C++ 練氣期之指標所指何處
1. 指標
指標是一種C++資料型別,用來描述記憶體地址。
什麼是記憶體地址?
記憶體中的每一個儲存單元格都有自己的地址,地址是使用二進位制進行編碼。地址從形態上看是一個整型資料型別。但是,它的資料含義並不表示數位,而是一個位置標誌,類似於門牌號。

指標型別資料的算術運算:
- 在地址上
加上或減去一個正整數,表示向前或向後移動地址。移動地址的意義:可實現從一個儲存位置到達另一個儲存位置。 - 地址與地址之間也可以相減,表示兩個地址之間的差距。
- 地址與地址之間不可以相加、相乘、相除運算。對地址進行相加、相乘、相除類似門牌號門牌號之間相加、相乘、相除,沒有任何意義可言。
2. 指標變數
變數是一個儲存塊,為了能存取到變數中的資料,開發者需要為變數指定一個名字,即變數名。編譯器會在分配變數後,把變數和變數名進行關聯。
變數名和變數地址有什麼關係?
變數名是變數的邏輯地址,由開發者提供。而變數地址是變數的實體地址,指變數在記憶體中的具體位置。如下宣告語句,在編譯時,編譯器會做一些細碎的底層工作。
int num=20;
- 根據資料型別的約定,在
記憶體中找到一個可用的記憶體塊。int一般大小為4B。 - 獲取到記憶體塊的實體地址,並把實體地址和開發者提供的變數名(邏輯名)進行關聯,並儲存在對映表中。
- 把數位
20儲存在num變數中。
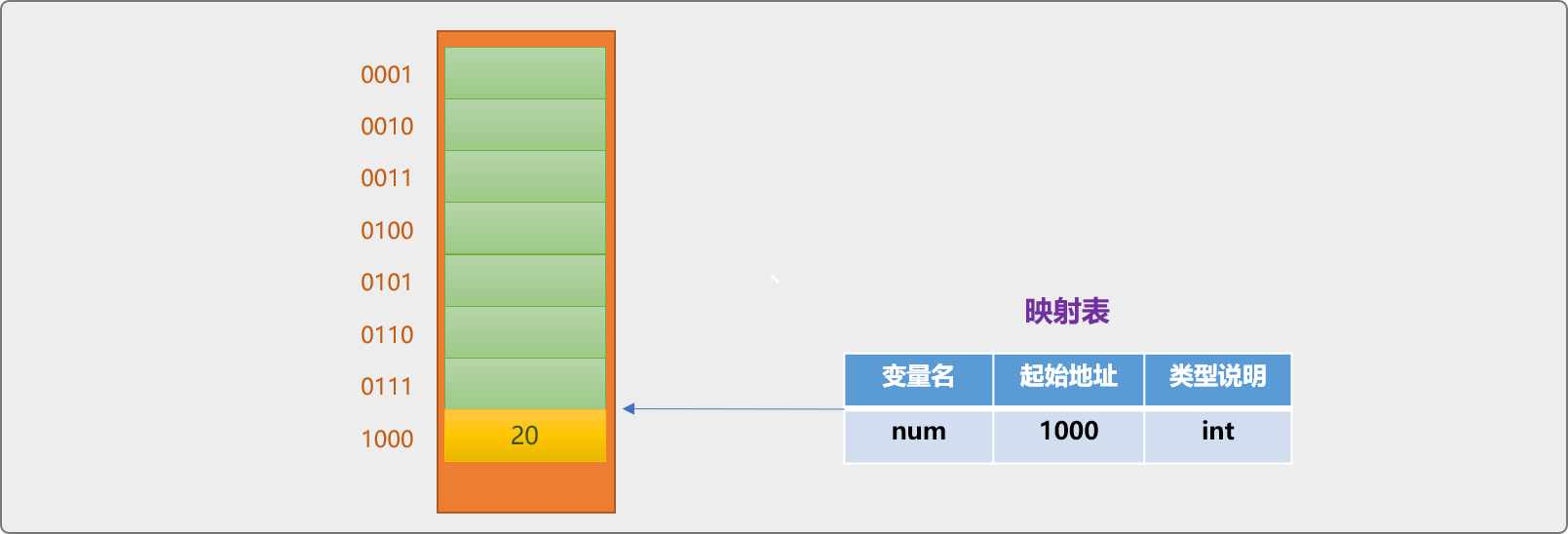
在使用 num存取變數時,需要藉助對映表,找到變數名對應的記憶體地址,方能存取變數中的資料。變數名是變數地址的邏輯名。
std::cout<<num;
//輸出結果:20
能不能獲取到變數在記憶體的地址,通過地址存取變數?
