go-zero微服務實戰系列(九、極致優化秒殺效能)
上一篇文章中引入了訊息佇列對秒殺流量做削峰的處理,我們使用的是Kafka,看起來似乎工作的不錯,但其實還是有很多隱患存在,如果這些隱患不優化處理掉,那麼秒殺搶購活動開始後可能會出現訊息堆積、消費延遲、資料不一致、甚至服務崩潰等問題,那麼後果可想而知。本篇文章我們就一起來把這些隱患解決掉。
批次資料聚合
在SeckillOrder這個方法中,每來一次秒殺搶購請求都往往Kafka中傳送一條訊息。假如這個時候有一千萬的使用者同時來搶購,就算我們做了各種限流策略,一瞬間還是可能會有上百萬的訊息會發到Kafka,會產生大量的網路IO和磁碟IO成本,大家都知道Kafka是基於紀錄檔的訊息系統,寫訊息雖然大多情況下都是順序IO,但當海量的訊息同時寫入的時候還是可能會扛不住。
那怎麼解決這個問題呢?答案是做訊息的聚合。之前傳送一條訊息就會產生一次網路IO和一次磁碟IO,我們做訊息聚合後,比如聚合100條訊息後再傳送給Kafka,這個時候100條訊息才會產生一次網路IO和磁碟IO,對整個Kafka的吞吐和效能是一個非常大的提升。其實這就是一種小包聚合的思想,或者叫Batch或者批次的思想。這種思想也隨處可見,比如我們使用Mysql插入批次資料的時候,可以通過一條SQL語句執行而不是迴圈的一條一條插入,還有Redis的Pipeline操作等等。
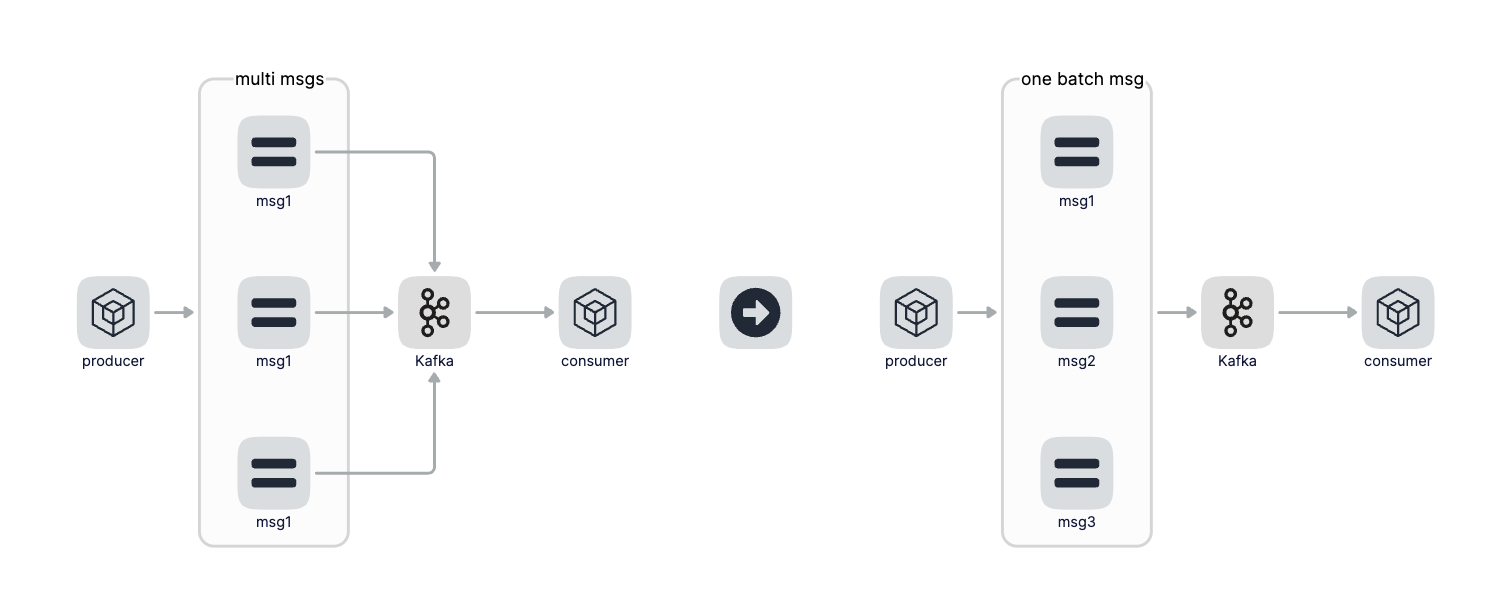
那怎麼來聚合呢,聚合策略是啥呢?聚合策略有兩個維度分別是聚合訊息條數和聚合時間,比如聚合訊息達到100條我們就往Kafka傳送一次,這個條數是可以設定的,那如果一直也達不到100條訊息怎麼辦呢?通過聚合時間來兜底,這個聚合時間也是可以設定的,比如設定聚合時間為1秒鐘,也就是無論目前聚合了多少條訊息只要聚合時間達到1秒,那麼就往Kafka傳送一次資料。聚合條數和聚合時間是或的關係,也就是隻要有一個條件滿足就觸發。
在這裡我們提供一個批次聚合資料的工具Batcher,定義如下
type Batcher struct {
opts options
Do func(ctx context.Context, val map[string][]interface{})
Sharding func(key string) int
chans []chan *msg
wait sync.WaitGroup
}
Do方法:滿足聚合條件後就會執行Do方法,其中val引數為聚合後的資料
Sharding方法:通過Key進行sharding,相同的key訊息寫入到同一個channel中,被同一個goroutine處理
在merge方法中有兩個觸發執行Do方法的條件,一是當聚合的資料條數大於等於設定的條數,二是當觸發設定的定時器
程式碼實現比較簡單,如下為具體實現:
type msg struct {
key string
val interface{}
}
type Batcher struct {
opts options
Do func(ctx context.Context, val map[string][]interface{})
Sharding func(key string) int
chans []chan *msg
wait sync.WaitGroup
}
func New(opts ...Option) *Batcher {
b := &Batcher{}
for _, opt := range opts {
opt.apply(&b.opts)
}
b.opts.check()
b.chans = make([]chan *msg, b.opts.worker)
for i := 0; i < b.opts.worker; i++ {
b.chans[i] = make(chan *msg, b.opts.buffer)
}
return b
}
func (b *Batcher) Start() {
if b.Do == nil {
log.Fatal("Batcher: Do func is nil")
}
if b.Sharding == nil {
log.Fatal("Batcher: Sharding func is nil")
}
b.wait.Add(len(b.chans))
for i, ch := range b.chans {
go b.merge(i, ch)
}
}
func (b *Batcher) Add(key string, val interface{}) error {
ch, msg := b.add(key, val)
select {
case ch <- msg:
default:
return ErrFull
}
return nil
}
func (b *Batcher) add(key string, val interface{}) (chan *msg, *msg) {
sharding := b.Sharding(key) % b.opts.worker
ch := b.chans[sharding]
msg := &msg{key: key, val: val}
return ch, msg
}
func (b *Batcher) merge(idx int, ch <-chan *msg) {
defer b.wait.Done()
var (
msg *msg
count int
closed bool
lastTicker = true
interval = b.opts.interval
vals = make(map[string][]interface{}, b.opts.size)
)
if idx > 0 {
interval = time.Duration(int64(idx) * (int64(b.opts.interval) / int64(b.opts.worker)))
}
ticker := time.NewTicker(interval)
for {
select {
case msg = <-ch:
if msg == nil {
closed = true
break
}
count++
vals[msg.key] = append(vals[msg.key], msg.val)
if count >= b.opts.size {
break
}
continue
case <-ticker.C:
if lastTicker {
ticker.Stop()
ticker = time.NewTicker(b.opts.interval)
lastTicker = false
}
}
if len(vals) > 0 {
ctx := context.Background()
b.Do(ctx, vals)
vals = make(map[string][]interface{}, b.opts.size)
count = 0
}
if closed {
ticker.Stop()
return
}
}
}
func (b *Batcher) Close() {
for _, ch := range b.chans {
ch <- nil
}
b.wait.Wait()
}
使用的時候需要先建立一個Batcher,然後定義Batcher的Sharding方法和Do方法,在Sharding方法中通過ProductID把不同商品的聚合投遞到不同的goroutine中處理,在Do方法中我們把聚合的資料一次性批次的傳送到Kafka,定義如下:
b := batcher.New(
batcher.WithSize(batcherSize),
batcher.WithBuffer(batcherBuffer),
batcher.WithWorker(batcherWorker),
batcher.WithInterval(batcherInterval),
)
b.Sharding = func(key string) int {
pid, _ := strconv.ParseInt(key, 10, 64)
return int(pid) % batcherWorker
}
b.Do = func(ctx context.Context, val map[string][]interface{}) {
var msgs []*KafkaData
for _, vs := range val {
for _, v := range vs {
msgs = append(msgs, v.(*KafkaData))
}
}
kd, err := json.Marshal(msgs)
if err != nil {
logx.Errorf("Batcher.Do json.Marshal msgs: %v error: %v", msgs, err)
}
if err = s.svcCtx.KafkaPusher.Push(string(kd)); err != nil {
logx.Errorf("KafkaPusher.Push kd: %s error: %v", string(kd), err)
}
}
s.batcher = b
s.batcher.Start()
在SeckillOrder方法中不再是每來一次請求就往Kafka中投遞一次訊息,而是先通過batcher提供的Add方法新增到Batcher中等待滿足聚合條件後再往Kafka中投遞。
