位元組跳動資料平臺技術揭祕:基於 ClickHouse 的複雜查詢實現與優化
更多技術交流、求職機會、試用福利,歡迎關注位元組跳動資料平臺微信公眾號,回覆【1】進入官方交流群
ClickHouse 作為目前業內主流的列式儲存資料庫(DBMS)之一,擁有著同型別 DBMS 難以企及的查詢速度。作為該領域中的後起之秀,ClickHouse 已憑藉其效能優勢引領了業內新一輪分析型資料庫的熱潮。但隨著企業業務資料量的不斷擴大,在複雜 query 場景下,ClickHouse 容易存在查詢異常問題,影響業務正常推進。
位元組跳動作為國內最大規模的 ClickHouse 使用者,在對 ClickHouse 的應用與優化過程中積累了大量技術經驗。本文將分享位元組跳動解決 ClickHouse 複雜查詢問題的優化思路與技術細節。
專案背景
ClickHouse 的執行模式與 Druid、ES 等巨量資料引擎類似,其基本的查詢模式可分為兩個階段。第一階段,Coordinator 在收到查詢後,將請求傳送給對應的 Worker 節點。第二階段,Worker 節點完成計算,Coordinator 在收到各 Worker 節點的資料後進行匯聚和處理,並將處理後的結果返回。
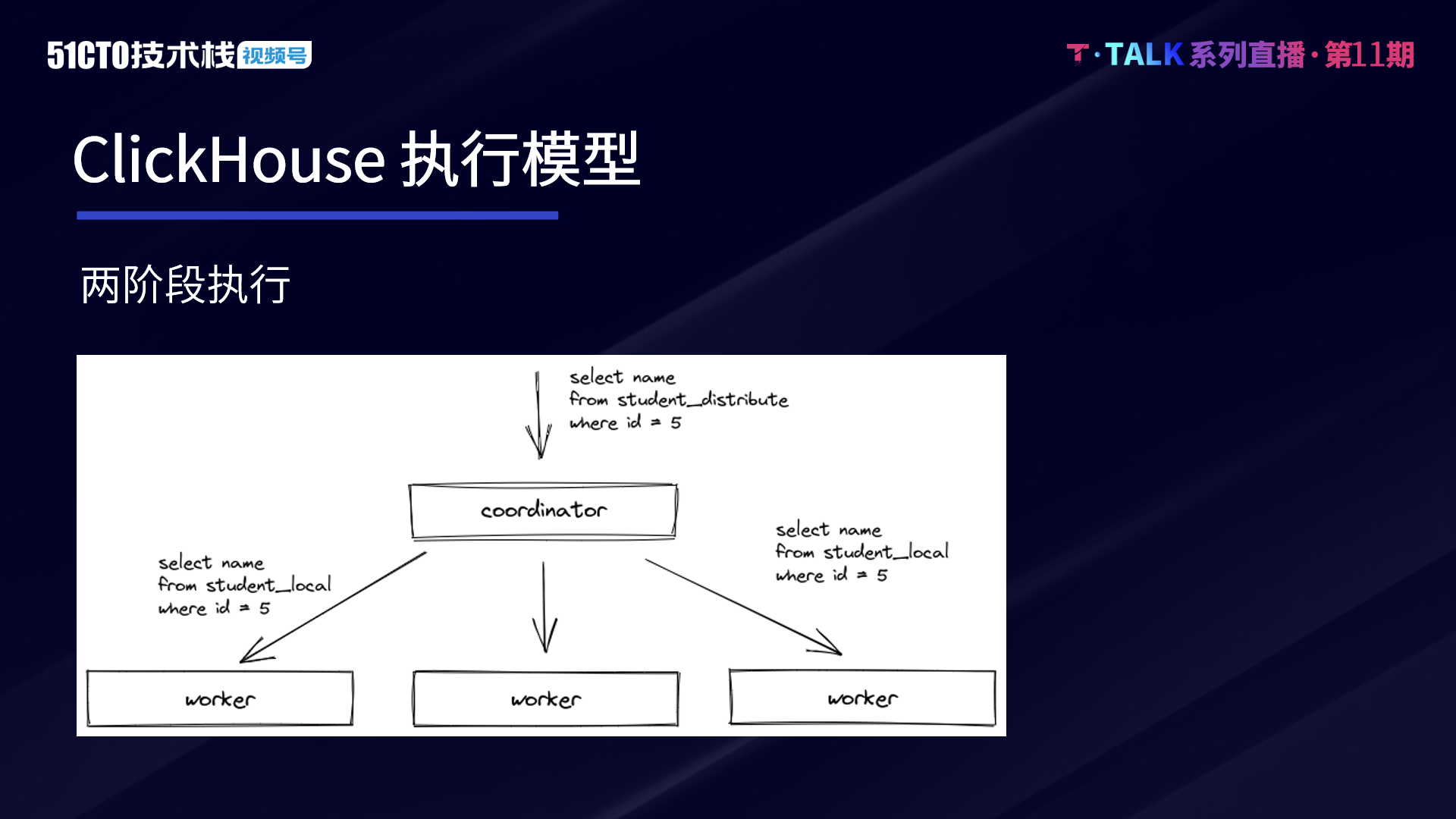
兩階段的執行模式能夠較為高效地支援目前許多常見的業務場景,例如各類大寬表單的查詢,這也是 ClickHouse 最擅長的場景。ClickHouse 的優點是簡單、高效,通常來說,簡單就意味著高效。但隨著企業業務的持續發展,愈加複雜的業務場景對 ClickHouse 提出了以下三類挑戰。
第一類,當一階段返回的資料較多,且二階段計算較為複雜時,Coordinator 會承受較大壓力,容易成為 Query 的瓶頸。例如一些重計算的 Agg 運算元,如 Count Distinct,若採用雜湊表的方式進行去重,第二階段需在 Coordinator 單機上去合併各個 Worker 的雜湊表。這個計算量會很重且無法並行。
第二類,由於目前 ClickHouse 模式並不支援 Shuffle,因此對於 Join 而言,右表必須為全量資料。無論是普通 Join 還是 Global Join,當右表的資料量較大時,若將資料都放到記憶體中,會比較容易 OOM。若將資料 spill 到磁碟,雖然可以解決記憶體問題,但由於有磁碟 IO 和資料序列化、反序列化的代價,因此查詢的效能會受到影響。特別是當 Join 採用 Hash Join 時,如果右表是一張大表,構建也會比較慢。針對構建問題,近期社群也進行了一些右表並行構建的優化,資料按照 Join key 進行 Split 來並行地構建多個 Hash Table,但額外的代價是左右表都需要增加一次 Split 操作。
