Kafka KRaft模式探索
1.概述
Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者在網站中的所有動作流資料。其核心元件包含Producer、Broker、Consumer,以及依賴的Zookeeper叢集。其中Zookeeper叢集是Kafka用來負責叢集後設資料的管理、控制器的選舉等。
2.內容
目前,Kafka在使用的過程當中,會出現一些問題。由於重度依賴Zookeeper叢集,當Zookeeper叢集效能發生抖動時,Kafka的效能也會收到很大的影響。因此,在Kafka發展的過程當中,為了解決這個問題,提供KRaft模式,來取消Kafka對Zookeeper的依賴。
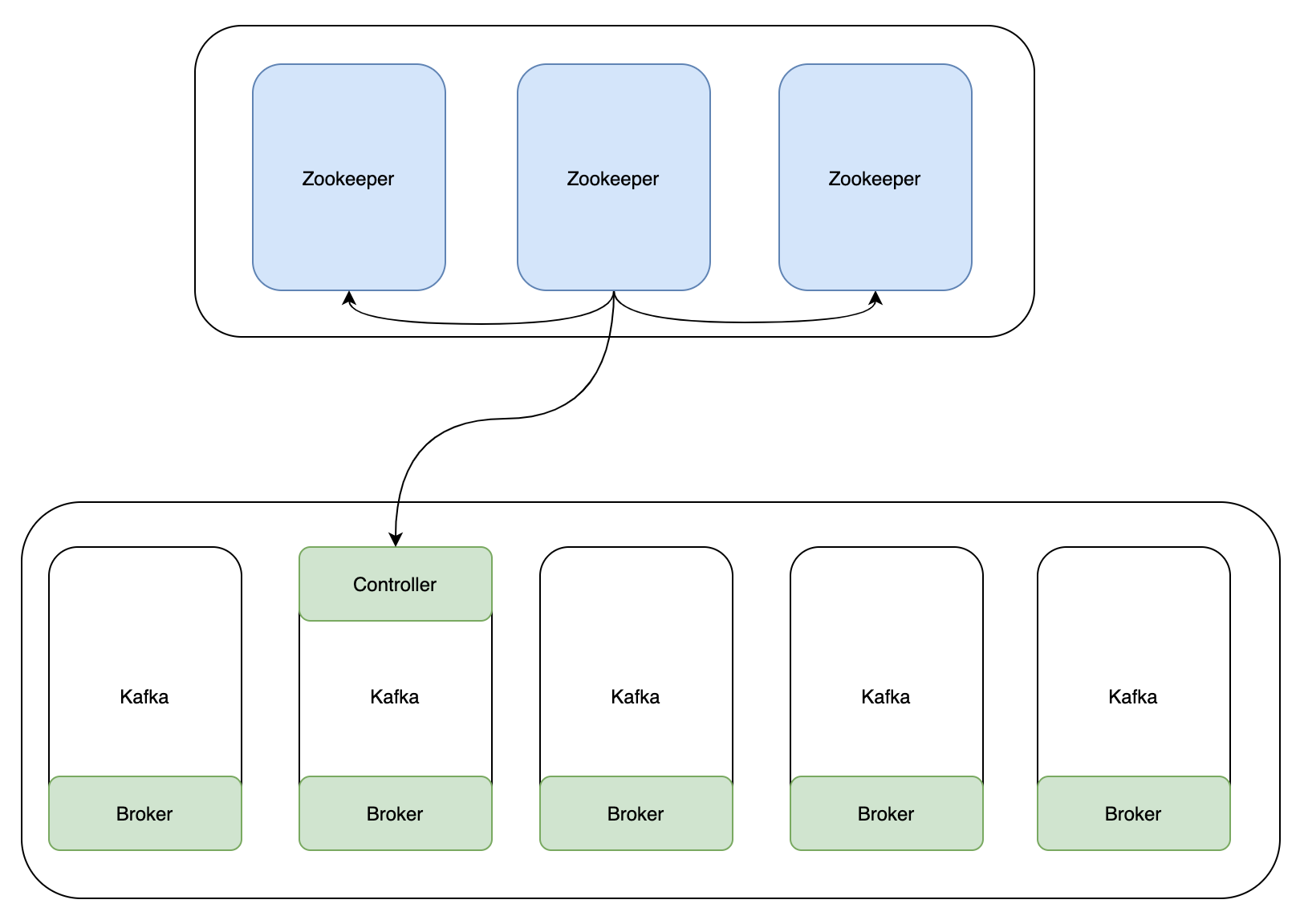
上圖是在未使用KRaft模式時,Kafka的一個架構,在做後設資料管理、Controller的選舉等都需要依賴Zookeeper叢集。
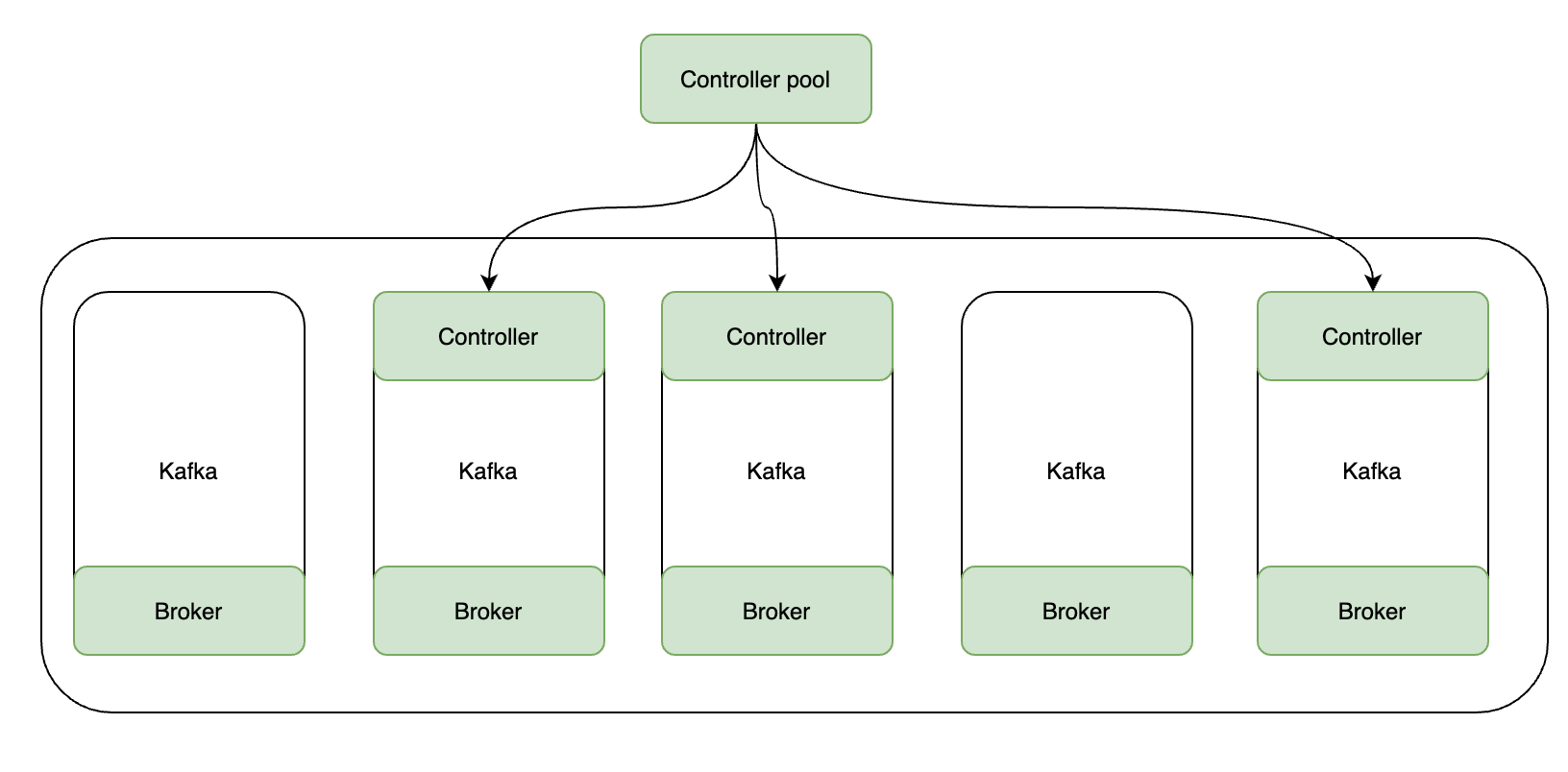
在Kafka引入KRaft新內部功能後,對Zookeeper的依賴將會被取消。在 KRaft 中,一部分 broker 被指定為控制器,這些控制器提供過去由 ZooKeeper 提供的共識服務。所有叢集後設資料都將儲存在 Kafka 主題中並在內部進行管理。
2.1 KRaft模式的優勢
- 更簡單的部署和管理——通過只安裝和管理一個應用程式,Kafka 現在的運營足跡要小得多。這也使得在邊緣的小型裝置中更容易利用 Kafka;
- 提高可延伸性——KRaft 的恢復時間比 ZooKeeper 快一個數量級。這使我們能夠有效地擴充套件到單個叢集中的數百萬個分割區。ZooKeeper 的有效限制是數萬;
- 更有效的後設資料傳播——基於紀錄檔、事件驅動的後設資料傳播可以提高 Kafka 的許多核心功能的效能。
1. KRaft叢集節點角色
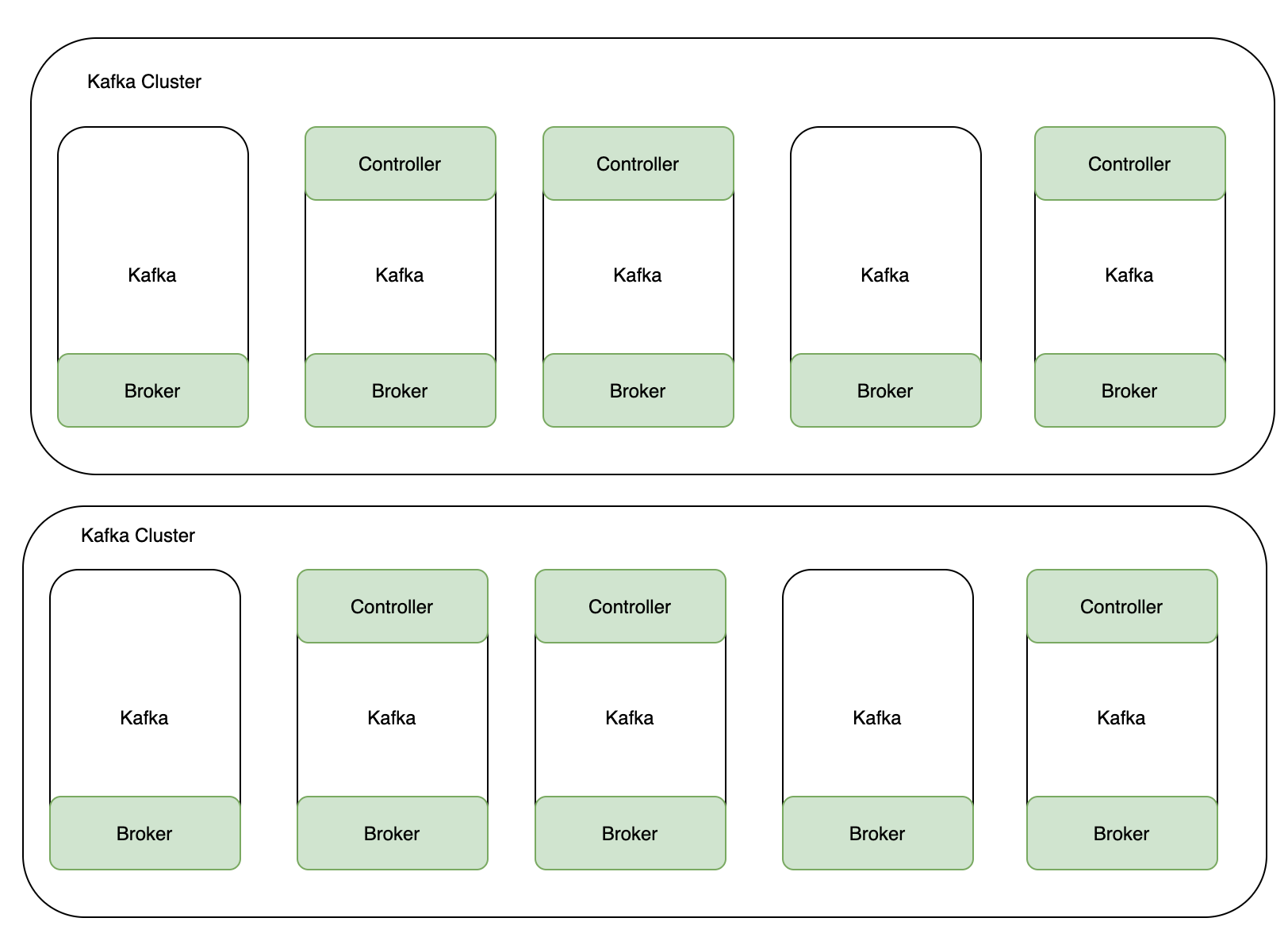
在 KRaft 模式下,Kafka 叢集可以以專用或共用模式執行。在專用模式下,一些節點將其process.roles設定設定為controller,而其餘節點將其設定為broker。對於共用模式,一些節點將process.roles設定為controller, broker並且這些節點將執行雙重任務。採用哪種方式取決於叢集的大小。
2. KRaft模式控制器
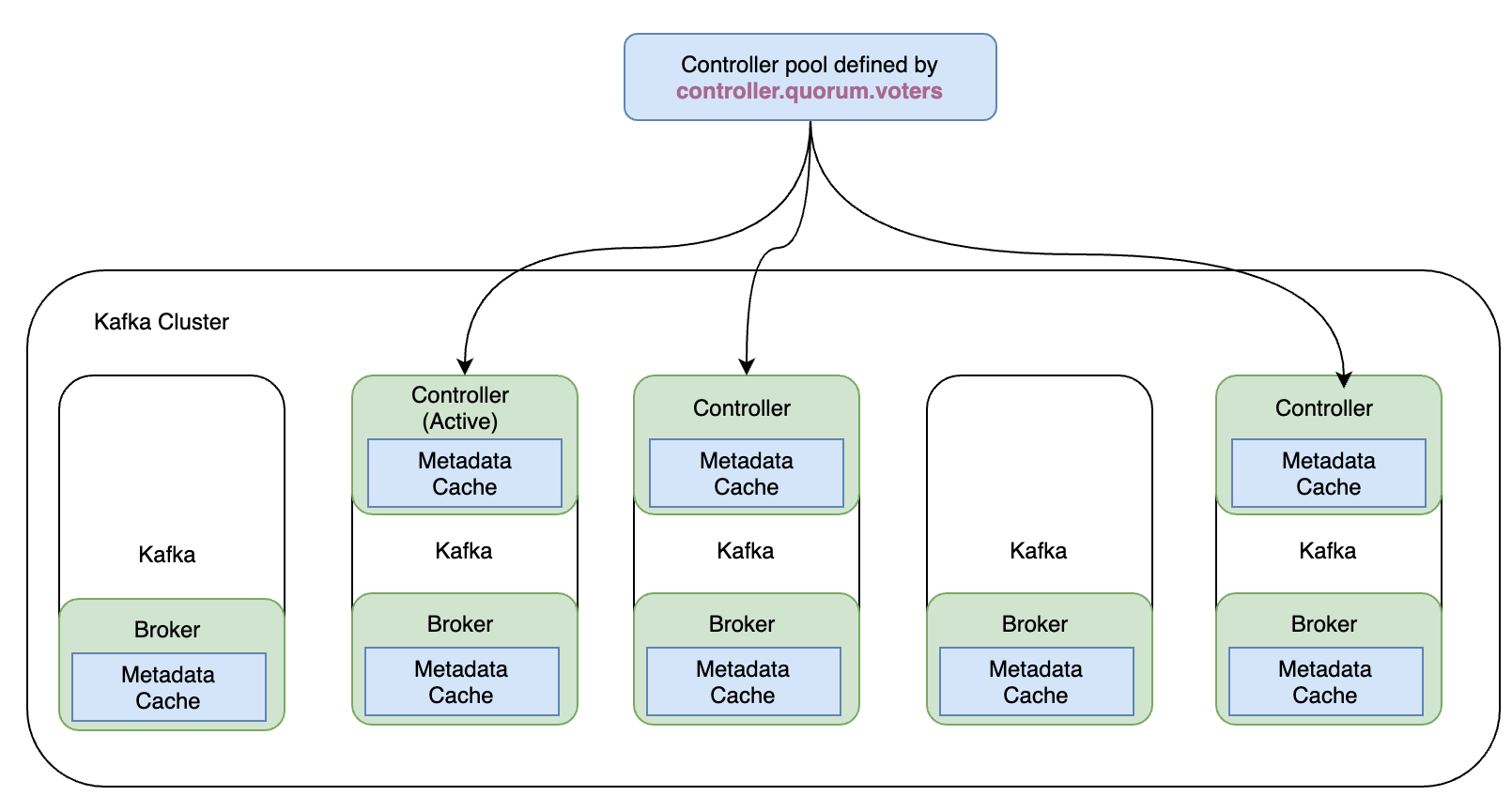
在 KRaft 模式叢集中充當控制器的代理列在controller.quorum.voters每個代理上設定的設定屬性中。這允許所有代理與控制器進行通訊。這些控制器代理之一將是活動控制器,它將處理與其他代理通訊對後設資料的更改。
所有控制器代理都維護一個保持最新的記憶體後設資料快取,以便任何控制器都可以在需要時接管作為活動控制器。這是 KRaft 的特性之一,使其比基於 ZooKeeper 的控制平面高效得多。
3. KRaft叢集後設資料
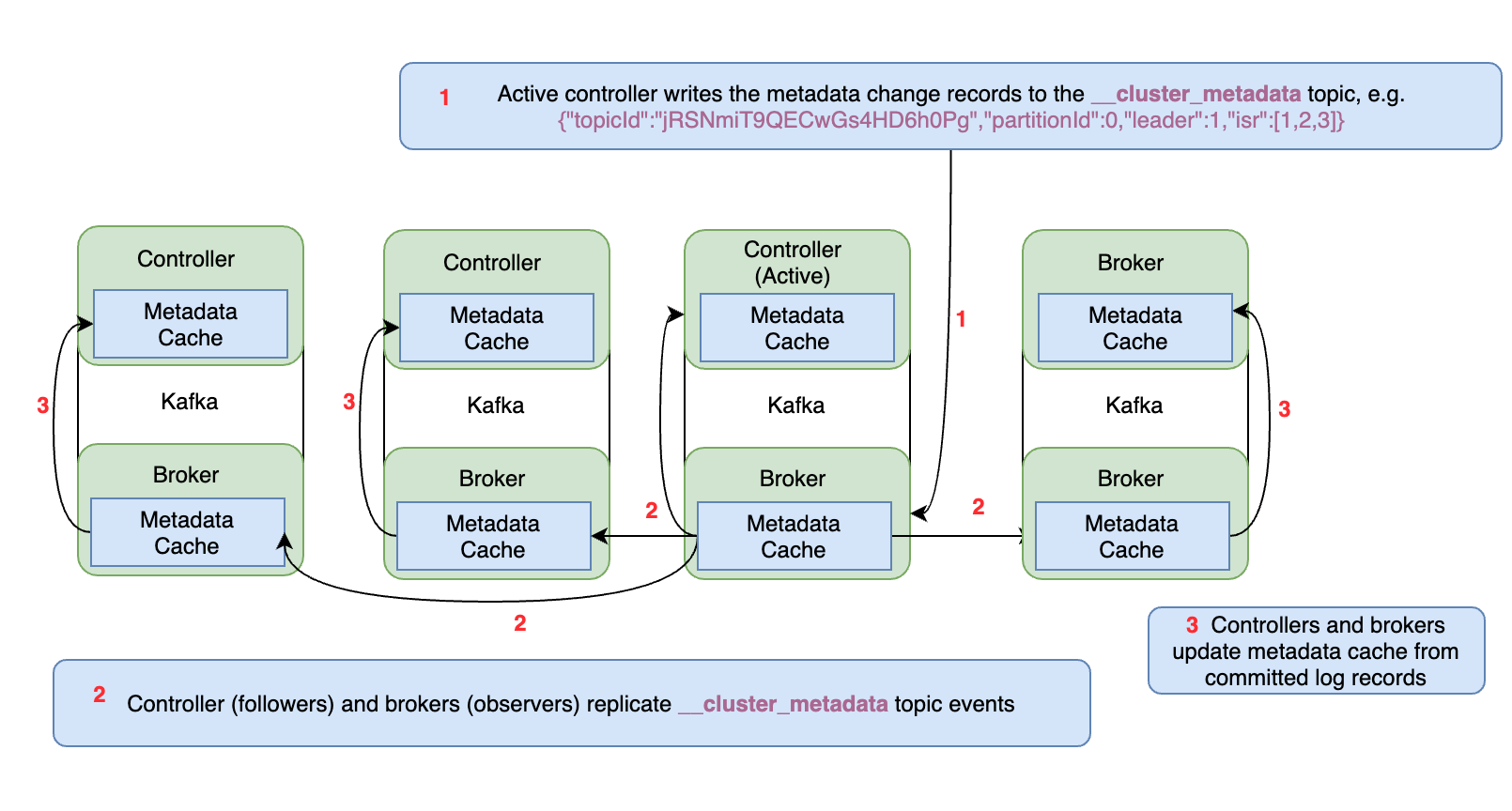
KRaft 基於 Raft 共識協定,該協定作為 KIP-500 的一部分引入 Kafka,並在其他相關 KIP 中定義了更多細節。在 KRaft 模式下,叢集後設資料(反映所有控制器管理資源的當前狀態)儲存在名為__cluster_metadata. KRaft 使用這個主題在控制器和代理節點之間同步叢集狀態更改。
活動控制器是這個內部後設資料主題的單個分割區的領導者。其他控制器是副本追隨者。經紀人是副本觀察者。因此,不是控制器將後設資料更改廣播給其他控制器或代理,而是它們各自獲取更改。這使得保持所有控制器和代理同步非常有效,並且還縮短了代理和控制器的重啟時間。