當然可以,前提是需要宣告一個指標變數,儲存變數的實體地址。
用來儲存地址(指標)型別資料的變數稱為
指標變數。
指標變數也是記憶體中的一個儲存塊,只是變數中儲存的是另一個變數在記憶體中的地址。如下程式碼,儲存 num變數在記憶體的地址。
//整型型別變數
int num=20;
//指標型別的變數
int* num_p=#
程式碼說明:
int *表示指標型別。宣告指標變數時,需要指定變數是用來儲存指標型別資料。
int *表示指標變數是用來儲存一個int型別變數的地址,並不是指變數用來儲存一個整型資料。
&運運算元,取地址運運算元。&num表示獲取num變數的記憶體(物理)地址。
既然是變數,指標變數在記憶體也有屬於自己的儲存位置。如下圖所示,只是指標變數中儲存的是地址資訊。
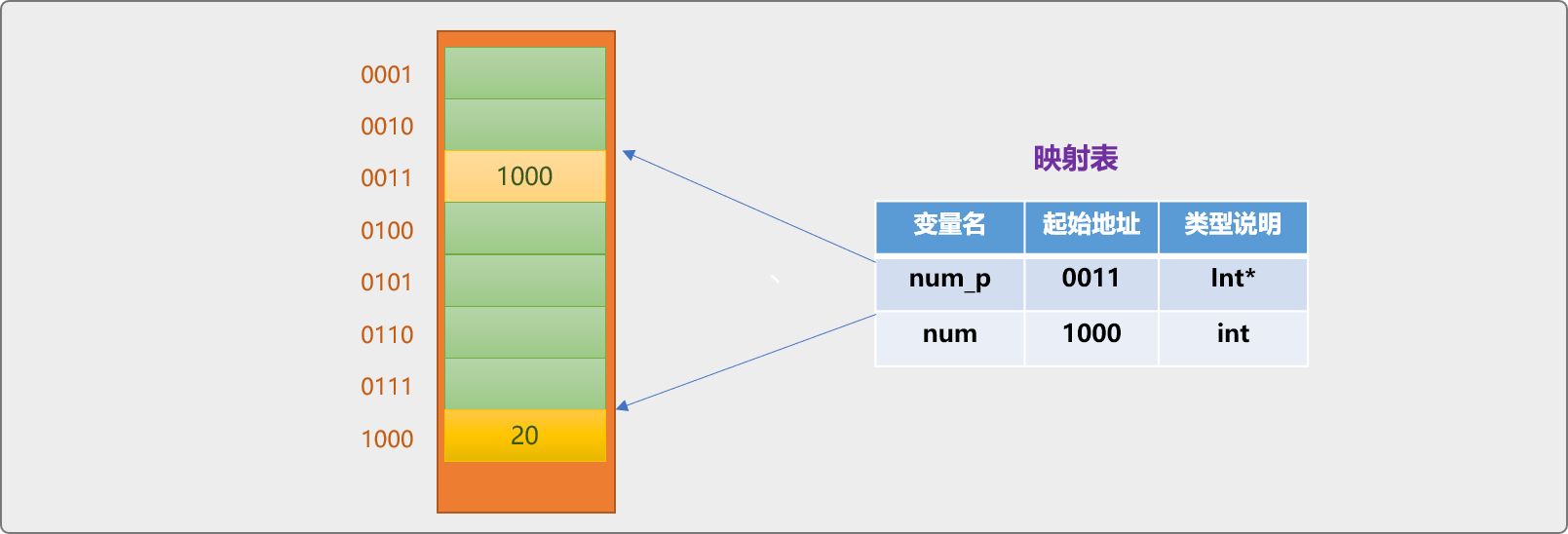
指標變數實際佔用記憶體大小是多少,由底層編譯器決定。
如何通過指標變數中的地址存取 num 變數?
