Lepton 無失真壓縮原理及效能分析
作者:vivo 網際網路資料庫團隊- Li Shihai
本文主要介紹無失真壓縮圖片的概要流程和原理,以及Lepton無失真壓縮在前期調研中發現的問題和解決方案。
一、從一個遊戲開始
1.1 遊戲找茬
請拿出你的秒錶計時,在15秒時間內找出下面圖片的差異。

時間到了,你發現兩張圖片的差異了嗎?
二、智者的成長
在上面的遊戲中,你可能你並沒有發現兩張圖片間有任何差異,而實際上它們一張是3.7MB的jpg格式的原圖,另外一張是大小為485KB的jpg格式壓縮圖片,只是大小不同。你可能會有些生氣,憤憤不平到這是欺騙,然而聰明的你很快在大腦中產生了一連串的疑問,這些問號讓你層層揭開遊戲的面紗,不在為愚弄而悔恨,反而從新知中獲得快樂。
2.1 蘇格拉底助產術
- 上面圖片為何變小了呢?
- 丟失了的資訊去哪了呢?
- 為什麼圖片質量下降了,我卻看不出來呢?
- 我還能將它變的更小嗎?
- 我能將它還原成原來的大小嗎?
- 為什麼要壓縮我的圖片?
上面圖片為何變小了?圖片從3.7MB變成485KB是因為我使用了圖片檢視工具將原圖另存成一張新的圖片,在另存的過程中,有一個圖片質量選擇的引數,我選擇了質量最低,儲存後便生成了一張更小的圖片。可是圖片質量下降了,為什麼看不出來呢?這就需要了解圖片壓縮的原理。
2.2 探求表象背後的故事
利用人眼的弱點。
人的視網膜上有兩種細胞,視錐細胞和視杆細胞。視錐細胞用來感知顏色,視杆細胞用來感知亮度。而相對於顏色,我們對明暗的感知更明顯。
因此可以採取對顏色資訊進行壓縮來減小圖片的大小。
所以我們在圖片壓縮前會進行顏色空間的變換,JPEG圖片通常會變換成YCbCr顏色空間,Y代表亮度,Cb藍色色彩度,Cr紅色色彩度,變換後我們更容易處理色彩部分。然後我們將一張圖片切成一塊塊8*8的畫素塊,然後使用離散餘弦轉換演演算法(DCT)計算出高頻區和低頻區。
由於人眼對高頻區的複雜資訊不敏感,因此可以對這一部分進行壓縮,這個過程叫量化。最後再將新的檔案進行打包。這個流程下來就完成了圖片的壓縮。
基本流程如下圖:

JPEG壓縮有損。
在上面的流程中,在預測模組的顏色空間轉換後,通過捨棄部分顏色濃度資訊,提高壓縮率。常見選項為4:2:0,經過這一步後原來需要8個數位表示的資訊,現在只需要2個,直接拋棄了75%的Cb Cr資訊,然而這一步驟是不可逆的,也就造成了圖片壓縮的有損。此外在熵編碼模組,會進一步使用行程長度編碼或Huffman編碼進一步對圖片資訊進行壓縮,而這一部分的壓縮是無失真的,是可逆的。
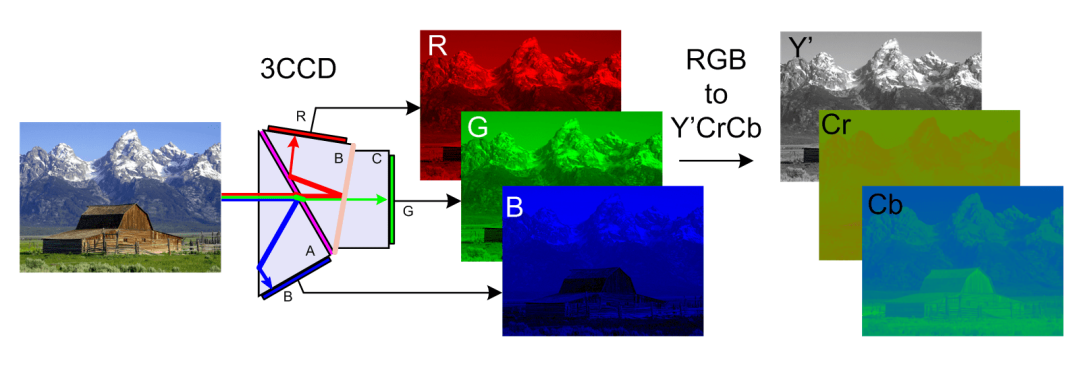
(YCbCr空間轉換)
霍夫曼編碼原理如下:
假如待編碼的字元總共38個符號資料,對其進行統計,得到的符號和對應頻度如下表:

首先,對所有符號按照頻數大小排序,排序後如下圖:

然後,選擇兩個頻數最小的作為葉子節點,頻數最小的作為左子節點,另外一個作為右子節點,根節點為兩個葉子節點的頻數之和。
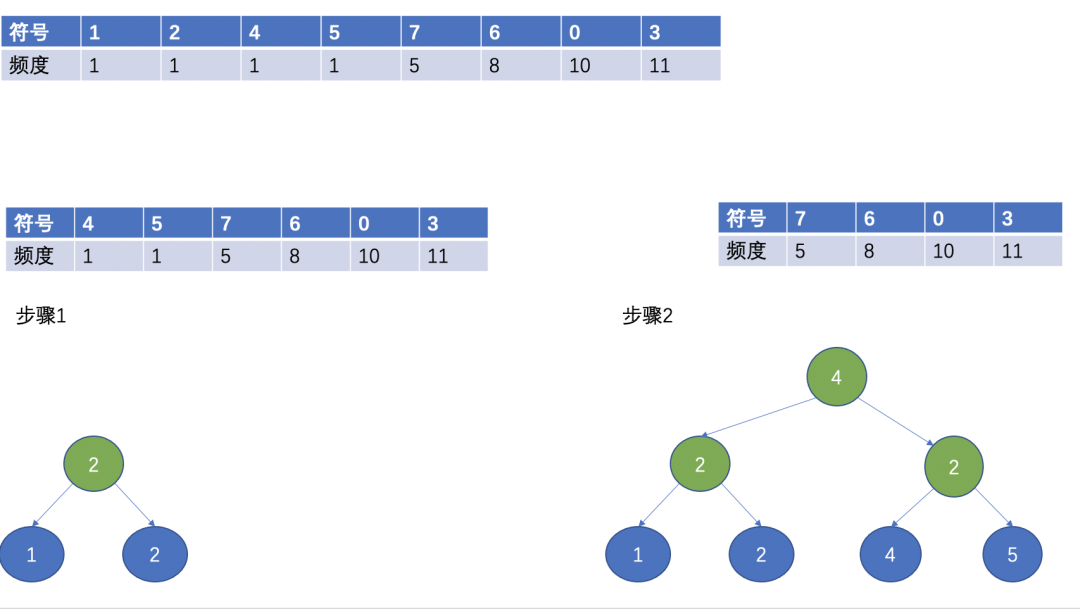
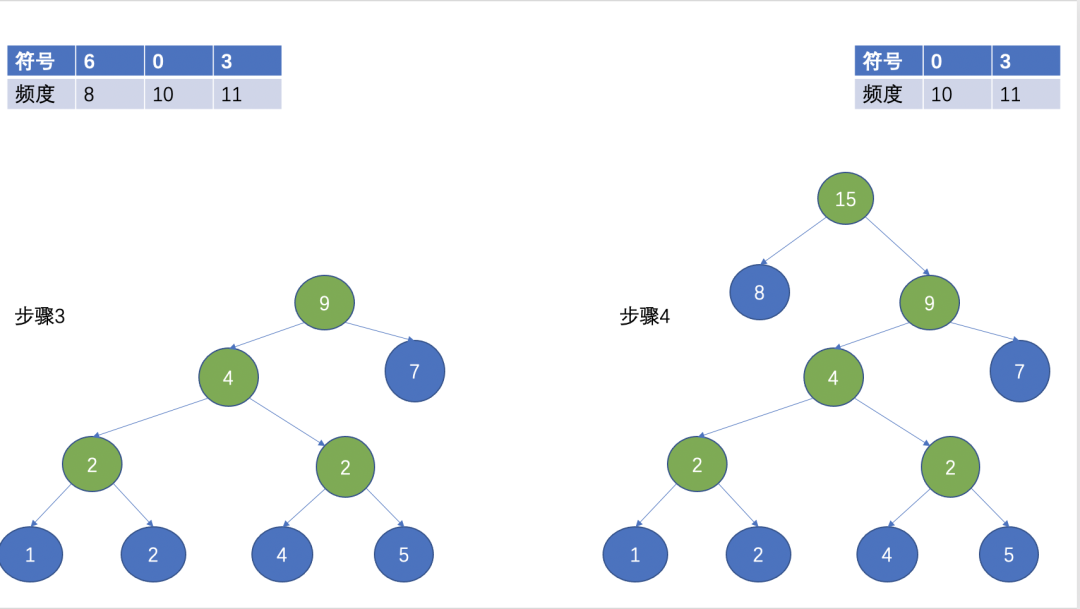
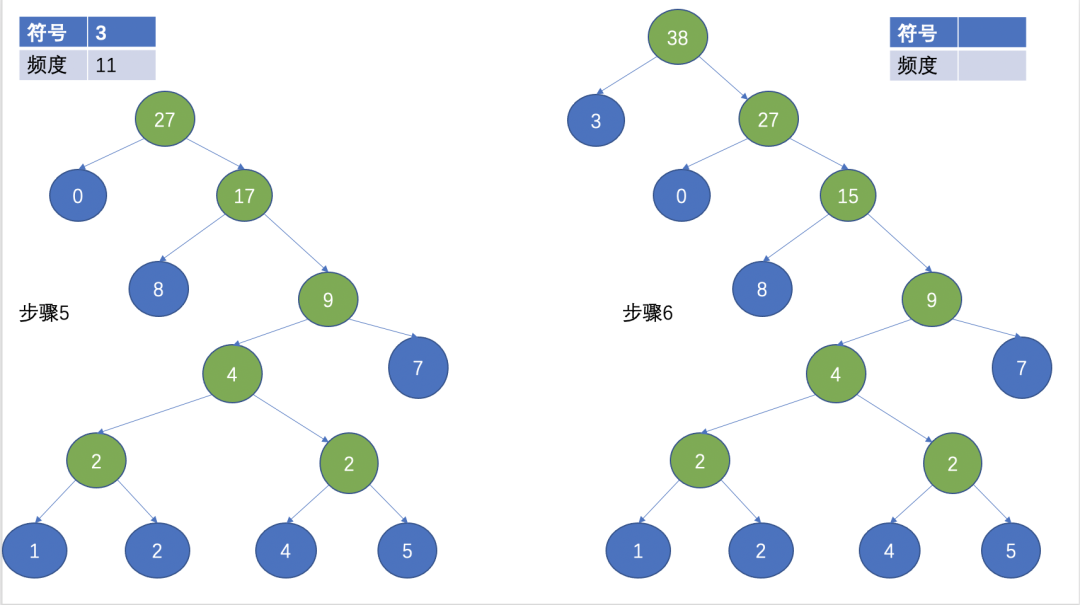
(Huffman 樹)
經過上面的步驟,就形成了一顆Huffman樹,Huffman編碼經常用在無失真壓縮中,其基本思想是用短的編碼表示出現頻率高的字元,用長的編碼來表示出現頻率低的字元,這使得編碼之後的字串的平均長度、長度的期望值降低,從而實現壓縮的目的。
三、故事的主角 Lepton
不完美。
上面的JPEG壓縮雖然降低了圖片的大小且質量良好以至於人眼很難分辨其差異,但是由於是有損的壓縮,圖片質量不能恢復到原來的品質,而且實際上此時的jpg圖片仍有壓縮空間。
Lepton便可以在JPEG基礎上進一步對圖片進行無失真壓縮。
3.1 為什麼選擇 Lepton
與lepton類似的壓縮工具還有jpegcan,MozJPEG,PackJPG,PAQ8PX。但這些工具都或多或少有一些缺陷,使得不如lepton更加適合工業生產。
比如PackJPG需要按照全域性排序的順序重新排列檔案中的所有壓縮畫素值。這意味著解壓縮是單執行緒的,同時需要整個影象放入記憶體中導致處理圖片的時延較高吞吐較低。
下圖是lepton論文中對幾款工具的比較:

3.2 Lepton進行了哪些優化。
首先在演演算法上Lepton將影象分為兩部分header和圖片資料本身,header使用DEFLATE進行無失真壓縮,圖片本身使用算數編碼替換霍爾曼編碼進行無失真壓縮。由於JPEG使用Huffman編碼,這使得利用多執行緒比較困難,Lepton使用"Huffman切換詞"進行了改進。
其次Lepton使用了一個複雜的自適應概率模型,這個模型是通過在大量的野外影象上進行測試而開發的。該模型的目標是對每個係數的值產生最準確的預測,從而產生更小的檔案;在工程上允許多執行緒並行處理,允許分塊跨多個伺服器分散式處理,流的方式逐行處理有效的控制了記憶體,同時還保證了資料讀取和輸出的安全。
正是Lepton在上述關鍵問題的優化,使得它目前可以很好的在生產環境中使用。
3.3 Lepton在vivo儲存中的探索
預期收益:
目前物件儲存其中的一個叢集大約有100PB資料,其中圖片資料大概佔70%, 而圖片中有90%的圖片都是jpeg型別圖片,如果按照平均23%的壓縮率,那麼 100PB * 70% * 90% * 23% = 14.5PB,將實現大約14.5PB的成本節約。
同時由於是無失真壓縮,很好的保證了使用者的使用體驗。當前lepton壓縮功能的設計如下圖:
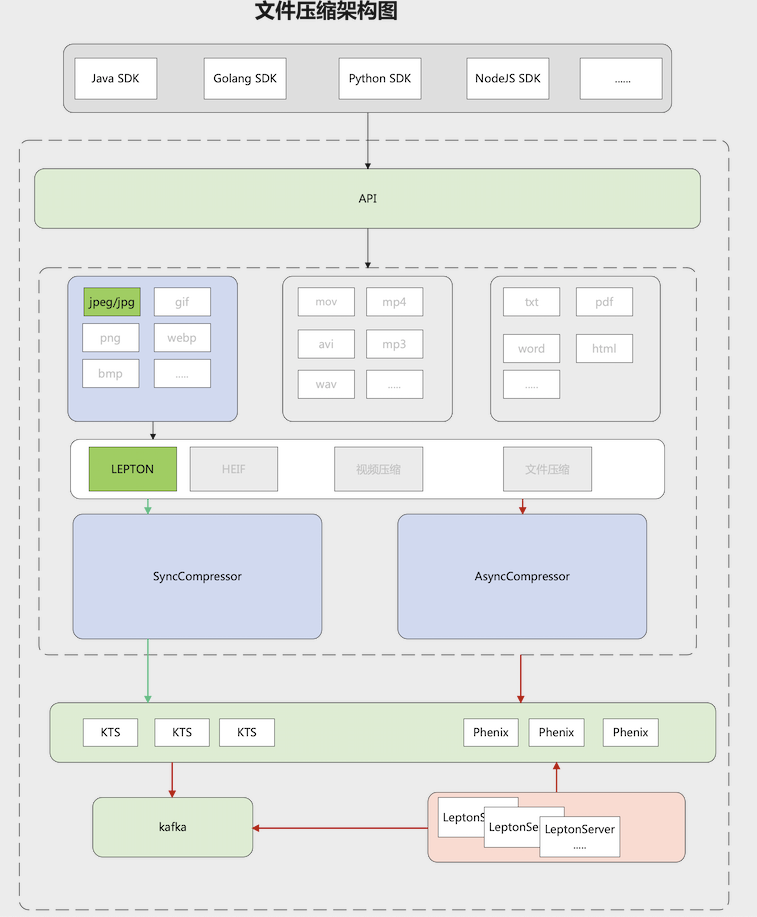
當前遇到的挑戰:
- lepton壓縮與解壓縮對伺服器的計算效能要求較高、消耗較大。
- 期望充分利用空閒伺服器CPU資源,達到降本增效的目的。
- 面對潮汐現象具備動態擴縮容的能力。
當前面臨的主要問題:
當前大部分圖片的大小在4M-5M, 經過測試對於4M-5M大小的檔案壓縮時延在1s左右的情況下,需要伺服器至少16核心、承載5QPS。此時每個核心的利用率都在95%以上。可見 Lepton的壓縮對計算效能要求很高。當前常見的解決方案是使用FPGA卡進行硬體加速、以及橫向擴容大量的計算節點。FPGA的使用會增加硬體成本,降低壓縮帶來的成本收益。
解決方案:
為了解決上述問題及挑戰,我們嘗試採用物理伺服器和Kubernetes混合部署的方式解決計算資源的使用和動態擴所容的問題,架構示意圖如下: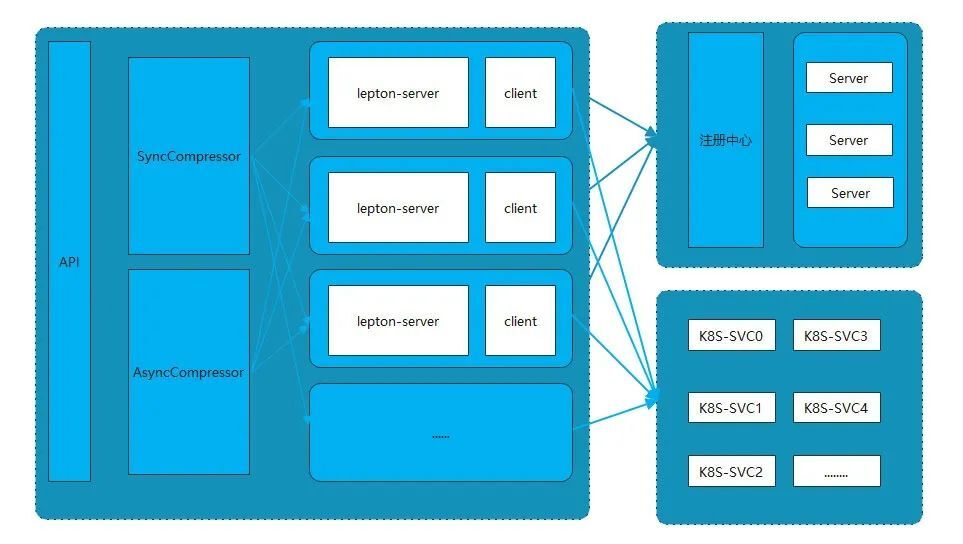
對於物理伺服器的管理以及擴所容通過服務的註冊於發現進行彈性擴所容、通過此cgroup/Taskset等方式對程序的cpu使用進行管理。同時對接使用Kubernetes以容器的方式進行管理、容器的靈活性更加適合這種計算型的服務。
3.4 效能評測
無論是同步壓縮,還是非同步壓縮,通常更加關注圖片讀取的延時。大量的圖片讀取會給伺服器帶來較大的壓力,壓力主要來自於圖片的解壓計算。為了提高解壓縮效率,以及充分利用公司的資源,我們未來將lepton壓縮服務以獨立的服務模式分佈於cpu空閒的伺服器,可以按照資源空閒程度,空閒時間,充分利用資源的峰谷來提高計算效能。
壓測資料:
我們選取了不同大小的圖片檔案,在單機環境下進行了壓縮與解壓縮測試,測試結果如下圖:
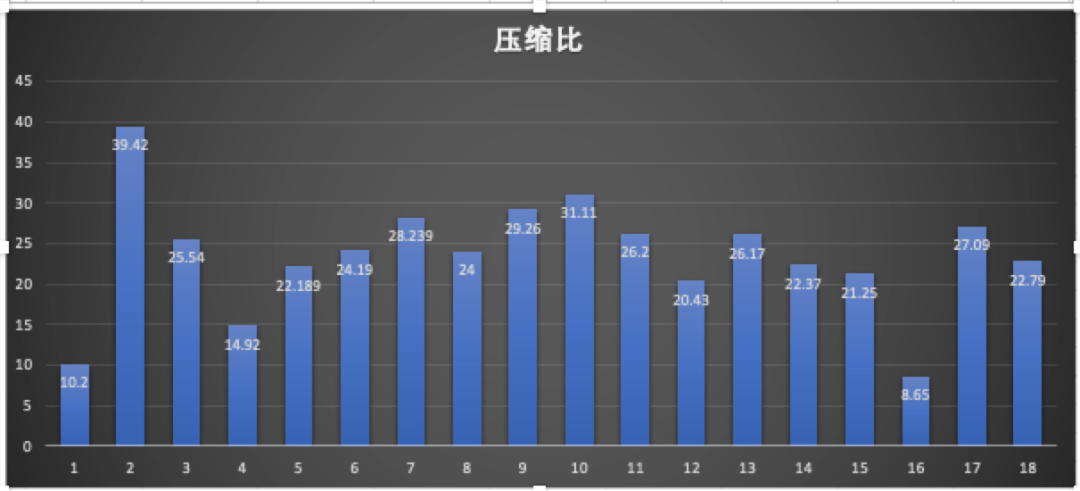
壓縮比平均保持在22%左右。
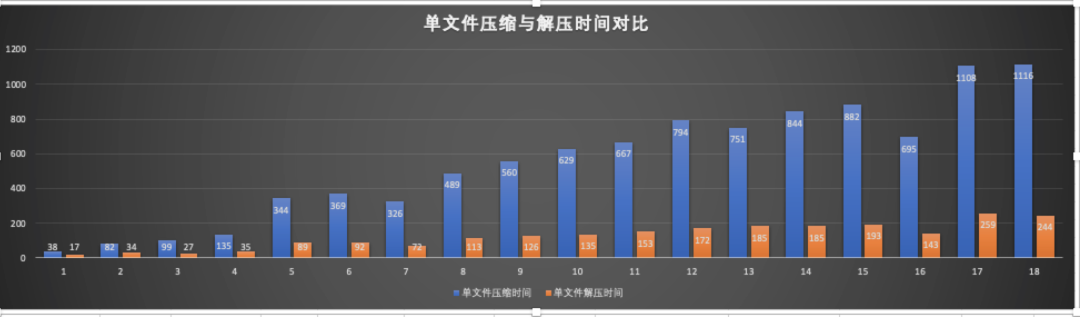
上圖是不同大小的檔案壓縮與解壓縮時間比例圖,橙色是解壓時間,藍色是壓縮時間。

上圖是不同大小的圖片,在32執行緒並行,每個執行緒處理100個檔案的測試資料。
四、 圖片壓縮的常見問題
4.1 通過檔案格式區分有損和無失真壓縮

4.2 常見的無失真壓縮演演算法

五、 總結
Lepton的無失真壓縮能夠提供比較高的壓縮比,同時不影響使用者的圖片質量和使用體驗、在巨量資料量的場景下會獲得比較明顯的收益。
不足之處是對計算效能要求較高、只支援jpeg型別的圖片。對於效能的要求行業內也都有比較成熟的解決方案,例如上文提到的FPGA和彈性計算方案。關鍵在於根據企業需求選擇合理的方案。
參照:
- 《The Design, Implementation, and Deployment of a System to Transparently Compress Hundreds of Petabytes of Image Files For a File-Storage Service》
- 《基於深度學習的JPEG影象雲端儲存研究》
- 《JPEG-Lepton壓縮技術關鍵模組VLSI結構設計研究》