詳解SQL中Groupings Sets 語句的功能和底層實現邏輯
摘要:本文首先簡單介紹 Grouping Sets 的用法,然後以 Spark SQL 作為切入點,深入解析 Grouping Sets 的實現機制。
本文分享自華為雲社群《深入理解 SQL 中的 Grouping Sets 語句》,作者:元閏子。
SQL 中 Group By 語句大家都很熟悉,根據指定的規則對資料進行分組,常常和聚合函數一起使用。
比如,考慮有表 dealer,表中資料如下:
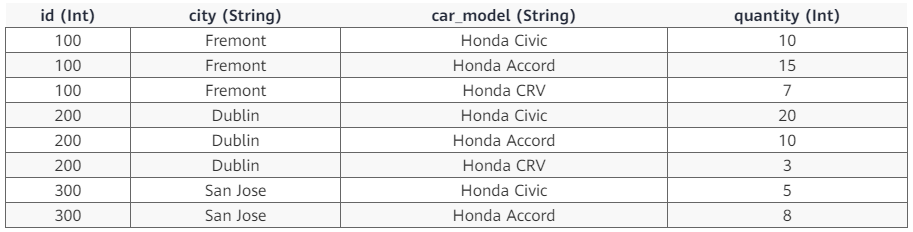
如果執行 SQL 語句 SELECT id, sum(quantity) FROM dealer GROUP BY id ORDER BY id,會得到如下結果:
+---+-------------+ | id|sum(quantity)| +---+-------------+ |100| 32| |200| 33| |300| 13| +---+-------------+
上述 SQL 語句的意思就是對資料按 id 列進行分組,然後在每個分組內對 quantity 列進行求和。
Group By 語句除了上面的簡單用法之外,還有更高階的用法,常見的是 Grouping Sets、RollUp 和 Cube,它們在 OLAP 時比較常用。其中,RollUp 和 Cube 都是以 Grouping Sets 為基礎實現的,因此,弄懂了 Grouping Sets,也就理解了 RollUp 和 Cube 。
本文首先簡單介紹 Grouping Sets 的用法,然後以 Spark SQL 作為切入點,深入解析 Grouping Sets 的實現機制。
Spark SQL 是 Apache Spark 巨量資料處理框架的一個子模組,用來處理結構化資訊。它可以將 SQL 語句翻譯多個任務在 Spark 叢集上執行,允許使用者直接通過 SQL 來處理資料,大大提升了易用性。
Grouping Sets 簡介
Spark SQL 官方檔案中
Groups the rows for each grouping set specified after GROUPING SETS. (... 一些舉例) This clause is a shorthand for a
UNION ALLwhere each leg of theUNION ALLoperator performs aggregation of each grouping set specified in theGROUPING SETSclause. (... 一些舉例)
也即,Grouping Sets 語句的作用是指定幾個 grouping set 作為 Group By 的分組規則,然後再將結果聯合在一起。它的效果和,先分別對這些 grouping set 進行 Group By 分組之後,再通過 Union All 將結果聯合起來,是一樣的。
比如,對於 dealer 表,Group By Grouping Sets ((city, car_model), (city), (car_model), ()) 和 Union All((Group By city, car_model), (Group By city), (Group By car_model), 全域性聚合) 的效果是相同的:
先看 Grouping Sets 版的執行結果:
spark-sql> SELECT city, car_model, sum(quantity) AS sum FROM dealer > GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) > ORDER BY city, car_model; +--------+------------+---+ | city| car_model|sum| +--------+------------+---+ | null| null| 78| | null|Honda Accord| 33| | null| Honda CRV| 10| | null| Honda Civic| 35| | Dublin| null| 33| | Dublin|Honda Accord| 10| | Dublin| Honda CRV| 3| | Dublin| Honda Civic| 20| | Fremont| null| 32| | Fremont|Honda Accord| 15| | Fremont| Honda CRV| 7| | Fremont| Honda Civic| 10| |San Jose| null| 13| |San Jose|Honda Accord| 8| |San Jose| Honda Civic| 5| +--------+------------+---+
再看 Union All 版的執行結果:
spark-sql> (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL > (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL > (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL > (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) > ORDER BY city, car_model; +--------+------------+---+ | city| car_model|sum| +--------+------------+---+ | null| null| 78| | null|Honda Accord| 33| | null| Honda CRV| 10| | null| Honda Civic| 35| | Dublin| null| 33| | Dublin|Honda Accord| 10| | Dublin| Honda CRV| 3| | Dublin| Honda Civic| 20| | Fremont| null| 32| | Fremont|Honda Accord| 15| | Fremont| Honda CRV| 7| | Fremont| Honda Civic| 10| |San Jose| null| 13| |San Jose|Honda Accord| 8| |San Jose| Honda Civic| 5| +--------+------------+---+
兩版的查詢結果完全一樣。
Grouping Sets 的執行計劃
從執行結果上看,Grouping Sets 版本和 Union All 版本的 SQL 是等價的,但 Grouping Sets 版本更加簡潔。
那麼,Grouping Sets 僅僅只是 Union All 的一個縮寫,或者語法糖嗎?
