爬蟲(14)
1.什麼是Scrapy-Redis
- Scrapy-Redis是scrapy框架基於redis的分散式元件,是scrapy的擴充套件;分散式爬蟲將多臺主機組合起來,共同完成一個爬取任務,快速高效地提高爬取效率。
- 原先scrapy的請求是放在記憶體中,從記憶體中獲取。scrapy-redisr將請求統一放在redis裡面,各個主機檢視請求是否爬取過,沒有爬取過,排隊入佇列,主機取出來爬取。爬過了就看下一條請求。
- 各主機的spiders將最後解析的資料通過管道統一寫入到redis中
- 優點:加快專案的執行速度;單個節點的不穩定性不影響整個系統的穩定性;支援端點爬取
- 缺點:需要投入大量的硬體資源,硬體、網路頻寬等
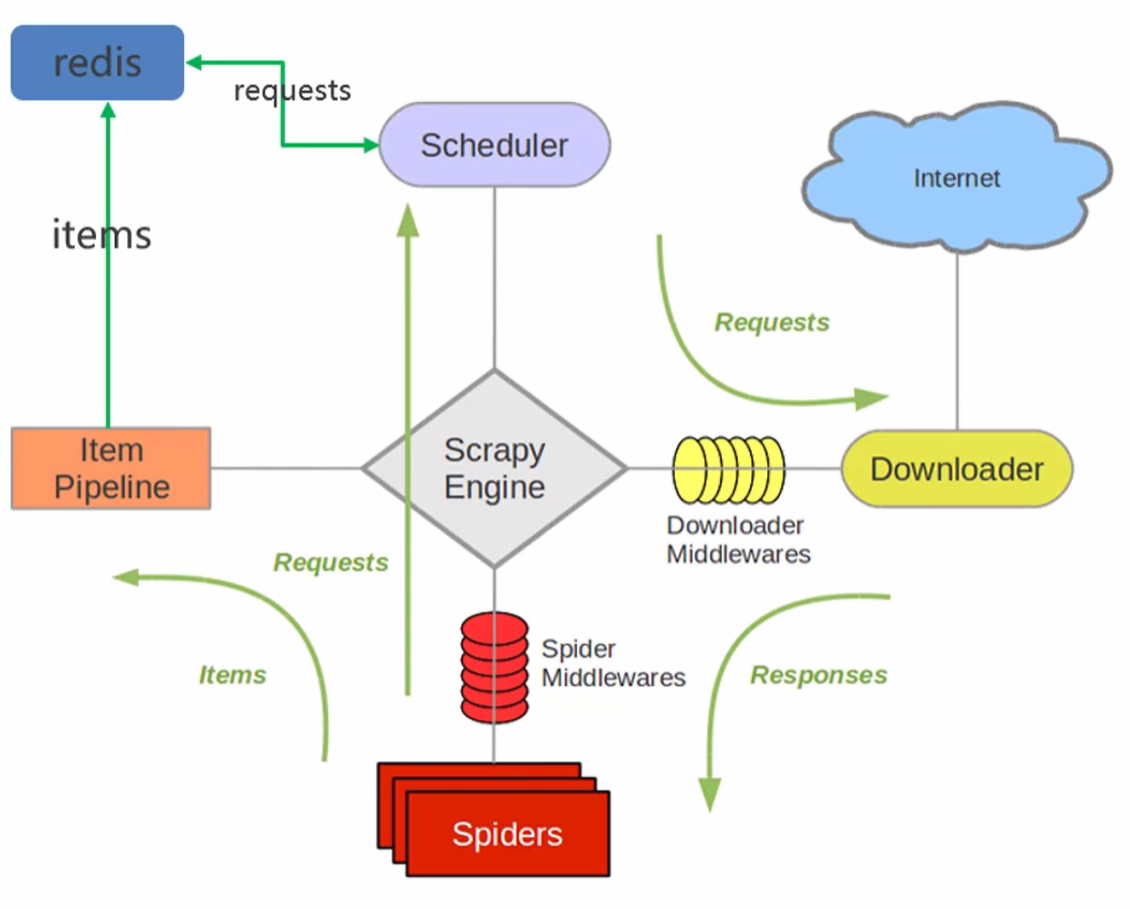
- 在scrapy框架流程的基礎上,把儲存request物件放到了redis的有序集合中,利用該有序集合實現了請求佇列
- 並對request物件生成指紋物件,也儲存到同一redis的集合中,利用request指紋避免傳送重複的請求
2.Scrapy-Redis分散式策略
假設有三臺電腦:Windows 10、Ubuntu 16.04、Windows 10,任意一臺電腦都可以作為 Master端 或 Slaver端,比如:
- Master端(核心伺服器) :使用 Windows 10,搭建一個Redis資料庫,不負責爬取,只負責url指紋判重、Request的分配,以及資料的儲存。
- Slaver端(爬蟲程式執行端) :使用 Ubuntu 16.04、Windows 10,負責執行爬蟲程式,執行過程中提交新的Request給Master。