4. KRaft後設資料複製
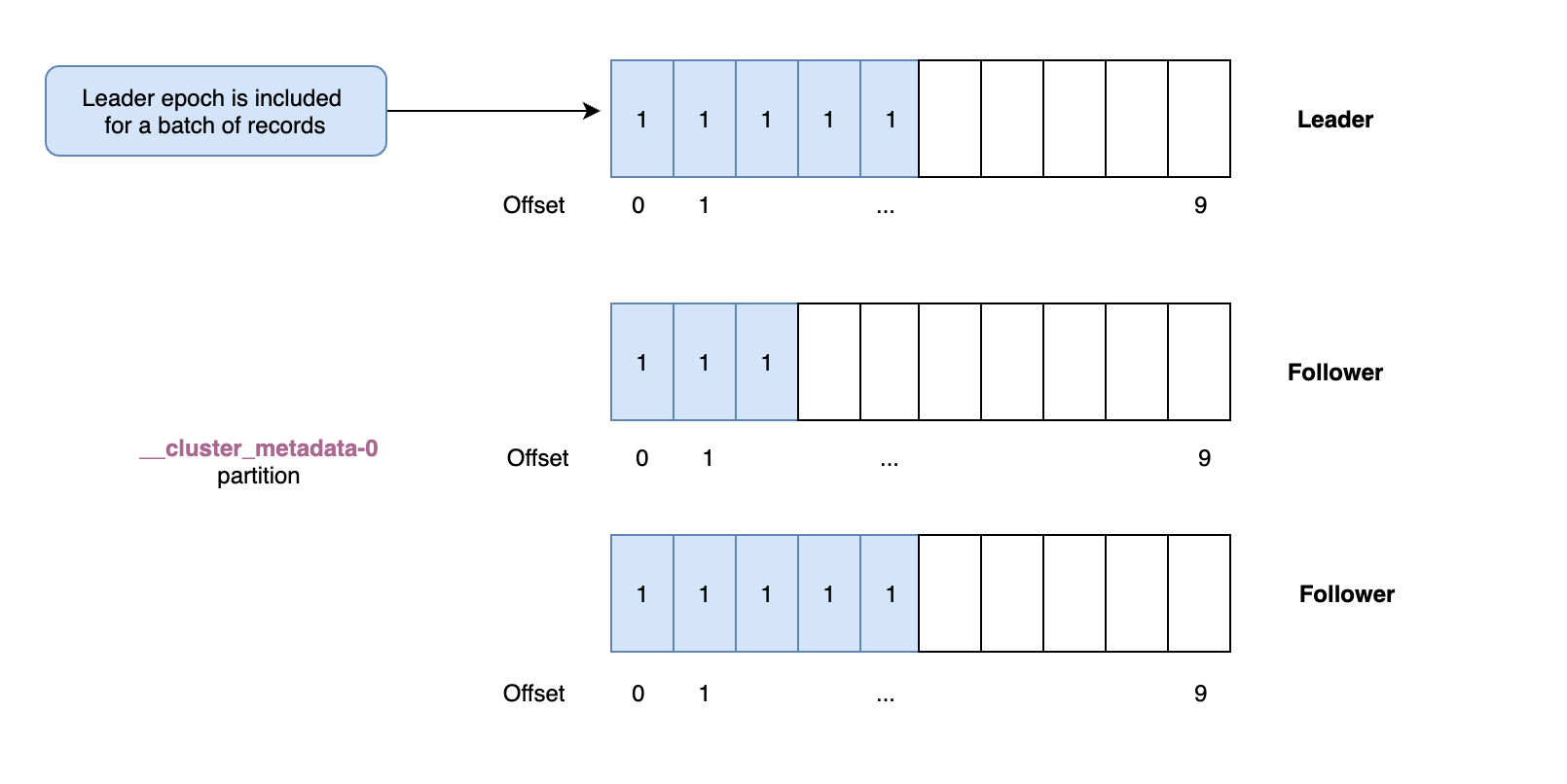
由於叢集後設資料儲存在 Kafka 主題中,因此該資料的複製與我們在資料平面複製模組中看到的非常相似。活動控制器是後設資料主題的單個分割區的領導者,它將接收所有寫入。其他控制器是跟隨者,將獲取這些更改。我們仍然使用與資料平面相同的偏移量和領導者時期。但是,當需要選舉領導者時,這是通過仲裁完成的,而不是同步副本集。因此,後設資料複製不涉及 ISR。另一個區別是後設資料記錄在寫入每個節點的本地紀錄檔時會立即重新整理到磁碟。
5. Leader選舉
當叢集啟動時以及當前領導者停止時,無論是作為捲動升級的一部分還是由於故障,都需要進行控制器領導者選舉。現在讓我們看一下 KRaft 領導人選舉所涉及的步驟。
- 投票請求:
- 當需要選舉leader控制器時,其他控制器將參與選舉新的leader。一個控制器,通常是第一個意識到需要新領導者
VoteRequest的控制器,將向其他控制器傳送一個。該請求將包括候選者的最後一個偏移量以及與該偏移量關聯的時期。它還將增加該時期並將其作為候選時期傳遞。候選控制器也將為該時期投票給自己;
- 當需要選舉leader控制器時,其他控制器將參與選舉新的leader。一個控制器,通常是第一個意識到需要新領導者
- 投票響應:
- 當跟隨者控制器接收到 a
VoteRequest時,它將檢查它是否看到了比候選者傳入的時期更高的時期。如果它有,或者如果它已經在同一時期投票給了不同的候選人,它將拒絕該請求。否則,它將檢視候選人傳遞的最新偏移量,如果它與自己的相同或更高,它將授予投票。該候選控制器現在有兩票:它自己的票和剛剛被授予的票。第一個獲得多數票的控制器成為新的領導者。
- 當跟隨者控制器接收到 a
- 完成:
-
一旦候選人獲得了多數票,它將認為自己是領導者,但它仍然需要將此通知其他控制者。為此,新領導者將向
BeginQuorumEpoch其他控制器傳送包括新紀元在內的請求。現在選舉已經完成。當舊的leader控制器重新上線時,它將在新的epoch跟隨新的leader,並將自己的後設資料紀錄檔與leader同步。
3.KRaft 叢集後設資料快照
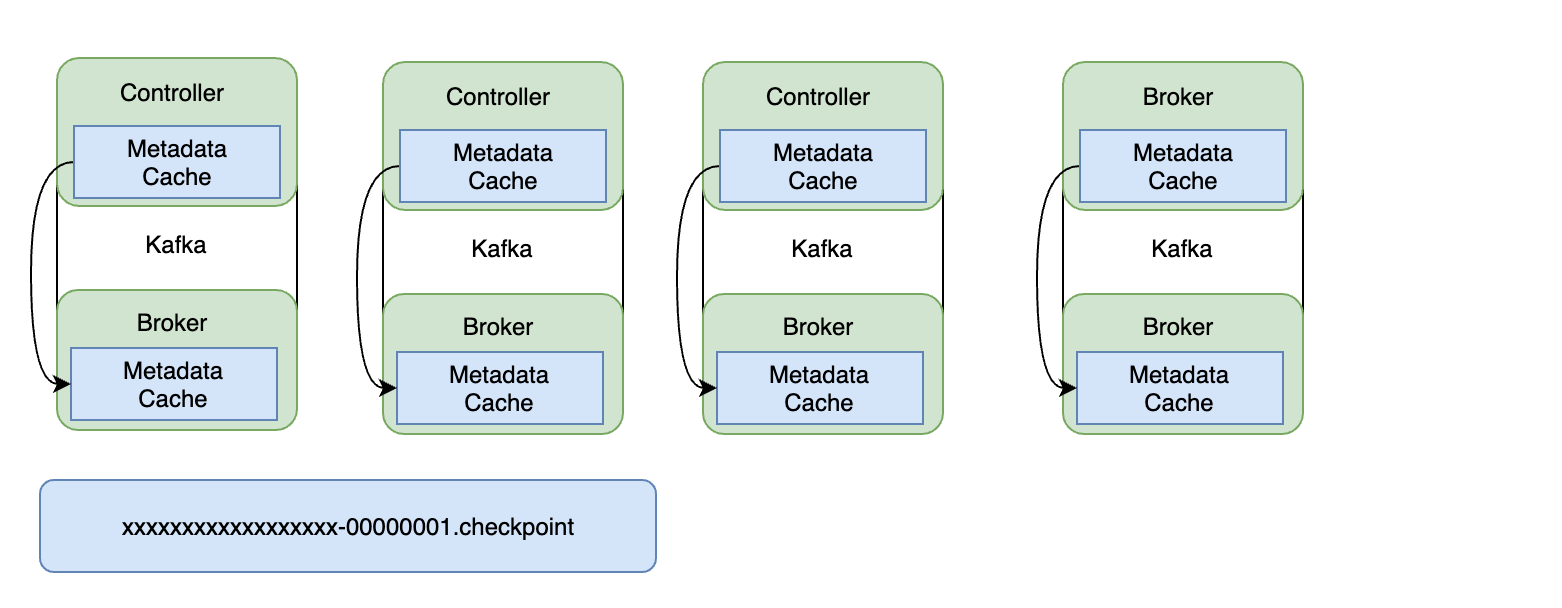
沒有明確的點我們知道不再需要叢集後設資料,但我們不希望後設資料紀錄檔無休止地增長。此要求的解決方案是後設資料快照。每個控制器和代理都會定期對其記憶體中的後設資料快取進行快照。這個快照被儲存到一個用結束偏移和控制器紀元標識的檔案中。現在我們知道後設資料紀錄檔中所有早於該偏移量和紀元的資料都已安全儲存,並且可以將紀錄檔截斷到該點。快照連同後設資料紀錄檔中的剩餘資料仍然會為我們提供整個叢集的完整後設資料。
3.1 讀取快照
後設資料快照的兩個主要用途是代理重新啟動和新代理上線。
當現有代理重新啟動時,它 (1) 將其最近的快照載入到記憶體中。然後EndOffset從其快照開始,它 (2) 從其本地__cluster_metadata紀錄檔中新增可用記錄。然後它 (3) 開始從活動控制器中獲取記錄。如果獲取的記錄偏移量小於活動控制器LogStartOffset,則控制器響應包括其最新快照的快照 ID。然後代理 (4) 獲取此快照並將其載入到記憶體中,然後再次繼續從__cluster_metadata分割區領導者(活動控制器)獲取記錄。
當一個新的代理啟動時,它 (3) 第一次開始從活動控制器中獲取記錄。通常,此偏移量將小於活動控制器LogStartOffset,並且控制器響應將包括其最新快照的快照 ID。代理 (4) 獲取此快照並將其載入到記憶體中,然後再次繼續從__cluster_metadata分割區領導者(活動控制器)獲取記錄。
