後端接入層技術的一些思考
後端接入層技術的一些思考
前言
網上技術文章已經氾濫了,部分寫得非常好,看著看著,就覺得自己太菜,感覺也沒有下筆的必要了。但是,寫文章也是一個梳理自身思路的一個過程,用輸出倒逼輸入,一直都是挺不錯的學習方法,不然網上文章看完就不記得是馬什麼梅了,因此,還是決定寫寫自己對於這塊技術的一些思考。
接入層,沒找到具體的定義,按我的理解,就是位於防火牆之後,承接前端使用者請求(通過瀏覽器或者app等)的最前沿的伺服器叢集,一般會和使用者正向代理軟體(瀏覽器、app之類)直接建立網路連線,負責接收使用者請求,轉發到邏輯層服務處理,再將邏輯層響應返回給使用者。當然,這只是最初級的場景,因為接入層實際是流量入口,所以它可以做很多流量排程的事情,舉個例子,大家如果去過都江堰,就會看到江的中間,有一段沙洲,這片沙洲就能將奔流的岷江水分流,分流後,水流就不至於在暴雨時節對下游造成洪澇災害。
「魚嘴」是都江堰的分水工程,因其形如魚嘴而得名,位於岷江江心,把岷江分成內外二江。西邊叫外江,俗稱「金馬河」,是岷江正流,主要用於排洪;東邊沿山腳的叫內江,是人工引水渠道,主要用於灌溉。
而且這也才是第一道分水工程,我查了下都江堰的排沙工程,又被秀到了,竟然暗合了軟體架構中的限流熔斷思想,當初去都江堰還是應該找個導遊,現在覺得真是看了個寂寞。
飛沙堰的作用主要是當內江的水量超過寶瓶口流量上限時,多餘的水便從飛沙堰自行溢位;如遇特大洪水的非常情況,它還會自行潰堤,讓大量江水迴歸岷江正流。
什麼叫「水旱從人,不知饑饉」,這就是。