為了進一步探究 Grouping Sets 的底層實現是否和 Union All 是一致的,我們可以來看下兩者的執行計劃。
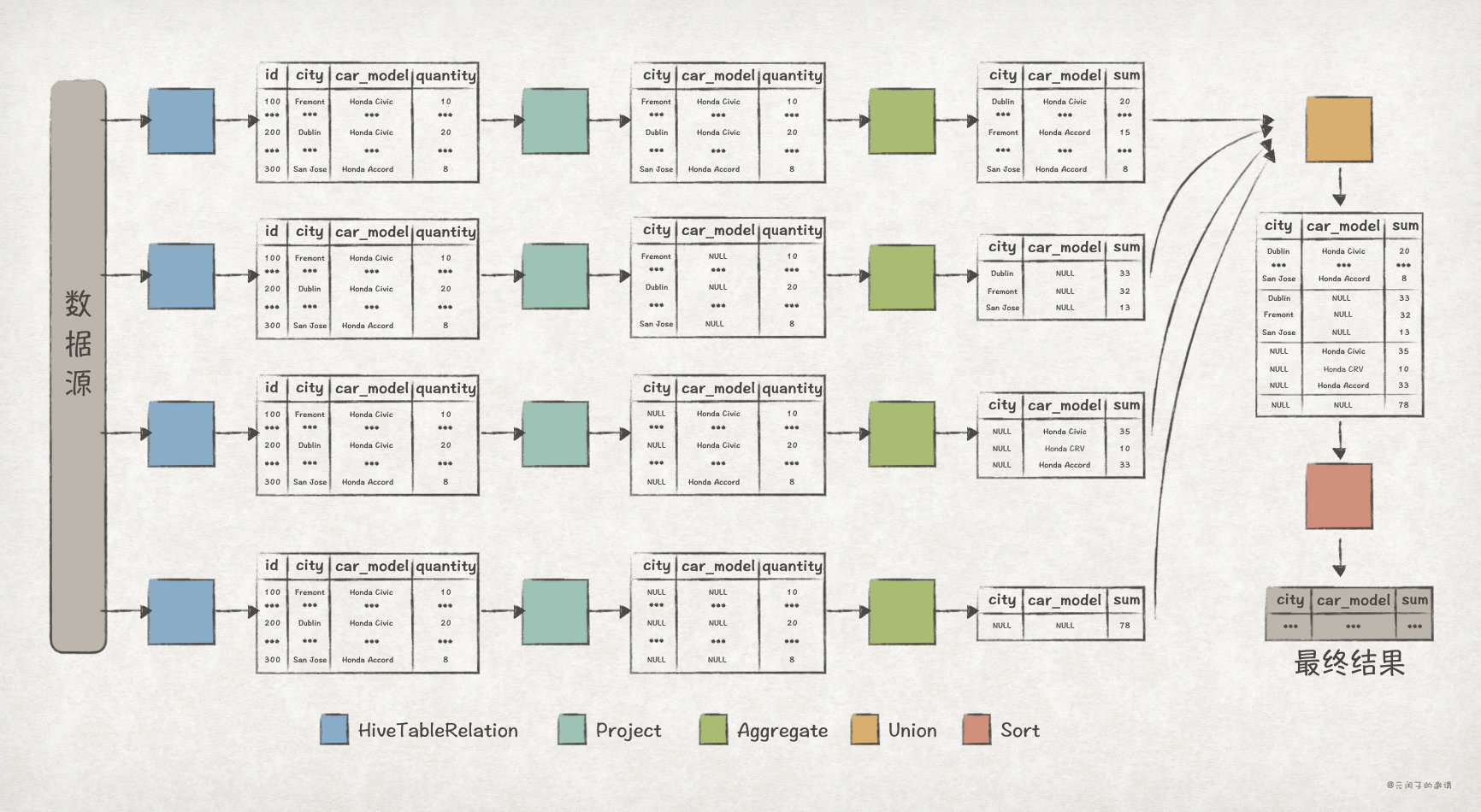
首先,我們通過 explain extended 來檢視 Union All 版本的 Optimized Logical Plan:
spark-sql> explain extended (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL(SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) ORDER BY city, car_model; == Parsed Logical Plan == ... == Analyzed Logical Plan == ... == Optimized Logical Plan == Sort [city#93 ASC NULLS FIRST, car_model#94 ASC NULLS FIRST], true +- Union false, false :- Aggregate [city#93, car_model#94], [city#93, car_model#94, sum(quantity#95) AS sum#79L] : +- Project [city#93, car_model#94, quantity#95] : +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#92, city#93, car_model#94, quantity#95], Partition Cols: []] :- Aggregate [city#97], [city#97, null AS car_model#112, sum(quantity#99) AS sum#81L] : +- Project [city#97, quantity#99] : +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#96, city#97, car_model#98, quantity#99], Partition Cols: []] :- Aggregate [car_model#102], [null AS city#113, car_model#102, sum(quantity#103) AS sum#83L] : +- Project [car_model#102, quantity#103] : +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#100, city#101, car_model#102, quantity#103], Partition Cols: []] +- Aggregate [null AS city#114, null AS car_model#115, sum(quantity#107) AS sum#86L] +- Project [quantity#107] +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#104, city#105, car_model#106, quantity#107], Partition Cols: []] == Physical Plan == ...