該__cluster_metadata主題將snapshot作為cleanup.policy。Kafka 控制器和後設資料快取將在記憶體中表示覆制的紀錄檔,最多可達高水位線。在執行快照時,Kafka 控制器和後設資料快取會將這個記憶體狀態序列化到磁碟。磁碟上的此快照檔案由已包含的複製紀錄檔的結束偏移量和紀元描述。
Kafka 控制器和後設資料快取將在 Kafka Raft 使用者端完成生成新快照時通知它。將紀錄檔的字首截斷到最新的快照是安全的。主題分割區將__cluster_metadata擁有最新的快照和零個或多箇舊快照。這些額外的快照必須被刪除,這在「何時刪除快照」中有描述。
3.2 快照設計
Kafka Raft 主題分割區如下所示:
Kafka Replicated Log: LogStartOffset -- high-watermark -- LEO -- V V V ----------------------------------------------- offset: | x | ... | y - 1 | y | ... | | ... | | epoch: | b | ... | c | d | ... | | ... | | ----------------------------------------------- Kafka Snapshot Files: <topic_name>-<partition_index>/x-a.checkpoint <topic_name>-<partition_index>/y-c.checkpoint
需要注意的是,checkpoint將使用擴充套件名,因為 Kafka 已經有一個帶有snapshot擴充套件名的檔案。
-