首先Slaver端從Master端拿任務(Request、url)進行資料抓取,Slaver抓取資料的同時,產生新任務的Request便提交給 Master 處理
Master端只有一個Redis資料庫,負責將未處理的Request去重和任務分配,將處理後的Request加入待爬佇列,並且儲存爬取的資料。
Scrapy-Redis預設使用的就是這種策略,我們實現起來很簡單,因為任務排程等工作Scrapy-Redis都已經幫我們做好了,我們只需要繼承RedisSpider、指定redis_key就行了。
缺點是,Scrapy-Redis排程的任務是Request物件,裡面資訊量比較大(不僅包含url,還有callback函數、headers等資訊),可能導致的結果就是會降低爬蟲速度、而且會佔用Redis大量的儲存空間,所以如果要保證效率,那麼就需要一定硬體水平。
3.Scrapy-Redis的安裝和專案建立
3.1.安裝scrapy-redis
pip install scrapy-redis
3.2.專案建立前置準備
- win 10
- Redis安裝:redis相關設定參照這個https://www.cnblogs.com/gltou/p/16226721.html;如果跟著筆記學到這的,前面連結那個redis版本3.0太老了,需要重新安裝新版本,新版本下載連結:https://pan.baidu.com/s/1UwhJA1QxDDIi2wZFFIZwow?pwd=thak,提取碼:thak;
- Another Redis Desktop Manager:這個軟體是用於檢視redis中儲存的資料,安裝也很簡單,一直下一步即可;下載連結:https://pan.baidu.com/s/18CC2N6XtPn_2NEl7gCgViA?pwd=ju81 提取碼:ju81
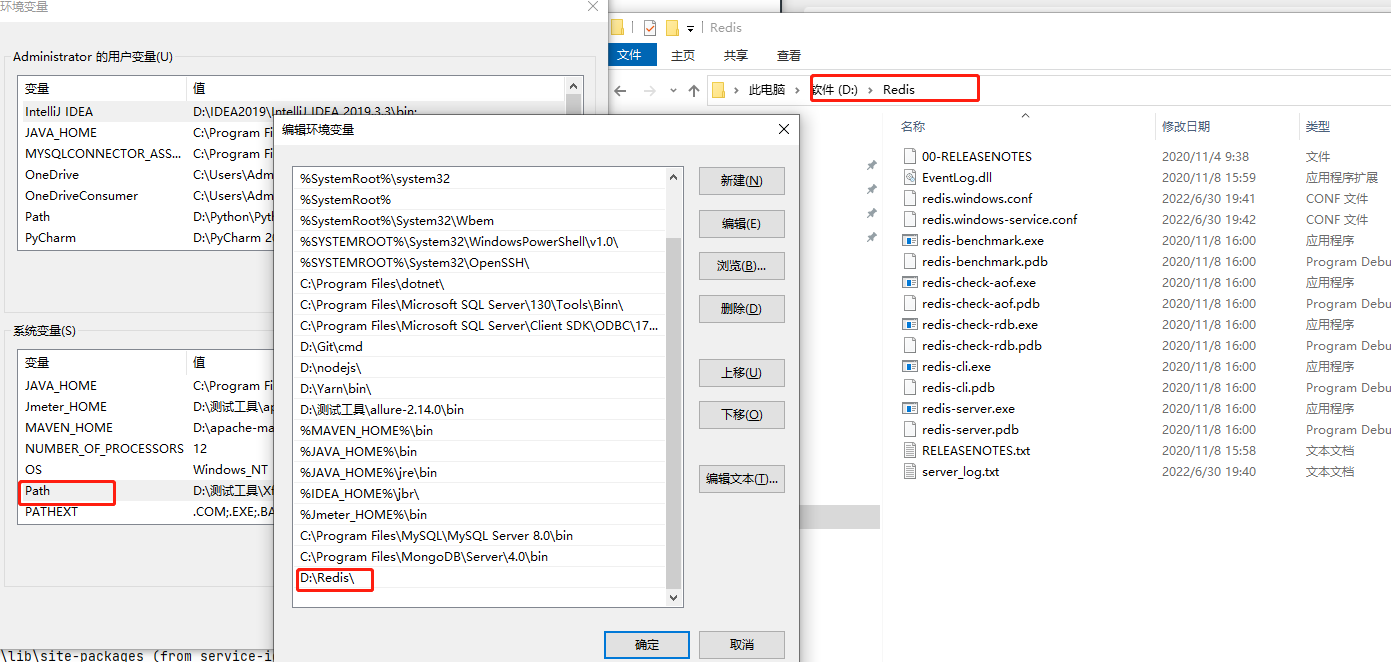
Redia安裝簡單講解:安裝包下載下來後,點選下一步一直安裝就行,把安裝路徑記錄好;注意安裝好後需要將redis的安裝目錄新增到環境變數中;每當你修改了組態檔,需要重啟redis時,要記得將服務重啟下
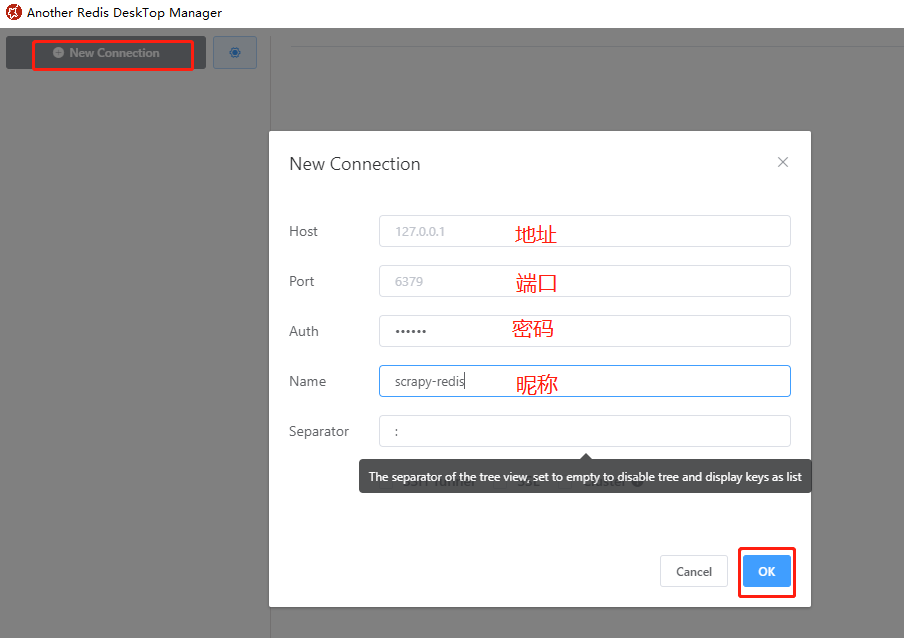
Another Redis Desktop Manager簡單講解:點選【New Connection】新增redis連線,連線內容如下(地址、埠等),密碼Auth和暱稱Name不是必填。
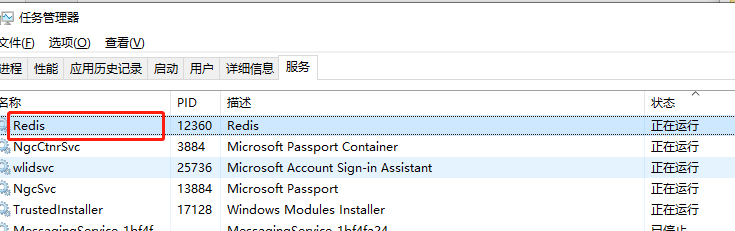
可以看到redis安裝的環境、當前redis的版本、記憶體、連線數等資訊。後面我們的筆記會講解通過該軟體檢視待抓取的URL以及URL的指紋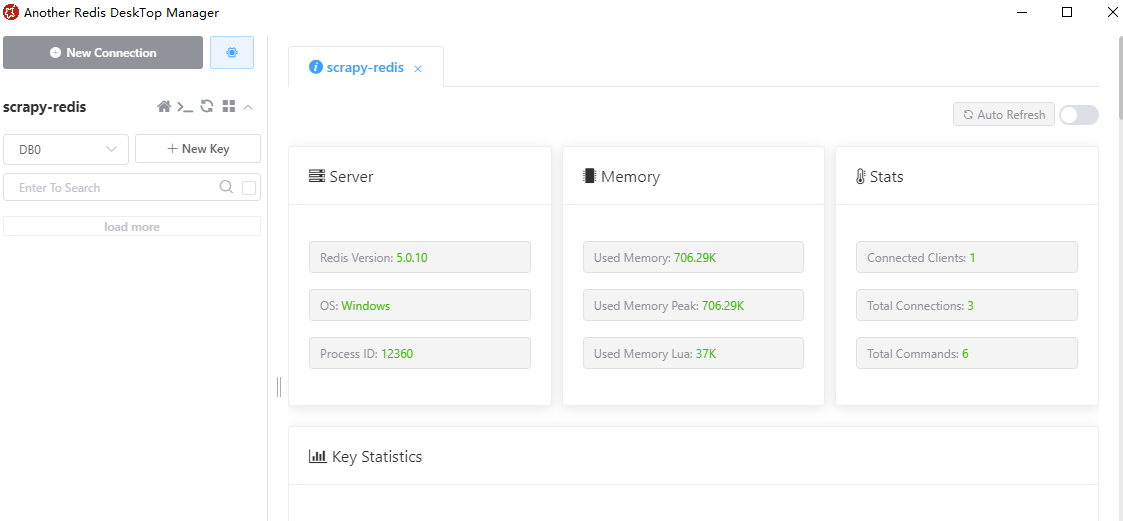
3.3.專案建立
建立普通scrapy爬蟲專案,在普通的專案上改造成scrapy-redis專案;普通爬蟲分為四個階段:建立專案、明確目標、建立爬蟲、儲存內容;
scrapy爬蟲專案建立好後,進行改造,具體改造點如下:
- 匯入scrapy-redis中的分散式爬蟲類
- 繼承類
- 註釋start_url & allowed_domains
- 設定redis_key獲取start_urls
- 編輯settings檔案
3.3.1.建立scrapy爬蟲
step-1:建立專案
建立scrapy_redis_demo目錄,在該目錄下輸入命令 scrapy startproject movie_test ,生成scrapy專案