模擬HashMap衝突
2022-07-06 12:05:41
最近看HashMap的原始碼,其中相同下標容易產生hash衝突,但是偵錯需要發生hash衝突,本文模擬hash衝突。
hash衝突原理
HashMap衝突是key首先呼叫hash()方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
然後使用hash值和tab陣列長度做與操作:
(n - 1) & hash
算出來的下標,如果一致就會產生衝突。
通過ASKII碼獲取單個字元
開始想到單字元,比如a、b、c、d、e這類字元,但是如果一個一個試的話特別繁瑣,想到了ASKII碼:
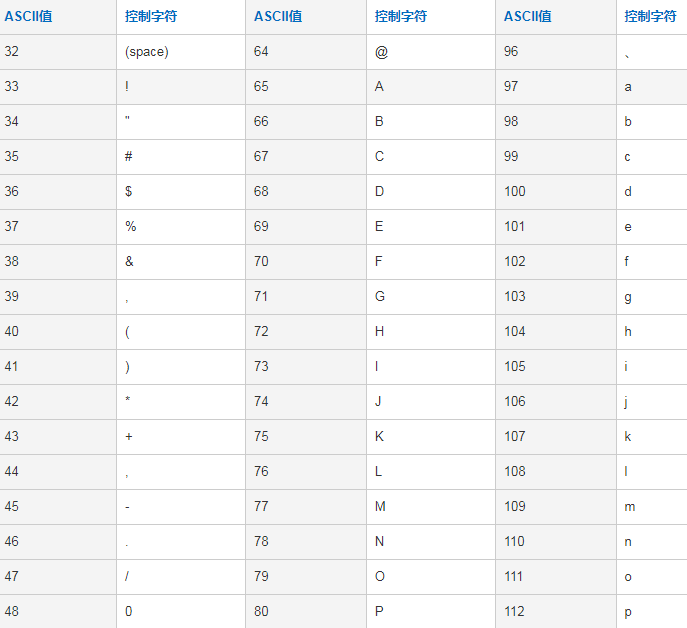
遍歷1~100的ASKII碼。通過ASKII碼獲取單字元:
for (int i = 33; i < 100; i++) {
char ch = (char) i;
String str = String.valueOf(ch);
}
通過str獲取下標,HashMap預設長度為16,所以n-1為15:
int index = 15 & hash(str);
獲取發生hash衝突的字元
算出index一致的話,就放在一個列表中。不同的index放在HashMap中,完整程式碼如下:
Map<Integer, List<String>> param = new HashMap<>();
for (int i = 33; i < 100; i++) {
char ch = (char) i;
String str = String.valueOf(ch);
int index = 15 & hash(str);
List<String> list = param.get(index);
if (list == null) {
list = new ArrayList<>();
}
list.add(str);
param.put(index,list);
}
param.forEach((k,v) -> System.out.println(k + " " + Arrays.toString(v.toArray())));
輸出結果:
0 [0, @, P, `]
1 [!, 1, A, Q, a]
2 [", 2, B, R, b]
3 [#, 3, C, S, c]
4 [$, 4, D, T]
5 [%, 5, E, U]
6 [&, 6, F, V]
7 [', 7, G, W]
8 [(, 8, H, X]
9 [), 9, I, Y]
原始碼偵錯
根據上面算出來的結果,使用其中的一個例子:
1 [!, 1, A, Q, a]
先新增資料:
Map<String,Integer> map = new HashMap<>();
map.put("!",1);
map.put("1",1);
map.put("A",1);
先新增1, A, Q三個資料。然後新增Q。
開啟調式,定位到putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
在原始碼解析文章詳解HashMap原始碼解析(下)中知道,發生hash衝突是會在上面程式碼的第16行,一直for迴圈遍歷連結串列,替換相同的key或者在連結串列中新增資料:
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
調式:
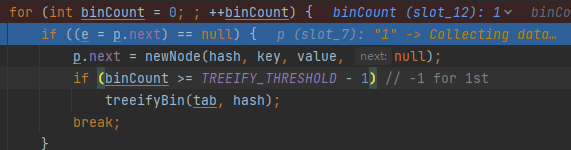
會一直遍歷for迴圈,直到p.next==null遍歷到鏈尾,然後在連結串列尾部新增節點資料:
p.next = newNode(hash, key, value, null);
總結
- 通過
(h = key.hashCode()) ^ (h >>> 16)高位運算hash碼和(n - 1) & hash雜湊表陣列長度取模,分析hash衝突原理。 - 通過
ASKII碼遍歷獲取字串,獲取發生hash衝突的字元。 - 呼叫
put方法,呼叫hash衝突原始碼。