如下程式碼,先試著直接輸出指標變數 num_p 中的資料。
std::cout<<num_p;
輸出結果:0x70fe14。很明顯這是記憶體地址的 16進位制格式,也證實指標變數中儲存的是地址。
千萬別問我為什麼輸出的不是
1000。圖片只是一個演示。
有了這個地址後,可以通過這個地址存取num變數中的資料。
std::cout<<*num_p;
//輸出:20
需要注意:在宣告和通過地址存取資料時,都要使用 *符號:
- 宣告時
*表示指標型別。int* num_p; - 使用指標變數時,表示通過地址找到變數中的資料。
*num_p 和 num是存取同一個變數的兩種方案。前者是使用物理名(記憶體地址)存取變數的語法,後者是使用邏輯名(變數名)存取變數。
同樣的也能夠使用指標變數對其參照的變數進行賦值。
int num=20;
int* num_p=#
//通過指標變數賦值,和 num=30 等同
*num_p=30;
std::cout<<*num_p<<std::endl;
std::cout<<num<<std::endl;
//輸出結果:
30
30
3. 幾個問題
3.1 為什麼要使用指標變數
在使用指標變數時,總會有一個疑問,既然能夠使用變數名存取變數,為什麼還要搞一個指標變數。指標變數不僅要佔用記憶體空間,且語法繁瑣,是不是有點囉嗦了。
其實,指標變數是C系列語言的特色,是演化過程中保留下來的原始特性:
- 存取速度。
指標存取是直接硬體存取,速度較快。
遍歷陣列時,通過指標的加法、減法運演演算法則,可以向前或向後快速移動指標。
int nums[4]={1,2,3,4};
int* nums_p=nums;
for(int i=0;i<4;i++){
std::cout<<*(nums_p+i)<<std::endl;
}
//輸出
1
2
3
4
陣列變數本質是指標變數,儲存著陣列在記憶體中的首地址。所以在把陣列的地址賦值另一個指標變數時,int* nums_p=nums;是不需要使用&符號的。
上述程式碼nums_p+i讓指標變數能加上一個正整數,實現指標的移動,這裡要注意,加上 1 不是表示只移動一個儲存單元格,而是移動int大小。
如果知道資料在陣列中的位置,可以直接在首指標基礎上加上一個移動單位,便能快速存取陣列中的資料。