err = l.batcher.Add(strconv.FormatInt(in.ProductId, 10), &KafkaData{Uid: in.UserId, Pid: in.ProductId})
if err!= nil {
logx.Errorf("l.batcher.Add uid: %d pid: %d error: %v", in.UserId, in.ProductId, err)
}
降低訊息的消費延遲
通過批次訊息處理的思想,我們提供了Batcher工具,提升了效能,但這主要是針對生產端而言的。當我們消費到批次的資料後,還是需要序列的一條條的處理資料,那有沒有辦法能加速消費從而降低消費訊息的延遲呢?有兩種方案分別是:
- 增加消費者的數量
- 在一個消費者中增加訊息處理的並行度
因為在Kafka中,一個Topci可以設定多個Partition,資料會被平均或者按照生產者指定的方式寫入到多個分割區中,那麼在消費的時候,Kafka約定一個分割區只能被一個消費者消費,為什麼要這麼設計呢?我理解的是如果有多個Consumer同時消費一個分割區的資料,那麼在操作這個消費進度的時候就需要加鎖,對效能影響比較大。所以說當消費者數量小於分割區數量的時候,我們可以增加消費者的數量來增加訊息處理能力,但當消費者數量大於分割區的時候再繼續增加消費者數量就沒有意義了。
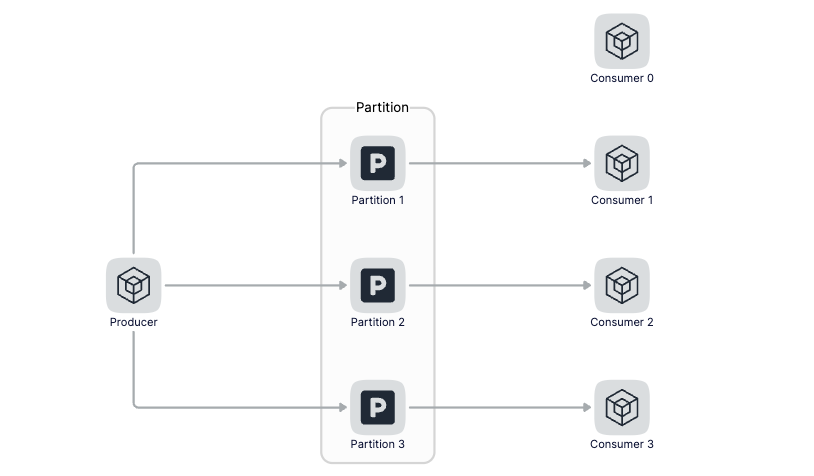
不能增加Consumer的時候,可以在同一個Consumer中提升處理訊息的並行度,即通過多個goroutine來並行的消費資料,我們一起來看看如何通過多個goroutine來消費訊息。
在Service中定義msgsChan,msgsChan為Slice,Slice的長度表示有多少個goroutine並行的處理資料,初始化如下:
func NewService(c config.Config) *Service {
s := &Service{
c: c,
ProductRPC: product.NewProduct(zrpc.MustNewClient(c.ProductRPC)),
OrderRPC: order.NewOrder(zrpc.MustNewClient(c.OrderRPC)),
msgsChan: make([]chan *KafkaData, chanCount),
}
for i := 0; i < chanCount; i++ {
ch := make(chan *KafkaData, bufferCount)
s.msgsChan[i] = ch
s.waiter.Add(1)
go s.consume(ch)
}
return s
}
從Kafka中消費到資料後,把資料投遞到Channel中,注意投遞訊息的時候按照商品的id做Sharding,這能保證在同一個Consumer中對同一個商品的處理是序列的,序列的資料處理不會導致並行帶來的資料競爭問題
func (s *Service) Consume(_ string, value string) error {
logx.Infof("Consume value: %s\n", value)
var data []*KafkaData
if err := json.Unmarshal([]byte(value), &data); err != nil {
return err
}
for _, d := range data {
s.msgsChan[d.Pid%chanCount] <- d
}
return nil
}
我們定義了chanCount個goroutine同時處理資料,每個channel的長度定義為bufferCount,並行處理資料的方法為consume,如下:
func (s *Service) consume(ch chan *KafkaData) {
defer s.waiter.Done()
for {
m, ok := <-ch
if !ok {
log.Fatal("seckill rmq exit")
}
fmt.Printf("consume msg: %+v\n", m)
p, err := s.ProductRPC.Product(context.Background(), &product.ProductItemRequest{ProductId: m.Pid})
if err != nil {
logx.Errorf("s.ProductRPC.Product pid: %d error: %v", m.Pid, err)
return
}
if p.Stock <= 0 {
logx.Errorf("stock is zero pid: %d", m.Pid)
return
}
_, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: m.Uid, Pid: m.Pid})
if err != nil {
logx.Errorf("CreateOrder uid: %d pid: %d error: %v", m.Uid, m.Pid, err)
return
}
_, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: m.Pid, Num: 1})
if err != nil {
logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", m.Uid, m.Pid, err)
}
}
}
怎麼保證不會超賣
當秒殺活動開始後,大量使用者點選商品詳情頁上的秒殺按鈕,會產生大量的並行請求查詢庫存,一旦某個請求查詢到有庫存,緊接著系統就會進行庫存的扣減。然後,系統生成實際的訂單,並進行後續的處理。如果請求查不到庫存,就會返回,使用者通常會繼續點選秒殺按鈕,繼續查詢庫存。簡單來說,這個階段的操作就是三個:檢查庫存,庫存扣減、和訂單處理。因為每個秒殺請求都會查詢庫存,而請求只有查到庫存有餘量後,後續的庫存扣減和訂單處理才會被執行,所以,這個階段中最大的並行壓力都在庫存檢查操作上。
為了支撐大量高並行的庫存檢查請求,我們需要使用Redis單獨儲存庫存量。那麼,庫存扣減和訂單處理是否都可以交給Mysql來處理呢?其實,訂單的處理是可以在資料庫中執行的,但庫存扣減操作不能交給Mysql直接處理。因為到了實際的訂單處理環節,請求的壓力已經不大了,資料庫完全可以支撐這些訂單處理請求。那為什麼庫存扣減不能直接在資料庫中執行呢?這是因為,一旦請求查到有庫存,就意味著該請求獲得購買資格,緊接著就會進行下單操作,同時庫存量會減一,這個時候如果直接運算元據庫來扣減庫存可能就會導致超賣問題。
直接運算元據庫扣減庫存為什麼會導致超賣呢?由於資料庫的處理速度較慢,不能及時更新庫存餘量,這就會導致大量的查詢庫存的請求讀取到舊的庫存值,並進行下單,此時就會出現下單數量大於實際的庫存量,導致超賣。所以,就需要直接在Redis中進行庫存扣減,具體的操作是,當庫存檢查完後,一旦庫存有餘量,我們就立即在Redis中扣減庫存,同時,為了避免請求查詢到舊的庫存值,庫存檢查和庫存扣減這兩個操作需要保證原子性。
我們使用Redis的Hash來儲存庫存,total為總庫存,seckill為已秒殺的數量,為了保證查詢庫存和減庫存的原子性,我們使用Lua指令碼進行原子操作,讓秒殺量小於庫存的時候返回1,表示秒殺成功,否則返回0,表示秒殺失敗,程式碼如下:
const (
luaCheckAndUpdateScript = `
local counts = redis.call("HMGET", KEYS[1], "total", "seckill")
local total = tonumber(counts[1])
local seckill = tonumber(counts[2])
if seckill + 1 <= total then
redis.call("HINCRBY", KEYS[1], "seckill", 1)
return 1
end
return 0
`
)
func (l *CheckAndUpdateStockLogic) CheckAndUpdateStock(in *product.CheckAndUpdateStockRequest) (*product.CheckAndUpdateStockResponse, error) {
val, err := l.svcCtx.BizRedis.EvalCtx(l.ctx, luaCheckAndUpdateScript, []string{stockKey(in.ProductId)})
if err != nil {
return nil, err
}
if val.(int64) == 0 {
return nil, status.Errorf(codes.ResourceExhausted, fmt.Sprintf("insufficient stock: %d", in.ProductId))
}
return &product.CheckAndUpdateStockResponse{}, nil
}
func stockKey(pid int64) string {