從上述的 Optimized Logical Plan 可以清晰地看出 Union All 版本的執行邏輯:
-
執行每個子查詢語句,計算得出查詢結果。其中,每個查詢語句的邏輯是這樣的:
-
在 HiveTableRelation 節點對
dealer表進行全表掃描。 -
在 Project 節點選出與查詢語句結果相關的列,比如對於子查詢語句
SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer,只需保留quantity列即可。 -
在 Aggregate 節點完成
quantity列對聚合運算。在上述的 Plan 中,Aggregate 後面緊跟的就是用來分組的列,比如Aggregate [city#902]就表示根據city列來進行分組。
-
-
在 Union 節點完成對每個子查詢結果的聯合。
-
最後,在 Sort 節點完成對資料的排序,上述 Plan 中
Sort [city#93 ASC NULLS FIRST, car_model#94 ASC NULLS FIRST]就表示根據city和car_model列進行升序排序。
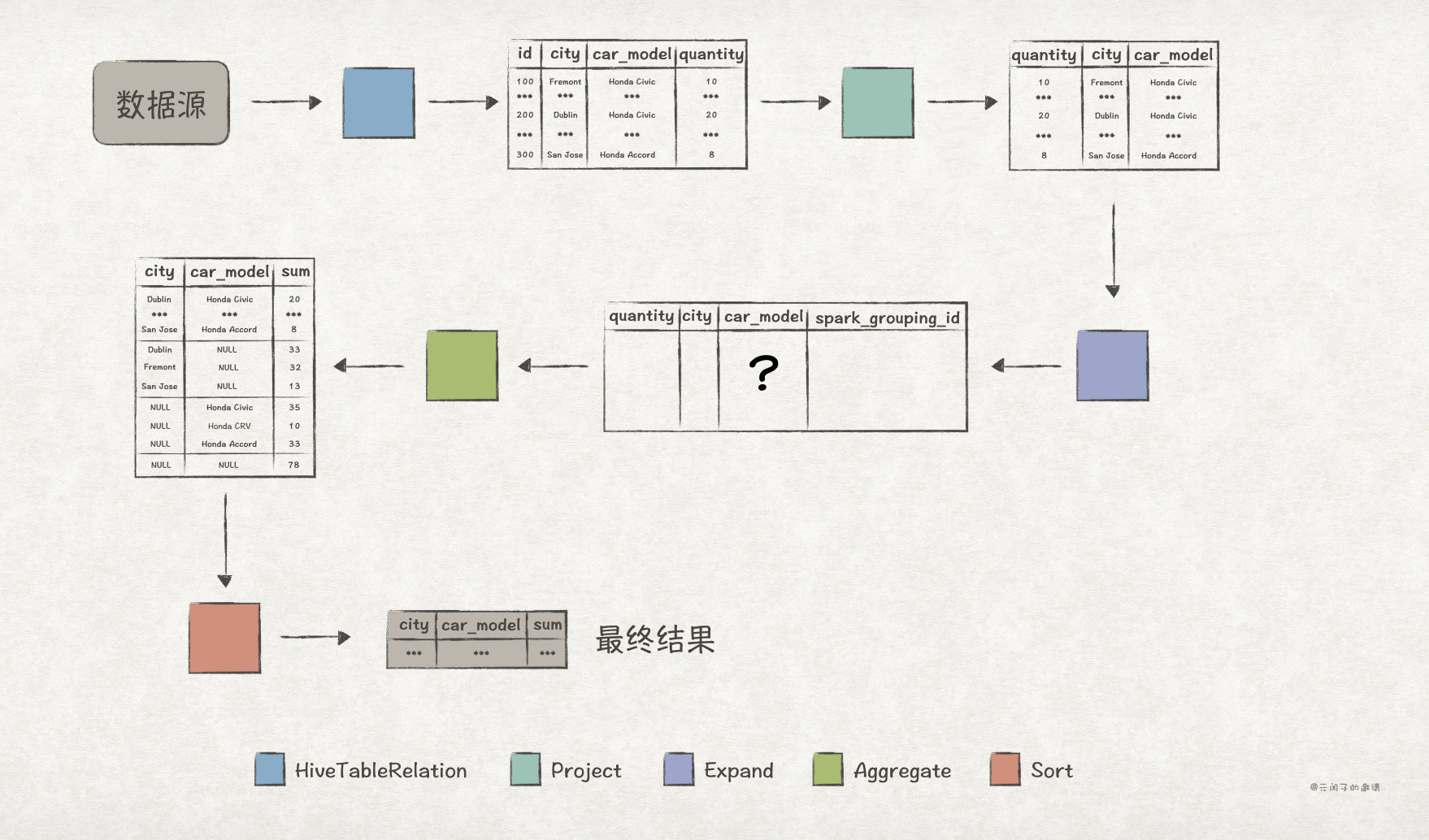
接下來,我們通過 explain extended 來檢視 Grouping Sets 版本的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) ORDER BY city, car_model; == Parsed Logical Plan == ... == Analyzed Logical Plan == ... == Optimized Logical Plan == Sort [city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST], true +- Aggregate [city#138, car_model#139, spark_grouping_id#137L], [city#138, car_model#139, sum(quantity#133) AS sum#124L] +- Expand [[quantity#133, city#131, car_model#132, 0], [quantity#133, city#131, null, 1], [quantity#133, null, car_model#132, 2], [quantity#133, null, null, 3]], [quantity#133, city#138, car_model#139, spark_grouping_id#137L] +- Project [quantity#133, city#131, car_model#132] +- HiveTableRelation [`default`.`dealer`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [id#130, city#131, car_model#132, quantity#133], Partition Cols: []] == Physical Plan == ...
從 Optimized Logical Plan 來看,Grouping Sets 版本要簡潔很多!具體的執行邏輯是這樣的:
-
在 HiveTableRelation 節點對
dealer表進行全表掃描。 -
在 Project 節點選出與查詢語句結果相關的列。
-
接下來的 Expand 節點是關鍵,資料經過該節點後,多出了
spark_grouping_id列。從 Plan 中可以看出來,Expand 節點包含了Grouping Sets裡的各個 grouping set 資訊,比如[quantity#133, city#131, null, 1]對應的就是(city)這一 grouping set。而且,每個 grouping set 對應的spark_grouping_id列的值都是固定的,比如(city)對應的spark_grouping_id為1。 -