- 存取
new建立的記憶體塊。
如下語句:
int *num01=new int;
new運運算元會在堆中開闢一個用來儲存int型別資料的儲存塊,返回儲存塊的記憶體地址(指標型別資料) ,這時只能使用指標變數儲存,並且通過指標變數使用這個儲存塊 。
指標變數的存在為使用堆提供了必要條件,C++稱堆為動態記憶體區域,開發者可隨時根據自己的需求在程式執行時申請、使用。
理論上講,編譯器也可以讓開發者提供變數名,然後把變數名和
new返回的地址進行對映。顯然,省略對映環節,直接指標存取,即減輕了編譯器的負擔,又提升了存取速度。
int *num01=new int;
*num01=40;
std::cout<<*num01<<std::endl;
//輸出:40
- 使用指標變數作為函數的引數,用來影響函數呼叫處變數中的值。
如果現在有一個需求,使用一個函數交換 2 個變數中的資料。先看一下下面的程式碼是否能實現這個效果。
#include <iostream>
//交換函數
void swap(int num1,int num2){
int tmp=num1;
num1=num2;
num2=tmp;
}
int main(int argc, char** argv) {
int num1=20;
int num2=30;
std::cout<<"交換前:"<<num1<<":"<<num2<<std::endl;
swap(num1,num2);
std::cout<<"交換後:"<<num1<<":"<<num2<<std::endl;
return 0;
}
輸出結果:
交換前:20:30
交換後:20:30
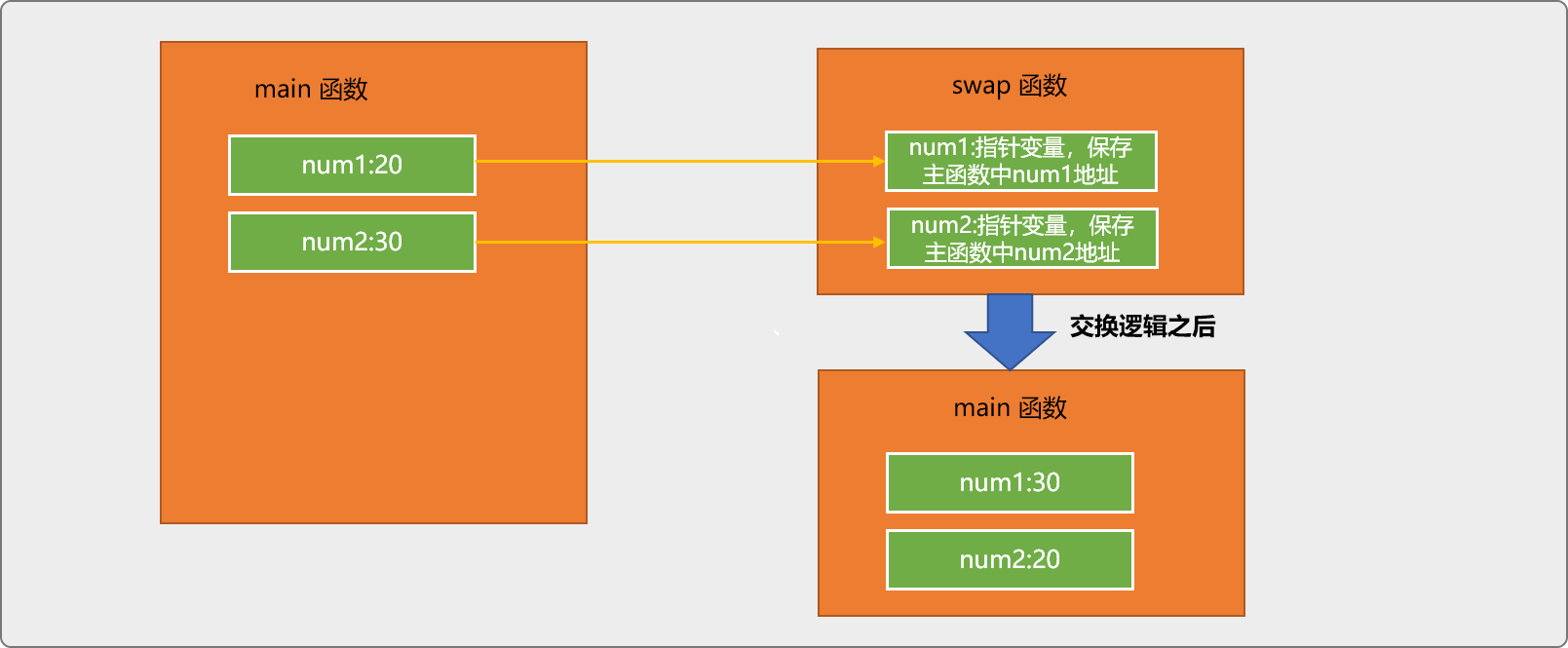
主函數中的 num1和num2變數中的資料根本沒有交換。
原因在於呼叫函數swap時,引數是值傳遞。所謂值傳遞,指把主函數中num1和num2變數的值傳遞給swap函數中的 num1和num2變數。swap的交換邏輯僅修改了自身 2 個變數中的值。
如下圖所示,主函數變數中的資料沒有改變。

如果希望通過呼叫swap後直接修改主函數中num1和num2中的值,可以使用指標變數作引數。