說回正題,接入層就是個流量口子,我們可以根據我們的想法,自由地分發流量給後端的服務叢集(負載均衡),當流量過大時,可以限流熔斷,同時,可以進行認證鑑權,打擊灰產,紀錄檔記錄,監控上報,灰度釋出等各類功能。
接下來,會說一下典型的架構。
單idc架構(無長連線)
大部分中小型公司,如果就是提供一個網站對外存取,也不需要接收後端通知的話(如實時IM通訊),可能都會是這類架構,我任職過的公司裡,也有這類架構。下圖就以我熟悉的nginx來作為接入層元件了,lvs也可以,個人研究不多,就先算了。
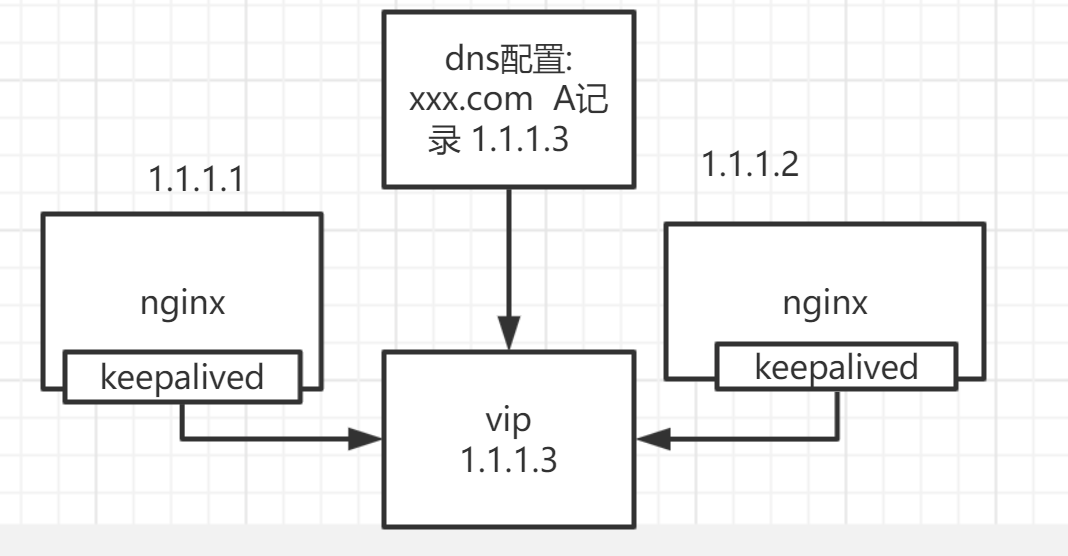
這個架構主要的問題在於,接入服務都在單個機房,一旦這個機房掛了或者這個vip出了問題,服務基本就不可用了。
同城多idc架構(無長連線)
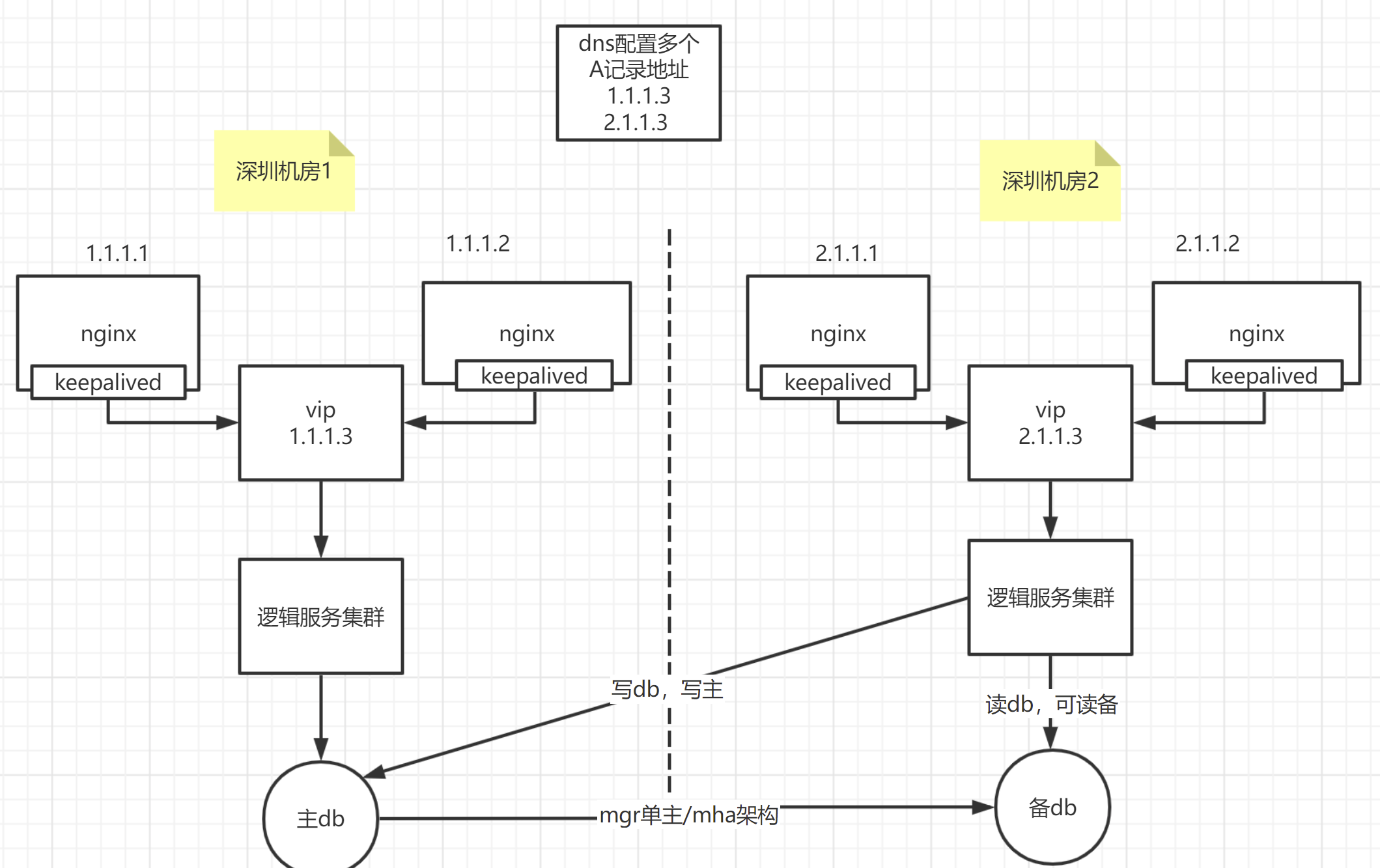
解決的辦法,就是多機房容災,包括了同城多個機房(一個城市裡多個機房)、兩地多中心(兩個城市,多個機房)、三地多中心(三個城市,多個機房);再根據機房是否多活(多個機房可以同時處理使用者請求,即每個機房都有流量),分為了:同城多活、異地多活(異地多活就是異地的多個城市,如深圳、上海,都可以同時處理流量,這時候基本要上單元化架構了)
中小公司,我個人覺得,同城多活基本也就足夠了,基本就是下面這個樣子。
單idc架構(有長連線場景)
短連線:tcp建立連線,傳輸完資料後,馬上關閉連線。下次要傳資料時,再來一次三次握手--傳資料--四次揮手。
長連線:tcp建立連線,傳輸完資料後,不關閉連線,下次要傳資料時,找到前面沒關的長連線,直接傳資料,傳完也不關閉。