第三類,則是關於複雜查詢(如多表 Join、巢狀多個子查詢、window function 等),ClickHouse 對這類需求場景的支援並不是特別友好,由於 ClickHouse 並不能通過 Shuffle 來分散資料增加執行並行度,並且其生成的 Pipeline 在一些 case 下並不能充分並行。因此在某些場景下,難以發揮叢集的全部資源。
隨著企業業務複雜度的不斷提升,複雜查詢,特別是有多輪的分散式 Join,且有很多 agg 的計算的需求會越來越強烈。在這種情況下,業務並不希望所有的 Query 都按照 ClickHouse 擅長的模式進行,即通過上游資料 ETL 來產生大寬表。這樣做對 ETL 的成本較大,並且可能會有一些資料冗餘。

企業的叢集資源是有限的,但整體的資料量會持續增長,因此在這種情況下,我們希望能夠充分地去利用機器的資源,來應對這種越來越複雜的業務場景和 SQL。所以我們的目標是基於 ClickHouse 能夠高效支援複雜查詢。
技術方案
對於 ClickHouse 複雜查詢的實現,我們採用了分 Stage 的執行方式,來替換掉目前 ClickHouse 的兩階段執行方式。類似於其他的分散式資料庫引擎,例如 Presto 等,會將一個複雜的 Query 按資料交換情況切分成多個 Stage,各 Stage 之間則通過 Exchange 完成資料交換。Stage 之間的資料交換主要有以下三種形式。
-
按照單個或者多個 key 進行 Shuffle
-
將單個或者多個節點的資料匯聚到一個節點上,稱為 Gather
-
將同一份資料複製到多個節點上,稱為 Broadcast 或廣播
對於單個 Stage 執行,繼續複用 ClickHouse 目前底層的執行方式。開發上按照不同功能切分不同模組。各個模組預定介面,減少彼此的依賴與耦合。即使模組發生變動或內部邏輯調整,也不會影響其他模組。其次,對模組採用外掛架構,允許模組按照靈活設定支援不同的策略。這樣便能夠根據不同業務場景實現不同的策略。

首先,當 Coordinator 接受複雜的查詢以後,它會在當前的語法樹的基礎上,根據節點型別和資料分佈情況,插入 Exchange 節點,並生成一個分散式 Plan。其次,Coordinator 節點會根據 ExchangeNode 型別切分 Plan,並生成每個 Stage 執行計劃片段。
