Java 集合常見知識點&面試題總結(上),2022 最新版!
你好,我是 Guide。秋招即將到來(提前批已經開始),我對 JavaGuide 的內容進行了重構完善,公眾號同步一下最新更新,希望能夠幫助你。
你也可以在網站(javaguide.cn)上線上閱讀,閱讀體驗會更好!
前 3 篇:
集合概述
Java 集合概覽
Java 集合, 也叫作容器,主要是由兩大介面派生而來:一個是 Collection介面,主要用於存放單一元素;另一個是 Map 介面,主要用於存放鍵值對。對於Collection 介面,下面又有三個主要的子介面:List、Set 和 Queue。
Java 集合框架如下圖所示:
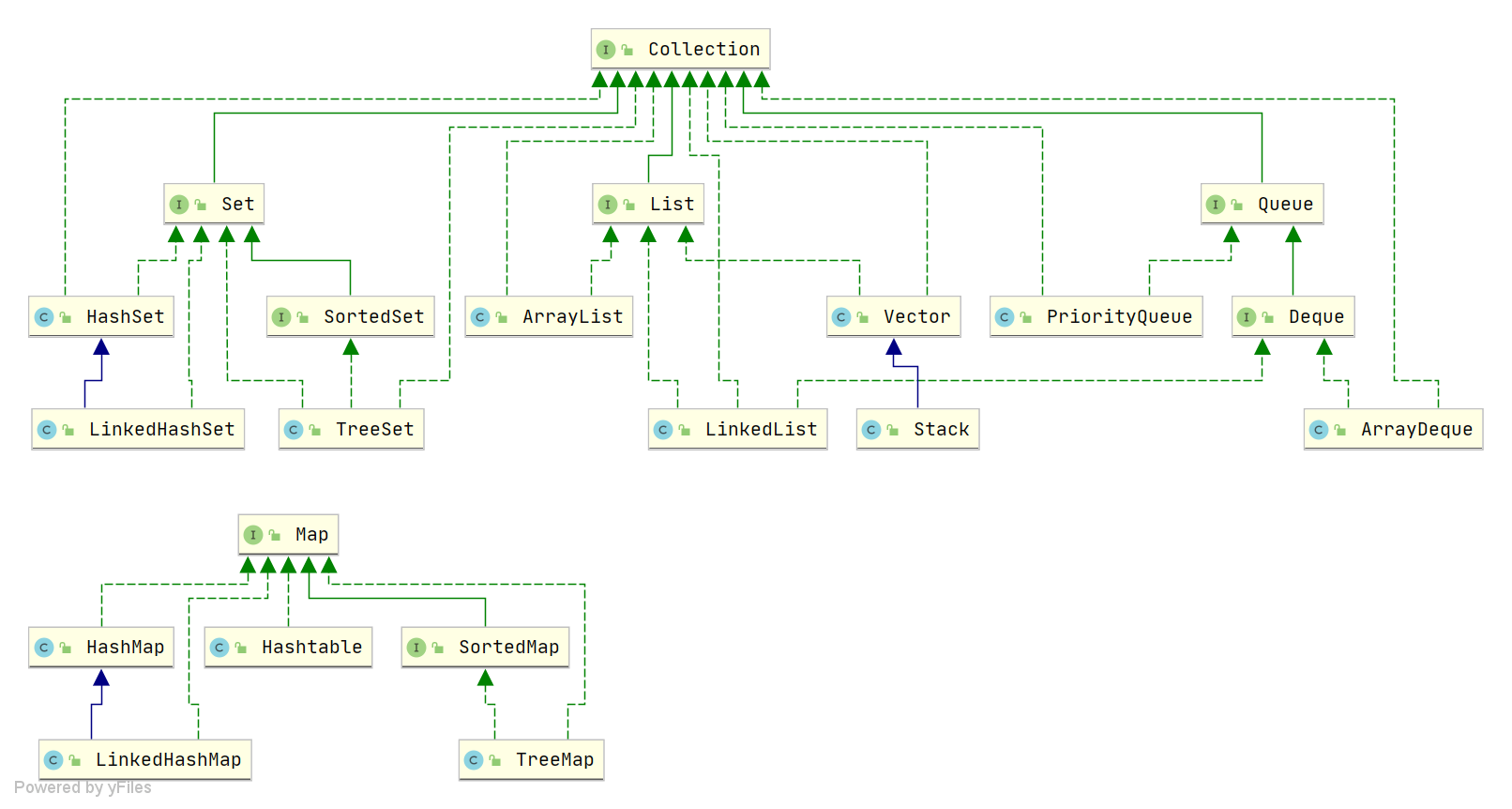
注:圖中只列舉了主要的繼承派生關係,並沒有列舉所有關係。比方省略了AbstractList, NavigableSet等抽象類以及其他的一些輔助類,如想深入瞭解,可自行檢視原始碼。
說說 List, Set, Queue, Map 四者的區別?
List(對付順序的好幫手): 儲存的元素是有序的、可重複的。Set(注重獨一無二的性質): 儲存的元素是無序的、不可重複的。Queue(實現排隊功能的叫號機): 按特定的排隊規則來確定先後順序,儲存的元素是有序的、可重複的。Map(用 key 來搜尋的專家): 使用鍵值對(key-value)儲存,類似於數學上的函數 y=f(x),"x" 代表 key,"y" 代表 value,key 是無序的、不可重複的,value 是無序的、可重複的,每個鍵最多對映到一個值。
集合框架底層資料結構總結
先來看一下 Collection 介面下面的集合。
List
Arraylist:Object[]陣列Vector:Object[]陣列LinkedList: 雙向連結串列(JDK1.6 之前為迴圈連結串列,JDK1.7 取消了迴圈)
Set
HashSet(無序,唯一): 基於HashMap實現的,底層採用HashMap來儲存元素LinkedHashSet:LinkedHashSet是HashSet的子類,並且其內部是通過LinkedHashMap來實現的。有點類似於我們之前說的LinkedHashMap其內部是基於HashMap實現一樣,不過還是有一點點區別的TreeSet(有序,唯一): 紅黑樹(自平衡的排序二元樹)
Queue
PriorityQueue:Object[]陣列來實現二元堆積ArrayQueue:Object[]陣列 + 雙指標
再來看看 Map 介面下面的集合。
Map
HashMap: JDK1.8 之前HashMap由陣列+連結串列組成的,陣列是HashMap的主體,連結串列則是主要為了解決雜湊衝突而存在的(「拉鍊法」解決衝突)。JDK1.8 以後在解決雜湊衝突時有了較大的變化,當連結串列長度大於閾值(預設為 8)(將連結串列轉換成紅黑樹前會判斷,如果當前陣列的長度小於 64,那麼會選擇先進行陣列擴容,而不是轉換為紅黑樹)時,將連結串列轉化為紅黑樹,以減少搜尋時間LinkedHashMap:LinkedHashMap繼承自HashMap,所以它的底層仍然是基於拉鍊式雜湊結構即由陣列和連結串列或紅黑樹組成。另外,LinkedHashMap在上面結構的基礎上,增加了一條雙向連結串列,使得上面的結構可以保持鍵值對的插入順序。同時通過對連結串列進行相應的操作,實現了存取順序相關邏輯。詳細可以檢視:《LinkedHashMap 原始碼詳細分析(JDK1.8)》Hashtable: 陣列+連結串列組成的,陣列是Hashtable的主體,連結串列則是主要為了解決雜湊衝突而存在的TreeMap: 紅黑樹(自平衡的排序二元樹)
如何選用集合?
主要根據集合的特點來選用,比如我們需要根據鍵值獲取到元素值時就選用 Map 介面下的集合,需要排序時選擇 TreeMap,不需要排序時就選擇 HashMap,需要保證執行緒安全就選用 ConcurrentHashMap。
當我們只需要存放元素值時,就選擇實現Collection 介面的集合,需要保證元素唯一時選擇實現 Set 介面的集合比如 TreeSet 或 HashSet,不需要就選擇實現 List 介面的比如 ArrayList 或 LinkedList,然後再根據實現這些介面的集合的特點來選用。
為什麼要使用集合?
當我們需要儲存一組型別相同的資料的時候,我們應該是用一個容器來儲存,這個容器就是陣列,但是,使用陣列儲存物件具有一定的弊端,
因為我們在實際開發中,儲存的資料的型別是多種多樣的,於是,就出現了「集合」,集合同樣也是用來儲存多個資料的。
陣列的缺點是一旦宣告之後,長度就不可變了;同時,宣告陣列時的資料型別也決定了該陣列儲存的資料的型別;而且,陣列儲存的資料是有序的、可重複的,特點單一。
但是集合提高了資料儲存的靈活性,Java 集合不僅可以用來儲存不同型別不同數量的物件,還可以儲存具有對映關係的資料。
Collection 子介面之 List
Arraylist 和 Vector 的區別?
ArrayList是List的主要實現類,底層使用Object[ ]儲存,適用於頻繁的查詢工作,執行緒不安全 ;Vector是List的古老實現類,底層使用Object[ ]儲存,執行緒安全的。
Arraylist 與 LinkedList 區別?
- 是否保證執行緒安全:
ArrayList和LinkedList都是不同步的,也就是不保證執行緒安全; - 底層資料結構:
Arraylist底層使用的是Object陣列;LinkedList底層使用的是 雙向連結串列 資料結構(JDK1.6 之前為迴圈連結串列,JDK1.7 取消了迴圈。注意雙向連結串列和雙向迴圈連結串列的區別,下面有介紹到!) - 插入和刪除是否受元素位置的影響:
ArrayList採用陣列儲存,所以插入和刪除元素的時間複雜度受元素位置的影響。 比如:執行add(E e)方法的時候,ArrayList會預設在將指定的元素追加到此列表的末尾,這種情況時間複雜度就是 O(1)。但是如果要在指定位置 i 插入和刪除元素的話(add(int index, E element))時間複雜度就為 O(n-i)。因為在進行上述操作的時候集合中第 i 和第 i 個元素之後的(n-i)個元素都要執行向後位/向前移一位的操作。LinkedList採用連結串列儲存,所以,如果是在頭尾插入或者刪除元素不受元素位置的影響(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),時間複雜度為 O(1),如果是要在指定位置i插入和刪除元素的話(add(int index, E element),remove(Object o)), 時間複雜度為 O(n) ,因為需要先移動到指定位置再插入。
- 是否支援快速隨機存取:
LinkedList不支援高效的隨機元素存取,而ArrayList支援。快速隨機存取就是通過元素的序號快速獲取元素物件(對應於get(int index)方法)。 - 記憶體空間佔用:
ArrayList的空 間浪費主要體現在在 list 列表的結尾會預留一定的容量空間,而 LinkedList 的空間花費則體現在它的每一個元素都需要消耗比 ArrayList 更多的空間(因為要存放直接後繼和直接前驅以及資料)。
我們在專案中一般是不會使用到 LinkedList 的,需要用到 LinkedList 的場景幾乎都可以使用 ArrayList 來代替,並且,效能通常會更好!就連 LinkedList 的作者約書亞 · 布洛克(Josh Bloch)自己都說從來不會使用 LinkedList 。
另外,不要下意識地認為 LinkedList 作為連結串列就最適合元素增刪的場景。我在上面也說了,LinkedList 僅僅在頭尾插入或者刪除元素的時候時間複雜度近似 O(1),其他情況增刪元素的時間複雜度都是 O(n) 。
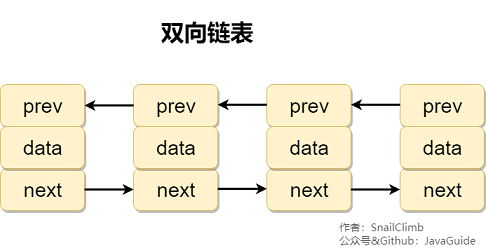
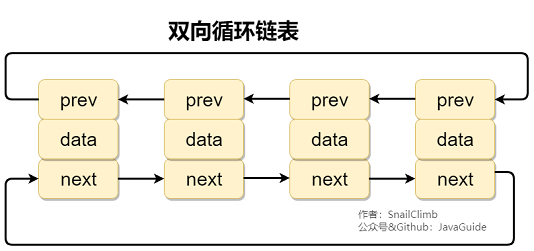
補充內容:雙向連結串列和雙向迴圈連結串列
雙向連結串列: 包含兩個指標,一個 prev 指向前一個節點,一個 next 指向後一個節點。
另外推薦一篇把雙向連結串列講清楚的文章:https://juejin.cn/post/6844903648154271757
雙向迴圈連結串列: 最後一個節點的 next 指向 head,而 head 的 prev 指向最後一個節點,構成一個環。
補充內容:RandomAccess 介面
public interface RandomAccess {
}
檢視原始碼我們發現實際上 RandomAccess 介面中什麼都沒有定義。所以,在我看來 RandomAccess 介面不過是一個標識罷了。標識什麼? 標識實現這個介面的類具有隨機存取功能。
在 binarySearch() 方法中,它要判斷傳入的 list 是否 RandomAccess 的範例,如果是,呼叫indexedBinarySearch()方法,如果不是,那麼呼叫iteratorBinarySearch()方法
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
ArrayList 實現了 RandomAccess 介面, 而 LinkedList 沒有實現。為什麼呢?我覺得還是和底層資料結構有關!ArrayList 底層是陣列,而 LinkedList 底層是連結串列。陣列天然支援隨機存取,時間複雜度為 O(1),所以稱為快速隨機存取。連結串列需要遍歷到特定位置才能存取特定位置的元素,時間複雜度為 O(n),所以不支援快速隨機存取。,ArrayList 實現了 RandomAccess 介面,就表明了他具有快速隨機存取功能。 RandomAccess 介面只是標識,並不是說 ArrayList 實現 RandomAccess 介面才具有快速隨機存取功能的!
說一說 ArrayList 的擴容機制吧
詳見筆主的這篇文章:ArrayList 擴容機制分析
Collection 子介面之 Set
comparable 和 Comparator 的區別
comparable介面實際上是出自java.lang包 它有一個compareTo(Object obj)方法用來排序comparator介面實際上是出自 java.util 包它有一個compare(Object obj1, Object obj2)方法用來排序
一般我們需要對一個集合使用自定義排序時,我們就要重寫compareTo()方法或compare()方法,當我們需要對某一個集合實現兩種排序方式,比如一個 song 物件中的歌名和歌手名分別採用一種排序方法的話,我們可以重寫compareTo()方法和使用自制的Comparator方法或者以兩個 Comparator 來實現歌名排序和歌星名排序,第二種代表我們只能使用兩個引數版的 Collections.sort().
Comparator 客製化排序
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(-1);
arrayList.add(3);
arrayList.add(3);
arrayList.add(-5);
arrayList.add(7);
arrayList.add(4);
arrayList.add(-9);
arrayList.add(-7);
System.out.println("原始陣列:");
System.out.println(arrayList);
// void reverse(List list):反轉
Collections.reverse(arrayList);
System.out.println("Collections.reverse(arrayList):");
System.out.println(arrayList);
// void sort(List list),按自然排序的升序排序
Collections.sort(arrayList);
System.out.println("Collections.sort(arrayList):");
System.out.println(arrayList);
// 客製化排序的用法
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
System.out.println("客製化排序後:");
System.out.println(arrayList);
Output:
原始陣列:
[-1, 3, 3, -5, 7, 4, -9, -7]
Collections.reverse(arrayList):
[-7, -9, 4, 7, -5, 3, 3, -1]
Collections.sort(arrayList):
[-9, -7, -5, -1, 3, 3, 4, 7]
客製化排序後:
[7, 4, 3, 3, -1, -5, -7, -9]
重寫 compareTo 方法實現按年齡來排序
// person物件沒有實現Comparable介面,所以必須實現,這樣才不會出錯,才可以使treemap中的資料按順序排列
// 前面一個例子的String類已經預設實現了Comparable介面,詳細可以檢視String類的API檔案,另外其他
// 像Integer類等都已經實現了Comparable介面,所以不需要另外實現了
public class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
* T重寫compareTo方法實現按年齡來排序
*/
@Override
public int compareTo(Person o) {
if (this.age > o.getAge()) {
return 1;
}
if (this.age < o.getAge()) {
return -1;
}
return 0;
}
}
public static void main(String[] args) {
TreeMap<Person, String> pdata = new TreeMap<Person, String>();
pdata.put(new Person("張三", 30), "zhangsan");
pdata.put(new Person("李四", 20), "lisi");
pdata.put(new Person("王五", 10), "wangwu");
pdata.put(new Person("小紅", 5), "xiaohong");
// 得到key的值的同時得到key所對應的值
Set<Person> keys = pdata.keySet();
for (Person key : keys) {
System.out.println(key.getAge() + "-" + key.getName());
}
}
Output:
5-小紅
10-王五
20-李四
30-張三
無序性和不可重複性的含義是什麼
1、什麼是無序性?無序性不等於隨機性 ,無序性是指儲存的資料在底層陣列中並非按照陣列索引的順序新增 ,而是根據資料的雜湊值決定的。
2、什麼是不可重複性?不可重複性是指新增的元素按照 equals()判斷時 ,返回 false,需要同時重寫 equals()方法和 HashCode()方法。
比較 HashSet、LinkedHashSet 和 TreeSet 三者的異同
HashSet、LinkedHashSet和TreeSet都是Set介面的實現類,都能保證元素唯一,並且都不是執行緒安全的。HashSet、LinkedHashSet和TreeSet的主要區別在於底層資料結構不同。HashSet的底層資料結構是雜湊表(基於HashMap實現)。LinkedHashSet的底層資料結構是連結串列和雜湊表,元素的插入和取出順序滿足 FIFO。TreeSet底層資料結構是紅黑樹,元素是有序的,排序的方式有自然排序和客製化排序。- 底層資料結構不同又導致這三者的應用場景不同。
HashSet用於不需要保證元素插入和取出順序的場景,LinkedHashSet用於保證元素的插入和取出順序滿足 FIFO 的場景,TreeSet用於支援對元素自定義排序規則的場景。
Collection 子介面之 Queue
Queue 與 Deque 的區別
Queue 是單端佇列,只能從一端插入元素,另一端刪除元素,實現上一般遵循 先進先出(FIFO) 規則。
Queue 擴充套件了 Collection 的介面,根據 因為容量問題而導致操作失敗後處理方式的不同 可以分為兩類方法: 一種在操作失敗後會丟擲異常,另一種則會返回特殊值。
Queue 介面 |
丟擲異常 | 返回特殊值 |
|---|---|---|
| 插入隊尾 | add(E e) | offer(E e) |
| 刪除隊首 | remove() | poll() |
| 查詢隊首元素 | element() | peek() |
Deque 是雙端佇列,在佇列的兩端均可以插入或刪除元素。
Deque 擴充套件了 Queue 的介面, 增加了在隊首和隊尾進行插入和刪除的方法,同樣根據失敗後處理方式的不同分為兩類:
Deque 介面 |
丟擲異常 | 返回特殊值 |
|---|---|---|
| 插入隊首 | addFirst(E e) | offerFirst(E e) |
| 插入隊尾 | addLast(E e) | offerLast(E e) |
| 刪除隊首 | removeFirst() | pollFirst() |
| 刪除隊尾 | removeLast() | pollLast() |
| 查詢隊首元素 | getFirst() | peekFirst() |
| 查詢隊尾元素 | getLast() | peekLast() |
事實上,Deque 還提供有 push() 和 pop() 等其他方法,可用於模擬棧。
ArrayDeque 與 LinkedList 的區別
ArrayDeque 和 LinkedList 都實現了 Deque 介面,兩者都具有佇列的功能,但兩者有什麼區別呢?
-
ArrayDeque是基於可變長的陣列和雙指標來實現,而LinkedList則通過連結串列來實現。 -
ArrayDeque不支援儲存NULL資料,但LinkedList支援。 -
ArrayDeque是在 JDK1.6 才被引入的,而LinkedList早在 JDK1.2 時就已經存在。 -
ArrayDeque插入時可能存在擴容過程, 不過均攤後的插入操作依然為 O(1)。雖然LinkedList不需要擴容,但是每次插入資料時均需要申請新的堆空間,均攤效能相比更慢。
從效能的角度上,選用 ArrayDeque 來實現佇列要比 LinkedList 更好。此外,ArrayDeque 也可以用於實現棧。
說一說 PriorityQueue
PriorityQueue 是在 JDK1.5 中被引入的, 其與 Queue 的區別在於元素出隊順序是與優先順序相關的,即總是優先順序最高的元素先出隊。
這裡列舉其相關的一些要點:
PriorityQueue利用了二元堆積的資料結構來實現的,底層使用可變長的陣列來儲存資料PriorityQueue通過堆元素的上浮和下沉,實現了在 O(logn) 的時間複雜度內插入元素和刪除堆頂元素。PriorityQueue是非執行緒安全的,且不支援儲存NULL和non-comparable的物件。PriorityQueue預設是小頂堆,但可以接收一個Comparator作為構造引數,從而來自定義元素優先順序的先後。
PriorityQueue 在面試中可能更多的會出現在手撕演演算法的時候,典型例題包括堆排序、求第K大的數、帶權圖的遍歷等,所以需要會熟練使用才行。
後記
專注 Java 原創乾貨分享,大三開源 JavaGuide (「Java學習+面試指南」一份涵蓋大部分 Java 程式設計師所需要掌握的核心知識。準備 Java 面試,首選 JavaGuide!),目前已經 120k+ Star。
原創不易,歡迎點贊分享,歡迎關注我在部落格園的賬號,我會持續分享原創乾貨!加油,衝!
如果本文對你有幫助的話,歡迎點贊分享,這對我繼續分享&創作優質文章非常重要。感謝