#include <iostream>
//形參為指標型別
void swap(int* num1,int* num2){
//*num1 通過地址存取主函數中的 num1 變數
int tmp=*num1;
//交換的是主函數中變數中的值
*num1=*num2;
*num2=tmp;
}
int main(int argc, char** argv) {
int num1=20;
int num2=30;
std::cout<<"交換前:"<<num1<<":"<<num2<<std::endl;
//主函數把變數的地址傳遞給 swap 函數
swap(&num1,&num2);
std::cout<<"交換後:"<<num1<<":"<<num2<<std::endl;
return 0;
}
輸出結果:
交換前:20:30
交換後:30:20
指標作為引數,傳遞的是變數地址,意味著,swap函數中兩個變數參照了主函數中兩個變數的實體地址。可以實現修改主函數中變數值的目的。
相當於主函數把變數房間的鑰匙傳遞給
swap函數,swap再使用鑰匙進入主函數中的變數,進行資料維護。
3.2 指標潛在的風險
3.2.1 初始化風險
必須初始化: 如下程式碼,編譯器不會報任何錯誤,但實際上是沒有任何意義的程式碼。
int* p;
std::cout<<p<<std::endl;
std::cout<<*p<<std::endl;
輸出結果:
0x40ebd9
264275272
當宣告指標變數 p時,如果沒有指定初始值,編譯器會隨意指定一個值。指望把這個值當成一個有效地址,是沒有意義的。如果把這指標變數用於程式碼邏輯,會產生無中生有的資料,顯然是違背資料的準確性和可靠性。
所以,在宣告指標變數後,一定要對其進行初始化。
不能使用整型常數初始化: 使用整型數位常數初始化指標變數,編譯層面是通不過的。
//語法錯誤
int* p=0x40aed9;
0x40aed9即使是一個有效的記憶體地址資料,因為型別不同,也不能把整型資料賦值給一個指標型別變數。
但是,可以強制型別轉換後再賦值。
地址形態上是數位,也僅是形態上是,本質上不是數位型別,不具有數位語意,也不具有數位運算操作能力,不能把地址型別與數位型別混淆。
