強化學習-學習筆記4 | Actor-Critic
Actor-Critic 是價值學習和策略學習的結合。Actor 是策略網路,用來控制agent運動,可以看做是運動員。Critic 是價值網路,用來給動作打分,像是裁判。
4. Actor-Critic
4.1 價值網路與策略網路構建
a. 原理介紹
狀態價值函數:
$ V_\pi(s)=\sum_{{a}}\pi({a}|{s})\cdot Q_\pi({s},{a})$ (離散情況,如果是連續的需要換成定積分)
V 是動作價值函數 \(Q_\pi\) 的期望,\(\pi({s}|{a})\) 策略函數控制 agent 做運動,\(Q_\pi({s},{a})\) 價值函數評價動作好壞。但是上述這兩個函數我們都不知道,但是可以分別用一個神經網路來近似這兩個函數,然後用Actor-Critic方法來同時學習這兩個網路。
策略網路(actor):用網路 \(\pi({s}|{a};\theta)\) 來近似 \(\pi({s}|{a})\),\(\theta\) 是網路引數
價值網路(critic):用網路 \(q({s},{a};w)\) 來近似 \(Q_\pi({s},{a})\),\(w\) 是網路引數
actor 是一個體操運動員,可以自己做動作,而 agent 想要做的更好,但是不知道怎麼改進,這就需要裁判給她打分,這樣運動員就知道什麼樣動作的分數高,什麼樣動作的分數低,這樣就能改進自己,讓分數越來越高。
這樣:$ V_\pi({s})=\sum_{{a}}\pi({a}|{s})\cdot Q_\pi({s},{a})\approx\sum_a\pi(a|s;\theta)\cdot q(s,a;w)$$
b. Actor 搭建
策略網路。
- 輸入:狀態 s
- 輸出:可能的動作概率分佈
- \(\mathcal{A}\) 是動作集,如\(\mathcal{A}\) ={ "left","right","up"}
- \(\sum_{a\in\mathcal{A}}\pi(a|s,\theta)=1\)

折積層 Conv 把 state 變成 一個特徵向量 feature ,用一個或多個全連線層 Dense 把特徵向量 對映為紫色,歸一化處理後得到每個動作的概率。
c. Critic搭建
輸入:有兩個,狀態 s 和動作 a
輸出:近似的動作價值函數(scalar)

如果 動作 是離散的,可以用 one-hot coding 來表示,比如向左為[1,0,0],向右為[0,1,0] ······ 分別用折積層與全連線層從輸入中提取特徵,得到兩個特徵向量,然後把這兩個特徵向量拼接起來,得到一個更高的特徵向量,最後用一個全連線層輸出一個實數,這個實數就是裁判給運動員打的分數。這個動作說明,處在狀態 s 的情況下,做出動作 a 是好還是壞。這個價值網路可以與策略網路共用折積層引數,也可以跟策略網路完全獨立。
4.2 Actor-Critic Method
同時訓練策略網路與動作網路就稱為 Actor-Critic Method。
定義:使用神經網路來近似 兩個價值函數
訓練:更新引數 \(\theta、w\)
- 更新策略網路\(\pi({s}|{a};\theta)\)是為了讓\(V({s};\theta,w)\)的值增加
- 監督訊號僅由價值網路提供
- 運動員actor 根據裁判critic 的打分來不斷提高自己的水平
- 更新價值網路\(q({s},{a};w)\)是為了讓打分更精準
- 監督訊號僅來自環境的獎勵
- 一開始裁判是隨機打分,但是會根據環境給的獎勵提高打分水平,使其接近真實打分。
步驟總結:
- 觀測狀態 \(s_t\)
- \(s_t\) 作為輸入,根據策略網路 \(\pi({\cdot}|{s_t};\theta_t)\) 隨機取樣一個動作 \(a_t\)
- 實施動作 \(a_t\) 並觀測新狀態 \(s_{t+1}\) 以及獎勵 \(r_t\)
- 用獎勵 \(r_t\) 通過 TD 演演算法 在價值網路中更新 w,讓裁判變得更準確
- 使用 策略梯度演演算法 在策略網路中更新\(\theta\),讓運動員技術更好
a. TD 更新價值網路
-
用價值網路 Q 給 動作\(a_t、a_{t+1}\) 打分,即計算 \(q({s_t}, {a_t} ;w_t)\) 與 \(q({s_{t+1}},{a_{t+1}};w_t)\)
-
計算TD target:\(y_t = {r_t} + \gamma \cdot q({s_{t+1}},{a_{t+1}};w_t)\),
比對上一篇筆記中的策略學習,需要用蒙特卡洛來近似\(q({s_t},{a_t} ;w_t)\),而使用價值網路來近似更真實一些。
-
損失函數是預測值與部分真實值之間的差。
Loss值: \(L(w)=\frac{1}{2}[q({s_t},{a_t};w)-y_t]^2\)
-
梯度下降:\(W_{t+1} = w_t -\alpha \cdot \frac{\partial L(w)}{\partial w}|w=w_t\)
b. 策略梯度更新策略網路
狀態價值函數 V 相當於運動員所有動作的平均分:
\(V({s};\theta,w)=\sum_a\pi({s}|{a};\theta)\cdot q({s},{a};w)\)
策略梯度:函數 \(V({s};\theta,w)\) 關於引數 \(\theta\) 的導數
- \(g({a},\theta)=\frac{\partial log \pi({a}|{s};\theta)}{\partial \theta} \cdot q({s},{a};w)\),這裡 q 相當於裁判的打分
- \(\frac{\partial V(s;\theta;w_t)}{\partial \theta} = \mathbb{E}_{A}[g({A},\theta)]\)策略梯度相當於對函數 g 求期望,把 A 給消掉,但是很難求期望,用蒙特卡洛近似取樣求就行了。
演演算法:
根據策略網路隨機抽樣得到動作 a :\({a} \sim \pi(\cdot|{s_t};\theta_t)\) 。
對於 \(\pi\) 隨機抽樣保證\(g(a,\theta)\)是無偏估計
有了隨機梯度 g,可以做一次梯度上升:\(\theta_{t+1} = \theta_t + \beta \cdot g({a},\theta_t)\),此處 \(\beta\) 是學習率。
c. 過程梳理
下面我們以運動員和裁判的例子梳理一下過程:

首先,運動員(左側的策略網路)觀測當前狀態 s ,控制 agent 做出動作 a;運動員想要進步,但它不知道怎樣變得更好(或者沒有評判標準),因此引入裁判來給予運動員評價:
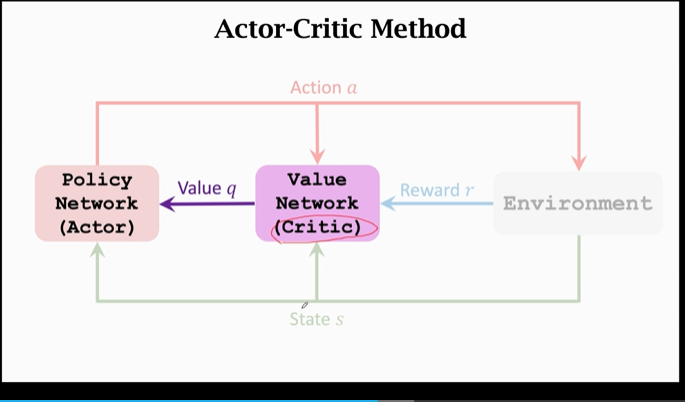
運動員做出動作後,裁判員(價值網路)會根據 a 和 s 對運動員(策略網路)打一個分 q,這樣運動員根據 q 來改進自己:

運動員的「技術」指的是 策略網路中的引數,我們此前認定引數越好,我們的效果就越好。在這個模型中,運動員拿到 s、q 以及 a來計算 策略梯度,通過梯度上升來更新引數。通過改進 「技術」,運動員的平均分(就是value q)會越來越高。
但值得注意的是:至此,運動員一直是在裁判的評判下進行的,他的標準 q 是裁判給的。運動員的平均分 q 越高也不能說明真實水平的上升。我們還需要提升裁判的水平。
增加一個想法:我覺得 actor-critic 的思想是兩部分,一是讓 評判標準更接近上帝 的想法,二是 在給定評判標準下 讓執行效果拿到更大的分數。

