一文講明白K8S各核心架構元件
一、寫在前面
K8S的文章很多人都寫過,若要想好好研讀,系統的學習,真推薦去看官方檔案。但是若是當上下班路上的爽文,可以看下我的筆記,我也會盡力多寫點自己的理解進來。
推薦手機閱讀原文,有動態表情圖,閱讀體驗感更佳:https://mp.weixin.qq.com/s/bL-85BhOj8H5Dis_94lmrQ
推薦手機閱讀原文,有動態表情圖,閱讀體驗感更佳:https://mp.weixin.qq.com/s/bL-85BhOj8H5Dis_94lmrQ
推薦手機閱讀原文,有動態表情圖,閱讀體驗感更佳:https://mp.weixin.qq.com/s/bL-85BhOj8H5Dis_94lmrQ
二、K8S為我們提供了怎樣的能力
大家都知道Docker,我們可以將自己的應用打包製作成Image,然後通過docker run命令將Image啟動成Container對外提供服務。
點選檢視白日夢的視訊教學-二十分鐘徹底搞懂Docker網路!
基於此,K8S不僅能將使用者提供的單個容器執行起來,將其對外暴露出去提供服務。還提供了:路由閘道器、叢集監控、災難恢復,以及應用的水平擴充套件等能力。
大家常聽過一個詞:微服務、雲原生應用,如何理解這個詞自然也是見仁見智。
如下圖是SpringCloud的架構圖:
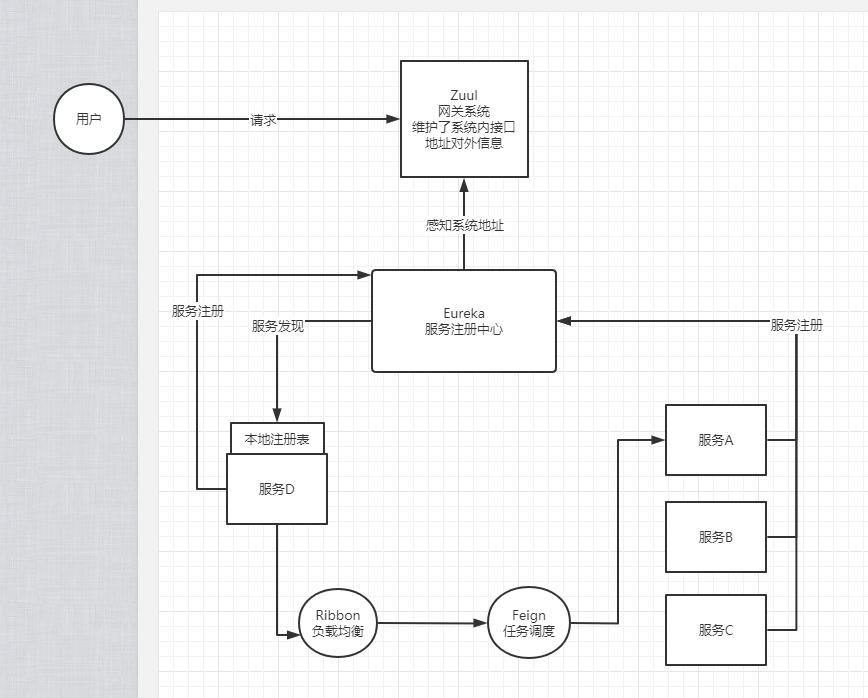
在SpringCloud中有不同的元件,諸如提供服務發現能力的:Eureka、提供負載均衡機制的Ribbon、以及微服務的統一入口Zuul,基於這套框架做過開發的同學都知道,無論是Eureka還是Zuul,無論開發量大小,都需要程式設計師開發相應的程式碼,即使這些程式碼和業務本身並沒有什麼關係。
而在K8S中,像Eureka的服務發現能力,Zuul的閘道器能力、以及Ribbon的負載均衡能力,K8S都是原生支援的,開發人員只需要寫好自己的業務程式碼,提供一個可執行的jar包,或者二進位制檔案即可部署進K8S中就行
當然不僅於此,K8S的服務網格元件如:Istio還提供了流量治理能力,比如按不同的請求頭做不同比例的流量分發排程、亦或者是金絲雀釋出。
說起容器編排,像Docker的Compose或者是Docker-Swarm都提供了簡單的容器編排的能力。
點選檢視白日夢的-玩轉Docker容器編排-DockerCompose、Docker-Swarm
像Docker-Compose或者Docker-Swarm的通病就是過於以Docker核心,提供的能力也過於簡單比如定義誰先啟動誰後啟動。無法滿足比較複雜的場景
而K8S的容器編排設計是站在更高的維度,Docker對於K8S而言只是執行它編排產出的媒介,K8S針對不同的編排場景提供了不同的編排資源物件,如提供Deployment編排無狀態應用,提供了Cronjob編排定時任務,提供了StatefulSet編排ES、Redis叢集這種有狀態應用等等,這都是前者所不能及的....
