Django資料庫效能優化之
前言
最近有個新需求:
- 人員基礎資訊(記作人員A),10w
- 某種型別的人員資訊(記作人員B),1000
要求在後臺上(Django Admin)分別展示:已錄入A的人員B列表、未錄入的人員B列表
團隊的DBA提議使用檢視可以解決這個問題(不愧是搞資料庫的)
PS:起先我覺得Django的Model是直接管理資料庫表的,使用Model來對映資料庫模型怕是有一定的麻煩,不過查了一下資料發現並不會~
只需要在Model的Meta子類中新增
managed = False即可,同時將db_table屬性設定為檢視名稱
但這專案是Django寫的,我認為既然有這麼好用的ORM,何必多此一舉去用SQL實現功能邏輯呢
於是大手一揮,不行,咱用Python來搞!
粗略實現
想想有挺多種方式來實現的,可以在Model中加一個方法,例如is_in_a(),然後在裡面判斷該人員B是否在人員A中
也可以在admin的設定中增加一個欄位~
最終我是在Model中增加了新的方法,當然思路不必侷限,Django還是很靈活的。
這個方法大概寫成這樣
def is_in_a(self) -> bool:
from apps.people.models import PersonA
queryset = PersonA.objects.filter(id_number=self.id_number)
return queryset.exists()
is_in_a.short_description = '是否已錄入'
is_in_a.boolean = True
OK,沒啥問題,接著設定一下admin
@admin.register(PersonB)
class PersonBAdmin(admin.ModelAdmin):
list_display = ['name', 'id_number', 'is_in_a']
這樣就可以在後臺上正常展示了,is_in_a就和普通的model欄位一樣使用
不過如果要加一個篩選功能的話,就不行,admin預設的list_filter只能支援資料庫欄位
要把我們自定義的欄位加入篩選,就只能自己寫一個Filter
首先來看一個錯誤的示範
class IsInAFilter(admin.SimpleListFilter):
title = '是否已錄入'
parameter_name = 'is_in_a'
def lookups(self, request, model_admin):
return (
('true', '已錄入'),
('false', '未錄入')
)
def queryset(self, request, queryset):
raw_ids = []
if self.value() == 'true':
for item in queryset:
if item.is_in_a():
raw_ids.append(item.pk)
if self.value() == 'false':
for item in queryset:
if not item.is_in_a():
raw_ids.append(item.pk)
return queryset if self.value() is None else queryset.filter(pk__in=raw_ids)
寫完了在admin的filter設定寫上就行
list_filter = [IsInAFilter]
實現是實現了,但篩選的時候速度奇慢,因為渲染列表的時候,每一項都要存取一次資料庫(恕我直言,這種程式碼就是shit)
PS:很遺憾,這程式碼是從我前年寫的一個專案裡copy過來的(逃
優化思路
這我肯定不能忍啊
最討厭的就是有人寫了屎山程式碼
更何況這是自己寫的shit,更不能忍了
立刻開始著手優化程式碼!
冷靜下來,稍加思索
這個東西慢在於列表中的每一項都要去判斷id_number在不在人員A中,那我改成批次判斷不就好了?
一想到批次,我就想到values_list,用它來生成倆id_number的列表,既然有倆列表了,那這不就是集合操作了?
完事,開搞!
集合
首先複習一下集合哈
這應該是高中數學知識
集合,就是將數個物件歸類而分成為一個或數個形態各異的大小整體。 一般來講,集合是具有某種特性的事物的整體,或是一些確認物件的彙集。構成集合的事物或物件稱作「元素」或「成員」。集合的元素可以是任何事物,可以是人,可以是物,也可以是字母或數位等。
集合的三大特性
無序性:一個集合中,每個元素的地位都是相同的,元素之間是無序的。
- 集合上可以定義序關係,定義了序關係後,元素之間就可以按照序關係排序。但就集合本身的特性而言,元素之間沒有必然的序。(參見序理論)
互異性:一個集合中,任何兩個元素都認為是不相同的,即每個元素只能出現一次。
- 有時需要對同一元素出現多次的情形進行刻畫,可以使用多重集,其中的元素允許出現多次。
確定性:給定一個集合,任給一個元素,該元素或者屬於或者不屬於該集合,二者必居其一,不允許有模稜兩可的情況出現。
數學概念不用深究,程式語言中的集合與數學的集合也有些許不同,不過互異性是都有的,也就是集合中沒有重複的元素。
集合操作
為了實現前文提到的效能優化,這裡我們只需要掌握集合的幾種運算就行
設a、b是兩個不同的集合
a = set([1, 2, 3, 4])
b = set([3, 4, 5, 6])
四種操作直接看錶格
| 計算 | 程式碼 | 說明 |
|---|---|---|
| 差集 | a - b |
集合a中包含而集合b中不包含的元素 |
| 並集 | `a | b` |
| 交集 | a & b |
集合a和b中都包含了的元素 |
| 對稱差集 | a ^ b |
不同時包含於a和b的元素 |
為了便於理解,再來畫個圖
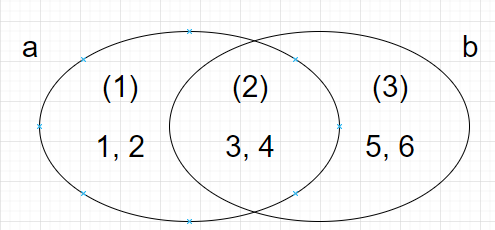
| 操作 | 結果 | 所得新集合元素 |
|---|---|---|
a - b |
(1) | {1, 2} |
| `a | b` | (1) + (2) + (3) |
a & b |
(2) | {3, 4} |
a ^ b |
(1) + (3) | {1, 2, 5, 6} |
這下就很清楚了吧~
所以上面那個問題,簡化成集合操作就是分別取交集和差集
最終實現
最終實現的程式碼不僅效能高起來了,程式碼量也比原來少,簡直完美
def queryset(self, request, queryset):
from apps.people.models import PersonA
# 使用集合操作提高效能
set1 = set(PersonA.objects.values_list('id_number', flat=True))
set2 = set(queryset.values_list('id_number', flat=True))
id_numbers = set()
# 選擇已錄入的,取交集
if self.value() == 'true':
id_numbers = set1 & set2
# 選擇未錄入的,取差集
elif self.value() == 'false':
id_numbers = set2 - set1
return queryset if self.value() is None else queryset.filter(id_number__in=id_numbers)
搞定~!
等等
最後推薦一下我查資料過程中發現的好東西
Django ORM Cookbook
中文版地址:https://django-orm-cookbook-zh-cn.readthedocs.io/zh_CN/latest/index.html
這是一本書,顧名思義教你使用DjangoORM的,裡面有50個例子,感覺挺不錯的,可以查缺補漏~
Intermediate Python
中文版地址:https://eastlakeside.gitbook.io/interpy-zh/
也是一本書,中文名「Python進階」,所以你應該知道里面講啥了吧~
參考資料
- 集合 (數學) - 維基百科:https://zh.m.wikipedia.org/zh/集合_(數學)
- python set集合運算(交集,並集,差集,對稱差集):https://blog.csdn.net/sxingming/article/details/51922776
- Python集合(Set)常用操作:https://www.jianshu.com/p/f60fabfefc09
- https://www.runoob.com/python3/python3-set.html