在 Aggregate 節點完成
quantity列對聚合運算,其中分組的規則為city, car_model, spark_grouping_id。注意,資料經過 Aggregate 節點後,spark_grouping_id列被刪除了! -
最後,在 Sort 節點完成對資料的排序。
從 Optimized Logical Plan 來看,雖然 Union All 版本和 Grouping Sets 版本的效果一致,但它們的底層實現有著巨大的差別。
其中,Grouping Sets 版本的 Plan 中最關鍵的是 Expand 節點,目前,我們只知道資料經過它之後,多出了 spark_grouping_id 列。而且從最終結果來看,spark_grouping_id 只是 Spark SQL 的內部實現細節,對使用者並不體現。那麼:
-
Expand 的實現邏輯是怎樣的,為什麼能達到
Union All的效果? -
Expand 節點的輸出資料是怎樣的?
-
spark_grouping_id列的作用是什麼?
通過 Physical Plan,我們發現 Expand 節點對應的運算元名稱也是 Expand:
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- Sort [city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST], true, 0 +- Exchange rangepartitioning(city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=422] +- HashAggregate(keys=[city#138, car_model#139, spark_grouping_id#137L], functions=[sum(quantity#133)], output=[city#138, car_model#139, sum#124L]) +- Exchange hashpartitioning(city#138, car_model#139, spark_grouping_id#137L, 200), ENSURE_REQUIREMENTS, [plan_id=419] +- HashAggregate(keys=[city#138, car_model#139, spark_grouping_id#137L], functions=[partial_sum(quantity#133)], output=[city#138, car_model#139, spark_grouping_id#137L, sum#141L]) +- Expand [[quantity#133, city#131, car_model#132, 0], [quantity#133, city#131, null, 1], [quantity#133, null, car_model#132, 2], [quantity#133, null, null, 3]], [quantity#133, city#138, car_model#139, spark_grouping_id#137L] +- Scan hive default.dealer [quantity#133, city#131, car_model#132], HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#130, city#131, car_model#132, quantity#133], Partition Cols: []]
帶著前面的幾個問題,接下來我們深入 Spark SQL 的 Expand 運算元原始碼尋找答案。
Expand 運算元的實現
Expand 運算元在 Spark SQL 原始碼中的實現為 ExpandExec 類(Spark SQL 中的運算元實現類的命名都是 XxxExec 的格式,其中 Xxx 為具體的運算元名,比如 Project 運算元的實現類為 ProjectExec),核心程式碼如下:
/** * Apply all of the GroupExpressions to every input row, hence we will get * multiple output rows for an input row. * @param projections The group of expressions, all of the group expressions should * output the same schema specified bye the parameter `output` * @param output The output Schema * @param child Child operator */ case class ExpandExec( projections: Seq[Seq[Expression]], output: Seq[Attribute], child: SparkPlan) extends UnaryExecNode with CodegenSupport { ... // 關鍵點1,將child.output,也即上游運算元輸出資料的schema, // 繫結到表示式陣列exprs,以此來計算輸出資料 private[this] val projection = (exprs: Seq[Expression]) => UnsafeProjection.create(exprs, child.output) // doExecute()方法為Expand運算元執行邏輯所在 protected override def doExecute(): RDD[InternalRow] = { val numOutputRows = longMetric("numOutputRows") // 處理上游運算元的輸出資料,Expand運算元的輸入資料就從iter迭代器獲取 child.execute().mapPartitions { iter => // 關鍵點2,projections對應了Grouping Sets裡面每個grouping set的表示式, // 表示式輸出資料的schema為this.output, 比如 (quantity, city, car_model, spark_grouping_id) // 這裡的邏輯是為它們各自生成一個UnsafeProjection物件,通過該物件的apply方法就能得出Expand運算元的輸出資料 val groups = projections.map(projection).toArray new Iterator[InternalRow] { private[this] var result: InternalRow = _ private[this] var idx = -1 // -1 means the initial state private[this] var input: InternalRow = _ override final def hasNext: Boolean = (-1 < idx && idx < groups.length) || iter.hasNext override final def next(): InternalRow = { // 關鍵點3,對於輸入資料的每一條記錄,都重複使用N次,其中N的大小對應了projections陣列的大小, // 也即Grouping