三、架構
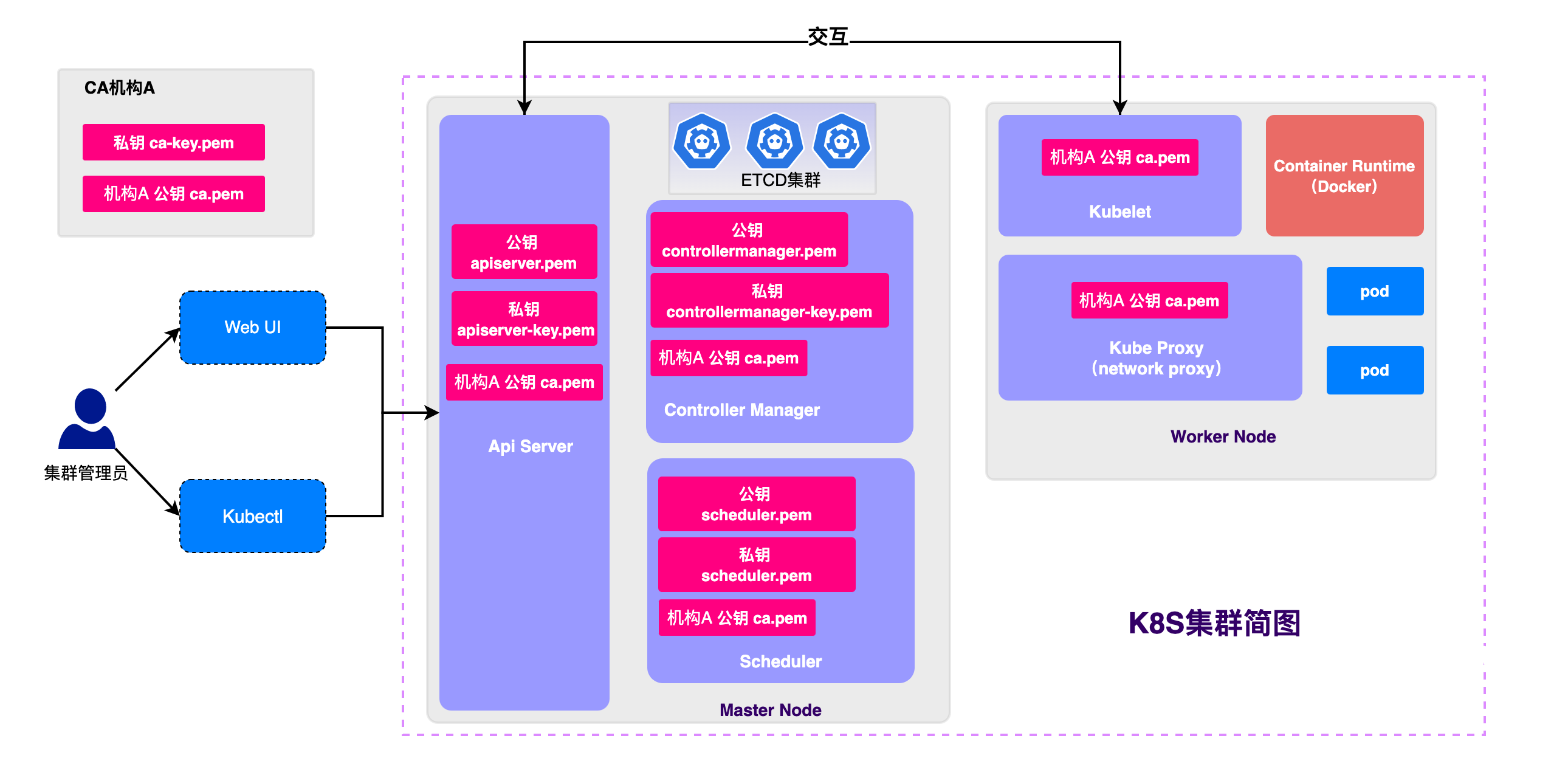
K8S架構簡圖如上,分為MasterNode、WorkNode兩大部分和五大元件,一開始接觸這些概念難免會有些陌生,但是本質上這些元件都是K8S的開發者對各種能力的抽象和封裝,下文會展開介紹
tip:上圖中很多xxx.pem檔案是K8S的https安全認證依賴的證書,想進一步瞭解原理可以閱讀這篇筆記:十二張圖,從零禮哦啊姐對稱加密/非對稱加密/CA認證/以及K8S各元件證書頒發原由
3.1、MasterNode
和Redis或者Nginx這種由二進位制檔案啟動後得到一個對外提供服務的守護行程不同,K8S中的MasterNode其實並不是一個二進位制檔案啟動後得到的對外提供服務的守護行程,它本質上是一個抽象的概念。
MasterNode包含3個程式,分別是:
- ApiServer
- 提供HTTP Rest介面,是叢集中各種核心資源的CRUD的統一入口,是叢集中各個元件互動的核心樞紐
- 叢集資源配額的統一入口
- 提供了完備的叢集安全機制
- ControllerManager
- 實時監控叢集中如Service等各種資源的狀態變化,不斷嘗試將它們的副本數量維持在一個期望的狀態。
- Scheduler:
- 負責排程功能,如:為Pod找到一個合適的宿主機器
3.2、WorkerNode
和MasterNode類似,WorkerNode本質也並不是一個獨立的應用程式,它包含兩個元件,如下
- kubelet
- Node節點管理
- Pod管理,同容器執行時互動下發容器的建立/關閉命令
- 容器健康狀態檢查
- kube-proxy
- 通過為Service資源的ClusterIP生成iptable或ipvs規則,實現將K8S內部的服務暴露到叢集外面去
既然WorkNode也是抽象的概念,那麼若在MasterNode啟動kube-proxy和kubelet程序,那麼MasterNode也會擁有WorkNode的能力,雙重角色,但生產環境不推薦這樣搞。
四、核心元件
4.1、ApiServer
4.1.1、概述
APIServer有完備的叢集安全驗證機制,提供了對K8S中如Pod、Service等資源CRUD等HttpRest介面,是叢集中各個元件之間資料互動的核心樞紐。
4.1.2、是叢集管理API的統一入口
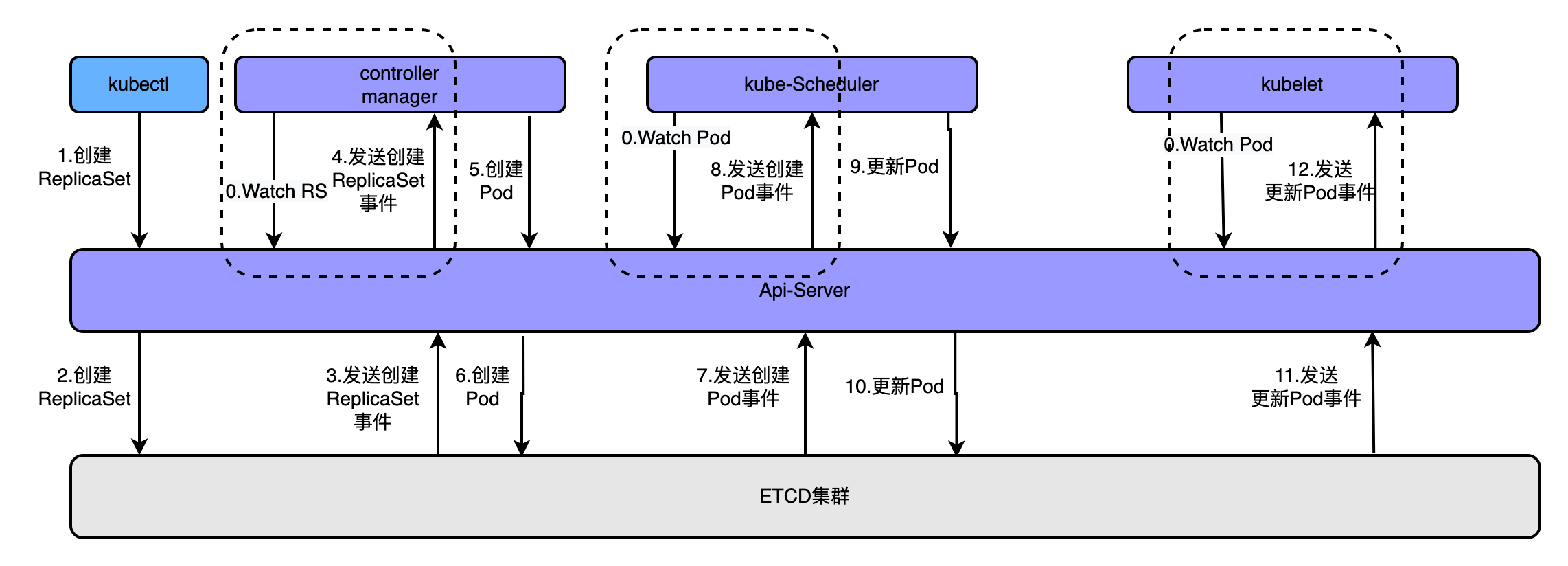
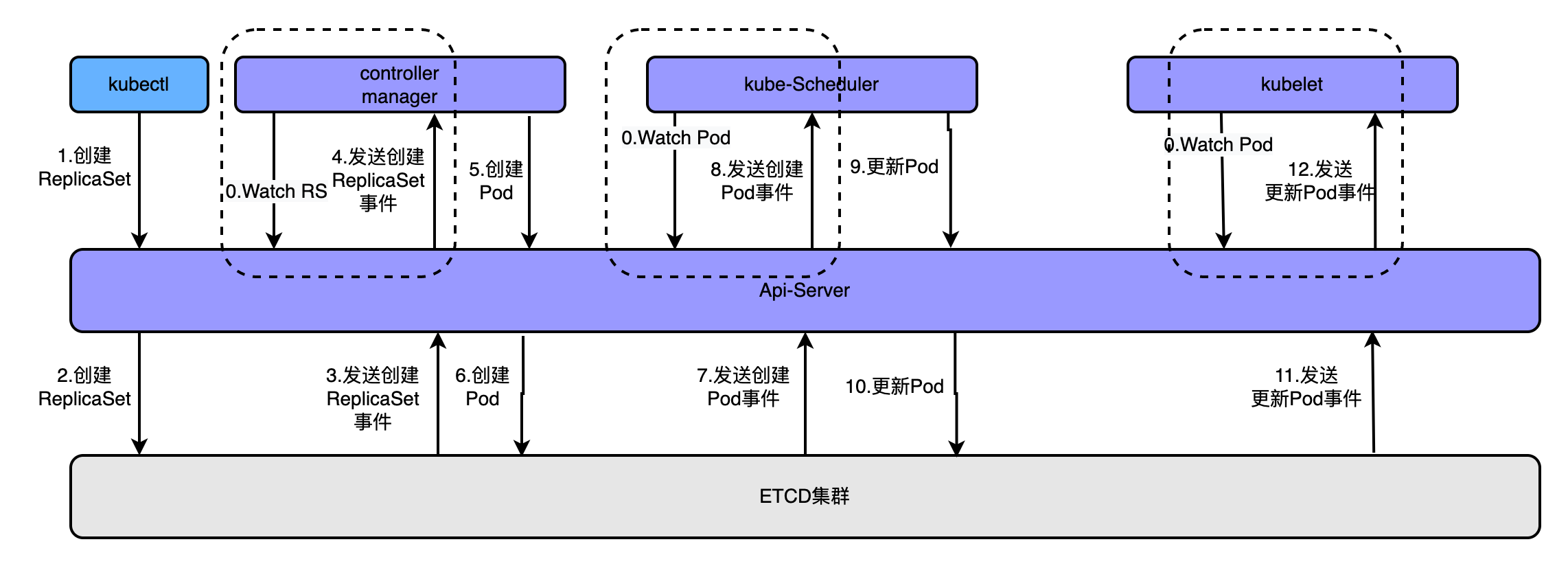
為了更好的理解這個概念可以看如下圖

通過kubectl命令執行建立kubectl apply -f rs.yaml建立pod時,經歷的流程如上圖,大概流程為
- apiserver接收kubectl的建立資源的請求
- apiserver將建立請求寫入ECTD
- apiserver接收到etcd的回撥事件
- apiserver將回撥事件傳送給ControllerManager
- controllerManager中的ReplicationController處理本次請求,建立RS,然後它會調控RS中的Pod的副本數量處於期望值,比期望值小就新建立Pod,於是它告訴ApiServer要建立Pod
- apiserver將建立pod的請求寫入etcd叢集
- apiserver接收etcd的建立pod的回撥事件
- apiserver將建立pod的回撥事件傳送給scheduler,由它為pod挑選一個合適的宿主node
- scheduler告訴apiserver,這個pod可以排程到哪個node上
- apiserver將scheduler告訴他的事件寫入etcd
- apiserver接收到etcd的回撥,將更新pod的事件傳送給對應node上的kubelet程序
- kubelet通過CRI介面同容器執行時(Docker)互動,維護更新對應的容器。
4.1.3、提供了完備的安全認證機制
ApiServer採用https+ca簽名證書強制雙向認證,也就說是想順利存取通ApiServer的介面需要持有對應的證書
進一步瞭解Https/CA原理可以閱讀這篇筆記:十二張圖,從零理解對稱加密/非對稱加密/CA認證/以及K8S各元件證書頒發原由
4.1.4、典型使用場景
比如在K8S內部搭建一個Elasticsearch的叢集,每個pod中執行一個Pod,想搭叢集的前提是得先知道有哪些執行著ES的Pod的ip地址。獲取的途徑只有一個:問ApiServer要。
那應用程式怎麼知道ApiServer的地址呢?如下:
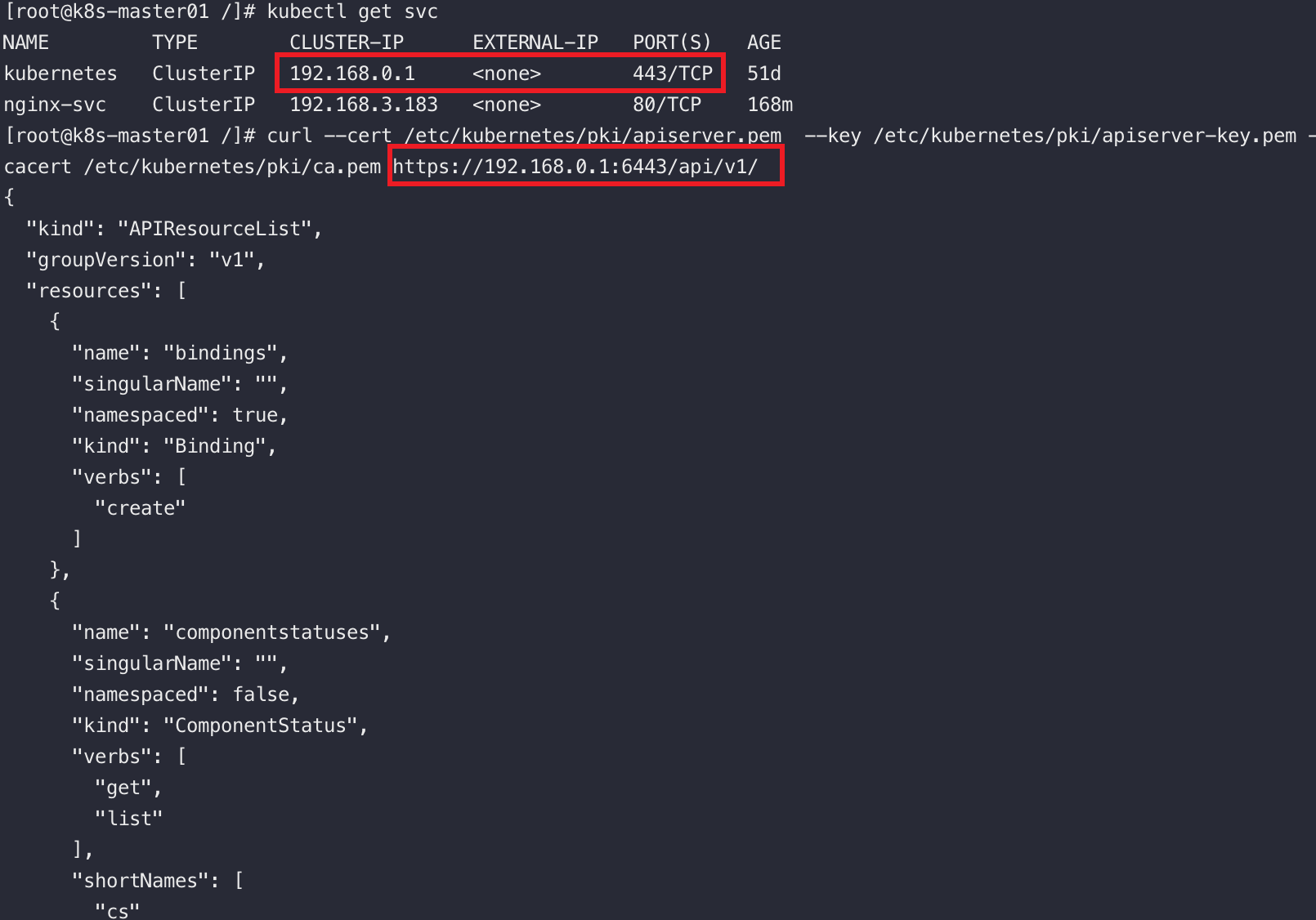
K8S中的Service佔用單獨的網段(啟用ipvs的前提下,我的service網段為:192.168.0.0)
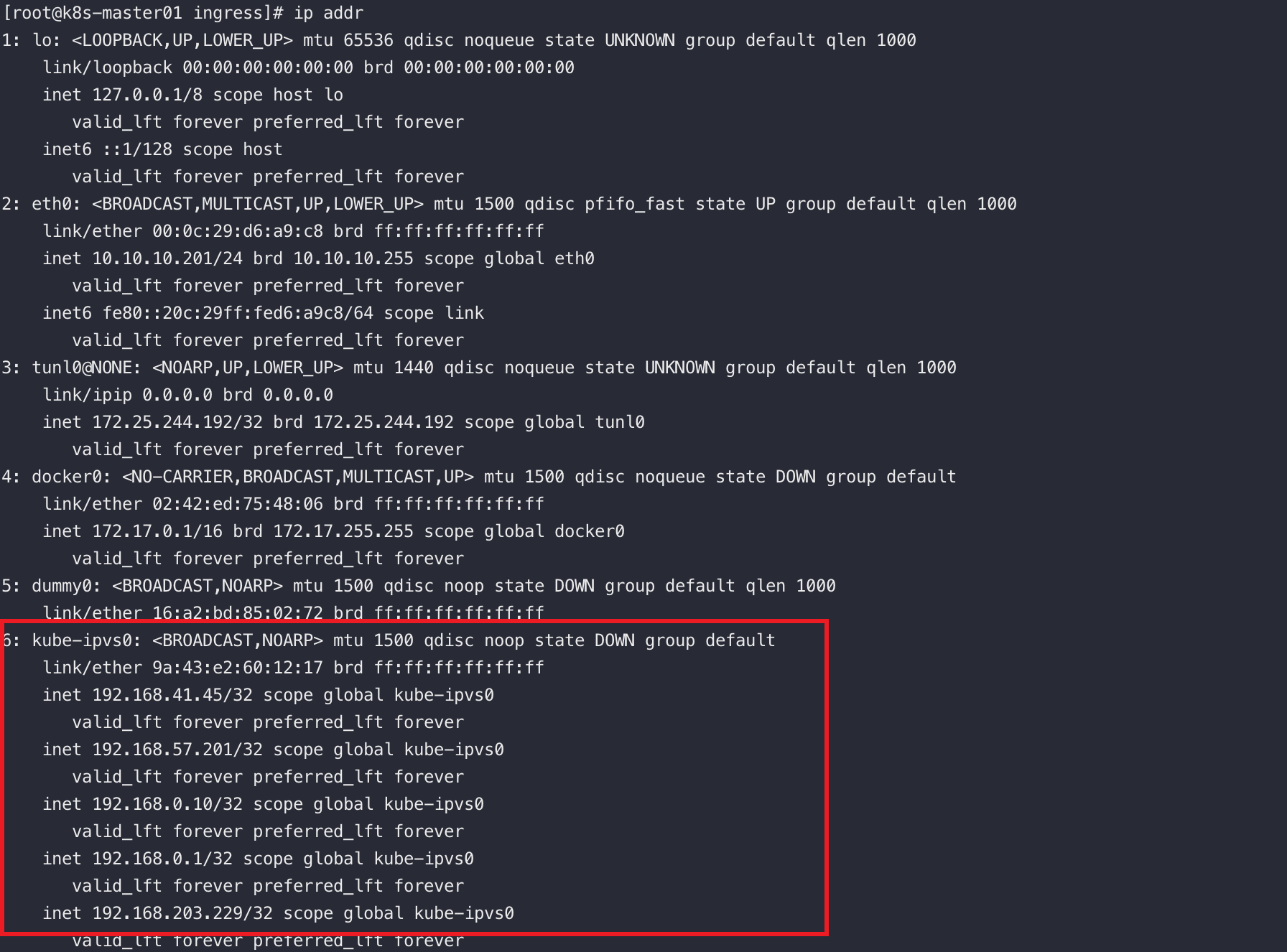
當我們安裝完K8S叢集後,在default名稱空間中會有個預設的叫kubernetes的Service,這個service使用的service網段的第一個地址,而且這個service是ApiServer的service,換句話說,通過這個service可以存取到apiserver

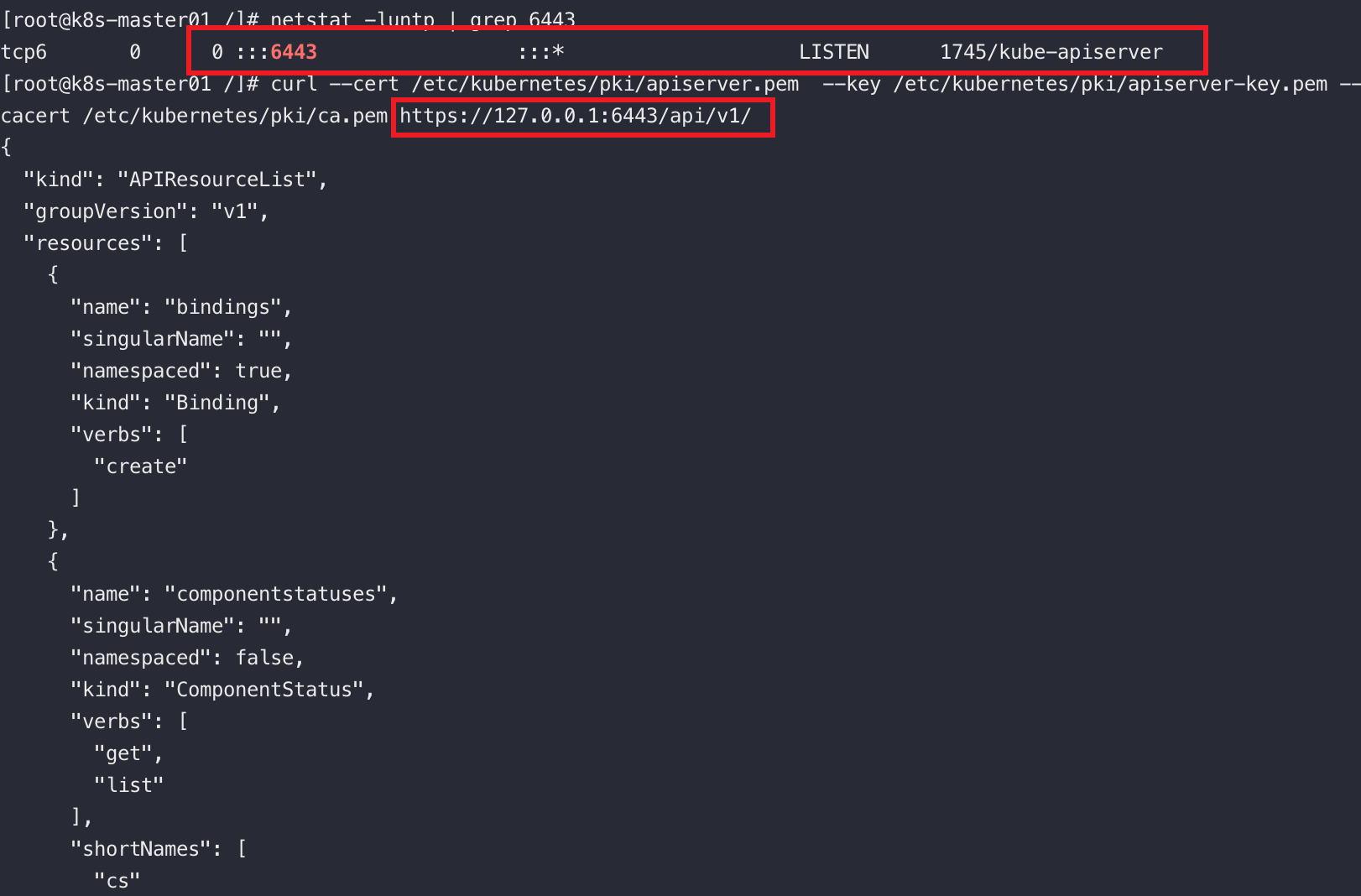
可以通過如下命令存取到原生的apiserver
curl --cert /etc/kubernetes/pki/admin.pem \
--key /etc/kubernetes/pki/admin-key.pem \
--cacert /etc/kubernetes/pki/ca.pem https://127..0.1:6443/api/v1/
將回環地址換成名為kubernetes的service的cluster-ip也能存取到api-server
curl --cert /etc/kubernetes/pki/admin.pem --key /etc/kubernetes/pki/admin-key.pem --cacert /etc/kubernetes/pki/ca.pem https://192.168.0.1:6443/api/v1/
4.1.5、Api Proxy介面
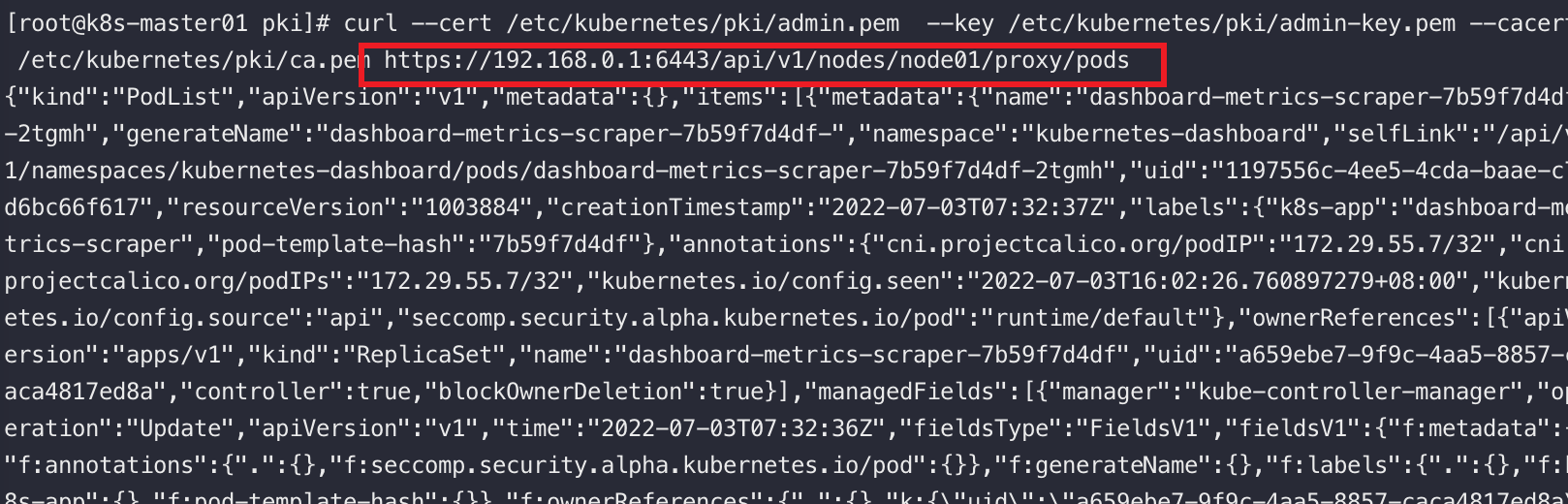
ApiServer提供了一種特殊的Restful介面,它本身不處理這些請求而將請求轉發給對應的Kubelet處理
如:關於Node相關的介面
# 查詢指定節點上所有的pod資訊
/api/v1/nodes/{nodename}/proxy/pods
# 查詢指定節點上物理資源的統計資訊
/api/v1/nodes/{nodename}/proxy/stats
# 查詢指定節點上的摘要資訊
/api/v1/nodes/{nodename}/proxy/spec
更多介面查詢官網~
關於Pod的介面
# 存取pod
/api/v1/namespace/{namespace-name}/pods/{name}/proxy
# 存取pod指定路徑
/api/v1/namespace/{namespace-name}/pods/{name}/{path:*}
4.2、ControllerManager
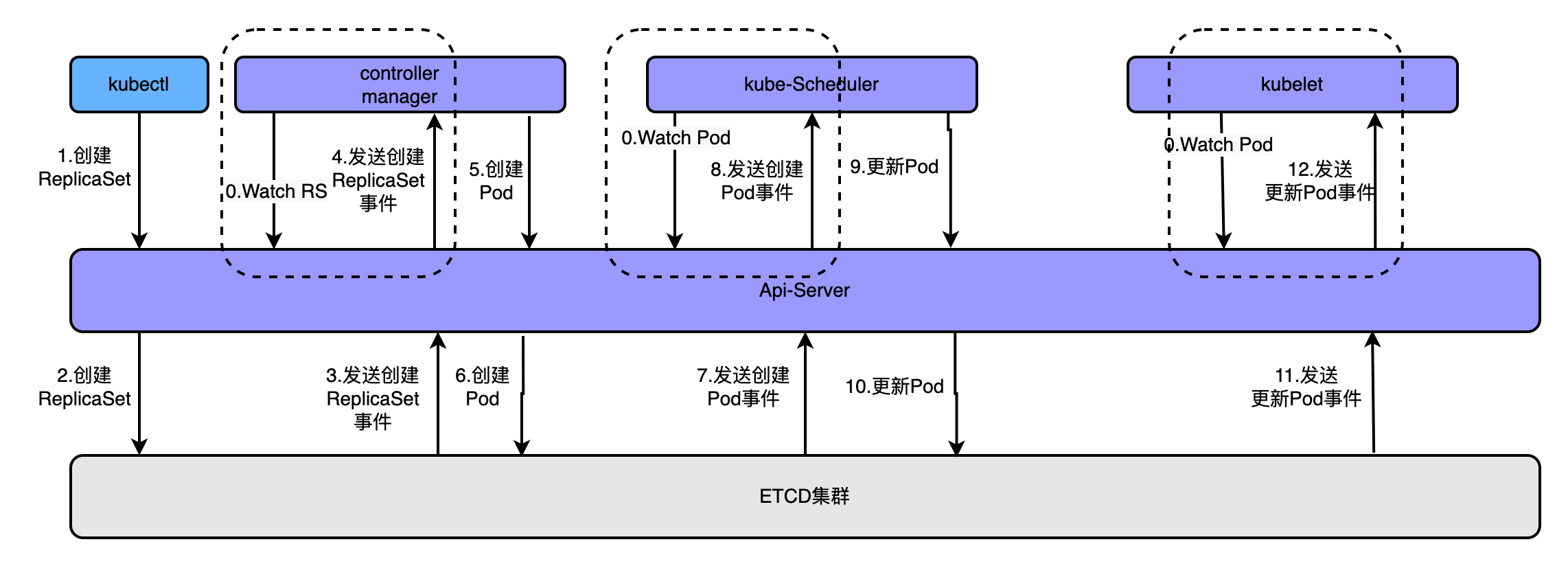
藉助上圖理解Controller的作用,它是K8S自動化管理各類資源的核心元件,所謂的自動化管理,其實就是實時監控叢集中各類資源的狀態的變化,不斷的嘗試將各類資源的副本數調整為期望值~
ControllerManager細分為8種Controller,如下
4.2.1、Replication Controller
- 確保任何時候ReplicaSet管理的Pod副本數量都為期望值
- 實際值高於期望值告訴apisever應該關閉多餘的pod,反之亦然
- 只有當Pod的重啟策略為Always,Replication Controller才會管理
- Replication Controller通過標籤管理Pod,若pod標籤被改,pod將脫離管控
- 提供重新排程、彈性擴/縮容、捲動更新能力
4.2.2、Node Controller
我們通過kubectl工具請求K8S的ApiServer獲取叢集中的Node資訊,如下
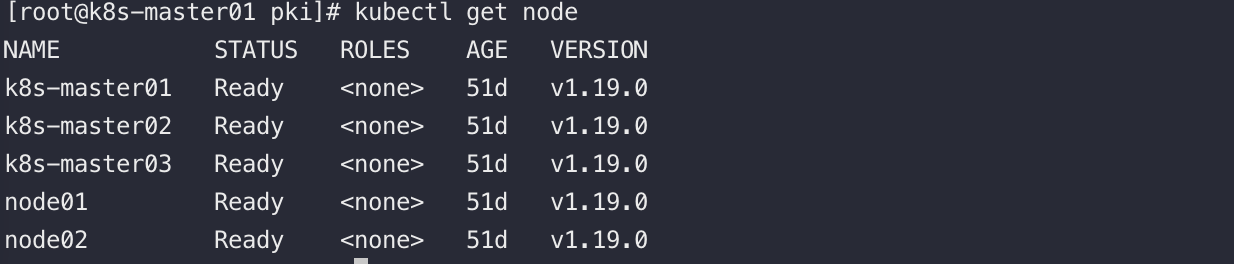
可以看到叢集中所有的節點和它的狀態都是Ready
apiserver是如何知道叢集中有哪些節點的呢?答案是:kubelet上報給apiserver,再經由watch機制轉發Node Controller,由Node Controller統一實現對叢集中Node的管理。若節點長時間異常,NodeControler會刪除該節點,節點上的資源重新排程到正常的節點中~
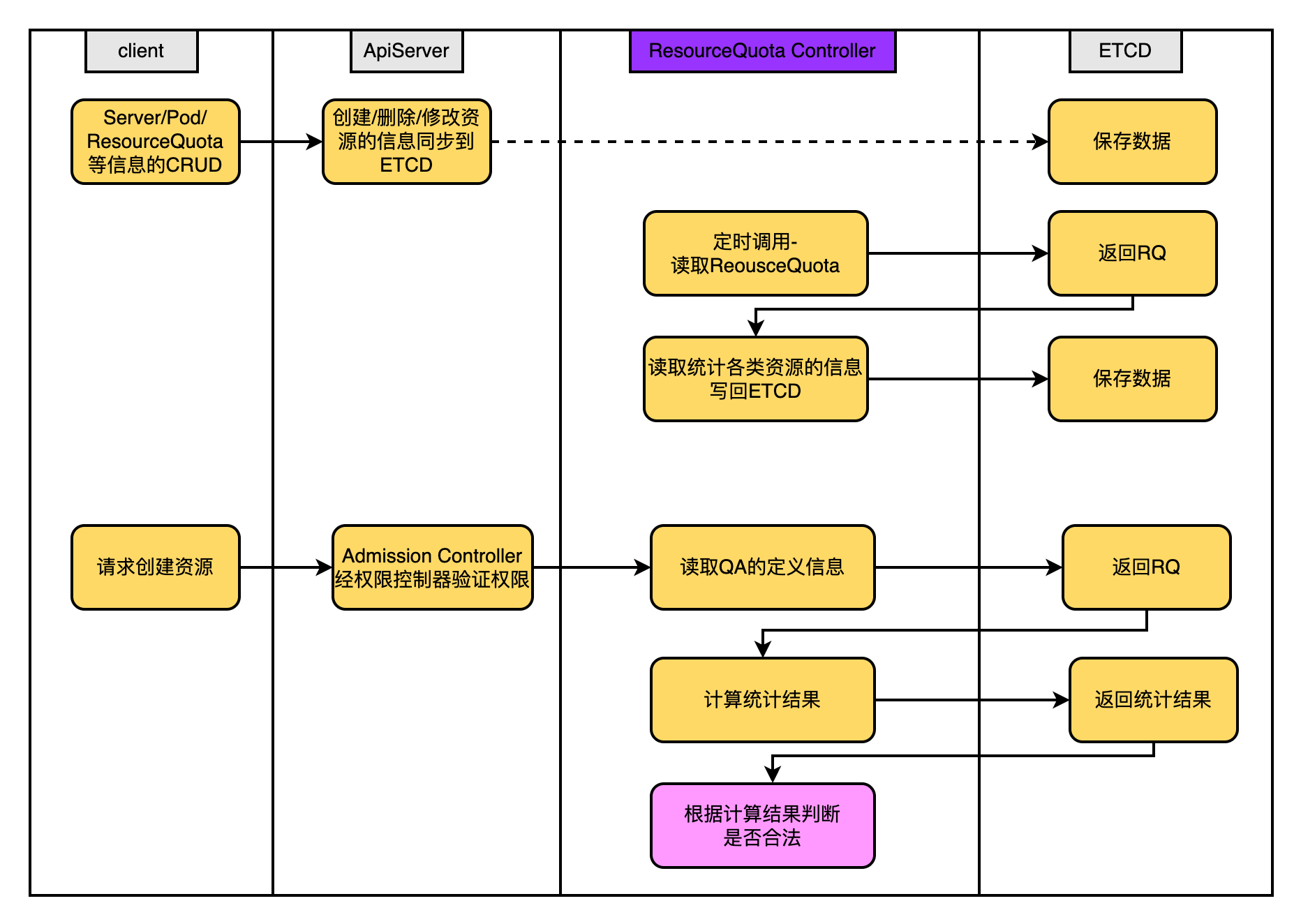
4.2.3、ResourceQuota Controller
ResourceQuota Controller的功能是確保:指定資源物件數量在任何時候都不要超過指定的最大數量,進而保證由於業務設計的缺陷導致整個系統的紊亂甚至宕機。
使用範例:將ResourceQuota建立到哪個namespace中,便對哪個namespace生效
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
# ==物件數量配額==
# 最多建立的cm數
configmaps: "10"
# 最多建立的pvc數
persistentvolumeclaims: "4"
# 最多啟動的pod數
pods: "4"
# 在該名稱空間中允許存在的 ReplicationController 總數上限。
replicationcontrollers: "20"
# 最多建立的secret數
secrets: "10"
# 最多建立的service數
services: "10"
# 在該名稱空間中允許存在的 LoadBalancer 型別的 Service 總數上限。
services.loadbalancers: "2"
# 在該名稱空間中允許存在的 NodePort 型別的 Service 總數上限。
services.nodeports: 2
# ==儲存型==
# 所有 PVC,儲存資源的需求總量不能超過該值。
requests.storage: 40Gi
# 在名稱空間的所有 Pod 中,本地臨時儲存請求的總和不能超過此值。
requests.ephemeral-storage: 512Mi
# 在名稱空間的所有 Pod 中,本地臨時儲存限制值的總和不能超過此值。
limits.ephemeral-storage: 40Gi
# ephemeral-storage 與 requests.ephemeral-storage 相同。
# ==cpu、memory==
# 所有非終止狀態的 Pod,其 CPU 限額總量不能超過該值。
limits.cpu: 1
# 所有非終止狀態的 Pod,其記憶體限額總量不能超過該值。
limits.memory: 16Gi
# 所有非終止狀態的 Pod,其 CPU 需求總量(pod中所有容器的request cpu)不能超過該值。
requests.cpu: 0.5
# 所有非終止狀態的 Pod,其記憶體需求總量(pod中所有容器的request cpu)不能超過該值。
requests.memory: 512Mi
# cpu: 0.5 和requests.cpu相同
# memory: 512Mi 和 requests.memory相同
目前支援的資源配額如下
- 容器級別
- 限制容器的CPU、記憶體
- Pod級別
- 對Pod中所有的容器的可用之和資源統一限制
- Namespace級別
- Pod數量
- RC的數量
- Service數量
- ResourceQuota的數量
- Secret數量
- 可持有的PV的數量等
感興趣自己去了解LimitRange資源物件,LimitRange的配額自動為Pod新增Cpu和Memory的設定,這裡不再展開
4.2.4、Namespace Controller
使用者通過apiserver建立namespace,apiserver會將namespace的資訊儲存入etcd中。
namespaceController通過apiserver讀取維護這些namespace的資訊,若ns被標記為刪除狀態,namespaceController會將其狀態改為Terminating
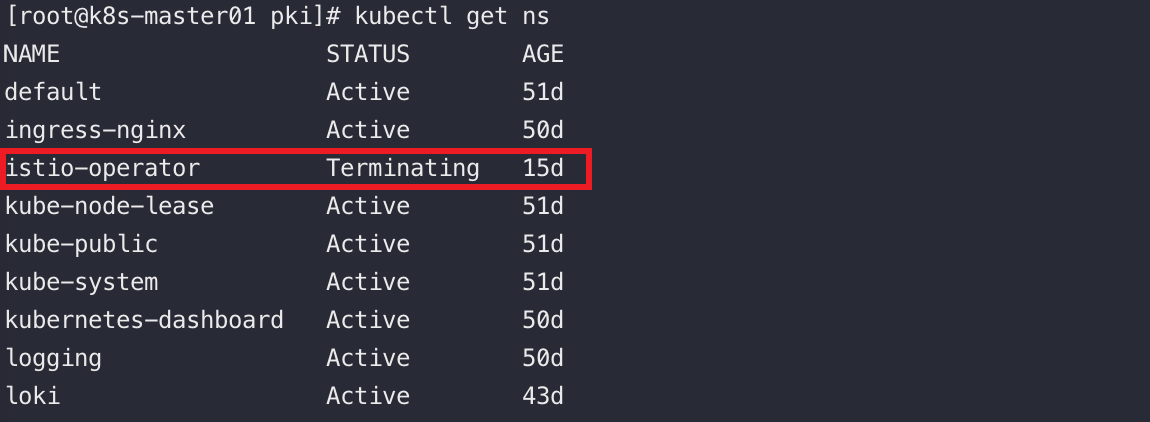
然後會刪除它裡面的ServiceAccount、RC、Pod等一切資源物件。
4.2.5、Service Controller - Endpoint Controller
Service Controller 會監聽維護Service的狀態、變化
Service、Pod、Endpoint之間的關係如下圖:Service通過標籤選擇器找到並代理對應的pod,pod的ip維護和Service同名的Endpoint中~
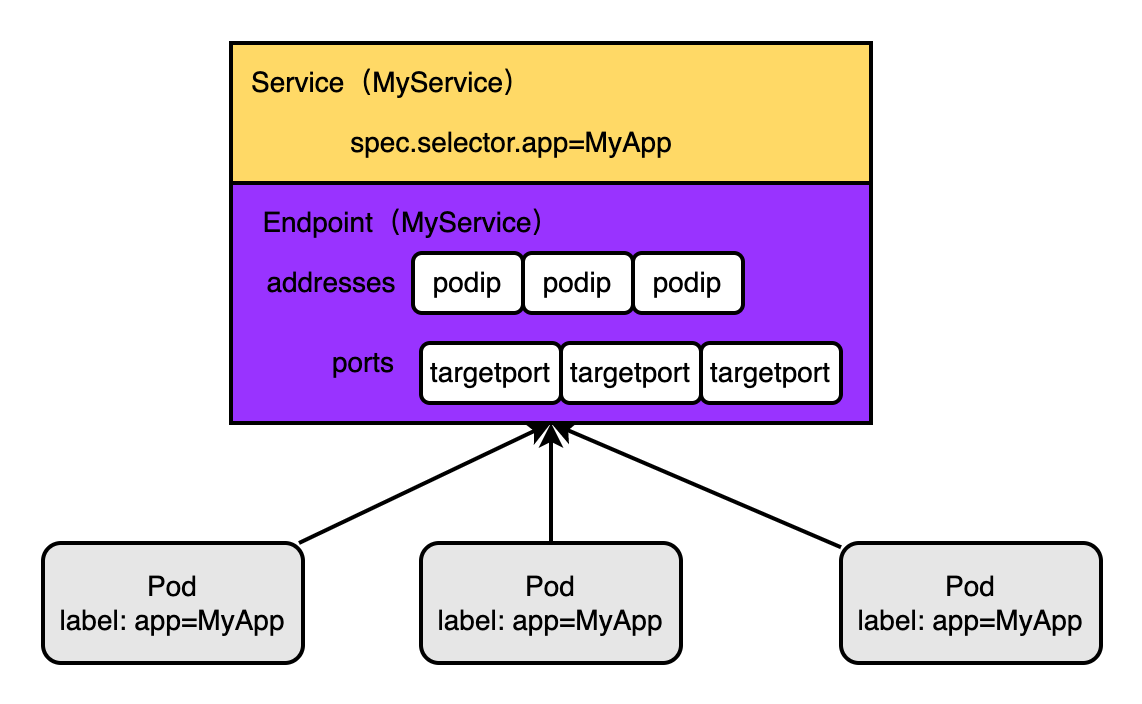
Endpoint Controller的作用是:監聽Service和他對應的pod的變化
- 當Service被刪除時,同步刪除和Service同名的Endpoint物件
- 新建/更新Service時,同步更新對應Endpoint的ip:port列表資訊
endpoint物件由每個node上的kube-proxy的程序使用,下文會說
4.3、Scheduler
負責接收ApiServer建立Pod的請求,為Pod選擇一個合適的Node,由該Node上的kubelet啟動Pod中的相應容器
排程流程分兩大步
- 預選策略
- 初步篩選出符合條件的Node
- 優選策略
- 在第一步的基礎上選擇更合適的Node
4.4、Kubelet
4.4.1、Node管理
通過設定啟動引數register-node引數開啟kubelet向apiserver註冊自己的資訊,apiserver會將資料
註冊之後通過kubectl如下命令可用檢視到叢集中的所有node 的資訊
若Node有問題,可以看到Status被標記為NotReady
4.4.2、Pod管理
最終管理員下發的建立Pod的請求由Kubelet轉發給它所在節點的容器執行時(Docker)處理
4.4.3、容器健康檢查
容器的livenessProbe探針(httpGet、tcpSocket、ExecAction)用於判斷容器的健康狀態。