return fmt.Sprintf("stock:%d", pid)
}
對應的seckill-rmq程式碼修改如下:
func (s *Service) consume(ch chan *KafkaData) {
defer s.waiter.Done()
for {
m, ok := <-ch
if !ok {
log.Fatal("seckill rmq exit")
}
fmt.Printf("consume msg: %+v\n", m)
_, err := s.ProductRPC.CheckAndUpdateStock(context.Background(), &product.CheckAndUpdateStockRequest{ProductId: m.Pid})
if err != nil {
logx.Errorf("s.ProductRPC.CheckAndUpdateStock pid: %d error: %v", m.Pid, err)
return
}
_, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: m.Uid, Pid: m.Pid})
if err != nil {
logx.Errorf("CreateOrder uid: %d pid: %d error: %v", m.Uid, m.Pid, err)
return
}
_, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: m.Pid, Num: 1})
if err != nil {
logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", m.Uid, m.Pid, err)
}
}
}
到這裡,我們已經瞭解瞭如何使用原子性的Lua指令碼來實現庫存的檢查和扣減。其實要想保證庫存檢查和扣減的原子性,還有另外一種方法,那就是使用分散式鎖。
分散式鎖的實現方式有很多種,可以基於Redis、Etcd等等,用Redis實現分散式鎖的文章比較多,感興趣的可以自行搜尋參考。這裡給大家簡單介紹下基於Etcd來實現分散式鎖。為了簡化分散式鎖、分散式選舉、分散式事務的實現,etcd社群提供了一個名為concurrency的包來幫助我們更簡單、正確的使用分散式鎖。它的實現非常簡單,主要流程如下:
- 首先通過concurrency.NewSession方法建立Session,本質上是建立了一個TTL為10的Lease
- 得到Session物件後,通過concurrency.NewMutex建立一個mutex物件,包括了Lease、key prefix等資訊
- 然後聽過mutex物件的Lock方法嘗試獲取鎖
- 最後通過mutex物件的Unlock方法釋放鎖
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
session, err := concurrency.NewSession(cli, concurrency.WithTTL(10))
if err != nil {
log.Fatal(err)
}
defer session.Close()
mux := concurrency.NewMutex(session, "lock")
if err := mux.Lock(context.Background()); err != nil {
log.Fatal(err)
}
if err := mux.Unlock(context.Background()); err != nil {
log.Fatal(err)
}
結束語
本篇文章主要是針對秒殺功能繼續做了一些優化。在Kafka訊息的生產端做了批次訊息聚合傳送的優化,Batch思想在實際生產開發中使用非常多,希望大家能夠活靈活用,在訊息的消費端通過增加並行度來提升吞吐能力,這也是提升效能常用的優化手段。最後介紹了可能導致超賣的原因,以及給出了相對應的解決方案。同時,介紹了基於Etcd的分散式鎖,在分散式服務中經常出現資料競爭的問題,一般可以通過分散式鎖來解決,但分散式鎖的引入勢必會導致效能的下降,所以,還需要結合實際情況考慮是否需要引入分散式鎖。
希望本篇文章對你有所幫助,謝謝。
每週一、週四更新
程式碼倉庫: https://github.com/zhoushuguang/lebron
專案地址
https://github.com/zeromicro/go-zero
歡迎使用 go-zero 並 star 支援我們!
微信交流群
關注『微服務實踐』公眾號並點選 交流群 獲取社群群二維條碼。