磁碟的基本知識和基本命令
一、概述
目的:更加系統的熟悉磁碟和磁碟的基本操作
二、檔案系統
2.1、硬碟的構成
從儲存資料的媒介上來區分,硬碟可分為機械硬碟(Hard Disk Drive, HDD)和固態硬碟(Solid State Disk, SSD),機械硬碟採用磁性碟片來儲存資料,而固態硬碟通過快閃記憶體顆粒來儲存資料
機械硬碟主要由磁碟碟片、磁頭、主軸與傳動軸等組成,資料就存放在磁碟碟片中。
- 什麼是磁軌呢?每個碟片都在邏輯上有很多的同心圓,最外面的同心圓就是 0 磁軌。我們將每個同心圓稱作磁軌(注意,磁軌只是邏輯結構,在盤面上並沒有真正的同心圓)。硬碟的磁軌密度非常高,通常一面上就有上千個磁軌。但是相鄰的磁軌之間並不是緊挨著的,這是因為磁化單元相隔太近會相互產生影響。
- 那磁區又是什麼呢?磁區其實是很形象的,大家都見過摺疊的紙扇吧,紙扇開啟後是半圓形或扇形的,不過這個扇形是由每個扇骨組合形成的。在磁碟上每個同心圓是磁軌,從圓心向外呈放射狀地產生分割線(扇骨),將每個磁軌等分為若干弧段,每個弧段就是一個磁區。每個磁區的大小是固定的,為 512Byte。磁區也是磁碟的最小儲存單位。硬碟的容量越來越大,為了減少資料量的拆解,所以新的大容量硬碟已經有 4KByte 的磁區設計
- 柱面又是什麼呢?如果硬碟是由多個碟片組成的,每個盤面都被劃分為數目相等的磁軌,那麼所有碟片都會從外向內進行磁軌編號,最外側的就是 0 磁軌。具有相同編號的磁軌會形成一個圓柱,這個圓柱就被稱作磁碟的柱面
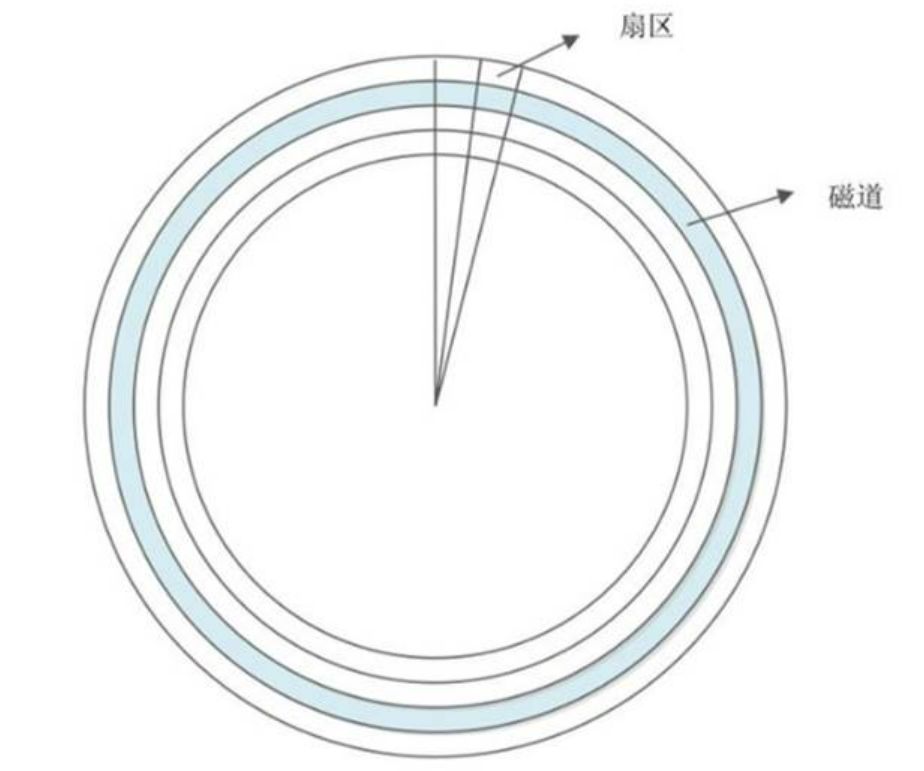
硬碟的大小是使用"磁頭數 x 柱面數 x 磁區數 x 每個磁區的大小"這樣的公式來計算的。其中,磁頭數(Heads)表示硬碟共有幾個磁頭,也可以理解為硬碟有幾個盤面,然後乘以 2;柱面數(Cylinders)表示硬碟每面碟片有幾條磁軌;磁區數(Sectors)表示每條磁軌上有幾個磁區;每個磁區的大小一般是 512Byte。
外圈的磁區數量比較多,因此如果資料寫入在外圈,轉一圈能夠讀寫的資料量當然比內圈還要多! 因此通常資料的讀寫會由外圈開始往內寫的喔!這是預設值啊!
傳輸介面:SAS介面、SATA介面、USB介面、(IDE 與 SCSI ,這兩被前面的取代)
固態硬碟和傳統的機械硬碟最大的區別就是不再採用碟片進行資料儲存,而採用儲存晶片進行資料儲存。固態硬碟的儲存晶片主要分為兩種:一種是採用快閃記憶體作為儲存媒介的;另一種是採用DRAM作為儲存媒介的。目前使用較多的主要是採用快閃記憶體作為儲存媒介的固態硬碟
近年來在測試磁碟的效能時, 有個很特殊的單位,稱為每秒讀寫操作次數 (Input/Output Operations PerSecond, IOPS)!這個數值越大,代表可操作次數較高,當然效能好的很!
- 磁區(Sector)為最小的物理儲存單位,且依據磁碟設計的不同,目前主要有 512Bytes 與 4K 兩種格式;
- 將磁區組成一個圓,那就是柱面(Cylinder);
- 早期的分割區主要以柱面為最小分割區單位,現在的分割區通常使用磁區為最小分割區單位(每個磁區都有其號碼喔,就好像座位一樣);
- 磁碟分割區表主要有兩種格式,一種是限制較多的 MBR 分割區表,一種是較新且限制較少的 GPT 分割區表。
- MBR 分割區表中,第一個磁區最重要,裡面有:(1)主要開機區(Master boot record, MBR)及分割區表(partition table), 其中 MBR 佔有 446 Bytes,而 partition table 則佔有 64 Bytes。
- GPT 分割區表除了分割區數量擴充較多之外,支援的磁碟容量也可以超過 2TB
- /dev/sd[a-p][1-128]:為實體磁碟的磁碟檔名;
- /dev/vd[a-d][1-128]:為虛擬磁碟的磁碟檔名
2.2、檔案系統基礎知識
因為每種作業系統所設定的檔案屬性/許可權並不相同, 為了存放這些檔案所需的資料,因此就需要將分割區進行格式化,以成為作業系統能夠利用的「檔案系統格式(filesystem),磁碟分割區完畢後還需要進行格式化(format),之後作業系統才能夠使用這個檔案系統
傳統的磁碟與檔案系統之應用中,一個分割區就是隻能夠被格式化成為一個檔案系統,所以我們可以說一個 filesystem 就是一個 partition。但是由於新技術的利用,例如我們常聽到的LVM與軟體磁碟陣列(software raid), 這些技術可以將一個分割區格式化為多個檔案系統(例如LVM),也能夠將多個分割區合成一個檔案系統(LVM, RAID),一個可被掛載的資料為一個檔案系統而不是一個分割區
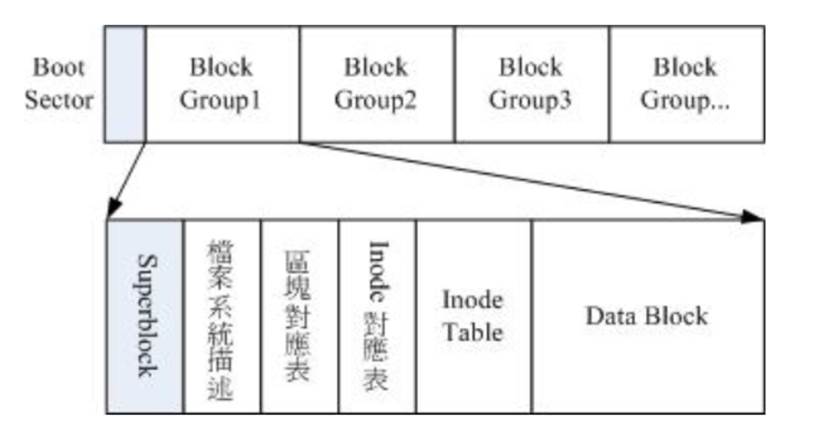
Linux 作業系統的檔案許可權(rwx)與檔案屬性(擁有者、群組、時間引數等)。 檔案系統通常會將這兩部份的資料分別存放在不同的區塊,許可權與屬性放置到 inode 中,至於實際資料則放置到 data block 區塊中。 另外,還有一個超級區塊 (superblock) 會記錄整個檔案系統的整體資訊,包括 inode 與 block 的總量、使用量、剩餘量等。
- superblock:記錄此 filesystem 的整體資訊,包括inode/block的總量、使用量、剩餘量, 以及檔案系統的格式與相關資訊等;
- inode:記錄檔案的屬性,一個檔案佔用一個inode,同時記錄此檔案的資料所在的 block 號碼;
- block:實際記錄檔案的內容,若檔案太大時,會佔用多個 block 。
2.3、EXT2檔案系統
檔案系統一開始就將 inode 與 block 規劃好了,除非重新格式化(或者利用 resize2fs 等指令變更檔案系統大小),否則 inode 與block 固定後就不再變動。
Ext2 檔案系統在格式化的時候基本上是區分為多個區塊群組 (block group) 的,每個區塊群組都有獨立的 inode/block/superblock 系統。
檔案系統最前面有一個開機磁區(boot sector),這個開機磁區可以安裝開機管理程式,
1、data block (資料區塊)
在 Ext2 檔案系統中所支援的 block 大小有 1K, 2K 及 4K 三種而已。在格式化
時 block 的大小就固定了,且每個 block 都有編號,以方便 inode 的記錄啦
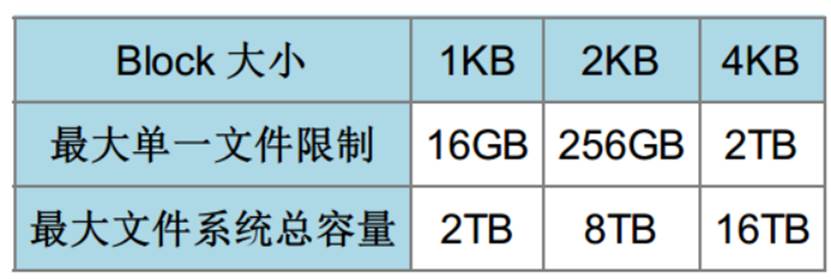
- 原則上,block 的大小與數量在格式化完就不能夠再改變了(除非重新格式化);
- 每個 block 內最多隻能夠放置一個檔案的資料;
- 承上,如果檔案大於 block 的大小,則一個檔案會佔用多個 block 數量;
- 承上,若檔案小於 block ,則該 block 的剩餘容量就不能夠再被使用了(磁碟空間會浪費)
2、inode table (inode 表格)
inode 記錄的檔案資料至少有下面這些:
- 該檔案的存取模式(read/write/excute);
- 該檔案的擁有者與群組(owner/group);
- 該檔案的容量;
- 該檔案建立或狀態改變的時間(ctime);
- 最近一次的讀取時間(atime);
- 最近修改的時間(mtime);
- 定義檔案特性的旗標(flag),如 SetUID...;
- 該檔案真正內容的指向 (pointer);
- 每個 inode 大小均固定為 128 Bytes (新的 ext4 與 xfs 可設定到 256 Bytes);
- 每個檔案都僅會佔用一個 inode 而已;
- 承上,因此檔案系統能夠建立的檔案數量與 inode 的數量有關;
- 系統讀取檔案時需要先找到 inode,並分析 inode 所記錄的許可權與使用者是否符合,若符合才能夠開始實際讀取 block 的內容
inode 記錄 block 號碼的區域定義為12個直接,一個間接, 一個雙間接與一個三間接記錄區
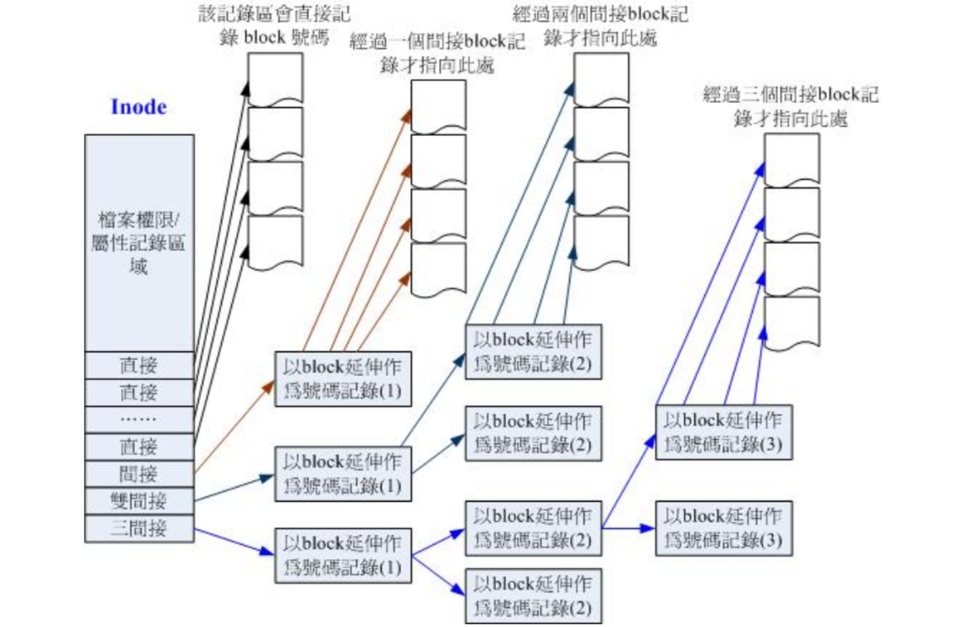
- 12 個直接指向: 12*1K=12K
由於是直接指向,所以總共可記錄 12 筆記錄,因此總額大小為如上所示;
- 間接: 256*1K=256K
每筆 block 號碼的記錄會花去 4Bytes,因此 1K 的大小能夠記錄 256 筆記錄,因此一個間接可以記錄的檔案大小如上;
- 雙間接: 2562561K=2562K
第一層 block 會指定 256 個第二層,每個第二層可以指定 256 個號碼,因此總額大小如上;
- 三間接: 256256256*1K=2563K
第一層 block 會指定 256 個第二層,每個第二層可以指定 256 個第三層,每個第三層可以指定 256 個號碼,因此總額大小如
上;
總額:將直接、間接、雙間接、三間接加總,得到 12 + 256 + 256*256 + 256*256*256 (K) = 16GB
3、Superblock (超級區塊)
主要記錄如下資訊:
-
block 與 inode 的總量;
-
未使用與已使用的 inode / block 數量;
-
block 與 inode 的大小 (block 為 1, 2, 4K,inode 為 128Bytes 或 256Bytes);
-
filesystem 的掛載時間、最近一次寫入資料的時間、最近一次檢驗磁碟 (fsck) 的時間等檔案系統的相關資訊;
-
一個 valid bit 數值,若此檔案系統已被掛載,則 valid bit 為 0 ,若未被掛載,則 valid bit 為 1 。
4、Filesystem Description (檔案系統描述說明)
描述每個 block group 的開始與結束的 block 號碼,以及說明每個區段 (superblock, bitmap, inodemap,data block) 分別介於哪一個 block 號碼之間
5、block bitmap (區塊對照表)
從 block bitmap 當中可以知道哪些 block 是空的,因此我們的系統就能夠很快速的找到可使用的空間來處置檔案,刪除block也是
6、inode bitmap (inode 對照表)
與 block bitmap 是類似的功能,只是 block bitmap 記錄的是使用與未使用的 block 號碼, 至於 inode bitmap 則是記錄使用與未使用的 inode 號碼
2.4、與目錄樹的關係
在 Linux 下的檔案系統建立一個目錄時,檔案系統會分配一個 inode 與至少一塊 block 給該目錄。其中,inode 記錄該目錄的相關許可權與屬性,並可記錄分配到的那塊 block 號碼; 而 block 則是記錄在這個目錄下的檔名與該檔名佔用的 inode號碼資料
由於目錄樹是由根目錄開始讀起,因此係統通過掛載的資訊可以找到掛載點的 inode 號碼,此時就能夠得到根目錄的inode 內容,並依據該 inode 讀取根目錄的 block 內的檔名資料,再一層一層的往下讀到正確的檔名
2.5、EXT2、EXT3、EXT4檔案的存取和紀錄檔式檔案系統
假設我們想要新增一個檔案,此時檔案系統的行為是:
-
先確定使用者對於欲新增檔案的目錄是否具有 w 與 x 的許可權,若有的話才能新增;
-
根據 inode bitmap 找到沒有使用的 inode 號碼,並將新檔案的許可權/屬性寫入;
-
根據 block bitmap 找到沒有使用中的 block 號碼,並將實際的資料寫入 block 中,且更新 inode 的 block 指向資料;
-
將剛剛寫入的 inode 與 block 資料同步更新 inode bitmap 與 block bitmap,並更新 superblock 的內容。
一般來說,我們將 inode table 與 data block 稱為資料存放區域,至於其他例如 superblock、 block bitmap 與 inodebitmap 等區段就被稱為 metadata (中介資料) ,因為 superblock, inode bitmap 及 block bitmap 的資料是經常變動的,每次新增、移除、編輯時都可能會影響到這三個部分的資料,因此才被稱為中介資料
紀錄檔式檔案系統 (Journaling filesystem)
避免的檔案系統不一致的情況發生,所以提出了紀錄檔是檔案系統(有點類似事務)
-
預備:當系統要寫入一個檔案時,會先在紀錄檔記錄區塊中紀錄某個檔案准備要寫入的資訊;
-
實際寫入:開始寫入檔案的許可權與資料;開始更新 metadata 的資料;
-
結束:完成資料與 metadata 的更新後,在紀錄檔記錄區塊當中完成該檔案的紀錄
這樣的紀錄檔式檔案系統在EXT3和EXT4中預設有
2.6、XFS檔案系統
EXT 家族當前較傷腦筋的地方:支援度最廣,但格式化超慢
xfs 就是一個紀錄檔式檔案系統,幾乎所有 Ext4 檔案系統有的功能, xfs 都可以具備!主要規劃為三個部份,一個資料區 (data section)、一個檔案系統活動登入區 (log section)以及一個實時執行區 (realtime section)。
1、資料區 (data section)
資料區就跟我們之前談到的 ext 家族一樣,包括 inode/data block/superblock 等資料,都放置在這個區塊。這個資料區與 ext 家族的 block group 類似,也是分為多個儲存區群組 (allocation groups) 來分別放置檔案系統所需要的資料。 每個儲存區群組都包含了
- (1)整個檔案系統的 superblock
- (2)剩餘空間的管理機制
- (3)inode的分配與追蹤。此
外,inode與 block 都是系統需要用到時, 這才動態設定產生,所以格式化動作超級快!另外,與 ext 家族不同的是, xfs 的 block 與 inode 有多種不同的容量可供設定,block 容量可由 512Bytes ~ 64K 調配,不過,Linux 的環境下, 由於記憶體控制的關係 (分頁檔 pagesize 的容量之故),因此最高可以使用的 block 大小為 4K 而已!
2、檔案系統活動登入區 (log section)
登入區這個區域主要被用來紀錄檔案系統的變化,其實有點像是紀錄檔區啦!檔案的變化會在這裡紀錄下來,直到該變化完整的寫入到資料區後, 該筆紀錄才會被終結。
3、實時執行區 (realtime section)
當有檔案要被建立時,xfs 會在這個區段裡面找一個到數個的 extent 區塊,將檔案放置在這個區塊內,等到分配完畢後,再寫入到 data section 的 inode 與 block 去! 這個 extent 區塊的大小得要在格式化的時候就先指定,最小值是 4K 最大可到 1G。一般非磁碟陣列的磁碟預設為 64K 容量,而具有類似磁碟陣列的 stripe 情況下,則建議 extent 設定為與 stripe 一樣大較佳。這個 extent 最好不要亂動,因為可能會影響到實體磁碟的效能喔
2.7、檔案系統的掛載和解除安裝
-
單一檔案系統不應該被重複掛載在不同的掛載點(目錄)中;
-
單一目錄不應該重複掛載多個檔案系統;
-
要作為掛載點的目錄,理論上應該都是空目錄才是
/etc/filesystems:系統指定的測試掛載檔案系統型別的優先順序;
/proc/filesystems:Linux系統已經載入的檔案系統型別
可以使用mount和umount命令進行掛載和解除安裝,詳情見相關命令
開機掛載:/etc/fstab
-
根目錄 / 是必須掛載的﹐而且一定要先於其它 mount point 被掛載進來。
-
其它 mount point 必須為已建立的目錄﹐可任意指定﹐但一定要遵守必須的系統目錄架構原則 (FHS)
-
所有 mount point 在同一時間之內﹐只能掛載一次。
-
所有 partition 在同一時間之內﹐只能掛載一次。
-
如若進行解除安裝﹐您必須先將工作目錄移到 mount point(及其子目錄) 之外
[root@study ~]# cat /etc/fstab
# Device Mount point filesystem parameters dump fsck
/dev/mapper/centos-root / xfs defaults 0 0
UUID=94ac5f77-cb8a-495e-a65b-2ef7442b837c /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
【裝置/UUID等】【掛載點】【檔案系統】【檔案系統引數】【dump】【fsck】
第一欄:磁碟裝置檔名/UUID/LABEL name:
這個欄位可以填寫的資料主要有三個專案:
-
檔案系統或磁碟的裝置檔名,如 /dev/vda2 等(不推薦使用)
-
檔案系統的 UUID 名稱,如 UUID=xxx
-
檔案系統的 LABEL 名稱,例如 LABEL=xxx
第二欄:掛載點 (mount point)::
就是掛載點啊!掛載點是什麼?一定是目錄啊~要知道啊!忘記的話,請回本章稍早之前的資料瞧瞧喔!
第三欄:磁碟分割區的檔案系統:
在手動掛載時可以讓系統自動測試掛載,但在這個檔案當中我們必須要手動寫入檔案系統才行! 包括 xfs, ext4, vfat,reiserfs, nfs 等等。
第四欄:檔案系統引數

第五欄:能否被 dump 備份指令作用:
dump 是一個用來做為備份的指令,不過現在有太多的備份方案了,所以這個專案可以不要理會啦!直接輸入 0 就好了
第六欄:是否以 fsck 檢驗磁區:
早期開機的流程中,會有一段時間去檢驗本機的檔案系統,看看檔案系統是否完整 (clean)。 不過這個方式使用的主要是通過 fsck 去做的,我們現在用的 xfs 檔案系統就沒有辦法適用,因為 xfs 會自己進行檢驗,不需要額外進行這個動作!所以直接填 0 就好了
2.8、記憶體交換空間swap建立
-
分割區:先使用 gdisk 在你的磁碟中分割區出一個分割區給系統作為 swap 。由於 Linux 的 gdisk 預設會將分割區的 ID 設定為 Linux 的
-
檔案系統,所以你可能還得要設定一下 system ID 就是了。
-
格式化:利用建立 swap 格式的「mkswap 裝置檔名」就能夠格式化該分割區成為 swap 格式囉
-
使用:最後將該 swap 裝置啟動,方法為:「swapon 裝置檔名」。
-
觀察:最終通過 free 與 swapon -s 這個指令來觀察一下記憶體的用量吧!
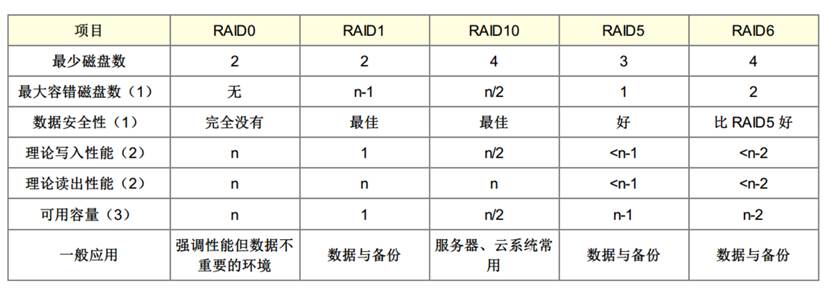
2.9、RAID
RAID-0 (等量模式, stripe):效能最佳:越多顆磁碟組成的 RAID-0 效能會越好,因為每顆負責的資料量就更低了,RAID-0 只要有任何一顆磁碟損毀,在 RAID 上面的所有資料都會遺失而無法讀取
RAID-1 (對映模式, mirror):完整備份:讓同一份資料,完整的儲存在兩顆磁碟上頭,整體 RAID 的容量幾乎少了 50%
RAID 1+0,RAID 0+1:(1)先讓兩顆磁碟組成 RAID 1,並且這樣的設定共有兩組;(2)將這兩組 RAID 1 再組成一組 RAID 0。這就是 RAID 1+0 囉!反過來說,RAID 0+1 就是先組成 RAID-0 再組成 RAID-1 的意思
RAID 5:效能與資料備份的均衡考慮:RAID5 至少需要三顆以上的磁碟才能夠組成這種型別的磁碟陣列,RAID 5 預設僅能支援一顆磁碟的損毀情況
Spare Disk:預備磁碟的功能:當磁碟陣列的磁碟損毀時,就得要將壞掉的磁碟拔除,然後換一顆新的磁碟。換成新磁碟並且順利啟動磁碟陣列後, 磁碟陣列就會開始主動的重建 (rebuild) 原本壞掉的那顆磁碟資料到新的磁碟上!然後你磁碟陣列上面的資料就復原了! 這就是磁碟陣列的優點
spare disk 就是一顆或多顆沒有包含在原本磁碟陣列等級中的磁碟,這顆磁碟平時並不會被磁碟陣列所使用, 當磁碟陣列有任何磁碟損毀時,則這顆 spare disk 會被主動的拉進磁碟陣列中,並將壞掉的那顆硬碟移出磁碟陣列! 然後立即重建資料系統。如此你的系統則可以永保安康啊!若你的磁碟陣列有支援熱拔插那就更完美了
磁碟陣列的優點
-
資料安全與可靠性:指的並非網路資訊保安,而是當硬體 (指磁碟) 損毀時,資料是否還能夠安全的救援或使用之意;
-
讀寫效能:例如 RAID 0 可以加強讀寫效能,讓你的系統 I/O 部分得以改善;
-
容量:可以讓多顆磁碟組合起來,故單一檔案系統可以有相當大的容量。
關閉RAID
# 1. 先解除安裝且刪除組態檔內與這個 /dev/md0 有關的設定:
[root@study ~]# umount /srv/raid
[root@study ~]# vim /etc/fstab
UUID=494cb3e1-5659-4efc-873d-d0758baec523 /srv/raid xfs defaults 0 0
# 將這一行刪除掉!或者是註解掉也可以!
# 2. 先覆蓋掉 RAID 的 metadata 以及 XFS 的 superblock,才關閉 /dev/md0 的方法
[root@study ~]# dd if=/dev/zero of=/dev/md0 bs=1M count=50
[root@study ~]# mdadm --stop /dev/md0
mdadm: stopped /dev/md0 <==不囉唆!這樣就關閉了!
[root@study ~]# dd if=/dev/zero of=/dev/vda5 bs=1M count=10
[root@study ~]# dd if=/dev/zero of=/dev/vda6 bs=1M count=10
[root@study ~]# dd if=/dev/zero of=/dev/vda7 bs=1M count=10
[root@study ~]# dd if=/dev/zero of=/dev/vda8 bs=1M count=10
[root@study ~]# dd if=/dev/zero of=/dev/vda9 bs=1M count=10
[root@study ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
unused devices: <none> <==看吧!確實不存在任何陣列裝置!
[root@study ~]# vim /etc/mdadm.conf
#ARRAY /dev/md0 UUID=2256da5f:4870775e:cf2fe320:4dfabbc6
# 一樣啦!刪除他或是註解他!
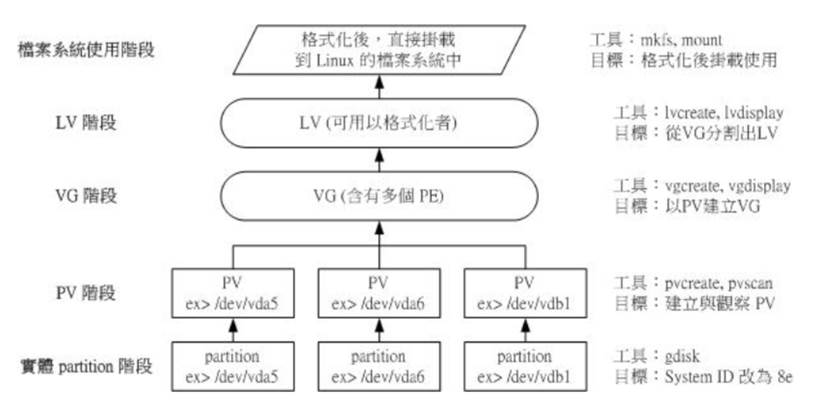
2.10、邏輯卷管理
Physical Volume, PV, 實體卷軸:我們實際的 partition (或 Disk) 需要調整系統識別碼 (system ID) 成為 8e (LVM 的識別碼),然後再經過pvcreate 的指令將他轉成 LVM 最底層的實體卷軸 (PV) ,之後才能夠將這些 PV 加以利用! 調整 system ID 的方是就是通過 gdisk 啦!
Volume Group, VG, 卷軸群組:所謂的 LVM 大磁碟就是將許多 PV 整合成這個 VG 的東西就是啦!所以 VG 就是 LVM 組合起來的大磁碟!
Physical Extent, PE, 實體範圍區塊:LVM 預設使用 4MB 的 PE 區塊,而 LVM 的 LV 在 32 位系統上最多僅能含有 65534 個 PE (lvm1 的格式)
Logical Volume, LV, 邏輯卷軸:最終的 VG 還會被切成 LV,這個 LV 就是最後可以被格式化使用的類似分割區
資料寫入這個LV 時,到底他是怎麼寫入硬碟當中的? 呵呵!好問題~其實,依據寫入機制的不同,而有兩種方式:
-
線性模式 (linear):假如我將 /dev/vda1, /dev/vdb1 這兩個 partition 加入到 VG 當中,並且整個 VG 只有一個 LV 時,那麼所謂的線性模式就是:當 /dev/vda1 的容量用完之後,/dev/vdb1 的硬碟才會被使用到, 這也是我們所建議的模式。
-
交錯模式 (triped):那什麼是交錯模式?很簡單啊,就是我將一筆資料拆成兩部分,分別寫入 /dev/vda1 與 /dev/vdb1 的意思,感覺上有點像 RAID 0 啦!如此一來,一份資料用兩顆硬碟來寫入,理論上,讀寫的效能會比較好。
三、磁碟相關命令
3.1、dumpe2fs
查詢 Ext 家族 superblock 資訊的指令
[root@study ~]# dumpe2fs [-bh] 裝置檔名
選項與引數:
-b :列出保留為壞軌的部分(一般用不到吧!?)
-h :僅列出 superblock 的資料,不會列出其他的區段內容!
範例:鳥哥的一塊 1GB ext4 檔案系統內容
[root@study ~]# blkid <==這個指令可以叫出目前系統有被格式化的裝置
/dev/vda1: LABEL="myboot" UUID="ce4dbf1b-2b3d-4973-8234-73768e8fd659" TYPE="xfs"
/dev/vda2: LABEL="myroot" UUID="21ad8b9a-aaad-443c-b732-4e2522e95e23" TYPE="xfs"
/dev/vda3: UUID="12y99K-bv2A-y7RY-jhEW-rIWf-PcH5-SaiApN" TYPE="LVM2_member"
/dev/vda5: UUID="e20d65d9-20d4-472f-9f91-cdcfb30219d6" TYPE="ext4" <==看到 ext4 了!
[root@study ~]# dumpe2fs /dev/vda5
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name: <none> # 檔案系統的名稱(不一定會有)
Last mounted on: <not available> # 上一次掛載的目錄位置
Filesystem UUID: e20d65d9-20d4-472f-9f91-cdcfb30219d6
Filesystem magic number: 0xEF53 # 上方的 UUID 為 Linux 對裝置的定義碼
Filesystem revision #: 1 (dynamic) # 下方的 features 為檔案系統的特徵資料
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit
flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl # 預設在掛載時會主動加上的掛載引數
Filesystem state: clean # 這塊檔案系統的狀態為何,clean 是沒問題
Errors behavior: Continue
Filesystem OS type: LinuxInode count: 65536 # inode 的總數
Block count: 262144 # block 的總數
Reserved block count: 13107 # 保留的 block 總數
Free blocks: 249189 # 還有多少的 block 可用數量
Free inodes: 65525 # 還有多少的 inode 可用數量
First block: 0
Block size: 4096 # 單個 block 的容量大小
Fragment size: 4096
Group descriptor size: 64
....(中間省略)....
Inode size: 256 # inode 的容量大小!已經是 256 了喔!
....(中間省略)....
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 3c2568b4-1a7e-44cf-95a2-c8867fb19fbc
Journal backup: inode blocks
Journal features: (none)
Journal size: 32M # Journal 紀錄檔式資料的可供紀錄總容量
Journal length: 8192
Journal sequence: 0x00000001
Journal start: 0
Group 0: (Blocks 0-32767) # 第一塊 block group 位置
Checksum 0x13be, unused inodes 8181
Primary superblock at 0, Group descriptors at 1-1 # 主要 superblock 的所在喔!
Reserved GDT blocks at 2-128
Block bitmap at 129 (+129), Inode bitmap at 145 (+145)
Inode table at 161-672 (+161) # inode table 的所在喔!
28521 free blocks, 8181 free inodes, 2 directories, 8181 unused inodes
Free blocks: 142-144, 153-160, 4258-32767 # 下面兩行說明剩餘的容量有多少
Free inodes: 12-8192
Group 1: (Blocks 32768-65535) [INODE_UNINIT] # 後續為更多其他的 block group 喔!
-
Group0 所佔用的 block 號碼由 0 到 32767 號,superblock 則在第 0 號的 block 區塊內!
-
檔案系統描述說明在第 1 號 block 中;
-
block bitmap 與 inode bitmap 則在 129 及 145 的 block 號碼上。
-
至於 inode table 分佈於 161-672 的 block 號碼中!
-
由於 (1)一個 inode 佔用 256 Bytes ,(2)總共有 672 - 161 + 1(161本身) = 512 個 block 花在 inode table 上, (3)每
-
個 block 的大小為 4096 Bytes(4K)。由這些資料可以算出 inode 的數量共有 512 * 4096 / 256 = 8192 個 inode 啦!
-
這個 Group0 目前可用的 block 有 28521 個,可用的 inode 有 8181 個;
-
剩餘的 inode 號碼為 12 號到 8192 號
3.2、xfs_info
[root@study ~]# xfs_info 掛載點|裝置檔名
範例一:找出系統 /boot 這個掛載點下面的檔案系統的 superblock 紀錄
[root@study ~]# df -T /boot
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/vda2 xfs 1038336 133704 904632 13% /boot
# 沒錯!可以看得出來是 xfs 檔案系統的!來觀察一下內容吧!
[root@study ~]# xfs_info /dev/vda2
1 meta-data=/dev/vda2 isize=256 agcount=4, agsize=65536 blks
2 = sectsz=512 attr=2, projid32bit=1
3 = crc=0 finobt=0
4 data = bsize=4096 blocks=262144, imaxpct=25
5 = sunit=0 swidth=0 blks
6 naming =version 2 bsize=4096 ascii-ci=0 ftype=0
7 log =internal bsize=4096 blocks=2560, version=2
8 = sectsz=512 sunit=0 blks, lazy-count=1
9 realtime =none extsz=4096 blocks=0, rtextents=0
-
第 1 行裡面的 isize 指的是 inode 的容量,每個有 256Bytes 這麼大。至於 agcount 則是前面談到的儲存區群組 (allocationgroup) 的個數,共有 4 個, agsize 則是指每個儲存區群組具有 65536 個 block 。配合第 4 行的 block 設定為 4K,因此整個檔案系統的容量應該就是 4655364K 這麼大!
-
第 2 行裡面 sectsz 指的是邏輯磁區 (sector) 的容量設定為 512Bytes 這麼大的意思。
-
第 4 行裡面的 bsize 指的是 block 的容量,每個 block 為 4K 的意思,共有 262144 個 block 在這個檔案系統內。
-
第 5 行裡面的 sunit 與 swidth 與磁碟陣列的 stripe 相關性較高。這部份我們下面格式化的時候會舉一個例子來說明。
-
第 7 行裡面的 internal 指的是這個登入區的位置在檔案系統內,而不是外部裝置的意思。且佔用了 4K * 2560 個 block,總共約10M 的容量。
-
第 9 行裡面的 realtime 區域,裡面的 extent 容量為 4K。不過目前沒有使用
3.3、df
列出檔案系統的整體磁碟使用量
[root@study ~]# df [-ahikHTm] [目錄或檔名]
選項與引數:
-a :列出所有的檔案系統,包括系統特有的 /proc 等檔案系統;
-k :以 KBytes 的容量顯示各檔案系統;
-m :以 MBytes 的容量顯示各檔案系統;
-h :以人們較易閱讀的 GBytes, MBytes, KBytes 等格式自行顯示;
-H :以 M=1000K 取代 M=1024K 的進位方式;
-T :連同該 partition 的 filesystem 名稱 (例如 xfs) 也列出;
-i :不用磁碟容量,而以 inode 的數量來顯示
範例一:將系統內所有的 filesystem 列出來!
[root@study ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/centos-root 10475520 3409408 7066112 33% /
devtmpfs 627700 0 627700 0% /dev
tmpfs 637568 80 637488 1% /dev/shm
tmpfs 637568 24684 612884 4% /run
tmpfs 637568 0 637568 0% /sys/fs/cgroup
/dev/mapper/centos-home 5232640 67720 5164920 2% /home
/dev/vda2 1038336 133704 904632 13% /boot
# 在 Linux 下面如果 df 沒有加任何選項,那麼預設會將系統內所有的
# (不含特殊記憶體內的檔案系統與 swap) 都以 1 KBytes 的容量來列出來!
# 至於那個 /dev/shm 是與記憶體有關的掛載,大小為記憶體的一半,重啟會丟失資料
-
Filesystem:代表該檔案系統是在哪個 partition ,所以列出裝置名稱;
-
1k-blocks:說明下面的數位單位是 1KB 呦!可利用 -h 或 -m 來改變容量;
-
Used:顧名思義,就是使用掉的磁碟空間啦!
-
Available:也就是剩下的磁碟空間大小;
-
Use%:就是磁碟的使用率啦!如果使用率高達 90% 以上時, 最好需要注意一下了,免得容量不足造成系統問題喔!(例如最容易被灌爆的 /var/spool/mail 這個放置郵件的磁碟)
-
Mounted on:就是磁碟掛載的目錄所在啦!(掛載點啦!)
系統裡面其實還有很多特殊的檔案系統存在的。那些比較特殊的檔案系統幾乎都是在記憶體當中,例如 /proc 這個掛載點。因此,這些特殊的檔案系統都不會佔據磁碟空間喔!
由於 df 主要讀取的資料幾乎都是針對一整個檔案系統,因此讀取的範圍主要是在 Superblock 內的資訊, 所以這個指令顯示結果的速度非常的快速!
/dev/shm/ 目錄,其實是利用記憶體虛擬出來的磁碟空間,通常是總實體記憶體的一半! 由於是通過記憶體模擬出來的磁碟,因此你在這個目錄下面建立任何資料檔案時,存取速度是非常快速的!(在記憶體內工作) 不過,也由於他是記憶體模擬出來的,因此這個檔案系統的大小在每部主機上都不一樣,而且建立的東西在下次開機時就消失了! 因為是在記憶體中嘛!
3.4、du
評估檔案系統的磁碟使用量(常用在推估目錄所佔容量)
[root@study ~]# du [-ahskm] 檔案或目錄名稱
選項與引數:
-a :列出所有的檔案與目錄容量,因為預設僅統計目錄下面的檔案量而已。
-h :以人們較易讀的容量格式 (G/M) 顯示;
-s :列出總量而已,而不列出每個各別的目錄佔用容量;
-S :不包括子目錄下的總計,與 -s 有點差別。
-k :以 KBytes 列出容量顯示;
-m :以 MBytes 列出容量顯示;
範例一:列出目前目錄下的所有檔案大小
[root@study ~]# du
4 ./.cache/dconf <==每個目錄都會列出來
4 ./.cache/abrt
8 ./.cache
....(中間省略)....
0 ./test4
4 ./.ssh <==包括隱藏檔案的目錄
76 . <==這個目錄(.)所佔用的總量
# 直接輸入 du 沒有加任何選項時,則 du 會分析「目前所在目錄」
# 的檔案與目錄所佔用的磁碟空間。但是,實際顯示時,僅會顯示目錄容量(不含檔案),
# 因此 . 目錄有很多檔案沒有被列出來,所以全部的目錄相加不會等於 . 的容量喔!
# 此外,輸出的數值資料為 1K 大小的容量單位。
一般使用du -hs *統計當前目錄下第一級子目錄的大小
3.5、ln
Linux 下面的連結檔案有兩種,一種是類似 Windows 的捷徑功能的檔案,可以讓你快速的連結到目標檔案(或目錄); 另一種則是通過檔案系統的 inode 連結來產生新檔名,而不是產生新檔案!這種稱為實體連結 (hard link)
Hard Link (實體連結, 硬式連結或實際連結)
- 每個檔案都會佔用一個 inode ,檔案內容由 inode 的記錄來指向;
- 想要讀取該檔案,必須要經過目錄記錄的檔名來指向到正確的 inode 號碼才能讀取
- 如果你將任何一個「檔名」刪除,其實 inode 與 block 都還是存在的!
- hard link 只是在某個目錄下的 block 多寫入一個關連資料而已,既不會增加 inode 也不會耗用 block 數量
- 不能跨 Filesystem;
- 不能 link 目錄
Symbolic Link (符號連結,亦即是捷徑)
ymbolic link 就是在建立一個獨立的檔案,而這個檔案會讓資料的讀取指向他 link 的那個檔案的檔名
[root@study ~]# ln [-sf] 來原始檔 目標檔案
選項與引數:
-s :如果不加任何引數就進行連結,那就是hard link,至於 -s 就是symbolic link
-f :如果 目標檔案存在時,就主動的將目標檔案直接移除後再建立!
範例一:將 /etc/passwd 複製到 /tmp 下面,並且觀察 inode 與 block
[root@study ~]# cd /tmp
[root@study tmp]# cp -a /etc/passwd .
[root@study tmp]# du -sb ; df -i .
6602 . <==先注意一下這裡的容量是多少!
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/mapper/centos-root 10485760 109748 10376012 2% /
# 利用 du 與 df 來檢查一下目前的引數~那個 du -sb 是計算整個 /tmp 下面有多少 Bytes 的容量啦!
3.6、lsblk
lsblk 列出系統上的所有磁碟列表
[root@study ~]# lsblk [-dfimpt] [device]
選項與引數:
-d :僅列出磁碟本身,並不會列出該磁碟的分割區資料
-f :同時列出該磁碟內的檔案系統名稱
-i :使用 ASCII 的線段輸出,不要使用複雜的編碼 (再某些環境下很有用)
-m :同時輸出該裝置在 /dev 下面的許可權資料 (rwx 的資料)
-p :列出該裝置的完整檔名!而不是僅列出最後的名字而已。
-t :列出該磁碟裝置的詳細資料,包括磁碟佇列機制、預讀寫的資料量大小等
範例一:列出本系統下的所有磁碟與磁碟內的分割區資訊
[root@study ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 40G 0 disk # 一整顆磁碟
|-vda1 252:1 0 2M 0 part
|-vda2 252:2 0 1G 0 part /boot
`-vda3 252:3 0 30G 0 part
|-centos-root 253:0 0 10G 0 lvm / # 在 vda3 內的其他檔案系統
|-centos-swap 253:1 0 1G 0 lvm [SWAP]
`-centos-home 253:2 0 5G 0 lvm /home
- NAME:就是裝置的檔名囉!會省略 /dev 等前導目錄!
- MAJ:MIN:其實核心認識的裝置都是通過這兩個程式碼來熟悉的!分別是主要:次要裝置程式碼!
- RM:是否為可解除安裝裝置 (removable device),如光碟、USB 磁碟等等
- SIZE:當然就是容量囉!
- RO:是否為唯讀裝置的意思
- TYPE:是磁碟 (disk)、分割區 (partition) 還是唯讀記憶體 (rom) 等輸出
- MOUTPOINT:就是前一章談到的掛載點
3.7、blkid
列出裝置的 UUID 等引數,lsblk 已經可以使用 -f 來列出檔案系統與裝置的 UUID 資料
[root@study ~]# blkid
/dev/vda2: UUID="94ac5f77-cb8a-495e-a65b-2ef7442b837c" TYPE="xfs"
/dev/vda3: UUID="WStYq1-P93d-oShM-JNe3-KeDl-bBf6-RSmfae" TYPE="LVM2_member"
/dev/sda1: UUID="35BC-6D6B" TYPE="vfat"
/dev/mapper/centos-root: UUID="299bdc5b-de6d-486a-a0d2-375402aaab27" TYPE="xfs"
/dev/mapper/centos-swap: UUID="905dc471-6c10-4108-b376-a802edbd862d" TYPE="swap"
/dev/mapper/centos-home: UUID="29979bf1-4a28-48e0-be4a-66329bf727d9" TYPE="xfs"
3.8、parted
磁碟的分割區型別,還可以進行分割區的相關操作
[root@study ~]# parted device_name print
範例一:列出 /dev/vda 磁碟的相關資料
[root@study ~]# parted /dev/vda print
Model: Virtio Block Device (virtblk) # 磁碟的模組名稱(廠商)
Disk /dev/vda: 42.9GB # 磁碟的總容量
Sector size (logical/physical): 512B/512B # 磁碟的每個邏輯/物理磁區容量
Partition Table: gpt # 分割區表的格式 (MBR/GPT)
Disk Flags: pmbr_boot
Number Start End Size File system Name Flags # 下面才是分割區資料
1 1049kB 3146kB 2097kB bios_grub
2 3146kB 1077MB 1074MB xfs
3 1077MB 33.3GB 32.2GB lvm
[root@study ~]# parted [裝置] [指令 [引數]]
選項與引數:
指令功能:
新增分割區:mkpart [primary|logical|extended] [ext4|vfat|xfs] 開始 結束
顯示分割區:print
刪除分割區:rm [partition]
範例一:以 parted 列出目前本機的分割區表資料
[root@study ~]# parted /dev/vda print
Model: Virtio Block Device (virtblk) <==磁碟介面與型號
Disk /dev/vda: 42.9GB <==磁碟檔名與容量
Sector size (logical/physical): 512B/512B <==每個磁區的大小
Partition Table: gpt <==是 GPT 還是 MBR 分割區
Disk Flags: pmbr_boot
Number Start End Size File system Name Flags
1 1049kB 3146kB 2097kB bios_grub
2 3146kB 1077MB 1074MB xfs
3 1077MB 33.3GB 32.2GB lvm
4 33.3GB 34.4GB 1074MB xfs Linux filesystem
5 34.4GB 35.4GB 1074MB ext4 Microsoft basic data
6 35.4GB 36.0GB 537MB linux-swap(v1) Linux swap
[ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ]
-
Number:這個就是分割區的號碼啦!舉例來說,1號代表的是 /dev/vda1 的意思;
-
Start:分割區的起始位置在這顆磁碟的多少 MB 處?有趣吧!他以容量作為單位喔!
-
End:此分割區的結束位置在這顆磁碟的多少 MB 處?
-
Size:由上述兩者的分析,得到這個分割區有多少容量;
-
File system:分析可能的檔案系統型別為何的意思!
-
Name:就如同 gdisk 的 System ID 之意。
3.9、gdisk/fdisk
MBR 分割區表請使用 fdisk 分割區, GPT 分割區表請使用 gdisk 分割區
[root@study ~]# gdisk 裝置名稱
範例:由前一小節的 lsblk 輸出,我們知道系統有個 /dev/vda,請觀察該磁碟的分割區與相關資料
[root@study ~]# gdisk /dev/vda <==仔細看,不要加上數位喔!
GPT fdisk (gdisk) version 0.8.6
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT. <==找到了 GPT 的分割區表!
Command (? for help): <==這裡可以讓你輸入指令動作,可以按問號 (?) 來檢視可用指令
Command (? for help): ?
b back up GPT data to a file
c change a partition's name
d delete a partition # 刪除一個分割區
i show detailed information on a partition
l list known partition types
n add a new partition # 增加一個分割區
o create a new empty GUID partition table (GPT)
p print the partition table # 印出分割區表 (常用)
q quit without saving changes # 不儲存分割區就直接離開 gdisk
r recovery and transformation options (experts only)
s sort partitions
t change a partition's type code
v verify disk
w write table to disk and exit # 儲存分割區操作後離開 gdisk
x extra functionality (experts only)
? print this menu
Command (? for help):
應該要通過 lsblk 或 blkid 先找到磁碟,再用 parted /dev/xxx print 來找出內部的分割區表型別,之後才用 gdisk 或 fdisk 來作業系統
fdisk 跟 gdisk 使用的方式幾乎一樣!只是一個使用 ? 作為指令提示資料,一個使用 m 作為提示這樣而已
3.10、partprobe
更新 Linux 核心的分割區表資訊,分割區後可以使用該命令進行更新
[root@study ~]# partprobe [-s] # 你可以不要加 -s !那麼螢幕不會出現訊息!
[root@study ~]# partprobe -s # 不過還是建議加上 -s 比較清晰!
/dev/vda: gpt partitions 1 2 3 4 5 6
[root@study ~]# lsblk /dev/vda # 實際的磁碟分割區狀態
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 252:0 0 40G 0 disk
|-vda1 252:1 0 2M 0 part
|-vda2 252:2 0 1G 0 part /boot
|-vda3 252:3 0 30G 0 part
| |-centos-root 253:0 0 10G 0 lvm /
| |-centos-swap 253:1 0 1G 0 lvm [SWAP]
| `-centos-home 253:2 0 5G 0 lvm /home
|-vda4 252:4 0 1G 0 part
|-vda5 252:5 0 1G 0 part
`-vda6 252:6 0 500M 0 part
[root@study ~]# cat /proc/partitions # 核心的分割區紀錄
major minor #blocks name
252 0 41943040 vda
252 1 2048 vda1
252 2 1048576 vda2
252 3 31461376 vda3
252 4 1048576 vda4
252 5 1048576 vda5
252 6 512000 vda6
# 現在核心也正確的抓到了分割區引數了!
3.11、mkfs.xfs
建立 xfs 檔案系統, 因此使用的是 mkfs.xfs 這個指令
[root@study ~]# mkfs.xfs [-b bsize] [-d parms] [-i parms] [-l parms] [-L label] [-f] \
[-r parms] 裝置名稱
選項與引數:
關於單位:下面只要談到「數值」時,沒有加單位則為 Bytes 值,可以用 k,m,g,t,p (小寫)等來解釋
比較特殊的是 s 這個單位,它指的是 sector 的「個數」喔!
-b :後面接的是 block 容量,可由 512 到 64k,不過最大容量限制為 Linux 的 4k 喔!
-d :後面接的是重要的 data section 的相關引數值,主要的值有:
agcount=數值 :設定需要幾個儲存群組的意思(AG),通常與 CPU 有關
agsize=數值 :每個 AG 設定為多少容量的意思,通常 agcount/agsize 只選一個設定即可
file :指的是「格式化的裝置是個檔案而不是個裝置」的意思!(例如虛擬磁碟)
size=數值 :data section 的容量,亦即你可以不將全部的裝置容量用完的意思
su=數值 :當有 RAID 時,那個 stripe 數值的意思,與下面的 sw 搭配使用
sw=數值 :當有 RAID 時,用於儲存資料的磁碟數量(須扣除備份碟與備用碟)
sunit=數值 :與 su 相當,不過單位使用的是「幾個 sector(512Bytes大小)」的意思
swidth=數值 :就是 su*sw 的數值,但是以「幾個 sector(512Bytes大小)」來設定
-f :如果裝置內已經有檔案系統,則需要使用這個 -f 來強制格式化才行!
-i :與 inode 有較相關的設定,主要的設定值有:
size=數值 :最小是 256Bytes 最大是 2k,一般保留 256 就足夠使用了!
internal=[0|1]:log 裝置是否為內建?預設為 1 內建,如果要用外部裝置,使用下面設定
logdev=device :log 裝置為後面接的那個裝置上頭的意思,需設定 internal=0 才可!
size=數值 :指定這塊登入區的容量,通常最小得要有 512 個 block,大約 2M 以上才行!
-L :後面接這個檔案系統的檔頭名稱 Label name 的意思!
-r :指定 realtime section 的相關設定值,常見的有:
extsize=數值 :就是那個重要的 extent 數值,一般不須設定,但有 RAID 時,
最好設定與 swidth 的數值相同較佳!最小為 4K 最大為 1G 。
範例:將前一小節分割區出來的 /dev/vda4 格式化為 xfs 檔案系統
[root@study ~]# mkfs.xfs /dev/vda4
meta-data=/dev/vda4 isize=256 agcount=4, agsize=65536 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# 很快格是化完畢!都用預設值!較重要的是 inode 與 block 的數值
[root@study ~]# blkid /dev/vda4
/dev/vda4: UUID="39293f4f-627b-4dfd-a
3.12、mkfs.ext4
格式化為ext4檔案系統
[root@study ~]# mkfs.ext4 [-b size] [-L label] 裝置名稱
選項與引數:
-b :設定 block 的大小,有 1K, 2K, 4K 的容量,
-L :後面接這個裝置的檔頭名稱。
範例:將 /dev/vda5 格式化為 ext4 檔案系統Tips
[root@study ~]# mkfs.ext4 /dev/vda5
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label= # 顯示 Label name
OS type: Linux
Block size=4096 (log=2) # 每一個 block 的大小
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks # 跟 RAID 相關性較高
65536 inodes, 262144 blocks # 總計 inode/block 的數量
13107 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=268435456
8 block groups # 共有 8 個 block groups 喔!
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: done
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
[root@study ~]# dumpe2fs -h /dev/vda5
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: 3fd5cc6f-a47d-46c0-98c0-d43b072e0e12
....(中間省略)....
Inode count: 65536
Block count: 262144
Block size: 4096
Blocks per group: 32768
Inode size: 256
Journal size: 32M
3.13、xfs_repair
處理 XFS 檔案系統,當有 xfs 檔案系統錯亂才需要使用這個指令!所以,這個指令最好是不要用到啦
[root@study ~]# xfs_repair [-fnd] 裝置名稱
選項與引數:
-f :後面的裝置其實是個檔案而不是實體裝置
-n :單純檢查並不修改檔案系統的任何資料 (檢查而已)
-d :通常用在單人維護模式下面,針對根目錄 (/) 進行檢查與修復的動作!很危險!不要隨便使用
範例:檢查一下剛剛建立的 /dev/vda4 檔案系統
[root@study ~]# xfs_repair /dev/vda4
Phase 1 - find and verify superblock...
Phase 2 - using internal log
Phase 3 - for each AG...
Phase 4 - check for duplicate blocks...
Phase 5 - rebuild AG headers and trees...
Phase 6 - check inode connectivity...
Phase 7 - verify and correct link counts...
done
# 共有 7 個重要的檢查流程!詳細的流程介紹可以 man xfs_repair 即可!
範例:檢查一下系統原本就有的 /dev/centos/home 檔案系統
[root@study ~]# xfs_repair /dev/centos/home
xfs_repair: /dev/centos/home contains a mounted filesystem
xfs_repair: /dev/centos/home contains a mounted and writable filesystem
fatal error -- couldn't initialize XFS library
3.14、fsck.ext4
處理 EXT4 檔案系統fsck 是個綜合指令,如果是針對 ext4 的話,建議直接使用 fsck.ext4 來檢測比較妥當
[root@study ~]# fsck.ext4 [-pf] [-b superblock] 裝置名稱
選項與引數:
-p :當檔案系統在修復時,若有需要回復 y 的動作時,自動回覆 y 來繼續進行修復動作。
-f :強制檢查!一般來說,如果 fsck 沒有發現任何 unclean 的旗標,不會主動進入
細部檢查的,如果您想要強制 fsck 進入細部檢查,就得加上 -f 旗標囉!
-D :針對檔案系統下的目錄進行最佳化設定。
-b :後面接 superblock 的位置!一般來說這個選項用不到。但是如果你的 superblock 因故損毀時,
通過這個引數即可利用檔案系統內備份的 superblock 來嘗試救援。一般來說,superblock 備份在:
1K block 放在 8193, 2K block 放在 16384, 4K block 放在 32768
範例:找出剛剛建立的 /dev/vda5 的另一塊 superblock,並據以檢測系統
[root@study ~]# dumpe2fs -h /dev/vda5 | grep 'Blocks per group'
Blocks per group: 32768
# 看起來每個 block 群組會有 32768 個 block,因此第二個 superblock 應該就在 32768 上!
# 因為 block 號碼為 0 號開始編的!
[root@study ~]# fsck.ext4 -b 32768 /dev/vda5
e2fsck 1.42.9 (28-Dec-2013)
/dev/vda5 was not cleanly unmounted, check forced.
Pass 1: Checking inodes, blocks, and sizes
Deleted inode 1577 has zero dtime. Fix<y>? yes
Pass 2: Checking directory structurePass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/vda5: ***** FILE SYSTEM WAS MODIFIED ***** # 檔案系統被改過,所以這裡會有警告!
/dev/vda5: 11/65536 files (0.0% non-contiguous), 12955/262144 blocks
# 好巧合!鳥哥使用這個方式來檢驗系統,恰好遇到檔案系統出問題!於是可以有比較多的解釋方向!
# 當檔案系統出問題,它就會要你選擇是否修復~如果修復如上所示,按下 y 即可!
# 最終系統會告訴你,檔案系統已經被更改過,要注意該專案的意思!
3.15、mount
[root@study ~]# mount -a
[root@study ~]# mount [-l]
[root@study ~]# mount [-t 檔案系統] LABEL='' 掛載點
[root@study ~]# mount [-t 檔案系統] UUID='' 掛載點 # 鳥哥近期建議用這種方式喔!
[root@study ~]# mount [-t 檔案系統] 裝置檔名 掛載點
選項與引數:
-a :依照組態檔 /etc/fstab 的資料將所有未掛載的磁碟都掛載上來
-l :單純的輸入 mount 會顯示目前掛載的資訊。加上 -l 可增列 Label 名稱!
-t :可以加上檔案系統種類來指定欲掛載的型別。常見的 Linux 支援型別有:xfs, ext3, ext4,
reiserfs, vfat, iso9660(光碟格式), nfs, cifs, smbfs (後三種為網路檔案系統型別)
-n :在預設的情況下,系統會將實際掛載的情況實時寫入 /etc/mtab 中,以利其他程式的執行。
但在某些情況下(例如單人維護模式)為了避免問題會刻意不寫入。此時就得要使用 -n 選項。
-o :後面可以接一些掛載時額外加上的引數!比方說帳號、密碼、讀寫許可權等:
async, sync: 此檔案系統是否使用同步寫入 (sync) 或非同步 (async) 的
記憶體機制,請參考檔案系統執行方式。預設為 async。
atime,noatime: 是否修訂檔案的讀取時間(atime)。為了效能,某些時刻可使用 noatime
ro, rw: 掛載檔案系統成為唯讀(ro) 或可讀寫(rw)
auto, noauto: 允許此 filesystem 被以 mount -a 自動掛載(auto)
dev, nodev: 是否允許此 filesystem 上,可建立裝置檔案? dev 為可允許
suid, nosuid: 是否允許此 filesystem 含有 suid/sgid 的檔案格式?
exec, noexec: 是否允許此 filesystem 上擁有可執行 binary 檔案?
user, nouser: 是否允許此 filesystem 讓任何使用者執行 mount ?一般來說,
mount 僅有 root 可以進行,但下達 user 引數,則可讓
一般 user 也能夠對此 partition 進行 mount 。
defaults: 預設值為:rw, suid, dev, exec, auto, nouser, and async
remount: 重新掛載,這在系統出錯,或重新更新引數時,很有用!
3.16、umount
[root@study ~]# umount [-fn] 裝置檔名或掛載點
選項與引數:
-f :強制解除安裝!可用在類似網路檔案系統 (NFS) 無法讀取到的情況下;
-l :立刻解除安裝檔案系統,比 -f 還強!
-n :不更新 /etc/mtab 情況下解除安裝。
3.17、mdadm
[root@study ~]# mdadm --detail /dev/md0
[root@study ~]# mdadm --create /dev/md[0-9] --auto=yes --level=[015] --chunk=NK \
> --raid-devices=N --spare-devices=N /dev/sdx /dev/hdx...
選項與引數:
--create :為建立 RAID 的選項;
--auto=yes :決定建立後面接的軟體磁碟陣列裝置,亦即 /dev/md0, /dev/md1...
--chunk=Nk :決定這個裝置的 chunk 大小,也可以當成 stripe 大小,一般是 64K 或 512K。
--raid-devices=N :使用幾個磁碟 (partition) 作為磁碟陣列的裝置
--spare-devices=N :使用幾個磁碟作為備用 (spare) 裝置
--level=[015] :設定這組磁碟陣列的等級。支援很多,不過建議只要用 0, 1, 5 即可
--detail :後面所接的那個磁碟陣列裝置的詳細資訊
[root@study ~]# mdadm --manage /dev/md[0-9] [--add 裝置] [--remove 裝置] [--fail 裝置]
選項與引數:
--add :會將後面的裝置加入到這個 md 中!
--remove :會將後面的裝置由這個 md 中移除
--fail :會將後面的裝置設定成為出錯的狀態
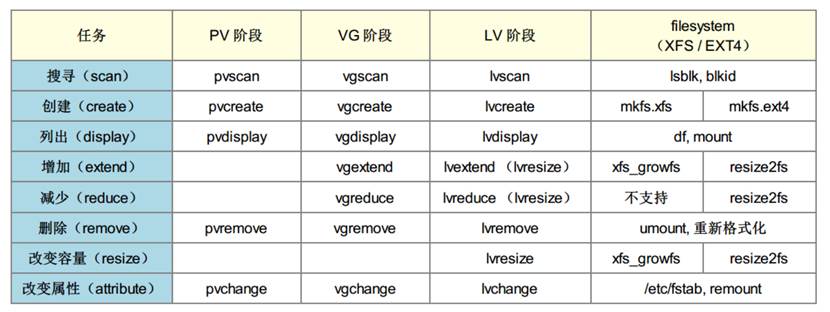
3.18、邏輯卷相關命令
3.19、dd
https://www.cnblogs.com/yuanqiangfei/p/9138625.html
dd:用指定大小的塊拷貝一個檔案,並在拷貝的同時進行指定的轉換。
注意:指定數位的地方若以下列字元結尾,則乘以相應的數位:b=512;c=1;k=1024;w=2
引數註釋:
1. if=檔名:輸入檔名,預設為標準輸入。即指定原始檔。< if=input file >
2. of=檔名:輸出檔名,預設為標準輸出。即指定目的檔案。< of=output file >
3. ibs=bytes:一次讀入bytes個位元組,即指定一個塊大小為bytes個位元組。
obs=bytes:一次輸出bytes個位元組,即指定一個塊大小為bytes個位元組。
bs=bytes:同時設定讀入/輸出的塊大小為bytes個位元組。
4. cbs=bytes:一次轉換bytes個位元組,即指定轉換緩衝區大小。
5. skip=blocks:從輸入檔案開頭跳過blocks個塊後再開始複製。
6. seek=blocks:從輸出檔案開頭跳過blocks個塊後再開始複製。
注意:通常只用當輸出檔案是磁碟或磁帶時才有效,即備份到磁碟或磁帶時才有效。
7. count=blocks:僅拷貝blocks個塊,塊大小等於ibs指定的位元組數。
8. conv=conversion:用指定的引數轉換檔案。
ascii:轉換ebcdic為ascii
ebcdic:轉換ascii為ebcdic
ibm:轉換ascii為alternate ebcdic
block:把每一行轉換為長度為cbs,不足部分用空格填充
unblock:使每一行的長度都為cbs,不足部分用空格填充
lcase:把大寫字元轉換為小寫字元
ucase:把小寫字元轉換為大寫字元
swab:交換輸入的每對位元組
noerror:出錯時不停止
notrunc:不截短輸出檔案
sync:將每個輸入塊填充到ibs個位元組,不足部分用空(NUL)字元補齊。
3.20、fio
https://www.cnblogs.com/raykuan/p/6914748.html
在fio官網下載fio-2.1.10.tar檔案,解壓後./configure、make、make install之後就可以使用fio了(注意:該命令不要在已有資料的檔案系統操作)
filename=/dev/emcpowerb 支援檔案系統或者裸裝置,-filename=/dev/sda2或-filename=/dev/sdb
direct=1 測試過程繞過機器自帶的buffer,使測試結果更真實
rw=randwread 測試隨機讀的I/O
rw=randwrite 測試隨機寫的I/O
rw=randrw 測試隨機混合寫和讀的I/O
rw=read 測試順序讀的I/O
rw=write 測試順序寫的I/O
rw=rw 測試順序混合寫和讀的I/O
bs=4k 單次io的塊檔案大小為4k
bsrange=512-2048 同上,提定資料塊的大小範圍
size=5g 本次的測試檔案大小為5g,以每次4k的io進行測試
numjobs=30 本次的測試執行緒為30
runtime=1000 測試時間為1000秒,如果不寫則一直將5g檔案分4k每次寫完為止
ioengine=psync io引擎使用pync方式,如果要使用libaio引擎,需要yum install libaio-devel包
rwmixwrite=30 在混合讀寫的模式下,寫佔30%
group_reporting 關於顯示結果的,彙總每個程序的資訊此外
lockmem=1g 只使用1g記憶體進行測試
zero_buffers 用0初始化系統buffer
nrfiles=8 每個程序生成檔案的數量
測試場景:
100%隨機,100%讀, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100read_4k
100%隨機,100%寫, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100write_4k
100%順序,100%讀 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100read_4k
100%順序,100%寫 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100write_4k
100%隨機,70%讀,30%寫 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4k
bw=平均IO頻寬
iops=IOPS
runt=執行緒執行時間
slat=提交延遲
clat=完成延遲
lat=響應時間
bw=頻寬
cpu=利用率
IO depths=io佇列
IO submit=單個IO提交要提交的IO數
IO complete=Like the above submit number, but for completions instead.
IO issued=The number of read/write requests issued, and how many of them were short.
IO latencies=IO完延遲的分佈
io=總共執行了多少size的IO
aggrb=group總頻寬
minb=最小.平均頻寬.
maxb=最大平均頻寬.
mint=group中執行緒的最短執行時間.
maxt=group中執行緒的最長執行時間.
ios=所有group總共執行的IO數.
merge=總共發生的IO合併數.
ticks=Number of ticks we kept the disk busy.
io_queue=花費在佇列上的總共時間.
util=磁碟利用率
3.21、iostat
https://blog.csdn.net/qq_20332637/article/details/82146753
yum install sysstat
cpu屬性值說明:
%user:CPU處在使用者模式下的時間百分比。
%nice:CPU處在帶NICE值的使用者模式下的時間百分比。
%system:CPU處在系統模式下的時間百分比。
%iowait:CPU等待輸入輸出完成時間的百分比。
%steal:管理程式維護另一個虛擬處理器時,虛擬CPU的無意識等待時間百分比。
%idle:CPU空閒時間百分比。
備註:
如果%iowait的值過高,表示硬碟存在I/O瓶頸
如果%idle值高,表示CPU較空閒
如果%idle值高但系統響應慢時,可能是CPU等待分配記憶體,應加大記憶體容量。
如果%idle值持續低於10,表明CPU處理能力相對較低,系統中最需要解決的資源是CPU。
cpu屬性值說明:
tps:該裝置每秒的傳輸次數
kB_read/s:每秒從裝置(drive expressed)讀取的資料量;
kB_wrtn/s:每秒向裝置(drive expressed)寫入的資料量;
kB_read: 讀取的總資料量;
kB_wrtn:寫入的總數量資料量

[root@rac01-node01 /]# iostat -xd 3
Linux 3.8.13-16.2.1.el6uek.x86_64 (rac01-node01) 05/27/2017 _x86_64_ (40 CPU)
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.05 0.75 2.50 0.50 76.59 69.83 48.96 0.00 1.17 0.47 0.14
scd0 0.00 0.00 0.02 0.00 0.11 0.00 5.25 0.00 21.37 20.94 0.05
dm-0 0.00 0.00 2.40 1.24 75.88 69.83 40.00 0.01 1.38 0.38 0.14
dm-1 0.00 0.00 0.02 0.00 0.14 0.00 8.00 0.00 0.65 0.39 0.00
sdc 0.00 0.00 0.01 0.00 0.11 0.00 10.20 0.00 0.28 0.28 0.00
sdb 0.00 0.00 0.01 0.00 0.11 0.00 10.20 0.00 0.15 0.15 0.00
sdd 0.00 0.00 0.01 0.00 0.11 0.00 10.20 0.00 0.25 0.25 0.00
sde 0.00 0.00 0.01 0.00 0.11 0.00 10.20 0.00 0.14 0.14 0.00
- rrqms:每秒這個裝置相關的讀取請求有多少被Merge了(當系統呼叫需要讀取資料的時候,VFS將請求發到各個FS,如果FS發現不同的讀取請求讀取的是相同Block的資料,FS會將這個請求合併Merge)
- wrqm/s:每秒這個裝置相關的寫入請求有多少被Merge了。
- rsec/s:The number of sectors read from the device per second.
- wsec/s:The number of sectors written to the device per second.
- rKB/s:The number of kilobytes read from the device per second.
- wKB/s:The number of kilobytes written to the device per second.
- avgrq-sz:平均請求磁區的大小,The average size (in sectors) of the requests that were issued to the device.
- avgqu-sz:是平均請求佇列的長度。毫無疑問,佇列長度越短越好,The average queue length of the requests that were issued to the device.
- await:每一個IO請求的處理的平均時間(單位是微秒毫秒)。這裡可以理解為IO的響應時間,一般地系統IO響應時間應該低於5ms,如果大於10ms就比較大了。這個時間包括了佇列時間和服務時間,也就是說,一般情況下,await大於svctm,它們的差值越小,則說明佇列時間越短,反之差值越大,佇列時間越長,說明系統出了問題。
- svctm:表示平均每次裝置I/O操作的服務時間(以毫秒為單位)。如果svctm的值與await很接近,表示幾乎沒有I/O等待,磁碟效能很好。如果await的值遠高於svctm的值,則表示I/O佇列等待太長,系統上執行的應用程式將變慢。
- %util: 在統計時間內所有處理IO時間,除以總共統計時間。例如,如果統計間隔1秒,該裝置有0.8秒在處理IO,而0.2秒閒置,那麼該裝置的%util = 0.8/1 = 80%,所以該引數暗示了裝置的繁忙程度,一般地,如果該引數是100%表示磁碟裝置已經接近滿負荷執行了(當然如果是多磁碟,即使%util是100%,因為磁碟的並行能力,所以磁碟使用未必就到了瓶頸)。
3.22、iotop
https://www.cnblogs.com/yinzhengjie/p/9934260.html
yum -y install iotop
各個引數說明:
-o, --only只顯示正在產生I/O的程序或執行緒。除了傳參,可以在執行過程中按o生效。
-b, --batch非互動模式,一般用來記錄紀錄檔。
-n NUM, --iter=NUM設定監測的次數,預設無限。在非互動模式下很有用。
-d SEC, --delay=SEC設定每次監測的間隔,預設1秒,接受非整形資料例如1.1。
-p PID, --pid=PID指定監測的程序/執行緒。
-u USER, --user=USER指定監測某個使用者產生的I/O。
-P, --processes僅顯示程序,預設iotop顯示所有執行緒。
-a, --accumulated顯示累積的I/O,而不是頻寬。
-k, --kilobytes使用kB單位,而不是對人友好的單位。在非互動模式下,指令碼程式設計有用。
-t, --time 加上時間戳,非互動非模式。
-q, --quiet 禁止頭幾行,非互動模式。有三種指定方式。
-q 只在第一次監測時顯示列名
-qq 永遠不顯示列名。
-qqq 永遠不顯示I/O彙總。
互動按鍵:
和top命令類似,iotop也支援以下幾個互動按鍵。
left和right方向鍵:改變排序。
r:反向排序。
o:切換至選項--only。
p:切換至--processes選項。
a:切換至--accumulated選項。
q:退出。
i:改變執行緒的優先順序。
出處:https://www.cnblogs.com/zsql/
如果您覺得閱讀本文對您有幫助,請點選一下右下方的推薦按鈕,您的推薦將是我寫作的最大動力!
版權宣告:本文為博主原創或轉載文章,歡迎轉載,但轉載文章之後必須在文章頁面明顯位置註明出處,否則保留追究法律責任的權利。