kubelet會定期呼叫這些探針來判斷容器是否存活~
httpGet
向容器傳送Http Get請求,呼叫成功(通過Http狀態碼判斷)則確定Pod就緒;
使用方式:
livenessProbe:
httpGet:
path: /app/healthz
port: 80
exec
在容器內執行某命令,命令執行成功(通過命令退出狀態碼為0判斷)則確定Pod就緒;
使用方式:
livenessProbe:
exec:
command:
- cat
- /app/healthz
tcpSocket
開啟一個TCP連線到容器的指定埠,連線成功建立則確定Pod就緒。
使用方式:
livenessProbe:
tcpSocket:
port: 80
一般就緒探針會在啟動容器一段時間後才開始第一次的就緒探測,之後做週期性探測。所以在定義就緒指標時,會給以下幾個引數:
- initialDelaySeconds:在初始化容器多少秒後開始第一次就緒探測;
- timeoutSeconds:如果該次就緒探測超過多少秒後還未成功,判定為超時,該次探測失敗,Pod不就緒。預設值1,最小值1;
- periodSeconds:如果Pod未就緒,則每隔多少秒週期性的做就緒探測。預設值10,最小值1;
- failureThreshold:如果容器之前探測成功,後續連續幾次探測失敗,則確定容器未就緒。預設值3,最小值1;
- successThreshold:如果容器之前探測失敗,後續連續幾次探測成功,則確定容器就緒。預設值1,最小值1。
4.5、KubeProxy
K8S原生的支援通過Service的方式代理一組Pod暴露到叢集外部對外提供服務,建立Service時會這個Service建立一個Cluster-IP。而kubeproxy本質上就是這個Service的cluster-ip的負載均衡器。
在k8s的不同版本中,kubeproxy負載均衡Service的ClusterIp的方式不盡相同,主要如下
4.5.1、k8s1.2版本前
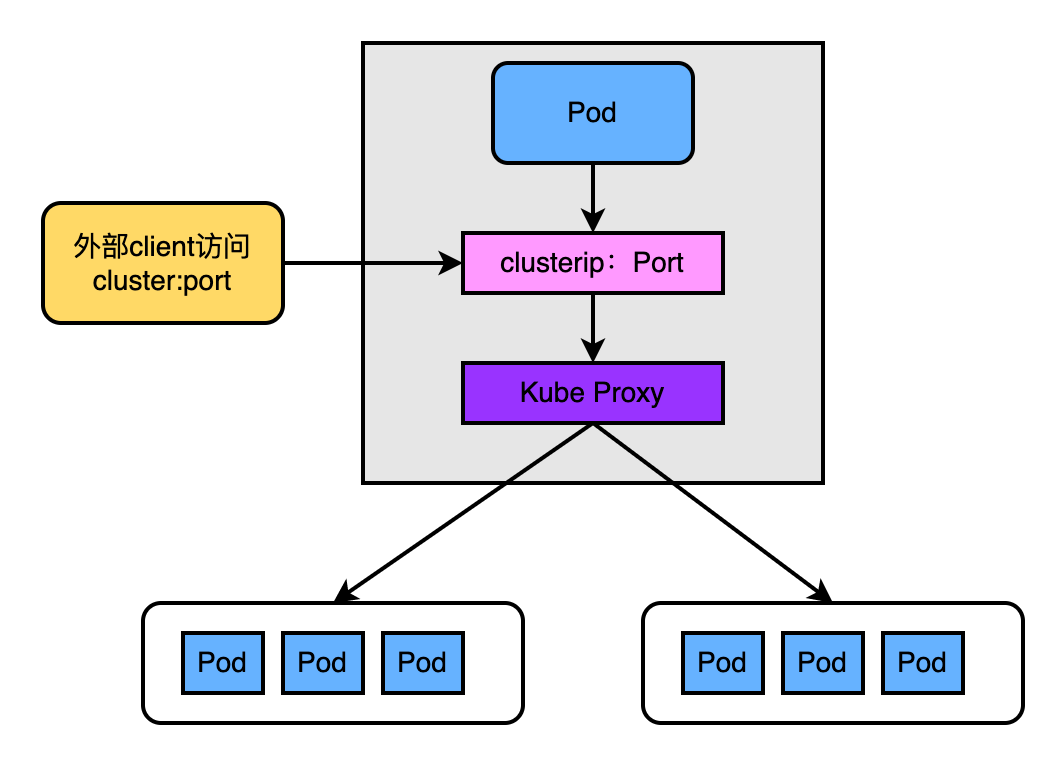
如上圖這個版本的KubeProxy的更像是一個TCP/UDP代理,最明顯的特徵是:外部使用者存取cluster:port過來的流量真實的經過了KubeProxy的處理和轉發,即流量經過了userspace中。
4.5.2、k8s1.2~1.7版本
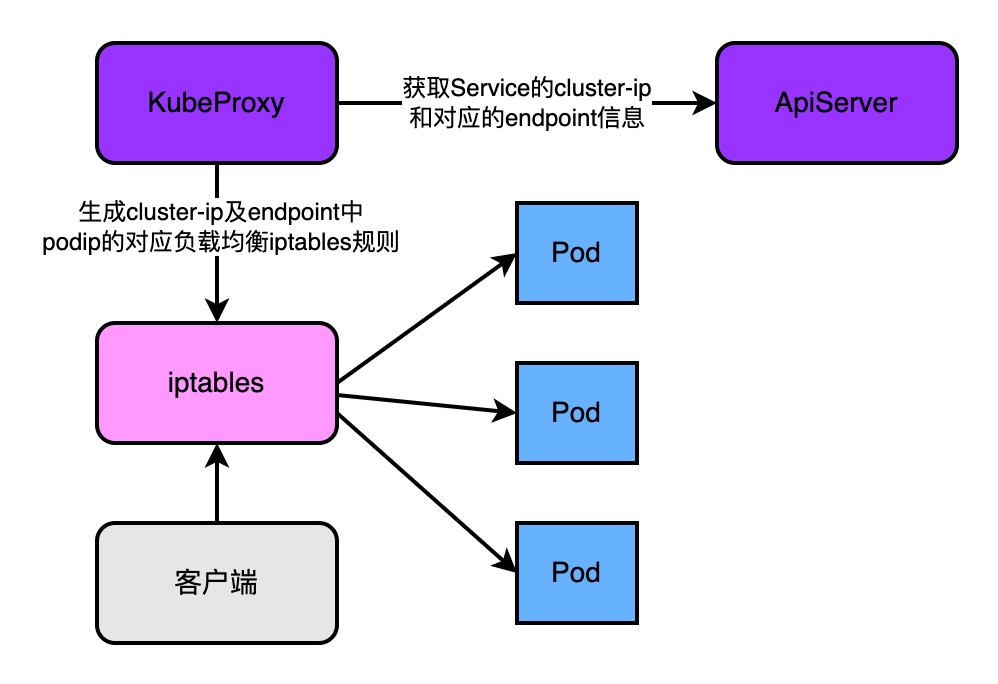
在這個版本KubeProxy端明顯特徵是:使用者的流量不再由kubeproxy負責轉發負載均衡。kubeproxy僅負責通過apiserver獲取service和它對應的endpoint,然後根據這些資料資訊生成iptables的規則,使用者的流量通過iptables找到最終的pod。
4.5.3、k8s1.8版本及之後