對於 價值網路/裁判 來說 初始的打分是隨機的。裁判要靠 獎勵r 來提高打分的水平,這裡獎勵r 就相當於 上帝的判斷。價值網路根據 a、s、r 來給出分數 q ,通過相鄰兩次的分數 \(q_t、q_{t+1}\) 以及 \(r_t\),使用 TD 演演算法 來更新引數,提高效果
d. 演演算法總結
下面稍微正式一點的總結一下:
-
觀測舊狀態 \(s_t\),根據策略網路\(\pi({\cdot}|{s_t};\theta_t)\)隨機取樣一個動作\(a_t\)
-
agent 執行動作\(a_t\);環境會告訴我們新的狀態\(s_{t+1}\)和獎勵\(r_t\)
-
拿新的狀態\(s_{t+1}\)作為輸入,用策略網路\(\pi\)計算出新的概率並隨機取樣新的動作:\({\tilde{a}_{t+1}} \sim \pi({\cdot}|{s_{t+1}};\theta_t)\),這個動作只是假想的動作,agent不會執行,只是拿來算下 Q 值。
-
接下來算兩次價值網路的輸出:\(q_t=q({s_t},{a_t};w_t)和q_{t+1}=q({s_{t+1}},{\tilde{a}_{t+1}};w_t)\),\({\tilde{a}_{t+1}}\)用完就丟掉了,並不會真正執行;
-
計算TD error:\(\delta_t = {q_t}-\underbrace{({r_t}+\gamma \cdot {q_{t+1}})}_{TD \\\ target}\)
-
對價值網路求導:\(d_{w,t} = \frac{\partial q({s_t},{a_t};w)}{\partial w}|w=w_t\)
這一步 torch 和 tensenflow 都可以自動求導。
-
TD演演算法 更新價值網路,讓裁判打分更精準:\(w_{t+1}=w_t - \alpha \cdot \delta_t\cdot d_{w,t}\)
-
對策略網路$$\pi$$求導:\(d_{\theta,t}=\frac{\partial log \pi({a_t}|{s_t},\theta)}{\partial \theta}|\theta=\theta_t\)
同理,可以自動求導
-
用梯度上升來更新策略網路,讓運動員平均成績更高:\(\theta_{t+1} = \theta_t + \beta \cdot {q_t} \cdot d_{\theta,t}\),這裡\({q_t} \cdot d_{\theta,t}\)是策略梯度的蒙特卡洛近似。
每一輪迭代做以上9個步驟,且製作一次動作,觀測一次獎勵,更新一次神經網路引數。
根據策略梯度演演算法推導,演演算法第 9 步用到了 \({q_t}\),它是裁判給動作打的分數,書和論文通常拿 \({\delta_t}\) 來替代 \({q_t}\)。\({q_t}\) 是標準演演算法,\({\delta_t}\) 是Policy Gradient With Baseline(效果更好),都是對的,算出來期望也相等。
Baseline是什麼?接近 \(q_t\) 的數都可以作為 Baseline,但不能是 \(a_t\) 的函數。
至於為什麼baseline效果更好,因為可以更好的計算方差,更快的收斂。
這裡的等價後面再討論。這裡先理解。
4.3 總結
我們的目標是:狀態價值函數:$ V_\pi({s})=\sum_{{a}}\pi({a}|{s})\cdot Q_\pi({s},{a})$,越大越好
- 但是直接學 \(\pi\) 函數不容易,用神經網路-策略網路 \(\pi({s}|{a};\theta)\) 來近似
- 計算 策略梯度 的時候有個困難就是不知道動作價值函數 \(Q_\pi\),所以要用神經網路-價值網路\(q({s},{a};w)\)來近似。
在訓練時:
- agent由 策略網路(actor) 給出動作 \(a_t \sim \pi(\cdot|{s_t};\theta)\)
- 價值網路 q 輔助訓練 \(\pi\),給出評分
訓練後:
- 還是由策略網路給出動作\(a_t \sim \pi(\cdot|{s_t};\theta)\)
- 價值網路 q 不再使用
如何訓練:
用策略梯度來更新策略網路:
- 儘可能提升狀態價值:$ V_\pi({s})=\sum_a\pi(a|s;\theta)\cdot q(s,a;w)$
- 計算策略梯度,用蒙特卡洛算: \(\frac{\partial V(s;\theta;w_t)}{\partial \theta} = \mathbb{E}_{A}[\frac{\partial \\\ log \\\ \pi({a}|{s};\theta)}{\partial \theta} \cdot q({s},{a};w)]\)
- 執行梯度上升。
TD 演演算法更新價值網路
-
\(q_t = q(s_t,a_t;w)\)是價值網路是對期望回報的估計;
-
TD target:\(y_t = r_t + \gamma \cdot \mathop{max}\limits_{a} q(s_{t+1},a_{t+1};w)\),\(y_t\)也是價值網路是對期望回報的估計,不過它用到了真實獎勵,因此更靠譜一點,所以將其作為 target,相當於機器學習中的標籤。
-
把\(q_t與y_t\)差值平方作為損失函數計算梯度:
\(\frac{\partial(q_t-y_t)^2/2}{\partial w} = (q_t-y_t)\cdot\frac{\partial q(s_t,a_t;w)}{\partial w}\)
-
梯度下降,縮小\(q_t與y_t\)差距。
x. 參考教學
- 視訊課程:深度強化學習(全)_嗶哩嗶哩_bilibili
- 視訊原地址:https://www.youtube.com/user/wsszju
- 課件地址:https://github.com/wangshusen/DeepLearning
- 筆記參考: