdist bdist_wheel; cd apache-flink-libraries; python setup.py sdist; cd ..;
如果是公司內網,這裡需要設定pip源,安裝的時候有依賴,因為我編譯的時候使用的是虛擬機器器,可以上網的
python -m pip install apache-flink-libraries/dist/*.tar.gz
python -m pip install dist/*.tar.gz
通過pip list | grep flink命令檢視安裝效果

測試
Local-SingleJVM 模式部署
該模式多用於開發測試階段,簡單的利用 Python pyflink_job.py 命令,PyFlink 就會預設啟動一個 Local-SingleJVM 的 Flink 環境來執行作業,如下:
寫一個指令碼:wordcount.py
from pyflink.table import DataTypes, TableEnvironment, EnvironmentSettings
from pyflink.table.descriptors import Schema, OldCsv, FileSystem
from pyflink.table.expressions import lit
settings = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build()
t_env = TableEnvironment.create(settings)
# write all the data to one file
t_env.get_config().get_configuration().set_string("parallelism.default", "1")
t_env.connect(FileSystem().path('/tmp/input')) \
.with_format(OldCsv().field('word', DataTypes.STRING())) \
.with_schema(Schema().field('word', DataTypes.STRING())) \
.create_temporary_table('mySource')
t_env.connect(FileSystem().path('/tmp/output')) \
.with_format(OldCsv().field_delimiter('\t') \
.field('word', DataTypes.STRING()) \
.field('count', DataTypes.BIGINT())) \
.with_schema(Schema() \
.field('word', DataTypes.STRING()) \
.field('count', DataTypes.BIGINT())) \
.create_temporary_table('mySink')
tab = t_env.from_path('mySource')
tab.group_by(tab.word).select(tab.word, lit(1).count).execute_insert('mySink').wait()
在shell 命令列執行:
echo -e "flink\npyflink\nflink" > /tmp/input
python wordcount.py
cat /tmp/output

Local-SingleNode 模式部署
這種模式一般用在單機環境中進行部署,如 IoT 裝置中,我們從 0 開始進行該模式的部署操作。我們進入到 flink/build-target 目錄,執行如下命令:
cd /root/flink-1.13.2/build-target/bin/
./start-cluster.sh

登陸http://ip:8081檢視
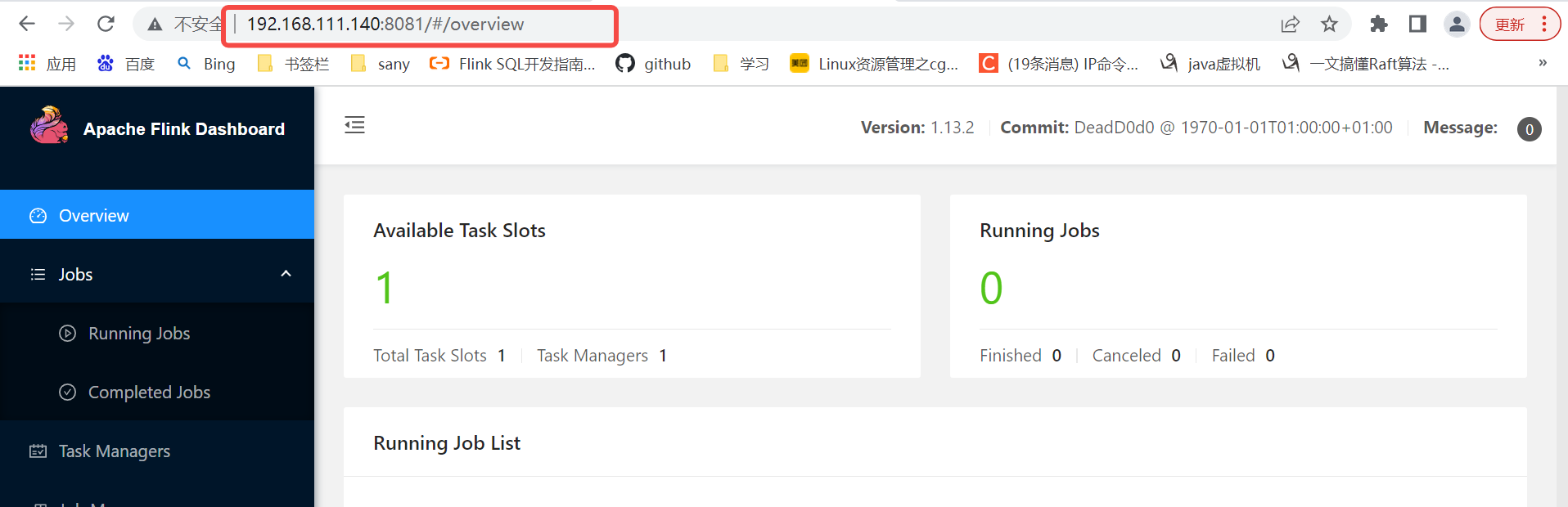
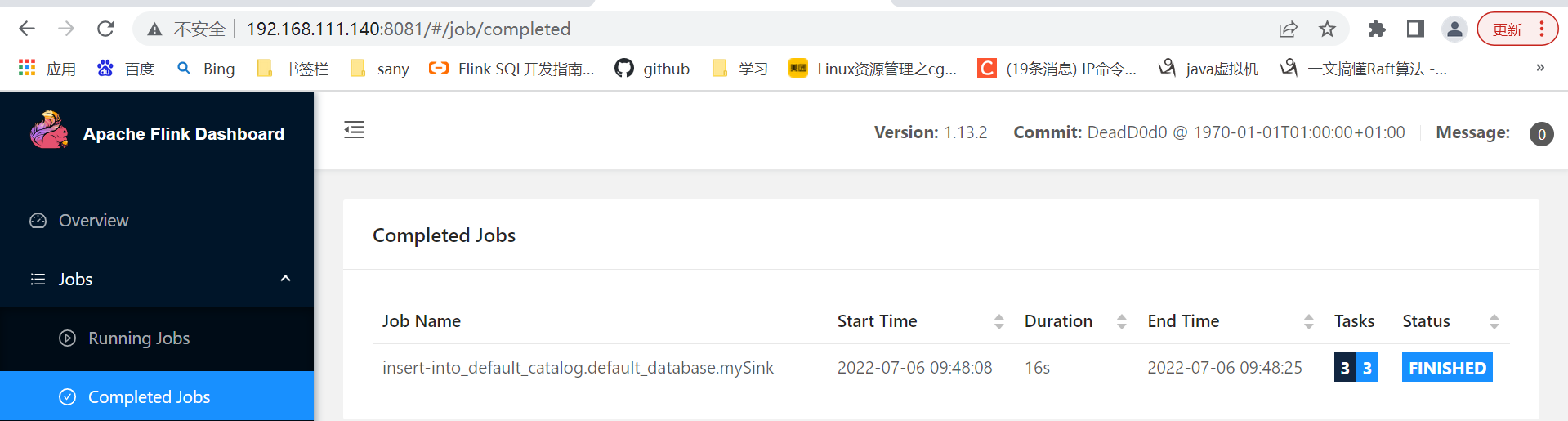
提交作業:
/root/flink-1.13.2/build-target/bin/flink run -m localhost:8081 -py /root/wordcount.py

出處:https://www.cnblogs.com/zsql/
如果您覺得閱讀本文對您有幫助,請點選一下右下方的推薦按鈕,您的推薦將是我寫作的最大動力!
版權宣告:本文為博主原創或轉載文章,歡迎轉載,但轉載文章之後必須在文章頁面明顯位置註明出處,否則保留追究法律責任的權利。