//正確
int* p=(int*)0x44eb99;
雖然,通過強制轉換可以成功初始化指標變數,但是存在潛在風險:
0x44eb99地址不一定是一個有效的地址。0x44eb99即使是一個有效地址,有可能此地址正被其它變數使用。如此,你便修改了其它變數的值。誤打誤撞,跑到了別人家裡。
如下程式碼,本意並不是想讓p儲存score變數的記憶體地址。如果恰好0x70fddc就是score的記憶體地址。則通過*p對變數的修改最終會導致score變數中的資料被修改。
int score=89;
//本意是想使用一個空閒的空間,誤打誤撞參照了 score 的地址
int* p=(int*)0x70fddc;
//會修改 score 中的值
*p=56;
std::cout<<score<<std::endl;
std::cout<<*p<<std::endl;
//輸出
56
56
可以認為指標存取是變數名存取的另一種形式,所以在初始化指標變數時, 需要使用 &或 new 運運算元合理計算出來的地址。指標變數必須是一個已經存在的、合法變數的記憶體地址。
型別一致初始化: 如下程式碼是錯誤的,千萬不要認為會發生自動型別轉換。num_p只能參照double型別變數的地址,這是語法層面約定。
int num=34;
//語法錯誤,宣告指標時的資料型別,嚴格規定了指標變數能參照的變數型別
double* num_p=#
3.2.2 越界風險
指標越界: 指指標移動到了非法區域,如下程式碼:
int num=34;
int* num_p=#
std::cout<<"正常輸出:"<<*num_p<<std::endl;
//指標移到了一個沒有宣告的區域
std::cout<<"移動指標輸出:"<<*(num_p+1)<<std::endl;
輸出結果:
正常輸出:34
移動指標輸出:7405060
雖然指標變數可以通過加上一個整型數位進行移動。但是一定要控制合法範圍,否則會發生如上的非法存取,非法存取到的資料一旦用於資料邏輯,會存在很大的風險。
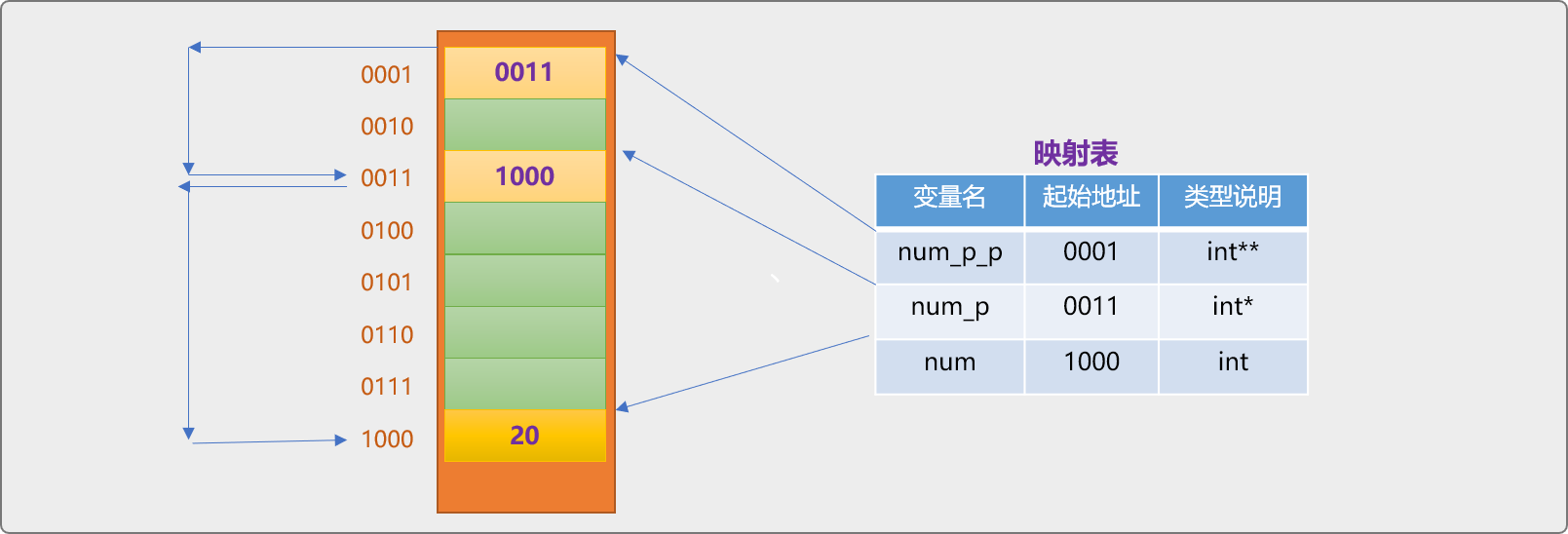
3.3 多級指標
指標變數本身也是一個儲存塊,它所在記憶體地址是否還可以儲存在另一個指標變數中?