接著,Coordinator 節點會呼叫 SegmentScheduler 排程器,將各 Stage 的 PlanSegment 傳送給 Worker 節點。當 Worker 接收到 PlanSegment 後,InterpreterPlanSegment 會完成資料的讀取和執行,通過 ExchangeManager 完成資料的互動。最後,Coordinator 從最後一輪 Stage 所對應的 ExchangeManager 中去讀取資料,並返回給 Client。
查詢片段排程器 SegmentScheduler 負責排程查詢不同的 PlanSegment,根據上下游依賴關係和資料分佈,以及 Stage 並行度和 worker 分佈和狀態資訊,按照一定的排程策略,將 PlanSemgent 發給不同的 Worker 節點。
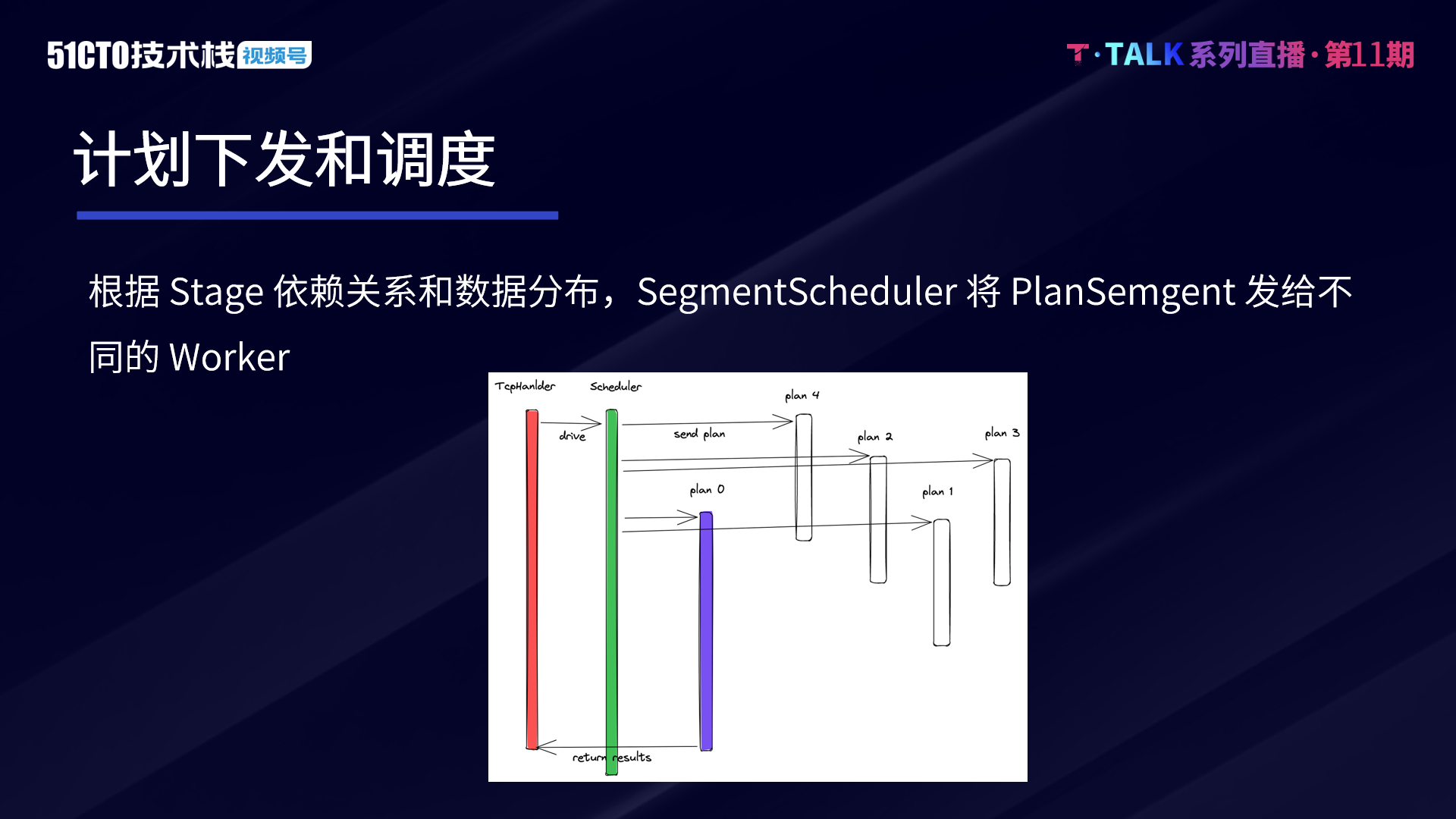
目前而言,我們在進行計劃下發和排程時,主要實現了兩種策略。
第一種是依賴排程,根據 Stage 依賴關係定義拓撲結構,產生 DAG 圖,並根據 DAG 圖排程 Stage。依賴排程要等到依賴 Stage 啟動以後,才會排程對應的 Stage。例如兩表 Join,會先排程左右表讀取 Stage,之後再排程 Join 這個 Stage,因為 Join 的 Stage 依賴於左右表的 Stage。
第二種是 AllAtOnce 策略,先計算每個 Stage 的相關資訊,後一次性排程所有 Stage。
相比而言,這兩種策略是在容錯、資源使用和延時上去做取捨。第一種策略依賴排程,可以實現更好的容錯。由於 ClickHouse 資料可以有多個副本,讀資料時,如部分節點連線失敗,可以嘗試它的副本節點。對後續依賴的節點的 Stage 來說,並不需要感知到前面 Stage 的執行情況。非 Source Stage,本身沒有對資料的依賴,所以容錯能力會更強,只要保證 Stage 並行度的節點存活即可。甚至極端情況下,如需保證 Query 正常執行,也可以降低 Stage 的並行度。但排程存在依賴關係,並不能完全並行,會增加排程的時長。Stage 較多的情況下,排程延時可能會佔據 SQL 整體不小的比例。針對上述問題的可做如下優化:對於一些沒有依賴關係的,儘可能支援並行。例如同一個 Stage 的不同節點,可以並行。沒有依賴關係的 Stage,也可以並行。
第二種排程策略是 AllAtOnce,通過並行可以極大降低排程延時。為防止出現大量網路 IO 執行緒,可以通過非同步化手段控制執行緒數目。AllAtOnce 策略的缺點是容錯性沒有依賴排程好,每一個 Stage 的 Worker 在排程前就已經確定了,排程過程中有一個 Worker 出現連線異常,則整個 Query 都會失敗。另一類情況,Stage 在上游資料還沒有 ready,就被排程起來了,則需要較長時間等資料。例如 Final 的 agg Stage,要等 Partial agg 完成以後才能夠拿到對應的資料。雖然我們也對此進行了一些優化,並不會長時間空跑,浪費 CPU 資源。但是其實也消耗了一部分資源,例如需要去建立這些執行的執行緒。
ClickHouse 的查詢節點執行主要是以 SQL 形式在節點間互相互動。在切分 Stage 後,我們需要支援能夠執行一個單獨的 PlanSegment 的執行計劃。因此,InterpreterPlanSegment 主要的作用就是接受一個序列化後的 PlanSegment,能夠在 Worker 節點上去執行整個 PlanSegment 的邏輯。此外,我們也進行了功能和效能上的增強,例如支援一個 Stage 處理多個 Join,這樣便可以減少 Stage 的數目和一些不必要的傳輸,用一個 Stage 就可以完成整個 Join 的過程。InterpreterPlanSegment 的執行會上報對應的狀態資訊,如出現執行異常,會將異常資訊報告給查詢片段排程器,排程器會取消 Query 其他的 Stage 的 Worker 執行。
ExchangeManager 是 PlanSegment 資料交換的媒介,能平衡資料上下游處理的能力。整體而言,我們的設計採用 Push 與佇列的方式,當上遊的資料 ready 時,主動推播給下游,並在這個基礎上支援了反壓的能力。
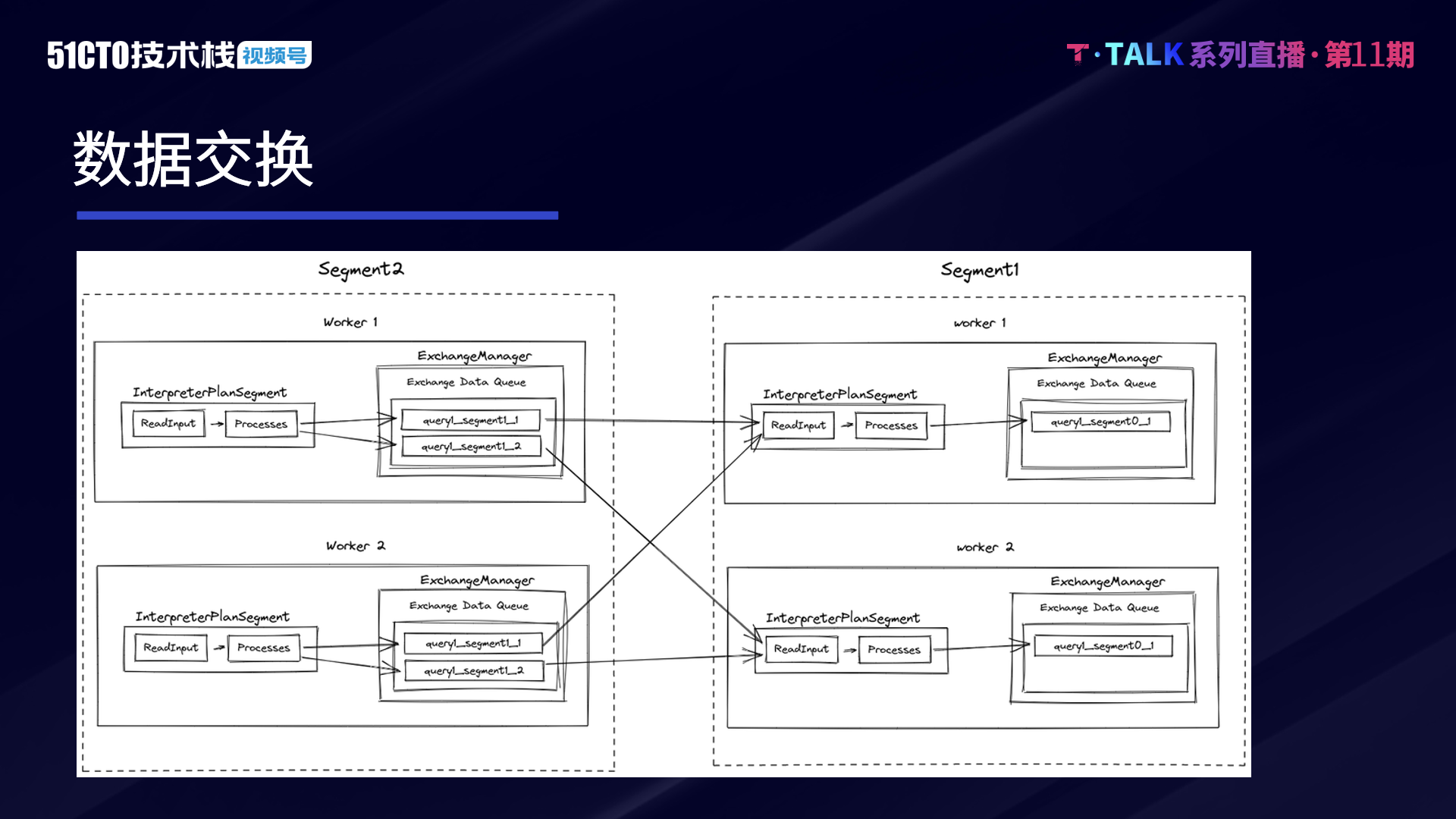
在整個流程中,上下游都會通過佇列來優化傳送和讀取,上游與下游會有一個自己的佇列。當佇列飽和的時候,會通過類似反壓的機制來控制上游這個執行速度,若上游計算快,下游處理能力比較慢,出現下游處理不過來的情況,則會通過反壓的方式來控制上游執行的速度。
由於採用 push 和佇列,因此要考慮一個相對比較特殊的場景,在某些 case 的情況下,下游的 Stage 並不需要讀取全部的上游的資料。例如 Limit100,下游只需讀取 100 條資料,而上游可能會產生非常大規模的資料。因此在這種情況下,當下遊的 Stage 讀取到足夠的資料後,它需要能夠主動取消上游 Stage 的執行,並且清空佇列。
ExchangeManager 考慮的優化點較多,例如細粒度的記憶體控制,能夠按照範例、Query、Segment 等多個層次進行記憶體控制,避免 OOM。更長期的考慮是在一些對延遲要求不高、資料量大的場景,通過將資料 Spill 到磁碟,降低記憶體的使用

第二,為了提升傳輸效率,小資料要做 Merge,巨量資料要做 Split。同時,在網路傳輸和處理某些場景的時候,需要做一種有序性的保證。例如在 Sort 的場景,Partial Sort 和 Merge Sort 的網路傳輸過程必須要保證是有序的,傳輸資料不能出現亂序的情況,否則進行 Merge Sort 時資料就會出問題,並影響最終結果。
第三,連線的複用和網路的優化,包括上下游在同一個節點,儘可能走記憶體交換,而不走網路。這樣可以減少網路開銷以及資料的序列化和反序列化的代價。此外,ClickHouse 在計算上做了非常充足的優化,因此其在某些場景中,記憶體頻寬會成為瓶頸,在 ExchangeManager 的一些場景中,可以用一些零拷貝和其他優化,儘量減少記憶體的拷貝。
第四,例外處理和監控。相比於單機,分散式情況下異常情況會更加複雜,且更加難以感知。通過重試能夠避免一些節點短時性的高負載或者異常對查詢的影響。做好監控,在出問題的時候,能快速感知,並進行排查,也能夠針對性地去做優化。
優化與診斷
首先是 Join 的多種實現和優化。根據資料的規模和分佈,可以根據不同的場景去選擇合適的 Join 的實現方式:
-
Shuffle Join,是目前使用方式最多,也是最常見的。
-
Broadcast Join,大表 Join 小表場景,將右表廣播到左表的所有 Worker 節點上面,這樣可以避免左表大表的資料傳輸。
-
Colocate Join,如果左右表都已按照 Join key 分佈,並且它們是相通的分佈的話,其實不需要去做資料的 exchange,可以將資料的傳輸減到最小。
網路連線的優化,核心本質是減少連線的建立和使用,特別是在資料需要 Shuffle 時,下一輪 Stage 中的每一個節點都要從上游的 Stage 中的每個節點去拉取資料。若叢集整體的節點數較多,且存在很多較複雜的 Query,就會建立非常多的連線。
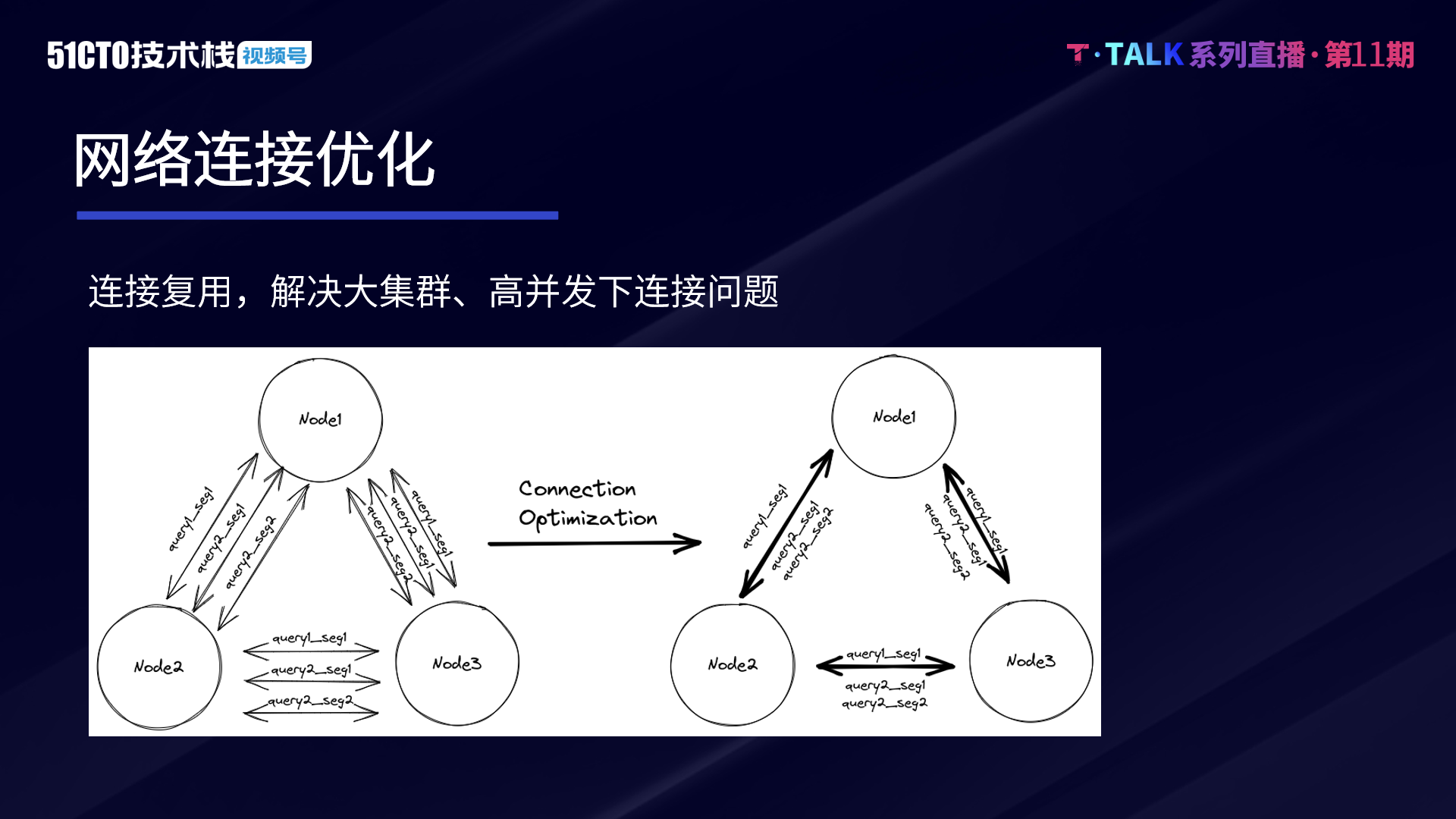
目前在位元組內部,ClickHouse 叢集的規模非常大,在當前 ClickHouse 二階段執行的高並行情況下,單機最大可能會建立幾萬個連線。因此必須要進行網路連線的優化,特別是支援連線的複用,每個連線上可以跑多個 Stage 查詢。通過儘可能去複用連線,在不同的節點之間,能夠建立固定數目的連線,不同的 Query、Stage 都會複用這些連線,連線數並不會隨著 Query 和 Stage 的規模的增長而增長。
網路傳輸優化,在資料中心內,遠端的直接的記憶體存取,通常指 RDMA,是一種能夠超過遠端主機作業系統的核心,去存取記憶體裡的資料的技術。由於這種技術不需要經過作業系統,所以不僅節省了大量的 CPU 資源,同樣也提升了系統吞吐量,降低了系統的網路通訊延遲,尤其適合大規模並行的計算機叢集。由於 ClickHouse 在計算層面做了很多優化,而網路頻寬相比於記憶體頻寬要小不少,在一些資料量傳輸特別大的場景,網路傳輸會成為一定的瓶頸。為了提升網路傳輸的效率和提升資料 exchange 的吞吐,一方面可以引入壓縮來降低傳輸資料量,另一方面可以引入 RDMA 來減少一定的開銷。經過測試,在一些資料傳輸量大的場景,有不小的收益。
利用 Runtime Filter 的優化在不少資料庫也有使用。Join 的運算元通常是 OLAP 引擎裡最耗時的運算元,優化 Join 運算元有兩種思路。一種思路是可以提升 Join 運算元的效能。比如對於 HashJoin,可以優化 HashTable 實現,也可以實現更好的雜湊演演算法,包括做一些更好的並行的方式。
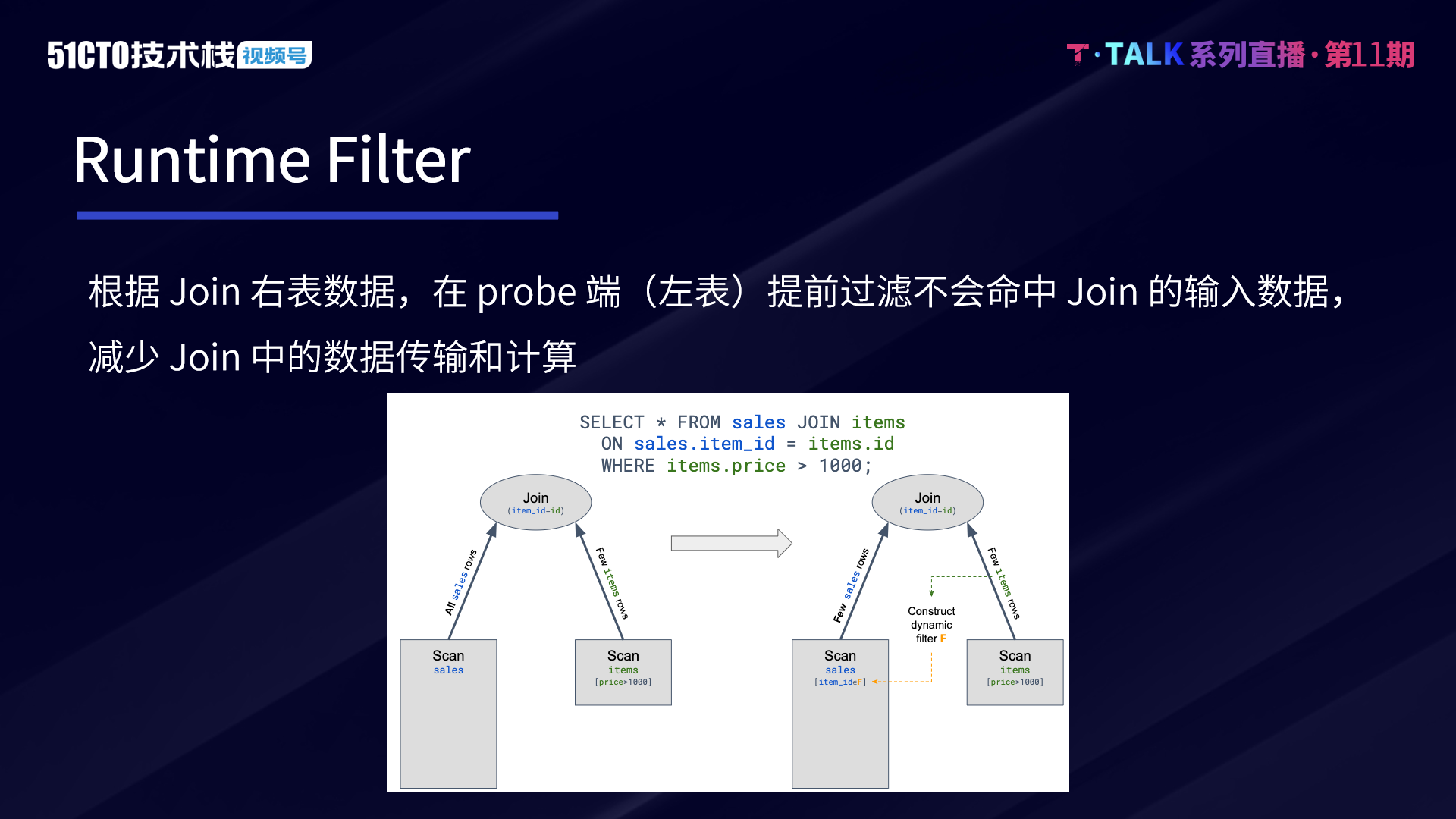
另一種思路是,如果本身運算元耗時比較重,可以減少參與運算元計算的資料。Runtime Filter 是在一些場景下特別是事實表 Join 多張維度表的星型模型場景有比較好的效果。在此類場景下,通常事實表的規模會非常大,而大部分的過濾條件都是在維度表上面。
Runtime Filter 的作用,是通過在 Join 的 Probe 端,提前過濾掉並不會命中 Join 條件的輸入資料,從而大幅減少 Join 中的資料傳輸和計算。通過這種方式,能夠減少整體的執行時間。因此我們在複雜查詢上也支援了 Runtime Filter,目前主要支援 Min Max 和 Bloom Filter。
如果 runtime filter 的列(join column)構建了索引(主鍵、skip index…),是需要重新生成 pipeline 的。因為命中索引後,可能會減少資料的讀取,pipeline 並行度和對應資料的處理 range 都可能發生變化。如果 runtime filter 的列跟索引無關,可以在計劃生成的時候預先帶上過濾條件,一開始為空,只是佔位,runtime filter 下發的時候把佔位資訊改成真正的過濾條件即可。這樣即使 runtime filter 下發超時了,查詢片段已經開始執行,只要查詢片段沒有執行完,之後的資料仍然可以進行過濾。
但需要注意的是,Runtime Filter 是一種特殊場景下的優化,針對場景是右表資料量不大,並且構建的 Runtime Filter 對左表有比較好的過濾效果。若右表資料量較大,構建的 Runtime Filter 的時間比較久,或對左表的資料過濾沒有效果。Runtime Filter 反而會增加查詢的耗時和計算的開銷。因此要根據資料的特徵和規模來決定是否開啟優化。