LEO - 紀錄檔結束偏移量 - 要寫入磁碟的下一個偏移量。
-
high-watermark - 已複製到 N/2 + 1 個副本的最大偏移量和 epoch。
-
LogStartOffset - 紀錄檔開始偏移量 - 複製紀錄檔中的最小偏移量。
3.3 快照格式
Kafka 控制器和後設資料快取負責快照的內容。每個快照都由一個唯一標識SnapshotId,即快照中包含的複製紀錄檔中記錄的紀元和結束偏移量。快照將儲存在主題分割區目錄中,名稱為<SnapshotId.EndOffset>-<SnapshotId.Epoch>.checkpoint. 例如,對於主題 __cluster_metadata、分割區 0、快照結束偏移 5120793 和快照 epoch 2,完整檔名將是__cluster_metadata-0/00000000000005120793-00000000000000000002.checkpoint.
快照時期將在訂購快照時使用,更重要的LastFetchedEpoch是在 Fetch 請求中設定欄位時使用。追隨者可能有快照和空紀錄檔。在這種情況下,follower 將LastFetchEpoch在 Fetch 請求中設定時使用快照的紀元。
快照檔案的磁碟格式將與紀錄檔格式的版本 2 相同。這是版本 2 的紀錄檔格式供參考:
RecordBatch => BatchHeader [Record] BatchHeader BaseOffset => Int64 Length => Int32 PartitionLeaderEpoch => Int32 Magic => Int8 CRC => Uint32 Attributes => Int16 LastOffsetDelta => Int32 // also serves as LastSequenceDelta FirstTimestamp => Int64 MaxTimestamp => Int64 ProducerId => Int64 ProducerEpoch => Int16 BaseSequence => Int32 Record => Length => Varint Attributes => Int8 TimestampDelta => Varlong OffsetDelta => Varint Key => Bytes Value => Bytes Headers => [HeaderKey HeaderValue] HeaderKey => String HeaderValue => Bytes
使用紀錄檔格式的版本 2 將允許 Kafka 控制器和後設資料快取壓縮記錄並識別快照中的損壞記錄。即使快照使用紀錄檔格式儲存此狀態,也沒有要求:
- 在and中分別使用有效的
BaseOffset和。OffsetDeltaBatchHeaderRecord - 使快照中的記錄與複製紀錄檔中的記錄相匹配。
3.4 快照記錄
為了允許 KRaft 實現在不影響 Kafka 控制器和後設資料快取的情況下包含有關快照的附加資訊,快照將包含兩個控制記錄批次。控制記錄批次SnapshotHeaderRecord 將始終是快照中的第一個記錄批次。控制記錄批次SnapshotFooterRecord 將是快照中的最後一個記錄批次。這兩條記錄將具有以下架構。
1.快照頭架構
{ "type": "data", "name": "SnapshotHeaderRecord", "validVersions": "0", "flexibleVersions": "0+", "fields": [ {"name": "Version", "type": "int16", "versions": "0+", "about": "The version of the snapshot header record"}, { "name": "LastContainedLogTimestamp", "type": "int64", "versions": "0+", "about": "The append time of the last record from the log contained in this snapshot" } ] }
2.快照腳架構
{ "type": "data", "name": "SnapshotFooterRecord", "validVersions": "0", "flexibleVersions": "0+", "fields": [ { "name": "Version", "type": "int16", "versions": "0+", "about": "The version of the snapshot footer record" } ] }
4.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!
另外,博主出書了《Kafka並不難學》和《Hadoop巨量資料挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點選購買連結購買博主的書進行學習,在此感謝大家的支援。關注下面公眾號,根據提示,可免費獲取書籍的教學視訊。
郵箱:[email protected]
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社群1):424769183
QQ群(Kafka並不難學): 825943084
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),方便管理員稽核,謝謝!