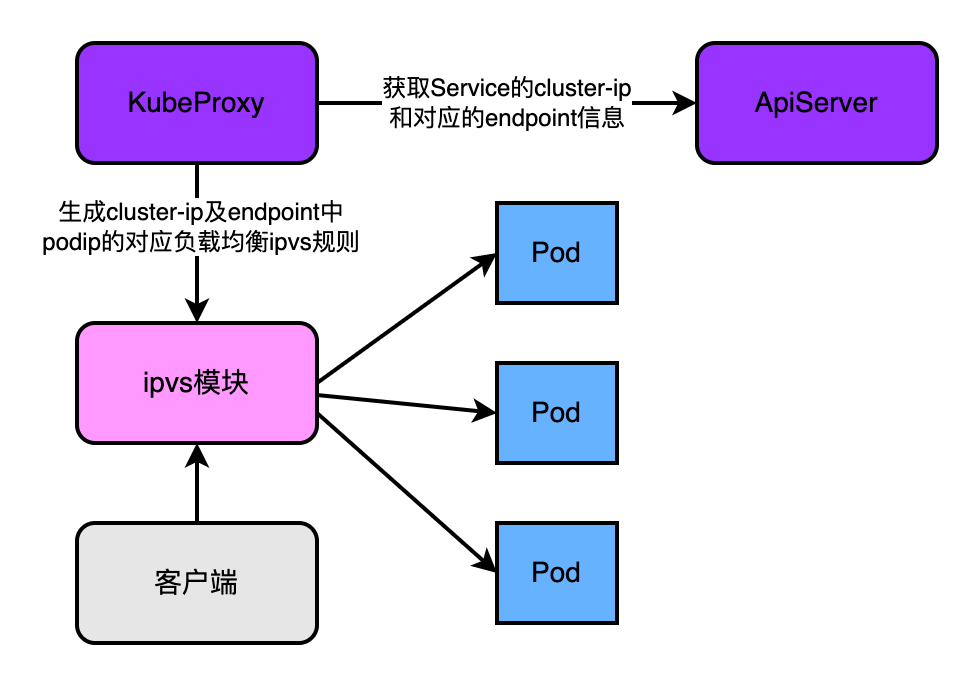
和上一個版本的區別是支援了ipvs模組。
兩者的定位不同:雖然iptables和ipvs都是基於netfilter實現的,但是iptables為防火牆而設計,而ipvs的定位是高效能的負載均衡。
在資料結構層面實現不同:iptables是鏈式結構,流量流經iptables要過所謂的四表五鏈,當叢集中中的pod數量劇增,iptables會變得十分臃腫,效率下降。而ipvs是基於hash表實現的,理論上支援無限擴張,且定址快。
ipvs也有不足,比如不支援包過濾、地址偽裝、SNAT,在使用Nodeport型別的Service時,依然需要和iptables搭配使用。
五、網路元件
5.1、CoreDNS
CoreDNS是K8S的服務發現機制(有DNS能力),實現了通過解析service-name解析出cluster-ip的能力。而且service被重新建立時cluter-ip是可能發生變化的,但是server-name不會改變。
我們是以POD的形式將CoreDNS部署進K8S的,如下檢視CoreDNS的service

這裡的kube-dns的ip地址通常可以在安裝coredns的組態檔中指定:coredns.yaml

驗證下kube-dns解析外網域名的DNS能力
[root@master01 ~]# yum -y install bind-utils
[root@master01 ~]# dig -t A www.baidu.com @192.168.0.10 +short
www.a.shifen.com.
39.156.66.18
39.156.66.14
驗證下kube-dns解析service名的DNS能力
# ${serviceName}.${名稱空間}.svc.cluster.local.
[root@master01 ~]# dig -t A kubernetes.default.svc.cluster.local. @192.168.0.10 +short
192.168.0.1
5.2、CNI網路外掛
像Calico或者flanel等,都是符合CNI規範的網路外掛,作用如下:
- 保證叢集中的pod生成叢集內全域性唯一的IP地址。
- 為K8S叢集提供了一個扁平化的叢集網路(service網路)意思就是說,它實現了叢集內的Pod跨node也能直接互通。
注意點:flanel不支援NetworkPolicy資源物件定義的網路策略,而Calico支援。
什麼是網路策略?如下
- 只有來自IngressController的流量才能存取帶有role=frontend標籤的pod
- 只有namespaceA的pod不能存取其他namespace的pod
- 只有源ip地址在某個網段的請求才能存取Project-A
- 從ProjectB出去的流量指定存取指定網段的Pod
參考:kubernetes官網、《kubernetes權威指南》