Sets裡指定的grouping set的數量 if (idx <= 0) { // in the initial (-1) or beginning(0) of a new input row, fetch the next input tuple input = iter.next() idx = 0 } // 關鍵點4,對輸入資料的每一條記錄,通過UnsafeProjection計算得出輸出資料, // 每個grouping set對應的UnsafeProjection都會對同一個input計算一遍 result = groups(idx)(input) idx += 1 if (idx == groups.length && iter.hasNext) { idx = 0 } numOutputRows += 1 result } } } } ... }
ExpandExec 的實現並不複雜,想要理解它的運作原理,關鍵是看懂上述原始碼中提到的 4 個關鍵點。
關鍵點 1 和 關鍵點 2 是基礎,關鍵點 2 中的 groups 是一個 UnsafeProjection[N] 陣列型別,其中每個 UnsafeProjection 代表了 Grouping Sets 語句裡指定的 grouping set,它的定義是這樣的:
// A projection that returns UnsafeRow. abstract class UnsafeProjection extends Projection { override def apply(row: InternalRow): UnsafeRow } // The factory object for `UnsafeProjection`. object UnsafeProjection extends CodeGeneratorWithInterpretedFallback[Seq[Expression], UnsafeProjection] { // Returns an UnsafeProjection for given sequence of Expressions, which will be bound to // `inputSchema`. def create(exprs: Seq[Expression], inputSchema: Seq[Attribute]): UnsafeProjection = { create(bindReferences(exprs, inputSchema)) } ... }
UnsafeProjection 起來了類似列投影的作用,其中, apply 方法根據建立時的傳參 exprs 和 inputSchema,對輸入記錄進行列投影,得出輸出記錄。
比如,前面的 GROUPING SETS ((city, car_model), (city), (car_model), ()) 例子,它對應的 groups 是這樣的:
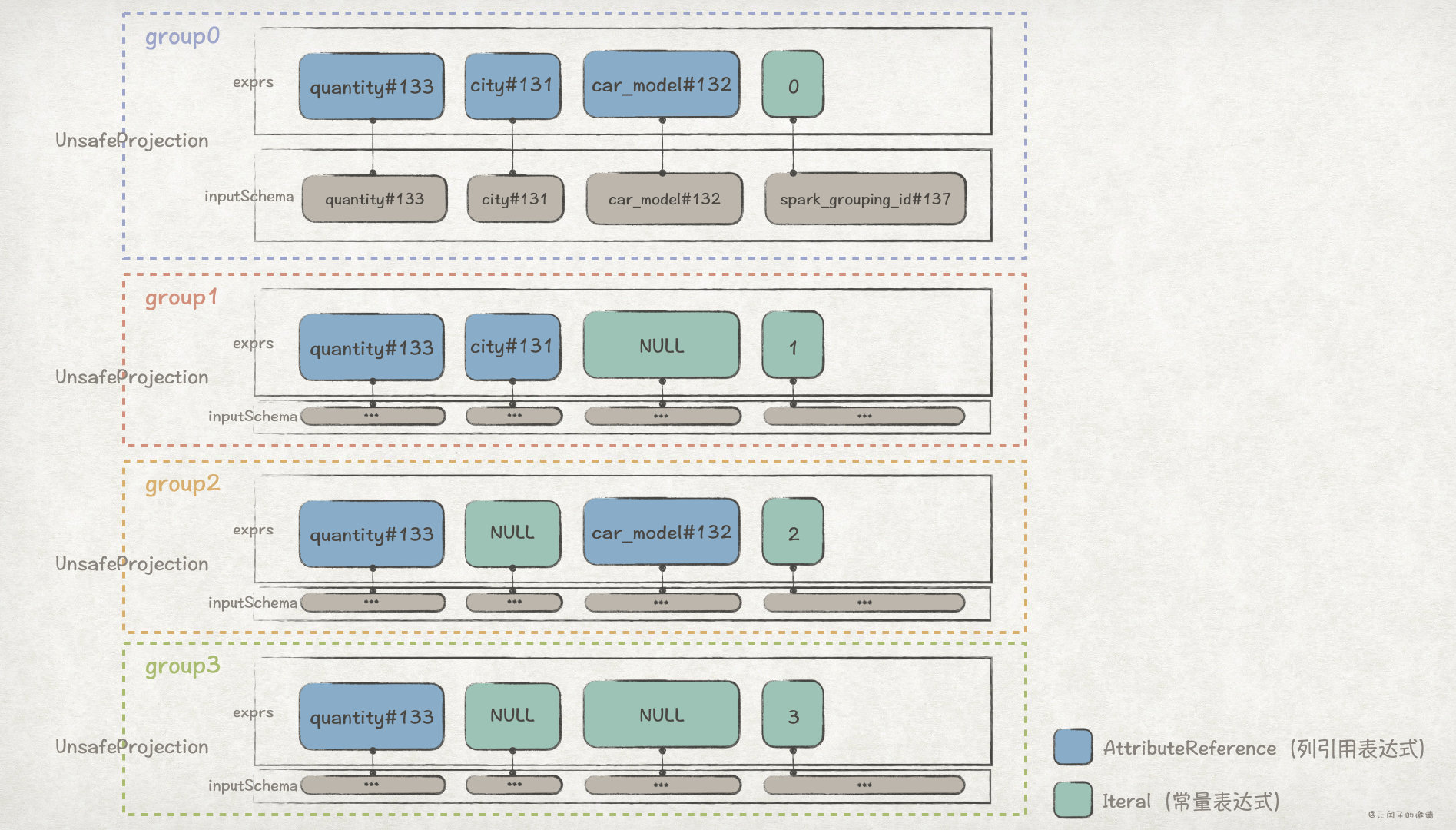
其中,AttributeReference 型別的表示式,在計算時,會直接參照輸入資料對應列的值;Iteral 型別的表示式,在計算時,值是固定的。
關鍵點 3 和 關鍵點 4 是 Expand 運算元的精華所在,ExpandExec 通過這兩段邏輯,將每一個輸入記錄,擴充套件(Expand)成 N 條輸出記錄。
關鍵點 4中groups(idx)(input)等同於groups(idx).apply(input)。
還是以前面 GROUPING SETS ((city, car_model), (city), (car_model), ()) 為例子,效果是這樣的:
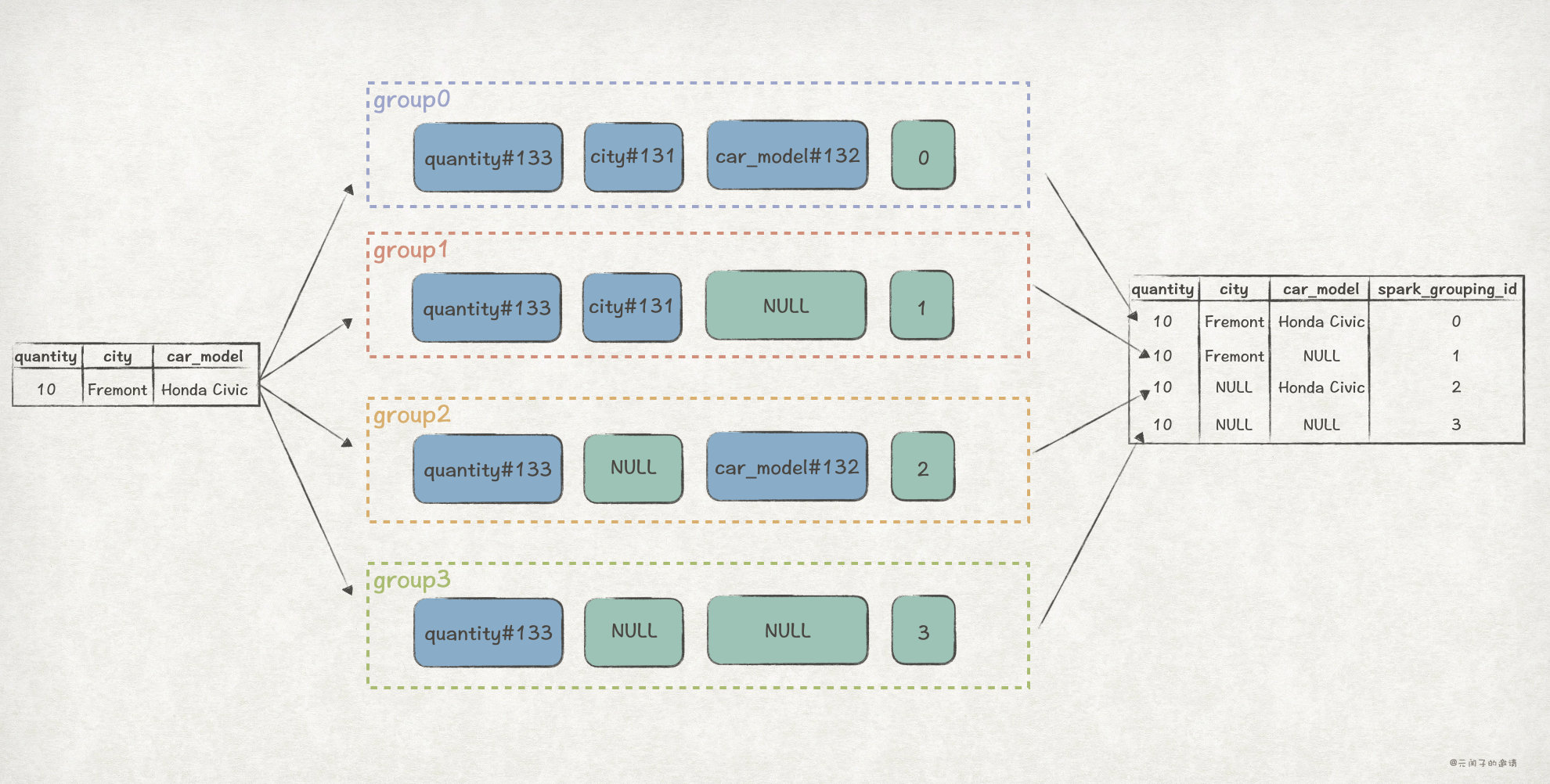
到這裡,我們已經弄清楚 Expand 運算元的工作原理,再回頭看前面提到的 3 個問題,也不難回答了:
-
Expand 的實現邏輯是怎樣的,為什麼能達到
Union All的效果?如果說
Union All是先聚合再聯合,那麼 Expand 就是先聯合再聚合。Expand 利用groups裡的 N 個表示式對每條輸入記錄進行計算,擴充套件成 N 條輸出記錄。後面再聚合時,就能達到與Union All一樣的效果了。 -
Expand 節點的輸出資料是怎樣的?
在 schema 上,Expand 輸出資料會比輸入資料多出
spark_grouping_id列;在記錄數上,是輸入資料記錄數的 N 倍。 -
spark_grouping_id列的作用是什麼?spark_grouping_id給每個 grouping set 進行編號,這樣,即使在 Expand 階段把資料先聯合起來,在 Aggregate 階段(把spark_grouping_id加入到分組規則)也能保證資料能夠按照每個 grouping set 分別聚合,確保了結果的正確性。
查詢效能對比
spark-sql 執行完 SQL 語句之後會列印耗時資訊,我們對兩個版本的 SQL 分別執行 10 次,得到如下資訊:
// Grouping Sets 版本執行10次的耗時資訊 // SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) ORDER BY city, car_model; Time taken: 0.289 seconds, Fetched 15 row(s) Time taken: 0.251 seconds, Fetched 15 row(s) Time taken: 0.259 seconds, Fetched 15 row(s) Time taken: 0.258 seconds, Fetched 15 row(s) Time taken: 0.296 seconds, Fetched 15 row(s) Time taken: 0.247 seconds, Fetched 15 row(s) Time taken: 0.298 seconds, Fetched 15 row(s) Time taken: 0.286 seconds, Fetched 15 row(s) Time taken: 0.292 seconds, Fetched 15 row(s) Time taken: 0.282 seconds, Fetched 15 row(s) // Union All 版本執行10次的耗時資訊 // (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) ORDER BY city, car_model; Time taken: 0.628 seconds, Fetched 15 row(s) Time taken: 0.594 seconds, Fetched 15 row(s) Time taken: 0.591 seconds, Fetched 15 row(s) Time taken: 0.607 seconds, Fetched 15 row(s) Time taken: 0.616 seconds, Fetched 15 row(s) Time taken: 0.64 seconds, Fetched 15 row(s) Time taken: 0.623 seconds, Fetched 15 row(s) Time taken: 0.625 seconds, Fetched 15 row(s) Time taken: 0.62 seconds, Fetched 15 row(s) Time taken: 0.62 seconds, Fetched 15 row(s)
可以算出,Grouping Sets 版本的 SQL 平均耗時為 0.276s;Union All 版本的 SQL 平均耗時為 0.616s,是前者的 2.2 倍!
