爬蟲(9)
2022-07-05 12:07:45
什麼是Scrapy
- 基於Twisted的非同步處理框架
- 純python實現的爬蟲框架
- 基本結構:5+2框架,5個元件,2箇中介軟體
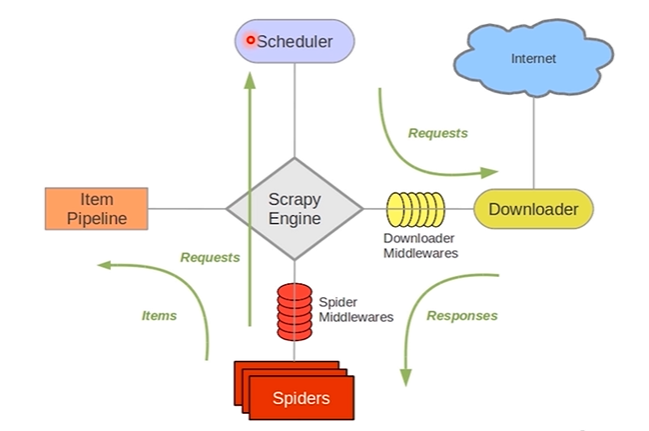
5個元件:
- Scrapy Engine:引擎,負責其他部件通訊 進行訊號和資料傳遞;負責Scheduler、Downloader、Spiders、Item Pipeline中間的通訊訊號和資料的傳遞,此元件相當於爬蟲的「大腦」,是整個爬蟲的排程中心
- Scheduler:排程器,將request請求排列入隊,當引擎需要交還給引擎,通過引擎將請求傳遞給Downloader;簡單地說就是一個佇列,負責接收引擎傳送過來的 request請求,然後將請求排隊,當引擎需要請求資料的時候,就將請求佇列中的資料交給引擎。初始的爬取URL和後續在頁面中獲取的待爬取的URL將放入排程器中,等待爬取,同時排程器會自動去除重複的URL(如果特定的URL不需要去重也可以通過設定實現,如post請求的URL)
- Downloader:下載器,將引擎engine傳送的request進行接收,並將response結果交還給引擎engine,再由引擎傳遞給Spiders處理
- Spiders:解析器,它負責處理所有responses,從中分析提取資料,獲取Item欄位需要的資料,並將需要跟進的URL提交給引擎,再次進入Scheduler(排程器);同時也是入口URL的地方
- Item Pipeline:資料管道,就是我們封裝去重類、儲存類的地方,負責處理 Spiders中獲取到的資料並且進行後期的處理,過濾或者儲存等等。當頁面被爬蟲解析所需的資料存入Item後,將被傳送到專案管道(Pipeline),並經過幾個特定的次序處理資料,最後存入本地檔案或存入資料庫
2箇中介軟體:
- Downloader Middlewares:下載中介軟體,可以當做是一個可自定義擴充套件下載功能的元件,是在引擎及下載器之間的特定勾點(specific hook),處理Downloader傳遞給引擎的response。通過設定下載器中介軟體可以實現爬蟲自動更換user-agent、IP等功能。
- Spider Middlewares:爬蟲中介軟體,Spider中介軟體是在引擎及Spider之間的特定勾點(specific hook),處理spider的輸入(response)和輸出(items及requests)。自定義擴充套件、引擎和Spider之間通訊功能的元件,通過插入自定義程式碼來擴充套件Scrapy功能。
Scrapy操作檔案(中文的):https://www.osgeo.cn/scrapy/topics/spider-middleware.html
Scrapy框架的安裝
cmd視窗,pip進行安裝
pip install scrapy

Scrapy框架安裝時常見的問題
找不到win32api模組----windows系統中常見
pip install pypiwin32
建立Scrapy爬蟲專案
新建專案
scrapy startproject xxx專案名稱
範例:
scrapy startproject tubatu_scrapy_project

專案目錄
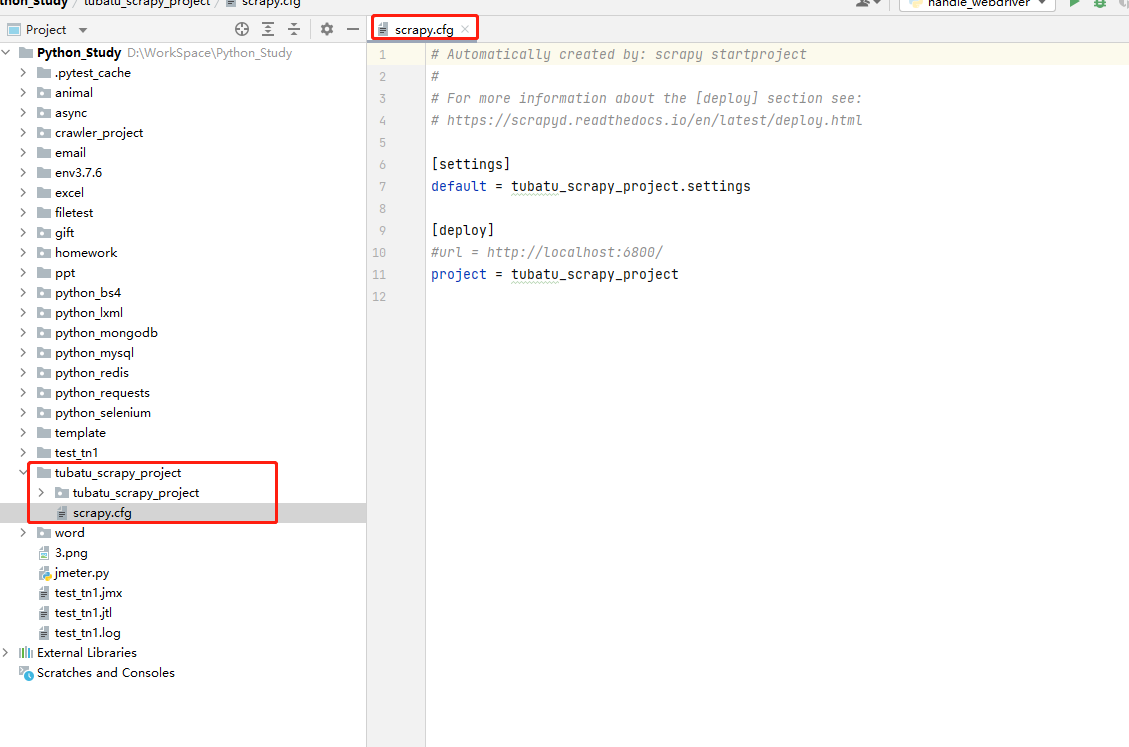
scrapy.cfg:專案的組態檔,定義了專案組態檔的路徑等設定資訊
- 【settings】:定義了專案的組態檔的路徑,即./tubatu_scrapy_project/settings檔案
- 【deploy】:部署資訊
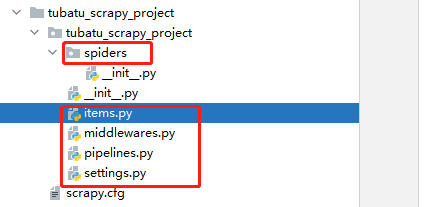
- items.py:就是我們定義item資料結構的地方;也就是說我們想要抓取哪些欄位,所有的item定義都可以放到這個檔案中
- pipelines.py:專案的管道檔案,就是我們說的資料處理管道檔案;用於編寫資料儲存,清洗等邏輯,比如將資料儲存到json檔案,就可以在這邊編寫邏輯
- settings.py:專案的設定檔案,可以定義專案的全域性設定,比如設定爬蟲的 USER_AGENT ,就可以在這裡設定;常用設定項如下:
- ROBOTSTXT_OBEY :是否遵循ROBTS協定,一般設定為False
- CONCURRENT_REQUESTS :並行量,預設是32個並行
- COOKIES_ENABLED :是否啟用cookies,預設是False
- DOWNLOAD_DELAY :下載延遲
- DEFAULT_REQUEST_HEADERS :預設請求頭
- SPIDER_MIDDLEWARES :是否啟用spider中介軟體
- DOWNLOADER_MIDDLEWARES :是否啟用downloader中介軟體
- 其他詳見連結
- spiders目錄:包含每個爬蟲的實現,我們的解析規則寫在這個目錄下,即爬蟲的解析器寫在這個目錄下
- middlewares.py:定義了 SpiderMiddleware和DownloaderMiddleware 中介軟體的規則;自定義請求、自定義其他資料處理方式、代理存取等
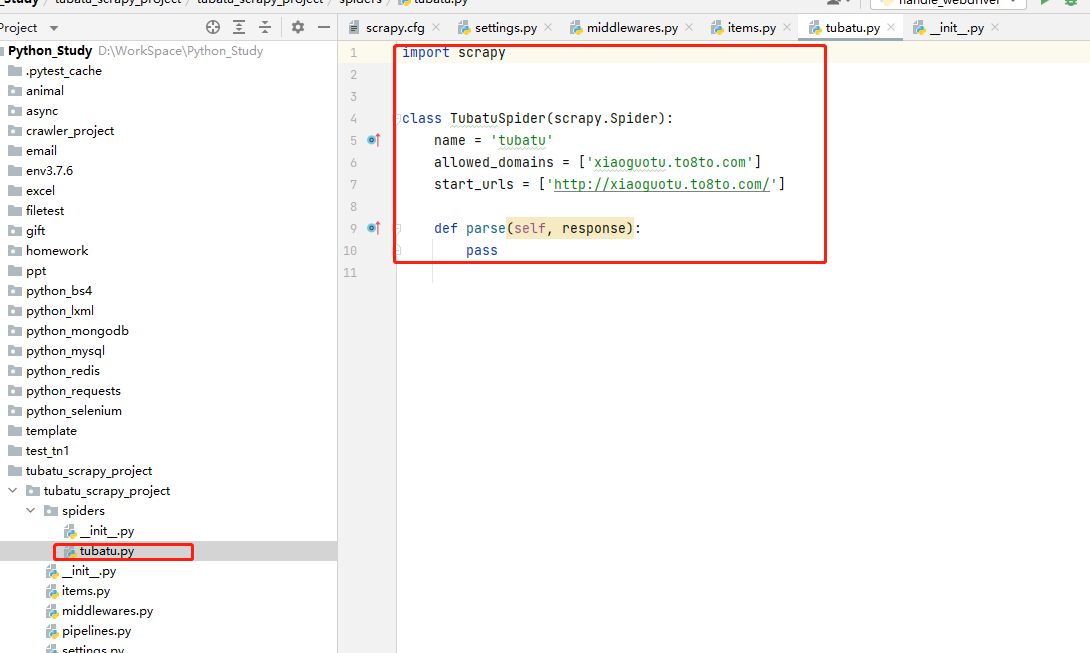
自動生成spiders模板檔案
cd到spiders目錄下,輸出如下命令,生成爬蟲檔案:
scrapy genspider 檔名 爬取的地址

執行爬蟲
方式一:cmd啟動
cd到spiders目錄下,執行如下命令,啟動爬蟲:
scrapy crawl 爬蟲名
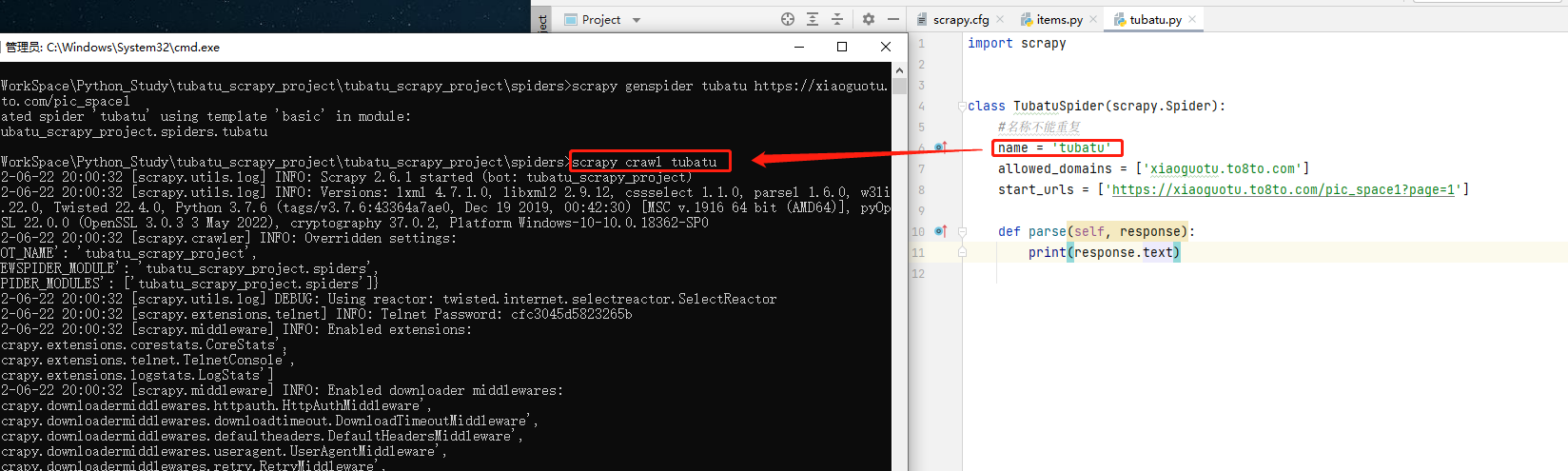
方式二:py檔案啟動
在專案下建立main.py檔案,建立啟動指令碼,執行main.py啟動檔案,程式碼範例如下:
code-爬蟲檔案