效能診斷和分析對複雜查詢很關鍵,由於引入了複雜查詢的多 Stage 模型,SQL 執行的模式會變得複雜。對此的優化首先是儘可能完善各類 Metrics,包括 Query 執行時間、不同 Stage 執行時間、起始時間、結束時間、處理的 IO 資料量、運算元處理的資料、執行情況,以及各類的運算元 Metrics 和一些 Profile Events(例如 Runtime Filter 會有構建時間、過濾資料量等 Metrics)。
其次,我們記錄了反壓資訊與上下游的佇列長度,以此推斷 Stage 的執行情況和瓶頸。
通常可以有如下判斷:
-
輸入和輸出佇列數目同為低或同為高分別表明當前 stage 處理正常或處於被下游反壓,此時可以通過反壓資訊來進一步判斷
-
當輸入和輸出佇列數目不一樣,這可能是出於反壓傳導的中間狀態或者該 stage 就是反壓的根源
-
如果一個 stage 的輸出佇列數目很多,且經常被反壓,通常是被下游 stage 所影響,所以可以排除它本身是反壓根源的可能性,更多關注它的下游
-
如果一個 stage 的輸出佇列數目很少,但其輸入佇列的數目很高,則表明它有可能是反壓的根源。優化目標是提升這個 stage 的處理能力。
總的來說,SQL 的場景包羅萬象,非常複雜的場景有時還是需要對引擎有一定了解的同學去診斷和分析,給出優化建議。位元組目前也在不斷完善這些經驗,希望能夠通過不斷完善 Metrics 和分析的路徑,持續減輕 Oncall 的負擔,在某些場景下能夠更加準確地給出優化建議。
效果與展望
根據上述所提,目前執行模型存在三個缺點,我們進行了複雜查詢的優化,因此需要驗證這種新的模式是否能夠解決發現的問題,測試場景如下:
-
第二階段計算較複雜,且第一階段資料較多
-
Hash Join 右表是大表
-
多表 Join,模擬複雜 Query
以 SSB 1T 資料作為資料集,環境則是構建了 8 個節點的叢集。
Case1——二階段計算複雜。我們看到有一個比較重的計算運算元 UniqExact,就是 count distinct 的計算方式,通過 Hash 表做去重。count distinct 預設採用這種演演算法,當我們使用複雜查詢後,Query 的執行時間從 8.5 秒減少到 2.198 秒。第二階段 agg uniqExact 運算元的合併原本由 coordinator 單點合併,現在通過按照 group by key shuffle 後可以由多個節點並行完成。因此通過 shuffle 減輕了 coordinator 的 merge agg 壓力。