長連線一般適用於,後端需要主動通知使用者的場景,當然了,也不是說,這種時候就必須要用長連線,使用者端輪詢、長輪詢也是可以實現這種場景的,但這裡我們只說長連線這種實現方式。
這種方式的好處在於,非常實時,要的就是一個快,後端只要需要給我發訊息,我馬上能收到。
對於這塊的架構,我個人目前傾向於如下設計:
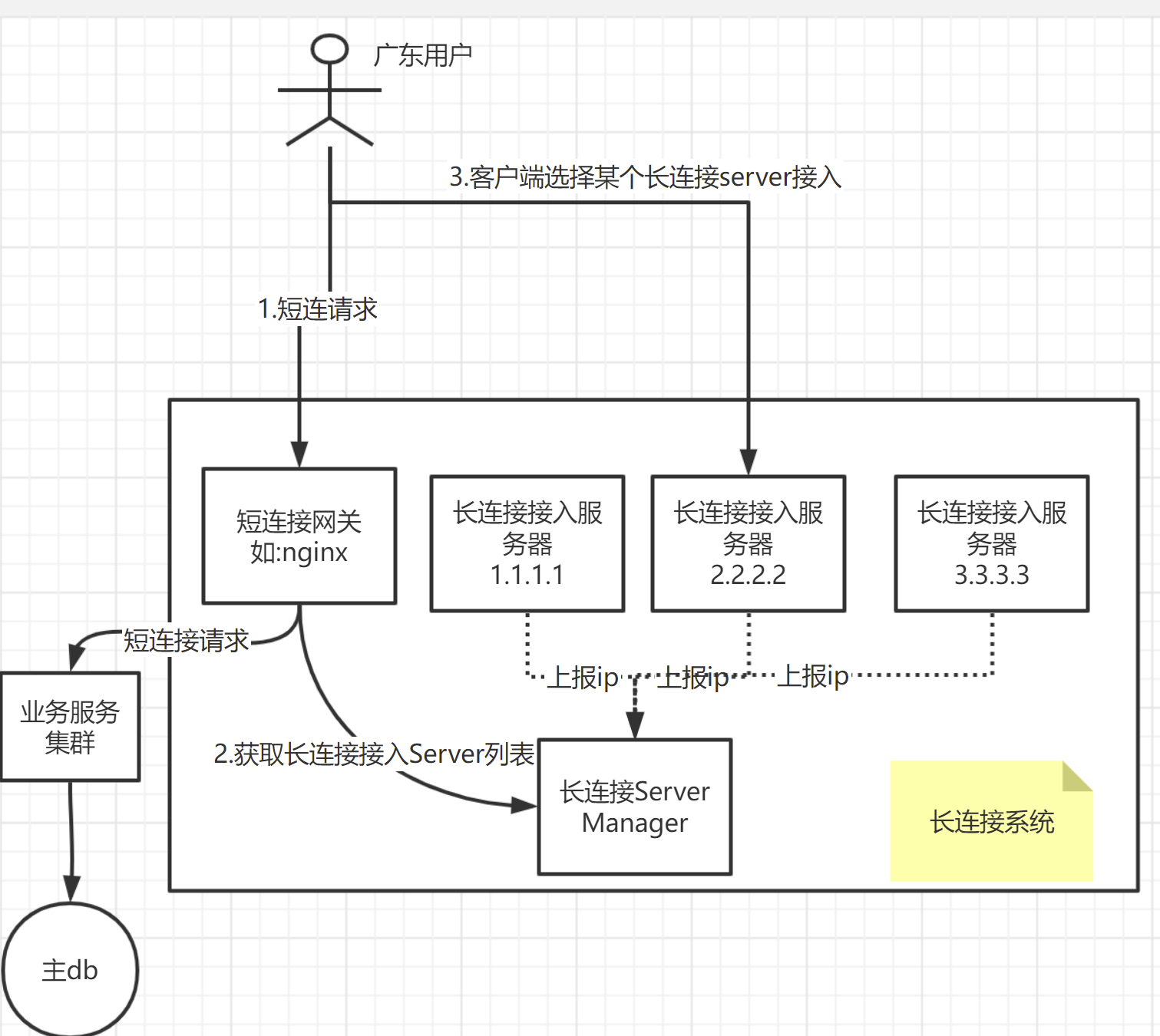
即,使用者在準備進行長連線時,首要的事情就是,拿到要接入的長連線伺服器的ip+埠,要拿到這個ip+埠,有很多方式,像我圖裡畫的,就是這樣一種模式:
- client端,首先呼叫短連線閘道器,短連線閘道器可能首先對使用者鑑權,提示登陸等;登陸成功後,client端呼叫短連線閘道器,請求獲取長連線伺服器的"ip+埠"列表。當然,這裡為了簡單,你可以直接寫死成一個設定,但是,我們建議靈活一點,提取一個單獨的服務(如上圖的長連線server manager),對外提供對應的獲取長連線伺服器列表的介面。
- client端,拿到長連線伺服器列表後,接下來要做的就是選擇其中的一個。這塊就可以有很多策略了,比如,可以ping一下每個ip,看看延遲,可以選擇延遲最低的;或者是根據業務邏輯,自己實現一個策略。
- client拿到想要連線的ip+埠後,進行tcp 連線即可;對應的長連線伺服器,收到client連線請求後,就會在記憶體或者redis之類的,維護一個map,key:使用者id/終端id,value:長連線物件。同時,可以上報一些統計資料給長連線server manager,如當前伺服器1.1.1.1維護了2000個使用者的長連線,屆時,長連線server manager就可以根據這些統計資料,來提示client可以連線某個負載比較小的伺服器(這塊的策略也可以自由實現,比如幫client端推薦一個長連線伺服器、強制使用者端使用某臺伺服器等)
這裡還有一點,使用者端現在是通過呼叫如上方式,獲取長連線伺服器;但要是這個鏈路有問題呢,這時候可以有對應的降級機制,比如使用dns域名方式來獲取,或者是使用使用者端中寫死的一批ip。
伺服器端如何主動做推播呢?這裡不打算展開了,比如要給使用者xxx發訊息,那此時,有兩種方式,一種是,想辦法查詢到,xxx在哪臺接入伺服器上;另一種是,給每臺接入伺服器發請求,類似於廣播,接入伺服器收到這種廣播請求後,檢查對應的使用者歸不歸自己管,不歸的話,就不管。
多idc架構(有長連線場景)
這個架構還有啥問題嗎?大家可以看到,圖裡是位於深圳機房的,服務於廣東使用者,估計延遲還好,要是服務北京使用者,北京使用者通過長連線,連到深圳,深圳這邊推播訊息時,走公網推播給使用者,這個延遲肯定低不了。有啥好辦法嗎,我覺得,可以採用多機房,就近接入的方式。
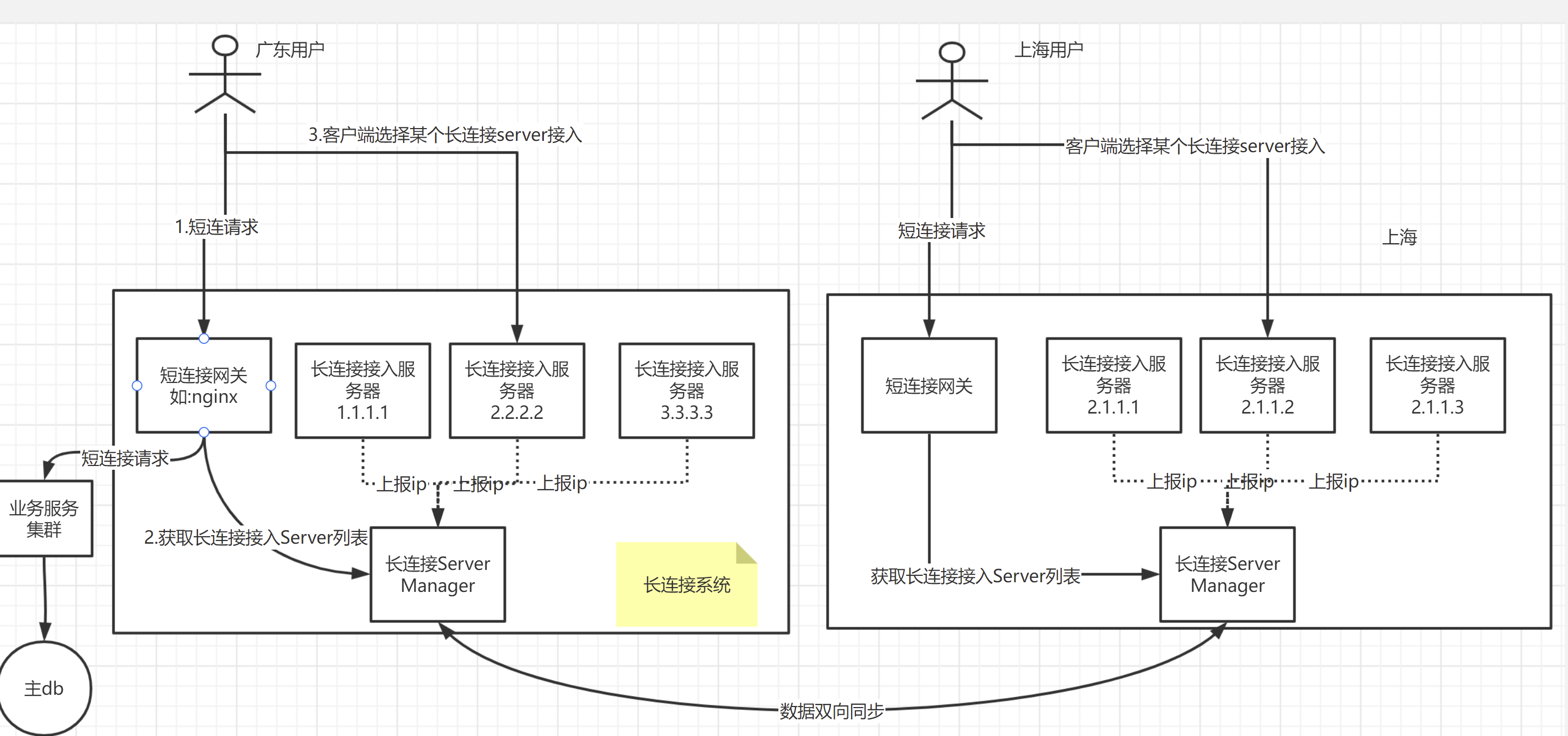
比如,深圳、上海各一個機房,北京使用者接入上海機房,物理上就近多了,自然要快一些。這個場景下,流程是如何的呢?
- 使用者通過dns(設定多條A記錄,指向上海、深圳機房的短連線閘道器地址),理論上,可以獲取到就近的機房的地址;如廣東使用者應該會取到深圳機房地址,北京使用者會取到上海機房的地址。如果不行的話,我們還有其他辦法,如gslb,後面講。
- 此時,假設沒有部署異地多活,上海機房只負責了接入層,沒部署業務層的服務和db等;此時,深圳側的業務服務發起訊息推播,推給北京某個使用者,此時是可以通過長連線Server Manager,查到使用者在上海接入;那就把這個推播請求,發給上海這邊的接入伺服器。因為大公司的機房之間,路線一般是有專網,或者是花了不少錢的,速度肯定比公網要快一些。比如,騰訊的深圳上海機房的延遲,基本就是幾十ms。
這邊有一個點是,深圳、上海的長連線Server Manager進行了雙向同步。不雙向同步,感覺也是可以的,我們可以根據使用者的登陸ip,查詢ip屬於哪個省,如果是北京,則認為該使用者在上海機房接入了,則交給上海機房去推播即可。
gslb技術
我們上面提到,深圳、上海各一個機房,此時,dns要配兩條A記錄地址,指向各機房。同時,我們假設了,dns解析商那邊,會把北京使用者解析到上海機房。
但這個假設,不一定生效,dns解析商那邊的解析還是比較粗糙的,如果我們希望把這塊掌握在自己手裡,那就可以使用gslb技術(global server load balance)。
有一種簡單的實現方式,簡單來說,就是dns解析那裡,設定兩條ns記錄,ns記錄分別指向深圳、上海機房的自研的dns伺服器。自研的dns伺服器,就可以用我們自定義的規則,來決定這次dns解析,給使用者返回什麼地址。自研dns,可以這樣做,比如查詢使用者屬於電信還是網通,屬於哪個省,來決定返回深圳、還是上海的機房地址。