顯然,這是可以的,如下程式碼:
//宣告常規變數
int num=20;
//一級指標變數:用來儲存 num 變數的地址
int* num_p=#
//二給指標變數,用來儲存 num_p 變數的地址
int** num_p_p=&num_p;
int**表示二級指標型別,本質還是記憶體地址,是另一個指標變數的記憶體地址。
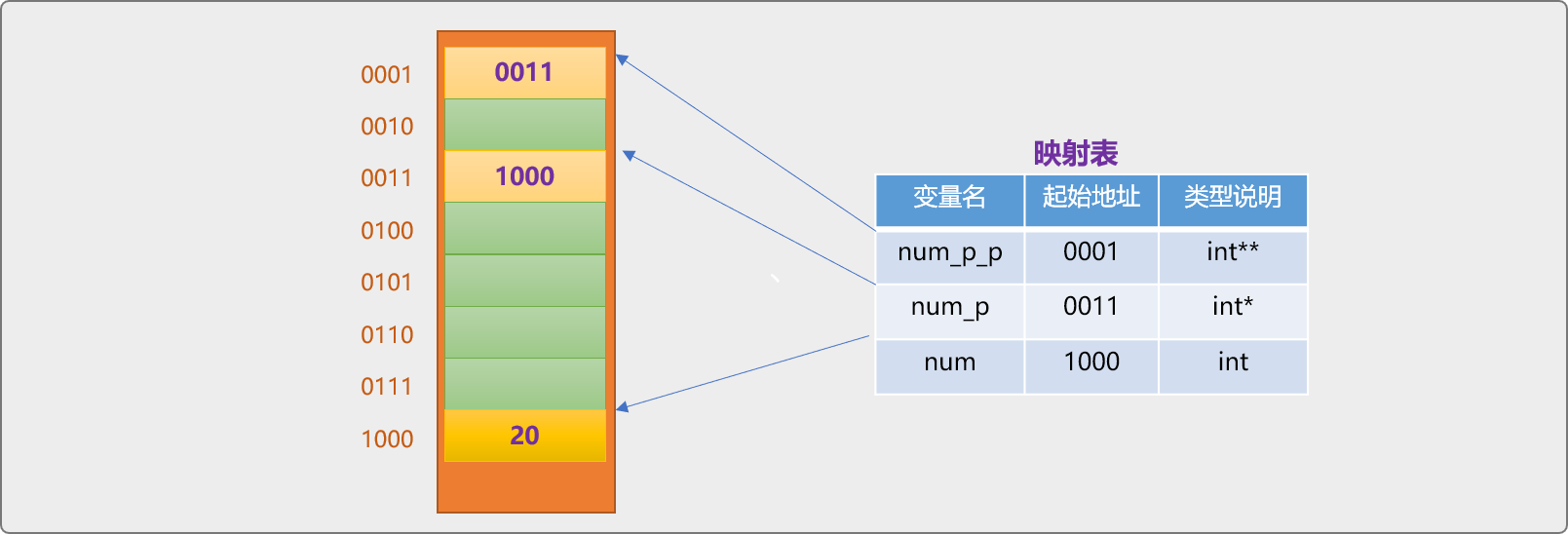
使用二級指標存取 num變數中的資料。
//……
*(*num_p_p)=30;
std::cout<<"輸出:"<<num<<std::endl;
程式碼解釋:
*num_p_p獲取到num_p變數中的記憶體地址值1000。*(*num_p_p)利用上面返回的1000地址,找到變數num位置,並返回變數num的值。
同理可以使用多維指標,如下是三維指標。
int num=20;
int* num_p=#
int** num_p_p=&num_p;
int*** num_p_p_p=&num_p_p;
*(*(*num_p_p_p))=30;
std::cout<<"輸出:"<<num<<std::endl;
//輸出:30
4. 總結
雖然可以通過使用指標提升記憶體的存取效能,但也因存在指標的自由性,易出現潛在風險。如JAVA在語法層面對指標使用做了限制,權衡利弊,雖然消弱了指標的自由性,同時也降低了程式碼的潛在風險。