所以,Grouping Sets 版本的 SQL 不僅在表達上更加簡潔,在效能上也更加高效。
RollUp 和 Cube
Group By 的高階用法中,還有 RollUp 和 Cube 兩個比較常用。
首先,我們看下 RollUp 語句。
Spark SQL 官方檔案中
Specifies multiple levels of aggregations in a single statement. This clause is used to compute aggregations based on multiple grouping sets.
ROLLUPis a shorthand forGROUPING SETS. (... 一些例子)
官方檔案中,把 RollUp 描述為 Grouping Sets 的簡寫,等價規則為:RollUp(A, B, C) == Grouping Sets((A, B, C), (A, B), (A), ())。
比如,Group By RollUp(city, car_model) 就等同於 Group By Grouping Sets((city, car_model), (city), ())。
下面,我們通過 expand extended 看下 RollUp 版本 SQL 的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY ROLLUP(city, car_model) ORDER BY city, car_model; == Parsed Logical Plan == ... == Analyzed Logical Plan == ... == Optimized Logical Plan == Sort [city#2164 ASC NULLS FIRST, car_model#2165 ASC NULLS FIRST], true +- Aggregate [city#2164, car_model#2165, spark_grouping_id#2163L], [city#2164, car_model#2165, sum(quantity#2159) ASsum#2150L] +- Expand [[quantity#2159, city#2157, car_model#2158, 0], [quantity#2159, city#2157, null, 1], [quantity#2159, null, null, 3]], [quantity#2159, city#2164, car_model#2165, spark_grouping_id#2163L] +- Project [quantity#2159, city#2157, car_model#2158] +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#2156, city#2157, car_model#2158, quantity#2159], Partition Cols: []] == Physical Plan == ...
從上述 Plan 可以看出,RollUp 底層實現用的也是 Expand 運算元,說明 RollUp 確實是基於 Grouping Sets 實現的。 而且 Expand [[quantity#2159, city#2157, car_model#2158, 0], [quantity#2159, city#2157, null, 1], [quantity#2159, null, null, 3]] 也表明 RollUp 符合等價規則。
下面,我們按照同樣的思路,看下 Cube 語句。
Spark SQL 官方檔案中
CUBEclause is used to perform aggregations based on combination of grouping columns specified in theGROUP BYclause.CUBEis a shorthand forGROUPING SETS. (... 一些例子)
同樣,官方檔案把 Cube 描述為 Grouping Sets 的簡寫,等價規則為:Cube(A, B, C) == Grouping Sets((A, B, C), (A, B), (A, C), (B, C), (A), (B), (C), ())。
比如,Group By Cube(city, car_model) 就等同於 Group By Grouping Sets((city, car_model), (city), (car_model), ())。
下面,我們通過 expand extended 看下 Cube 版本 SQL 的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY CUBE(city, car_model) ORDER BY city, car_model; == Parsed Logical Plan == ... == Analyzed Logical Plan == ... == Optimized Logical Plan == Sort [city#2202 ASC NULLS FIRST, car_model#2203 ASC NULLS FIRST], true +- Aggregate [city#2202, car_model#2203, spark_grouping_id#2201L], [city#2202, car_model#2203, sum(quantity#2197) ASsum#2188L] +- Expand [[quantity#2197, city#2195, car_model#2196, 0], [quantity#2197, city#2195, null, 1], [quantity#2197, null, car_model#2196, 2], [quantity#2197, null, null, 3]], [quantity#2197, city#2202, car_model#2203, spark_grouping_id#2201L] +- Project [quantity#2197, city#2195, car_model#2196] +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#2194, city#2195, car_model#2196, quantity#2197], Partition Cols: []] == Physical Plan == ...
從上述 Plan 可以看出,Cube 底層用的也是 Expand 運算元,說明 Cube 確實基於 Grouping Sets 實現,而且也符合等價規則。
所以,RollUp 和 Cube 可以看成是 Grouping Sets 的語法糖,在底層實現和效能上是一樣的。
最後
本文重點討論了 Group By 高階用法 Groupings Sets 語句的功能和底層實現。
雖然 Groupings Sets 的功能,通過 Union All 也能實現,但前者並非後者的語法糖,它們的底層實現完全不一樣。Grouping Sets 採用的是先聯合再聚合的思路,通過 spark_grouping_id 列來保證資料的正確性;Union All 則採用先聚合再聯合的思路。Grouping Sets 在 SQL 語句表達和效能上都有更大的優勢。
Group By 的另外兩個高階用法 RollUp 和 Cube 則可以看成是 Grouping Sets 的語法糖,它們的底層都是基於 Expand 運算元實現,在效能上與直接使用 Grouping Sets 是一樣的,但在 SQL 表達上更加簡潔。
參考
[1]
[2]