Case2——右表為大表。由於 ClickHouse 對多表的優化做的還不是很到位。這裡採用子查詢來下推過濾的條件。在這個 case 中,Lineorder 是一張大表,採用複雜查詢的模式以後,Query 執行時間從 17 秒優化到了 1.7 秒。由於 Lineorder 是一張大表,通過 Shuffle 可以將資料按照 Join key Shuffle 到各 Worker 節點上,這樣就減少了右表構建的壓力。

Case3——多表 Join。開啟複雜查詢後,Query 的執行時間從 8.58 秒優化到 4.464 秒,所有的右表都可以同時開始資料的處理和構建。為了和現有模式做對比,複雜查詢這裡並沒有開啟 runtime filter,開啟 runtime filter 後效果會更好。

事實上,優化器對複雜查詢的效能提升也非常大,通過一些 RBO 的規則,例如常見的謂詞下推、相關子查詢的處理等,可以極大提升 SQL 的執行效率。在複雜查詢的模式下,由於有優化器的存在,使用者甚至不需要寫得非常複雜,優化器自動去完成這些下推和 RBO 規則優化。
此外,選擇用哪一種 Join 的實現,也會對 Join 的效能影響較大。若能夠滿足 Join Key 分佈,使用 Colocate Join 可以減少左右表 Shuffle 的傳輸代價。在多表 Join 的情況下,Join 的順序和 Join 的實現方式對執行的時長影響,會比兩表 Join 更大。藉助這種資料的統計資訊,通過一些 CBO 的優化,可以得到一個比較好的執行模式。
有了優化器,業務同學可以按照業務邏輯來寫任何的 SQL,引擎自動計算出相對最優的 SQL 計劃並執行,加速查詢的執行。
總結一下,ClickHouse 目前的執行模式在很多單表的場景下表現非常優異,我們主要針對複雜場景做優化,通過實現多 Stage 的模式,實現了 Stage 之間的資料的傳輸,從工程實踐上做了較多嘗試和優化,去提升執行和網路傳輸的效能。並希望通過完善 Metrics 和智慧診斷來降低 SQL 分析和調優的門檻。目前已經實現了第一步,未來位元組仍有很多努力的方向。
首先,是要繼續去提升執行和 Exchange 的效能。這裡不談論引擎執行通用的優化,比如更好的索引或者運算元的優化,主要是跟複雜查詢模式有關。舉一個例子,比如 Stage 複用,在 SQL 出現子查詢結果被反覆使用的場景,比如一些多表 join 和 CTE 場景可能有幫助。通過 Stage 複用可以減少相同資料的多次讀取。Stage 複用我們之前就已經支援,但是用的場景比較少,未來準備更靈活和通用。其次,Metrics 和智慧診斷加強。SQL 的靈活度很高,因此一些複雜查詢如果沒有 Metrics 其實幾乎很難去做診斷和調優。以上都是位元組跳動資料平臺在未來會長期的持續去發力的方向。